
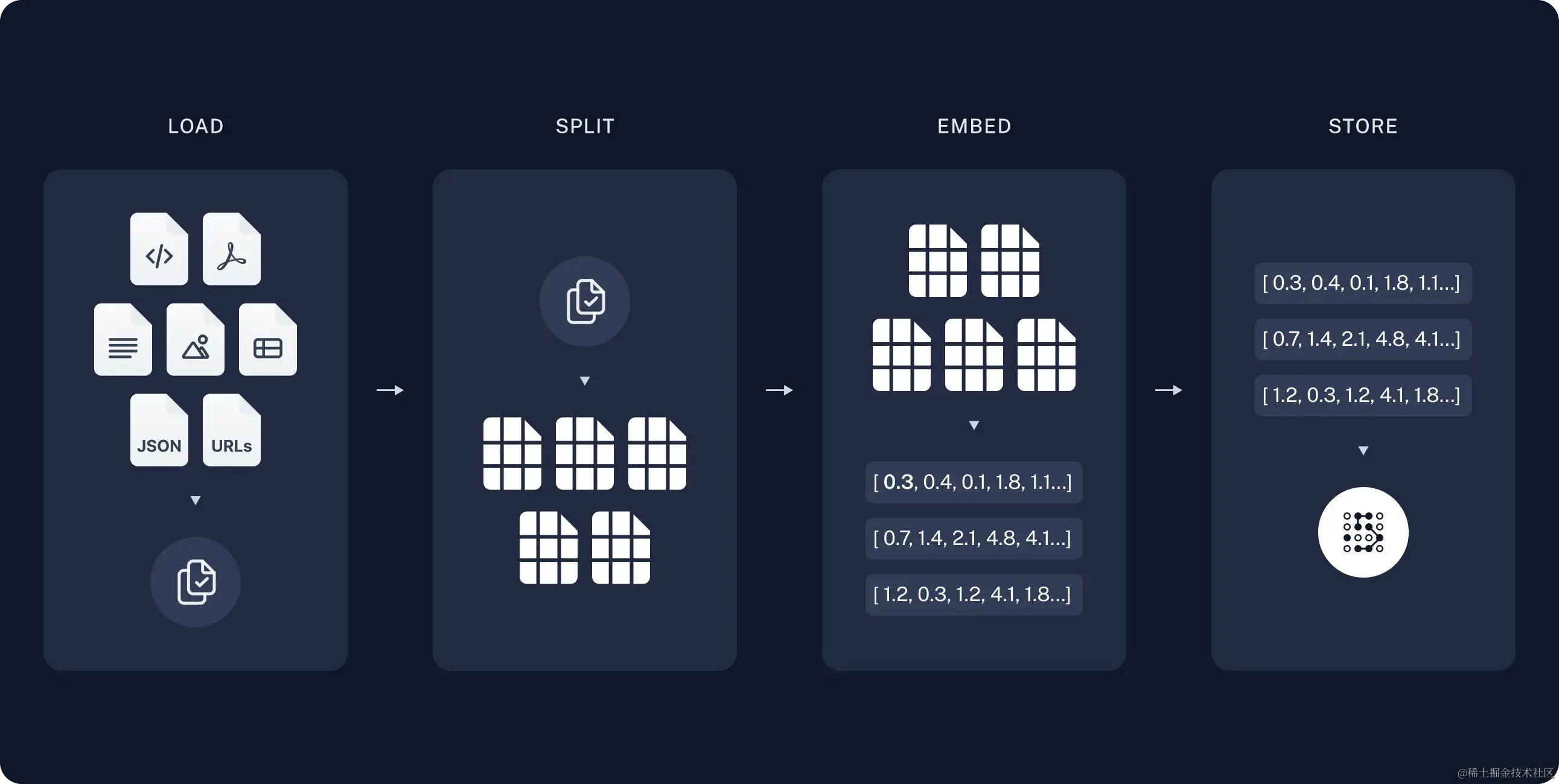
LAIC2022之犯罪事实实体识别(基于飞桨UIE+半监督)
基于飞桨PaddleNLP通用框架UIE + 半监督训练,快速生成比赛结果,分数在0.8569,仍有潜力空间
零.写在最前
该项目源于2022 CCF BDCI 大赛之《“中国法研杯”司法人工智能挑战赛之犯罪事实实体识别》
• 赛题任务
犯罪事实实体识别是司法NLP应用中的一项核心基础任务,能为多种下游场景所复用,是案件特征提取、类案推荐等众多NLP任务的重要基础工具。本赛题要求选手使用模型抽取出犯罪事实中相关预定义实体。
与传统的实体抽取不同,犯罪事实中的实体具有领域性强、分布不均衡等特性。
• 解决思路
基于百度开放的通用信息抽取UIE框架进行训练定制+微调,快速实现关系抽取任务
再通过生成伪标签数据进行多次训练
快速命令行模型 数据预处理+训练+生成比赛结果:
# 1. 切换到工作目录 + 安装 paddlenlp
%cd work/
!pip install --upgrade paddlenlp
# 2. 一键生成 doccano格式数据
!python pre.py
# 3. 生成训练集和验证集
!python doccano.py \
--doccano_file ./data/train_doccano.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
# 4. 训练微调
!python finetune.py \
--train_path ./data/train.txt \
--dev_path ./data/dev.txt \
--save_dir ./checkpoint \
--learning_rate 1e-5 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 30 \
--model uie-base \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device gpu
# 5. 评价模型
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
# 6. 生成比赛结果文件
! python predict.py
# 7. 生成半监督 伪标签数据
! python ulabel2000.py
# 8. 加入伪标签数据生成训练集
!python pre2000.py
!python doccano.py \
--doccano_file ./data/train_doccano.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
# 9. 训练微调,载入之前训练好的模型
!python finetune.py \
--init_from_ckpt ./checkpoint/model_best \
--train_path ./data/train.txt \
--dev_path ./data/dev.txt \
--save_dir ./checkpoint_2000 \
--learning_rate 1e-5 \
--batch_size 16 \
--max_seq_len 512 \
--num_epochs 5 \
--model uie-base \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device gpu
# 10. 评价模型
!python evaluate.py \
--model_path ./checkpoint_2000/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
# 11. 生成比赛结果文件
! python predict2000.py
一.通用信息抽取统一框架UIE
UIE框架实现了实体抽取、关系抽取、事件抽取、情感分析等任务的统一建模,并使得不同任务间具备良好的迁移和泛化能力.

二.数据预处理
1. 生成 doccano 格式数据
相关标注格式细节请访问

# pre.py
import paddle
import numpy as np
import pandas as pd
from config import Config
import json
labelsTpl = {
'11339':'被告人交通工具',
'11340':'被告人交通工具情况及行驶情况',
'11341':'被告人违规情况',
'11342':'行为地点',
'11343':'搭载人姓名',
'11344':'其他事件参与人',
'11345':'参与人交通工具',
'11346':'参与人交通工具情况及行驶情况',
'11347':'参与人违规情况',
'11348':'被告人责任认定',
