
【论文复现赛第七期】Fact-Seg论文复现(拯救你的小目标分割)
为解决遥感图像中的小目标分割问题,Fact-Seg 提出了双分支解码器、联合概率损失和基于小目标挖掘的网络优化,并在两个遥感数据集上验证了模型的有效性。项目的验收精度( mIoU)为64.64
【论文复现赛第七期】Fact-Seg论文复现(拯救你的小目标分割)
摘要
小目标语义分割任务致力于从高分辨率遥感图像中自动提取关键目标。与遥感图像的大规模覆盖区域相比,像汽车和轮船这样的关键目标往往仅在遥感图像中占据几个像素。为了解决这个问题,作者提出了前景激活驱动的小目标语义分割网络Fact-Seg。该网络由双分支解码器和联合概率损失(CP)组成。其中,前景激活分支(FA)用于激活小目标特征,并抑制大规模的背景噪音,语义微调分支(SR)用于进一步区分小目标。CP损失可以高效地联合前景激活分支和语义微调分支的输出。在联合阶段,前景激活分支增强了小目标的弱特征,语义微调分支以二进制掩码的形式对激活分支的输出进行微调。在优化阶段,基于小目标挖掘的网络优化自动选择出有效样本并对优化方向做出微调,从而解决了小目标和大规模背景样本不均衡的问题。两个高清遥感分割数据集上的实验结果表明,提出的Fact-Seg模型要优于现有的其他方法,并实现了精度和效率的完美权衡。
1. Fact-Seg
1.1 总体架构
Fact-Seg的总体架构如下图所示,高清遥感图像首先会经过ResNet-50进行特征提取,得到不同阶段的特征{ F1 , F2, F3, F4 }。之后,上述特征经过前景激活(FA)和语义微调(RC)双分支进行特征解码,最后采用联合概率损失(CP)和小目标挖掘策略(SOM)对两个分支的输出进行优化。
在推理阶段,语义微调分支输出的预测结果会经过sigmoid函数生成掩码图像binary_prob,Fact-Seg分别采用1-binary_prob和binary_prob对前景激活分支预测结果的背景通道和前景通道进行微调。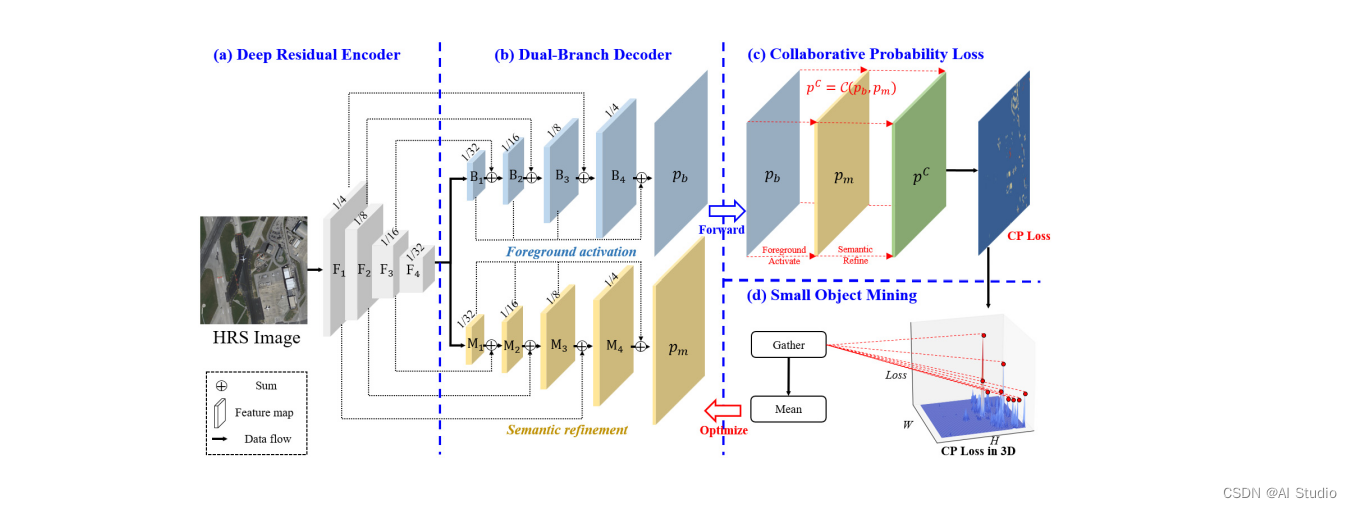
1.2 双分支解码器
双分支解码器基于FPN进行改进。具体而言,深度残差编码器提取出的特征 F 4 F_4 F4 首先经过一个 1 × 1 1\times1 1×1卷积和 3 × 3 3\times3 3×3卷积将维度降至256维,得到特征 B 1 B_1 B1,之后对 B 1 B_1 B1进行2倍上采样。上采样后的特征与编码器提取出的特征 F 3 F_3 F3进行求和,再经过一个 3 × 3 3\times3 3×3卷积得到 B 2 B_2 B2。依次类推,最深层的特征 F 4 F_4 F4渐进式地上采样,并与编码器中对应尺度的特征按元素求和。最后,我们可以得到FA分支的解码特征{ B 1 B_1 B1, B 2 B_2 B2, B 3 B_3 B3, B 4 B_4 B4 }和SR分支的解码特征{ M 1 M_1 M1, M 2 M_2 M2, M 3 M_3 M3, M 4 M_4 M4}。具体过程可由如下公式表示:
B i + 1 = Upsample × 2 ( Γ ( B i ) ) + ζ ( F 4 − i ) , i = 1 , 2 , 3 ( 1 ) M i + 1 = Upsample × 2 ( Γ ( M i ) ) + ζ ( F 4 − i ) , i = 1 , 2 , 3 ( 2 ) \begin{array}{ccc}B_{i+1}=\operatorname{Upsample}_{\times 2}(\Gamma(B_i))+\zeta(F_{4-i}),&i=1,2,3&(1)\\ M_{i+1}=\operatorname{Upsample}_{\times 2}(\Gamma(M_i))+\zeta(F_{4-i}),&i=1,2,3&(2)\end{array} Bi+1=Upsample×2(Γ(Bi))+ζ(F4−i),Mi+1=Upsample×2(Γ(Mi))+ζ(F4−i),i=1,2,3i=1,2,3(1)(2)
其中, ζ \zeta ζ 表示跳跃连接, Γ \Gamma Γ 表示解码器中的特征变换过程。
获得不同尺度的解码特征后,作者设计了一个简单的融合模块对多尺度解码特征进行融合。以FA分支解码特征为例, B 1 B_1 B1, B 2 B_2 B2, B 3 B_3 B3, B 4 B_4 B4 层解码特征分别会进行3次,2次,1次,0次上采样阶段。每次上采样,解码特征会依次进行 3 × 3 3\times3 3×3卷积、组归一化、Relu激活和2倍双线性插值上采样操作。最后,将所有上采样后的特征按元素求和,再经过 1 × 1 1\times1 1×1卷积、4倍上采样和softmax分类器,得到与原图尺寸一致的像素级类别标签。
1.3 联合概率损失
传统的多分类语义分割采用CE损失,具体定义如下:
C E ( p , y ) = − ∑ i = 0 N − 1 y i l o g ( p i ) ( 3 ) \begin{array}{ccc} \mathrm{CE}(p,y)=-\sum\limits_{i=0}^{N-1}y_i log(p_i)&(3) \end{array} CE(p,y)=−i=0∑N−1yilog(pi)(3)
其中, y i y_i yi ∈ 0 , 1 \in {0, 1} ∈0,1 表示真实标签类别, p i p_i pi ∈ [ 0 , 1 ] \in [0, 1] ∈[0,1] 是第i个类别对应 y i y_i yi=1 标签的估计概率,N表示总类别数。
| Background | Foreground | |
|---|---|---|
| FA分支 | p b p_b pb | 1 − p b 1-p_b 1−pb |
| SR分支 | p m 0 p_{m_0} pm0 | p m i > 0 p_{m_{i>0}} pmi>0 |
为了更好地结合双分支解码器的输出,作者基于联合概率(CP)假设,提出了联合概率损失。如表1所示,作者将FA分支输出的前景概率记为 p b p_b pb,背景概率记为 1 − p b 1-p_b 1−pb,SR分支的输出概率记为 p m i ( 0 ≤ i < N ) p_{m_i} (0\leq i<N) pmi(0≤i<N) ,具体的CP假设如下:
