
CvT论文复现:Convolutions与Transformers的结合
【论文复现第7期】CvT通过convolutional token embedding机制和convolutional projection机制,在ViT中引入卷积,改善了ViT的性能和效率。
摘要
微软团队提出了一个新的架构,名为CvT,它通过在ViT中引入卷积来改进ViT的性能和效率。这是通过两个主要的改进来实现的:一个是新的卷积token embedding,一个是利用卷积投影的卷积变形器块。这些变化为ViT架构引入了卷积神经网络(CNN)的理想特性(如平移、缩放和失真不变性),同时保持了变形器的优点(如动态注意力、全局背景和更好的概括性)。通过广泛的实验验证了CvT在ImageNet-1k上比其他ViT和ResNets取得了最先进的性能,而且参数更少,FLOPs更低。此外,在更大的数据集(如ImageNet-22k)上进行预训练并针对下游任务进行微调时,性能的提升也得以保持。
1. CvT: Introducing Convolutions to Vision Transformers.
1.1 总体架构
CvT的pipeline如下图所示,是一种级联联的结构,每一个stage包含两部分:Convolutional Token Embedding模块和若干个Convolutional Transformer blocks。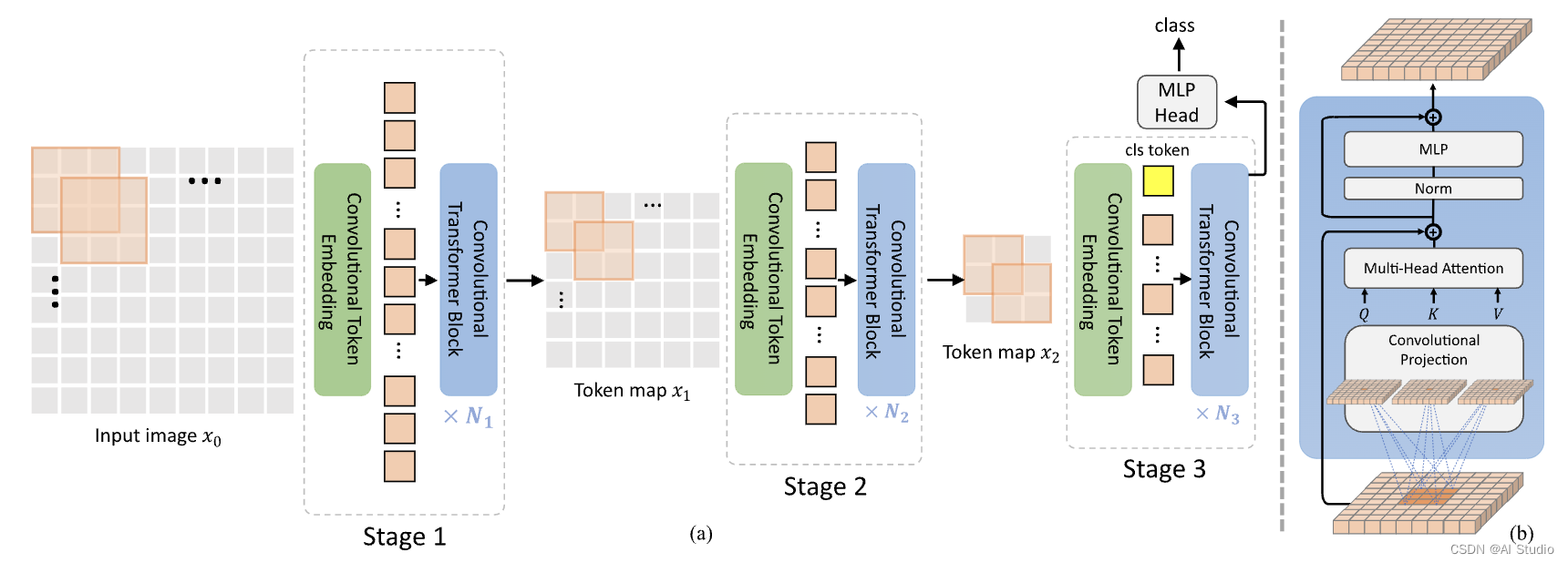
1.2 Convolutional Token Embedding
Convolutional Token Embedding的主要作用是来模拟 CNN 的下采样设计,在减少 Token 的数量的同时增加其的宽度。
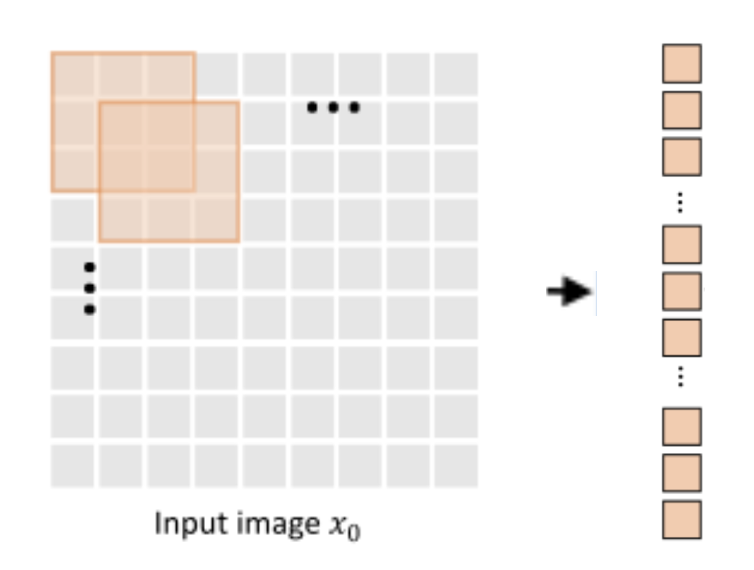
下面是 Convolutional Token Embedding 的实现代码:
class ConvEmbed(nn.Layer):
def __init__(self,
patch_size=7,
in_chans=3,
embed_dim=64,
stride=4,
padding=2,
norm_layer=None):
super().__init__()
self.patch_size = patch_size
self.proj = nn.Conv2D(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else None
def forward(self, x):
x = self.proj(x)
B, C, H, W = x.shape
x = rearrange(x, 'b c h w -> b (h w) c')
if self.norm:
x = self.norm(x)
x = rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
return x
1.3 Convolutional Projection
