
手把手教你读推荐论文-Comirec(上)
Comirec论文解读&代码实现(上)
Comirec:Controllable Multi-Interest Framework for Recommendation
1.论文解读
论文链接:https://arxiv.org/abs/2005.09347
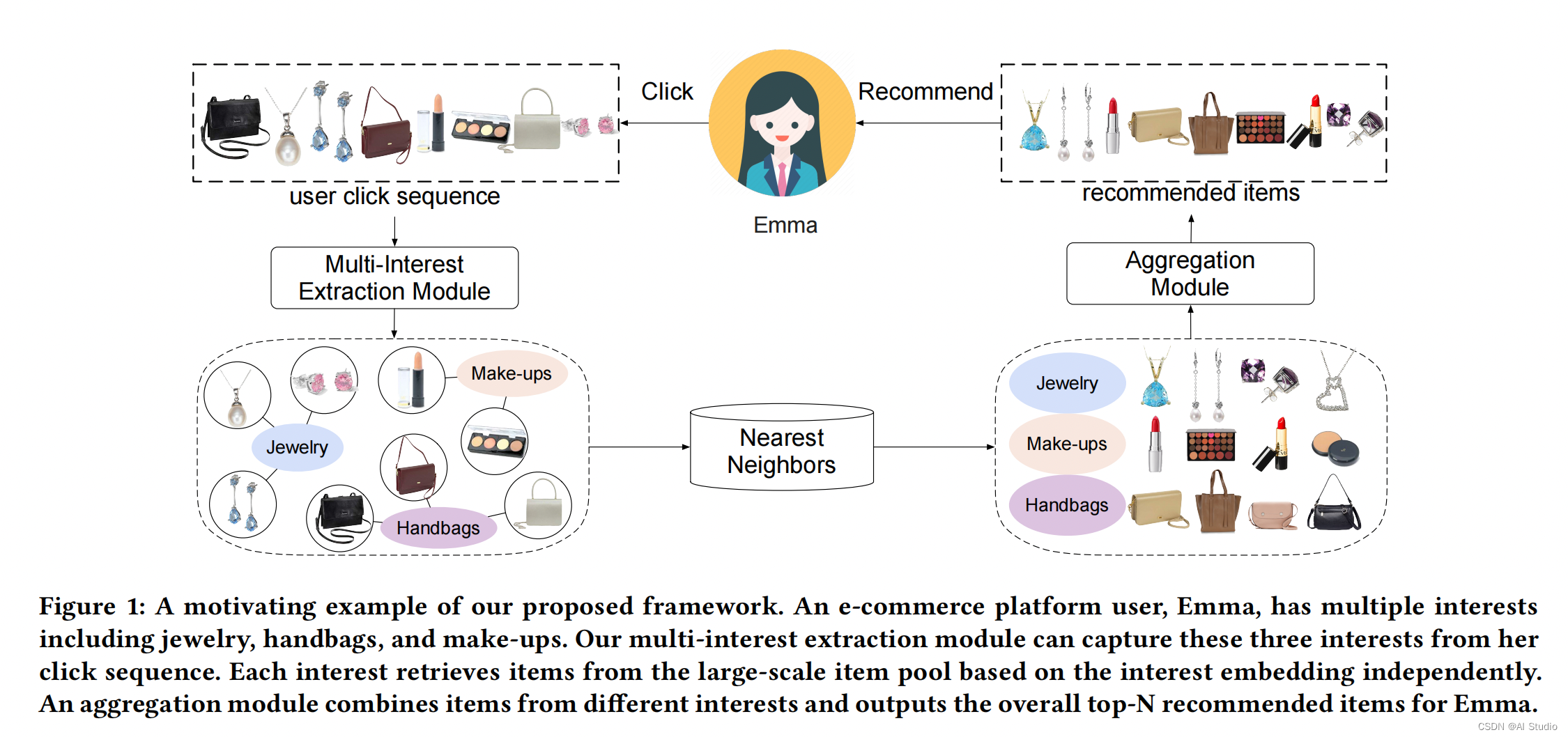
Comirec是阿里发表在KDD 2020上的一篇工作,这篇论文对MIND多行为召回进行了扩展,一方面改进了MIND中的动态路由算法,另一方面提出了一种新的多兴趣召回方法,同时对推荐的多样性层面也做出了一定的贡献,通过一种贪心的做法,在损失较小的推荐效果的情况下可以显著的提高推荐的多样性(感觉非常非常牵强,我们这里就不介绍这个了),从而极大的提高用户的使用体验,可以更进一步的探索用户的潜在兴趣。
这里我们将这篇论文分为上下两部分,我们在这个项目中介绍Comirec-DR模型,在下一篇教程中介绍Comirec-SA模型
1.1 Comirec-DR模型

在这里Comirec-DR也是同样的使用了胶囊网络中的动态路由算法来对其进行多兴趣表征的提取,我们这里同样的对这里流程的每一行进行解析,在解析完这里的动态路由算法之后,我们会将Comirec-DR与MIND进行对比,通过对比可以更加深入的理解这两篇论文对动态路由的使用。
首先,我们记输入的序列为 { e i , i = 1 , . . . , r } \{ e_i,i=1,...,r \} {ei,i=1,...,r},其中每一个item可以看作为一个胶囊,所提取出的多兴趣表征为 { v j , j = 1 , . . . , K } \{ v_j,j=1,...,K \} {vj,j=1,...,K},其中每一个兴趣向量也可以看作是一个胶囊。很容易就知道,这里的 r r r表示用户行为序列的长度, K K K表示所提取出的多兴趣向量的个数,下面我们按照上述流程图中逐一理解每一行流程的含义:
- 1.第一行对输入序列胶囊 i i i与所产生的兴趣胶囊 j j j的权重 b i j b_{ij} bij初始化为0
- 2.第二行开始进行动态路由,这里和MIND一样,我们同样进行三次动态路由
- 3.第三行是对每一个序列胶囊 i i i对应的所有兴趣胶囊 j j j的权重 { b i j , j = 1 , . . . , K } \{b_{ij},j=1,...,K\} {bij,j=1,...,K}进行Softmax归一化
- 4.第四行是对每一个兴趣胶囊 j j j对应所有的序列胶囊 i i i执行第四行中的计算,这里要注意 W i j ∈ R d × d W_{ij} \in \mathbb{R}^{d \times d} Wij∈Rd×d为序列胶囊 i i i到兴趣胶囊 j j j的映射矩阵,这样就完成了对序列到单个兴趣胶囊的特征提取,以此类推我们可以得到所有的兴趣胶囊
- 5.我们这里对4中得到的兴趣胶囊的表征通过squash激活函数激活
s q u a s h ( z j ) = ∣ ∣ z j ∣ ∣ 2 1 + ∣ ∣ z j ∣ ∣ 2 z j ∣ ∣ z j ∣ ∣ squash(z_j)=\frac{{||z_{j}||}^2}{1+{||z_{j}||}^2}\frac{z_{j}}{{||z_{j}||}} squash(zj)=1+∣∣zj∣∣2∣∣zj∣∣2∣∣zj∣∣zj
- 6.最后我们通过第6行中的公式来更新 b i j b_{ij} bij
- 7.至此就完成了一次动态路由,我们将这个过程重复三次就得到了完整的动态路由,也就完成了多兴趣表征的建模
1.2 Comirec-DR与MIND的异同

在了解Comirec-DR的具体做法之后,可以看出,Comirec-DR与MIND的核心区别主要有两个:
- 1. b i j b_{ij} bij的初始化方式不一样,在Comirec-DR中对 b i j b_{ij} bij全部初始化为0,在MIND中对 b i j b_{ij} bij全部用高斯分布分布进行初始化
- 2.在进行序列胶囊与兴趣胶囊之间的映射转换时的变量声明方式不一样,在Comirec-DR中对于不同的序列胶囊 i i i与兴趣胶囊 j j j,我们都有一个独立的 W i j ∈ R d × d W_{ij} \in \mathbb{R}^{d \times d} Wij∈Rd×d来完成序列胶囊 i i i到兴趣胶囊 j j j之间的映射,但是在MIND中,其提出的B2I Dynamic Routing中将所有的序列胶囊 i i i与兴趣胶囊 j j j的映射矩阵使用同一矩阵 S ∈ R d × d S \in \mathbb{R}^{d \times d} S∈Rd×d
在其他部分Comirec-DR与MIND就并无差别了,可以看出Comirec-DR在核心思路上与MIND时统一的,只是在个别细节上的处理稍有不同
2.代码实践
!pip install faiss
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting faiss
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/ef/2e/dc5697e9ff6f313dcaf3afe5ca39d7d8334114cbabaed069d0026bbc3c61/faiss-1.5.3-cp37-cp37m-manylinux1_x86_64.whl (4.7 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m4.7/4.7 MB[0m [31m5.3 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: numpy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from faiss) (1.19.5)
Installing collected packages: faiss