1)两个分支的输出分布相互独立,每个分支使用非线性表征来处理深度残差编码器中的共享输出 2)只有两个分支中相同的背景或前景输出才会计算联合概率。损失函数不会对相互对立的输出,即 1 − p b 1- p_b 1−pb和 p m 0 p_{m_0} pm0, p b p_b pb 和 p m i > 0 p_{m_{i>0}} pmi>0 进行融合。
基于上述假设,我们可以定义联合概率 p i C p_i^C piC如下:
p i C = C ( p b , p m ) = { 1 Z p b p m i , i = 0 1 Z ( 1 − p b ) p m i , 0 < i < N ( 4 ) \begin{array}{ccc} p_i^C=\mathcal{C}(p_b,p_m)=\begin{cases}\dfrac{1}{Z}p_bp_{m_i},&i=0\\ \\ \dfrac{1}{Z}(1-p_b)p_{m_i},&0<i<N\end{cases}\quad(4) \end{array} piC=C(pb,pm)=⎩
⎨
⎧Z1pbpmi,Z1(1−pb)pmi,i=00<i<N(4)
其中, C \mathcal{C} C 表示融合过程,Z表示归一化因子,并定义如下:
Z = p b p m 0 + ∑ i = 1 N − 1 ( 1 − p b ) p m i . ( 5 ) \begin{array}{ccc} Z=p_b p_{m_0}+\sum\limits_{i=1}^{N-1}(1-p_b)p_{m_i}.\quad\quad(5) \end{array} Z=pbpm0+i=1∑N−1(1−pb)pmi.(5)
归一化因子使得联合概率 p i C p_i^C piC 可以满足约束: ∑ i = 0 N − 1 p i C = 1 \sum_{i=0}^{N-1}p_{i}^{C}=1 ∑i=0N−1piC=1 , p i C p_i^C piC ≥ \geq ≥ 0 , 从而可以替换公式3中的多分类概率 p i p_{i} pi ,联合概率损失使两步任务转化为单步任务端到端优化问题。 该网络在训练过程中采用CP损失优化;在推断时,采用联合概率 p i C p_{i}^{C} piC 作为最终的多分类概率。CP 损失定义如下:
C P ( p b , p m i , y ) = CE ( p i C , y ) = − ∑ i = 0 N − 1 y i log ( p i C ) = − y 0 log p b p m 0 − ∑ i = 1 N − 1 y i log p m i − ∑ i = 1 N − 1 y i l o g ( 1 − p b ) + log Z . ( 6 ) \begin{array}{ccc} CP(p_b,p_{m_i},y)&=\operatorname{CE}(p_i^C,y)=-\sum_{i=0}^{N-1}y_i\log\left(p_i^C\right)\\\\&=-y_0\log p_b p_{m_0}-\sum_{i=1}^{N-1}y_i\log p_{m_i}\\\\&-\sum_{i=1}^{N-1}y_i log(1-p_b)+\log Z.\quad(6) \end{array} CP(pb,pmi,y)=CE(piC,y)=−∑i=0N−1yilog(piC)=−y0logpbpm0−∑i=1N−1yilogpmi−∑i=1N−1yilog(1−pb)+logZ.(6)
1.4 基于小目标挖掘的网络优化
基于小目标挖掘的网络优化(SOM)在目标检测中的在线难例挖掘策略(OHEM)基础上进行改进,将每一个像素点视为一个样本,具体过程如算法1。该算法可以基于当前损失自动选取难例。

2. 代码复现
2.1 下载并导入所需的库
!pip install scikit-image
!pip install reprod_log
!pip install paddleseg
!pip install pillow
import re
import cv2
import math
import time
import random
import os.path
import paddle
import random
import argparse
import logging
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.io import DataLoader
from paddle.autograd import PyLayer
from paddleseg.utils import (TimeAverager, calculate_eta, resume, logger,
worker_init_fn, train_profiler, op_flops_funs,visualize)
from paddleseg import utils
from visualdl import LogWriter
from module.factseg import FactSeg
from isaid_eval import SegmSlidingWinInference
from data1.isaid import ISAIDSegmmDataset, ImageFolderDataset,RemoveColorMap
from simplecv1.core.config import AttrDict
from simplecv1.util.config import import_config
from simplecv1.module.fpn import FPN
from simplecv1.module.resnet import ResNetEncoder
from simplecv1.interface import CVModule
from simplecv1.api.preprocess import comm,segm
