
【懒惰就是生产力】目标检测数据集半自动标注
人工标注少量数据,基于PaddleDetection训练模型批量标注剩余数据集。labelme和labelImg标注工具皆可。
背景介绍
标注数据集对深度学习而言是很重要的一步,但是标注数据是一项枯燥乏味的工作,而重复劳动对人来说又是极痛苦的。在刚刚过去的第十七届全国大学生智能汽车竞赛中我们深有体会。为了减少工作量,笔者将半自动标注的方法运用于该比赛的数据集标注当中,大大降低了人力成本与时间成本,也让我们有足够的底气采集大量数据集。
项目简介
半自动标注是什么?
- 人工标注少量数据
- 使用labelme或者labelImg标注少量数据,大概每类五十张图片
- 训练目标检测模型
- 从PaddleDetection模型库中尽可能选择精度高的检测模型
- 模型推理自动标注
- 选择在验证集上mAP最好的模型,对剩余的图片进行检测
- 把检测的结果转换成labelme格式的json文件(或者labelImg的xml文件)
- 人工矫正标注结果
- 使用labelme或labelImg调整预标注的结果
- 修改后的数据加入训练集,训练更优的模型。
- 通过2~5步骤的循环迭代,可以逐步求精

本项目就以笔者参加的全国大学生智能汽车竞赛为例,提供从技术方案、数据准备、模型训练,到模型自动标注的全流程可复用方案,有效解决了目标检测数据集标注问题,同样适用于其他检测场景,更换数据集后即可使用。
1. 数据准备
首先我们需要手动标注一定量的数据,一般情况下几十张应该足够了。本项目示例的数据集每类三十张。一般来说常用的标注软件就是labelme和labelImg,所以笔者分别使用这两个软件对每张图片进行了矩形框标注,大家在运行项目的时候只需要选择一种标注方式。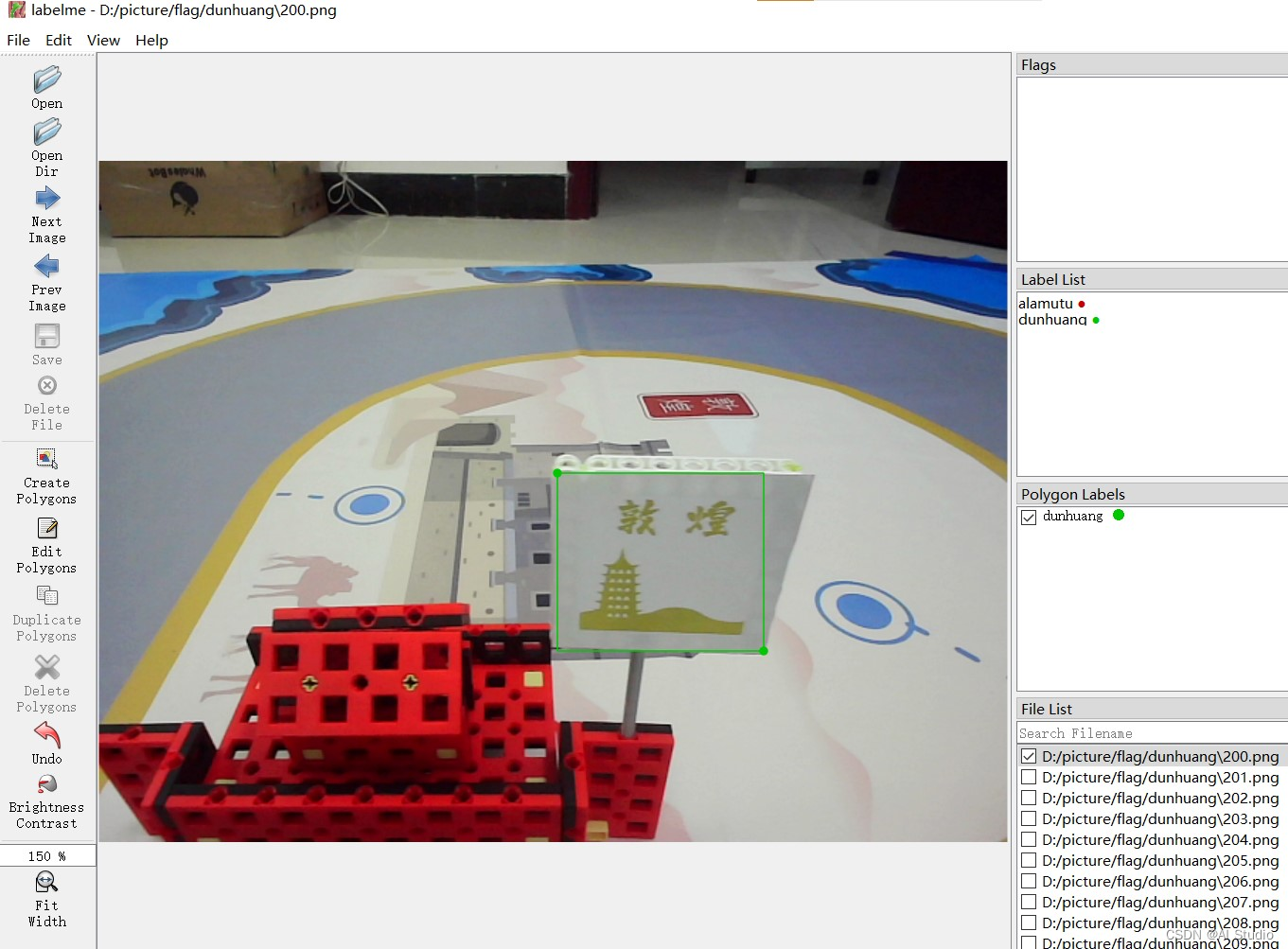
1.1 解压已经标注好的少量数据集
示例数据集格式:
共三类,分别是alamutu,dunhuang,jstdb,每张图片仅有一个GT,图片后缀为png
├── alamutu
│ ├── 30张图片,且有30个对应的json文件(用labelme标注)
├── dunhuang
│ ├── 30张图片,且有30个对应的json文件(用labelme标注)
├── jstdb
│ ├── 30张图片,且有30个对应的json文件(用labelme标注)
├── Label (存放每个类别的所有标签)(xml文件)(用labelImg标注)
│ ├── alamutu
│ ├── dunhuang
│ ├── jstdb
├── label_list(包含类别信息,每行表示一类)
- 如果使用labelme标注,则每类图片放在一个文件夹下,文件名为类别名称,标签文件放在同一文件夹下。所有图片名称不能重复
- 如果使用labelImg标注,则每类图片放在一个文件夹下,文件名为类别名称,标签文件放在Label文件夹下的子目录下,子目录的名称为类别名称。不同类别的图片名称可重复
# 解压已标注的数据集(共三类)
!unzip -oq /home/aistudio/data/data171717/castle.zip -d /home/aistudio/data/to_train
# 将类别信息复制到工作目录下(去掉背景类,此文件需要自行修改)
!cp -r /home/aistudio/labels.txt /home/aistudio/data/to_train
# 获取所有类别信息
label_list=[] # 定义一个列表,用于存放所有类别,以供后续使用
# 按行读取labels.txt文件中的类别
with open('/home/aistudio/data/to_train/labels.txt','r') as f:
for line in f:
label_list.append(line.strip('\n').split(',')[0]) # 将每行的数据追加到列表中
1.2 删除没有对应标注文件的图片
实际标注过程可能会有部分图片不存在目标物,所以此类图片删去
# 删除没有对应json文件的图片
import os # 包含很多操作文件和目录的函数的库
total_directory = '/home/aistudio/data/to_train' # 存放所有图片和标签文件的根目录
count = 0 # 定义count,用于记录没有对应标注文件的图片
for dir in os.listdir(total_directory): # 遍历根目录
if dir not in label_list: # 如果文件夹名称不属于任意类别则跳过
continue
imgpath = os.path.join(total_directory,dir) # 拼接图片文件夹路径
