
文图生成模型大集合
1、文心ERNIE-ViLG快速体验; 2、基于PaddleNLP实现文图生成二次开发
文图生成趣味应用
多模态数据(文本、图像、声音)是人类认识、理解和表达世间万物的重要载体。近年来,多模态数据的爆炸性增长促进了内容互联网的繁荣,也带来了大量多模态内容理解和生成的需求。与常见的跨模态理解任务不同,文到图的生成任务是流行的跨模态生成任务,其主要任务是从一句描述性文本生成一张与文本内容相对应的图片。 这一文图生成的任务,极大地释放了AI的想象力,也激发了人类的创意,给视觉内容创作者、文字内容创作者和大众用户带来了方便。用户可以生成多样化创意图片,并从中汲取创意灵感,打破创意瓶颈,从而可以进行创作出更优质的作品。文图生成领域典型的模型有OpenAI开发的DALL-E和DALL-E2,近期,工业界也训练出了更大、更新的文图生成模型,例如谷歌提出的Parti和Imagen,百度提出的文心ERNIE-ViLG和文心一格等模型。
百度文心ERNIE-ViLG 模型提出统一的跨模态双向生成模型,通过自回归生成模式对图像生成和文本生成任务进行统一建模,更好地捕捉模态间的语义对齐关系,从而同时提升图文双向生成任务的效果。文心 ERNIE-ViLG 在文本生成图像的权威公开数据集 MS-COCO 上,图片质量评估指标 FID(Fréchet Inception Distance)远超 OpenAI 的DALL-E等同类模型,并刷新了图像描述多项任务的最好效果。此外,文心ERNIE-ViLG还凭借强大的跨模态理解能力,在生成式视觉问答任务上也取得了领先成绩。
目前PaddleNLP一共集成了6种文图生成模型,下表主要从语言、模型结构、参数量、生成速度及大小这五个方面进行了对比。
| 模型 | 语言 | 结构 | 参数量 | 生成速度 | 图像大小 |
|---|---|---|---|---|---|
| DALL-E Mini | 英文 | BART+VQGAN | 484.7M | ~15s | 256x256 |
| 英文CLIP+Disco Diffusion | 英文 | CLIP+Disco Diffusion | 723.1M | ~10min | 1024x768 |
| 英文Stable Diffusion模型 | 英文 | Diffusion Model | 1066.2M | ~7s | 512x512 |
| 阿里EasyNLP文图生成模型 | 中文 | GPT+VQGAN | 173.4M | ~5s / ~0.5s | 256x256 |
| 中文Ernie-ViL2.0+Disco Diffusion | 中文 | Ernie-ViL2.0+Disco Diffusion | 775.6M | ~10min | 1024x768 |
| 文心ERNIE-ViLG | 中文 | Diffusion Model | Unknown | Unknown | 1024x1024,1536x1024 等 |
文心ERNIE-ViLG 与 Stable Diffusion优缺点比较
| 优点 | 缺点 | |
|---|---|---|
| 文心Ernie-ViLG | 1. 中文语言,对国内用户更友好。 2. 在有限资源下(只需要有网络),用户即可本地搭建中文文生图系统。 3. 生成的图片更具有中国特色。 |
1. 模型并未完全开源,仅开放ask调用方式,不利于二次开发及定制化训练。 |
| StableDiffusion | 1. 支持定制化训练,微调,用户可以自定义训练自己的物体及风格样式。 | 1. 英文语言,对国内用户不友好。 2. 本地依赖一定的GPU资源,安装环境配置较为复杂。 3. 生成的图片大多是具有国外的风格特色,不适应中国本土特色。 |
如图1所示,在PaddleNLP内,我们可以用Pipeline快速搭建 文心ERNIE-ViLG文图生成系统。

图1 使用Pipeline快速搭建文心ERNIE-ViLG文图生成系统
1. ErnieViLG在线体验
1.1 准备工作
在开始之前我们需要安装依赖包,如图2所示,等待出现成功安装的信息后,然后重启内核!

图2 重启内核
!pip install paddle-pipelines==0.3.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddlenlp==2.4.1
from IPython.display import clear_output
clear_output()
print("ErniViLG环境安装成功!请重启内核!!")