from simplecv1.opt.learning_rate import PolynomialDecay1
from simplecv1.metric.miou import NPMeanIntersectionOverUnion as NPmIoU
from simplecv1.data.preprocess import sliding_window
from simplecv1.process.function import th_divisible_pad
2.2 创建数据集
# 创建相关文件夹
!mkdir output
%cd /home/aistudio/data/data170962
!mkdir train test
%cd /home/aistudio/data/data170962/train
!mkdir images masks
%cd /home/aistudio/data/data170962/test
!mkdir images masks
%cd /home/aistudio/
# 解压数据集(建议在终端复制如下命令,由于解压数据集较大,会造成控制台卡顿,且控制台解压时间较长)
!unzip -d /home/aistudio/data/data170962/train/images /home/aistudio/data/data170962/part1.zip
!unzip -d /home/aistudio/data/data170962/train/images /home/aistudio/data/data170962/part2.zip
!unzip -d /home/aistudio/data/data170962/train/images /home/aistudio/data/data170962/part3.zip
!unzip -d /home/aistudio/data/data170962/train/masks /home/aistudio/data/data170962/seg_train.zip
!unzip -d /home/aistudio/data/data170962/test/images /home/aistudio/data/data170962/val_image.zip
!unzip -d /home/aistudio/data/data170962/test/masks /home/aistudio/data/data170962/seg_val.zip
# 导入配置文件
config_path = 'isaid.factseg'
cfg = import_config(config_path)
cfg = AttrDict.from_dict(cfg)
config_path='isaid.factseg'
ckpt_path='/home/aistudio/data/data170962/fact-seg_temp.pdparams'
resume_model_path=''
opts = None
if opts is not None:
cfg.update_from_list(opts)
train_config = cfg['data']['train']['params']
test_config = cfg['data']['test']['params']
batch_size = cfg['data']['train']['params']['batch_size']
train_dataset = ISAIDSegmmDataset(train_config.image_dir,
train_config.mask_dir,
train_config.patch_config,
train_config.transforms)
val_dataset = ImageFolderDataset(image_dir=test_config.image_dir, mask_dir=test_config.mask_dir)
print("train_dataset: %d" % len(train_dataset))
print("val_dataset: %d" % len(val_dataset))
batch_sampler = paddle.io.DistributedBatchSampler(train_dataset, batch_size=batch_size, shuffle=True, drop_last=False)
train_loader = paddle.io.DataLoader(
train_dataset,
batch_sampler=batch_sampler,
num_workers=16,
return_list=True,
)
val_loader = DataLoader(val_dataset,batch_size=1,shuffle=False,num_workers=8, collate_fn=lambda x:x)
2.3 模型的创建
2.3.1 双分支解码器
class AssymetricDecoder(nn.Layer):
def __init__(self,
in_channels,
out_channels,
in_feat_output_strides=(4, 8, 16, 32),
out_feat_output_stride=4,
norm_fn=nn.BatchNorm2D,
num_groups_gn=None):
super(AssymetricDecoder, self).__init__()
if norm_fn == nn.BatchNorm2D:
norm_fn_args = dict(num_features=out_channels)
elif norm_fn == nn.GroupNorm:
if num_groups_gn is None:
raise ValueError('When norm_fn is nn.GroupNorm, num_groups_gn is needed.')
