
基于PaddleNLP的属性级情感分析Web系统
基于PaddleNLP搭建评论观点抽取和属性级情感分析模型,并基于前后端分离式架构完成属性级情感分析Web系统搭建,通过细粒度情感分析帮助用户和商家更好决策。
基于PaddleNLP的属性级情感分析Web系统
演示视频传送门: https://www.bilibili.com/video/BV1H14y1H7Pp/?vd_source=0d95776ba676743c358eea0075f247c4
一.项目介绍
1.1 项目简介
本项目基于PaddleNLP搭建评论观点抽取和属性级情感分析模型,实现细粒度、属性级情感分析。可抽取文本中评论属性和对应观点,并对抽取内容进行细粒度情感倾向分析从而获取评论文本中各个属性所对应的情感分析结果,进而给到企业用户或商家具体有效的建议以及帮助用户高效地从评论获取消费指南。
为更好进行功能演示,本项目基于前后端分离式架构完成属性级情感分析Web系统搭建,支持输入单条文本进行在线属性级情感分析以及上传Excel文件进行批量文本情感分析。
技术栈:后端:FastAPI + PaddleNLP;前端:Vue+ ElementUI。
1.2 属性级情感分析研究意义
随着互联网以及电商的发展普及,人们的消费习惯逐渐转变到线上,亿万用户在互联网上可以获得信息、交流信息,发表自己的观点和分享自己的体验,表达各种情感和情绪,如批评、赞扬以及喜、怒、哀、乐等。对顾客网络评论信息进行分析,对于商家来说,可以获取餐厅有关服务、菜品、环境等各方面的真实反馈,以便制定发展决策,改善自身服务,改善用户体验,提升竞争优势;对于顾客来说,通过了解其他消费者的评论信息,可以有效避免踩雷,优化消费决策。
目前电商平台仅将用户评论文本整体根据用户评分分为好评、差评和中评,存在以下问题:1.分类精度降低,用户在描述一个商品时,对商品的多个属性可能会给出不同的情感态度、褒贬不一,只按照整体句子给出情感态度就会导致分类的精度下降,难以获取具体有效的建议。2.用户评分与内容情感倾向不一致,用户可能为了完成商家所谓的好评率可能会在评分上给出好评,文字上说明真实情况,于是出现评分与情感倾向不一致的可能。
随着应用的深入,传统的情感分析则不能完全满足需求,用户和商家希望进一步获取评价对象每个属性所对应的具体情感分析结果。为此,属性级情感分析应运而生,并得到越来越高的重视,逐渐成为情感分析的研究热点和重点。
属性级情感分析与篇章/句子级情感分析不同,其研究针对的是句子中的各个属性,所对应的属性不同,同一句子所反映的情感倾向也可能会有差异。一般分为三个子任务:评论属性抽取、观点抽取和情感分类,抽取文本中评论属性和对应观点,并对抽取的内容进行细粒度情感倾向分析从而获取文本中各个属性所对应的具体情感分析结果。随着技术不断深入发展,其作用日益突出,通过评论文本属性级情感分析能够给到企业用户或商家更加具体的优化建议,也能帮助用户高效地从评论获取消费指南。
二.搭建评论观点抽取和属性级情感分析模型

2.1 导入PaddleNLP依赖
PaddleNLP是飞桨自然语言处理开发库,具备易用的文本领域API、多场景的应用示例和高性能分布式训练三大特点,旨在提升飞桨开发者文本领域建模效率,并提供丰富的NLP应用示例。
1.易用的文本领域API:
提供丰富的产业级预置任务能力 Taskflow 和全流程的文本领域API:支持丰富中文数据集加载的 Dataset API,可灵活高效地完成数据预处理的 Data API ,预置60+预训练词向量的 Embedding API ,提供100+预训练模型的 Transformer API 等,可大幅提升NLP任务建模的效率。
2.多场景的应用示例:
覆盖从学术到产业级的NLP应用示例,涵盖NLP基础技术、NLP系统应用以及相关拓展应用。全面基于飞桨核心框架2.0全新API体系开发,为开发者提供飞桨文本领域的最佳实践。
3.高性能分布式训练:
基于飞桨核心框架领先的自动混合精度优化策略,结合分布式Fleet API,支持4D混合并行策略,可高效地完成大规模预训练模型训练。