Successfully installed faiss-1.5.3
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
import paddle
from paddle import nn
from paddle.io import DataLoader, Dataset
import paddle.nn.functional as F
import pandas as pd
import numpy as np
import copy
import os
import math
import random
from sklearn.metrics import roc_auc_score,log_loss
from sklearn.preprocessing import normalize
from tqdm import tqdm
from collections import defaultdict
from sklearn.manifold import TSNE
import seaborn as sns
from matplotlib import pyplot as plt
import faiss
import warnings
warnings.filterwarnings("ignore")
2.1 Dataset
class SeqnenceDataset(Dataset):
def __init__(self, config, df, phase='train'):
self.config = config
self.df = df
self.max_length = self.config['max_length']
self.df = self.df.sort_values(by=['user_id', 'timestamp'])
self.user2item = self.df.groupby('user_id')['item_id'].apply(list).to_dict()
self.user_list = self.df['user_id'].unique()
self.phase = phase
def __len__(self, ):
return len(self.user2item)
def __getitem__(self, index):
if self.phase == 'train':
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = random.choice(range(4, len(item_list))) # 从[8,len(item_list))中随机选择一个index
# k = np.random.randint(2,len(item_list))
item_id = item_list[k] # 该index对应的item加入item_id_list
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), paddle.to_tensor([item_id])
else:
user_id = self.user_list[index]
item_list = self.user2item[user_id]
hist_item_list = []
hist_mask_list = []
k = int(0.8 * len(item_list))
# k = len(item_list)-1
if k >= self.max_length: # 选取seq_len个物品
hist_item_list.append(item_list[k - self.max_length: k])
hist_mask_list.append([1.0] * self.max_length)
else:
hist_item_list.append(item_list[:k] + [0] * (self.max_length - k))
hist_mask_list.append([1.0] * k + [0.0] * (self.max_length - k))
return paddle.to_tensor(hist_item_list).squeeze(0), paddle.to_tensor(hist_mask_list).squeeze(
0), item_list[k:]
def get_test_gd(self):
self.test_gd = {}
for user in self.user2item:
item_list = self.user2item[user]
test_item_index = int(0.8 * len(item_list))
self.test_gd[user] = item_list[test_item_index:]
return self.test_gd
2.2 Comirec-DR 模型定义
class CapsuleNetwork(nn.Layer):
def __init__(self, hidden_size, seq_len, bilinear_type=2, interest_num=4, routing_times=3, hard_readout=True,
relu_layer=False):
super(CapsuleNetwork, self).__init__()
self.hidden_size = hidden_size # h
self.seq_len = seq_len # s
self.bilinear_type = bilinear_type
self.interest_num = interest_num
self.routing_times = routing_times
self.hard_readout = hard_readout
self.relu_layer = relu_layer
self.stop_grad = True
self.relu = nn.Sequential(
