
【飞桨学习赛:猫十二分类体验赛】 第2名方案
基于PaddleX-CV全流程开发工具,实现图像分类任务。
【飞桨学习赛:猫十二分类体验赛】 22年10月第2名方案
一.赛题介绍
本场比赛要求参赛选手对十二种猫进行分类,属于CV方向经典的图像分类任务。图像分类任务作为其他图像任务的基石,可以让大家更快上手计算机视觉。

二.数据简介
比赛数据集包含12种猫的图片,并划分为训练集与测试集。
训练集: 提供高清彩色图片以及图片所属的分类,共有2160张猫的图片,含标注文件。
测试集: 仅提供彩色图片,共有240张猫的图片,不含标注文件。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GLfBabq5-1669199443175)(https://ai-studio-static-online.cdn.bcebos.com/e9a8322ce8a747cdb30759e9f8f27a8689f49ba85ca741b2a91768eb33103569)]
三. 比赛难点和亮点
-
个人认为是对神经网络的选择和个人对神经网络的了解
-
其次,数据增强也是其中之一,对于不同方法的掌握
-
还有相关参数的调整
-
最终精度:0.97
-
项目亮点在于使用ResNet残差网络,并载入相应的预训练模型即可快速上手体验完成训练任务
!pip install paddlex
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlex
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/ca/03/b401c6a34685aa698e7c2fbcfad029892cbfa4b562eaaa7722037fef86ed/paddlex-2.1.0-py3-none-any.whl (1.6 MB)
Collecting paddleslim==2.2.1
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/0b/dc/f46c4669d4cb35de23581a2380d55bf9d38bb6855aab1978fdb956d85da6/paddleslim-2.2.1-py3-none-any.whl (310 kB)
Requirement already satisfied: scipy in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (1.6.3)
Requirement already satisfied: pyyaml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (5.1.2)
Requirement already satisfied: openpyxl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (3.0.5)
Requirement already satisfied: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (0.4.4)
Requirement already satisfied: opencv-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (4.6.0.66)
Collecting lap
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/bf/64/d9fb6a75b15e783952b2fec6970f033462e67db32dc43dfbb404c14e91c2/lap-0.4.0.tar.gz (1.5 MB)
Preparing metadata (setup.py) ... [?25ldone
[?25hRequirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (4.64.1)
Collecting motmetrics
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/45/41/b019fe934eb811b9aba9b335f852305b804b9c66f098d7e35c2bdb09d1c8/motmetrics-1.2.5-py3-none-any.whl (161 kB)
Collecting scikit-learn==0.23.2
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/f4/cb/64623369f348e9bfb29ff898a57ac7c91ed4921f228e9726546614d63ccb/scikit_learn-0.23.2-cp37-cp37m-manylinux1_x86_64.whl (6.8 MB)
Collecting visualdl>=2.2.2
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/8a/e5/940426714a10c916466764eaea51ab7e10bd03896c625fcc4524a0855175/visualdl-2.4.1-py3-none-any.whl (4.9 MB)
Requirement already satisfied: flask-cors in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (3.0.8)
Requirement already satisfied: chardet in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (3.0.4)
Collecting pycocotools
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/ef/c6/90220be3b39fbc4cbd203775ca47dd8dc97fae06fbd2b500637395621b7c/pycocotools-2.0.6.tar.gz (24 kB)
Installing build dependencies ... [?25ldone
[?25h Getting requirements to build wheel ... [?25ldone
[?25h Preparing metadata (pyproject.toml) ... [?25ldone
[?25hRequirement already satisfied: shapely>=1.7.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlex) (1.8.5.post1)
Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.2.1->paddlex) (2.2.3)
Requirement already satisfied: pyzmq in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.2.1->paddlex) (23.2.1)
Requirement already satisfied: pillow in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.2.1->paddlex) (8.2.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==0.23.2->paddlex) (2.1.0)
Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==0.23.2->paddlex) (0.14.1)
Requirement already satisfied: numpy>=1.13.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn==0.23.2->paddlex) (1.20.3)
Requirement already satisfied: Flask-Babel>=1.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (1.0.0)
Requirement already satisfied: pandas in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (1.1.5)
Requirement already satisfied: multiprocess in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (0.70.11.1)
Requirement already satisfied: six>=1.14.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (1.16.0)
Requirement already satisfied: protobuf>=3.11.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (3.20.1)
Requirement already satisfied: requests in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (2.22.0)
Requirement already satisfied: flask>=1.1.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (1.1.1)
Requirement already satisfied: bce-python-sdk in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (0.8.53)
Requirement already satisfied: packaging in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from visualdl>=2.2.2->paddlex) (21.3)
Collecting xmltodict>=0.12.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/94/db/fd0326e331726f07ff7f40675cd86aa804bfd2e5016c727fa761c934990e/xmltodict-0.13.0-py2.py3-none-any.whl (10.0 kB)
Requirement already satisfied: et-xmlfile in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from openpyxl->paddlex) (1.0.1)
Requirement already satisfied: jdcal in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from openpyxl->paddlex) (1.4.1)
Requirement already satisfied: itsdangerous>=0.24 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.2.2->paddlex) (1.1.0)
Requirement already satisfied: Werkzeug>=0.15 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.2.2->paddlex) (0.16.0)
Requirement already satisfied: Jinja2>=2.10.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.2.2->paddlex) (3.0.0)
Requirement already satisfied: click>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from flask>=1.1.1->visualdl>=2.2.2->paddlex) (8.0.4)
Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl>=2.2.2->paddlex) (2019.3)
Requirement already satisfied: Babel>=2.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Flask-Babel>=1.0.0->visualdl>=2.2.2->paddlex) (2.8.0)
Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.2.1->paddlex) (0.10.0)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.2.1->paddlex) (3.0.9)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.2.1->paddlex) (1.1.0)
Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.2.1->paddlex) (2.8.2)
Requirement already satisfied: future>=0.6.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl>=2.2.2->paddlex) (0.18.0)
Requirement already satisfied: pycryptodome>=3.8.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bce-python-sdk->visualdl>=2.2.2->paddlex) (3.9.9)
Requirement already satisfied: dill>=0.3.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from multiprocess->visualdl>=2.2.2->paddlex) (0.3.3)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.2.2->paddlex) (2019.9.11)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.2.2->paddlex) (1.25.6)
Requirement already satisfied: idna<2.9,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests->visualdl>=2.2.2->paddlex) (2.8)
Requirement already satisfied: importlib-metadata in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from click>=5.1->flask>=1.1.1->visualdl>=2.2.2->paddlex) (4.2.0)
Requirement already satisfied: MarkupSafe>=2.0.0rc2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from Jinja2>=2.10.1->flask>=1.1.1->visualdl>=2.2.2->paddlex) (2.0.1)
Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->paddleslim==2.2.1->paddlex) (56.2.0)
Requirement already satisfied: typing-extensions>=3.6.4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata->click>=5.1->flask>=1.1.1->visualdl>=2.2.2->paddlex) (4.3.0)
Requirement already satisfied: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata->click>=5.1->flask>=1.1.1->visualdl>=2.2.2->paddlex) (3.8.1)
Building wheels for collected packages: lap, pycocotools
Building wheel for lap (setup.py) ... [?25ldone
[?25h Created wheel for lap: filename=lap-0.4.0-cp37-cp37m-linux_x86_64.whl size=1593890 sha256=ef3c0e29337369f142acb517a6b2589ab4d65441a78756391faeda32fd5815b9
Stored in directory: /home/aistudio/.cache/pip/wheels/5c/d0/d2/e331d17a999666b1e2eb99743cfa1742629f9d26c55c657001
Building wheel for pycocotools (pyproject.toml) ... [?25ldone
[?25h Created wheel for pycocotools: filename=pycocotools-2.0.6-cp37-cp37m-linux_x86_64.whl size=275105 sha256=f8cf2f2e6eaf2df4992cc25eb4a3278adb3cab07ac57a2718041fcb63bdc274f
Stored in directory: /home/aistudio/.cache/pip/wheels/f8/94/70/046149e666bd5812b7de6b87a28dcef238f7162f4108e0b3d8
Successfully built lap pycocotools
Installing collected packages: lap, xmltodict, scikit-learn, pycocotools, paddleslim, motmetrics, visualdl, paddlex
Attempting uninstall: scikit-learn
Found existing installation: scikit-learn 0.24.2
Uninstalling scikit-learn-0.24.2:
Successfully uninstalled scikit-learn-0.24.2
Attempting uninstall: paddleslim
Found existing installation: paddleslim 2.1.1
Uninstalling paddleslim-2.1.1:
Successfully uninstalled paddleslim-2.1.1
Attempting uninstall: visualdl
Found existing installation: visualdl 2.2.0
Uninstalling visualdl-2.2.0:
Successfully uninstalled visualdl-2.2.0
Successfully installed lap-0.4.0 motmetrics-1.2.5 paddleslim-2.2.1 paddlex-2.1.0 pycocotools-2.0.6 scikit-learn-0.23.2 visualdl-2.4.1 xmltodict-0.13.0
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
pip install paddleslim==2.1.1
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddleslim==2.1.1
Using cached https://pypi.tuna.tsinghua.edu.cn/packages/ee/e7/c6b97eb6809d14634ae5cbf287285584045d6f8949d0b436dc64cbefbf7a/paddleslim-2.1.1-py3-none-any.whl (288 kB)
Requirement already satisfied: matplotlib in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.1.1) (2.2.3)
Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.1.1) (4.64.1)
Requirement already satisfied: pyzmq in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.1.1) (23.2.1)
Requirement already satisfied: pillow in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.1.1) (8.2.0)
Requirement already satisfied: opencv-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddleslim==2.1.1) (4.6.0.66)
Requirement already satisfied: numpy>=1.7.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (1.20.3)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (3.0.9)
Requirement already satisfied: cycler>=0.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (0.10.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (1.1.0)
Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (2.8.2)
Requirement already satisfied: six>=1.10 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (1.16.0)
Requirement already satisfied: pytz in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from matplotlib->paddleslim==2.1.1) (2019.3)
Requirement already satisfied: setuptools in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from kiwisolver>=1.0.1->matplotlib->paddleslim==2.1.1) (56.2.0)
Installing collected packages: paddleslim
Attempting uninstall: paddleslim
Found existing installation: paddleslim 2.2.1
Uninstalling paddleslim-2.2.1:
Successfully uninstalled paddleslim-2.2.1
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
paddlex 2.1.0 requires paddleslim==2.2.1, but you have paddleslim 2.1.1 which is incompatible.[0m[31m
[0mSuccessfully installed paddleslim-2.1.1
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
Note: you may need to restart the kernel to use updated packages.