ErniViLG环境安装成功!请重启内核!!
1.2 申请密钥
在运行下面的命令之前,我们需要在ERNIE-ViLG官网申请API Key和 Secret key两个密钥,申请流程如图3所示:
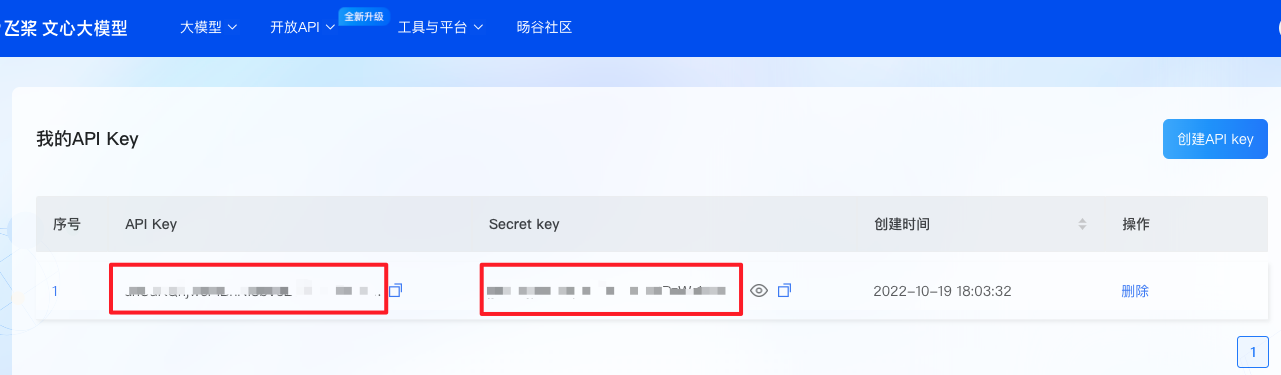
图3 申请API Key和Secret key
from pipelines.nodes import ErnieTextToImageGenerator
from pipelines import TextToImagePipeline
# ERNIE-ViLG官网申请API Key和 Secret key两个密钥 (注意请替换这里的密钥,当前密钥已经失效!!!)
api_key = "MzQIiXsZbEU4piSNO0ZhnlQuYxRAVe95"
secret_key = "dhqPgYXyNDzdFEt7Wh989mYNWvd1nZGW"
# 定义pipeline
erine_image_generator = ErnieTextToImageGenerator(ak=api_key,
sk=secret_key)
pipe = TextToImagePipeline(erine_image_generator)
1.3 定义生成图片所需的参数
参数解释如下:
- text_prompts(str): 输入的语句,描述想要生成的图像的内容。
- style(Optional[str]): 生成图像的风格,当前支持 古风、油画、水彩、卡通、二次元、浮世绘、蒸汽波艺术、 low poly、像素风格、概念艺术、未来主义、赛博朋克、写实风格、洛丽塔风格、巴洛克风格、超现实主义、探索无限。
- resolution(Optional[str]): 生成图像的分辨率,当前支持 ‘1024 * 1024’, ‘1024 * 1536’, ‘1536 * 1024’,默认为’1024 * 1024’。
- topk(Optional[int]): 保存前多少张图,最多保存6张。
- output_dir(Optional[str]): 保存输出图像的目录,默认为"ernievilg_output"。
# 需要返回多少张图片
topk = 5
# 指定需要返回的图片大小(高度x宽度)
size = "1024*1024"
# 需要生成的prompt文本
prompt_text= "云上的繁华都市中,世界传说,仙境,插画作品, 超现实主义"
# 指定的风格
style = "古风"
# 指定生成图片的保存路径
output_dir = "ernievilg_output"
# 开始生成图片
prediction = pipe.run(query=prompt_text,
params={
"TextToImageGenerator": {
"topk": topk,
"style": style,
"resolution": size,
"output_dir": output_dir
}
})
0%| | 0/100 [00:00<?, ?%/s]
Saving Images...
Done
1.4 展示图片
# 展示生成的图片
from PIL import Image
for image in prediction['results']:
display(Image.open(image))





2. Stable Diffusion在线体验
2.1 准备工作
在开始之前我们需要安装依赖包
如图4所示,等待出现成功安装的信息后,然后重启内核!