nn.Linear(self.hidden_size, self.hidden_size, bias_attr=False),
nn.ReLU()
)
if self.bilinear_type == 0: # MIND
self.linear = nn.Linear(self.hidden_size, self.hidden_size, bias_attr=False)
elif self.bilinear_type == 1:
self.linear = nn.Linear(self.hidden_size, self.hidden_size * self.interest_num, bias_attr=False)
else: # ComiRec_DR
self.w = self.create_parameter(
shape=[1, self.seq_len, self.interest_num * self.hidden_size, self.hidden_size])
def forward(self, item_eb, mask):
if self.bilinear_type == 0: # MIND
item_eb_hat = self.linear(item_eb) # [b, s, h]
item_eb_hat = paddle.repeat_interleave(item_eb_hat, self.interest_num, 2) # [b, s, h*in]
elif self.bilinear_type == 1:
item_eb_hat = self.linear(item_eb)
else: # ComiRec_DR
u = paddle.unsqueeze(item_eb, 2) # shape=(batch_size, maxlen, 1, embedding_dim)
item_eb_hat = paddle.sum(self.w[:, :self.seq_len, :, :] * u,
3) # shape=(batch_size, maxlen, hidden_size*interest_num)
item_eb_hat = paddle.reshape(item_eb_hat, (-1, self.seq_len, self.interest_num, self.hidden_size))
item_eb_hat = paddle.transpose(item_eb_hat, perm=[0,2,1,3])
# item_eb_hat = paddle.reshape(item_eb_hat, (-1, self.interest_num, self.seq_len, self.hidden_size))
# [b, in, s, h]
if self.stop_grad: # 截断反向传播,item_emb_hat不计入梯度计算中
item_eb_hat_iter = item_eb_hat.detach()
else:
item_eb_hat_iter = item_eb_hat
# b的shape=(b, in, s)
if self.bilinear_type > 0: # b初始化为0(一般的胶囊网络算法)
capsule_weight = paddle.zeros((item_eb_hat.shape[0], self.interest_num, self.seq_len))
else: # MIND使用高斯分布随机初始化b
capsule_weight = paddle.randn((item_eb_hat.shape[0], self.interest_num, self.seq_len))
for i in range(self.routing_times): # 动态路由传播3次
atten_mask = paddle.repeat_interleave(paddle.unsqueeze(mask, 1), self.interest_num, 1) # [b, in, s]
paddings = paddle.zeros_like(atten_mask)
# 计算c,进行mask,最后shape=[b, in, 1, s]
capsule_softmax_weight = F.softmax(capsule_weight, axis=-1)
capsule_softmax_weight = paddle.where(atten_mask==0, paddings, capsule_softmax_weight) # mask
capsule_softmax_weight = paddle.unsqueeze(capsule_softmax_weight, 2)
if i < 2:
# s=c*u_hat , (batch_size, interest_num, 1, seq_len) * (batch_size, interest_num, seq_len, hidden_size)
interest_capsule = paddle.matmul(capsule_softmax_weight,
item_eb_hat_iter) # shape=(batch_size, interest_num, 1, hidden_size)
cap_norm = paddle.sum(paddle.square(interest_capsule), -1, keepdim=True) # shape=(batch_size, interest_num, 1, 1)
scalar_factor = cap_norm / (1 + cap_norm) / paddle.sqrt(cap_norm + 1e-9) # shape同上
interest_capsule = scalar_factor * interest_capsule # squash(s)->v,shape=(batch_size, interest_num, 1, hidden_size)
# 更新b
delta_weight = paddle.matmul(item_eb_hat_iter, # shape=(batch_size, interest_num, seq_len, hidden_size)