import warnings
warnings.filterwarnings('ignore') # 忽略警告信息
()
import os
from paddlex import transforms as T # 用于定义模型训练、验证、预测过程中,输入图像的预处理和数据增强操作
import paddlex as pdx
import paddle
from paddle.regularizer import L2Decay # L2 权重衰减正则化
import numpy as np
import pandas as pd
import shutil # 文件文档处理库
import cv2
import imghdr # 检测图片类型
from PIL import Image
from matplotlib import pyplot as plt
[11-17 13:52:49 MainThread @utils.py:79] WRN paddlepaddle version: 2.1.2. The dynamic graph version of PARL is under development, not fully tested and supported
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/__init__.py:107: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import MutableMapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/rcsetup.py:20: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Iterable, Mapping
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/colors.py:53: DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
from collections import Sized
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
if data.dtype == np.object:
四.数据分析与处理
【1】数据导入(解压数据集:这个平台可以直接书写linux语句)
!unzip -q /home/aistudio/data/data10954/cat_12_train.zip -d data/data10954/
!unzip -q /home/aistudio/data/data10954/cat_12_test.zip -d data/data10954/
## 相关文件夹的删除与建立
!rm -rf data/data10954/ImageNetDataset # 删除文件夹,防止多次运行时出错
for i in range(12):
cls_path = os.path.join('data/data10954/ImageNetDataset/', '%02d' % int(i)) # 拼接路径
if not os.path.exists(cls_path):
os.makedirs(cls_path) # 创建文件夹
!ls data/data10954/ImageNetDataset # 列出文件夹(linux语句)
##生成文件名和类别的一一对应关系,之后将根据类别cls将图片放入目标文件夹:data/data10954/ImageNetDataset/*/*.jpg。
train_df = pd.read_csv('data/data10954/train_list.txt', header=None, sep='\t') # 读取测试集标签
train_df.columns = ['name', 'cls'] # 返回列索引列表
train_df['name'] = train_df['name'].apply(lambda x: str(x).strip().split('/')[-1]) # 切分文件名,舍去cat_12_train/
train_df['cls'] = train_df['cls'].apply(lambda x: '%02d' % int(str(x).strip())) # 使图片标签类别变成2位数字
【2】图片模式检验&修复
图片模式主要有以下几种:
1、RGB 为真色彩模式, 可组合为 256 x 256 x256 种, 打印需要更改为 CMYK模式, 需要注意数值溢出的问题。
2、HSB 模式(本篇没有涉及),建立基于人类感觉颜色的方式,将颜色分为色相(Hue),饱和度(Saturation),明亮度(Brightness),这里不详细展开。
3、CMYK模式,应用在印刷领域,4个字母意思是青、洋红、黄、黑,因为不能保证纯度,所以需要黑。
4、位图模式,见1, 颜色由黑和白表示(True, False)。
5、灰度模式,只有灰度, 所有颜色转化为灰度值,见L,I,F。
6、双色调模式(未有涉及),节约成本将可使用双色调。
7、Lab模式(未涉及,ps内置),由3通道组成(亮度,a,b)组成,作为RGB到CMYK的过渡。
8、多通道模式,删除RGB,CMYK,Lab中某一个通道后,会转变为多通道,多通道用于处理特殊打印,它的每个通道都为256级灰度通道。
9、索引颜色模式,用在多媒体和网页,通过颜色表查取,没有则就近取,仅支持单通道,(8位/像素)。
通过对数据集图片模式进行检验,我们发现其含有 ‘P’,’RGBA’,’RGB’ 三种不同模式的图片。
P(pallete)模式:调色板模式,把原来单像素占用24(32)个bit的RGB(A)真彩图片中的像素值,重映射到了8bit长,即0~255的数值范围内。而这套映射关系,就是属于这张图的所谓“调色板”(Pallete)。
## 图片格式应当为RGB三通道,其中一张RGBA模式图片展示如下
img = Image.open('data/data10954/cat_12_train/ulFBEZNRQrxn57voHAJ4UG6Mct2sw1Cj.jpg')
