
【飞桨特色模型挑战赛】CTRGCN的轻量化
对CTRGCN模型进行轻量化,在inference模型约为9.7M(小于10M)条件下,在NTU-RGB+D数据集,joint模态,X-sub评测标准,Top1指标为91.157%(大于89%)!
2022年10月12日最新提交所做的改进(当前V3):增加精度为91.157%的CTRCGN_lightV2,其GPU和CPU上推理速度对比分别比原模型分别快1.72倍和1.71倍!
2022年10月8日最新提交所做的改进(见V2):第一、增加使用添加mixup数据增强方法、CustomWarmupCosineDecay学习率衰减函数、标签平滑、更多训练epochs等改进的调优后训练配置训练后导出的推理模型,精度高达90.953%;第二、增加GPU和CPU上推理速度对比,我们的轻量化模型要比原模型分别快1.33倍和1.6倍;第三、增加与竞品的对比
一、简介
1.1 任务要求
本次任务是要对CTRGCN模型进行轻量化,官方释放的在NTU-RGB+D数据集,joint模态,X-sub评测标准下的CTRGCN模型的Top1精度为89.93%,推理文件夹大小约为14.5MB(CTRGCN_joint.pdiparams:5.6MB,CTRGCN_joint.pdiparams.info:62.1KB,CTRGCN_joint.pdmodel:8.8MB),要求是:
- 对模型进行轻量化,在inference模型小于
10M条件下,在NTU-RGB+D数据集,joint模态,X-sub评测标准,Top1指标大于89%且最优指标取胜; - 完成轻量化后的模型的TIPC基础链条功能验证;
- 复现后合入PaddleVideo
1.2 CTRGCN模型介绍
我们首先简要介绍CTRGCN的创新之处CTR-GC,即其空间建模部分,然后介绍CTR-GCN的整体结构。
1.2.1 CTR-GC
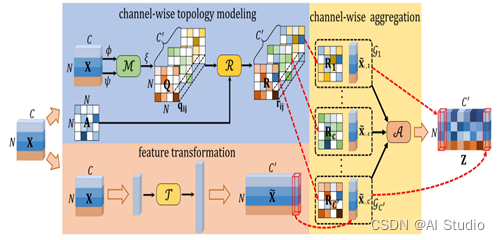
在上图展示了CTR-GC的总体框架。结合上图和下图(b),首先将输入特征X(形状为(B, T, N, C))利用特征变换函数T(·)进行特征变换(即降维),得到x1, x2(形状为(B, T, N, C//r));然后分别进行时间维度全局池化得到x1, x2(形状为(B, N, C//r)),再利用通道相关性建模函数M(·)对x1, x2进行处理,M(·)可以是简单的act(x1-x2),也可以是MLP(x1, x2),论文里取的是act(x1-x2),即x1(B, N, 1, C//r)-x2(B, 1, N, C//r),这样得到通道特定的关系A’(形状为(B, N, N, C//r)),然后再利用1x1 conv进行升维操作,得到A’(形状为(B, N, N, C’));最后和初始化为物理图拓扑结构的通道共享自适应图拓扑矩阵A(形状为(N, N))加权求和,得到通道细化的图拓扑结构(形状为(B, N, N, C’)),与使用1x1 conv特征变换后的特征X’ (形状为(B, T, N, C’)) 相乘进行空间信息聚集。
其中B表示一个batch的样本数量,T表示时间维度的帧数,N表示关节点数目,C表示特征维度,r表示维度降低的倍数,论文里取r=8;T(·)一般采用1x1 conv,act(·)表示激活函数,论文里选用Tanh(·)函数,MLP表示多层感知机,C’表示变换后(比如升维操作)的特征维度。,
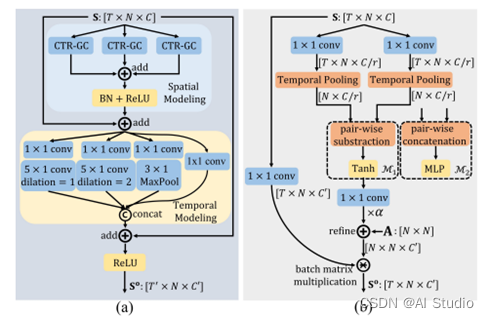
1.2.2 CTR-GCN整体结构
