
[论文复现赛第七期] GFPGAN
基于PaddleGAN复现GFPGAN,并合入PaddleGAN
1 模型结构
GFP-GAN利用丰富和多样化的先验封装在预训练的脸GAN盲脸恢复。通过空间特征变换层,将生成式面部先验(GFP)融合到人脸恢复过程中,使人脸恢复过程更容易实现
论文说,之前的研究GAN中,通常产生的图像保真度较低,因为低维潜在码不足以指导准确还原。
论文提出了,以在一次向前传递中实现真实和保真的良好平衡的网络结构,具体地说,GFPGAN包括降解去除模块和作为面部先验的预训练的面部GAN。
1.1 整体结构
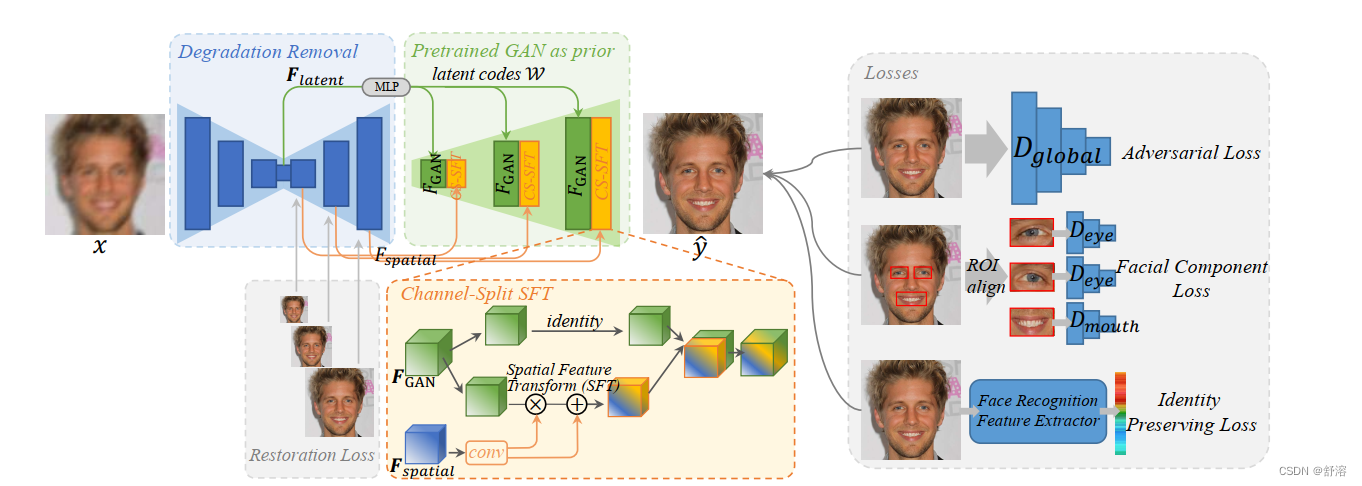
包括一个降解去除模块(U-Net)和一个预先训练的面部GAN作为面部先验。它们之间通过潜在的代码映射和若干通道分割空间特征变换进行连接(CS-SFT)层。
训练时,使用了,中间修复损失去除复杂退化;利用鉴别器增强面部细节的面部成分丢失;保留身份丢失保留面子的身份
1.2 降解去除模块
U-Net结构作为降解去除模块
降级删除模块被设计为显式删除以上降解和提取“干净”的特点和扁平化Fspatial,减轻后续模块的负担。采用U-Net结构作为降解去除模块,因为它可以增加大模糊的接受域,生成多分辨率特征。
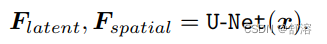
为了对去除退化有一个中间监督,在训练的早期阶段在每个分辨率尺度上使用L1 restoration loss 。
1.3 生成面部先验和潜在代码映射
不直接生成最终图像,而是生成最接近人脸的中间卷积特征FGAN,因为它包含更多的细节,可以通过输入特征进一步调制,以获得更好的保真度
潜在码W通过预训练GAN中的每个卷积层,生成每个分辨率尺度的GAN特征。
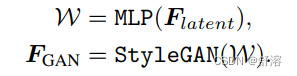
1.4 通道分割空间特征变换
在每个分辨率尺度下,我们生成一对仿射变换参数(α;β)通过几个卷积层从输入特征f空间。然后,通过缩放和移位的方式进行调制
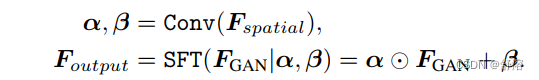
为了更好地平衡真实度和保真度,提出了通道分割空间特征变换(CSSFT)层,该层通过输入特征Fspatial(有助于逼真度)对部分GAN特征进行空间调制,而让左侧GAN特征(有助于真实度)直接通过
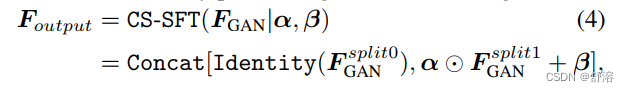

这使得,CS-SFT具有直接融合先验信息和输入图像有效调制的优点,从而在纹理的忠实度和保真度之间达到很好的平衡。
1.5 模型目标和损失函数
1.5.1 reconstruction loss
采用L1 loss 和 perceptual loss 作为 reconstruction loss
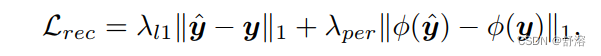
1.5.2 Adversarial Loss
Similar to StyleGAN2
1.5.3 Facial Component Loss
为了进一步增强感知显著的人脸成分,我们引入了人脸成分丢失和左眼、右眼和嘴的局部鉴别。
1.5.4 Identity Preserving Loss
根据输入面特征嵌入定义损失。具体来说,采用预先训练的人脸识别ArcFace模型,该模型捕获了身份识别的最显著特征。身份保留损失使得还原结果在紧凑的深特征空间中与地面真值有很小的距离
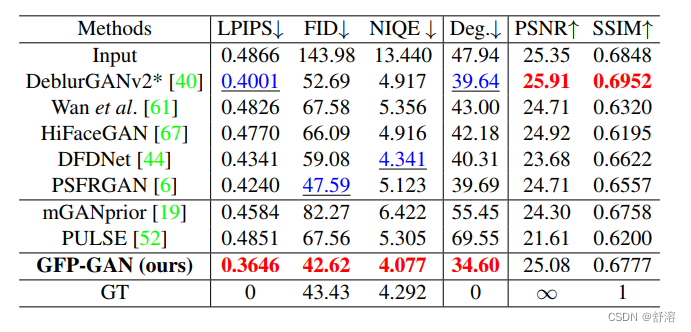
1.6 实验结果
2 快速开始修复图片
设置img_path为自己的图片路径
输出结果将保存在/home/aistudio/work/PaddleGAN/test目录下的out_gfpgan.png
%cd /home/aistudio/work/
!git clone https://github.com/PaddlePaddle/PaddleGAN.git
# 配置环境
%cd /home/aistudio/work/PaddleGAN/
!pip install -r requirements.txt -q
%env PYTHONPATH=.:$PYTHONPATH
%env CUDA_VISIBLE_DEVICES=0
import paddle
import cv2
import numpy as np
import sys
from ppgan.faceutils.face_enhancement.gfpgan_enhance import gfp_FaceEnhancement
# 图片路径可以用自己的
img_path='test/2.png'
img = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 这是原来的模糊图片
cv2.imwrite('test/outlq.png',img)
img=np.array(img).astype('float32')
faceenhancer = gfp_FaceEnhancement()
img = faceenhancer.enhance_from_image(img)
