
【第七期论文复现赛-OCR】CAN-手写数学公式识别网络
CAN论文复现,CAN是2022年ECCV会议收录的手写数学公式识别算法,本次复现的ExpRate为CROHME 51.72%,本算法已被PaddleOCR收录
【第七期论文复现赛-OCR】Counting-Aware Network(CAN)-手写数学公式识别网络
摘要
手写公式识别任务根据公式图片,输出latex符号形式的识别结果。目前的手写公式识别算法多用基于注意力的编解码器结构,但是基于注意力的识别往往会受到手写风格和空间分布的影响,因此在复杂结构和识别长序列方面的表现有所欠缺。Counting-Aware Network(CAN)是2022年ECCV会议收录的手写数学公式识别新算法,该算法同时优化手写公式识别和符号计数两个子任务,从而提升了长难公式的识别度。本文提出的基于弱监督的计数模块可以在没有符号级别位置标注的情况下对符号进行计数。实验表明CAN在手写公式识别数据集上的表现优于此前的方法,并且和其他编解码结构的方法相比,其由于计数模块增加的时间成本是可控的。
论文:When Counting Meets HMER: Counting-Aware Network for Handwritten Mathematical Expression Recognition
官方repo:https://github.com/LBH1024/CAN
复现repo:https://github.com/Lllllolita/CAN_Paddle
1、论文解读
1.1 总体架构
CAN是一个可训练的端到端模型,由特征提取网络(图中的backbone,选取DenseNet)、多尺度计数模块(Multi-Scale Counting Module,MSCM)和联合计数注意力解码器(Counting-Combined Attentional Decoder,CCAD)构成。模型接收一张灰度图,通过特征提取网络得到特征图F(即图中的feature map)。计数模块MSCM根据F预测每类符号所属的类别并生成一个一维计数向量V;解码器CCAD根据F和V,预测最终的符号序列。
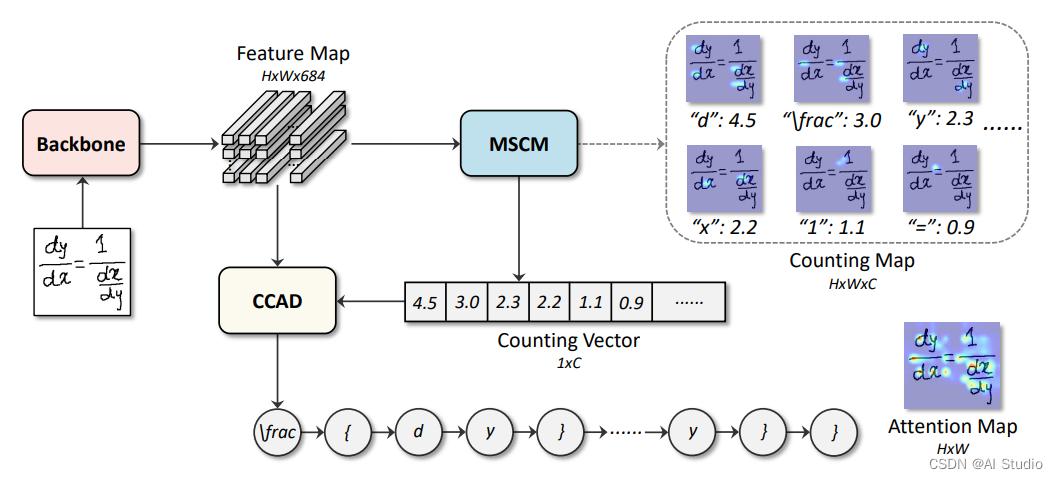
1.2 多尺度计数模块(MSCM)
MSCM包含多尺度特征分解(multi-scale feature extraction)、通道注意力(channel attention)和总和池化操作(sum-pooling)。考虑到手写公式识别受到书写风格等习惯影响,该模块有两个并行的不同大小卷积核(3*3和5*5)分支提取公式图像的多尺度特征,并分别通过通道注意力获取进一步的特征。对两个分支输出的深度特征进行1*1卷积得到表示符号位置的伪密度图M(如图1右上角Counting Map所示),根据以下公式分别计算两个分支对应的符号计数结果,取平均值作为最终的计数结果输入联合计数注意力解码器。
ν i = ∑ p = 1 H ∑ q = 1 W M i , p q \nu_i=\sum_{p=1}^{H}\sum_{q=1}^{W}M_i,pq νi=p=1∑Hq=1∑WMi,pq
1.3 联合计数注意力编码器
联合计数注意力解码器CCAD的结构如图2所示。CCAD接收特征提取网络提取的特征图F和计数模块输出的计数向量v,另外,为了增强模型对空间位置的敏感度,此处添加了绝对位置编码p(图中的positional encoding)。在解码阶段,t-1时刻的输出作为GRU在t时刻的隐状态输入。此时注意力权重的计算方式如下
e t = w T tanh ( T + P + W a A + W h h t ) + b α t , i j = exp ( e t , i j ) / ∑ p = 1 H ∑ q = 1 W e t , p q \begin{array}{c} e_{t}=w^{T} \tanh \left(\mathcal{T}+\mathcal{P}+W_{a} \mathcal{A}+W_{h} h_{t}\right)+b \\ \alpha_{t, i j}=\exp \left(e_{t, i j}\right) / \sum_{p=1}^{\mathrm{H}} \sum_{q=1}^{\mathrm{W}} e_{t, p q} \end{array} et=wTtanh(T+P+WaA+Whht)+bαt,ij=exp(et,ij)/∑p=1H∑q=1Wet,pq
其中w,b,Wa,Wh可训练参数,A为过去所有时刻注意力权重的和。将特征图F与\alpha相乘得到内容向量C,此时t时刻的符号预测公式为:
p ( y t ) = softmax ( w o T ( W c C + W v V + W t h t + W e E ) + b o y t ∼ p ( y t ) \begin{array}{c} p\left(y_{t}\right)=\operatorname{softmax}\left(w_{o}^{T}\left(W_{c} \mathcal{C}+W_{v} \mathcal{V}+W_{t} h_{t}+W_{e} E\right)+b_{o}\right.\\ y_{t} \sim p\left(y_{t}\right) \end{array} p(yt)=softmax(woT(WcC+WvV+Wtht+WeE)+boyt∼p(yt)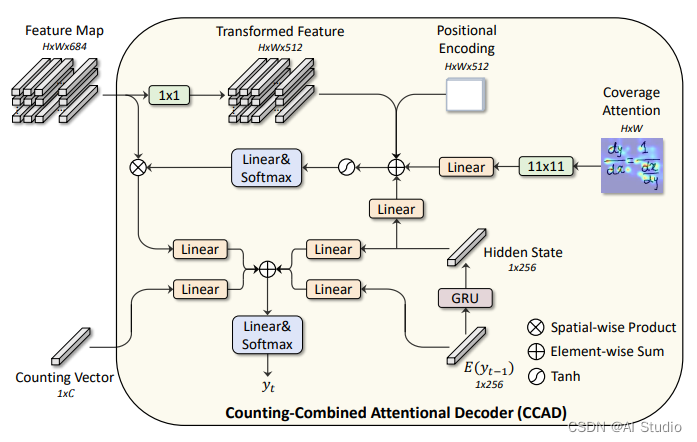
2、复现详情
2.1 模型搭建
CAN结构框架为Encoder-Decoder框架,Encoder(DenseNet)将输入图片编码成深层的语义特征,语义特征会输入到Decoder中的多尺度计数模块 Multi scale counting Module (MSCM) 和结合计数的注意力解码器counting-combined attentional decoder (CCAD)中,MSCM使用双路计数模块对不同感受野特征图进行计数,输出counting vector,counting vector 和语义特征共同输入到CCAD中进行解码,最后输出最终的图片识别结果。
2.1.1 DenseNet复现
import math
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
'''densenet:
ratio: 16
growthRate: 24
reduction: 0.5
bottleneck: True
use_dropout: True
'''
# DenseNet-B
class Bottleneck(nn.Layer):
def __init__(self, nChannels, growthRate, use_dropout):
super(Bottleneck, self).__init__()
interChannels = 4 * growthRate
self.bn1 = nn.BatchNorm2D(interChannels)
self.conv1 = nn.Conv2D(nChannels, interChannels, kernel_size=1, bias_attr=None)
self.bn2 = nn.BatchNorm2D(growthRate)
self.conv2 = nn.Conv2D(interChannels, growthRate, kernel_size=3, padding=1, bias_attr=None)
self.use_dropout = use_dropout
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
if self.use_dropout:
out = self.dropout(out)
out = F.relu(self.bn2(self.conv2(out)))
if self.use_dropout:
out = self.dropout(out)
out = paddle.concat([x, out], 1)
return out
# single layer
class SingleLayer(nn.Layer):
def __init__(self, nChannels, growthRate, use_dropout):
super(SingleLayer, self).__init__()
self.bn1 = nn.BatchNorm2D(nChannels)
self.conv1 = nn.Conv2D(nChannels, growthRate, kernel_size=3, padding=1, bias_attr=False)
self.use_dropout = use_dropout
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
out = self.conv1(F.relu(x))
if self.use_dropout:
out = self.dropout(out)
out = paddle.concat([x, out], 1)
return out
# transition layer
class Transition(nn.Layer):
def __init__(self, nChannels, nOutChannels, use_dropout):
super(Transition, self).__init__()
self.bn1 = nn.BatchNorm2D(nOutChannels)
self.conv1 = nn.Conv2D(nChannels, nOutChannels, kernel_size=1, bias_attr=False)
self.use_dropout = use_dropout
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
if self.use_dropout:
out = self.dropout(out)
out = F.avg_pool2d(out, 2, ceil_mode=True,exclusive=False)
return out
class DenseNet(nn.Layer):
def __init__(self, params):
super(DenseNet, self).__init__()
# ratio: 16
# growthRate: 24
# reduction: 0.5
growthRate = params['densenet']['growthRate']
reduction = params['densenet']['reduction']
bottleneck = params['densenet']['bottleneck']
use_dropout = params['densenet']['use_dropout']
nDenseBlocks = 16
nChannels = 2 * growthRate
self.conv1 = nn.Conv2D(params['encoder']['input_channel'], nChannels, kernel_size=7, padding=3, stride=2, bias_attr=False)
self.dense1 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout)
nChannels += nDenseBlocks * growthRate
nOutChannels = int(math.floor(nChannels * reduction))
self.trans1 = Transition(nChannels, nOutChannels, use_dropout)
nChannels = nOutChannels
self.dense2 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout)
nChannels += nDenseBlocks * growthRate
nOutChannels = int(math.floor(nChannels * reduction))
self.trans2 = Transition(nChannels, nOutChannels, use_dropout)
nChannels = nOutChannels
self.dense3 = self._make_dense(nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout)
def _make_dense(self, nChannels, growthRate, nDenseBlocks, bottleneck, use_dropout):
layers = []
for i in range(int(nDenseBlocks)):
if bottleneck:
layers.append(Bottleneck(nChannels, growthRate, use_dropout))
else:
layers.append(SingleLayer(nChannels, growthRate, use_dropout))
nChannels += growthRate
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = F.relu(out)
out = F.max_pool2d(out, 2, ceil_mode=True)
out = self.dense1(out)
out = self.trans1(out)
out = self.dense2(out)
out = self.trans2(out)
out = self.dense3(out)
return out
2.1.2 multi-scale counting Module (MSCM)模块复现
class ChannelAtt(nn.Layer):
def __init__(self, channel, reduction):
super(ChannelAtt, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2D(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel//reduction),
nn.ReLU(),
nn.Linear(channel//reduction, channel),
nn.Sigmoid())
def forward(self, x):
b, c, _, _ = x.shape
y = paddle.reshape(self.avg_pool(x),[b,c])
y = paddle.reshape(self.fc(y),[b,c,1,1])
return x * y
class CountingDecoder(nn.Layer):
'''
多尺度计数模块
'''
def __init__(self, in_channel, out_channel, kernel_size):
super(CountingDecoder, self).__init__()
self.in_channel = in_channel
self.out_channel = out_channel
self.trans_layer = nn.Sequential(
nn.Conv2D(self.in_channel, 512, kernel_size=kernel_size, padding=kernel_size//2, bias_attr=False),
nn.BatchNorm2D(512))
self.channel_att = ChannelAtt(512, 16)
self.pred_layer = nn.Sequential(
nn.Conv2D(512, self.out_channel, kernel_size=1, bias_attr=False),
nn.Sigmoid())
def forward(self, x, mask):
b, c, h, w = x.shape
x = self.trans_layer(x)
x = self.channel_att(x)
x = self.pred_layer(x)
if mask is not None:
x = x * mask
x = paddle.reshape(x,[b,self.out_channel, -1])
x1 = paddle.sum(x, axis=-1)
return x1,paddle.reshape(x,[b, self.out_channel, h, w])
2.1.3 counting-combined attentional decoder(CCAD)模块复现
class Attention(nn.Layer):
def __init__(self, params):
super(Attention, self).__init__()
self.params = params
# hidden_size :256
self.hidden = params['decoder']['hidden_size']
# attention_dim :512
self.attention_dim = params['attention']['attention_dim']
self.hidden_weight = nn.Linear(self.hidden, self.attention_dim)
# spatial attention
self.attention_conv = nn.Conv2D(1, 512, kernel_size=11, padding=5, bias_attr=False)
self.attention_weight = nn.Linear(512, self.attention_dim, bias_attr=False)
self.alpha_convert = nn.Linear(self.attention_dim, 1 )
def forward(self, cnn_features, cnn_features_trans, hidden, alpha_sum, image_mask=None):
query = self.hidden_weight(hidden)