print(img.mode)
plt.imshow(img)
plt.show(img)
## P、RGBA、L模式的图片转换为RGB模式
for i in range(len(train_df)):
img_path = os.path.join('data/data10954/cat_12_train', train_df.at[i, 'name']) # i 元素在列中的位置 ,name 列名
if os.path.exists(img_path) and imghdr.what(img_path): # 检测路径文件是否存在及判断类别
img = Image.open(img_path) # 打开文件
if img.mode != 'RGB':
img = Image.open(img_path)
print(img_path)
print(img.mode)
img = img.convert('RGB') # 转换成rgb形式
img.save(img_path) # 保存
for img_path in os.listdir('data/data10954/cat_12_test'):
src = os.path.join('data/data10954/cat_12_test',img_path)
img = Image.open(src)
if img.mode != 'RGB':
print(img_path)
img = img.convert('RGB')
img.save(src)
【3】数据可视化
## Data Visualization
## 随机查看同一类猫咪的特征
plt.figure(1)
img_1_1 = Image.open('data/data10954/cat_12_train/spNU7J8uk6BXiAyQErHegYMzjOaFR2qV.jpg')
plt.subplot(2, 2, 1) #图一包含1行2列子图,当前画在第一行第一列图上
plt.imshow(img_1_1)
plt.subplot(2, 2, 2)#当前画在第一行第2列图上
img_1_2 = Image.open('data/data10954/cat_12_train/7QZTYlspK2fqdJUwjC0HDmOFrM5W4PX9.jpg')
plt.imshow(img_1_2)
plt.subplot(2, 2, 3)
img_1_3 = Image.open('data/data10954/cat_12_train/oZin4PuwTet39xWCYhUBfvlzGyISb5DV.jpg')
plt.imshow(img_1_3)
plt.subplot(2, 2, 4)
img_1_4 = Image.open('data/data10954/cat_12_train/qbKjsR05lrFVYfLChtMGD7im36cUgAnE.jpg')
plt.imshow(img_1_4)
## 随机选取不同类别的猫咪进行查看
plt.figure(2)
img_0 = Image.open('data/data10954/cat_12_train/8GOkTtqw7E6IHZx4olYnhzvXLCiRsUfM.jpg')
plt.subplot(2, 6, 1)
plt.imshow(img_0)
img_0 = Image.open('data/data10954/cat_12_train/spNU7J8uk6BXiAyQErHegYMzjOaFR2qV.jpg')
plt.subplot(2, 6, 2)
plt.imshow(img_0)
img_0 = Image.open('data/data10954/cat_12_train/jbIdxGyNpoql3XQZrfREMiAzh7B46WOa.jpg')
plt.subplot(2, 6, 3)
plt.imshow(img_0)
img_0 = Image.open('data/data10954/cat_12_train/cCeBo4EJ9H1hbXsIS5G6Kxdzg27nwqfy.jpg')
plt.subplot(2, 6, 4)
plt.imshow(img_0)
img_0 = Image.open('data/data10954/cat_12_train/yxNcRSz4TI7FpwCVJBuea6MmGitZYUkK.jpg')
plt.subplot(2, 6, 5)
plt.imshow(img_0)
! pip install pyecharts
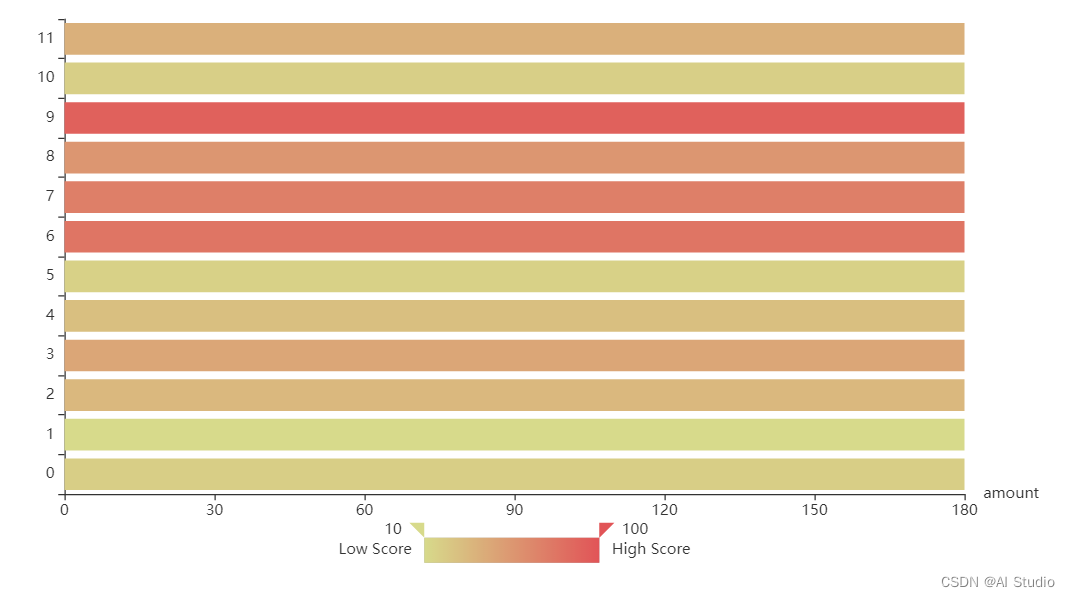
【4】样本平衡问题检验(此图像去找work文件夹中产生的labels.html打开即可看到)
为了检验或解决本项目样本不均匀问题,我们对data/cat_12_train中各类猫的图片数量进行统计并绘制条形图,结果如下图所示。由此可以观察出,本项目不存在样本不均衡问题,可直接进行下一步操作。
## 统计训练集各类猫的数目,防止样本不平衡问题。
from pyecharts import options as opts
from pyecharts.charts import Bar
with open("data/data10954/train_list.txt", "r") as f:
labels = f.readlines()
labels = [int(i.split()[-1]) for i in labels]
counts = pd.Series(labels).value_counts().sort_index().to_list()
values = np.random.rand(12) * 100
names = [str(i) for i in list(range(12))]
data = list(zip(values, counts, names))
source = [list(i) for i in data]
source.insert(0, ["score", "amount", "product"])
c = (
Bar()
.add_dataset(
source=source
)
.add_yaxis(
series_name="",