如上图(a)所示,CTR-GCN的基础Block是由空间建模模块和时序建模模块两部分组成。其中空间建模模块利用三个CTR-GC并行提取人体关键点之间的关系,将三个分支的结果求和作为最终的输出,然后经过常用的BN、ReLU层,并利用残差连接将输出和输入求和,作为时序建模模块的输入。为了提高模型速度,时序建模模块只使用了4个分支来建模多尺度的时域信息,提高了时域建模能力。每一个分支都包含一个1x1 conv进行通道降维。前三个分支包含两个不同空洞率的时序建模卷积和一个时间维最大池化。最后将四个分支的结果沿通道维拼接作为最终的输出。整个模型由十个上述描述的基础Block、一个全局平均池化层和一个全连接分类器组成。十个Block的输出通道数量是64-64-64-64-128-128-128-256-256-256。在第5个Block和第8个Block,时序建模卷积的stride=2,时间维度减半。
二、轻量化模型介绍及其精度、大小
2.1 CTRGCN_light的简述
最初我们是一味地使用轻量的模块如ghost模块来代替原始卷积从而减少总的参数量和浮点数运算量,但无疑增加了模型的复杂性,模型结构变得更加琐碎,这使得模型权重文件(即CTRGCN_joint.pdiparams)得以大幅度减小,但带来的代价是模型结构文件大小(即CTRGCN_joint.pdmodel)增大,二者互相抵消,导致很难达到总的文件大小不超过10MB。在逐步替代CTRGCN的时序建模模块(即MultiScale_TemporalConv模块)和空间建模模块(即unit_gcn模块)时,我们发现CTRGCN的空间建模模块对导出的推理模型的权重文件大小(即CTRGCN_joint.pdiparams)及模型结构文件大小(即CTRGCN_joint.pdmodel)影响很大。同时,我们认为每个bock均使用提取人体关键点之间的关系的空间建模模块很可能是过度冗余的,即没必要在每个基础Block中均使用空间建模模块。因此,为了保持相同的时域感受野,我们保留了相同深度的时序建模模块,而是减少不必要的一些空间建模模块。左图为原始的CTRGCN基础块堆叠结构,右图是我们的轻量化的CTRGCN_light的基础块堆叠结构。


根据输出时域分辨率,我们姑且将CTRGCN模型分为3个阶段(l1, l2, l3, l4为第一阶段,l5, l6, l7为第二阶段,l8, l9, l10为第三阶段),可以看到,我们在每个阶段的最后一个block保留了空间建模模块,除了第一个阶段是开始的第一个block保留了空间建模模块,其余阶段均是第二个block保留了空间建模模块,好处是在尽可能保留模型表达能力的同时,使用下采样后的分辨率来减少推理模型的总大小,其中TCN_unit是TCN_GCN_unit去掉空间建模模块的结构。除此之外,为了满足推理模型大小目标,我们进一步将base channel的大小从64调整为60。CTRGCN_light模型见paddlevideo/modeling/backbones/ctrgcn_light.py
我们之前使用PaddleVideo官方释放的CTRGCN训练配置训练我们的轻量化模型,但仍然出现了轻微的过拟合现象,并且回顾CTRGCN的原论文,实际的weight decay应设为4e-4(原来是1e-4)。然后为了进一步地减轻过拟合,与configs/recognition/agcn/agcn_ntucs.yaml一致,我们运用了mixup数据增强方法,系数alpha同样设为0.2,由于温启余弦学习率衰减函数(CustomWarmupCosineDecay)在一般情况下都要优于阶梯衰减函数,因此与agcn_ntucs.yaml一致,我们采取温启余弦学习率衰减函数,由于原推理模型是我们的轻量化推理模型的1.5倍,遵循从头剪枝方法提出的建议,为了使轻量化模型足够收敛,我们将训练总epochs也扩大约1.5倍,65*1.5约为98,故设为100个epochs,温启epochs设为其的0.1倍,即10个。由于标签平滑正则化也能对性能带来提升,我们同样引入了,其超参数ls_eps设为0.1。以前的训练配置见configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint.yaml,经过以上改进调优后的训练配置见configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml。