图4 重启内核
# 安装依赖包
!pip install "paddlenlp>=2.4.1" --user
!pip install -U ftfy regex fastcore Pillow --user
# 安装ppdiffusers库
!unzip -o ppdiffusers.zip
!unzip -o enhance_utils.zip
!rm __MACOSX -rf
from IPython.display import clear_output
clear_output()
print("环境安装成功!请重启内核!!")
环境安装成功!请重启内核!!
2.2 四行代码快速体验

图5 prompt小抄网址
Tips: 如果出现很多红字是正常情况。
| diffusers_paddle支持的模型名称 | huggingface对应的模型地址 | Tips备注 |
|---|---|---|
| CompVis/stable-diffusion-v1-4 | https://huggingface.co/CompVis/stable-diffusion-v1-4 | StableDiffusion v1-4模型,模型使用PNDM scheduler。 |
| runwayml/stable-diffusion-v1-5 | https://huggingface.co/runwayml/stable-diffusion-v1-5 | StableDiffusion v1-5模型,模型使用PNDM scheduler。 |
| hakurei/waifu-diffusion | https://huggingface.co/hakurei/waifu-diffusion | Waifu v1-2的模型,模型使用了DDIM scheduler。 |
| hakurei/waifu-diffusion-v1-3 | https://huggingface.co/hakurei/waifu-diffusion | Waifu v1-3的模型,模型使用了PNDM scheduler。 |
| naclbit/trinart_stable_diffusion_v2_60k | https://huggingface.co/naclbit/trinart_stable_diffusion_v2 | trinart 经过60k步数训练得到的模型,模型使用了DDIM scheduler。 |
| naclbit/trinart_stable_diffusion_v2_95k | https://huggingface.co/naclbit/trinart_stable_diffusion_v2 | trinart 经过95k步数训练得到的模型,模型使用了DDIM scheduler。 |
| naclbit/trinart_stable_diffusion_v2_115k | https://huggingface.co/naclbit/trinart_stable_diffusion_v2 | trinart 经过115k步数训练得到的模型,模型使用了DDIM scheduler。 |
| Deltaadams/Hentai-Diffusion | https://huggingface.co/Deltaadams/Hentai-Diffusion | Hentai模型,模型使用了PNDM scheduler。 |
