
手把手教你读推荐论文-SR-GNN
SR-GNN论文解读以及使用paddle复现SR-GNN
Session-based Recommendation with Graph Neural Networks
1.论文解读
论文链接:https://arxiv.org/abs/1811.00855
SR-GNN是中科院提出的一种基于会话序列建模的推荐系统,这里所谓的会话是指用户的交互过(每个会话表示一次用户行为和对应的服务,所以每个用户记录都会构建成一张图),这里说的会话序列应该是专门表示一个用户过往一段时间的交互序列。 基于会话的推荐是现在比较常用的一种推荐方式,比较常用的会话推荐包括 循环神经网络、马尔科夫链。但是这些常用的会话推荐方式有以下的两个缺点
- 当一个会话中用户的行为数量十分有限时【就是比较少时】,这种方法较难捕获用户的行为表示。比如使用RNN神经网络进行会话方式的推荐建模时,如果前面时序的动作项较少,会导致最后一个输出产生推荐项时,推荐的结果并不会怎么准确。
- 根据以往的工作发现,物品之前的转移模式在会话推荐中是十分重要的特征,但RNN和马尔科夫过程只对相邻的两个物品的单项转移向量进行 建模,而忽略了会话中其他的物品。【意思是RNN那种方式缺乏整体大局观,只构建了单项的转移向量,对信息的表达能力不够强】
首先在解读论文的时候,需要明白序列召回的输入和输出是什么,一般来说序列召回输入的是用户的行为序列(用户交互过的item id的列表),需要预测的是用户下一个时刻可能点击的top-k个item。那在实际操作的过程中,我们通常把用户的行为序列抽取成一个用户的表征向量,然后和Item的向量通过一些ANN的方法来进行快速的检索,从而筛选出和用户表征向量最相似的top-k个Item。我们下面介绍的SR-GNN就是完成了上述的两个流程
1.1 论文核心方法
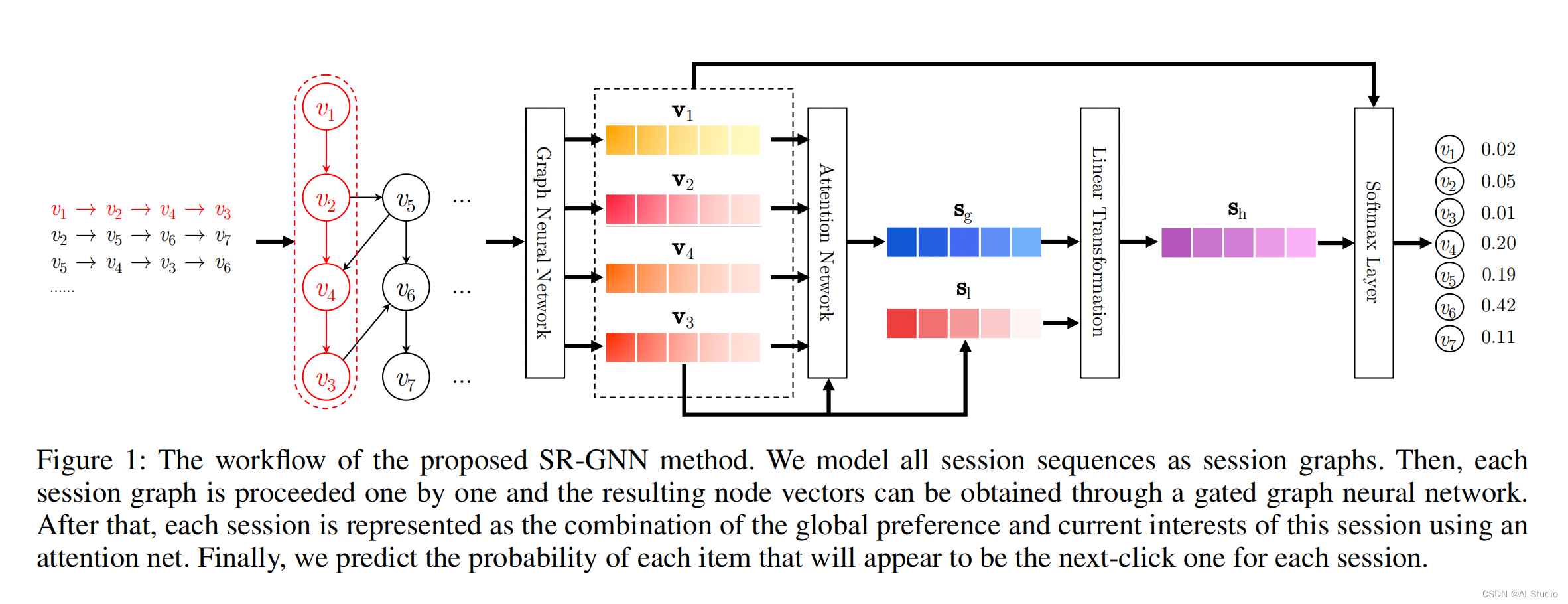
这里我们可以看到,我们对输入的用户的行为序列提取出用户的向量表征进行了如下的处理:
- 1.将用户的行为序列构造成 Session Graph
- 2.我们通过GNN来对所得的 Session Graph进行特征提取,得到每一个Item的向量表征
- 3.在经过GNN提取Session Graph之后,我们需要对所有的Item的向量表征进行融合,以此得到User的向量表征
在得到了用户的向量表征之后,我们就可以按照序列召回的思路来进行模型训练/模型验证了,下面我们来探讨这三个点如何展开
1.2 构建Session Graph
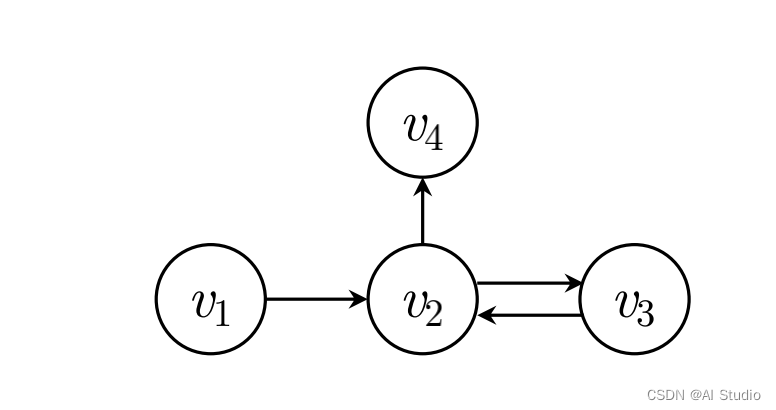