CvT中提出了卷积投影(Convolutional Projection),这部分在 Convolutional Transformer Block 里,从下图中我们可以看见,卷积投影用于生成 MHSA(Multi-Head Self Attention)所需要的 Q、K、V。
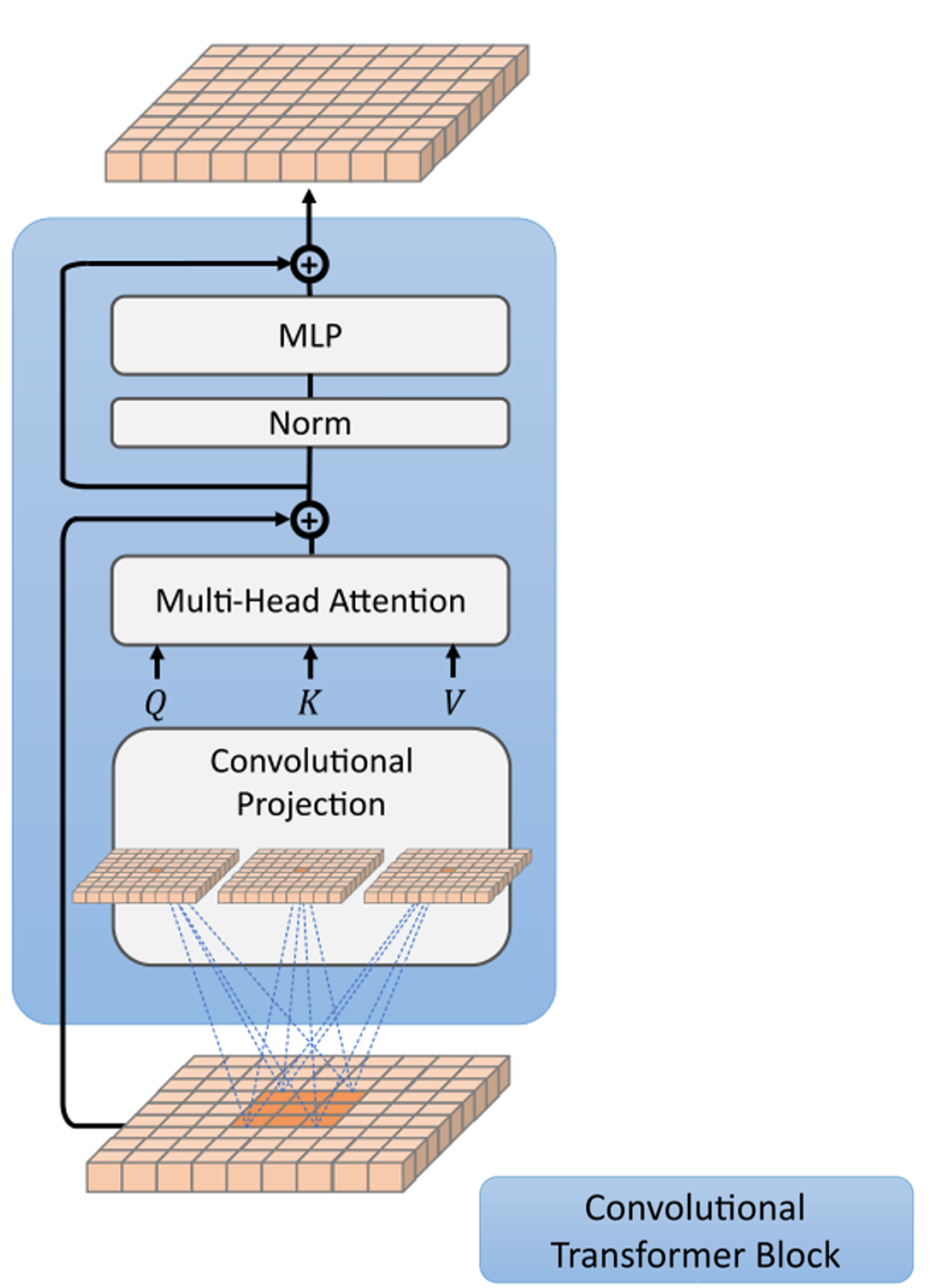
那么使用卷积投影和 ViT 的标准线性投影有什么区别呢,这么做有什么好处吗?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-M2uYt6Hq-1668436882686)(https://ai-studio-static-online.cdn.bcebos.com/f8964e27e2d04c64bc9f96a486bfab606dacc88944094539857194eebc2ced9a)]
在上方对比图中,左边是 ViT 中标准的线性投影,中边是CvT中的卷积投影。
在卷积投影中,首先将一维 tokens 通过 reshape 变成二维的 features,然后用卷积分别对每个位置提取 token 特征,最后 flatten 得倒一维的tokens 特征,即 Q、K、V。
这过程说简单点就是将卷积的局部性进入 tokens 的计算,目标是实现局部空间的上下文建模。
下面是 Convolutional Transformer Attention 的实现代码:
class Attention(nn.Layer):
def __init__(self,
dim_in,
dim_out,
num_heads,
qkv_bias=False,
attn_drop=0.,
proj_drop=0.,
method='dw_bn',
kernel_size=3,
stride_kv=1,
stride_q=1,
padding_kv=1,
padding_q=1,
with_cls_token=True,
**kwargs):
super().__init__()
self.stride_kv = stride_kv
self.stride_q = stride_q
self.dim = dim_out
self.num_heads = num_heads
# head_dim = self.qkv_dim // num_heads
self.scale = dim_out**-0.5
self.with_cls_token = with_cls_token
self.conv_proj_q = self._build_projection(
dim_in, dim_out, kernel_size, padding_q, stride_q, 'linear'
if method == 'avg' else method)
self.conv_proj_k = self._build_projection(
dim_in, dim_out, kernel_size, padding_kv, stride_kv, method)
self.conv_proj_v = self._build_projection(
dim_in, dim_out, kernel_size, padding_kv, stride_kv, method)