paddle.transpose(interest_capsule, perm=[0,1,3,2])
# shape=(batch_size, interest_num, hidden_size, 1)
) # u_hat*v, shape=(batch_size, interest_num, seq_len, 1)
delta_weight = paddle.reshape(delta_weight, (
-1, self.interest_num, self.seq_len)) # shape=(batch_size, interest_num, seq_len)
capsule_weight = capsule_weight + delta_weight # 更新b
else:
interest_capsule = paddle.matmul(capsule_softmax_weight, item_eb_hat)
cap_norm = paddle.sum(paddle.square(interest_capsule), -1, keepdim=True)
scalar_factor = cap_norm / (1 + cap_norm) / paddle.sqrt(cap_norm + 1e-9)
interest_capsule = scalar_factor * interest_capsule
interest_capsule = paddle.reshape(interest_capsule, (-1, self.interest_num, self.hidden_size))
if self.relu_layer: # MIND模型使用book数据库时,使用relu_layer
interest_capsule = self.relu(interest_capsule)
return interest_capsule
class ComirecDR(nn.Layer):
def __init__(self, config):
super(ComirecDR, self).__init__()
self.config = config
self.embedding_dim = self.config['embedding_dim']
self.max_length = self.config['max_length']
self.n_items = self.config['n_items']
self.item_emb = nn.Embedding(self.n_items, self.embedding_dim, padding_idx=0)
self.capsule = CapsuleNetwork(self.embedding_dim, self.max_length, bilinear_type=2,
interest_num=self.config['K'])
self.loss_fun = nn.CrossEntropyLoss()
self.reset_parameters()
def calculate_loss(self,user_emb,pos_item):
all_items = self.item_emb.weight
scores = paddle.matmul(user_emb, all_items.transpose([1, 0]))
return self.loss_fun(scores,pos_item)
def output_items(self):
return self.item_emb.weight
def reset_parameters(self, initializer=None):
for weight in self.parameters():
paddle.nn.initializer.KaimingNormal(weight)
def forward(self, item_seq, mask, item, train=True):
if train:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
item_e = self.item_emb(item).squeeze(1)
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
cos_res = paddle.bmm(multi_interest_emb, item_e.squeeze(1).unsqueeze(-1))
k_index = paddle.argmax(cos_res, axis=1)
best_interest_emb = paddle.rand((multi_interest_emb.shape[0], multi_interest_emb.shape[2]))
for k in range(multi_interest_emb.shape[0]):
best_interest_emb[k, :] = multi_interest_emb[k, k_index[k], :]
loss = self.calculate_loss(best_interest_emb,item)
output_dict = {
'user_emb': multi_interest_emb,
'loss': loss,
}
else:
seq_emb = self.item_emb(item_seq) # Batch,Seq,Emb
multi_interest_emb = self.capsule(seq_emb, mask) # Batch,K,Emb
output_dict = {
'user_emb': multi_interest_emb,
}
return output_dict
2.3 Pipeline
config = {
'train_path':'/home/aistudio/data/data173799/train_enc.csv',