'11349':'参与人责任认定',
'11350':'被告人行为总结'
}
class Pre(object):
def __init__(self):
self.cf = Config()
self.recordsId = 1
self.entitiesId = 1
def run(self):
trainTargetF = open(self.cf.dataFormalPath+'/train_doccano.json', 'w')
trainSrcF = open(self.cf.dataPath+'/train.json')
while True:
line = trainSrcF.readline()
if not line:
break
data = line.strip().split('\t')
data = json.loads(data[0])
text = data['context']
entities = []
for item in data['entities']:
spans = item['span'][0].split(";")
entity = {
'id':self.entitiesId,
'label':str(item['label']),
'start_offset':int(spans[0]),
'end_offset':int(spans[1])
}
entities.append(entity)
self.entitiesId = self.entitiesId + 1
re = {
'id':self.recordsId,
'text':text,
'entities':entities,
'relations':[]
}
self.recordsId = self.recordsId + 1
print(re)
trainTargetF.write(json.dumps(re, ensure_ascii=False))
trainTargetF.write('\n')
pre = Pre()
pre.run()
#2.生成 doccano 格式数据
!python pre.py
2. 生成UIE数据数据集
# 3. 生成训练集和验证集
!python doccano.py \
--doccano_file ./data/train_doccano.json \
--task_type ext \
--save_dir ./data \
--splits 0.8 0.2 0
可配置参数说明:
doccano_file: 从doccano导出的数据标注文件。
save_dir: 训练数据的保存目录,默认存储在data目录下。
negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。
task_type: 选择任务类型,可选有抽取和分类两种类型的任务。
options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。
prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。
is_shuffle: 是否对数据集进行随机打散,默认为True。
seed: 随机种子,默认为1000.
separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。
三.训练微调
# 4. 训练微调(单卡)
!python finetune.py \
--train_path ./data/train.txt \
--dev_path ./data/dev.txt \
--save_dir ./checkpoint \
--learning_rate 1e-5 \
--batch_size 4 \
--max_seq_len 512 \
--num_epochs 30 \
--model uie-base \
--seed 1000 \
--logging_steps 10 \
--valid_steps 100 \
--device gpu
可配置参数说明:
train_path: 训练集文件路径。
dev_path: 验证集文件路径。
save_dir: 模型存储路径,默认为./checkpoint。
learning_rate: 学习率,默认为1e-5。
batch_size: 批处理大小,请结合机器情况进行调整,默认为16。
max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
num_epochs: 训练轮数,默认为100。
model: 选择模型,程序会基于选择的模型进行模型微调,可选有uie-base, uie-medium, uie-mini, uie-micro和uie-nano,默认为uie-base。
seed: 随机种子,默认为1000.