self.proj_q = nn.Linear(dim_in, dim_out, bias_attr=qkv_bias)
self.proj_k = nn.Linear(dim_in, dim_out, bias_attr=qkv_bias)
self.proj_v = nn.Linear(dim_in, dim_out, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim_out, dim_out)
self.proj_drop = nn.Dropout(proj_drop)
def _build_projection(self, dim_in, dim_out, kernel_size, padding, stride,
method):
if method == 'dw_bn':
proj = nn.Sequential(
('conv', nn.Conv2D(
dim_in,
dim_in,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias_attr=False,
groups=dim_in)), ('bn', nn.BatchNorm2D(dim_in)),
('rearrage', Rearrange('b c h w -> b (h w) c')))
elif method == 'avg':
proj = nn.Sequential(
('avg', nn.AvgPool2D(
kernel_size=kernel_size,
stride=stride,
padding=padding,
ceil_mode=True)),
('rearrage', Rearrange('b c h w -> b (h w) c')))
elif method == 'linear':
proj = None
else:
raise ValueError('Unknown method ({})'.format(method))
return proj
def forward_conv(self, x, h, w):
if self.with_cls_token:
cls_token, x = paddle.split(x, [1, h * w], 1)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
if self.conv_proj_q is not None:
q = self.conv_proj_q(x)
else:
q = rearrange(x, 'b c h w -> b (h w) c')
if self.conv_proj_k is not None:
k = self.conv_proj_k(x)
else:
k = rearrange(x, 'b c h w -> b (h w) c')
if self.conv_proj_v is not None:
v = self.conv_proj_v(x)
else:
v = rearrange(x, 'b c h w -> b (h w) c')
if self.with_cls_token:
q = paddle.concat((cls_token, q), axis=1)