'valid_path':'/home/aistudio/data/data173799/valid_enc.csv',
'test_path':'/home/aistudio/data/data173799/test_enc.csv',
'lr':1e-4,
'Epoch':100,
'batch_size':256,
'embedding_dim':16,
'max_length':20,
'n_items':15406,
'K':4
}
def my_collate(batch):
hist_item, hist_mask, item_list = list(zip(*batch))
hist_item = [x.unsqueeze(0) for x in hist_item]
hist_mask = [x.unsqueeze(0) for x in hist_mask]
hist_item = paddle.concat(hist_item,axis=0)
hist_mask = paddle.concat(hist_mask,axis=0)
return hist_item,hist_mask,item_list
def save_model(model, path):
if not os.path.exists(path):
os.makedirs(path)
paddle.save(model.state_dict(), path + 'model.pdparams')
def load_model(model, path):
state_dict = paddle.load(path + 'model.pdparams')
model.set_state_dict(state_dict)
print('model loaded from %s' % path)
return model
2.4 基于Faiss的向量召回
def get_predict(model, test_data, hidden_size, topN=20):
item_embs = model.output_items().cpu().detach().numpy()
item_embs = normalize(item_embs, norm='l2')
gpu_index = faiss.IndexFlatIP(hidden_size)
gpu_index.add(item_embs)
test_gd = dict()
preds = dict()
user_id = 0
for (item_seq, mask, targets) in tqdm(test_data):
# 获取用户嵌入
# 多兴趣模型,shape=(batch_size, num_interest, embedding_dim)
# 其他模型,shape=(batch_size, embedding_dim)
user_embs = model(item_seq,mask,None,train=False)['user_emb']
user_embs = user_embs.cpu().detach().numpy()
# 用内积来近邻搜索,实际是内积的值越大,向量越近(越相似)
if len(user_embs.shape) == 2: # 非多兴趣模型评估
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
test_gd[user_id] = iid_list
preds[user_id] = I[i,:]
user_id +=1
else: # 多兴趣模型评估
ni = user_embs.shape[1] # num_interest
user_embs = np.reshape(user_embs,
[-1, user_embs.shape[-1]]) # shape=(batch_size*num_interest, embedding_dim)
user_embs = normalize(user_embs, norm='l2').astype('float32')
D, I = gpu_index.search(user_embs, topN) # Inner Product近邻搜索,D为distance,I是index
# D,I = faiss.knn(user_embs, item_embs, topN,metric=faiss.METRIC_INNER_PRODUCT)
for i, iid_list in enumerate(targets): # 每个用户的label列表,此处item_id为一个二维list,验证和测试是多label的
recall = 0
dcg = 0.0
item_list_set = []
# 将num_interest个兴趣向量的所有topN近邻物品(num_interest*topN个物品)集合起来按照距离重新排序
item_list = list(
zip(np.reshape(I[i * ni:(i + 1) * ni], -1), np.reshape(D[i * ni:(i + 1) * ni], -1)))
item_list.sort(key=lambda x: x[1], reverse=True) # 降序排序,内积越大,向量越近
for j in range(len(item_list)): # 按距离由近到远遍历推荐物品列表,最后选出最近的topN个物品作为最终的推荐物品
if item_list[j][0] not in item_list_set and item_list[j][0] != 0:
item_list_set.append(item_list[j][0])
if len(item_list_set) >= topN:
break
test_gd[user_id] = iid_list
preds[user_id] = item_list_set
user_id +=1
return test_gd, preds
def evaluate(preds,test_gd, topN=50):
total_recall = 0.0
total_ndcg = 0.0