if os.path.isdir(imgpath): # 判断是否是文件夹
files = os.listdir(imgpath)
for file in files: # 遍历子目录
number , postfix= file.split('.', 1) # 根据.分隔文件名称
if postfix == 'png': # 如果后缀是png
surplus = dir +'/'+ number + '.json'
dirtyfile = os.path.join(total_directory,surplus) # 拼接路径,得到json文件的绝对路径
if not os.path.exists(dirtyfile): # 如果对应的标注文件不存在
dirtyimg = number + '.png'
dirtyimgpath = os.path.join(imgpath,dirtyimg)
os.remove(dirtyimgpath) # 则删除图片
count += 1 # 累加没有对应标注文件的图片张数
print('成功删除没有对应json文件的图片:',dirtyimgpath)
print('一共删除的图片张数为:',count)
# # 删除没有对应xml文件的图片
# import os # 包含很多操作文件和目录的函数的库
# total_directory = '/home/aistudio/data/to_train' # 存放所有图片和标签文件的根目录
# count = 0 # 定义count,用于记录没有对应标注文件的图片
# for dir in os.listdir(total_directory): # 遍历根目录
# if dir not in label_list: # 如果文件夹名称不属于任意类别则跳过
# continue
# imgpath = os.path.join(total_directory,dir) # 拼接图片文件夹路径
# if os.path.isdir(imgpath): # 判断是否是文件夹
# files = os.listdir(imgpath)
# for file in files: # 遍历子目录
# number , postfix= file.split('.', 1) # 根据.分隔文件名称
# if postfix == 'png': # 如果后缀是png
# surplus = 'Label/' + dir +'/'+ number + '.xml'
# dirtyfile = os.path.join(total_directory,surplus) # 拼接路径,得到xml文件的绝对路径
# if not os.path.exists(dirtyfile): # 如果对应的标注文件不存在
# dirtyimg = number + '.png'
# dirtyimgpath = os.path.join(imgpath,dirtyimg)
# os.remove(dirtyimgpath) # 则删除图片
# count += 1 # 累加没有对应标注文件的图片张数
# print('成功删除没有对应xml文件的图片:',dirtyimgpath)
# print('一共删除的图片张数为:',count)
1.3 统计每个类别的图片张数
# 统计labels.txt中每一类别的图片数
import os # 包含很多操作文件和目录的函数的库
total_directory = '/home/aistudio/data/to_train' # 存放所有图片和标签文件的根目录
for dir in os.listdir(total_directory): # 遍历根目录
length = 0 # 定义length,用于统计图片张数
if dir not in label_list: # 如果文件夹名称不属于任意类别则跳过
continue
path = os.path.join(total_directory,dir) # 拼接路径
for file in os.listdir(path): # 遍历子目录
if file.endswith(('png','jpg')): # 根据文件后缀确定是否为图片
length += 1 # 累加图片张数
print('{} 图片数为:'.format(path),length) # 输出每类图片张数
1.4 划分数据集
1)labelme格式
# 将json文件移到jsons文件夹中
import os # 包含很多操作文件和目录的函数的库
import shutil
total_directory = '/home/aistudio/data/to_train/' # 存放所有图片和标签文件的根目录
# 移动文件
def mymovefile(srcfile, # 待移动的源文件路径