y_axis=[],
encode={"x": "amount", "y": "product"},
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Dataset normal bar example"),
xaxis_opts=opts.AxisOpts(name="amount"),
yaxis_opts=opts.AxisOpts(type_="category"),
visualmap_opts=opts.VisualMapOpts(
orient="horizontal",
pos_left="center",
min_=10,
max_=100,
range_text=["High Score", "Low Score"],
dimension=0,
range_color=["#D7DA8B", "#E15457"],
),
)
.render("./work/labels.html")
)
## 从源路径 src_path 移动至目标路径 dst_path。
for i in range(len(train_df)):
# 源路径
src_path = os.path.join('data/data10954/cat_12_train',train_df.at[i, 'name']) # i 元素在列中的位置 ,name 列名
# 目标路径
dst_path = os.path.join(os.path.join('data/data10954/ImageNetDataset/',train_df.at[i, 'cls']),train_df.at[i, 'name'])
try:
shutil.move(src_path, dst_path) # 移动图片到目标路径
except Exception as e:
print(e) # 抛出错误信息
【5】数据增强
在图像分类任务中,图像数据的增广是一种常用的正则化方法,常用于数据量不足或者模型参数较多的场景。在本章节中,我们将对除 ImageNet 分类任务标准数据增强外的8种数据增强方式进行简单的介绍和对比,用户也可以将这些增广方法应用到自己的任务中,以获得模型精度的提升。这8种数据增强方式在ImageNet上的精度指标如下所示。
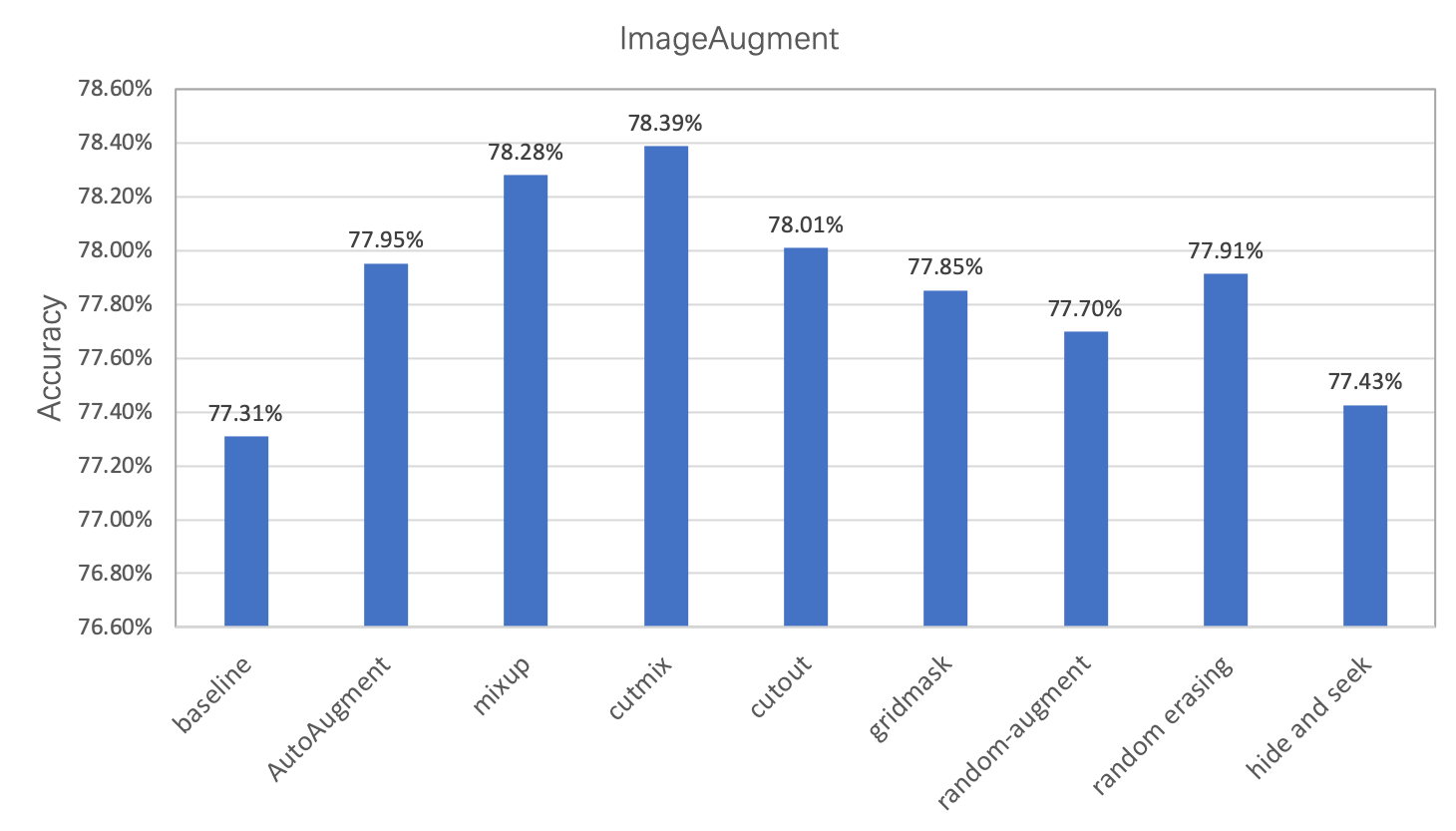
ImageNet 分类训练阶段的标准数据增强方式分为以下几个步骤:
- 图像解码:简写为 ImageDecode
- 随机裁剪到长宽均为 224 的图像:简写为 RandCrop
- 水平方向随机翻转:简写为 RandFlip
- 图像数据的归一化:简写为 Normalize
- 图像数据的重排,[224, 224, 3] 变为 [3, 224, 224]:简写为 Transpose
- 多幅图像数据组成 batch 数据,如 batch-size 个 [3, 224, 224] 的图像数据拼组成 [batch-size, 3, 224, 224]:简写为 Batch
下图为三类数据增强方式的效果展示:

图像变换类:图像变换类是在随机裁剪与翻转之间进行的操作,也可以认为是在原图上做的操作。主要方式包括AutoAugment和RandAugment,基于一定的策略,包括锐化、亮度变化、直方图均衡化等,对图像进行处理。这样网络在训练时就已经见过这些情况了,之后在实际预测时,即使遇到了光照变换、旋转这些很棘手的情况,网络也可以从容应对了。
图像裁剪类:图像裁剪类主要是在生成的在通道转换之后,在图像上设置掩码,随机遮挡,从而使得网络去学习一些非显著性的特征。否则网络一直学习很重要的显著性区域,之后在预测有遮挡的图片时,泛化能力会很差。主要方式包括:CutOut、RandErasing、HideAndSeek、GridMask。这里需要注意的是,在通道转换前后去做图像裁剪,其实是没有区别的。因为通道转换这个操作不会修改图像的像素值。
图像混叠类:组完batch之后,图像与图像、标签与标签之间进行混合,形成新的batch数据,然后送进网络进行训练。这也就是图像混叠类数据增广方式,主要的有Mixup与Cutmix两种方式。
由于本项目数据集中,包含2160张训练集图片,为了增强模型效果,我们采用数据增强,并通过调整方式及相关参数,使模型效果最优(相关设置请见配置文件)。
我们以训练集中7QZTYlspK2fqdJUwjC0HDmOFrM5W4PX9.jpg为例,展示数据增强效果:
(注:由于前期使用Pytorch进行模型建立,故将相关代码放于图片下方。)

相关代码如下:
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from torchvision import transforms
from timm.data.constants import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm import data
# 数据增强策略
trans = transforms.Compose([
transforms.RandomCrop((384, 384), pad_if_needed=True),
transforms.RandomHorizontalFlip(),
data.AutoAugment(data.auto_augment_policy('originalr')),
transforms.ToTensor(),
transforms.Normalize(IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD),
transforms.RandomErasing()
])
# 加载单张图片
image = Image.open("./0yTr3fswKBv4M8Fo2NcUnzibx6ClIm5e.jpg.jpg")
image = image.convert("RGB")
# 标准化的参数
mean = np.array(IMAGENET_DEFAULT_MEAN)
std = np.array(IMAGENET_DEFAULT_STD)
# 进行绘图
plt.figure(figsize=(12, 12))