total_hitrate = 0
for user in test_gd.keys():
recall = 0
dcg = 0.0
item_list = test_gd[user]
for no, item_id in enumerate(item_list):
if item_id in preds[user][:topN]:
recall += 1
dcg += 1.0 / math.log(no+2, 2)
idcg = 0.0
for no in range(recall):
idcg += 1.0 / math.log(no+2, 2)
total_recall += recall * 1.0 / len(item_list)
if recall > 0:
total_ndcg += dcg / idcg
total_hitrate += 1
total = len(test_gd)
recall = total_recall / total
ndcg = total_ndcg / total
hitrate = total_hitrate * 1.0 / total
return {f'recall@{topN}': recall, f'ndcg@{topN}': ndcg, f'hitrate@{topN}': hitrate}
# 指标计算
def evaluate_model(model, test_loader, embedding_dim,topN=20):
test_gd, preds = get_predict(model, test_loader, embedding_dim, topN=topN)
return evaluate(preds, test_gd, topN=topN)
# 读取数据
train_df = pd.read_csv(config['train_path'])
valid_df = pd.read_csv(config['valid_path'])
test_df = pd.read_csv(config['test_path'])
train_dataset = SeqnenceDataset(config, train_df, phase='train')
valid_dataset = SeqnenceDataset(config, valid_df, phase='test')
test_dataset = SeqnenceDataset(config, test_df, phase='test')
train_loader = DataLoader(dataset=train_dataset, batch_size=config['batch_size'], shuffle=True,num_workers=8)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=config['batch_size'], shuffle=False,collate_fn=my_collate)
test_loader = DataLoader(dataset=test_dataset, batch_size=config['batch_size'], shuffle=False,collate_fn=my_collate)
model = ComirecDR(config)
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=config['lr'])
log_df = pd.DataFrame()
best_reacall = -1
exp_path = './exp/ml-20m_softmax/MIND_{}_{}_{}/'.format(config['lr'],config['batch_size'],config['embedding_dim'])
os.makedirs(exp_path,exist_ok=True,mode=0o777)
patience = 5
last_improve_epoch = 1
log_csv = exp_path+'log.csv'
# *****************************************************train*********************************************
for epoch in range(1, 1 + config['Epoch']):
# try :
pbar = tqdm(train_loader)
model.train()
loss_list = []
acc_50_list = []
print()
print('Training:')
print()
for batch_data in pbar:
(item_seq, mask, item) = batch_data
output_dict = model(item_seq, mask, item)
loss = output_dict['loss']
loss.backward()
optimizer.step()
optimizer.clear_grad()
loss_list.append(loss.item())
pbar.set_description('Epoch [{}/{}]'.format(epoch,config['Epoch']))
pbar.set_postfix(loss = np.mean(loss_list))
# *****************************************************valid*********************************************
print('Valid')
recall_metric = evaluate_model(model, valid_loader, config['embedding_dim'], topN=50)
print(recall_metric)
recall_metric['phase'] = 'valid'