alpha_sum_trans = self.attention_conv(alpha_sum)
coverage_alpha = self.attention_weight(paddle.transpose(alpha_sum_trans,[0,2,3,1]))
alpha_score = paddle.tanh(paddle.unsqueeze(query,[1, 2]) + coverage_alpha + paddle.transpose(cnn_features_trans,[0,2,3,1]))
energy = self.alpha_convert(alpha_score)
energy = energy - energy.max()
energy_exp = paddle.exp(paddle.squeeze(energy,-1))
if image_mask is not None:
energy_exp = energy_exp * paddle.squeeze(image_mask,1)
alpha = energy_exp / (paddle.unsqueeze(paddle.sum(paddle.sum(energy_exp,-1),-1),[1,2]) + 1e-10)
alpha_sum = paddle.unsqueeze(alpha,1) + alpha_sum
context_vector = paddle.sum(paddle.sum((paddle.unsqueeze(alpha,1) * cnn_features),-1),-1)
return context_vector, alpha, alpha_sum
class PositionEmbeddingSine(nn.Layer):
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, x, mask):
y_embed = paddle.cumsum(mask,1, dtype='float32')
x_embed = paddle.cumsum(mask,2, dtype='float32')
if self.normalize:
eps = 1e-6
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale
dim_t = paddle.arange(self.num_pos_feats, dtype='float32')
dim_d = paddle.expand(paddle.to_tensor(2), dim_t.shape)
dim_t = self.temperature ** (2 * (dim_t / dim_d).astype('int64') / self.num_pos_feats)
pos_x = paddle.unsqueeze(x_embed,[3]) / dim_t
pos_y = paddle.unsqueeze(y_embed,[3]) / dim_t
pos_x = paddle.flatten(paddle.stack([paddle.sin(pos_x[:, :, :, 0::2]), paddle.cos(pos_x[:, :, :, 1::2])], axis=4),3)
pos_y = paddle.flatten(paddle.stack([paddle.sin(pos_y[:, :, :, 0::2]), paddle.cos(pos_y[:, :, :, 1::2])], axis=4),3)
pos = paddle.transpose(paddle.concat([pos_y, pos_x], axis=3),[0, 3, 1, 2])
return pos
class AttDecoder(nn.Layer):
def __init__(self, params):
super(AttDecoder, self).__init__()
self.params = params
self.input_size = params['decoder']['input_size']
self.hidden_size = params['decoder']['hidden_size']
self.out_channel = params['encoder']['out_channel']
self.attention_dim = params['attention']['attention_dim']
self.dropout_prob = params['dropout']
self.device = params['device']
self.ratio = params['densenet']['ratio']
self.word_num = params['word_num']
self.counting_num = params['counting_decoder']['out_channel']
paddle.device.set_device(self.device)
# init hidden state
self.init_weight = nn.Linear(self.out_channel, self.hidden_size)
self.embedding = nn.Embedding(self.word_num, self.input_size)
# word gru
self.word_input_gru = nn.GRUCell(self.input_size, self.hidden_size)
# attention
self.word_attention = Attention(params)
self.encoder_feature_conv = nn.Conv2D(self.out_channel, self.attention_dim,
kernel_size=params['attention']['word_conv_kernel'],
padding=params['attention']['word_conv_kernel']//2)
self.word_state_weight = nn.Linear(self.hidden_size, self.hidden_size)
self.word_embedding_weight = nn.Linear(self.input_size, self.hidden_size)
self.word_context_weight = nn.Linear(self.out_channel, self.hidden_size)
self.counting_context_weight = nn.Linear(self.counting_num, self.hidden_size)
self.word_convert = nn.Linear(self.hidden_size, self.word_num)
if params['dropout']:
self.dropout = nn.Dropout(params['dropout_ratio'])
def forward(self, cnn_features, labels, counting_preds, images_mask, labels_mask, is_train=True):
batch_size, num_steps = labels.shape # b, t
height, width = cnn_features.shape[2:]
word_probs = paddle.zeros((batch_size, num_steps, self.word_num))
images_mask = images_mask[:, :, ::self.ratio, ::self.ratio]
word_alpha_sum = paddle.zeros((batch_size, 1, height, width))
word_alphas = paddle.zeros((batch_size, num_steps, height, width))
hidden = self.init_hidden(cnn_features, images_mask)
counting_context_weighted = self.counting_context_weight(counting_preds)
cnn_features_trans = self.encoder_feature_conv(cnn_features)
position_embedding = PositionEmbeddingSine(256, normalize=True)
pos= position_embedding(cnn_features_trans, images_mask[:,0,:,:])
cnn_features_trans = cnn_features_trans + pos
if is_train:
for i in range(num_steps):
word_embedding = self.embedding(labels[:, i-1]) if i else self.embedding(paddle.ones([batch_size], dtype='int64'))
_, hidden = self.word_input_gru(word_embedding, hidden)
word_context_vec, word_alpha, word_alpha_sum = self.word_attention(cnn_features, cnn_features_trans, hidden,word_alpha_sum, images_mask)
current_state = self.word_state_weight(hidden)
word_weighted_embedding = self.word_embedding_weight(word_embedding)
word_context_weighted = self.word_context_weight(word_context_vec)
if self.params['dropout']:
word_out_state = self.dropout(current_state + word_weighted_embedding + word_context_weighted + counting_context_weighted)
else:
word_out_state = current_state + word_weighted_embedding + word_context_weighted + counting_context_weighted
word_prob = self.word_convert(word_out_state)
word_probs[:, i] = word_prob
word_alphas[:, i] = word_alpha
else:
word_embedding = self.embedding(paddle.ones([batch_size], dtype='int64'))
for i in range(num_steps):
hidden = self.word_input_gru(word_embedding, hidden)
word_context_vec, word_alpha, word_alpha_sum = self.word_attention(cnn_features, cnn_features_trans, hidden,word_alpha_sum, images_mask)
current_state = self.word_state_weight(hidden)
word_weighted_embedding = self.word_embedding_weight(word_embedding)
word_context_weighted = self.word_context_weight(word_context_vec)
if self.params['dropout']:
word_out_state = self.dropout(current_state + word_weighted_embedding + word_context_weighted + counting_context_weighted)
else:
word_out_state = current_state + word_weighted_embedding + word_context_weighted + counting_context_weighted
word_prob = self.word_convert(word_out_state)
word = word_prob.argmax(1)
word_embedding = self.embedding(word)
word_probs[:, i] = word_prob
word_alphas[:, i] = word_alpha
return word_probs, word_alphas
def init_hidden(self, features, feature_mask):
average = paddle.sum(paddle.sum(features * feature_mask,axis=-1),axis=-1) /paddle.sum((paddle.sum(feature_mask,axis=-1)),axis=-1)
average = self.init_weight(average)
return paddle.tanh(average)
2.1.4 CAN组网复现
class CAN(nn.Layer):
def __init__(self, params=None):
super(CAN, self).__init__()
self.params = params
self.use_label_mask = params['use_label_mask']
# backbone
self.encoder = DenseNet(params=self.params)
# decoder
self.in_channel = params['counting_decoder']['in_channel']
self.out_channel = params['counting_decoder']['out_channel']
# mscm
self.counting_decoder1 = CountingDecoder(self.in_channel, self.out_channel, 3)
self.counting_decoder2 = CountingDecoder(self.in_channel, self.out_channel, 5)
self.decoder = AttDecoder(self.params)
self.ratio = params['densenet']['ratio']
def forward(self, images, images_mask, labels, labels_mask, is_train=True):
cnn_features = self.encoder(images)
counting_mask = images_mask[:, :, ::self.ratio, ::self.ratio]
counting_preds1, _ = self.counting_decoder1(cnn_features, counting_mask)
counting_preds2, _ = self.counting_decoder2(cnn_features, counting_mask)
counting_preds = (counting_preds1 + counting_preds2) / 2
word_probs, word_alphas = self.decoder(cnn_features, labels, counting_preds, images_mask, labels_mask, is_train=is_train)
return word_probs, counting_preds, counting_preds1, counting_preds2
2.1.5 CAN损失函数复现
import paddle
import paddle.nn as nn
import numpy as np
def gen_counting_label(labels, channel, tag):
b , t =labels.shape
counting_labels = np.zeros([b, channel])
if tag:
ignore = [0, 1, 107, 108, 109, 110]
else:
ignore = []
for i in range(b):
for j in range(t):
k = labels[i][j]
if k in ignore:
continue
else:
counting_labels[i][k] += 1
counting_labels = paddle.to_tensor(counting_labels,dtype='float32')
return counting_labels
class CANLoss(nn.Layer):
'''
CAN的loss由两部分组成
word_average_loss:模型输出的符号准确率
counting_loss:每类符号的计数损失
'''
def __init__(self, params=None):
super(CANLoss, self).__init__()
self.use_label_mask = params['use_label_mask']
self.out_channel = params['counting_decoder']['out_channel']
self.cross = nn.CrossEntropyLoss(reduction='none') if self.use_label_mask else nn.CrossEntropyLoss()
self.counting_loss = nn.SmoothL1Loss(reduction='mean')