from ppdiffusers import StableDiffusionPipelineAllinOne
pipe = StableDiffusionPipelineAllinOne.from_pretrained("CompVis/stable-diffusion-v1-4")
# prompt 输入需要想要生成的文本
image = pipe.text2image(prompt="In the morning light,Chinese ancient buildings in the mountains,Magnificent and fantastic John Howe landscape,lake,clouds,farm,Fairy tale,light effect,Dream,Greg Rutkowski,James Gurney,artstation").images[0]
display(image)
[2022-10-28 16:01:08,610] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/model_index.json
[2022-10-28 16:01:08,616] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/vae/model_state.pdparams
[2022-10-28 16:01:08,621] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/vae/config.json
W1028 16:01:08.626961 4359 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1028 16:01:08.631892 4359 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-10-28 16:01:10,884] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/text_encoder/model_state.pdparams
[2022-10-28 16:01:10,889] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/text_encoder/model_config.json
[2022-10-28 16:01:12,566] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/feature_extractor/preprocessor_config.json
[2022-10-28 16:01:12,571] [ INFO] - loading configuration file from cache at /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/feature_extractor/preprocessor_config.json
[2022-10-28 16:01:12,573] [ INFO] - Feature extractor CLIPFeatureExtractor {
"crop_size": 224,
"do_center_crop": true,
"do_convert_rgb": true,