# 这是生成的清晰图片
cv2.imwrite('test/out_gfpgan.png',img)
3 复现结果:
本项目使用2000张celeba-val数据集,40000张FFHQ数据集,训练210000次后完成
210000次iter后,达到了
3.1 复现指标
ppgan.engine.trainer INFO: Metric psnr: 65.0461
(该指标越大越好)
ppgan.engine.trainer INFO: Metric fid: 36.8068
(该指标越小越好)
ppgan.engine.trainer INFO: Metric LPIPS: 0.3817
(该指标越小越好)
复现指标为:
原代码中iter总共800000
LPIPS=0.3646, FID=42.62,PSNR=25.08
3.2 复现可视化展示
3.2.1 模糊的图片

3.2.2 模型修复后

3.2.3 测试集标准答案


4 复现代码
4.1 模型配置
total_iters: 800000
output_dir: output
find_unused_parameters: True
log_config:
interval: 100
visiual_interval: 100
snapshot_config:
interval: 30000
enable_visualdl: False
validate:
interval: 5000
save_img: True
metrics:
psnr:
name: PSNR
crop_border: 0
test_y_channel: false
fid:
name: FID
batch_size: 8
model:
name: GFPGANModel
network_g:
name: GFPGANv1
out_size: 512
num_style_feat: 512
channel_multiplier: 1
resample_kernel: [1, 3, 3, 1]
decoder_load_path: https://paddlegan.bj.bcebos.com/models/StyleGAN2_FFHQ512_Cmul1.pdparams
fix_decoder: true
num_mlp: 8
lr_mlp: 0.01
input_is_latent: true
different_w: true
narrow: 1
sft_half: true
network_d:
name: StyleGAN2DiscriminatorGFPGAN
out_size: 512
channel_multiplier: 1
resample_kernel: [1, 3, 3, 1]
network_d_left_eye:
type: FacialComponentDiscriminator
network_d_right_eye:
type: FacialComponentDiscriminator
network_d_mouth:
type: FacialComponentDiscriminator
network_identity:
name: ResNetArcFace
block: IRBlock
layers: [2, 2, 2, 2]
use_se: False
path:
image_visual: gfpgan_train_outdir
pretrain_network_g: ~
param_key_g: params_ema
strict_load_g: ~
pretrain_network_d: ~
pretrain_network_d_left_eye: https://paddlegan.bj.bcebos.com/models/Facial_component_discriminator.pdparams
pretrain_network_d_right_eye: https://paddlegan.bj.bcebos.com/models/Facial_component_discriminator.pdparams
pretrain_network_d_mouth: https://paddlegan.bj.bcebos.com/models/Facial_component_discriminator.pdparams
pretrain_network_identity: https://paddlegan.bj.bcebos.com/models/arcface_resnet18.pdparams
# losses
# pixel loss
pixel_opt:
name: GFPGANL1Loss
loss_weight: !!float 1e-1
reduction: mean
# L1 loss used in pyramid loss, component style loss and identity loss
L1_opt:
name: GFPGANL1Loss
loss_weight: 1
reduction: mean
# image pyramid loss
pyramid_loss_weight: 1
remove_pyramid_loss: 50000