self.ratio = params['densenet']['ratio']
def forward(self, labels, labels_mask,word_probs, counting_preds, counting_preds1, counting_preds2):
counting_labels = gen_counting_label(labels, self.out_channel, True)
counting_loss = self.counting_loss(counting_preds1, counting_labels) + self.counting_loss(counting_preds2, counting_labels) \
+ self.counting_loss(counting_preds, counting_labels)
word_loss = self.cross(paddle.reshape(word_probs,[-1, word_probs.shape[-1]]), paddle.reshape(labels,[-1]))
word_average_loss = paddle.sum(paddle.reshape(word_loss * labels_mask,[-1])) / (paddle.sum(labels_mask) + 1e-10) if self.use_label_mask else word_loss
return word_average_loss, counting_loss
2.2 数据预处理,数据读取
# 数据处理代码块
import paddle.vision.transforms as transforms
import numpy as np
import os, json, random
import PIL.Image as Image
from paddle.io import Dataset, DistributedBatchSampler, DataLoader
class Words:
def __init__(self, word_path):
with open(word_path) as f:
words = f.readlines()
print(f'共 {len(words)} 类符号。')
self.words_dict = {words[i].strip(): i for i in range(len(words))}
self.words_index_dict = {i: words[i].strip()
for i in range(len(words))}
def __len__(self):
return len(self.words_dict)
# 字符映射至索引
def encode(self, labels):
label_index = [self.words_dict[item] for item in labels]
return label_index
# 索引映射至字符
def decode(self, label_index):
label = ' '.join([self.words_index_dict[int(item)]
for item in label_index])
return label
# 数据集类
class HMERDataset(Dataset):
def __init__(self, image_path, label_path, words, is_train=True, use_aug=False):
super(HMERDataset, self).__init__()
self.data_dir = image_path
self.data_lines = self.get_image_info_list(label_path)
self.data_idx_order_list = list(range(len(self.data_lines)))
self.words = words
def get_image_info_list(self, file_list):
if isinstance(file_list, str):
file_list = [file_list]
data_lines = []
for idx, file in enumerate(file_list):
with open(file, "rb") as f:
lines = f.readlines()
data_lines.extend(lines)
return data_lines
def __len__(self):
return len(self.data_idx_order_list)
def __getitem__(self, idx):
file_idx = self.data_idx_order_list[idx]
data_line = self.data_lines[file_idx]
data_line = data_line.decode('utf-8')
substr = data_line.strip("\n").split('\t')
file_name = substr[0]
label = substr[1]
label = np.array(self.words.encode(label.split()))
img_path = os.path.join(self.data_dir, file_name)
if not os.path.exists(img_path):
raise Exception("{} does not exist!".format(img_path))
image = np.array(Image.open(img_path))
image = np.expand_dims((255-image)/255,axis=0)
return image, label
# 数据集加载前预处理(batch内统一尺寸)
def collate_fn(batch_images):
max_width, max_height, max_length = 0, 0, 0
batch, channel = len(batch_images), batch_images[0][0].shape[0]
proper_items = []
for item in batch_images:
if item[0].shape[1] * max_width > 1600 * 320 or item[0].shape[2] * max_height > 1600 * 320:
continue
max_height = item[0].shape[1] if item[0].shape[1] > max_height else max_height
max_width = item[0].shape[2] if item[0].shape[2] > max_width else max_width
max_length = item[1].shape[0] if item[1].shape[0] > max_length else max_length
proper_items.append(item)
images, image_masks = np.zeros((len(proper_items), channel, max_height, max_width)), np.zeros(
(len(proper_items), 1, max_height, max_width))
labels, labels_masks = np.zeros((len(proper_items), max_length), dtype='int64'), np.zeros(
(len(proper_items), max_length))
for i in range(len(proper_items)):
_, h, w = proper_items[i][0].shape
images[i][:, :h, :w] = proper_items[i][0]
image_masks[i][:, :h, :w] = 1
l = proper_items[i][1].shape[0]
labels[i][:l] = proper_items[i][1]
labels_masks[i][:l] = 1
return images, image_masks, labels, labels_masks
collate_fn_dict = {'collate_fn': collate_fn}
# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
!ls /home/aistudio/data
# 根据数据集目录提取数据
!unzip -d /home/aistudio/data/data174727 /home/aistudio/data/data174727/CROHME.zip
data174727
Archive: /home/aistudio/data/data174727/CROHME.zip
creating: /home/aistudio/data/data174727/CROHME/
creating: /home/aistudio/data/data174727/CROHME/evaluation/
creating: /home/aistudio/data/data174727/CROHME/evaluation/images/
inflating: /home/aistudio/data/data174727/CROHME/evaluation/images/18_em_0.jpg
inflating: /home/aistudio/data/data174727/CROHME/evaluation/images/18_em_1.jpg
inflating: /home/aistudio/data/data174727/CROHME/evaluation/images/18_em_10.jpg
inflating: /home/aistudio/data/data174727/CROHME/evaluation/images/18_em_11.jpg
batch_size = 8
word_path = '/home/aistudio/data/data174727/CROHME/words_dict.txt'
train_image_path = '/home/aistudio/data/data174727/CROHME/training/images/'
train_label_path = '/home/aistudio/data/data174727/CROHME/training/labels.txt'
eval_image_path = '/home/aistudio/data/data174727/CROHME/evaluation/images/'
eval_label_path = '/home/aistudio/data/data174727/CROHME/evaluation/labels.txt'
words = Words(word_path)
print(f"训练数据路径 images: {train_image_path} labels: {train_label_path}")
print(f"验证数据路径 images: {eval_image_path} labels: {eval_label_path}")
train_dataset = HMERDataset(train_image_path, train_label_path, words, is_train=True)
eval_dataset = HMERDataset(eval_image_path, eval_label_path, words, is_train=False)
# 构造采样器,支持单机多卡情形
train_sampler = DistributedBatchSampler(dataset=train_dataset, batch_size=batch_size, shuffle=True,drop_last=False)
eval_sampler = DistributedBatchSampler(dataset=eval_dataset, batch_size=1, shuffle=True, drop_last=False)
train_loader = DataLoader(train_dataset, batch_sampler=train_sampler,
num_workers=1, collate_fn=collate_fn_dict['collate_fn'])
eval_loader = DataLoader(eval_dataset, batch_sampler=eval_sampler,
num_workers=1, collate_fn=collate_fn_dict['collate_fn'])
print(f'train dataset: {len(train_dataset)} train steps: {len(train_loader)} '
f'eval dataset: {len(eval_dataset)} eval steps: {len(eval_loader)} ')
共 111 类符号。
训练数据路径 images: /home/aistudio/data/data174727/CROHME/training/images/ labels: /home/aistudio/data/data174727/CROHME/training/labels.txt
验证数据路径 images: /home/aistudio/data/data174727/CROHME/evaluation/images/ labels: /home/aistudio/data/data174727/CROHME/evaluation/labels.txt
train dataset: 8835 train steps: 1105 eval dataset: 986 eval steps: 986
2.4 模型训练(包含模型优化器配置,超参数等)
# 模型训练
import os, time, random, datetime, argparse, yaml
import paddle
import numpy as np
from visualdl import LogWriter
# 加载config文件
def load_config(yaml_path):
try:
with open(yaml_path, 'r') as f:
params = yaml.load(f, Loader=yaml.FullLoader)
except:
print('尝试UTF-8编码....')
with open(yaml_path, 'r', encoding='UTF-8') as f:
params = yaml.load(f, Loader=yaml.FullLoader)
if not params['experiment']:
print('实验名不能为空!')
exit(-1)
if not params['train_image_path']:
print('训练图片路径不能为空!')
exit(-1)
if not params['train_label_path']:
print('训练label路径不能为空!')
exit(-1)
if not params['word_path']:
print('word dict路径不能为空!')
exit(-1)
if 'train_parts' not in params:
params['train_parts'] = 1
if 'valid_parts' not in params:
params['valid_parts'] = 1
if 'valid_start' not in params:
params['valid_start'] = 0
if 'word_conv_kernel' not in params['attention']:
params['attention']['word_conv_kernel'] = 1
return params
config_file = 'config.yaml'
params = load_config(config_file)
# 设置全局随机种子
random.seed(params['seed'])
np.random.seed(params['seed'])
paddle.seed(params['seed'])
# 设置计算设备
params['device'] = 'gpu:0'
paddle.device.set_device(params['device'])
Place(gpu:0)
# 创建模型
print("Creating model")
model = CAN(params)
now = time.strftime("%Y-%m-%d-%H-%M", time.localtime())
model.name = f'{params["experiment"]}_{now}_decoder-{params["decoder"]["net"]}'
# 创建可视化日志工具
from visualdl import LogWriter
writer = LogWriter(f'{params["log_dir"]}/{model.name}')
Creating model
# 构建学习率调参方法
import math
from paddle.optimizer.lr import *
class TwoStepCosineDecay(LRScheduler):
def __init__(self,
learning_rate,
T_max1,
T_max2,
eta_min=0,
last_epoch=-1,
verbose=False):
if not isinstance(T_max1, int):
raise TypeError(
"The type of 'T_max1' in 'CosineAnnealingDecay' must be 'int', but received %s."