这里首先需要根据用户的行为序列来进行构图,这里是针对每一条用户的行为序列都需要构建一张图,构图的方法也非常简单,我们这里将其视作是有向图,如果 v 2 v_2 v2和 v 1 v_1 v1在用户的行为序列里面是相邻的,并且 v 2 v_2 v2在 v 1 v_1 v1之后,则我们连出一条从 v 2 v_2 v2到 v 1 v_1 v1的边,按照这个规则我们可以构建出一张图。(下面是论文中给的样例图)
在完成构图之后,我们需要使用变量来存储这张图,这里用 A s A_s As来表示构图的结果,这个矩阵是一个 ( d , 2 d ) (d,2d) (d,2d)的矩阵 ,其分为一个 ( d , d ) (d,d) (d,d)的Outing矩阵和一个 ( d , d ) (d,d) (d,d)的Incoming矩阵对于Outing矩阵,直接去数节点向外伸出去的边的条数,如果节点向外伸出的节点数大于1,则进行归一化操作(例如节点 v 2 v_2 v2向外伸出了两个节点 v 3 , v 4 v_3,v_4 v3,v4,则节点 v 2 v_2 v2到节点 v 3 , v 4 v_3,v_4 v3,v4的值都为0.5)。Incoming矩阵同理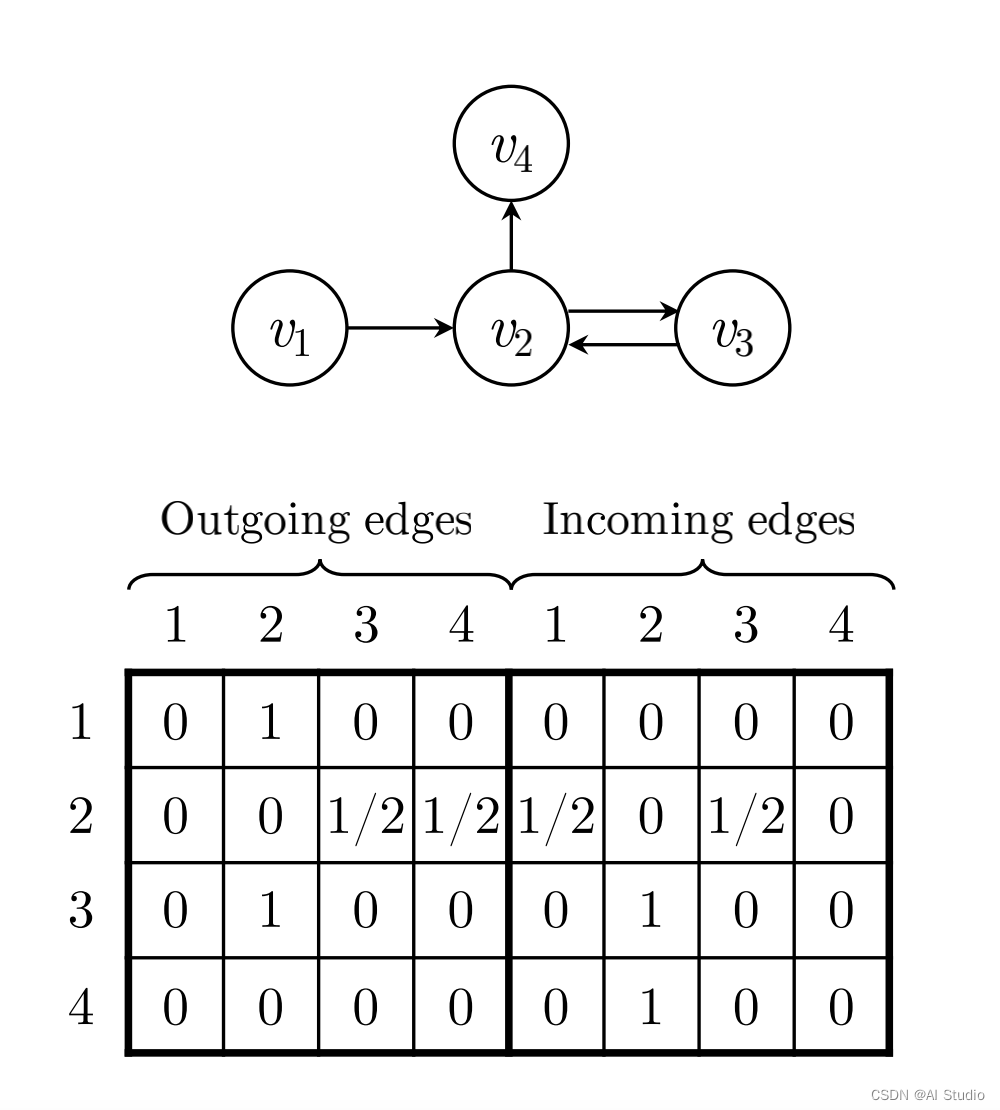
1.3 通过GNN学习Item的向量表征
这一部分我们主要关注如何从图中学习到Item的向量表征,这里设 v i t v_{i}^{t} vit表示在第t次GNN迭代后的item i的向量表征, A s , i ∈ R 1 × 2 n A_{s,i} \in R^{1 \times 2n} As,i∈R1×2n表示 A s A_{s} As矩阵中的第 i i i行,即代表着第 i i i个item的相关邻居信息。则我们这里通过公式(1)来对其邻居信息进行聚合,这里主要通过矩阵 A s , i A_{s,i} As,i和用户的序列 [ v 1 t − 1 , . . . , v n t − 1 ] T ∈ R n × d [v_{1}^{t-1},...,v_{n}^{t-1}]^{T} \in R^{n \times d} [v1t−1,...,vnt−1]T∈Rn×d的乘法进行聚合的,不过要注意这里的公式写的不太严谨,实际情况下两个 R 1 × 2 n 和 R n × d R^{1 \times 2n}和R^{n \times d} R1×2n和Rn×d的矩阵是无法直接做乘法的,在代码实现中,是将矩阵A分为in和out两个矩阵分别和用户的行为序列进行乘积的
