
MicroNet论文复现:用极低的FLOPs改进图像识别
【论文复现第7期】micronet旨在解决极低计算量下性能大幅下降的问题。研究发现,稀疏连接和动态激活函数这两个改进可有效地提高精度。前者避免了网络宽度的显著减少,后者减轻了网络深度减少的不利影响。
摘要
MicroNet旨在解决在极低的计算成本下(例如在ImageNet分类上的5M FLOPs)性能大幅下降的问题。研究发现,稀疏连接和动态激活函数这两个因素可以有效地提高准确性。前者避免了网络宽度的显著减少,而后者则减轻了网络深度减少的不利影响。在技术上,论文提出了微因子卷积法,它将卷积矩阵分解为低等级矩阵,将稀疏连接性整合到卷积中。论文还提出了一个新的动态激活函数,名为动态移位最大值,通过对输入特征图和其循环通道移位之间的多个动态融合的最大值来改善非线性。在这两个新算子的基础上,得到了一个名为MicroNet的网络系列,它在低FLOP制度下取得了比现有技术更显著的性能提升。例如,在1200万FLOPs的约束下,MicroNet在ImageNet分类上实现了59.4%的最高1级精度,比MobileNetV3高出9.6%。
1. MicroNet
1.1 总体架构
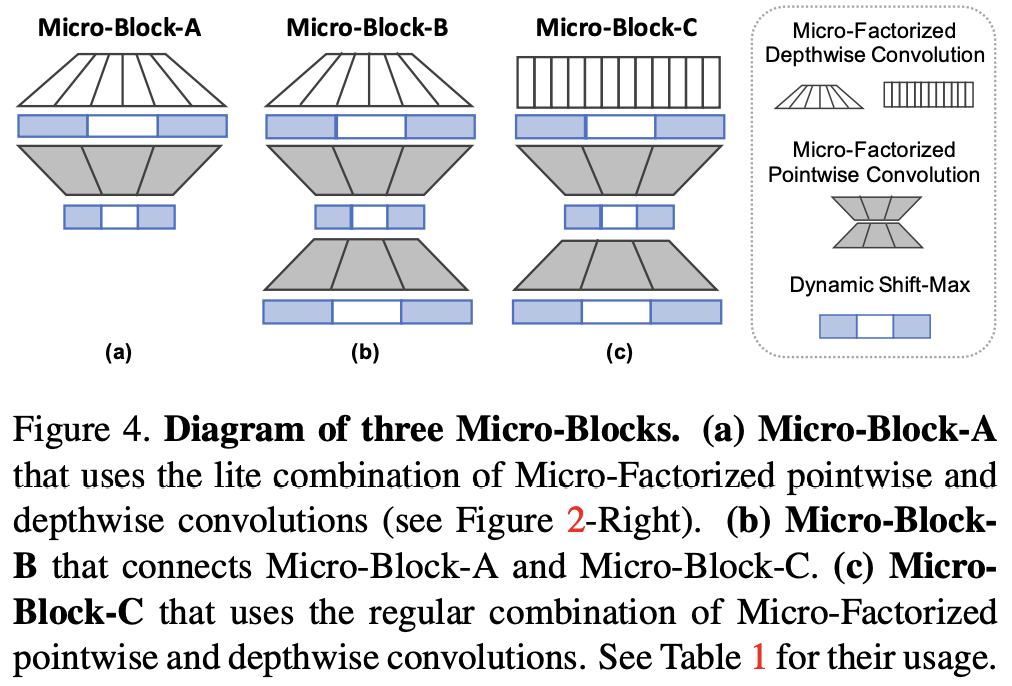
论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized convolution通过低秩近似将原卷积分解成多个小卷积,保持输入输出的连接性并降低连接数,Dynamic Shift-Max通过动态的组间特征融合增加节点的连接以及提升非线性,弥补网络深度减少带来的性能降低。
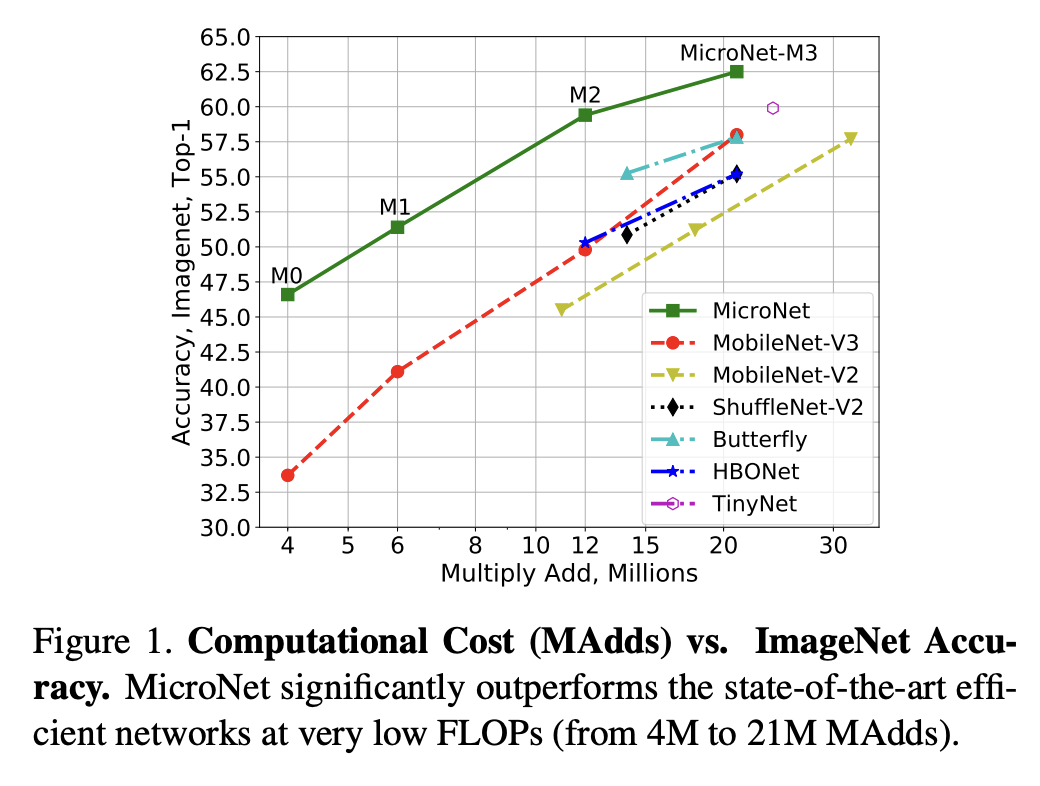
2. 代码复现
2.1 Micro-Factorized Convolution
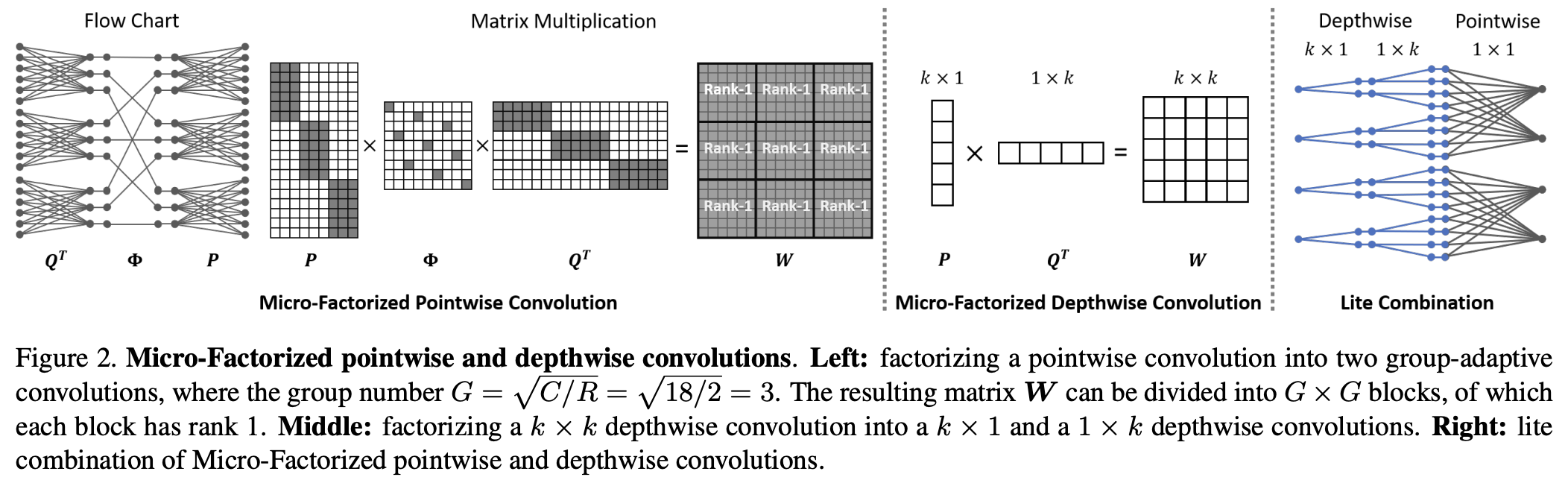
Micro-Factorized Convolution的目标是平衡通道数量和节点连接性。这里一个层的连接性被定义为每个输出节点的路径数,其中一个路径连接着一个输入结点和一个输出结点。
class MaxGroupPooling(nn.Layer):
def __init__(self, channel_per_group=2):
super().__init__()
self.channel_per_group = channel_per_group
def forward(self, x):
if self.channel_per_group == 1:
return x
# max op
b, c, h, w = x.shape
# reshape
y = x.reshape([b, c // self.channel_per_group, -1, h, w])
out, _ = paddle.max(y, axis=2)
return out
class GroupConv(nn.Layer):
def __init__(self, inp, oup, groups=2):
super().__init__()
self.inp = inp
self.oup = oup
self.groups = groups
# print('inp: %d, oup:%d, g:%d' % (inp, oup, self.groups[0]))
self.conv = nn.Sequential(
nn.Conv2D(
inp, oup, 1, groups=self.groups[0], bias_attr=False),
nn.BatchNorm2D(oup))
def forward(self, x):
x = self.conv(x)
return x
class ChannelShuffle(nn.Layer):
def __init__(self, groups):
super().__init__()
self.groups = groups
def forward(self, x):
b, c, h, w = x.shape
channels_per_group = c // self.groups