norm_fn_args = dict(num_groups=num_groups_gn, num_channels=out_channels)
else:
raise ValueError('Type of {} is not support.'.format(type(norm_fn)))
self.blocks = nn.LayerList()
for in_feat_os in in_feat_output_strides:
num_upsample = int(math.log2(int(in_feat_os))) - int(math.log2(int(out_feat_output_stride)))
num_layers = num_upsample if num_upsample != 0 else 1
self.blocks.append(nn.Sequential(*[
nn.Sequential(
nn.Conv2D(in_channels if idx == 0 else out_channels, out_channels, 3, 1, 1, bias_attr=False),
norm_fn(**norm_fn_args) if norm_fn is not None else nn.Identity(),
nn.ReLU(),
nn.UpsamplingBilinear2D(scale_factor=2) if num_upsample != 0 else nn.Identity(),
)
for idx in range(num_layers)]))
def forward(self, feat_list: list):
inner_feat_list = []
for idx, block in enumerate(self.blocks):
decoder_feat = block(feat_list[idx])
inner_feat_list.append(decoder_feat)
out_feat = sum(inner_feat_list) / 4.
return out_feat
2.3.2 联合概率损失(CP loss)
class Clone(PyLayer):
@staticmethod
def forward(ctx, cls_pred):
joint_prob = paddle.clone(cls_pred)
return joint_prob
@staticmethod
def backward(ctx, grad_a):
x = paddle.zeros_like(grad_a)
return x
class JointLoss(nn.Layer):
def __init__(self, ignore_index=255, sample='SOM', ratio=0.2):
super(JointLoss, self).__init__()
assert sample in ['SOM', 'OHEM']
self.ignore_index = ignore_index
self.sample = sample
self.ratio = ratio
def forward(self, cls_pred, binary_pred, cls_true, instance_mask=None):
valid_mask = (cls_true != self.ignore_index)
fgp = F.sigmoid(binary_pred)
clsp = F.softmax(cls_pred, axis=1)
joint_prob = Clone.apply(clsp)
joint_prob[:, 0, :, :] = (1-fgp).squeeze(axis=1) * clsp[:, 0, :, :]
joint_prob[:, 1:, :, :] = fgp * clsp[:, 1:, :, :]
Z = paddle.sum(joint_prob, axis=1, keepdim=True)
p_ci = joint_prob / Z
losses = F.nll_loss(paddle.log(p_ci), paddle.cast(cls_true, dtype='int64'), ignore_index=self.ignore_index, reduction='none')
if self.sample == 'SOM':
return som(losses, self.ratio)
else:
return losses.sum() / valid_mask.sum()
2.3.3 基于小目标挖掘的网络优化(SOM)
def som(loss, ratio):
# 1. keep num
num_inst = loss.numel()
num_hns = int(ratio * num_inst)
# 2. select loss
top_loss, _ = loss.reshape([-1]).topk(num_hns, -1)
loss_mask = (top_loss != 0)
# 3. mean loss
return paddle.sum(top_loss[loss_mask]) / (loss_mask.sum() + 1e-6)
2.3.4 Fact-Seg 模型的创建
class FactSeg(CVModule.CVModule):
def __init__(self, config):
super(FactSeg, self).__init__(config)
self.resencoder = ResNetEncoder(self.config.resnet_encoder)
# encoder attention
self.fgfpn = FPN(**self.config.foreground.fpn)
self.bifpn = FPN(**self.config.binary.fpn)
# decoder
self.fg_decoder = AssymetricDecoder(**self.config.foreground.assymetric_decoder)
self.bi_decoder = AssymetricDecoder(**self.config.binary.assymetric_decoder)
self.fg_cls = nn.Conv2D(self.config.foreground.out_channels, self.config.num_classes, kernel_size=1)
self.bi_cls = nn.Conv2D(self.config.binary.out_channels, 1, kernel_size=1)
# loss
if 'joint_loss' in self.config.loss:
self.joint_loss = JointLoss(**self.config.loss.joint_loss)
if 'inverse_ce' in self.config.loss:
self.inversece_loss = InverseWeightCrossEntroyLoss(self.config.num_classes, 255)
def forward(self, x, y=None):
feat_list = self.resencoder(x)
forefeat_list = list(self.fgfpn(feat_list))
binaryfeat_list = self.bifpn(feat_list)
if self.config.fbattention.atttention:
for i in range(len(binaryfeat_list)):
forefeat_list[i] = self.fbatt_block_list[i](binaryfeat_list[i], forefeat_list[i])
fg_out = self.fg_decoder(forefeat_list)
bi_out = self.bi_decoder(binaryfeat_list)
fg_pred = self.fg_cls(fg_out)
bi_pred = self.bi_cls(bi_out)
fg_pred = F.interpolate(fg_pred, scale_factor=4.0, mode='bilinear',
align_corners=True)
bi_pred = F.interpolate(bi_pred, scale_factor=4.0, mode='bilinear',
align_corners=True)
if self.training:
cls_true = y['cls']