a s , i t = A s , i [ v 1 t − 1 , . . . , v n t − 1 ] T H + b (1) a_{s,i}^{t}=A_{s,i}[v_{1}^{t-1},...,v_{n}^{t-1}]^{T}\textbf{H}+b \tag{1} as,it=As,i[v1t−1,...,vnt−1]TH+b(1)
'''
A : [batch,n,2n] 图的矩阵
hidden : [batch,n,d] 用户序列的emb
in矩阵:A[:, :, :A.size(1)]
out矩阵:A[:, :, A.size(1):2 * A.size(1)]
inputs : 就是公式1中的 a
'''
input_in = paddle.matmul(A[:, :, :A.shape[1]], self.linear_edge_in(hidden)) + self.b_iah
input_out = paddle.matmul(A[:, :, A.shape[1]:], self.linear_edge_out(hidden)) + self.b_ioh
# [batch_size, max_session_len, embedding_size * 2]
inputs = paddle.concat([input_in, input_out], 2)
在得到公式(1)中的 a s , i t a_{s,i}^{t} as,it之后,根据公式(2)(3)计算出两个中间变量 z s , i t , r s , i t z_{s,i}^{t},r_{s,i}^{t} zs,it,rs,it可以简单的类比LSTM,认为 z s , i t , r s , i t z_{s,i}^{t},r_{s,i}^{t} zs,it,rs,it分别是遗忘门和更新门
z s , i t = σ ( W z a s , i t + U z v i t − 1 ) ∈ R d (2) z_{s,i}^{t}=\sigma(W_{z}a_{s,i}^{t}+U_{z}v_{i}^{t-1}) \in R^{d} \tag{2} zs,it=σ(Wzas,it+Uzvit−1)∈Rd(2)
r s , i t = σ ( W r a s , i t + U r v i t − 1 ) ∈ R d (3) r_{s,i}^{t}=\sigma(W_{r}a_{s,i}^{t}+U_{r}v_{i}^{t-1}) \in R^{d} \tag{3} rs,it=σ(Wras,it+Urvit−1)∈Rd(3)
这里需要注意,我们在计算 z s , i t , r s , i t z_{s,i}^{t},r_{s,i}^{t} zs,it,rs,it的逻辑是完全一样的,唯一的区别就是用了不同的参数权重而已.