% type(T_max1))
if not isinstance(T_max2, int):
raise TypeError(
"The type of 'T_max2' in 'CosineAnnealingDecay' must be 'int', but received %s."
% type(T_max2))
if not isinstance(eta_min, (float, int)):
raise TypeError(
"The type of 'eta_min' in 'CosineAnnealingDecay' must be 'float, int', but received %s."
% type(eta_min))
assert T_max1 > 0 and isinstance(
T_max1, int), " 'T_max1' must be a positive integer."
assert T_max2 > 0 and isinstance(
T_max2, int), " 'T_max1' must be a positive integer."
self.T_max1 = T_max1
self.T_max2 = T_max2
self.eta_min = float(eta_min)
super(TwoStepCosineDecay, self).__init__(learning_rate, last_epoch,
verbose)
def get_lr(self):
if self.last_epoch <= self.T_max1:
if self.last_epoch == 0:
return self.base_lr
elif (self.last_epoch - 1 - self.T_max1) % (2 * self.T_max1) == 0:
return self.last_lr + (self.base_lr - self.eta_min) * (1 - math.cos(
math.pi / self.T_max1)) / 2
return (1 + math.cos(math.pi * self.last_epoch / self.T_max1)) / (
1 + math.cos(math.pi * (self.last_epoch - 1) / self.T_max1)) * (
self.last_lr - self.eta_min) + self.eta_min
else:
if (self.last_epoch - 1 - self.T_max2) % (2 * self.T_max2) == 0:
return self.last_lr + (self.base_lr - self.eta_min) * (1 - math.cos(
math.pi / self.T_max2)) / 2
return (1 + math.cos(math.pi * self.last_epoch / self.T_max2)) / (
1 + math.cos(math.pi * (self.last_epoch - 1) / self.T_max2)) * (
self.last_lr - self.eta_min) + self.eta_min
def _get_closed_form_lr(self):
if self.last_epoch <= self.T_max1:
return self.eta_min + (self.base_lr - self.eta_min) * (1 + math.cos(
math.pi * self.last_epoch / self.T_max1)) / 2
else:
return self.eta_min + (self.base_lr - self.eta_min) * (1 + math.cos(
math.pi * self.last_epoch / self.T_max2)) / 2
class TwoStepCosineLR(object):
def __init__(self,
learning_rate,
step_each_epoch,
epochs1,
epochs2,
warmup_epoch=0,
last_epoch=-1,
**kwargs):
super(TwoStepCosineLR, self).__init__()
self.learning_rate = learning_rate
self.T_max1 = step_each_epoch * epochs1
self.T_max2 = step_each_epoch * epochs2
self.last_epoch = last_epoch
self.warmup_epoch = round(warmup_epoch * step_each_epoch)
def __call__(self):
learning_rate = TwoStepCosineDecay(
learning_rate=self.learning_rate,
T_max1=self.T_max1,
T_max2=self.T_max2,
last_epoch=self.last_epoch)
if self.warmup_epoch > 0:
learning_rate = LinearWarmup(
learning_rate=learning_rate,
warmup_steps=self.warmup_epoch,
start_lr=0.0,
end_lr=self.learning_rate,
last_epoch=self.last_epoch)
return learning_rate
lr_scheduler = TwoStepCosineLR(float(params["lr"]),
len(train_loader),
200,
240,
warmup_epoch = 1,
last_epoch=-1)()
# 构建优化器
clip = paddle.nn.ClipGradByGlobalNorm(clip_norm=params['gradient'])
optimizer = paddle.optimizer.Momentum(
learning_rate=lr_scheduler,
momentum=0.9,
parameters=model.parameters(),
weight_decay=float(params['weight_decay']),
grad_clip=clip)
# 定义损失函数
criterion = CANLoss(params)
# 加载断点,继续训练
def load_checkpoint(model, optimizer, path):
state = paddle.load(path + '.pdparams')
model.set_state_dict(state)
if optimizer:
opt_state = paddle.load(path +'.pdopt')
optimizer.set_state_dict(opt_state)
if params['finetune']:
print('loading from pretrain')
load_checkpoint(model, optimizer, params['checkpoint'])
# 构建训练、验证方法
import time
import paddle
import sys
import cv2
import numpy as np
from difflib import SequenceMatcher
class Meter:
def __init__(self, alpha=0.9):
self.nums = []
self.exp_mean = 0
self.alpha = alpha
@property
def mean(self):
return np.mean(self.nums)
def add(self, num):
if len(self.nums) == 0:
self.exp_mean = num
self.nums.append(num)
self.exp_mean = self.alpha * self.exp_mean + (1 - self.alpha) * num
def cal_score(word_probs, word_label, mask):
line_right = 0
if word_probs is not None:
word_pred = word_probs.argmax(2)
word_scores = [SequenceMatcher(None, s1[:int(np.sum(s3))], s2[:int(np.sum(s3))], autojunk=False).ratio() * (
len(s1[:int(np.sum(s3))]) + len(s2[:int(np.sum(s3))])) / len(s1[:int(np.sum(s3))]) / 2
for s1, s2, s3 in zip(word_label.cpu().detach().numpy(), word_pred.cpu().detach().numpy(), mask.cpu().detach().numpy())]
batch_size = len(word_scores)
for i in range(batch_size):
if word_scores[i] == 1:
line_right += 1
ExpRate = line_right / batch_size
word_scores = np.mean(word_scores)
return word_scores, ExpRate
def train(model,criterion,optimizer,lr_scheduler,epoch,data_loader,writer = None):
model.train()
loss_meter = Meter()
train_reader_cost = 0.0
train_run_cost = 0.0
total_samples = 0
batch_past = 0
word_right = 0.0
exp_right = 0.0
length = 0.0
cal_num = 0.0
reader_start = time.time()
for batch_idx, (image, image_mask, label, label_mask) in enumerate(data_loader):
image = paddle.to_tensor(image,dtype='float32')
label = paddle.to_tensor(label, dtype='int64')
image_mask = paddle.to_tensor(image_mask, dtype='float32')
label_mask = paddle.to_tensor(label_mask, dtype='int64')
train_reader_cost += time.time() - reader_start
train_start = time.time()
batch_num, word_length = label.shape[:2]
lr_scheduler.step()
optimizer.clear_grad()
word_probs, counting_preds, counting_preds1, counting_preds2 = model(image, image_mask, label, label_mask)
word_loss, counting_loss = criterion(label, label_mask, word_probs, counting_preds, counting_preds1, counting_preds2)
loss = word_loss + counting_loss
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
train_run_cost += time.time() - train_start
wordRate, ExpRate = cal_score(word_probs, label, label_mask)
word_right = word_right + wordRate * word_length
exp_right = exp_right + ExpRate * batch_num
length = length + word_length
cal_num = cal_num + batch_num
total_samples += image.shape[0]
batch_past += 1
current_step = epoch * len(data_loader) + batch_idx + 1
msg = "[Epoch {}, iter: {}] wordRate: {:.5f}, expRate: {:.5f}, lr: {:.5f}, loss: {:.5f}, avg_reader_cost: {:.5f} sec, avg_batch_cost: {:.5f} sec, avg_samples: {}, avg_ips: {:.5f} images/sec.".format(
epoch+1, batch_idx +1, word_right / length, exp_right / cal_num,
optimizer.get_lr(),
loss.item(), train_reader_cost / batch_past,
(train_reader_cost + train_run_cost) / batch_past,
total_samples / batch_past,
total_samples / (train_reader_cost + train_run_cost))
print(msg)
sys.stdout.flush()
train_reader_cost = 0.0
train_run_cost = 0.0
total_samples = 0
batch_past = 0
reader_start = time.time()
writer.add_scalar(tag='epoch/train_loss', step=epoch + 1, value=loss_meter.mean)
writer.add_scalar(tag='epoch/train_WordRate', step=epoch + 1, value=word_right / length)
writer.add_scalar(tag='epoch/train_ExpRate', step=epoch + 1, value=exp_right / cal_num)
return loss_meter.mean, word_right / length, exp_right / cal_num
def evaluate(model, criterion, epoch, data_loader, writer=None):
loss_meter = Meter()
word_right = 0.0
exp_right = 0.0
length = 0.0
cal_num = 0.0
with paddle.no_grad():
model.eval()
for batch_idx, (image, image_mask, label, label_mask) in enumerate(data_loader):
image = paddle.to_tensor(image,dtype='float32')
label = paddle.to_tensor(label, dtype='int64')
image_mask = paddle.to_tensor(image_mask, dtype='float32')
label_mask = paddle.to_tensor(label_mask, dtype='int64')
batch_num, word_length = label.shape[:2]
word_probs, counting_preds, counting_preds1, counting_preds2 = model(image, image_mask, label, label_mask)
word_loss, counting_loss = criterion(label, label_mask, word_probs, counting_preds, counting_preds1, counting_preds2)
loss = word_loss + counting_loss
loss_meter.add(loss.item())
wordRate, ExpRate = cal_score(word_probs, label, label_mask)
word_right = word_right + wordRate * word_length
exp_right = exp_right + ExpRate * batch_num
length = length + word_length
cal_num = cal_num + batch_num
msg = "[Epoch {}, iter: {}] wordRate: {:.5f}, expRate: {:.5f}, word_loss: {:.5f}, counting_loss: {:.5f}".format(
epoch+1, batch_idx+1, word_right / length, exp_right / cal_num, word_loss.item(), counting_loss.item())
print(msg)
sys.stdout.flush()
writer.add_scalar(tag='epoch/eval_loss', step=epoch + 1, value=loss_meter.mean)
writer.add_scalar(tag='epoch/eval_WordRate', step=epoch + 1, value=word_right / length)
writer.add_scalar(tag='epoch/eval_ExpRate', step=epoch + 1, value=exp_right / len(data_loader.dataset))
return loss_meter.mean, word_right / length, exp_right / cal_num
# 开始训练
def save_checkpoint(model, optimizer, word_score, ExpRate_score, epoch, checkpoint_dir):
model_filename = f'{os.path.join(checkpoint_dir, model.name)}/{model.name}_WordRate-{word_score:.4f}_ExpRate-{ExpRate_score:.4f}_{epoch}.pdparams'
paddle.save(model.state_dict(),model_filename)
if optimizer:
opt_filename = f'{os.path.join(checkpoint_dir, model.name)}/{model.name}_WordRate-{word_score:.4f}_ExpRate-{ExpRate_score:.4f}_{epoch}.pdopt'
paddle.save(optimizer.state_dict(),opt_filename)
print(f'Save checkpoint: {epoch}\n')
min_score, init_epoch = 0, 0
start_time = time.time()
for epoch in range(init_epoch, params['epochs']):
print("Start training")
train_loss, train_word_score, train_exprate = train(model, criterion, optimizer, lr_scheduler, epoch, train_loader, writer = writer)
if epoch >= params['valid_start']:
print("Start evaluating")
# 验证本轮训练结果
eval_loss, eval_word_score, eval_exprate = evaluate(model, criterion, epoch, eval_loader, writer=writer)
print(f'Epoch: {epoch+1} loss: {eval_loss:.4f} word score: {eval_word_score:.4f} ExpRate: {eval_exprate:.4f}')
if eval_exprate > min_score and epoch >= params['save_start']:
min_score = eval_exprate
save_checkpoint(model, optimizer, eval_word_score, eval_exprate, epoch+1, params['checkpoint_dir'])
writer.close()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time {}'.format(total_time_str))
Start training
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/nn/layer/norm.py:654: UserWarning: When training, we now always track global mean and variance.