for i in range(25):
plt.subplot(5, 5, i + 1)
# 对图片进行增强
trans_image = trans(image)
# 提取增强后的图片,转换为numpy.ndarray格式
trans_image = trans_image.numpy().transpose([1, 2, 0])
# 反标准化
trans_image = std * trans_image + mean
trans_image = np.clip(trans_image, 0, 1)
# 展示图片
plt.imshow(trans_image)
plt.axis('off')
plt.savefig('./src/0yTr3fswKBv4M8Fo2NcUnzibx6ClIm5e.jpg_2.jpg', dpi=100)
plt.show()
五.模型构建
【1】模型概述(ResNet)
ResNet的诞生
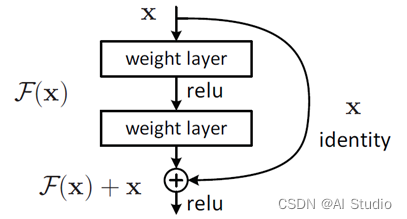
深度网络的退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。为了解决这个问题,ResNet的作者何凯明提出了残差学习来解决退化问题。
对于一个堆积层结构(几层堆积而成)当输入为 时其学习到的特征记为 ,现在我们希望其可以学习到残差 ,这样其实原始的学习特征是 。之所以这样是因为残差学习相比原始特征直接学习更容易。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如下图所示。这有点类似与电路中的“短路”,所以是一种短路连接(shortcut connection)。
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如图5所示。变化主要体现在ResNet直接使用stride=2的卷积做下采样,并且用global average pool层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从图5中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。图5展示的34-layer的ResNet,还可以构建更深的网络如表1所示。从表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
六.PaddleClas训练模型
PaddleClas支持通过修改配置文件(.yaml)的方式,灵活便捷的配置模型训练参数。相关配置文件已放于相应文件夹下。本文重点介绍全局配置(Global)、优化器(Optimizer)相关参数。
【1】全局配置相关参数
| 参数名字 | 参数名字 | 默认值 | 可选值 |
|---|---|---|---|
| checkpoints | 断点模型路径,用于恢复训练 | null | str |
| pretrained_model | 预训练模型路径 | null | str |
| output_dir | output_dir | “./output/” | str |
| save_interval | save_interval | 1 | int |
| eval_during_train | 是否在训练时进行评估 | True | bool |
| eval_interval | 每隔多少个epoch进行模型评估 | 1 | int |
| epochs | 训练总epoch数 | int | |
| print_batch_step | print_batch_step | 10 | int |
| use_visualdl | 是否是用visualdl可视化训练过程 | False | bool |
| image_shape | 图片大小 | [3,224,224] | list, shape: (3,) |
| save_inference_dir | save_inference_dir | “./inference” | str |
| eval_mode | eval的模式 | “classification” | “retrieval” |
| to_static | 是否改为静态图模式 | False | True |
| ues_dali | 是否使用dali库进行图像预处理 | False | True |
【2】优化器相关参数
| 参数名字 | 具体含义 | 默认值 | 可选值 |
|---|---|---|---|
| name | 优化器方法名 | “Momentum” | “Momentum” |
| momentum | momentum值 | 0.9 | float |
| lr.name | 学习率下降方式 | “Cosine” | “Linear”、"Piecewise"等其他下降方式 |
| lr.learning_rate | 学习率初始值 | 0.1 | float |
| lr.warmup_epoch | warmup轮数 | 0 | int,如5 |
| regularizer.name | 正则化方法名 | “L2” | [“L1”, “L2”] |
| regularizer.coeff | 正则化系数 | 0.00007 | float |
【3】生成ImageNet
【4】数据集划分
!paddlex --split_dataset --format ImageNet\
--dataset_dir data/data10954/ImageNetDataset\
--val_value 0.085\
--test_value 0
【5】定义数据增强、装载数据集
在对数据集进行数据增强之前,我们首先需要根据本数据集计算相关参数:
T.Normalize():
初始参数:
T.Normalize(mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225])
为在ImageNet上几百万张图片上的均值和方差,我们需计算本数据集上的均值和方差,并用此数据进行标准化。
import torch
from torch.utils.data import DataLoader