log_df = log_df.append(recall_metric, ignore_index=True)
log_df.to_csv(log_csv)
if recall_metric['recall@50'] > best_reacall:
save_model(model,exp_path)
best_reacall = recall_metric['recall@50']
last_improve_epoch = epoch
if epoch - last_improve_epoch > patience:
break
print('Testing')
model = load_model(model,exp_path)
recall_metric = evaluate_model(model, test_loader, config['embedding_dim'], topN=50)
print(recall_metric)
recall_metric['phase'] = 'test'
log_df = log_df.append(recall_metric, ignore_index=True)
log_df.to_csv(log_csv)
log_df
| hitrate@50 | ndcg@50 | phase | recall@50 | |
|---|---|---|---|---|
| 0 | 0.051331 | 0.017455 | valid | 0.003022 |
| 1 | 0.051621 | 0.017507 | valid | 0.003038 |
| 2 | 0.051549 | 0.017512 | valid | 0.003074 |
| 3 | 0.051839 | 0.017608 | valid | 0.003109 |
| 4 | 0.052058 | 0.017713 | valid | 0.003161 |
| 5 | 0.051912 | 0.017700 | valid | 0.003180 |
| 6 | 0.052203 | 0.017827 | valid | 0.003232 |
| 7 | 0.052348 | 0.018037 | valid | 0.003400 |
| 8 | 0.052494 | 0.018230 | valid | 0.003418 |
| 9 | 0.053003 | 0.018595 | valid | 0.003567 |
| 10 | 0.055911 | 0.020482 | valid | 0.004170 |
| 11 | 0.067180 | 0.027474 | valid | 0.007079 |
| 12 | 0.501381 | 0.270084 | valid | 0.100356 |
| 13 | 0.506471 | 0.273775 | valid | 0.099967 |
| 14 | 0.507416 | 0.278181 | valid | 0.103172 |
| 15 | 0.505308 | 0.277379 | valid | 0.103891 |
| 16 | 0.503926 | 0.279276 | valid | 0.107002 |
| 17 | 0.509670 | 0.283588 | valid | 0.110318 |
| 18 | 0.510906 | 0.284624 | valid | 0.112103 |
| 19 | 0.503853 | 0.280064 | valid | 0.109354 |
| 20 | 0.500654 | 0.276844 | valid | 0.107839 |
| 21 | 0.493311 | 0.270872 | valid | 0.104308 |
| 22 | 0.485895 | 0.265949 | valid | 0.101852 |
| 23 | 0.481533 | 0.263066 | valid | 0.100359 |
| 24 | 0.475643 | 0.257638 | valid | 0.097063 |
| 25 | 0.515147 | 0.289965 | test | 0.112846 |
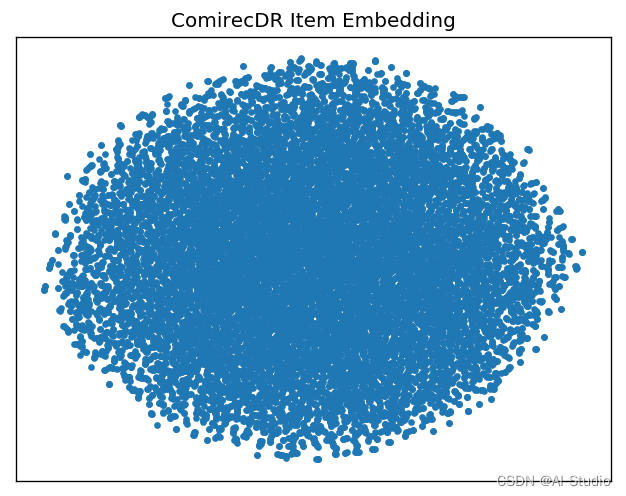
2.5 基于TSNE的Item Embedding分布可视化
def plot_embedding(data, title):
x_min, x_max = np.min(data, 0), np.max(data, 0)
data = (data - x_min) / (x_max - x_min)
fig = plt.figure(dpi=120)
plt.scatter(data[:,0], data[:,1], marker='.')
plt.xticks([])
plt.yticks([])
plt.title(title)
plt.show()
item_emb = model.output_items().numpy()
tsne_emb = TSNE(n_components=2).fit_transform(item_emb)
plot_embedding(tsne_emb,'ComirecDR Item Embedding')
3.总结
这里我们学习了Comirec论文中的提出的第一个模型:Comirec-DR,这个模型的灵感同样也是来自于胶囊网络中的动态路由算法,我们详细的介绍了Comirec-DR中的动态路由算法,同时也将Comirec-DR与MIND算法进行了对比,通过对比我们发现Comirec-DR与MIND算法的核心思路基本相同,只是在个别细节的处理有所区别,通过对比我们也可以更加深入的理解MIND与Comirec-DR算法。
4.参考资料
- https://aistudio.baidu.com/aistudio/projectdetail/4869792
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)