# reshape
x = x.reshape([b, self.groups, channels_per_group, h, w])
x = x.transpose([0, 2, 1, 3, 4])
out = x.reshape([b, c, h, w])
return out
class SpatialSepConvSF(nn.Layer):
def __init__(self, inp, oups, kernel_size, stride):
super().__init__()
oup1, oup2 = oups
self.conv = nn.Sequential(
nn.Conv2D(
inp,
oup1, (kernel_size, 1), (stride, 1), (kernel_size // 2, 0),
groups=1,
bias_attr=False),
nn.BatchNorm2D(oup1),
nn.Conv2D(
oup1,
oup1 * oup2, (1, kernel_size), (1, stride),
(0, kernel_size // 2),
groups=oup1,
bias_attr=False),
nn.BatchNorm2D(oup1 * oup2),
ChannelShuffle(oup1), )
def forward(self, x):
out = self.conv(x)
return out
class DepthSpatialSepConv(nn.Layer):
def __init__(self, inp, expand, kernel_size, stride):
super().__init__()
exp1, exp2 = expand
hidden_dim = inp * exp1
oup = inp * exp1 * exp2
self.conv = nn.Sequential(
nn.Conv2D(
inp,
inp * exp1, (kernel_size, 1), (stride, 1),
(kernel_size // 2, 0),
groups=inp,
bias_attr=False),
nn.BatchNorm2D(inp * exp1),
nn.Conv2D(
hidden_dim,
oup, (1, kernel_size), (1, stride), (0, kernel_size // 2),
groups=hidden_dim,
bias_attr=False),
nn.BatchNorm2D(oup))
def forward(self, x):
out = self.conv(x)
return out
2.2 Dynamic Shift-Max
Dynamic-ShiftMax是一种新的动态非线性,加强了由微因子化创建的组之间的联系。这是对Micro-Factorized Convolution的补充,后者侧重于组内的连接。
class DYShiftMax(nn.Layer):
def __init__(self,
inp,
oup,
reduction=4,
act_max=1.0,
act_relu=True,
init_a=[0.0, 0.0],
init_b=[0.0, 0.0],
relu_before_pool=False,
g=None,
expansion=False):
super().__init__()
self.oup = oup
self.act_max = act_max * 2
self.act_relu = act_relu
self.avg_pool = nn.Sequential(nn.ReLU() if relu_before_pool == True
else nn.Identity(),
nn.AdaptiveAvgPool2D(1))
self.exp = 4 if act_relu else 2
self.init_a = init_a
self.init_b = init_b
# determine squeeze
squeeze = _make_divisible(inp // reduction, 4)
if squeeze < 4:
squeeze = 4