在得到公式(2)(3)的中间变量之后,我们通过公式(4)计算出更新门下一步更新的特征,以及根据公式(5)来得出最终结果
v i t ∼ = t a n h ( W o a s , i t + U o ( r s , i t ⊙ v i t − 1 ) ) ∈ R d (4) {v_{i}^{t}}^{\sim}=tanh(W_{o}a_{s,i}^{t}+U_{o}(r_{s,i}^{t} \odot v_{i}^{t-1})) \in R^{d}\tag{4} vit∼=tanh(Woas,it+Uo(rs,it⊙vit−1))∈Rd(4)
v i t = ( 1 − z s , i t ) ⊙ v i t − 1 + z s , i t ⊙ v i t ∼ ∈ R d (5) v_{i}^{t}=(1-z_{s,i}^{t}) \odot v_{i}^{t-1} + z_{s,i}^{t} \odot {v_{i}^{t}}^{\sim} \in R^{d} \tag{5} vit=(1−zs,it)⊙vit−1+zs,it⊙vit∼∈Rd(5)
这里我们可以看出,公式(4)实际上是计算了在第t次GNN层的时候的Update部分,也就是 v i t ∼ {v_{i}^{t}}^{\sim} vit∼,而在公式(5)中通过遗忘门 z s , i t z_{s,i}^{t} zs,it来控制第t次GNN更新时, v i t − 1 v_{i}^{t-1} vit−1和${v_{i}{t}}{\sim} $所占的比例。这样就完成了GNN部分的item的表征学习
这里在写代码的时候要注意,对于公式(3)(4)(5),我们仔细观察,对于 a s , i t , v i t − 1 a_{s,i}^{t},v_{i}^{t-1} as,it,vit−1这两个变量而言,每个变量都和三个矩阵进行了相乘,这里的计算逻辑相同,所以将 W a , U v Wa,Uv Wa,Uv当作一次计算单元,在公式(3)(4)(5)中,均涉及了一次这样的操作,所以我们可以将这三次操作放在一起做,然后在讲结果切分为3份,还原三个公式,相关代码如下
'''
inputs : 公式(1)中的a
hidden : 用户序列,也就是v^{t-1}
这里的gi就是Wa,gh就是Uv,但是要注意这里不该是gi还是gh都包含了公式3~5的三个部分
'''
# gi.size equals to gh.size, shape of [batch_size, max_session_len, embedding_size * 3]
gi = paddle.matmul(inputs, self.w_ih) + self.b_ih
gh = paddle.matmul(hidden, self.w_hh) + self.b_hh
# (batch_size, max_session_len, embedding_size)
i_r, i_i, i_n = gi.chunk(3, 2) # 三个W*a
h_r, h_i, h_n = gh.chunk(3, 2) # 三个U*v
reset_gate = F.sigmoid(i_r + h_r) #公式(2)
input_gate = F.sigmoid(i_i + h_i) #公式(3)
new_gate = paddle.tanh(i_n + reset_gate * h_n) #公式(4)
hy = (1 - input_gate) * hidden + input_gate * new_gate # 公式(5)
1.4 生成User 向量表征(Generating Session Embedding)
在通过GNN获取了Item的嵌入表征之后,我们的工作就完成一大半了,剩下的就是讲用户序列的多个Item的嵌入表征融合成一个整体的序列的嵌入表征
这里SR-GNN首先利用了Attention机制来获取序列中每一个Item对于序列中最后一个Item v n ( s 1 ) v_{n}(s_1) vn(s1)的attention score,然后将其加权求和,其具体的计算过程如下
a i = q T σ ( W 1 v n + W 2 v i + c ) ∈ R 1 s g = ∑ i = 1 n a i v I ∈ R d (6) a_{i}=\textbf{q}^{T} \sigma(W_{1}v_{n}+W_{2}v_{i}+c) \in R^{1} \tag{6} \\ s_{g}= \sum_{i=1}^{n}a_{i}v_{I}\in R^{d} ai=qTσ(W1vn+W2vi+c)∈R1sg=i=1∑naivI∈Rd(6)
在得到 s g s_g sg之后,我们将 s g s_g sg与序列中的最后一个Item信息相结合,得到最终的序列的嵌入表征
s h = W 3 [ s 1 ; s g ] ∈ R d (7) s_h = W_{3}[ s_1 ;s_g] \in R^{d} \tag{7} sh=W3[s1;sg]∈Rd(7)
'''
seq_hidden : 序列中每一个item的emb
ht : 序列中最后一个item的emb,就是公式6~7中的v_n(s_1)
q1 : 公式(6)中的 W_1 v_n
q2 : 公式(6)中的 W_2 v_i
alpha : 公式(6)中的alpha
a : 公式(6)中的s_g
'''
seq_hidden = paddle.take_along_axis(hidden,alias_inputs,1)
# fetch the last hidden state of last timestamp
item_seq_len = paddle.sum(mask,axis=1)
ht = self.gather_indexes(seq_hidden, item_seq_len - 1)
q1 = self.linear_one(ht).reshape([ht.shape[0], 1, ht.shape[1]])
q2 = self.linear_two(seq_hidden)
alpha = self.linear_three(F.sigmoid(q1 + q2))
a = paddle.sum(alpha * seq_hidden * mask.reshape([mask.shape[0], -1, 1]), 1)
user_emb = self.linear_transform(paddle.concat([a, ht], axis=1))
至此我们就完成了SR-GNN的用户向量生产了,剩下的部分就可以按照传统的序列召回的方法来进行了,完整具体代码在第二部分介绍
2.代码实践
!pip install faiss
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting faiss
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ef/2e/dc5697e9ff6f313dcaf3afe5ca39d7d8334114cbabaed069d0026bbc3c61/faiss-1.5.3-cp37-cp37m-manylinux1_x86_64.whl (4.7 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m4.7/4.7 MB[0m [31m3.5 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from faiss) (1.19.5)
Installing collected packages: faiss
Successfully installed faiss-1.5.3
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
import paddle
from paddle import nn
from paddle.io import DataLoader, Dataset
import paddle.nn.functional as F
import pandas as pd