from torchvision.transforms import transforms
from dataset.CatDataset import CatDataset
trans = transforms.Compose([
transforms.Resize((410, 410)),
transforms.ToTensor()
])
train_dataset = CatDataset("E:/project/data10954", "train_list.txt", trans)
train_loader = DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
def get_mean_std(loader):
# Var[x] = E[X**2]-E[X]**2
channels_sum, channels_squared_sum, num_batches = 0, 0, 0
for data, _ in loader:
channels_sum += torch.mean(data, dim=[0, 2, 3])
channels_squared_sum += torch.mean(data ** 2, dim=[0, 2, 3])
num_batches += 1
print(num_batches)
print(channels_sum)
mean = channels_sum / num_batches
std = (channels_squared_sum / num_batches - mean ** 2) ** 0.5
return mean, std
mean, std = get_mean_std(train_loader)
print(mean)
print(std)
相关代码如上,经计算,本数据集的相关参数:
mean = [0.4848, 0.4435, 0.4023],
std = [0.2744, 0.2688, 0.2757]
# 训练集增强
train_transforms = T.Compose([
T.MixupImage(
alpha=1.5,
beta=1.5,
mixup_epoch=int(300 * 25. / 27)),
T.Resize(
target_size=438,
interp='CUBIC'),
# 以图像中心点扩散裁剪长宽为目标尺寸的正方形
T.RandomCrop(360),
# 以一定的概率对图像进行随机水平翻转
T.RandomHorizontalFlip(0.5),
# 以一定的概率对图像进行随机像素内容变换,可包括亮度、对比度、饱和度、色相角度、通道顺序的调整,模型训练时的数据增强操作
T.RandomDistort(
brightness_range=0.25,
brightness_prob=0.5,
contrast_range=0.25,
contrast_prob=0.5,
saturation_range=0.25,
saturation_prob=0.5,
hue_range=18.0,
hue_prob=0.5),
# 以一定的概率对图像进行高斯模糊
T.RandomBlur(0.1),
# 对图像进行标准化
T.Normalize([0.4848, 0.4435, 0.4023], [0.2744, 0.2688, 0.2757])
])
# 验证集增强
eval_transforms = T.Compose([
T.Resize(
target_size=410,
interp='AREA'),
T.CenterCrop(360),
T.Normalize([0.4848, 0.4435, 0.4023], [0.2744, 0.2688, 0.2757])
])
【6】装载数据集
train_dataset = pdx.datasets.ImageNet(
data_dir='data/data10954/ImageNetDataset',
file_list='data/data10954/ImageNetDataset/train_list.txt',
label_list='data/data10954/ImageNetDataset/labels.txt',
transforms=train_transforms,
shuffle=True) # 是否需要对数据集中样本打乱顺序
eval_dataset = pdx.datasets.ImageNet(
data_dir='data/data10954/ImageNetDataset',
file_list='data/data10954/ImageNetDataset/val_list.txt',
label_list='data/data10954/ImageNetDataset/labels.txt',
transforms=eval_transforms)
【7】配置 ResNet 模型并训练
#初始化模型
model = pdx.cls.ResNet101_vd_ssld(
num_classes=len(train_dataset.labels)
)
model.train(
train_dataset=train_dataset,
eval_dataset=eval_dataset,
num_epochs=420, #训练轮数
train_batch_size=80, #一个step所用到的样本量
warmup_steps=(len(train_dataset.file_list) // 80) * 6, #学习率从0经过steps轮迭代增长到设定的学习率
learning_rate=0.025, # 学习率
lr_decay_epochs=[40, 65, 115, 160, 205], #表示学习率在第几个epoch时衰减一次
lr_decay_gamma=0.1, # 学习率衰减率
save_interval_epochs=2, # 每几轮保存一次
log_interval_steps=(len(train_dataset.file_list) // 80) * 7, # 训练日志输出间隔
pretrain_weights='IMAGENET',