# print('reduction: {}, squeeze: {}/{}'.format(reduction, inp, squeeze))
# print('init-a: {}, init-b: {}'.format(init_a, init_b))
self.fc = nn.Sequential(
nn.Linear(inp, squeeze),
nn.ReLU(), nn.Linear(squeeze, oup * self.exp), nn.Hardsigmoid())
if g is None:
g = 1
self.g = g[1]
if self.g != 1 and expansion:
self.g = inp // self.g
# print('group shuffle: {}, divide group: {}'.format(self.g, expansion))
self.gc = inp // self.g
index = paddle.to_tensor(list(range(inp))).reshape([1, inp, 1, 1])
index = index.reshape([1, self.g, self.gc, 1, 1])
indexgs = paddle.split(index, [1, self.g - 1], axis=1)
indexgs = paddle.concat((indexgs[1], indexgs[0]), axis=1)
indexs = paddle.split(indexgs, [1, self.gc - 1], axis=2)
indexs = paddle.concat((indexs[1], indexs[0]), axis=2)
self.index = indexs.reshape([inp]).astype(paddle.int64)
self.expansion = expansion
def forward(self, x):
x_in = x
x_out = x
b, c, _, _ = x_in.shape
y = self.avg_pool(x_in).reshape([b, c])
y = self.fc(y).reshape([b, self.oup * self.exp, 1, 1])
y = (y - 0.5) * self.act_max
n2, c2, h2, w2 = x_out.shape
x2 = paddle.index_select(x_out, self.index, axis=1)
if self.exp == 4:
a1, b1, a2, b2 = paddle.split(y, 4, axis=1)
a1 = a1 + self.init_a[0]
a2 = a2 + self.init_a[1]
b1 = b1 + self.init_b[0]
b2 = b2 + self.init_b[1]
z1 = x_out * a1 + x2 * b1
z2 = x_out * a2 + x2 * b2
out = paddle.maximum(z1, z2)
elif self.exp == 2:
a1, b1 = paddle.split(y, 2, axis=1)
a1 = a1 + self.init_a[0]
b1 = b1 + self.init_b[0]
out = x_out * a1 + x2 * b1
return out
class DYMicroBlock(nn.Layer):
def __init__(self,
inp,
oup,
kernel_size=3,
stride=1,
ch_exp=(2, 2),
ch_per_group=4,
groups_1x1=(1, 1),
dy=[0, 0, 0],
ratio=1.0,
activation_cfg=None):
super().__init__()
# print(dy)
self.identity = stride == 1 and inp == oup
y1, y2, y3 = dy
act_max = activation_cfg["act_max"]
act_reduction = activation_cfg["reduction"] * ratio