import numpy as np
import copy
import os
import math
import random
from sklearn.metrics import roc_auc_score,log_loss
from sklearn.preprocessing import normalize
from tqdm import tqdm
from collections import defaultdict
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
import faiss
# paddle.device.set_device('gpu:0')
import warnings
warnings.filterwarnings("ignore")
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
2.1 Dataset
class SeqnenceDataset(Dataset):
def __init__(self, config, df, phase='train'):
self.config = config
self.df = df
self.max_length = self.config['max_length']
self.df = self.df.sort_values(by=['user_id', 'timestamp'])
self.user2item = self.df.groupby('user_id')['item_id'].apply(list).to_dict()
self.user_list = self.df['user_id'].unique()
self.phase = phase
def __len__(self, ):
return len(self.user2item)
def __getitem__(self, index):
if self.phase == 'train':
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = random.choice(range(4, len(item_list))) # 从[8,len(item_list))中随机选择一个index
# k = np.random.randint(2,len(item_list))
item_id = item_list[k] # 该index对应的item加入item_id_list
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), paddle.to_tensor([item_id])
else:
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = int(0.8 * len(item_list))
# k = len(item_list)-1
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), item_list[k:]
def get_test_gd(self):
self.test_gd = {}
for user in self.user2item:
item_list = self.user2item[user]
test_item_index = int(0.8 * len(item_list))
self.test_gd[user] = item_list[test_item_index:]
return self.test_gd
2.2 SR-GNN模型定义
class GNN(nn.Layer):
def __init__(self, embedding_size, step=1):
super(GNN, self).__init__()
self.step = step
self.embedding_size = embedding_size
self.input_size = embedding_size * 2
self.gate_size = embedding_size * 3
self.w_ih = self.create_parameter(shape=[self.input_size, self.gate_size])
self.w_hh = self.create_parameter(shape=[self.embedding_size, self.gate_size])
self.b_ih = self.create_parameter(shape=[self.gate_size])
self.b_hh = self.create_parameter(shape=[self.gate_size])
self.b_iah = self.create_parameter(shape=[self.embedding_size])
self.b_ioh = self.create_parameter(shape=[self.embedding_size])
self.linear_edge_in = nn.Linear(self.embedding_size, self.embedding_size)
self.linear_edge_out = nn.Linear(self.embedding_size, self.embedding_size)
def GNNCell(self, A, hidden):
input_in = paddle.matmul(A[:, :, :A.shape[1]], self.linear_edge_in(hidden)) + self.b_iah
input_out = paddle.matmul(A[:, :, A.shape[1]:], self.linear_edge_out(hidden)) + self.b_ioh
# [batch_size, max_session_len, embedding_size * 2]
inputs = paddle.concat([input_in, input_out], 2)
# gi.size equals to gh.size, shape of [batch_size, max_session_len, embedding_size * 3]
gi = paddle.matmul(inputs, self.w_ih) + self.b_ih
gh = paddle.matmul(hidden, self.w_hh) + self.b_hh
# (batch_size, max_session_len, embedding_size)
i_r, i_i, i_n = gi.chunk(3, 2)
h_r, h_i, h_n = gh.chunk(3, 2)
reset_gate = F.sigmoid(i_r + h_r)
input_gate = F.sigmoid(i_i + h_i)
new_gate = paddle.tanh(i_n + reset_gate * h_n)
hy = (1 - input_gate) * hidden + input_gate * new_gate
return hy
def forward(self, A, hidden):
for i in range(self.step):
hidden = self.GNNCell(A, hidden)
return hidden
class SRGNN(nn.Layer):
r"""SRGNN regards the conversation history as a directed graph.
In addition to considering the connection between the item and the adjacent item,
it also considers the connection with other interactive items.