k = paddle.concat((cls_token, k), axis=1)
v = paddle.concat((cls_token, v), axis=1)
return q, k, v
def forward(self, x, h, w):
if (self.conv_proj_q is not None or self.conv_proj_k is not None or
self.conv_proj_v is not None):
q, k, v = self.forward_conv(x, h, w)
q = rearrange(self.proj_q(q), 'b t (h d) -> b h t d', h=self.num_heads)
k = rearrange(self.proj_k(k), 'b t (h d) -> b h t d', h=self.num_heads)
v = rearrange(self.proj_v(v), 'b t (h d) -> b h t d', h=self.num_heads)
attn_score = (q @k.transpose([0, 1, 3, 2])) * self.scale
attn = nn.functional.softmax(attn_score, axis=-1)
attn = self.attn_drop(attn)
x = attn @v
x = rearrange(x, 'b h t d -> b t (h d)')
x = self.proj(x)
x = self.proj_drop(x)
return x
def rearrange(x, pattern, **axes_lengths):
if 'b (h w) c -> b c h w' == pattern:
b, _, c = x.shape
h, w = axes_lengths.pop('h', -1), axes_lengths.pop('w', -1)
return x.transpose([0, 2, 1]).reshape([b, c, h, w])
if 'b c h w -> b (h w) c' == pattern:
b, c, h, w = x.shape
return x.reshape([b, c, h * w]).transpose([0, 2, 1])
if 'b t (h d) -> b h t d' == pattern:
b, t, h_d = x.shape
h = axes_lengths['h']
return x.reshape([b, t, h, h_d // h]).transpose([0, 2, 1, 3])
if 'b h t d -> b t (h d)' == pattern:
b, h, t, d = x.shape
return x.transpose([0, 2, 1, 3]).reshape([b, t, h * d])
raise NotImplementedError(
f"Rearrangement '{pattern}' has not been implemented.")