项目GitHub: https://github.com/PaddlePaddle/PaddleNLP
项目Gitee: https://gitee.com/paddlepaddle/PaddleNLP
GitHub Issue反馈: https://github.com/PaddlePaddle/PaddleNLP/issues
PaddleNLP文档: https://paddlenlp.readthedocs.io/zh/latest/index.html
PaddleNLP支持预训练模型汇总:https://paddlenlp.readthedocs.io/zh/latest/model_zoo/index.html
# 下载安装最新版PaddleNLP
!pip install --upgrade paddlenlp
# 查看PaddleNLP版本
import paddle
import paddlenlp
print(paddlenlp.__version__)
2.4.3
2.2 评论观点抽取模型搭建
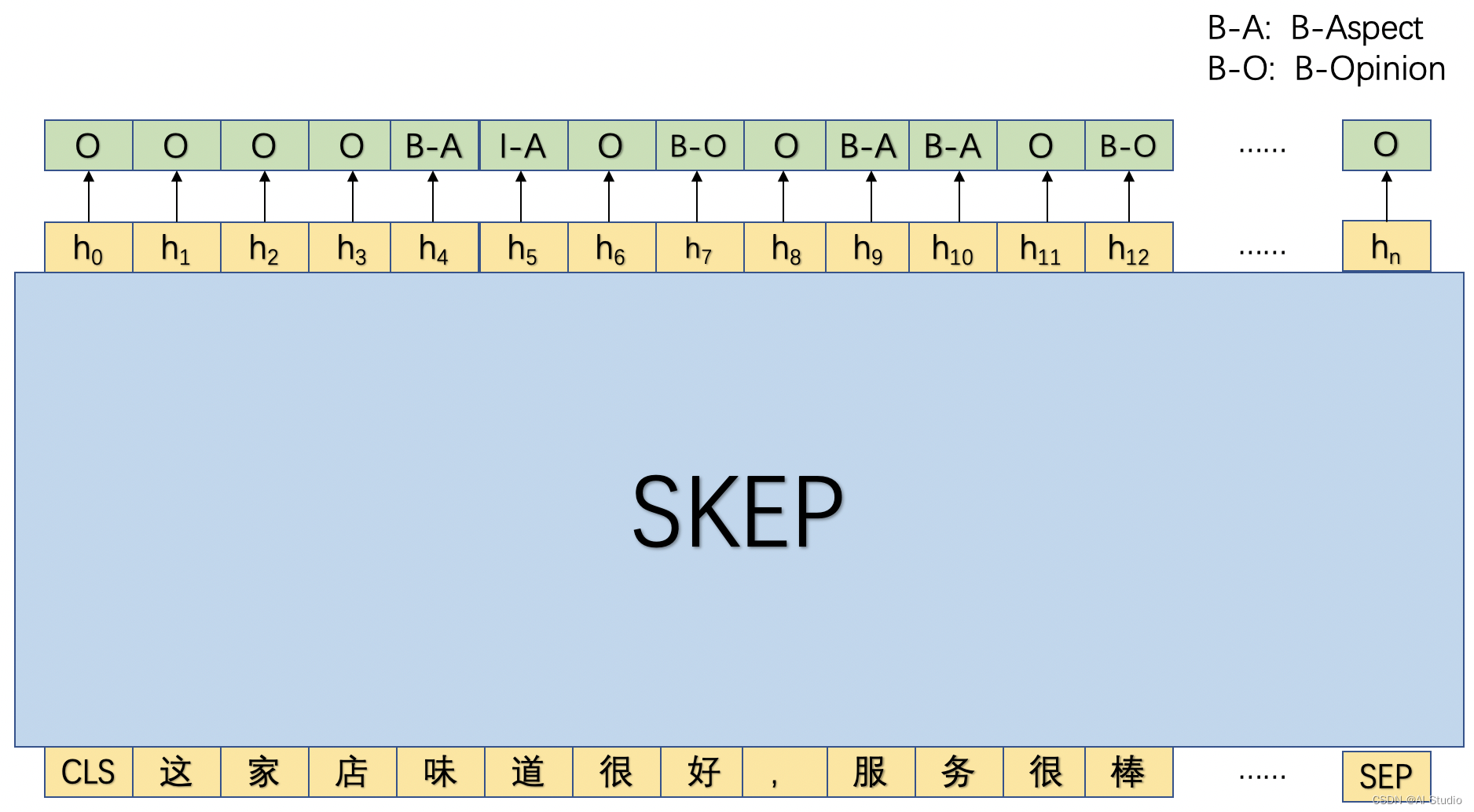
模型采用序列标注的方式进行评论观点抽取,即会抽取评论中的属性以及属性对应的观点。在具体实践上基于BIO的序列标注体系进行了标签的拓展:B-Aspect, I-Aspect, B-Opinion, I-Opinion, O,其中前两者用于标注评论属性,后两者用于标注相应观点。
如图所示,首先将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列,然后基于该向量序列进行预测每个位置上的输出标签。
# 观点抽取模型构建
class SkepForTokenClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForTokenClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
sequence_output, _ = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
return logits
2.3 属性级情感分类模型搭建
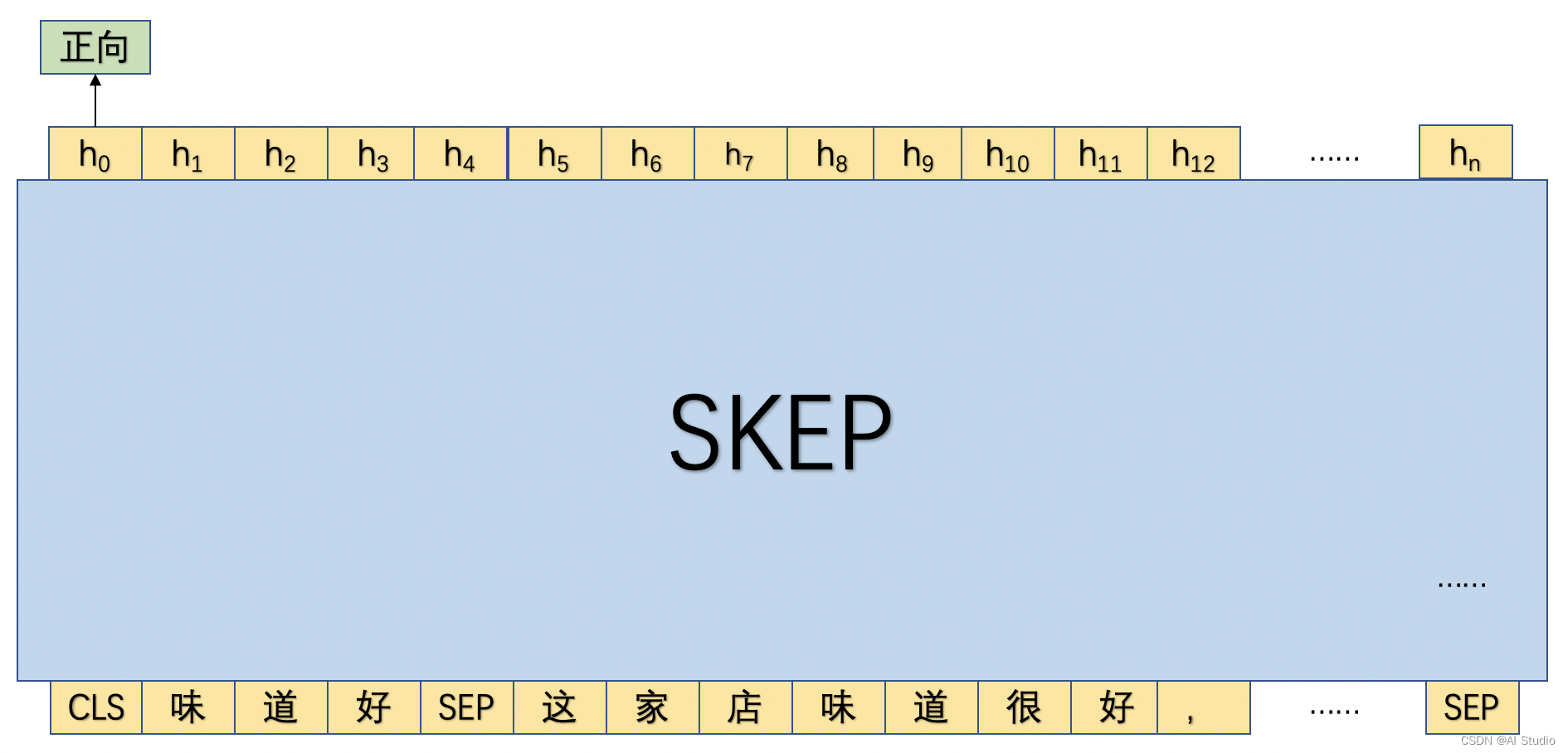
在抽取完评论观点之后,便可以有针对性的对各个属性进行评论。具体来讲,将抽取出的评论属性和评论观点进行拼接,然后和原始语句进行拼接作为一条独立的训练语句。
如图所示,首先将评论属性和观点词进行拼接为"味道好",接着将"味道好"和原文进行拼接,然后传入SKEP模型,SKEP将会对文本的每个token进行编码,产生对应向量序列并使用"CLS"位置对应的输出向量进行细粒度情感倾向分类。
# 属性级情感分类模型构建
class SkepForSequenceClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForSequenceClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits
2.4 下载训练好的模型参数
下载PaddleNLP开源的基于全量数据训练好的评论观点抽取模型和属性级情感分类模型,后面将基于下载好的模型进行全流程情感分析预测。
对模型训练部分感兴趣的,可以参考学习基于PaddleNLP搭建评论观点抽取和情感分析系统
# 进入data目录,data目录下文件每次重启都会重置减少占用
%cd /home/aistudio/data/
/home/aistudio/data
# 下载评论观点抽取模型
!wget https://bj.bcebos.com/paddlenlp/models/best_ext.pdparams