return dict(joint_loss =self.joint_loss(fg_pred, bi_pred, cls_true))
else:
binary_prob = F.sigmoid(bi_pred)
cls_prob = F.softmax(fg_pred, axis=1)
cls_prob[:, 0, :, :] = cls_prob[:, 0, :, :] * (1- binary_prob).squeeze(axis=1)
cls_prob[:, 1:, :, :] = cls_prob[:, 1:, :, :] * binary_prob
Z = paddle.sum(cls_prob, axis=1)
Z = Z.unsqueeze(axis=1)
cls_prob = paddle.divide(cls_prob,Z)
if y is None:
return cls_prob
cls_true = y['cls']
return cls_prob,dict(joint_loss =self.joint_loss(fg_pred, bi_pred, cls_true))
def set_defalut_config(self):
self.config.update(dict(
resnet_encoder=dict(
resnet_type='resnet50',
include_conv5=True,
batchnorm_trainable=True,
pretrained=True,
freeze_at=0,
output_stride=32,
with_cp=(False, False, False, False),
stem3_3x3=False,
),
num_classes=16,
foreground=dict(
fpn=dict(
in_channels_list=[256, 512, 1024, 2048],
out_channels=256,
),
assymetric_decoder=dict(
in_channels=256,
out_channels=128,
in_feat_output_strides=(4, 8, 16, 32),
out_feat_output_stride=4,
),
out_channels=128,
),
binary = dict(
fpn=dict(
in_channels_list=[256, 512, 1024, 2048],
out_channels=256,
),
out_channels=128,
assymetric_decoder=dict(
in_channels=256,
out_channels=128,
in_feat_output_strides=(4, 8, 16, 32),
out_feat_output_stride=4,
),
),
loss=dict(
ignore_index=255,
)
))
2.3.4 模型的参数
model = FactSeg(cfg['model']['params'])
paddle.summary(model, (1, 3, 512, 512))

2.4 训练
# 固定随机种子
SEED = 2333
random.seed(SEED)
np.random.seed(SEED)
paddle.seed(SEED)
# 初始化日志
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
handler = logging.FileHandler("train_log.txt")
handler.setLevel(logging.INFO)
formatter = logging.Formatter("[%(asctime)s] [%(levelname)s] : %(message)s ", "%Y-%m-%d %H:%M:%S")
# logging.filemode='w'
handler.setFormatter(formatter)
logger.addHandler(handler)
precision ="fp16"
amp_level ='O1'
visual_log = LogWriter("train_log")
start_iter = 0
batch_size = cfg['data']['train']['params']['batch_size']
iter1 = start_iter
num_iters = cfg['train']['num_iters']
avg_loss = 0.0
avg_loss_list = []
iters_per_epoch = len(batch_sampler)
best_mean_iou = -1.0
best_model_iter = -1
reader_cost_averager = TimeAverager()
batch_cost_averager = TimeAverager()
batch_start = time.time()
log_iters = cfg['train']['log_interval_step']
save_dir="/home/aistudio/output/"
def average_dict(input_dict):
list_1 = []
for k, v in input_dict.items():
# print(k,v,v.ndimension)
input_dict[k] = v.mean() if v.ndimension() != 0 else v
list_1.append(input_dict[k])
return input_dict, list_1
# 采用混合精度训练
if precision == 'fp16':
logger.info('use AMP to train. AMP level = {}'.format(amp_level))
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
if amp_level == 'O2':
model, optimizer = paddle.amp.decorate(
models=paddle_model,
optimizers=optimizer,
level='O2',
save_dtype='float32')
paddle_model = FactSeg(cfg['model']['params'])
lr_cfg = cfg['learning_rate']['params']
base_lr = lr_cfg['base_lr']
power = lr_cfg['power']
scheduler = PolynomialDecay1(learning_rate=base_lr, decay_steps=lr_cfg['max_iters'], power=power, cycle=False)
optimizer_cfg = cfg['optimizer']['params']
momentum = optimizer_cfg['momentum']
weight_decay = optimizer_cfg['weight_decay']
optimizer = paddle.optimizer.Momentum(learning_rate=scheduler, parameters=paddle_model.parameters(),
momentum=momentum, weight_decay=weight_decay,
grad_clip=paddle.nn.ClipGradByNorm(
clip_norm=cfg['optimizer']['grad_clip']['max_norm']))
# 恢复训练
if os.path.exists(resume_model_path):
paddle_state_dict = paddle.load(resume_model_path)
paddle_model.set_dict(paddle_state_dict)
print("loading from resume model"+resume_model_path)
for i in range(args.resume_iter):
iter1+=1
scheduler.step()
while iter1<num_iters:
for (img,y) in train_loader:
paddle_model.train()
iter1+=1
if iter1>num_iters:
break
reader_cost_averager.record(time.time() - batch_start)