Such as: A example of a session sequence(eg:item1, item2, item3, item2, item4) and the connection matrix A
Outgoing edges:
=== ===== ===== ===== =====
\ 1 2 3 4
=== ===== ===== ===== =====
1 0 1 0 0
2 0 0 1/2 1/2
3 0 1 0 0
4 0 0 0 0
=== ===== ===== ===== =====
Incoming edges:
=== ===== ===== ===== =====
\ 1 2 3 4
=== ===== ===== ===== =====
1 0 0 0 0
2 1/2 0 1/2 0
3 0 1 0 0
4 0 1 0 0
=== ===== ===== ===== =====
"""
def __init__(self, config):
super(SRGNN, self).__init__()
# load parameters info
self.config = config
self.embedding_size = config['embedding_dim']
self.step = config['step']
self.n_items = self.config['n_items']
# define layers and loss
# item embedding
self.item_emb = nn.Embedding(self.n_items, self.embedding_size, padding_idx=0)
# define layers and loss
self.gnn = GNN(self.embedding_size, self.step)
self.linear_one = nn.Linear(self.embedding_size, self.embedding_size)
self.linear_two = nn.Linear(self.embedding_size, self.embedding_size)
self.linear_three = nn.Linear(self.embedding_size, 1, bias_attr=False)
self.linear_transform = nn.Linear(self.embedding_size * 2, self.embedding_size)
self.loss_fun = nn.CrossEntropyLoss()
# parameters initialization
self.reset_parameters()
def gather_indexes(self, output, gather_index):
"""Gathers the vectors at the specific positions over a minibatch"""
# gather_index = gather_index.view(-1, 1, 1).expand(-1, -1, output.shape[-1])
gather_index = gather_index.reshape([-1, 1, 1])
gather_index = paddle.repeat_interleave(gather_index,output.shape[-1],2)
output_tensor = paddle.take_along_axis(output, gather_index, 1)
return output_tensor.squeeze(1)
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def _get_slice(self, item_seq):
# Mask matrix, shape of [batch_size, max_session_len]
mask = (item_seq>0).astype('int32')
items, n_node, A, alias_inputs = [], [], [], []
max_n_node = item_seq.shape[1]
item_seq = item_seq.cpu().numpy()
for u_input in item_seq:
node = np.unique(u_input)
items.append(node.tolist() + (max_n_node - len(node)) * [0])
u_A = np.zeros((max_n_node, max_n_node))
for i in np.arange(len(u_input) - 1):
if u_input[i + 1] == 0:
break
u = np.where(node == u_input[i])[0][0]
v = np.where(node == u_input[i + 1])[0][0]
u_A[u][v] = 1
u_sum_in = np.sum(u_A, 0)
u_sum_in[np.where(u_sum_in == 0)] = 1
u_A_in = np.divide(u_A, u_sum_in)
u_sum_out = np.sum(u_A, 1)
u_sum_out[np.where(u_sum_out == 0)] = 1
u_A_out = np.divide(u_A.transpose(), u_sum_out)
u_A = np.concatenate([u_A_in, u_A_out]).transpose()
A.append(u_A)
alias_inputs.append([np.where(node == i)[0][0] for i in u_input])
# The relative coordinates of the item node, shape of [batch_size, max_session_len]
alias_inputs = paddle.to_tensor(alias_inputs)
# The connecting matrix, shape of [batch_size, max_session_len, 2 * max_session_len]
A = paddle.to_tensor(A)
# The unique item nodes, shape of [batch_size, max_session_len]
items = paddle.to_tensor(items)
return alias_inputs, A, items, mask
def forward(self, item_seq, mask, item, train=True):
if train:
alias_inputs, A, items, mask = self._get_slice(item_seq)
hidden = self.item_emb(items)
hidden = self.gnn(A, hidden)
alias_inputs = alias_inputs.reshape([-1, alias_inputs.shape[1],1])
alias_inputs = paddle.repeat_interleave(alias_inputs, self.embedding_size, 2)
seq_hidden = paddle.take_along_axis(hidden,alias_inputs,1)
# fetch the last hidden state of last timestamp
item_seq_len = paddle.sum(mask,axis=1)
ht = self.gather_indexes(seq_hidden, item_seq_len - 1)
q1 = self.linear_one(ht).reshape([ht.shape[0], 1, ht.shape[1]])
q2 = self.linear_two(seq_hidden)
alpha = self.linear_three(F.sigmoid(q1 + q2))
a = paddle.sum(alpha * seq_hidden * mask.reshape([mask.shape[0], -1, 1]), 1)
user_emb = self.linear_transform(paddle.concat([a, ht], axis=1))
loss = self.calculate_loss(user_emb,item)
output_dict = {
'user_emb': user_emb,
'loss': loss