init_a = activation_cfg["init_a"]
init_b = activation_cfg["init_b"]
init_ab3 = activation_cfg["init_ab3"]
t1 = ch_exp
gs1 = ch_per_group
hidden_fft, g1, g2 = groups_1x1
hidden_dim1 = inp * t1[0]
hidden_dim2 = inp * t1[0] * t1[1]
if gs1[0] == 0:
self.layers = nn.Sequential(
DepthSpatialSepConv(inp, t1, kernel_size, stride),
DYShiftMax(
hidden_dim2,
hidden_dim2,
act_max=act_max,
act_relu=True if y2 == 2 else False,
init_a=init_a,
reduction=act_reduction,
init_b=init_b,
g=gs1,
expansion=False) if y2 > 0 else nn.ReLU6(),
ChannelShuffle(gs1[1]),
ChannelShuffle2(hidden_dim2 // 2)
if y2 != 0 else nn.Identity(),
GroupConv(hidden_dim2, oup, (g1, g2)),
DYShiftMax(
oup,
oup,
act_max=act_max,
act_relu=False,
init_a=[init_ab3[0], 0.0],
reduction=act_reduction // 2,
init_b=[init_ab3[1], 0.0],
g=(g1, g2),
expansion=False) if y3 > 0 else nn.Identity(),
ChannelShuffle(g2),
ChannelShuffle2(oup // 2)
if oup % 2 == 0 and y3 != 0 else nn.Identity(), )
elif g2 == 0:
self.layers = nn.Sequential(
GroupConv(inp, hidden_dim2, gs1),
DYShiftMax(
hidden_dim2,
hidden_dim2,
act_max=act_max,
act_relu=False,
init_a=[init_ab3[0], 0.0],
reduction=act_reduction,
init_b=[init_ab3[1], 0.0],
g=gs1,
expansion=False) if y3 > 0 else nn.Identity(), )
else:
self.layers = nn.Sequential(
GroupConv(inp, hidden_dim2, gs1),
DYShiftMax(
hidden_dim2,
hidden_dim2,
act_max=act_max,
act_relu=True if y1 == 2 else False,
init_a=init_a,
reduction=act_reduction,
init_b=init_b,
g=gs1,
expansion=False) if y1 > 0 else nn.ReLU6(),
ChannelShuffle(gs1[1]),
DepthSpatialSepConv(hidden_dim2, (1, 1), kernel_size, stride),
nn.Identity(),
DYShiftMax(
hidden_dim2,
hidden_dim2,
act_max=act_max,
act_relu=True if y2 == 2 else False,
init_a=init_a,
reduction=act_reduction,
init_b=init_b,
g=gs1,
expansion=True, ) if y2 > 0 else nn.ReLU6(),
ChannelShuffle2(hidden_dim2 // 4)