2.2 CTRGCN_lightV2的简述
出发点:我们认为琐碎的结构是不利于GPU并行加速和会带来结构的复杂性(导致推理模型结构文件体积过大),因此我们将时序建模模块每个分支的小的1x1卷积抽取出来,合并成一个大的1x1卷积,然后在前向传播中以内存划分为代价来为每个分支分配相应的1x1卷积输出;将空间建模模块num_subset个CTR-GC块合并成一个CTR-GC块,即进行模块融合和卷积融合来减少琐碎结构,但均是以前向传播中内存划分为代价。如此两个操作,使得推理模型的模型结构文件大幅下降且起到了稍微的加速作用。但仅此,正常导出的推理模型总大小仍然是不满足要求的,为此,我们进一步做了3处精简,第一:在stride=2时,设空间建模模块的输出等于输入(原来是输出是输入的2倍);第二:对模块融合和卷积融合后的CTR-GC进行精简,即对CTR-GC的输入只变换得到1个通道特定的关系A’,而不是原来的num_subset个,然后利用保留的num_subset个1x1 conv进行升维操作来使得num_subset个A’有差异性,尽可能得保持模型容量;第三、将base channel的大小从64调整为62。我们将其称之为CTRGCN_lightV2,其模型实现见paddlevideo/modeling/backbones/ctrgcn_light_v2.py。当然从CTRGCN_light到CTRGCN_lightV2中间存在一系列过渡模型,这里仅选取了推理加速明显且精度相对高的CTRGCN_lightV2,其余有时间整理。我们训练CTRGCN_lightV2是采用CTRGCN_light提到的调优后的训练配置,仅修改了骨干网络名字为"CTRGCN_lightV2"和修改base_channel为62,具体参数可见configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml
2.3 实验结果对比
轻量化CTRGCN与原始CTRGCN的精度及推理模型大小、速度对比:
| 模型 | 精度 | 正常导出的推理模型大小 | 使用最小化导出 | GPU推理速度(ms)(越低越好) | CPU推理速度(ms)(越低越好) |
|---|---|---|---|---|---|
| CTRGCN | 89.93% | 约14.5MB | 约12.0MB | 31.4189 | 302.6343 |
| 这位大佬的提交 | 90.967% | 约12.1MB | 约9.9MB | 28.9143 | 263.1905 |
| 官方训练配置下CTRGCN_light | 89.313% | 约9.7MB | 约8.1MB | 23.6619 | 188.5445 |
| 调优后配置下CTRGCN_light | 90.953% | 约9.7MB | 约8.1MB | 23.6619 | 188.5445 |
| 调优后配置下CTRGCN_lightV2 | 91.157% | 约9.8MB | 约8.2MB | 18.233 | 177.4101 |
| 调优后配置下CTRGCN_lightV2_dml | 91.187% | 约9.8MB | 约8.2MB | 18.233 | 177.4101 |
由上表可知:
对于CTRGCN_light:9.7MB = CTRGCN_joint.pdiparams:3.9MB,CTRGCN_joint.pdiparams.info:46KB,CTRGCN_joint.pdmodel:5.7MB,存放于inference/CTRGCN_light_joint_my中,其中old文件夹下是使用PaddleVideo官方释放的CTRGCN训练配置下得到的CTRGCN_light的推理模型,new文件夹中存放的是使用调优后训练配置训练得到的CTRGCN_light的推理模型,取得了90.953%的高精度。