# perceptual loss (content and style losses)
perceptual_opt:
name: GFPGANPerceptualLoss
layer_weights:
# before relu
"conv1_2": 0.1
"conv2_2": 0.1
"conv3_4": 1
"conv4_4": 1
"conv5_4": 1
vgg_type: vgg19
use_input_norm: true
perceptual_weight: !!float 1
style_weight: 50
range_norm: true
criterion: l1
# gan loss
gan_opt:
name: GFPGANGANLoss
gan_type: wgan_softplus
loss_weight: !!float 1e-1
# r1 regularization for discriminator
r1_reg_weight: 10
# facial component loss
gan_component_opt:
name: GFPGANGANLoss
gan_type: vanilla
real_label_val: 1.0
fake_label_val: 0.0
loss_weight: !!float 1
comp_style_weight: 200
# identity loss
identity_weight: 10
net_d_iters: 1
net_d_init_iters: 0
net_d_reg_every: 16
export_model:
- { name: "net_g_ema", inputs_num: 1 }
dataset:
train:
name: FFHQDegradationDataset
dataroot_gt: data/gfpgan_data/train
io_backend:
type: disk
use_hflip: true
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
out_size: 512
blur_kernel_size: 41
kernel_list: ["iso", "aniso"]
kernel_prob: [0.5, 0.5]
blur_sigma: [0.1, 10]
downsample_range: [0.8, 8]
noise_range: [0, 20]
jpeg_range: [60, 100]
# color jitter and gray
color_jitter_prob: 0.3
color_jitter_shift: 20
color_jitter_pt_prob: 0.3
gray_prob: 0.01
# If you do not want colorization, please set
# color_jitter_prob: ~
# color_jitter_pt_prob: ~
# gray_prob: 0.01
# gt_gray: True
crop_components: true
component_path: https://paddlegan.bj.bcebos.com/models/FFHQ_eye_mouth_landmarks_512.pdparams
eye_enlarge_ratio: 1.4
# data loader
use_shuffle: true
num_workers: 4
batch_size: 1
prefetch_mode: ~
test:
# Please modify accordingly to use your own validation
# Or comment the val block if do not need validation during training
name: PairedImageDataset
dataroot_lq: data/gfpgan_data/lq
dataroot_gt: data/gfpgan_data/gt
io_backend:
type: disk
mean: [0.5, 0.5, 0.5]
std: [0.5, 0.5, 0.5]
scale: 1
num_workers: 4
batch_size: 8
phase: val
lr_scheduler:
name: MultiStepDecay
learning_rate: 0.002
milestones: [600000, 700000]
gamma: 0.5
optimizer:
optim_g:
name: Adam
beta1: 0
beta2: 0.99
optim_d:
name: Adam
beta1: 0
beta2: 0.99
optim_component:
name: Adam
beta1: 0.9
beta2: 0.99
4.2 模型创建(部分代码)
class GFPGANv1(nn.Layer):
"""The GFPGAN architecture: Unet + StyleGAN2 decoder with SFT.