dstfile, # 目标文件路径
mode): # 模式,1表示move,2表示copy
if not os.path.isfile(srcfile): # 如果源文件不存在则输出提示信息
print("src not exist!")
else:
fpath,fname=os.path.split(dstfile) # 分离文件名和路径
if not os.path.exists(fpath): # 如果目标文件夹不存在
os.makedirs(fpath) # 则创建
if mode == 1:
shutil.move(srcfile,dstfile) # 移动文件
elif mode == 2:
shutil.copy(srcfile,dstfile) # 复制文件
# 将每类文件夹下的json文件移动到jsons文件夹下
for dirpaths, dirnames, filenames in os.walk(total_directory): # os.walk游走遍历目录名
for filename in filenames:
if filename.endswith('json'):
jsonfilepath = os.path.join(dirpaths, filename) # 如果是json文件,获取绝对路径
mymovefile(jsonfilepath,'/home/aistudio/data/to_train/labelme/jsons/{}'.format(filename),1)
if filename.endswith(('png','jpg')):
imgfilepath = os.path.join(dirpaths, filename) # 如果是图片文件,获取绝对路径
mymovefile(imgfilepath,'/home/aistudio/data/to_train/labelme/images/{}/{}'.format(os.path.split(dirpaths)[-1],filename),2)
# labelme转coco格式,并划分数据集
# stratified_sampling表示是否需要对图片进行分层随机抽样,
# 若为True,image_input_dir下必须是若干个子文件夹,子文件夹下只有图片
!python /home/aistudio/PaddleDetection-release-2.4/tools/x2coco.py \
--dataset_type=labelme \
--json_input_dir='/home/aistudio/data/to_train/labelme/jsons' \
--image_input_dir='/home/aistudio/data/to_train/labelme/images' \
--output_dir='/home/aistudio/data/to_train/coco_form' \
--stratified_sampling=True \
--train_proportion=0.75 \
--val_proportion=0.25 \
# --test_proportion=0.1
2)labelImg格式
# # labelImg标注的数据集划分(如果生成的txt文件为空,再次运行该cell即可)
# import os # 包含很多操作文件和目录的函数的库
# import random # 用于生成伪随机数的函数库
# # 定义图片与标签路径整合函数,得到训练、测试所需的txt文件
# def get_all_date(label_dir, # 存放所有标签的文件夹根路径
# labelTypeName, # 类别标签的名称
# img_dir): # 存放所有图片的文件夹路径
# res = [] # 定义一个列表,用于存放图片路径和对应的标签文件路径
# labelTypePath = os.path.join(label_dir, labelTypeName) # 标签文件路径拼接
# imgTypePath = os.path.join(img_dir, labelTypeName) # 图片路径拼接
# for file in os.listdir(labelTypePath): # 遍历每一类标签文件夹下的文件
# label_path = os.path.join(labelTypePath, file) # 标签文件路径拼接
# label_path = label_path.replace("\\",'/') # 用'/'替代"\\"
# img_path = os.path.join(imgTypePath, file.split('.')