if precision == 'fp16':
with paddle.amp.auto_cast(
level=amp_level,
enable=True,
custom_white_list={
"elementwise_add", "batch_norm", "sync_batch_norm"
},
custom_black_list={'bilinear_interp_v2'}):
loss = paddle_model(img,y)
loss,loss_list = average_dict(loss)
loss = sum([e for e in loss.values()])
scaled = scaler.scale(loss) # scale the loss
scaled.backward() # do backward
if isinstance(optimizer, paddle.distributed.fleet.Fleet):
scaler.minimize(optimizer.user_defined_optimizer, scaled)
else:
scaler.minimize(optimizer, scaled) # update parameters
lr = optimizer.get_lr()
paddle_model.clear_gradients()
scheduler.step()
avg_loss += loss.numpy()[0]
if not avg_loss_list:
avg_loss_list = [l.numpy() for l in loss_list]
else:
for i in range(len(loss_list)):
avg_loss_list[i] += loss_list[i].numpy()
batch_cost_averager.record(
time.time() - batch_start, num_samples=batch_size)
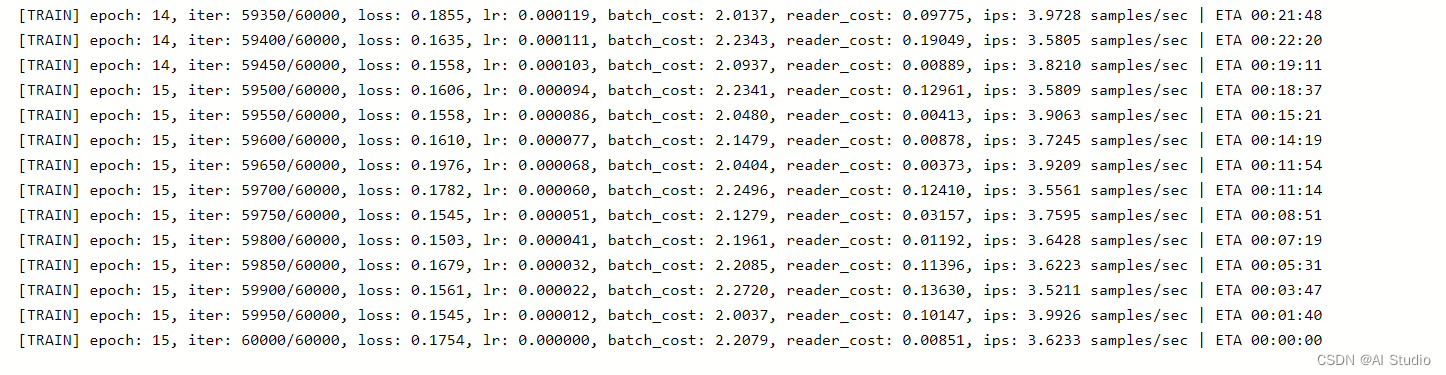
if iter1%log_iters==0:
avg_loss /= log_iters
avg_loss_list = [l[0] / log_iters for l in avg_loss_list]
remain_iters = num_iters - iter1
avg_train_batch_cost = batch_cost_averager.get_average()
avg_train_reader_cost = reader_cost_averager.get_average()
eta = calculate_eta(remain_iters, avg_train_batch_cost)
visual_log.add_scalar(tag="train_loss", step=iter1, value = avg_loss.item())
msg = "[TRAIN] epoch: {}, iter: {}/{}, loss: {:.4f}, lr: {:.6f}, batch_cost: {:.4f}, reader_cost: {:.5f}, ips: {:.4f} samples/sec | ETA {}".format((iter1 - 1
) // iters_per_epoch + 1, iter1, num_iters, avg_loss,
lr, avg_train_batch_cost, avg_train_reader_cost,
batch_cost_averager.get_ips_average(), eta)
logger.info(msg)
# print(msg)
avg_loss = 0.0
avg_loss_list = []
reader_cost_averager.reset()
batch_cost_averager.reset()
# 临时保存模型,用于模型恢复
if iter1%500==0:
save_path = save_dir+"fact-seg_temp.pdparams"
paddle.save(paddle_model.state_dict(),save_path)
# 模型评估所需显存过大,需要每5000迭代保存一次评估模型,之后单独进行评估
if iter1%5000==0:
best_model_path = save_dir+str(iter1)+"_best_model.pdparams"
paddle.save(paddle_model.state_dict(), best_model_path)
msg = '[EVAL] The model was saved at iter {}. save_path is {}'.format(iter1,best_model_path)
logger.info(msg)
# print(msg)
batch_start = time.time()
2.5 预测
# 解压阶段性保存模型,同样建议在终端解压
!unzip -d /home/aistudio/data/data171451 /home/aistudio/data/data171451/val_model.zip
# 预测消耗显存过大,为保证预测的正确进行,需要重启32G内核,并再次执行非训练部分的代码块
paddle_model = FactSeg(cfg['model']['params'])
ckpt_path='/home/aistudio/data/data171451/val_model/50000_best_model.pdparams'
print("loading path {}".format(ckpt_path))
paddle_state_dict = paddle.load(ckpt_path)
paddle_model.set_dict(paddle_state_dict)
paddle_model.eval()
patch_size = 896
miou_op = NPmIoU(num_classes=16, logdir=None)
image_trans = comm.Compose([
segm.ToTensor(True),
comm.THMeanStdNormalize((123.675, 116.28, 103.53), (58.395, 57.12, 57.375)),
comm.CustomOp(lambda x: x.unsqueeze(0))
])
segm_helper = SegmSlidingWinInference()
for idx, blob in enumerate(val_loader):
image, mask, filename = blob[0]
h, w = image.shape[:2]
if idx%10==0:
logging.info('Progress - [{} / {}] size = ({}, {})'.format(idx + 1, len(val_dataset), h, w))
seg_helper = segm_helper.patch((h, w), patch_size=(patch_size, patch_size), stride=512,
transforms=image_trans)
out = seg_helper.forward(paddle_model, image, size_divisor=32)
out = out.argmax(axis=1)
if mask is not None:
miou_op.forward(mask, out)
ious, miou = miou_op.summary()

2.6 结果分析
def plot_learning_curve(record, title='loss', ylabel='CE Loss'):
''' Plot learning curve of your CNN '''
maxtrain = max(map(float, record['train'][title]))
ymax = max(maxtrain, maxtrain) * 1.1
mintrain = min(map(float, record['train'][title]))
ymin = min(mintrain, mintrain) * 0.9
total_steps = len(record['train'][title])
x_1 = list(map(int, record['train']['iter']))
figure(figsize=(5, 3))