Ref: GFP-GAN: Towards Real-World Blind Face Restoration with Generative Facial Prior.
Args:
out_size (int): The spatial size of outputs.
num_style_feat (int): Channel number of style features. Default: 512.
channel_multiplier (int): Channel multiplier for large networks of StyleGAN2. Default: 2.
resample_kernel (list[int]): A list indicating the 1D resample kernel magnitude. A cross production will be
applied to extent 1D resample kernel to 2D resample kernel. Default: (1, 3, 3, 1).
decoder_load_path (str): The path to the pre-trained decoder model (usually, the StyleGAN2). Default: None.
fix_decoder (bool): Whether to fix the decoder. Default: True.
num_mlp (int): Layer number of MLP style layers. Default: 8.
lr_mlp (float): Learning rate multiplier for mlp layers. Default: 0.01.
input_is_latent (bool): Whether input is latent style. Default: False.
different_w (bool): Whether to use different latent w for different layers. Default: False.
narrow (float): The narrow ratio for channels. Default: 1.
sft_half (bool): Whether to apply SFT on half of the input channels. Default: False.
"""
def __init__(self,
out_size,
num_style_feat=512,
channel_multiplier=1,
resample_kernel=(1, 3, 3, 1),
decoder_load_path=None,
fix_decoder=True,
num_mlp=8,
lr_mlp=0.01,
input_is_latent=False,
different_w=False,
narrow=1,
sft_half=False):
super(GFPGANv1, self).__init__()
self.input_is_latent = input_is_latent
self.different_w = different_w
self.num_style_feat = num_style_feat
unet_narrow = narrow * 0.5
channels = {
'4': int(512 * unet_narrow),
'8': int(512 * unet_narrow),
'16': int(512 * unet_narrow),
'32': int(512 * unet_narrow),
'64': int(256 * channel_multiplier * unet_narrow),
'128': int(128 * channel_multiplier * unet_narrow),
'256': int(64 * channel_multiplier * unet_narrow),
'512': int(32 * channel_multiplier * unet_narrow),
'1024': int(16 * channel_multiplier * unet_narrow)
}
self.log_size = int(math.log(out_size, 2))
first_out_size = 2**int(math.log(out_size, 2))
self.conv_body_first = ConvLayer(3,
channels[f'{first_out_size}'],
1,
bias=True,
activate=True)
in_channels = channels[f'{first_out_size}']
self.conv_body_down = nn.LayerList()
for i in range(self.log_size, 2, -1):
out_channels = channels[f'{2 ** (i - 1)}']
self.conv_body_down.append(
ResBlock(in_channels, out_channels, resample_kernel))
in_channels = out_channels
self.final_conv = ConvLayer(in_channels,
channels['4'],
3,
bias=True,
activate=True)
in_channels = channels['4']
self.conv_body_up = nn.LayerList()
for i in range(3, self.log_size + 1):
out_channels = channels[f'{2 ** i}']
self.conv_body_up.append(ResUpBlock(in_channels, out_channels))
in_channels = out_channels
self.toRGB = nn.LayerList()
for i in range(3, self.log_size + 1):
self.toRGB.append(
EqualConv2d(channels[f'{2 ** i}'],
3,
1,
stride=1,
padding=0,
bias=True,
bias_init_val=0))
if different_w:
linear_out_channel = (int(math.log(out_size, 2)) * 2 -
2) * num_style_feat
else:
linear_out_channel = num_style_feat
self.final_linear = EqualLinear(channels['4'] * 4 * 4,
linear_out_channel,
bias=True,
bias_init_val=0,
lr_mul=1,
activation=None)
self.stylegan_decoder = StyleGAN2GeneratorSFT(
out_size=out_size,
num_style_feat=num_style_feat,
num_mlp=num_mlp,
channel_multiplier=channel_multiplier,
resample_kernel=resample_kernel,
lr_mlp=lr_mlp,
narrow=narrow,
sft_half=sft_half)
if decoder_load_path:
decoder_load_path = get_path_from_url(decoder_load_path)
self.stylegan_decoder.set_state_dict(paddle.load(decoder_load_path))
if fix_decoder:
for _, param in self.stylegan_decoder.named_parameters():
param.stop_gradient = True
self.condition_scale = nn.LayerList()
self.condition_shift = nn.LayerList()
for i in range(3, self.log_size + 1):
out_channels = channels[f'{2 ** i}']
if sft_half:
sft_out_channels = out_channels
else:
sft_out_channels = out_channels * 2
self.condition_scale.append(
nn.Sequential(
EqualConv2d(out_channels,
out_channels,
3,
stride=1,
padding=1,
bias=True,
bias_init_val=0), ScaledLeakyReLU(0.2),
EqualConv2d(out_channels,
sft_out_channels,
3,
stride=1,
padding=1,
bias=True,
bias_init_val=1)))
self.condition_shift.append(
nn.Sequential(
EqualConv2d(out_channels,
out_channels,
3,
stride=1,
padding=1,
bias=True,
bias_init_val=0), ScaledLeakyReLU(0.2),
EqualConv2d(out_channels,
sft_out_channels,
3,
stride=1,
padding=1,
bias=True,
bias_init_val=0)))
def forward(self,
x,
return_latents=False,
return_rgb=True,
randomize_noise=False):
"""Forward function for GFPGANv1.