logging_steps: 日志打印的间隔steps数,默认10。
valid_steps: evaluate的间隔steps数,默认100。
device: 选用什么设备进行训练,可选cpu或gpu。

四.评价模型
可配置参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。
test_path: 进行评估的测试集文件。
batch_size: 批处理大小,请结合机器情况进行调整,默认为16。
max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。
model: 选择所使用的模型,可选有uie-base, uie-medium, uie-mini, uie-micro和uie-nano,默认为uie-base。
debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。
!python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
五.生成提交文件
命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体。在开放域信息抽取中,抽取的类别没有限制,用户可以自己定义。
例如抽取的目标实体类型是"时间"、“选手"和"赛事名称”, schema构造如下:
['时间', '选手', '赛事名称']
生成的结果保存在 work/data/中
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import paddle
from config import Config
import paddlenlp
import json
from paddlenlp import Taskflow
import re
labelsTpl = {
'11339':'被告人交通工具',
'11340':'被告人交通工具情况及行驶情况',
'11341':'被告人违规情况',
'11342':'行为地点',
'11343':'搭载人姓名',
'11344':'其他事件参与人',
'11345':'参与人交通工具',
'11346':'参与人交通工具情况及行驶情况',
'11347':'参与人违规情况',
'11348':'被告人责任认定',
'11349':'参与人责任认定',
'11350':'被告人行为总结'
}
class Predict(object):
def __init__(self):
cf = Config()
self.cf = cf
self.pointsPath = cf.pointsPath
self.use_gpu = cf.use_gpu
def run(self):
#开启GPU
paddle.set_device('gpu:0') if self.use_gpu else paddle.set_device('cpu')
schema = []
for k,v in labelsTpl.items():
schema.append(str(k))
ie = Taskflow("information_extraction", schema=schema, task_path=self.pointsPath+'/model_best',position_prob=0.5)
# 写入结果文件
testTarF = open(self.cf.dataFormalPath+'/result.txt', 'w')
testSrcF = open(self.cf.dataPath+'/test.json')
while True:
line = testSrcF.readline()
if not line:
break
data = line.strip().split('\t')
data = json.loads(data[0])
entities = []
result = ie(data['context'])
if len(result) < 1:
continue
for item in result:
for key, value in item.items():
spans = []
texts = []
if len(value) > 1:
print(data['id'],value)
for value2 in value:
for fr in re.finditer(value2['text'],data['context']):
spans.append([fr.span()[0],fr.span()[1]])
texts.append(value2['text'])
entity = {
'label': str(key),
'span':spans,
'text':texts
}
entities.append(entity)
res = {
'context':data['context'],
'id':data['id'],
'entities':entities
}
#print(res)
testTarF.write(json.dumps(res, ensure_ascii=False))
testTarF.write('\n')
predict = Predict()
predict.run()
# 5. 生成比赛结果文件
! python predict.py
六.半监督生成伪数据
目前使用已标注好的数据进行有监督训练,得分在8.4左右。
可以通过变换模型,微调学习率,更改切分数据比例,修改预测阈值position_prob,进行调参以达到更高分数
比赛中还有未标注的数据,可以通过半监督训练提升成绩
将已有模型预测未标注数据,生成伪标注数据,继续加入到训练集生成训练
# 生成半监督 伪标签数据
! python ulabel2000.py
之后再通过pre2000.py 和 doccano 生成符合训练格式的数据集,以此反复训练
特别注意,当再次微调时需要载入初始模型
!python finetune.py \
--init_from_ckpt ./checkpoint/model_best \
六.总结
基于UIE,通过定制数据微调,即可快速实现抽取任务。
优化方向可以通过选择不同的模型,微调learning_rate,batch_size等方式进行实验
在生成比赛结果中可以通过设置position_prob阀值来控制返回结果
ie = Taskflow(“information_extraction”, schema=schema, task_path=self.pointsPath+‘/model_best’,position_prob=0.8)
通过已有模型预测未标注数据,生成伪标注数据加入训练集训练
本项目中只用了未标注2000条。还有8000条未用。可以根据自身情况,调整每次加入的数据量,以此反复训练,以达最优效果

希望对大家有所帮助
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)