对于CTRGCN_lightV2:9.8MB = CTRGCN_joint.pdiparams:4.3MB,CTRGCN_joint.pdiparams.info:33.3KB,CTRGCN_joint.pdmodel:5.4MB,存放于inference/CTRGCN_lightV2_joint_my中,精度为91.157%!
最小化导出是指去掉RecognizerGCN及BaseRecognizer封装的外壳(这些外壳应该是PaddleVideo为了统一基于骨骼点的动作识别GCN模型,使得研究者专注于模型骨干结构的设计),而直接使用nn.Sequential封装模型的骨干和分类头,从而减轻模型封装的复杂度,使得导出的模型更加轻量。这样做虽然使得导出模型大小满足了任务要求,但实际上并没有起到加速作用。可以看到,相比竞品,我们的两个轻量化模型在取得了相似甚至更高的精度的同时,推理速度要远远高于它,而推理模型大小不管正常导出,还是最小化导出均满足任务要求!
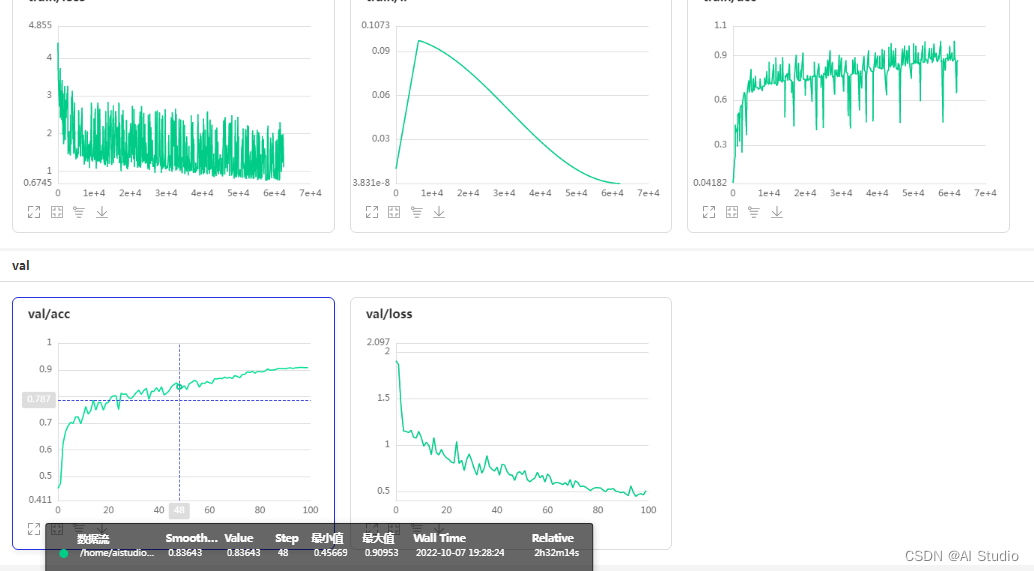
精度为90.953%的CTRGCN_light训练日志在output/CTRGCN_light_my/new文件夹下的logs文件夹中,可以通过visuadl可视化(即左手边的可视化按钮)打开。visualdl下的训练日志曲线如下图所示:
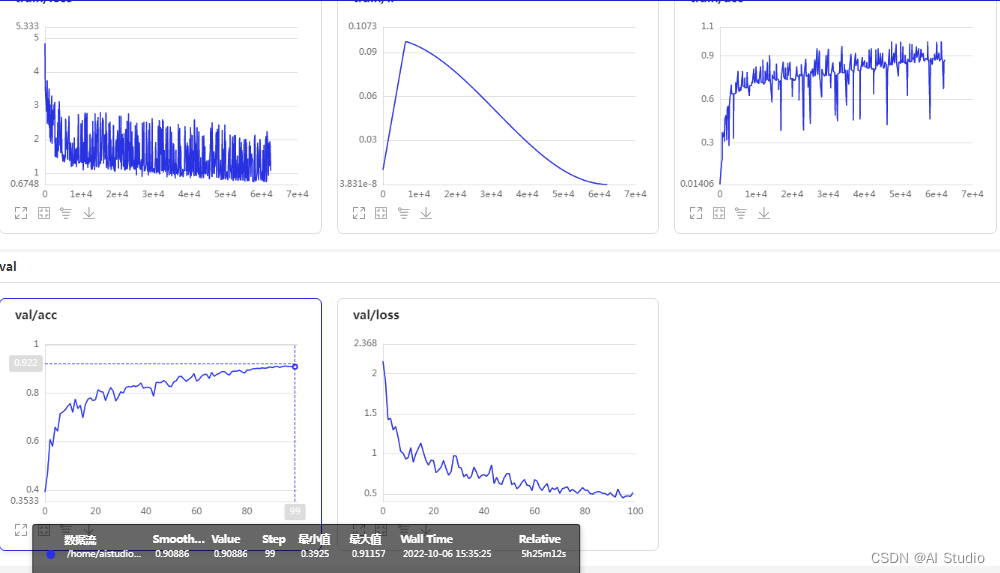
精度为91.157%的CTRGCN_lightV2训练日志在output/CTRGCN_lightV2_my/文件夹下的logs文件夹中,可以通过visuadl可视化(即左手边的可视化按钮)打开。visualdl下的训练日志曲线如下图所示:
三、准备数据
我们是要在NTU-RGB+D数据集、joint模态、X-sub评测标准下对我们的轻量化的CTRGCN模型进行训练、验证及推理。CTRGCN的数据准备详情见/home/aistudio/PaddleVideo-develop/docs/zh-CN/dataset/ntu-rgbd.md,我们并没有完全按照其流程,即省略了数据集下载过程,因为sh data/ntu-rgb-d/download_dataset.sh命令需要翻墙下载,是不可行的,我们直接挂载大佬小吴今天不熬夜已经上传的下载好的数据集nturgbd_skeletons_s001_to_s017.zip,并使用wget https://videotag.bj.bcebos.com/Data/statistics.zip 命令得到statistics文件夹,之后的数据处理过程是与ntu-rgbd.md文档一致的,最终得到如下文件树形式
─── /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d
├── download_dataset.sh
├── nturgb+d_skeletons
│ ├── S001C001P001R001A001.skeleton
│ ├── S001C001P001R001A002.skeleton
│ ├── S001C001P001R001A003.skeleton
│ ├── S001C001P001R001A004.skeleton
│ ├── S001C001P001R001A005.skeleton
│ ├── S001C001P001R001A006.skeleton
│ ├── S001C001P001R001A007.skeleton
│ ├── ....
│ └── S017C003P020R002A060.skeleton
├── denoised_data
│ ├── actors_info
│ │ ├── S001C001P001R001A024.txt
│ │ ├── S001C001P001R001A025.txt
│ │ ├── S001C001P001R001A026.txt
│ │ ├── ....