# 下载属性级情感分类模型
!wget https://bj.bcebos.com/paddlenlp/models/best_cls.pdparams
--2022-11-21 15:32:02-- https://bj.bcebos.com/paddlenlp/models/best_ext.pdparams
正在解析主机 bj.bcebos.com (bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a
正在连接 bj.bcebos.com (bj.bcebos.com)|182.61.200.229|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 1268047552 (1.2G) [application/octet-stream]
正在保存至: “best_ext.pdparams”
best_ext.pdparams 100%[===================>] 1.18G 3.74MB/s in 3m 27s
2022-11-21 15:35:30 (5.83 MB/s) - 已保存 “best_ext.pdparams” [1268047552/1268047552])
--2022-11-21 15:35:30-- https://bj.bcebos.com/paddlenlp/models/best_cls.pdparams
正在解析主机 bj.bcebos.com (bj.bcebos.com)... 182.61.200.229, 182.61.200.195, 2409:8c04:1001:1002:0:ff:b001:368a
正在连接 bj.bcebos.com (bj.bcebos.com)|182.61.200.229|:443... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 1268035252 (1.2G) [application/octet-stream]
正在保存至: “best_cls.pdparams”
best_cls.pdparams 100%[===================>] 1.18G 6.82MB/s in 10m 29s
2022-11-21 15:46:00 (1.92 MB/s) - 已保存 “best_cls.pdparams” [1268035252/1268035252])
2.5 加载训练好的模型
from paddlenlp.transformers import SkepTokenizer, SkepModel
from utils import data_ext, data_cls
from utils.utils import decoding, concate_aspect_and_opinion, format_print
# 映射表
label_ext_path = "/home/aistudio/work/label_ext.dict"
label_cls_path = "/home/aistudio/work/label_cls.dict"
# PaddleNLP开源的基于全量数据训练好的评论观点抽取模型和属性级情感分类模型
ext_model_path = "/home/aistudio/data/best_ext.pdparams"
cls_model_path = "/home/aistudio/data/best_cls.pdparams"
# load dict
model_name = "skep_ernie_1.0_large_ch"
ext_label2id, ext_id2label = data_ext.load_dict(label_ext_path)
cls_label2id, cls_id2label = data_cls.load_dict(label_cls_path)