[0]+'.png') # 图片路径拼接,图片和标签文件的名字相同
# img_path = img_path.replace("\\",'/') # 用'/'替代"\\"
# if os.path.exists(img_path) and os.path.exists(label_path): # 如果图片和标签文件都存在
# res.append((img_path,label_path)) # 则将两者的路径以元组形式存入列表中
# return res
# if __name__ == "__main__":
# res_list = [] # 定义一个列表,用于存放所有图片路径和对应的标签文件路径
# img_dir = '/home/aistudio/data/to_train/' # 存放所有图片和标签文件的根目录
# label_dir = '/home/aistudio/data/to_train/Label/' # 存放所有标签文件的根目录
# train_anno_path = '/home/aistudio/data/to_train/road_train.txt' # 训练集的标注文件路径
# val_anno_path = '/home/aistudio/data/to_train/road_val.txt' # 验证集的标注文件路径
# for labelTypeName in os.listdir(label_dir): # 遍历存放所有标签文件的文件夹
# res = get_all_date(label_dir,labelTypeName,img_dir) # 调用函数得到某个类别的所有图片和标签文件路径,以列表形式返回
# random.shuffle(res) # 打乱列表元素
# res_list.append(res) # 将某一类的列表追加到总列表内
# # 划分数据集
# ratio = 0.2 # 设置验证集的比例
# for res in res_list: # 遍历存放所有图片路径和标签文件路径的列表
# for i in range(0, len(res)):
# if i < ratio * len(res): # 取ratio作为验证集
# with open(val_anno_path, 'a') as f: # 'a'代表着每次运行都追加txt的内容
# f.writelines(res[i][0] + ' ' + res[i][1] + '\n') # 按行写入图片路径和标签文件路径
# else: # 取1-ratio作为训练集
# with open(train_anno_path, 'a') as f:
# f.writelines(res[i][0] + ' ' + res[i][1] + '\n')
# # 训练集各类别的图片顺序打乱
# lines=[] # 定义一个列表,用于存放从txt文件中读取的数据
# with open(train_anno_path, 'r') as infile: # 以只读模式打开txt文件
# for line in infile:
# lines.append(line) # 按行读取txt里的数据,将其存入列表
# random.shuffle(lines) # 再次打乱图片顺序
# out = open(train_anno_path,'w') # 'w'代表着每次运行都覆盖内容
# for line in lines:
# out.write(line) # 按行写入
# # 验证集同理
# lines1=[]
# with open(val_anno_path, 'r') as infile1:
# for line in infile1:
# lines1.append(line)
# random.shuffle(lines1)
# out1 = open(val_anno_path,'w')
# for line in lines1:
# out1.write(line)
# print('finish')
2. 模型训练——用于自动标注
2.1 环境准备
# 切换工作路径
%cd ~
%cd PaddleDetection-release-2.4/
# 每次启动都得运行,安装相关依赖
!pip install -r requirements.txt
# 编译安装paddledet
!python setup.py install
由于本项目的环境配置为:
PaddlePaddle = 2.2.2
Python == 3.7.4
所以部分模型可能不适用,可选择更高版本的PaddlePaddle试试。
本项目展示的是coco格式的模型训练,如果是用labelImg标注的数据集,则需要在配置文件种改成voc格式,如:
metric: VOC
map_type: 11point
num_classes: 3
TrainDataset:
!VOCDataSet
dataset_dir: /home/aistudio/data/to_train # 数据集根目录
anno_path: road_train.txt # 训练集列表文件基于数据集根目录的相对路径
label_list: labels.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
!VOCDataSet
dataset_dir: /home/aistudio/data/to_train
anno_path: road_val.txt
label_list: labels.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
!ImageFolder
anno_path: /home/aistudio/data/to_train/labels.txt
2.2 检测模型训练
# 单卡
!export CUDA_VISIBLE_DEVICES=0
# 模型训练
# 如果要恢复训练,则加上 -r output/picodet_l_640_coco_mydataset/best_model
# 如果要边训练边评估,则加上--eval
!python tools/train.py \
-c configs/picodet_l_640_coco_mydataset.yml --eval\
--use_vdl=True \
--vdl_log_dir=visualDL
2.3 检测模型评估
# output_eval表示Evaluation directory, default is current directory.
# classwise表示是否计算每一类的AP和画P-R曲线,PR曲线图默认存放在bbox_pr_curve文件夹下
!python tools/eval.py -c configs/picodet_l_640_coco_mydataset.yml \
--output_eval=/home/aistudio/data/to_train/coco_form/val \
--classwise \
se \
-o weights=/home/aistudio/PaddleDetection-release-2.4/output/picodet_l_640_coco_mydataset/best_model.pdparams
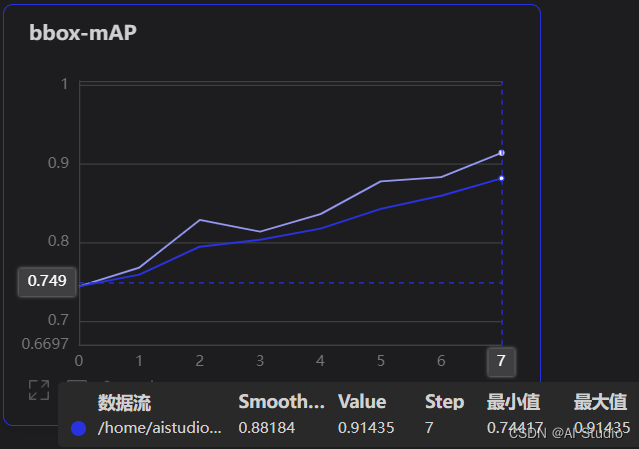
以下是笔者在手动标注数据集上训练的效果。对90张手动标注数据集进行分层随机抽样,训练集:验证集=3:1,80e共耗时6min,mAP达到91.4%,足以用于接下来的自动标注。值得一提的是,模型推理效果越好,人工矫正标注结果的工作量就越小!
3. 自动标注数据集
首先,我们先来了解一下labelme生成的json文件的内部数据(labelImg同理):
{
"version": "4.5.6" # labelme版本
"flags": {}, # 分类样本标注时用到,是样本的类别(整个图片属于什么类别)
"shapes": [ # shapes里面以字典的形式存放标注的标签个数(类别个数)
{ # 第一个对象
"label": "alamutu", # 第一个对象的标签
"points": [ # 围成框的所有点,标注时第一个点存放在这里index为0的位置。
[
49.666666666666664, # 第一个点 x 坐标
223.33333333333331 # 第一个点 y 坐标
],
[
218.33333333333334, # 第二个点的x坐标
346.6666666666667 # 第二个点的y坐标
]
],
"group_id": null, # 组别
"shape_type": "rectangle", # 标注形式,这里是矩形
"flags": {}
}
],
"imagePath": "100.png", # 原图片的名称
"imageData": "xxxxxx", # 原图像数据通过b64编码生成的字符串数据,可以再次解码成图片。这里不重要,只需要知道是图像数据的另一种存储形式
"imageHeight": 480, # 图片高(rows)
"imageWidth": 640 # 图片宽(cols)
}
所以目标很明确——只需要将模型推理得到的目标框坐标和所属类别转化为labelme标注格式并存储为json格式即可,而其余字段可在读取图片时得到。
3.1 解压待标注的数据集
# 这里把数据集解压到work文件夹下,待自动标注完成后将图片删掉,只留下标注文件
!unzip -oq /home/aistudio/data/data173296/castle_to_anno.zip -d /home/aistudio/work/Dataset/
3.2 批量生成标注文件
所得标注文件保存在图片所在的目录下
# 切换工作路径
%cd ~
%cd PaddleDetection-release-2.4/