plt.plot(x_1, record['train'][title], c='tab:red', label='train')
plt.ylim(ymin, ymax)
plt.xlabel('Training steps')
plt.ylabel(ylabel)
plt.title('Learning curve of {}'.format(title))
plt.legend()
plt.show()
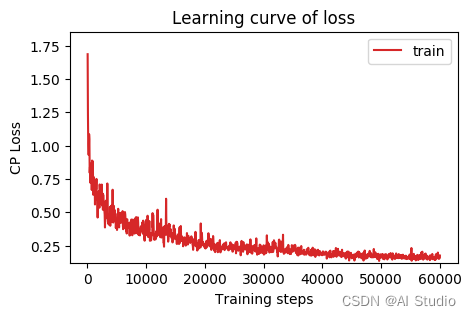
2.6.1 loss和miou曲线
loss_record = {'train': {'loss': [], 'iter': []}, 'val': {'loss': [], 'iter': []}} # for recording loss
train_log_path='/home/aistudio/Log/train_log.txt'
loss_iter = 50
with open(train_log_path,'r') as f:
lines = f.readlines()
for l in lines:
if l.startswith('[TRAIN]'):
start = l.index('loss: ')
end = l.index(', lr: ')
loss = float(l[start+5:end])
loss_record['train']['loss'].append(loss)
loss_record['train']['iter'].append(loss_iter)
loss_iter+=50
plot_learning_curve(loss_record, title='loss', ylabel='CP Loss')
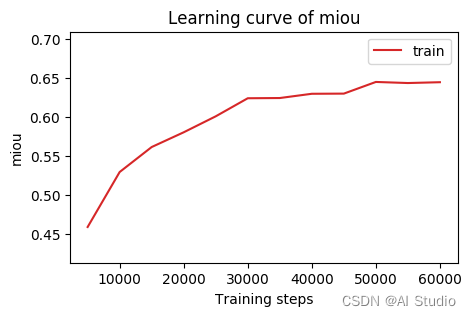
val_log_path = '/home/aistudio/Log/eva_log.txt'
val_iter = 5000
miou_record = {'train': {'miou': [], 'iter': []}} # for recording miou
with open(val_log_path,'r') as f:
lines = f.readlines()
for l in lines:
if 'mIoU' in l:
mIoU = re.findall(r'-?\d+\.?\d*e?-?\d*?', l)
miou_record['train']['miou'].append(float(mIoU[0]))
miou_record['train']['iter'].append(val_iter)
val_iter+=5000
plot_learning_curve(miou_record, title='miou', ylabel='miou')
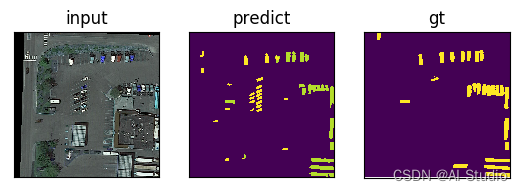
2.6.2 预测与真实标签比较
# 可视化代码先需要运行预测部分的解压各阶段模型命令,由于aistudio不会自动释放显存,多次运行会造成显存堆积,需要重启内核
def show_images(plt_list):
for i in range(len(plt_list)):
plt.figure(i)
plt.subplot(131)
plt.title('input')
plt.xticks([])
plt.yticks([])
plt.imshow(np.uint8(plt_list[i][0]))
plt.subplot(132)
plt.title('predict')
plt.xticks([])
plt.yticks([])
plt.imshow(plt_list[i][1])
plt.subplot(133)
plt.title('gt')
plt.xticks([])
plt.yticks([])
plt.imshow(plt_list[i][2])
plt.show()
model = FactSeg(cfg['model']['params'])
ckpt_path='/home/aistudio/data/data171451/val_model/50000_best_model.pdparams'
print("loading path {}".format(ckpt_path))
paddle_state_dict = paddle.load(ckpt_path)
model.set_dict(paddle_state_dict)
model.eval()
mask_dir = '/home/aistudio/data/data170962/test/masks/images'
img_path = '/home/aistudio/data/data170962/test/images/images/P0007.png'
image = cv2.imread(img_path)
mask_fp = os.path.join(mask_dir, os.path.basename(img_path)).replace('.png','_instance_color_RGB.png')
mask = cv2.imread(mask_fp)
_, mask = RemoveColorMap()(None, mask)
mask = np.array(mask, copy=False)
h, w = image.shape[:2]
patch_size = 896
stride = 512
image_trans = comm.Compose([
segm.ToTensor(True),
comm.THMeanStdNormalize((123.675, 116.28, 103.53), (58.395, 57.12, 57.375)),
comm.CustomOp(lambda x: x.unsqueeze(0))
])
out_list = []
wins = sliding_window((h, w), (patch_size, patch_size), stride)
size_divisor = None
i = 1
plt_list = []
for win in wins:
x1, y1, x2, y2 = win
image_np = np.array(image)
image_np = image_np[y1:y2, x1:x2, :].astype(np.float32)
save_image = image_np
mask_np = np.array(mask)
mask_np = mask_np[y1:y2, x1:x2]
if image_trans is not None:
image_np = image_trans(image_np)
h, w = image_np.shape[2:4]
if size_divisor is not None:
image_np = th_divisible_pad(image_np, size_divisor)
with paddle.no_grad():
out = model(image_np)
pred = paddle.argmax(out,axis=1)
pred_mask = pred
pred_mask = paddle.squeeze(pred_mask)
if size_divisor is not None:
out = out[:, :, :h, :w]
plt_list.append([save_image,pred_mask.cpu(),mask_np])
i+=1
paddle.device.cuda.empty_cache()
if i>3:
break
wins = None
show_images(plt_list)
Loading model Resnet50
ResNetEncoder: pretrained = True
loading path /home/aistudio/data/data171451/val_model/50000_best_model.pdparams
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:425: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_min = np.asscalar(a_min.astype(scaled_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/image.py:426: DeprecationWarning: np.asscalar(a) is deprecated since NumPy v1.16, use a.item() instead