"When training, we now always track global mean and variance.")
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/math_op_patch.py:278: UserWarning: The dtype of left and right variables are not the same, left dtype is paddle.float32, but right dtype is paddle.int64, the right dtype will convert to paddle.float32
format(lhs_dtype, rhs_dtype, lhs_dtype))
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:17: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
[Epoch 1, iter: 1] wordRate: 0.01389, expRate: 0.00000, lr: 0.00001, loss: 621.42468, avg_reader_cost: 1.32856 sec, avg_batch_cost: 5.28179 sec, avg_samples: 8.0, avg_ips: 1.51464 images/sec.
[Epoch 1, iter: 2] wordRate: 0.04483, expRate: 0.00000, lr: 0.00002, loss: 872.62134, avg_reader_cost: 0.00081 sec, avg_batch_cost: 0.59160 sec, avg_samples: 8.0, avg_ips: 13.52261 images/sec.
[Epoch 1, iter: 3] wordRate: 0.02977, expRate: 0.00000, lr: 0.00003, loss: 348.43390, avg_reader_cost: 0.00076 sec, avg_batch_cost: 0.66045 sec, avg_samples: 8.0, avg_ips: 12.11297 images/sec.
[Epoch 1, iter: 4] wordRate: 0.02159, expRate: 0.00000, lr: 0.00004, loss: 678.26526, avg_reader_cost: 0.00076 sec, avg_batch_cost: 0.68001 sec, avg_samples: 8.0, avg_ips: 11.76461 images/sec.
[Epoch 1, iter: 5] wordRate: 0.02387, expRate: 0.00000, lr: 0.00005, loss: 199.29759, avg_reader_cost: 0.00079 sec, avg_batch_cost: 0.39971 sec, avg_samples: 8.0, avg_ips: 20.01429 images/sec.
…
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
/tmp/ipykernel_270/3362094701.py in <module>
11 for epoch in range(init_epoch, params['epochs']):
12 print("Start training")
---> 13 train_loss, train_word_score, train_exprate = train(model, criterion, optimizer, lr_scheduler, epoch, train_loader, writer = writer)