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "CLIPFeatureExtractor",
"image_mean": [
0.48145466,
0.4578275,
0.40821073
],
"image_std": [
0.26862954,
0.26130258,
0.27577711
],
"resample": 3,
"size": 224
}
[2022-10-28 16:01:12,576] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/safety_checker/model_state.pdparams
[2022-10-28 16:01:12,578] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/safety_checker/model_config.json
[2022-10-28 16:01:15,559] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/scheduler/scheduler_config.json
[2022-10-28 16:01:15,565] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/unet/model_state.pdparams
[2022-10-28 16:01:15,568] [ INFO] - Found /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/unet/config.json
[2022-10-28 16:01:23,211] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/tokenizer/vocab.json
[2022-10-28 16:01:23,214] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/tokenizer/merges.txt
[2022-10-28 16:01:23,216] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/tokenizer/added_tokens.json
[2022-10-28 16:01:23,218] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/tokenizer/special_tokens_map.json
[2022-10-28 16:01:23,220] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/CompVis/stable-diffusion-v1-4/tokenizer/tokenizer_config.json
0%| | 0/51 [00:00<?, ?it/s]

2.3 使用UI界面快速体验文生图和图生图
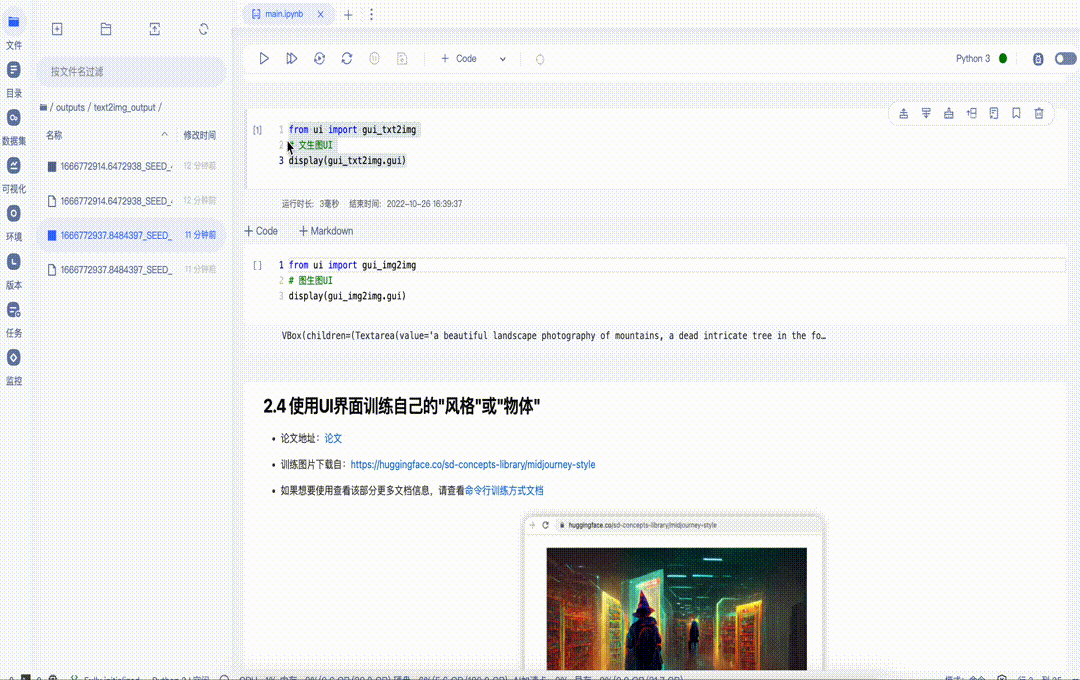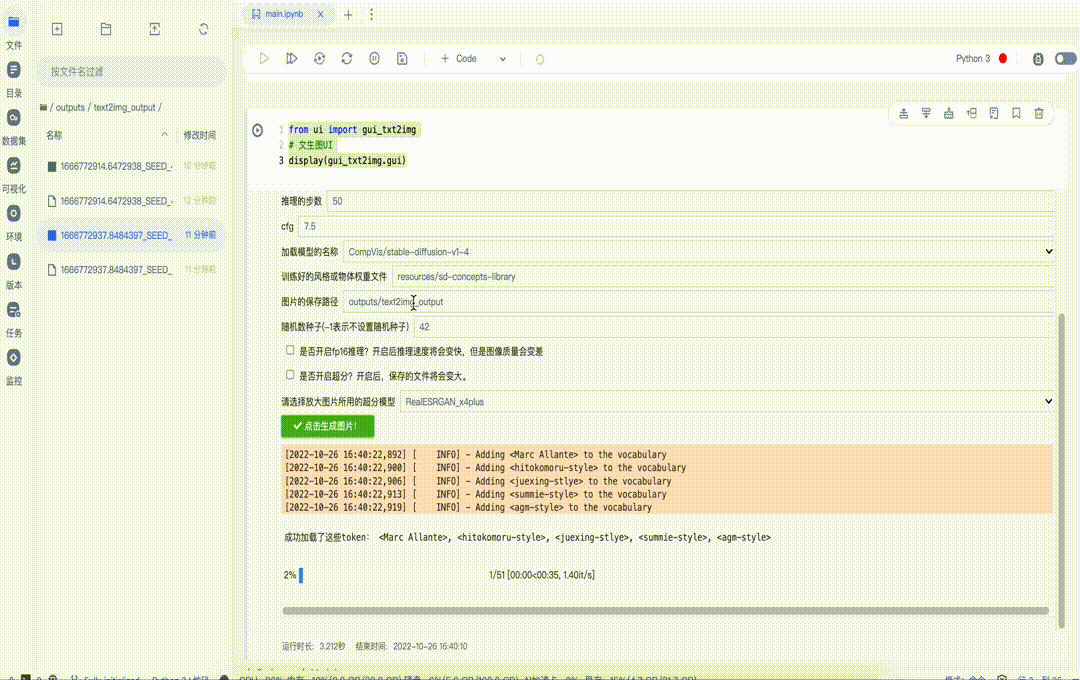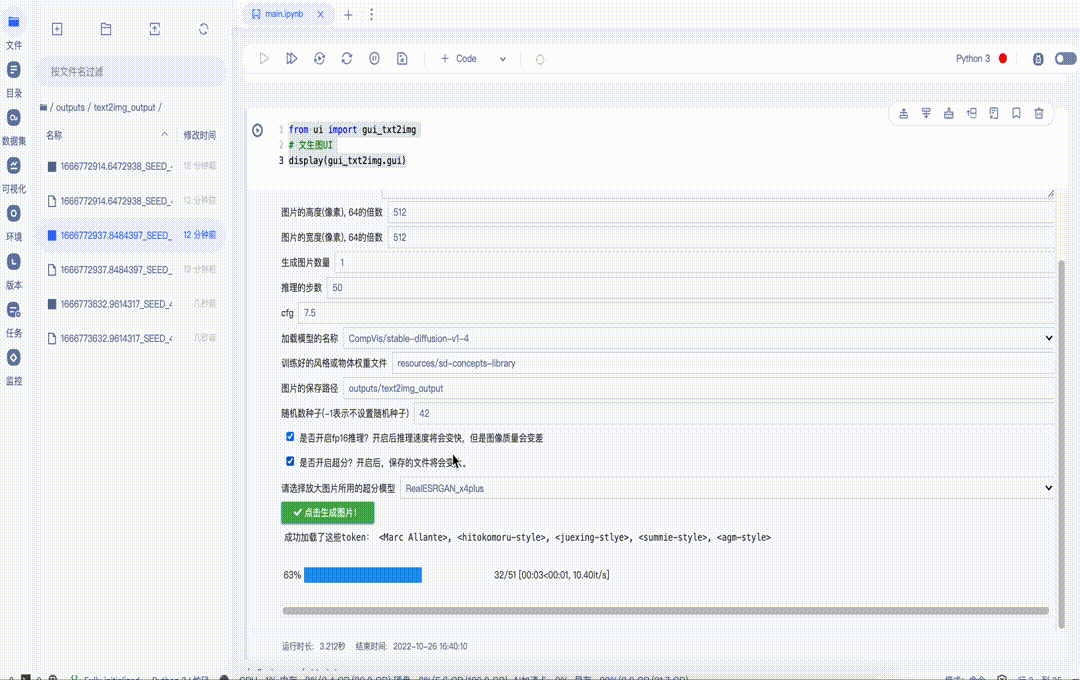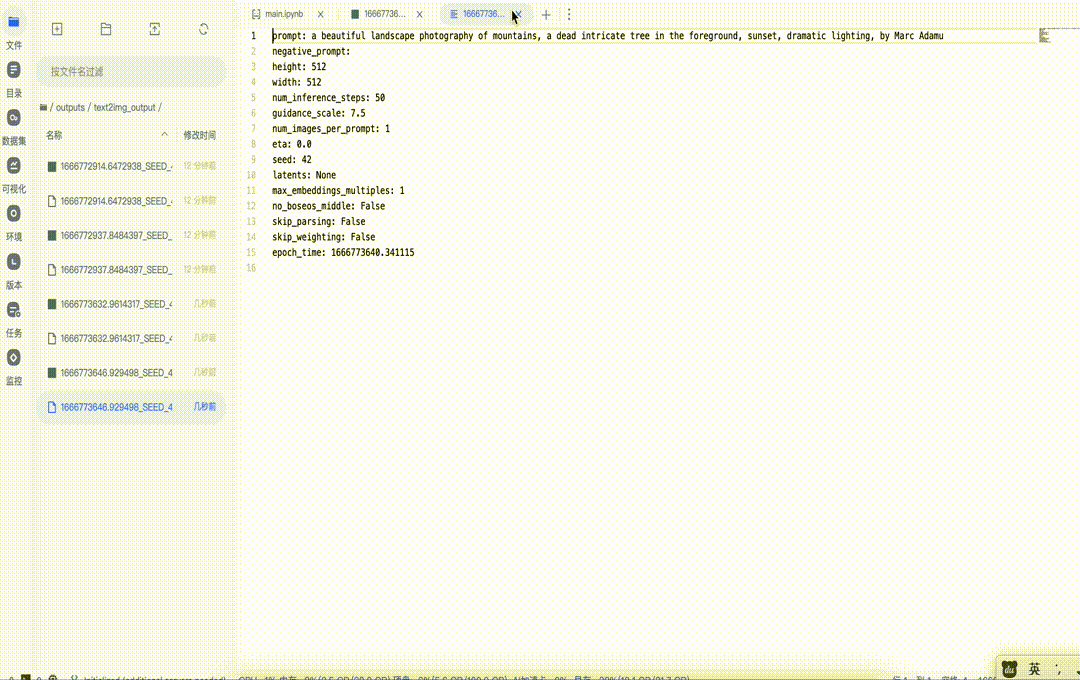