Args:
x (Tensor): Input images.
return_latents (bool): Whether to return style latents. Default: False.
return_rgb (bool): Whether return intermediate rgb images. Default: True.
randomize_noise (bool): Randomize noise, used when 'noise' is False. Default: True.
"""
conditions = []
unet_skips = []
out_rgbs = []
feat = self.conv_body_first(x)
for i in range(self.log_size - 2):
feat = self.conv_body_down[i](feat)
unet_skips.insert(0, feat)
feat = self.final_conv(feat)
style_code = self.final_linear(feat.reshape([feat.shape[0], -1]))
if self.different_w:
style_code = style_code.reshape(
[style_code.shape[0], -1, self.num_style_feat])
for i in range(self.log_size - 2):
feat = feat + unet_skips[i]
feat = self.conv_body_up[i](feat)
scale = self.condition_scale[i](feat)
conditions.append(scale.clone())
shift = self.condition_shift[i](feat)
conditions.append(shift.clone())
if return_rgb:
out_rgbs.append(self.toRGB[i](feat))
image, _ = self.stylegan_decoder([style_code],
conditions,
return_latents=return_latents,
input_is_latent=self.input_is_latent,
randomize_noise=randomize_noise)
return image, out_rgbs
4.3 面部判别器
class FacialComponentDiscriminator(nn.Layer):
"""Facial component (eyes, mouth, noise) discriminator used in GFPGAN.
"""
def __init__(self):
super(FacialComponentDiscriminator, self).__init__()
self.conv1 = ConvLayer(3,
64,
3,
downsample=False,
resample_kernel=(1, 3, 3, 1),
bias=True,
activate=True)
self.conv2 = ConvLayer(64,
128,
3,
downsample=True,
resample_kernel=(1, 3, 3, 1),
bias=True,
activate=True)
self.conv3 = ConvLayer(128,
128,
3,
downsample=False,
resample_kernel=(1, 3, 3, 1),
bias=True,
activate=True)
self.conv4 = ConvLayer(128,
256,
3,
downsample=True,
resample_kernel=(1, 3, 3, 1),
bias=True,
activate=True)
self.conv5 = ConvLayer(256,
256,
3,
downsample=False,
resample_kernel=(1, 3, 3, 1),
bias=True,
activate=True)
self.final_conv = ConvLayer(256, 1, 3, bias=True, activate=False)
def forward(self, x, return_feats=False):
"""Forward function for FacialComponentDiscriminator.
Args:
x (Tensor): Input images.
return_feats (bool): Whether to return intermediate features. Default: False.
"""
feat = self.conv1(x)
feat = self.conv3(self.conv2(feat))
rlt_feats = []
if return_feats:
rlt_feats.append(feat.clone())
feat = self.conv5(self.conv4(feat))
if return_feats:
rlt_feats.append(feat.clone())
out = self.final_conv(feat)
if return_feats:
return out, rlt_feats
else:
return out, None
具体可以参考 PaddleGAN库内的GFPGAN.md
4.4 开始训练
%cd /home/aistudio/work/paddle-gan-develop
!python -u tools/main.py --config-file configs/gpfgan_1024_ffhq.yaml
# 多卡训练
!CUDA_VISIBLE_DEVICES=0,1,2,3
!python -m paddle.distributed.launch tools/main.py \
--config-file configs/gpfgan_ffhq1024.yaml
4.5 模型测试
!python tools/main.py -c configs/gfpgan_ffhq1024.yaml --load GFPGAN.pdparams --evaluate-only
5 复现感想
本次复现极大的提高了我的代码水平,复现过程中最重要的是根据论文明白模型结构,并且根据结构改代码再对齐,才能得到一个不错的精度。
遇到问题先看报错,再想,再搜索,再提问!
感谢百度举办的这次活动给我这个机会
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)