}
else:
alias_inputs, A, items, mask = self._get_slice(item_seq)
hidden = self.item_emb(items)
hidden = self.gnn(A, hidden)
alias_inputs = alias_inputs.reshape([-1, alias_inputs.shape[1],1])
alias_inputs = paddle.repeat_interleave(alias_inputs, self.embedding_size, 2)
seq_hidden = paddle.take_along_axis(hidden, alias_inputs,1)
# fetch the last hidden state of last timestamp
item_seq_len = paddle.sum(mask, axis=1)
ht = self.gather_indexes(seq_hidden, item_seq_len - 1)
q1 = self.linear_one(ht).reshape([ht.shape[0], 1, ht.shape[1]])
q2 = self.linear_two(seq_hidden)
alpha = self.linear_three(F.sigmoid(q1 + q2))
a = paddle.sum(alpha * seq_hidden * mask.reshape([mask.shape[0], -1, 1]), 1)
user_emb = self.linear_transform(paddle.concat([a, ht], axis=1))
output_dict = {
'user_emb': user_emb,
}
return output_dict
2.3 Pipeline
config = {
'train_path':'/home/aistudio/data/data173799/train_enc.csv',
'valid_path':'/home/aistudio/data/data173799/valid_enc.csv',
'test_path':'/home/aistudio/data/data173799/test_enc.csv',
'lr':1e-4,
'Epoch':100,
'batch_size':256,
'embedding_dim':16,
'num_layers':1,
'max_length':20,
'n_items':15406,
'step':2,
}
def my_collate(batch):
hist_item, hist_mask, item_list = list(zip(*batch))
hist_item = [x.unsqueeze(0) for x in hist_item]
hist_mask = [x.unsqueeze(0) for x in hist_mask]
hist_item = paddle.concat(hist_item,axis=0)
hist_mask = paddle.concat(hist_mask,axis=0)
return hist_item,hist_mask,item_list
def save_model(model, path):
if not os.path.exists(path):
os.makedirs(path)
paddle.save(model.state_dict(), path + 'model.pdparams')
def load_model(model, path):
state_dict = paddle.load(path + 'model.pdparams')
model.set_state_dict(state_dict)
print('model loaded from %s' % path)
return model
2.4 基于Faiss的向量召回
def get_predict(model, test_data, hidden_size, topN=20):
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
test_gd = dict()
preds = dict()
user_id = 0
for (item_seq, mask, targets) in tqdm(test_data):
# 获取用户嵌入
# 多兴趣模型,shape=(batch_size, num_interest, embedding_dim)
# 其他模型,shape=(batch_size, embedding_dim)
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 用内积来近邻搜索,实际是内积的值越大,向量越近(越相似)
if len(user_embs.shape) == 2: # 非多兴趣模型评估
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
test_gd[user_id] = iid_list
preds[user_id] = I[i,:]
user_id +=1
else: # 多兴趣模型评估
ni = user_embs.shape[1] # num_interest
user_embs = np.reshape(user_embs,
[-1, user_embs.shape[-1]]) # shape=(batch_size*num_interest, embedding_dim)
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
recall = 0
dcg = 0.0
item_list_set = []
# 将num_interest个兴趣向量的所有topN近邻物品(num_interest*topN个物品)集合起来按照距离重新排序
item_list = list(
zip(np.reshape(I[i * ni:(i + 1) * ni], -1), np.reshape(D[i * ni:(i + 1) * ni], -1)))
item_list.sort(key=lambda x: x[1], reverse=True) # 降序排序,内积越大,向量越近
for j in range(len(item_list)): # 按距离由近到远遍历推荐物品列表,最后选出最近的topN个物品作为最终的推荐物品
if item_list[j][0] not in item_list_set and item_list[j][0] != 0:
item_list_set.append(item_list[j][0])
if len(item_list_set) >= topN:
break
test_gd[user_id] = iid_list
preds[user_id] = item_list_set
user_id +=1
return test_gd, preds
def evaluate(preds,test_gd, topN=50):
total_recall = 0.0
total_ndcg = 0.0
total_hitrate = 0
for user in test_gd.keys():
recall = 0
dcg = 0.0
item_list = test_gd[user]
for no, item_id in enumerate(item_list):
if item_id in preds[user][:topN]:
recall += 1
dcg += 1.0 / math.log(no+2, 2)
idcg = 0.0
for no in range(recall):
idcg += 1.0 / math.log(no+2, 2)
total_recall += recall * 1.0 / len(item_list)
if recall > 0:
total_ndcg += dcg / idcg
total_hitrate += 1
total = len(test_gd)
recall = total_recall / total
ndcg = total_ndcg / total
hitrate = total_hitrate * 1.0 / total
return {f'recall@{topN}': recall, f'ndcg@{topN}': ndcg, f'hitrate@{topN}': hitrate}
# 指标计算
def evaluate_model(model, test_loader, embedding_dim,topN=20):