tokenizer = SkepTokenizer.from_pretrained(model_name)
print("label dict loaded.")
# load ext model 加载观点抽取模型
ext_state_dict = paddle.load(ext_model_path)
ext_skep = SkepModel.from_pretrained(model_name)
ext_model = SkepForTokenClassification(ext_skep, num_classes=len(ext_label2id))
ext_model.load_dict(ext_state_dict)
print("extraction model loaded.")
# load cls model 加载属性级情感分析模型
cls_state_dict = paddle.load(cls_model_path)
cls_skep = SkepModel.from_pretrained(model_name)
cls_model = SkepForSequenceClassification(cls_skep, num_classes=len(cls_label2id))
cls_model.load_dict(cls_state_dict)
print("classification model loaded.")
[2022-11-21 15:46:00,315] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/skep/skep_ernie_1.0_large_ch.vocab.txt and saved to /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch
[2022-11-21 15:46:00,317] [ INFO] - Downloading skep_ernie_1.0_large_ch.vocab.txt from https://bj.bcebos.com/paddlenlp/models/transformers/skep/skep_ernie_1.0_large_ch.vocab.txt
100%|██████████| 54.4k/54.4k [00:00<00:00, 2.99MB/s]
[2022-11-21 15:46:00,440] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/tokenizer_config.json
[2022-11-21 15:46:00,442] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/special_tokens_map.json
label dict loaded.
[2022-11-21 15:46:05,174] [ INFO] - Downloading https://bj.bcebos.com/paddlenlp/models/transformers/skep/skep_ernie_1.0_large_ch.pdparams and saved to /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch
100%|██████████| 1238309/1238309 [14:52<00:00, 1387.09it/s]
W1121 16:00:58.046947 201 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1121 16:00:58.050565 201 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
extraction model loaded.