# --draw_threshold表示推理结果置信度阈值
# 可通过--save_labelme和--save_labelImg进行选择保存为json还是xml格式
!python tools/infer.py -c configs/picodet_l_640_coco_mydataset.yml \
--infer_dir=/home/aistudio/work/Dataset/ \
-o weights=output/picodet_l_640_coco_mydataset/best_model.pdparams \
--draw_threshold=0.5 \
--save_labelme
如果出现以下报错:
Traceback (most recent call last):
File "/home/aistudio/PaddleDetection-release-2.4/ppdet/data/reader.py", line 55, in __call__
data = f(data)
File "/home/aistudio/PaddleDetection-release-2.4/ppdet/data/transform/operators.py", line 105, in __call__
sample = self.apply(sample, context)
File "/home/aistudio/PaddleDetection-release-2.4/ppdet/data/transform/operators.py", line 132, in apply
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
cv2.error: OpenCV(4.1.1) /io/opencv/modules/imgproc/src/color.cpp:182: error: (-215:Assertion failed) !_src.empty() in function 'cvtColor'
- 检查图片路径,用绝对路径且无中文、空格
- 图片损坏,把对应图片找到并删除,将
/home/aistudio/PaddleDetection-release-2.4/ppdet/data/reader.py的line54注释去掉,可以找到最后一张出错的图片是哪个
如果出现以下多余框的问题,可以考虑调大draw_threshold这个阈值
# 查看其中一个标注文件的内容
!cat /home/aistudio/work/Dataset/alamutu/10003.json
# 因为图片在电脑本地已存在
# 为了下载方便,删除所有图片,留下标注文件
import os # 包含很多操作文件和目录的函数的库
dir = '/home/aistudio/work/Dataset' # 待标注数据集的路径
for root, directories, files in os.walk(dir): # os.walk游走遍历目录名
for filename in files:
if filename.endswith(('jpg','png')): # 根据文件后缀判断是不是图片
filepath = os.path.join(root, filename) # 拼接图片路径
os.remove(filepath) # 删除图片
print('已删除所有图片')
由于数据集数量较少,训练出来的模型推理效果可能没那么好,这种情况是难免的,如下图所示:

- 对于上图中矩形框位置不准确的问题,只能通过人工矫正解决——下载标注文件到本地,打开标注软件,重新修改矩形框的位置。
- 对于类别推理有误的问题,可以通过先验知识解决——由于本项目的示例数据集每张只有一个GT,所以可以提前知道该图片包含的目标物所属的类别,只需重新遍历得到的标注文件,根据先验知识将其所属类别进行强制修改!这样做的好处在于模型推理只需要定位准确就行,分类效果不做要求。
3.3 批量修改标签名
将图片中包含的所有标签名强制改为图片所在文件夹的名称
# !/usr/bin/env python
# -*- encoding: utf-8 -*-
# 批量修改json文件的标签名
import os # 包含很多操作文件和目录的函数的库
import json
origin_ann_dir = '/home/aistudio/work/Dataset/' # 设置原始标签路径
count = 0 # 定义count,用于错标注的图片张数
for dirpaths, dirnames, filenames in os.walk(origin_ann_dir): # os.walk游走遍历目录名
for filename in filenames:
if filename.endswith('json'):
origin_ann_path = os.path.join(dirpaths, filename) # 如果是,获取绝对路径
with open(origin_ann_path,'r',encoding = 'utf-8') as jf: # json文件读入成字符串格式
info = json.load(jf) # 载入字符串,json格式转python格式
# 找到位置进行修改
for i in range(len(info['shapes'])):