│ │ ├── S017C003P020R002A059.txt
│ │ └── S017C003P020R002A060.txt
│ ├── denoised_failed_1.log
│ ├── denoised_failed_2.log
│ ├── frames_cnt.txt
│ ├── missing_skes_1.log
│ ├── missing_skes_2.log
│ ├── missing_skes.log
│ ├── noise_length.log
│ ├── noise_motion.log
│ ├── noise_spread.log
│ ├── raw_denoised_colors.pkl
│ ├── raw_denoised_joints.pkl
│ └── rgb+ske
├── raw_data
│ ├── frames_cnt.txt
│ ├── frames_drop.log
│ ├── frames_drop_skes.pkl
│ └── raw_skes_data.pkl
├── get_raw_denoised_data.py
├── get_raw_skes_data.py
├── seq_transformation.py
├── statistics
│ ├── camera.txt
│ ├── label.txt
│ ├── performer.txt
│ ├── replication.txt
│ ├── setup.txt
│ └── skes_available_name.txt
├── xview
│ ├── train_data.npy
│ ├── train_label.pkl
│ ├── val_data.npy
│ └── val_label.pkl
└── xsub
├── train_data.npy
├── train_label.pkl
├── val_data.npy
└── val_label.pkl
注:文件夹
denoised_data、raw_data和nturgb+d_skeletons都为处理处理的临时文件,可在提取出xview和xsub后删除。
3.1 数据集下载及解压
# 解压PaddleVideo套件
!unzip -qo PaddleVideo-develop.zip -d /home/aistudio/
# 解压挂载好的数据集,并复制到PaddleVideo/data/ntu-rgb-d/下
!unzip -qo /home/aistudio/data/data146482/nturgbd_skeletons_s001_to_s017.zip -d /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d/
# 下载并解压得到statistics文件夹
%cd /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d
!wget https://videotag.bj.bcebos.com/Data/statistics.zip
!mkdir statistics
!unzip -qo statistics.zip -d statistics/ && rm -rf statistics.zip
%cd /home/aistudio/
3.2 数据集处理
处理过程要等待一段时间
%cd /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d
# Get skeleton of each performer
!python get_raw_skes_data.py
# Remove the bad skeleton
!python get_raw_denoised_data.py
# Transform the skeleton to the center of the first frame
!python seq_transformation.py
%cd /home/aistudio/
%cd /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d
!rm -rf nturgb+d_skeletons/
!rm -rf denoised_data/
!rm -rf raw_data/
%cd /home/aistudio/
/home/aistudio/PaddleVideo-develop/data/ntu-rgb-d
/home/aistudio
四、开始使用
4.1 环境依赖
本项目是完全基于AIStudio的32GB V100环境实现训练及验证、推理的
4.1.1 PaddleVideo套件的引入
我们的轻量化CTRGCN的训练、验证及推理全流程均基于开源套件PaddleVideo,因此我们先从github clone到本环境中,注意本环境中我们已内置将轻量化CTRGCN及其训练日志、最优模型合并入的PaddleVideo,因此git clone过程不需要再运行。
#!git clone https://github.com/PaddlePaddle/PaddleVideo.git
# 在3.1 已进行解压,此处不需要再运行
行
#!unzip -qo PaddleVideo-develop.zip -d /home/aistudio/
4.1.2 安装所需依赖
需要安装PaddleVideo需要的依赖
%cd /home/aistudio/PaddleVideo-develop
!pip install -r requirements.txt
%cd /home/aistudio/
4.2 模型训练
4.2.1 CTRGCN_light
第一种训练配置:完全按照CTRGCN的训练配置进行训练,仅修改了骨干网络名字为"CTRGCN_light"和修改base_channel为60,具体参数可见/home/aistudio/PaddleVideo-develop/configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint.yaml
对/home/aistudio/PaddleVideo-develop/paddlevideo/solver/custom_lr.py修改,将CustomWarmupAdjustDecay的输入参数num_iters默认为1,不然会报错:TypeError: unsupported operand type(s) for /: ‘int’ and ‘NoneType’
# 运行该指令即可启动训练
%cd /home/aistudio/PaddleVideo-develop/
!python main.py --validate -c configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint.yaml --seed 1
%cd /home/aistudio/
一个epoch的训练日志如下图:
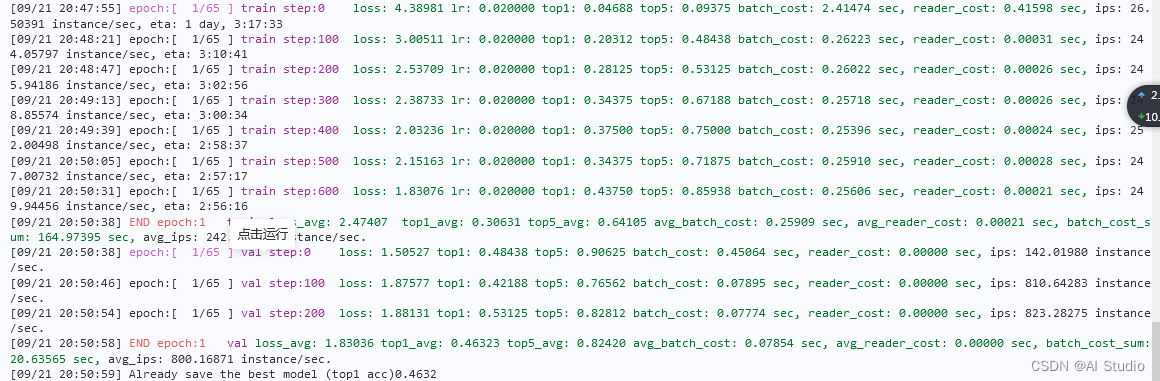
第二种训练配置:使用调优后的训练配置进行训练,具体参数可见/home/aistudio/PaddleVideo-develop/configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml,强烈推荐,精度会高很多!