if y1 != 0 and y2 != 0 else nn.Identity()
if y1 == 0 and y2 == 0 else ChannelShuffle2(hidden_dim2 // 2),
GroupConv(hidden_dim2, oup, (g1, g2)),
DYShiftMax(
oup,
oup,
act_max=act_max,
act_relu=False,
init_a=[init_ab3[0], 0.0],
reduction=act_reduction // 2
if oup < hidden_dim2 else act_reduction,
init_b=[init_ab3[1], 0.0],
g=(g1, g2),
expansion=False) if y3 > 0 else nn.Identity(),
ChannelShuffle(g2),
ChannelShuffle2(oup // 2) if y3 != 0 else nn.Identity(), )
def forward(self, x):
out = self.layers(x)
if self.identity:
out = out + x
return out
3.数据集和复现精度
3.1 数据集
ImageNet项目是一个大型视觉数据库,用于视觉目标识别研究任务,该项目已手动标注了 1400 多万张图像。ImageNet-1k 是 ImageNet 数据集的子集,其包含 1000 个类别。训练集包含 1281167 个图像数据,验证集包含 50000 个图像数据。2010 年以来,ImageNet 项目每年举办一次图像分类竞赛,即 ImageNet 大规模视觉识别挑战赛(ILSVRC)。挑战赛使用的数据集即为 ImageNet-1k。到目前为止,ImageNet-1k 已经成为计算机视觉领域发展的最重要的数据集之一,其促进了整个计算机视觉的发展,很多计算机视觉下游任务的初始化模型都是基于该数据集训练得到的。
| 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注 |
|---|---|---|---|---|
| ImageNet1k | 1.2M | 50k | 1000 |
3.2 复现精度
| 模型 | epochs | top1 acc (参考精度) | top1 acc (复现精度) | 权重 | 训练日志 |
|---|---|---|---|---|---|
| micronet_m0 | 600 | 46.6 | 46.4 | m1_epoch_594.pdparams | m0_train.log |
| micronet_m3 | 600 | 62.5 | 62.8 | m3_epoch_591.pdparams | m3_train.log |
权重及训练日志下载地址:百度网盘 or work/best_model.pdparams
4.准备环境
4.1 安装paddlepaddle
# 安装GPU版本的Paddle
pip install paddlepaddle-gpu==2.3.2
更多安装方法可以参考:Paddle安装指南。
4.2 下载代码
%cd /home/aistudio/
# !git clone https://github.com/flytocc/PaddleClas.git
# !cd PaddleClas
# !git checkout -b micronet_PR
!unzip PaddleClas-micronet_PR.zip
%cd /home/aistudio/PaddleClas-micronet_PR
!pip install -r requirements.txt
5.开始使用
5.1 模型预测

%cd /home/aistudio/PaddleClas-micronet_PR
%run tools/infer.py \
-c ./ppcls/configs/ImageNet/MicroNet/micronet_m3.yaml \
-o Infer.infer_imgs=./deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg \
-o Global.pretrained_model=/home/aistudio/work/best_model
最终输出结果为
[{'class_ids': [178, 209, 211, 208, 236], 'scores': [0.99474, 0.00512, 8e-05, 3e-05, 2e-05], 'file_name': './deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg', 'label_names': ['Weimaraner', 'Chesapeake Bay retriever', 'vizsla, Hungarian pointer', 'Labrador retriever', 'Doberman, Doberman pinscher']}]
表示预测的类别为Weimaraner(魏玛猎狗),ID是178,置信度为0.99474。
5.2 模型训练
- 单机多卡训练
python -m paddle.distributed.launch --gpus=0,1,2,3 \
tools/train.py \
-c ./ppcls/configs/ImageNet/MicroNet/micronet_m3.yaml
部分训练日志如下所示。
[2022/08/31 04:13:11] ppcls INFO: [Train][Epoch 302/600][Iter: 1550/2503]lr(LinearWarmup): 0.10046482, top1: 0.48098, top5: 0.72183, CELoss: 2.36589, loss: 2.36589, batch_cost: 0.27864s, reader_cost: 0.01763, ips: 459.37528 samples/s, eta: 2 days, 9:48:20
[2022/08/31 04:13:14] ppcls INFO: [Train][Epoch 302/600][Iter: 1560/2503]lr(LinearWarmup): 0.10046271, top1: 0.48091, top5: 0.72176, CELoss: 2.36646, loss: 2.36646, batch_cost: 0.27873s, reader_cost: 0.01755, ips: 459.22941 samples/s, eta: 2 days, 9:49:24
5.3 模型评估
python -m paddle.distributed.launch --gpus=0,1,2,3 \
tools/eval.py \
-c ./ppcls/configs/ImageNet/MicroNet/micronet_m3.yaml \
-o Global.pretrained_model=$TRAINED_MODEL
6. License
This project is released under MIT License.
7. 参考链接与文献
- MicroNet: Improving Image Recognition with Extremely Low FLOPs: https://arxiv.org/abs/2108.05894
- micronet: https://github.com/liyunsheng13/micronet
@article{li2021micronet,
title={MicroNet: Improving Image Recognition with Extremely Low FLOPs},
author={Li, Yunsheng and Chen, Yinpeng and Dai, Xiyang and Chen, Dongdong and Liu, Mengchen and Yuan, Lu and Liu, Zicheng and Zhang, Lei and Vasconcelos, Nuno},
journal={arXiv preprint arXiv:2108.05894},
year={2021}
}
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)