#pretrain_weights (str or None): 若指定为'.pdparams'文件时,则从文件加载模型权重;
#若为字符串'IMAGENET',则自动下载在ImageNet图片数据上预训练的模型权重;
#若为None,则不使用预训练模型。默认为'IMAGENET'
save_dir='output/ResNet101_vd_ssld',
use_vdl=False)
七.训练技巧与参数选择
【1】调优策略
在训练网络的过程中,通常会打印每一个epoch的训练集准确率和验证集准确率,二者刻画了该模型在两个数据集上的表现。通常来说,训练集的准确率比验证集准确率微高或者二者相当是比较不错的状态。如果发现训练集的准确率比验证集高很多,说明在这个任务上已经过拟合,需要在训练过程中加入更多的正则,如增大l2_decay的值,加入更多的数据增广策略,加入label_smoothing策略等;如果发现训练集的准确率比验证集低一些,说明在这个任务上可能欠拟合,需要在训练过程中减弱正则效果,如减小l2_decay的值,减少数据增广方式,增大图片crop区域面积,减弱图片拉伸变换,去除label_smoothing等。
【2】优化器&学习率选择
学习率下降策略:
在整个训练过程中,我们不能使用同样的学习率来更新权重,否则无法到达最优点,所以需要在训练过程中调整学习率的大小。在训练初始阶段,由于权重处于随机初始化的状态,损失函数相对容易进行梯度下降,所以可以设置一个较大的学习率。在训练后期,由于权重参数已经接近最优值,较大的学习率无法进一步寻找最优值,所以需要设置一个较小的学习率。
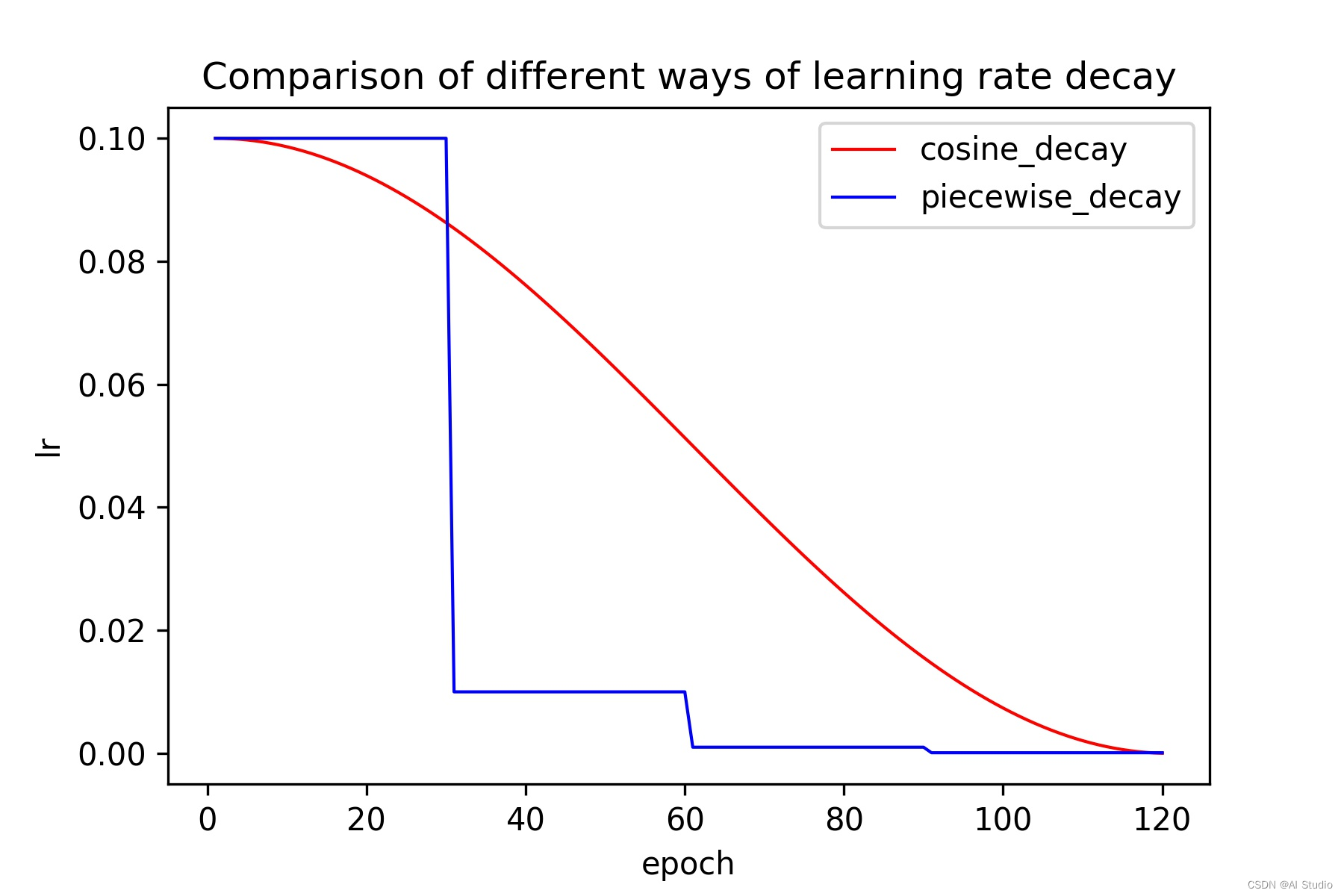
Cosine_decay和piecewise_decay的学习率变化曲线如下图所示,容易观察到,在整个训练过程中,cosine_decay都保持着较大的学习率,所以其收敛较为缓慢,但是最终的收敛效果较peicewise_decay更好一些。
warmup策略:
让学习率先进行预热,在训练初期,本文不直接使用最大的学习率,而是用一个逐渐增大的学习率去训练网络,当学习率增大到最高点时,再使用学习率下降策略中提到的学习率下降方式衰减学习率的值。
Optimizer:
name: AdamW
beta1: 0.9
beta2: 0.999
epsilon: 1e-8
weight_decay: 0.05
no_weight_decay_name: absolute_pos_embed relative_position_bias_table .bias norm
one_dim_param_no_weight_decay: True
lr:
name: Cosine
learning_rate: 3e-6
eta_min: 1e-6
warmup_epoch: 20
warmup_start_lr: 1e-6
【3】batch_size
batch_size决定了一次将多少数据送入神经网络参与训练,当batch_size的值与学习率的值呈线性关系时,收敛精度几乎不受影响。因本文采用飞桨—至尊版GPU环境,所以在条件的允许下,尽量增大batch_size值的大小
(从64开始尝试,若训练过程中出现内存溢出错误,则减小batch_size值的大小。)
【4】模型预测,另存为提交文件
model = pdx.load_model('output/ResNet101_vd_ssld/epoch_40') # 加载模型
model.get_model_info() # 显示信息
八.生成 work/result.csv
通过csv文件去查看分类结果,分类结果并不是100%正确,在有经过数据增强和神经网络的学习前,正确率大约在20%,经过数据增强和残差神经网络学习以后可以到达90%左右,但是这其中也不排除训练次数太多导致的过拟合,最终使正确率降低了一些。
import glob
test_list = glob.glob('data/data10954/cat_12_test/*.jpg')
test_df = pd.DataFrame() # 创建表结构
for i in range(len(test_list)):
img = Image.open(test_list[i]).convert('RGB')
img = np.asarray(img, dtype='float32') # 转换数据类型
result = model.predict(img[:, :, [2, 1, 0]]) # 预测结果
test_df.at[i, 'name'] = str(test_list[i]).split('/')[-1] # 文件名
test_df.at[i, 'cls'] = int(result[0]['category_id']) # 类别
test_df[['name']] = test_df[['name']].astype(str)
test_df[['cls']] = test_df[['cls']].astype(int)
test_df.to_csv('work/result.csv', index=False, header=False) # 生成csv文件
f.at[i, 'cls'] = int(result[0]['category_id']) # 类别
test_df[['name']] = test_df[['name']].astype(str)
test_df[['cls']] = test_df[['cls']].astype(int)
test_df.to_csv('work/result.csv', index=False, header=False) # 生成csv文件
test_df.head()
九.总结与展望
- 本项目选择了ResNet完成了猫图像分类。
- 在接下来的工作中,可以考虑增加图像增强操作,例如图像裁剪,图像亮度调整,图像对比度调整等待,从而丰富训练集,防止过拟合。
- 可以考虑使用其他残差网络,进行改进。
对于这个分数,其实还要很多可以改进的地方。
如果有问题,欢迎讨论
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 2
2 1
1- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)