test_gd, preds = get_predict(model, test_loader, embedding_dim, topN=topN)
return evaluate(preds, test_gd, topN=topN)
# 读取数据
train_df = pd.read_csv(config['train_path'])
valid_df = pd.read_csv(config['valid_path'])
test_df = pd.read_csv(config['test_path'])
train_dataset = SeqnenceDataset(config, train_df, phase='train')
valid_dataset = SeqnenceDataset(config, valid_df, phase='test')
test_dataset = SeqnenceDataset(config, test_df, phase='test')
train_loader = DataLoader(dataset=train_dataset, batch_size=config['batch_size'], shuffle=True,num_workers=8)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=config['batch_size'], shuffle=False,collate_fn=my_collate)
test_loader = DataLoader(dataset=test_dataset, batch_size=config['batch_size'], shuffle=False,collate_fn=my_collate)
model = SRGNN(config)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=config['lr'])
log_df = pd.DataFrame()
best_reacall = -1
exp_path = './exp/ml-20m_softmax/SRGNN_{}_{}_{}/'.format(config['lr'],config['batch_size'],config['embedding_dim'])
os.makedirs(exp_path,exist_ok=True,mode=0o777)
patience = 5
last_improve_epoch = 1
log_csv = exp_path+'log.csv'
# *****************************************************train*********************************************
for epoch in range(1, 1 + config['Epoch']):
# try :
pbar = tqdm(train_loader)
model.train()
loss_list = []
acc_50_list = []
print()
print('Training:')
print()
for batch_data in pbar:
(item_seq, mask, item) = batch_data
output_dict = model(item_seq, mask, item)
loss = output_dict['loss']
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_list.append(loss.item())
pbar.set_description('Epoch [{}/{}]'.format(epoch,config['Epoch']))
pbar.set_postfix(loss = np.mean(loss_list))
# *****************************************************valid*********************************************
print('Valid')
recall_metric = evaluate_model(model, valid_loader, config['embedding_dim'], topN=50)
print(recall_metric)
recall_metric['phase'] = 'valid'
log_df = log_df.append(recall_metric, ignore_index=True)
log_df.to_csv(log_csv)
if recall_metric['recall@50'] > best_reacall:
save_model(model,exp_path)
best_reacall = recall_metric['recall@50']
last_improve_epoch = epoch
if epoch - last_improve_epoch > patience:
break
print('Testing')
model = load_model(model,exp_path)
recall_metric = evaluate_model(model, test_loader, config['embedding_dim'], topN=50)
print(recall_metric)
recall_metric['phase'] = 'test'
log_df = log_df.append(recall_metric, ignore_index=True)
log_df.to_csv(log_csv)
log_df
| hitrate@50 | ndcg@50 | phase | recall@50 | |
|---|---|---|---|---|
| 0 | 0.584048 | 0.326966 | valid | 0.129350 |
| 1 | 0.581358 | 0.321557 | valid | 0.124243 |
| 2 | 0.564490 | 0.304944 | valid | 0.110797 |
| 3 | 0.550749 | 0.287643 | valid | 0.099720 |
| 4 | 0.538970 | 0.277709 | valid | 0.094904 |
| 5 | 0.557438 | 0.290121 | valid | 0.101922 |
| 6 | 0.559255 | 0.296474 | valid | 0.107475 |
| 7 | 0.586691 | 0.328189 | test | 0.130097 |
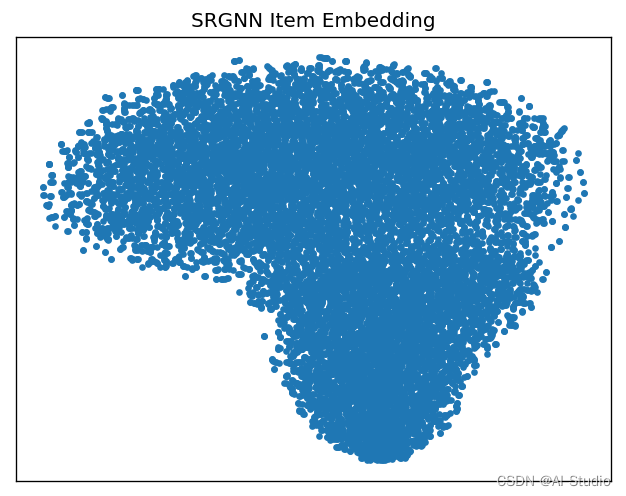
2.5 基于TSNE的Item Embedding分布可视化
def plot_embedding(data, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min)
fig = plt.figure(dpi=120)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.xticks([])
plt.yticks([])
plt.title(title)
plt.show()
item_emb = model.output_items().numpy()
tsne_emb = TSNE(n_components=2).fit_transform(item_emb)
plot_embedding(tsne_emb,'SRGNN Item Embedding')
3.总结
SR-GNN是一篇非常好的将GNN融入到序列召回模型的一篇工作,其利用了GNN的非结构化处理数据的能力以及Attention对序列建模的能力极大的提高了序列召回的效果,同时也算是GNN在序列召回中非常有里程碑意义的一篇工作
4.参考资料
- https://arxiv.org/pdf/2106.05081
- https://ojs.aaai.org/index.php/AAAI/article/download/3804/3682
- https://www.ijcai.org/proceedings/2019/0547.pdf
- https://arxiv.org/pdf/2107.03813
- https://arxiv.org/pdf/1911.11942.pdf
- https://recbole.io
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)