14 if epoch >= params['valid_start']:
15 print("Start evaluating")
/tmp/ipykernel_270/1862542379.py in train(model, criterion, optimizer, lr_scheduler, epoch, data_loader, writer)
61 word_loss, counting_loss = criterion(label, label_mask, word_probs, counting_preds, counting_preds1, counting_preds2)
62 loss = word_loss + counting_loss
---> 63 loss.backward()
64 optimizer.step()
65 loss_meter.add(loss.item())
<decorator-gen-249> in backward(self, grad_tensor, retain_graph)
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/wrapped_decorator.py in __impl__(func, *args, **kwargs)
23 def __impl__(func, *args, **kwargs):
24 wrapped_func = decorator_func(func)
---> 25 return wrapped_func(*args, **kwargs)
26
27 return __impl__
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py in __impl__(*args, **kwargs)
432 assert _non_static_mode(
433 ), "We only support '%s()' in dynamic graph mode, please call 'paddle.disable_static()' to enter dynamic graph mode." % func.__name__
--> 434 return func(*args, **kwargs)
435
436 return __impl__
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/varbase_patch_methods.py in backward(self, grad_tensor, retain_graph)
291 core.dygraph_run_backward([self], [grad_tensor],
292 retain_graph,
--> 293 framework._dygraph_tracer())
294 if in_profiler_mode():
295 record_event.end()
KeyboardInterrupt:
2.5 模型验证
#加载模型,并将模型文件名写入config.yaml,如"CAN_2022-09-12-21-24_decoder-AttDecoder_WordRate-0.9166_ExpRate-0.5172_201"
load_checkpoint(model, None, params['checkpoint'])
eval_loss, eval_word_score, eval_exprate = evaluate(model, criterion, 0, eval_loader, writer=writer)
print(f'Epoch: 0 loss: {eval_loss:.4f} word score: {eval_word_score:.4f} ExpRate: {eval_exprate:.4f}')