if info['shapes'][i]['label'] != dirpaths.split('/')[-1]: # 如果标签名与所在文件夹名称不同
info['shapes'][i]['label'] = dirpaths.split('/')[-1] # 则修改标签名
count += 1 # 累加错标注的图片张数
# 把修改后的python格式的json文件,另存为新的json文件
with open(origin_ann_path,'w') as new_jf:
json.dump(info,new_jf)
print('错识别总个数为:',count)
print('已全部改正')
# #!/usr/bin/env python2
# # -*- coding: utf-8 -*-
# # 批量修改xml文件的标签名
# # 检查有没有错识别
# import os
# import xml.etree.ElementTree as ET
# count = 0 # 定义count,用于错标注的图片张数
# origin_ann_dir = '/home/aistudio/work/Dataset/' # 设置原始标签路径
# for dirpaths, dirnames, filenames in os.walk(origin_ann_dir): # os.walk游走遍历目录名
# for filename in filenames:
# if filename.endswith('xml'):
# origin_ann_path = os.path.join(dirpaths, filename) # 如果是,获取绝对路径
# tree = ET.parse(origin_ann_path) # ET是一个xml文件解析库,ET.parse()打开xml文件。parse--"解析"
# root = tree.getroot() # 获取根节点
# for object in root.findall('object'): # 找到根节点下所有“object”节点
# name = str(object.find('name').text) # 找到object节点下name子节点的值(字符串)
# # 如果name不等于所在文件夹的名称,则修改name
# if name != dirpaths.split('/')[-1]:
# object.find('name').text = dirpaths.split('/')[-1]
# tree = ET.ElementTree(root)
# count += 1 # 累加错标注的图片张数
# print('predict wrongly',origin_ann_path)
# tree.write(origin_ann_path)
# print('错识别总个数为:',count)
# print('已全部改正')
3.4 压缩所有标签文件
#把Dataset文件夹及其子文件夹下所有文件打包,将所得压缩包下载即可
%cd /home/aistudio/work/
# 压缩文件夹(-r表示包含子目录)
!zip -r -q -o annotations.zip Dataset/
效果对比
将自动标注后的图片合并到训练集中重新训练模型,合并前后的效果对比图如下: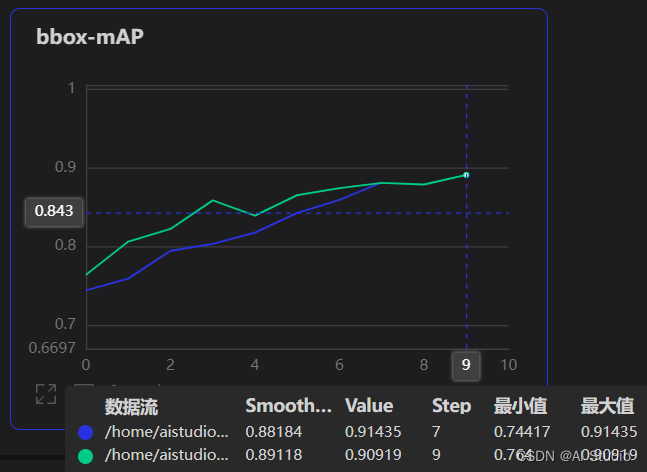
- 其中,蓝色曲线是合并前的,绿色曲线是合并后的,可以看到,半自动标注的数据集融入到训练集后提升了模型效果(绿色曲线整体位于蓝色曲线上方),不过,由于手动标注略有误差,所以mAP最后都收敛在90%左右。
- 本项目示例的待标注图片每类也是30张,经测试,用上述模型自动标注得到的标签文件均无需修改,直接加入到原来的数据集中,模型训练效果如上图绿色曲线所示。
总结
- 本项目基于PaddleDetection实现半自动标注,对
tools/x2coco.py,tools/infer.py,ppdet/engine/trainer.py,ppdet/utils/visualizer.py的部分函数进行了修改以适用于本项目。 - 只支持矩形框标注的图片文件,大家可以根据个人需求修改上述几个代码。
- 至于模型选择与训练方面,还有待提升,调参这一块可以再下点功夫。总之,模型效果越好,半自动标注的实用性就越强。
- 如果半自动标注工具的效果能达到要求,就会大幅减小标注的工作量。并且这样做有一个好处就是可以迭代,用初代模型的预测结果标注的数据经人工审核后再用来训练下一代模型,这样自动标注的质量也会越来越高。
- 但是,精度和效率很难达到平衡,目前来看,主流方法还是全人工标注。如果待标注的数据量实在太多,建议还是去找数据标注外包公司,毕竟专业的事情还是交给专业的人干比较好。
- 最后,君子藏器于身,待时而动——希望本项目对你有所帮助与启发。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 12
12 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)