class Rearrange(nn.Layer):
def __init__(self, pattern, **axes_lengths):
super().__init__()
self.pattern = pattern
self.axes_lengths = axes_lengths
def forward(self, x):
return rearrange(x, self.pattern, **self.axes_lengths)
def extra_repr(self):
return self.pattern
2.数据集和复现精度
2.1 数据集
ImageNet项目是一个大型视觉数据库,用于视觉目标识别研究任务,该项目已手动标注了 1400 多万张图像。ImageNet-1k 是 ImageNet 数据集的子集,其包含 1000 个类别。训练集包含 1281167 个图像数据,验证集包含 50000 个图像数据。2010 年以来,ImageNet 项目每年举办一次图像分类竞赛,即 ImageNet 大规模视觉识别挑战赛(ILSVRC)。挑战赛使用的数据集即为 ImageNet-1k。到目前为止,ImageNet-1k 已经成为计算机视觉领域发展的最重要的数据集之一,其促进了整个计算机视觉的发展,很多计算机视觉下游任务的初始化模型都是基于该数据集训练得到的。
| 数据集 | 训练集大小 | 测试集大小 | 类别数 | 备注 |
|---|---|---|---|---|
| ImageNet1k | 1.2M | 50k | 1000 |
2.2 复现精度
| 模型 | epochs | top1 acc (参考精度) | (复现精度) | 权重 | 训练日志 |
|---|---|---|---|---|
| cvt_13_224x224 | 300 | 81.6 | 81.6 | best_model.pdparams | train.log |
权重及训练日志下载地址:百度网盘 or work/best_model.pdparams
3.准备环境
3.1 安装paddlepaddle
# 安装GPU版本的Paddle
pip install paddlepaddle-gpu==2.3.2
更多安装方法可以参考:Paddle安装指南。
3.2 下载代码
%cd /home/aistudio/
# !git clone https://github.com/flytocc/PaddleClas.git
# !cd PaddleClas
# !git checkout -b CvT_PR
!unzip PaddleClas-CvT_PR.zip
%cd /home/aistudio/PaddleClas-CvT_PR
!pip install -r requirements.txt
4.开始使用
4.1 模型预测

%cd /home/aistudio/PaddleClas-CvT_PR
%run tools/infer.py \
-c ./ppcls/configs/ImageNet/CvT/cvt_13_224x224.yaml \
-o Infer.infer_imgs=./deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg \
-o Global.pretrained_model=/home/aistudio/work/best_model
最终输出结果为
[{'class_ids': [178, 211, 210, 246, 268], 'scores': [0.83224, 0.00164, 0.00102, 0.0009, 0.00086], 'file_name': './deploy/images/ImageNet/ILSVRC2012_val_00020010.jpeg', 'label_names': ['Weimaraner', 'vizsla, Hungarian pointer', 'German short-haired pointer', 'Great Dane', 'Mexican hairless']}]
表示预测的类别为Weimaraner(魏玛猎狗),ID是178,置信度为0.83224。
4.2 模型训练
- 单机多卡训练
python -m paddle.distributed.launch --gpus=0,1,2,3 \
tools/train.py \
-c ./ppcls/configs/ImageNet/CvT/cvt_13_224x224.yaml
部分训练日志如下所示。
[2022/09/15 11:55:32] ppcls INFO: [Train][Epoch 260/300][Iter: 1000/2500]lr(LinearWarmup): 0.00010335, CELoss: 2.84290, loss: 2.84290, batch_cost: 0.60855s, reader_cost: 0.01440, ips: 210.33667 samples/s, eta: 17:10:17
[2022/09/15 11:56:02] ppcls INFO: [Train][Epoch 260/300][Iter: 1050/2500]lr(LinearWarmup): 0.00010335, CELoss: 2.84662, loss: 2.84662, batch_cost: 0.60854s, reader_cost: 0.01392, ips: 210.33875 samples/s, eta: 17:09:46
4.3 模型评估
python -m paddle.distributed.launch --gpus=0,1,2,3 \
tools/eval.py \
-c ./ppcls/configs/ImageNet/CvT/cvt_13_224x224.yaml \
-o Global.pretrained_model=$TRAINED_MODEL
ps: 如果未指定cls_label_path_val,会读取data_path/val里的图片作为val-set。
5. License
This project is released under MIT License.
If you find this work or code is helpful in your research, please cite:
@article{wu2021cvt,
title={Cvt: Introducing convolutions to vision transformers},
author={Wu, Haiping and Xiao, Bin and Codella, Noel and Liu, Mengchen and Dai, Xiyang and Yuan, Lu and Zhang, Lei},
journal={arXiv preprint arXiv:2103.15808},
year={2021}
}
7. 参考链接与文献
- CvT: Introducing Convolutions to Vision Transformers: https://arxiv.org/abs/2103.15808
- CvT: https://github.com/microsoft/CvT
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)