[Epoch 1, iter: 1] wordRate: 0.76923, expRate: 0.00000, word_loss: 1.39683, counting_loss: 0.06093
[Epoch 1, iter: 2] wordRate: 0.84000, expRate: 0.00000, word_loss: 0.10158, counting_loss: 0.01839
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:17: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.
[Epoch 1, iter: 3] wordRate: 0.80000, expRate: 0.00000, word_loss: 0.96282, counting_loss: 0.31501
[Epoch 1, iter: 4] wordRate: 0.87786, expRate: 0.25000, word_loss: 0.00473, counting_loss: 0.21619
[Epoch 1, iter: 5] wordRate: 0.88608, expRate: 0.20000, word_loss: 0.32554, counting_loss: 0.00933
[Epoch 1, iter: 6] wordRate: 0.90110, expRate: 0.33333, word_loss: 0.02151, counting_loss: 0.02723
[Epoch 1, iter: 7] wordRate: 0.88571, expRate: 0.28571, word_loss: 0.68410, counting_loss: 0.16471
[Epoch 1, iter: 8] wordRate: 0.88263, expRate: 0.25000, word_loss: 0.30230, counting_loss: 0.02236
[Epoch 1, iter: 9] wordRate: 0.89177, expRate: 0.33333, word_loss: 0.01814, counting_loss: 0.01104
[Epoch 1, iter: 10] wordRate: 0.89627, expRate: 0.40000, word_loss: 0.00337, counting_loss: 0.00578
[Epoch 1, iter: 11] wordRate: 0.89344, expRate: 0.36364, word_loss: 1.63371, counting_loss: 0.01715
[Epoch 1, iter: 12] wordRate: 0.90210, expRate: 0.33333, word_loss: 0.19470, counting_loss: 0.05584
[Epoch 1, iter: 13] wordRate: 0.89965, expRate: 0.30769, word_loss: 1.37756, counting_loss: 0.03847
[Epoch 1, iter: 14] wordRate: 0.90102, expRate: 0.35714, word_loss: 0.10300, counting_loss: 0.03011
[Epoch 1, iter: 15] wordRate: 0.89776, expRate: 0.33333, word_loss: 0.80881, counting_loss: 0.03043
......
[Epoch 1, iter: 985] wordRate: 0.90987, expRate: 0.51675, word_loss: 0.58685, counting_loss: 0.12471