# 运行该指令即可启动训练
%cd /home/aistudio/PaddleVideo-develop/
!python main.py --validate -c configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml --seed 1
%cd /home/aistudio/
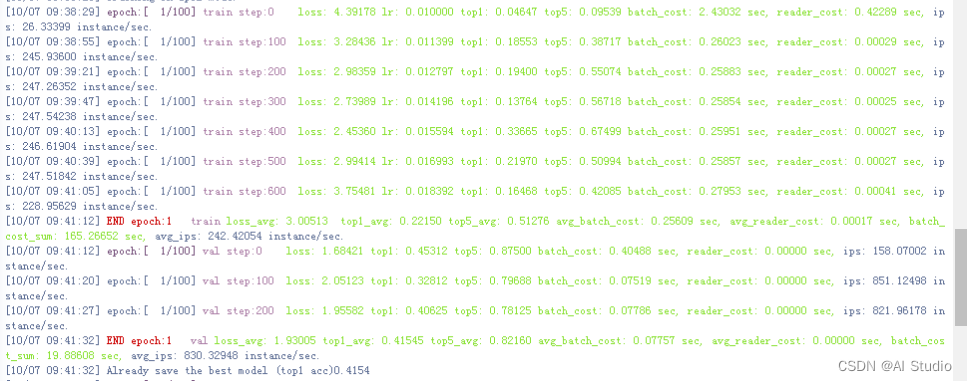
4.2.2 CTRGCN_lightV2(精度更高)
与CTRGCN_light相比采用第二种训练配置,仅修改了骨干网络名字为"CTRGCN_lightV2"和修改base_channel为62,具体参数可见/home/aistudio/PaddleVideo-develop/configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml
# 运行该指令即可启动训练
%cd /home/aistudio/PaddleVideo-develop/
!python main.py --validate -c configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml --seed 1
%cd /home/aistudio/

4.3 模型评估
4.3.1 CTRGCN_light
我们的训练好的CTRGCN_light模型权重文件存放在/home/aistudio/PaddleVideo-develop/output/CTRGCN_light_my/new文件夹中,训练日志在该文件夹下的logs文件夹中,可以通过visuadl可视化(即左手边的可视化按钮)打开。你可以通过-w指定自己训练的模型权重。我们的训练好的模型精度为90.953%,远大于89%。评估结果如下图所示:

# 运行该指令即可启动评估
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 main.py --test -c configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml -w /home/aistudio/PaddleVideo-develop/output/CTRGCN_light_my/new/CTRGCN_light_joint_best.pdparams
%cd /home/aistudio/
4.3.2 CTRGCN_lightV2(精度更高)
我们的训练好的CTRGCN_lightV2模型权重文件存放在/home/aistudio/PaddleVideo-develop/output/CTRGCN_lightV2_my/文件夹中,训练日志在该文件夹下的logs文件夹中,可以通过visuadl可视化(即左手边的可视化按钮)打开。你可以通过-w指定自己训练的模型权重。我们的训练好的模型精度为91.157%,远大于89%。评估结果如下图所示:

# 运行该指令即可启动评估
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 main.py --test -c configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml -w /home/aistudio/PaddleVideo-develop/output/CTRGCN_lightV2_my/CTRGCN_lightV2_joint_best.pdparams
%cd /home/aistudio/
4.4 导出推理模型
4.4.1 CTRGCN_light
我们利用训练好的CTRGCN_light模型权重文件导出其推理模型,得到的三个文件的总大小约为9.7MB,满足不超过10MB要求,存放在/home/aistudio/PaddleVideo/inference/CTRGCN_light_joint_my中。
# 运行该指令即可启动推理模型导出(出现的警告可以忽视)
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/export_model.py -c configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml \
-p output/CTRGCN_light_my/new/CTRGCN_light_joint_best.pdparams \
-o inference/CTRGCN_light_joint
%cd /home/aistudio/
# 最小化导出,使用nn.Sequential封装模型骨干和分类头
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/export_model_light.py -c configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml \
-p output/CTRGCN_light_my/new/CTRGCN_light_joint_best.pdparams \
-o inference/CTRGCN_light_joint/export_light
%cd /home/aistudio/
4.4.2 CTRGCN_lightV2(精度更高)
我们利用训练好的CTRGCN_lightV2模型权重文件导出其推理模型,得到的三个文件的总大小约为9.8MB,满足不超过10MB要求,存放在/home/aistudio/PaddleVideo/inference/CTRGCN_lightV2_joint_my中。
# 运行该指令即可启动推理模型导出(出现的警告可以忽视)
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/export_model.py -c configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml \
-p output/CTRGCN_lightV2_my/CTRGCN_lightV2_joint_best.pdparams \
-o inference/CTRGCN_lightV2_joint
%cd /home/aistudio/
# 最小化导出,使用nn.Sequential封装模型骨干和分类头
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/export_model_light.py -c configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml \
-p output/CTRGCN_lightV2_my/CTRGCN_lightV2_joint_best.pdparams \
-o inference/CTRGCN_lightV2_joint/export_light
%cd /home/aistudio/
4.5 模型推理
4.5.1 CTRGCN_light
我们使用CTRGCN_light导出的推理模型对data/example_NTU-RGB-D_sketeton.npy进行预测,输出的top1类别id为58,置信度为0.6840217,与使用官方预训练的CTRGCN模型导出的推理模型进行预测得到的top1类别id相同,我们的模型预测如下图:

# 运行该指令即可启动模型推理
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/predict.py --input_file data/example_NTU-RGB-D_sketeton.npy \
--config configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml \
--model_file inference/CTRGCN_light_joint_my/new/CTRGCN_light_joint.pdmodel \
--params_file inference/CTRGCN_light_joint_my/new/CTRGCN_light_joint.pdiparams \
--use_gpu=True \
--use_tensorrt=False
%cd /home/aistudio/
4.5.2 CTRGCN_lightV2(精度更高)
我们使用CTRGCN_lightV2导出的推理模型对data/example_NTU-RGB-D_sketeton.npy进行预测,输出的top1类别id为58,置信度为0.6479401,与使用官方预训练的CTRGCN模型导出的推理模型进行预测得到的top1类别id相同,我们的模型预测如下图:

# 运行该指令即可启动模型推理
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/predict.py --input_file data/example_NTU-RGB-D_sketeton.npy \
--config configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml \
--model_file inference/CTRGCN_lightV2_joint_my/CTRGCN_lightV2_joint.pdmodel \
--params_file inference/CTRGCN_lightV2_joint_my/CTRGCN_lightV2_joint.pdiparams \
--use_gpu=True \
--use_tensorrt=False
%cd /home/aistudio/
4.6 模型推理测速(可选)
我们使用轻量化CTRGCN导出的推理模型进行GPU测速。在进行测试之前,需安装AutoLog用于记录计算时间,使用如下命令安装:
!python3.7 -m pip install git+https://github.com/LDOUBLEV/AutoLog
构建推理使用的测试数据,即从验证集中选取100条
import numpy as np
import os
val_root = "/home/aistudio/PaddleVideo-develop/data/ntu-rgb-d/xsub/val_data.npy"
val_data = np.load(val_root)
test_time_data = val_data[:100]
test_time_root = "/home/aistudio/PaddleVideo-develop/data/ntu-rgb-d/test_time/"
if not os.path.exists(test_time_root):
os.makedirs(test_time_root)
with open("/home/aistudio/PaddleVideo-develop/data/ntu-rgb-d/test_time/file.list", "w") as f:
for i in range(100):
file_name = os.path.join(test_time_root, str(i)+".npy")
np.save(file_name, test_time_data[i])
f.write(file_name+"\n")
4.6.1 CTRGCN_light
执行下面语句进行模型推理速度测试,如图(第一个GPU测速,第二个CPU测速):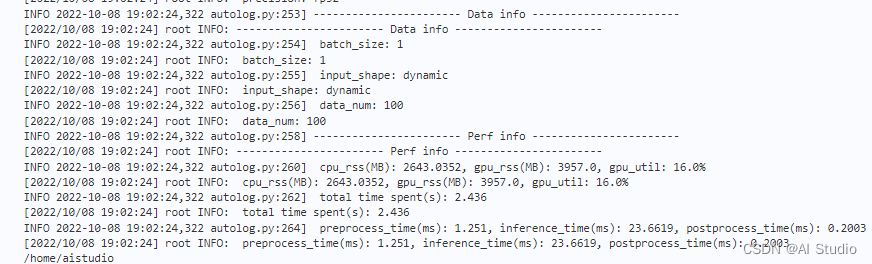

# GPU测速,use_gpu=True;CPU测速,use_gpu=False
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/predict.py --input_file /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d/test_time/file.list \