图6 文生图UI使用
from ui import gui_txt2img
# 文生图UI
display(gui_txt2img.gui)
VBox(children=(Textarea(value='a beautiful landscape photography of mountains, a dead intricate tree in the fo…

图7 图生图UI体验
from ui import gui_img2img
# 图生图UI
display(gui_img2img.gui)
VBox(children=(Textarea(value='a beautiful landscape photography of mountains, a dead intricate tree in the fo…
2.4 使用UI界面训练自己的"风格"或"物体"
-
论文地址:论文
-
训练图片下载自:https://huggingface.co/sd-concepts-library/midjourney-style
-
如果想要使用查看该部分更多文档信息,请查看命令行训练方式文档

图8 midjourney-style训练图片

图9 定制化训练UI体验
from ui import gui_train_text_invertion
# 运行之前,请重启内核释放显存!
display(gui_train_text_invertion.gui)
VBox(children=(Dropdown(description='需要学习什么?风格或物体', layout=Layout(width='100%'), options=('style', 'object'), …
from ui import gui_text_invertion
display(gui_text_invertion.gui)
VBox(children=(Textarea(value='a beautiful landscape photography in <midjourney-style>', description='prompt描述…
3. 参考资料
- https://github.com/CompVis/stable-diffusion
- https://github.com/PaddlePaddle/PaddleNLP
- https://github.com/huggingface/diffusers
- https://wenxin.baidu.com/moduleApi/ernieVilg
- https://yige.baidu.com
4. 加入交流群,一起学习吧
以上实现基于PaddleNLP,开源不易,希望大家多多支持~
如果对您有帮助,记得给PaddleNLP点个小小的Star⭐,收藏起来,不易走丢~
GitHub地址:https://github.com/PaddlePaddle/PaddleNLP
- 加入微信交流群,一起学习吧
欢迎扫码填写基础问卷后,加入PaddleNLP技术交流群(微信),获得超多福利:
(1)领取官方团队准备的10GB NLP学习大礼包
(2)获取近期课程链接,及时跟进最新发布功能
(3)与众多NLPer、PaddleNLP工程师交流最新技术
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)