[Epoch 1, iter: 986] wordRate: 0.90992, expRate: 0.51724, word_loss: 0.00277, counting_loss: 0.11260
Epoch: 0 loss: 0.4890 word score: 0.9099 ExpRate: 0.5172
3、 结果展示
3.1 实验结果
| NetWork | epochs | opt | batch_size | dataset | memory | card | ExpRate | weight | log |
|---|---|---|---|---|---|---|---|---|---|
| CAN | 220 | Momenta | 8 | CROHME | 32G | 1 | 51.72 | weight | log |
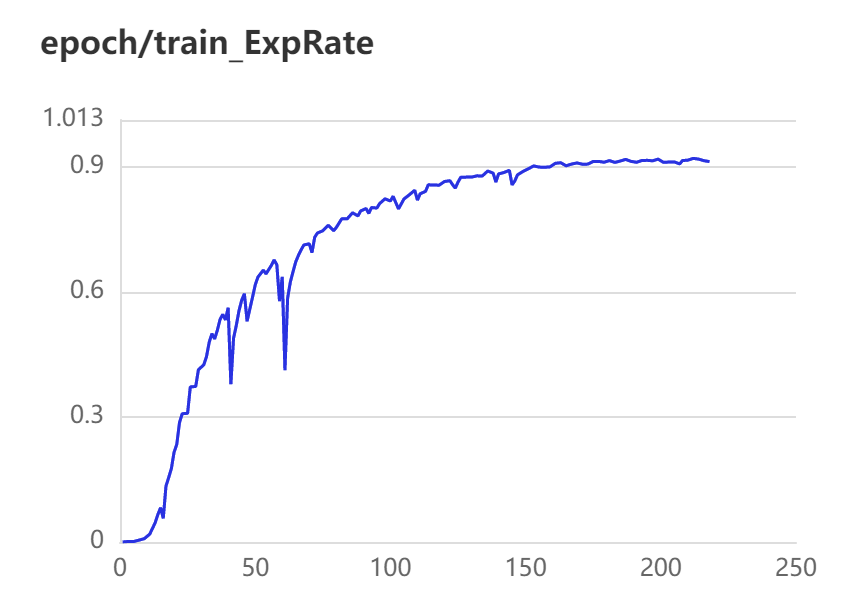
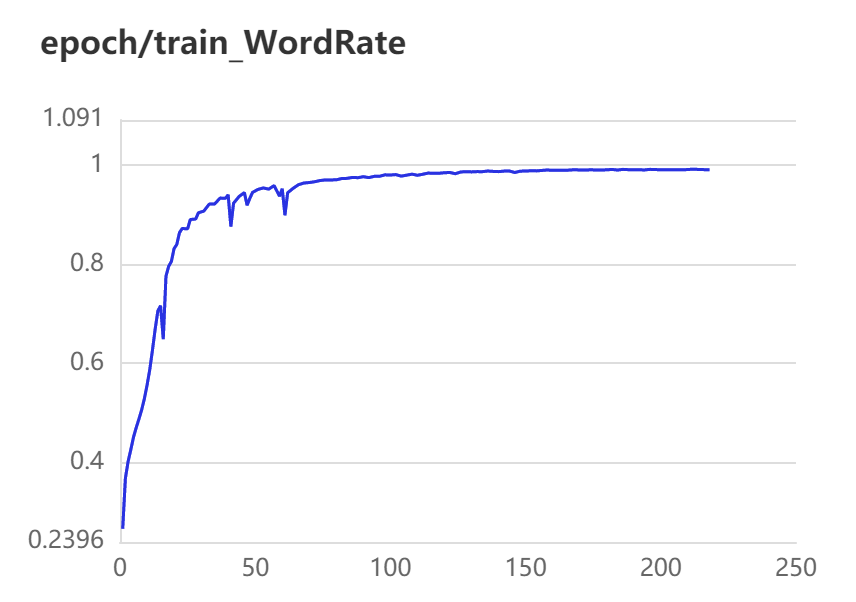
3.2 训练、验证可视化
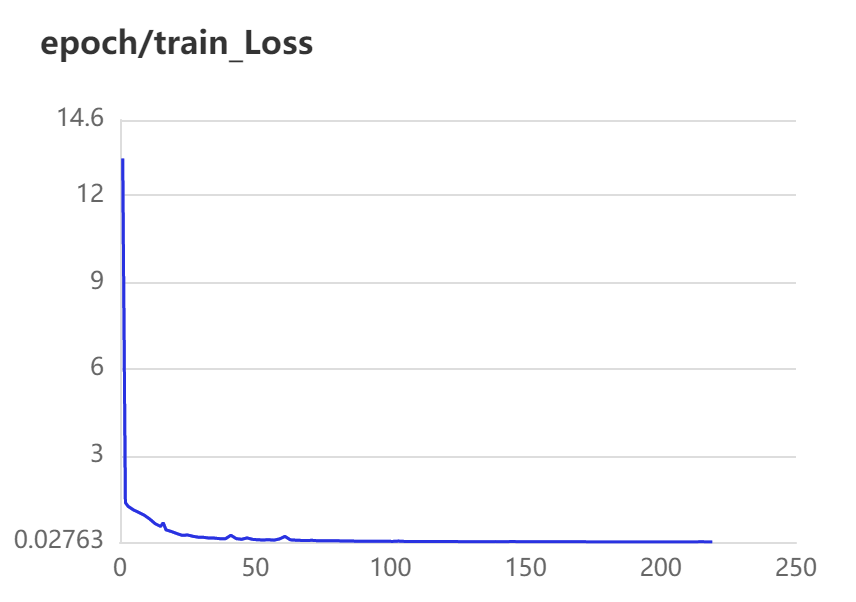
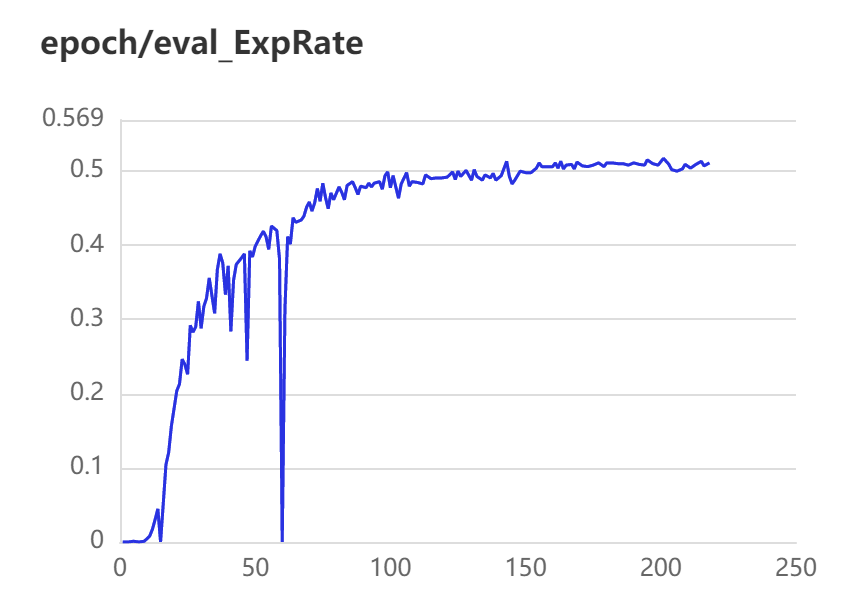
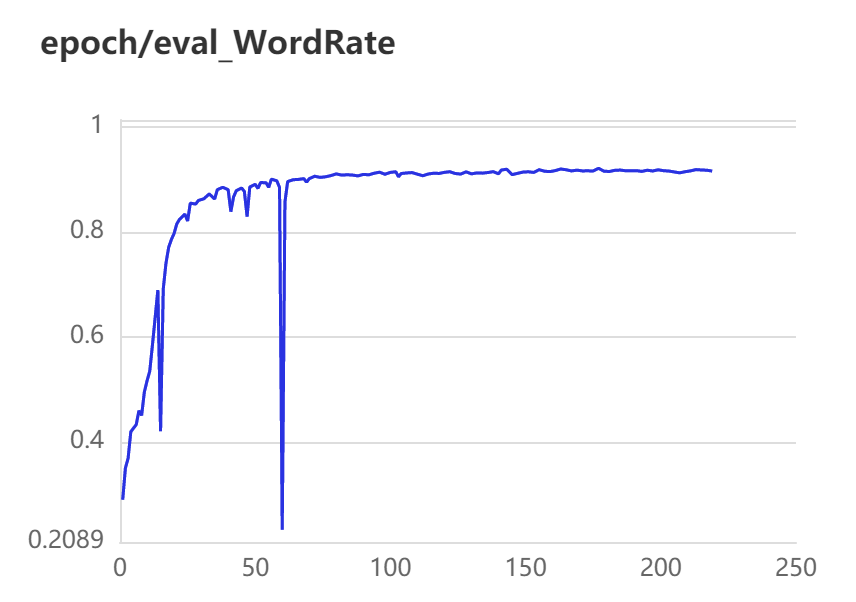
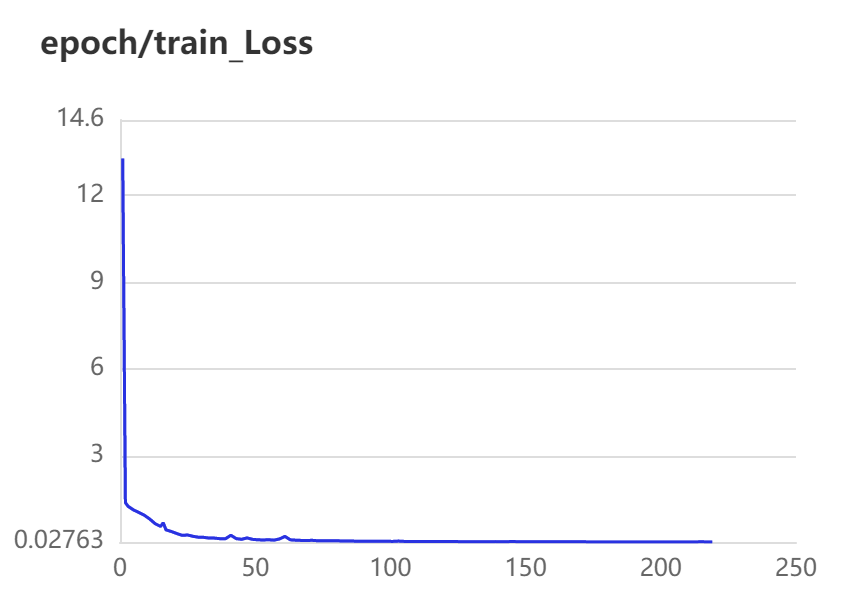
3.3 实验结果对比
| platform | epochs | opt | batch_size | ExpRate | WordRate |
|---|---|---|---|---|---|
| PaddlePaddle | 220 | Momenta | 8 | 51.72 | 90.99 |
| Pytorch | 240 | SGD | 8 | 50.20 | 88.05 |
3.4 训练、验证可视化对比
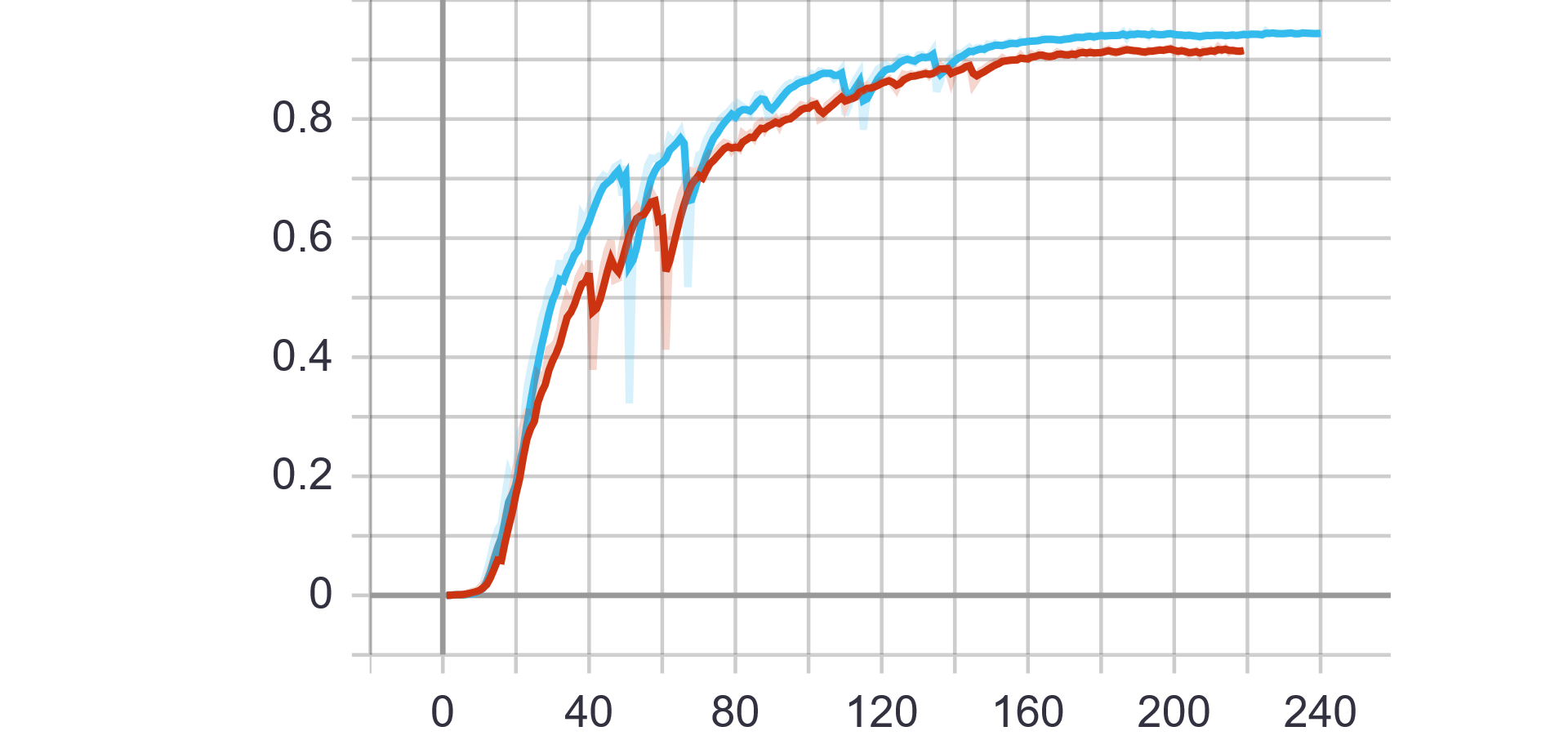
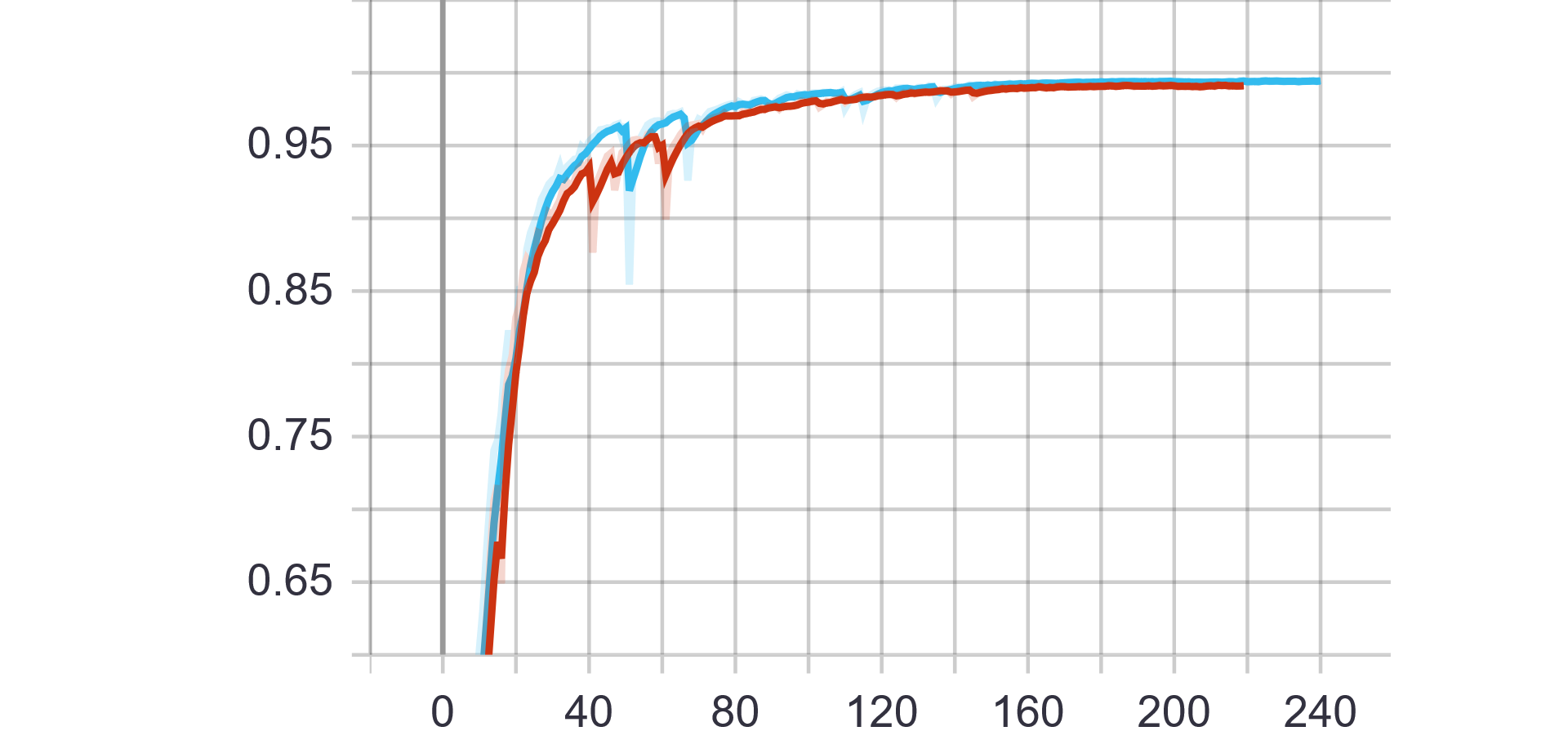
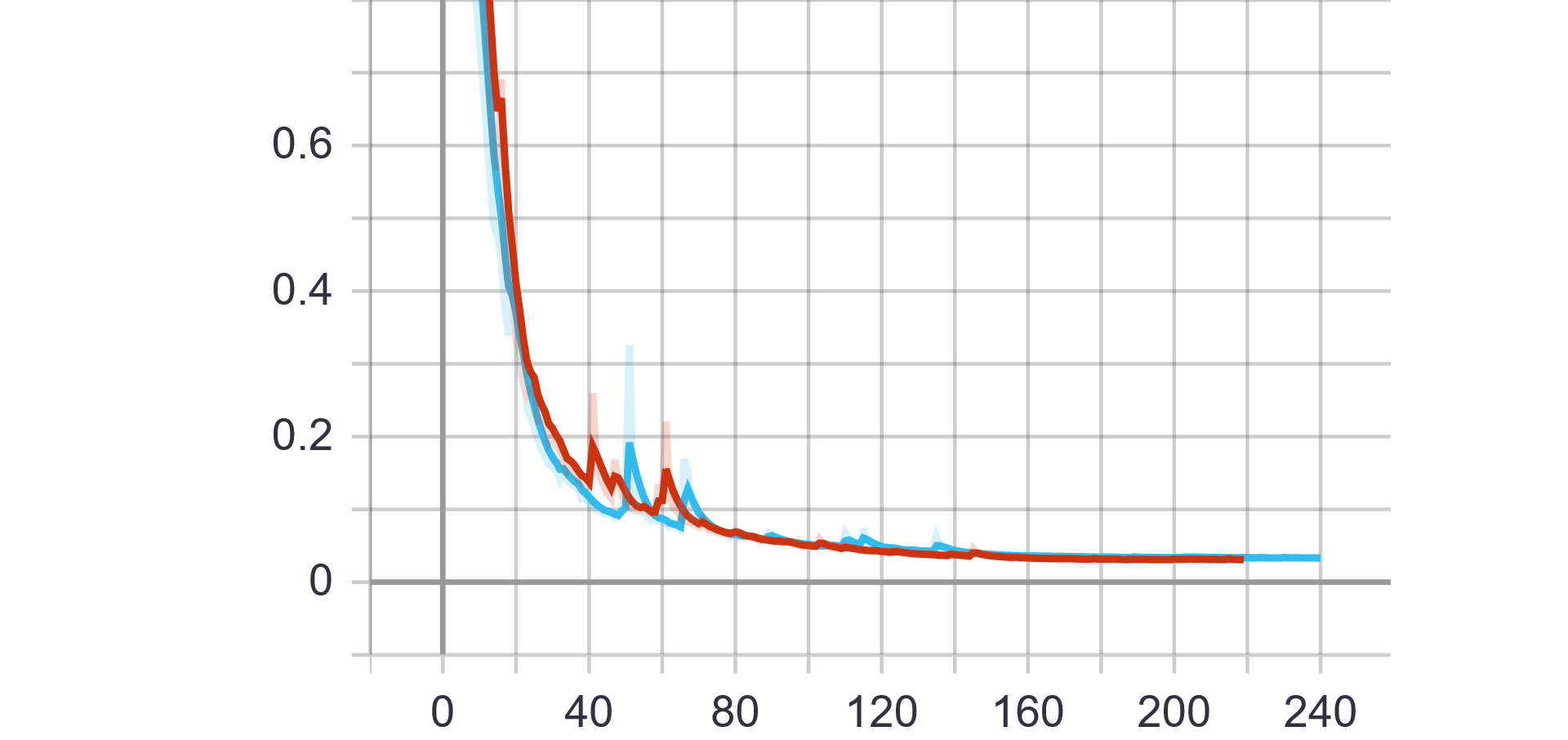
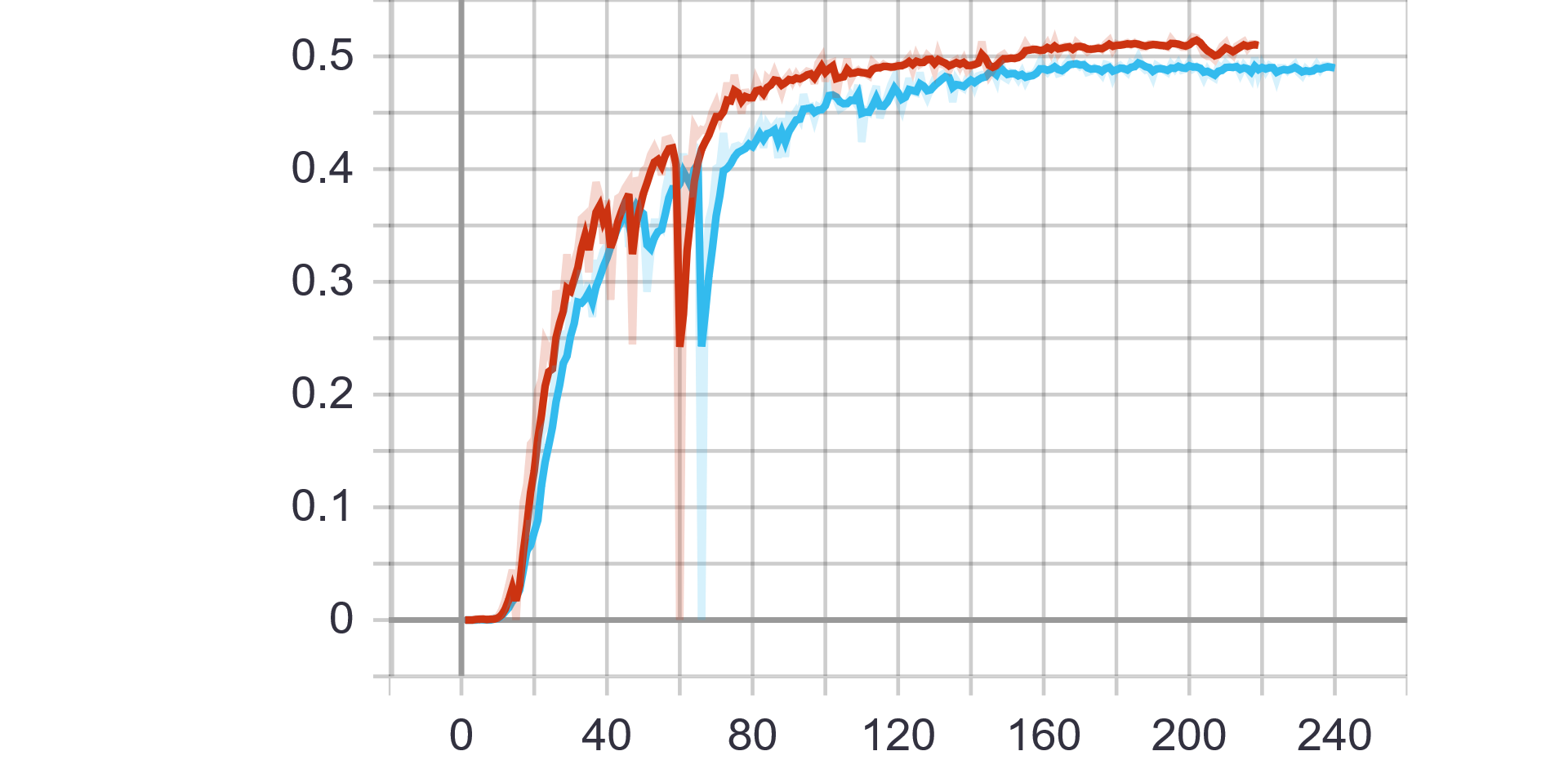
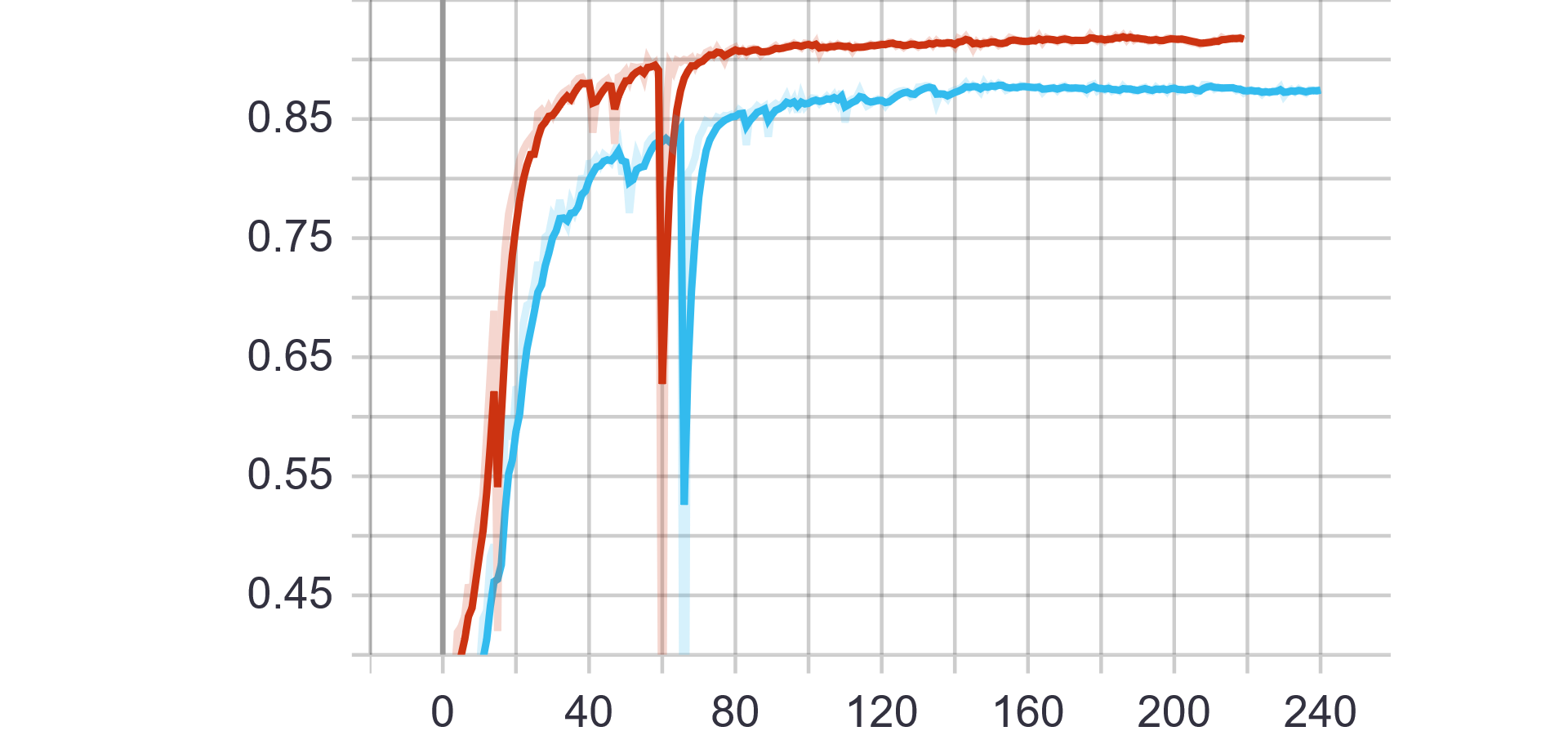
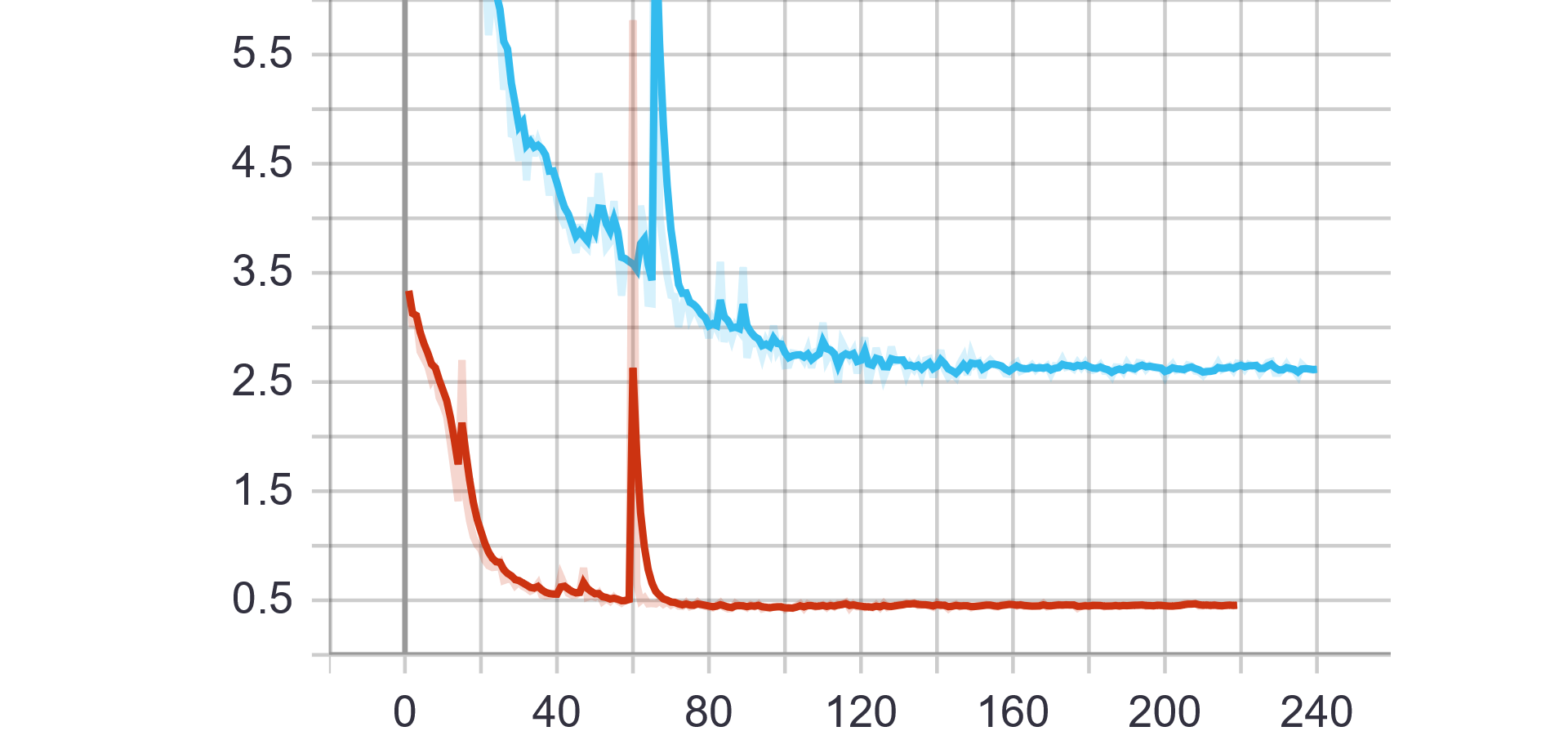
蓝色曲线为Pytorch训练所得结果,红色曲线为Paddle训练所得结果。
第一行为训练数据,从左到右依次为train ExpRate、train WordRate、train Loss
第二行为验证数据,从左到右依次为eval ExpRate、eval WordRate、eval Loss
Pytorch和Paddle训练均采用相同的参数,从验证结果可看出,基于Paddle的实验结果更优。
4、 总结
本项目使用paddle框架对模型对结合了计数模块的手写数学公式识别算法CAN进行了复现,在复现过程中主要积累了以下几条经验:
-
若复现模型出现前向、反向无法对齐的情况,应仔细对比Pytorch和Paddle关于组网的底层api实现的异同。
-
若复现模型出现精度无法对齐的情况,应仔细检查Pytorch和Paddle关于优化器、学习率等优化相关的底层api实现的异同。本论文默认优化器为Adadelta,然而Pytorch的Adadelta和Paddle存在实现差异,导致复现精度相差过大,后检查了Paddle和Pytorch的优化器相关底层源码,并采取了使用不同的初始化方式和不同的优化器进行消融实验取出精度最优的方案进行复现。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 6
6 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)