a_max = np.asscalar(a_max.astype(scaled_dtype))


2.6.3 可视化结果
# 更改自PaddleSeg visualize代码
def visualize_1(image, result, color_map, save_dir=None, weight=0.6):
color_map = [color_map[i:i + 3] for i in range(0, len(color_map), 3)]
color_map = np.array(color_map).astype("uint8")
c1 = cv2.LUT(result, color_map[:, 0])
c2 = cv2.LUT(result, color_map[:, 1])
c3 = cv2.LUT(result, color_map[:, 2])
pseudo_img = np.dstack((c3, c2, c1))
vis_result = cv2.addWeighted(image, weight, pseudo_img, 1 - weight, 0)
return vis_result
def show_visual_images(plt_list):
for i in range(len(plt_list)):
plt.figure(i)
plt.title('visual image')
plt.xticks([])
plt.yticks([])
color_map = visualize.get_color_map_list(256)
image = np.uint8(plt_list[i][0])
mask = np.uint8(plt_list[i][1])
vis_image = visualize_1(image, mask, color_map, weight=0.6)
mask = np.dstack([mask,mask,mask])
vis_image[mask==0] = 0
image[mask>0] = 0
vis_image +=image
plt.imshow(cv2.cvtColor(np.uint8(vis_image),cv2.COLOR_BGR2RGB))
plt.show()
model = FactSeg(cfg['model']['params'])
ckpt_path='/home/aistudio/data/data171451/val_model/50000_best_model.pdparams'
print("loading path {}".format(ckpt_path))
paddle_state_dict = paddle.load(ckpt_path)
model.set_dict(paddle_state_dict)
model.eval()
mask_dir = '/home/aistudio/data/data170962/test/masks/images'
img_path = '/home/aistudio/data/data170962/test/images/images/P0053.png'
image = cv2.imread(img_path)
mask_fp = os.path.join(mask_dir, os.path.basename(img_path)).replace('.png','_instance_color_RGB.png')
mask = cv2.imread(mask_fp)
_, mask = RemoveColorMap()(None, mask)
mask = np.array(mask, copy=False)
h, w = image.shape[:2]
patch_size = 896
stride = 512
image_trans = comm.Compose([
segm.ToTensor(True),
comm.THMeanStdNormalize((123.675, 116.28, 103.53), (58.395, 57.12, 57.375)),
comm.CustomOp(lambda x: x.unsqueeze(0))
])
out_list = []
wins = sliding_window((h, w), (patch_size, patch_size), stride)
size_divisor = None
i = 1
plt_list = []
for win in wins:
x1, y1, x2, y2 = win
image_np = np.array(image)
image_np = image_np[y1:y2, x1:x2, :].astype(np.float32)
save_image = image_np
mask_np = np.array(mask)
mask_np = mask_np[y1:y2, x1:x2]
if image_trans is not None:
image_np = image_trans(image_np)
h, w = image_np.shape[2:4]
if size_divisor is not None:
image_np = th_divisible_pad(image_np, size_divisor)
with paddle.no_grad():
out = model(image_np)
pred = paddle.argmax(out,axis=1)
pred_mask = pred
pred_mask = paddle.squeeze(pred_mask)
if size_divisor is not None:
out = out[:, :, :h, :w]
plt_list.append([save_image,pred_mask.cpu(),pred_mask])
i+=1
if i>1:
break
wins = None
show_visual_images(plt_list)
Loading model Resnet50
ResNetEncoder: pretrained = True
loading path /home/aistudio/data/data171451/val_model/50000_best_model.pdparams

复现论文的数据对比
| method | iters | bs | card | loss | align_corners | mIoU |
|---|---|---|---|---|---|---|
| 论文精度 | 60k | 4 | 2 | JointLoss | √ | 64.80 |
| 验收精度 | 60k | 8 | 1 | JointLoss | √ | 64.64 |
各种模型对比结果
| Model | Backbone | mIoU(%) |
|---|---|---|
| FCN8S | VGG16 | 41.65 |
| U-Net | - | 39.20 |
| DenseASPP | DenseNet121 | 56.80 |
| SFPN | ResNet50 | 59.31 |
| RefineNet | ResNet50 | 60.20 |
| PSPNet | ResNet50 | 60.25 |
| DeepLabv3 | ResNet50 | 59.04 |
| DeepLabv3+ | ResNet50 | 60.82 |
| FarSeg | ResNet50 | 63.71 |
| DenseU-Net | DenseNet121 | 58.70 |
| Mask-RCNN | ResNet101 | 54.18 |
| FactSeg | ResNet50 | 64.80 |
参考文章:
总结
为了解决高清遥感图像中小目标分割问题,本文提出了一种前景激活驱动的小目标分割网络(Fact-Seg)。该网络由双分支解码器,CP损失和基于SOM的网络优化组成,并在两个高清遥感图像数据集上取得了SOTA的成绩。
未来工作:将Fact-Seg扩展于轨道卫星数据处理、语义分割、目标检测等相关任务中。
复现心得: 在反向对齐过程中,如果从最后一层开始梯度就无法对齐,可以再向前排查损失函数中的paddle API是否对齐。如Fact-Seg复现过程中,由于paddle中的Clone算子和pytorch在梯度反向传播时有所不同,导致模型反向传播无法对齐,因此需要重写Clone算子。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 4
4 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)