--time_test_file=True \
--config configs/recognition/ctrgcn/ctrgcn_light_ntucs_joint_aug.yaml \
--model_file inference/CTRGCN_light_joint_my/new/CTRGCN_light_joint.pdmodel \
--params_file inference/CTRGCN_light_joint_my/new/CTRGCN_light_joint.pdiparams \
--use_gpu=True \
--use_tensorrt=False \
--enable_mkldnn=True \
--enable_benchmark=True \
--disable_glog True
%cd /home/aistudio/
4.6.2 CTRGCN_lightV2(精度更高)
执行下面语句进行模型推理速度测试,如图(第一个GPU测速,第二个CPU测速):


# GPU测速,use_gpu=True;CPU测速,use_gpu=False
%cd /home/aistudio/PaddleVideo-develop/
!python3.7 tools/predict.py --input_file /home/aistudio/PaddleVideo-develop/data/ntu-rgb-d/test_time/file.list \
--time_test_file=True \
--config configs/recognition/ctrgcn/ctrgcn_light_v2_ntucs_joint_aug.yaml \
--model_file inference/CTRGCN_lightV2_joint_my/CTRGCN_lightV2_joint.pdmodel \
--params_file inference/CTRGCN_lightV2_joint_my/CTRGCN_lightV2_joint.pdiparams \
--use_gpu=True \
--use_tensorrt=False \
--enable_mkldnn=True \
--enable_benchmark=True \
--disable_glog True
%cd /home/aistudio/
五、TIPC基础链条功能验证
参考自大佬txyugood,
该部分依赖auto_log,需要进行安装,安装方式如下:
%cd /home/aistudio/
!git clone https://gitee.com/Double_V/AutoLog
%cd AutoLog/
!pip3 install -r requirements.txt
!python3 setup.py bdist_wheel
!pip3 install ./dist/auto_log-1.2.0-py3-none-any.whl
5.1 CTRGCN_light
对/home/aistudio/PaddleVideo-develop/test_tipc/configs/CTRGCN_light_joint/train_infer_python_aug.txt进行修改以完成TIPC基础链条功能验证。
修改后测试指令如下:
%cd /home/aistudio/PaddleVideo-develop/
!bash test_tipc/prepare.sh test_tipc/configs/CTRGCN_light_joint/train_infer_python_aug.txt 'lite_train_lite_infer'
!bash test_tipc/test_train_inference_python.sh test_tipc/configs/CTRGCN_light_joint/train_infer_python_aug.txt 'lite_train_lite_infer'
测试结果如截图所示:
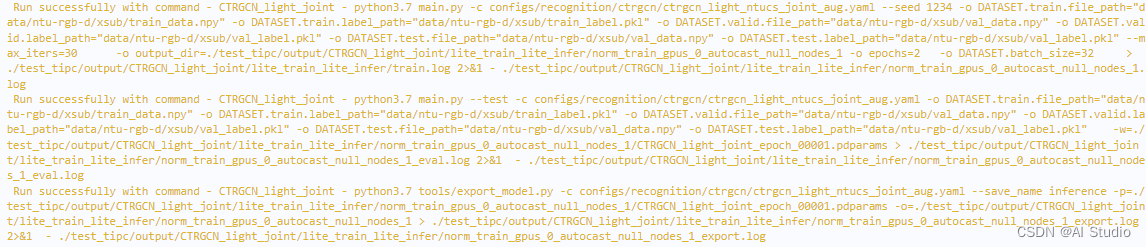

也可以到/home/aistudio/PaddleVideo-develop/test_tipc/output/CTRGCN_light_joint/lite_train_lite_infer下查看相关日志。
5.2 CTRGCN_lightV2(精度更高)
对/home/aistudio/PaddleVideo-develop/test_tipc/configs/CTRGCN_lightV2_joint/train_infer_python_aug.txt进行修改以完成TIPC基础链条功能验证。 修改后测试指令如下:
%cd /home/aistudio/PaddleVideo-develop/
!bash test_tipc/prepare.sh test_tipc/configs/CTRGCN_lightV2_joint/train_infer_python_aug.txt 'lite_train_lite_infer'
!bash test_tipc/test_train_inference_python.sh test_tipc/configs/CTRGCN_lightV2_joint/train_infer_python_aug.txt 'lite_train_lite_infer'
测试结果如截图所示:

也可以到/home/aistudio/PaddleVideo-develop/test_tipc/output/CTRGCN_lightV2_joint/lite_train_lite_infer下查看相关日志。
六、总结
1. 模型的轻量化不仅要考虑模型权重数量及浮点数运算量的减少,还要避免轻量化结构过于琐碎,同时还要保证足够的表达能力; 2. 进行卷积融合、模块融合来减少琐碎结构是有助于整个推理模型轻量化的此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)