[2022-11-21 16:01:02,965] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/skep_ernie_1.0_large_ch/skep_ernie_1.0_large_ch.pdparams
classification model loaded.
2.6 单条文本属性级情感分析预测
# 定义单文本属性级情感分析预测函数
def predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512):
ext_model.eval()
cls_model.eval()
# processing input text
encoded_inputs = tokenizer(list(input_text), is_split_into_words=True, max_seq_len=max_seq_len,)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# extract aspect and opinion words
logits = ext_model(input_ids, token_type_ids=token_type_ids)
predictions = logits.argmax(axis=2).numpy()[0]
tag_seq = [ext_id2label[idx] for idx in predictions][1:-1]
aps = decoding(input_text, tag_seq)
# predict sentiment for aspect with cls_model
results = []
for ap in aps:
aspect = ap[0]
opinion_words = list(set(ap[1:]))
aspect_text = concate_aspect_and_opinion(input_text, aspect, opinion_words)
encoded_inputs = tokenizer(aspect_text, text_pair=input_text, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
logits = cls_model(input_ids, token_type_ids=token_type_ids)
prediction = logits.argmax(axis=1).numpy()[0]
result = {"aspect": aspect, "opinions": str(opinion_words), "sentiment": cls_id2label[prediction]}
results.append(result)
# 标准形式输出预测结果
format_print(results)
# 返回预测结果,list形式
return results
input_text = "蛋糕味道不错,很好吃,店家很耐心,服务也很好,很棒!"
predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512)
aspect: 蛋糕味道, opinions: ['不错', '好吃'], sentiment: 正向
aspect: 店家, opinions: ['耐心'], sentiment: 正向
aspect: 服务, opinions: ['好', '棒'], sentiment: 正向
pinions: [‘好’, ‘棒’], sentiment: 正向
[{'aspect': '蛋糕味道', 'opinions': "['不错', '好吃']", 'sentiment': '正向'},
{'aspect': '店家', 'opinions': "['耐心']", 'sentiment': '正向'},
{'aspect': '服务', 'opinions': "['好', '棒']", 'sentiment': '正向'}]
2.7 批量文本属性级情感分析预测
# 定义批量文本预测函数
def batchPredict(data, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512):
ext_model.eval()
cls_model.eval()
analysisResults = []
for input_text in data:
# processing input text
encoded_inputs = tokenizer(list(input_text), is_split_into_words=True, max_seq_len=max_seq_len,)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# extract aspect and opinion words
logits = ext_model(input_ids, token_type_ids=token_type_ids)
predictions = logits.argmax(axis=2).numpy()[0]
tag_seq = [ext_id2label[idx] for idx in predictions][1:-1]
aps = decoding(input_text, tag_seq)
# predict sentiment for aspect with cls_model
results = []
for ap in aps:
aspect = ap[0]
opinion_words = list(set(ap[1:]))
aspect_text = concate_aspect_and_opinion(input_text, aspect, opinion_words)
encoded_inputs = tokenizer(aspect_text, text_pair=input_text, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
logits = cls_model(input_ids, token_type_ids=token_type_ids)
prediction = logits.argmax(axis=1).numpy()[0]
result = {"属性": aspect, "观点": opinion_words, "情感倾向": cls_id2label[prediction]}
results.append(result)
singleResult = {"text": input_text, "result": str(results)}
analysisResults.append(singleResult)
# 返回预测结果 list形式
return analysisResults
# 读取要进行批量情感分析的Excel文件内容
import pandas as pd
df = pd.read_excel('/home/aistudio/work/测试数据.xlsx', index_col=None)
# 读取Excel中列名为“text”或“文本”的数据,若无该列名则默认读取第一列数据
if 'text' in df.columns:
contents = df['text']
elif '文本' in df.columns:
contents = df['文本']
else: contents = df[df.columns[0]]
# 批量文本属性级情感分析预测
batchPredict(contents, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512)
[{'text': '环境装修不错,也很干净,前台服务非常好',
'result': "[{'属性': '环境', '观点': ['不错', '干净'], '情感倾向': '正向'}, {'属性': '服务', '观点': ['好'], '情感倾向': '正向'}]"},
{'text': '蛋糕味道不错,很好吃,店家很耐心,服务也很好,很棒',
'result': "[{'属性': '蛋糕味道', '观点': ['不错', '好吃'], '情感倾向': '正向'}, {'属性': '店家', '观点': ['耐心'], '情感倾向': '正向'}, {'属性': '服务', '观点': ['好', '棒'], '情感倾向': '正向'}]"},
{'text': '掌柜的服务态度真好,商品质量也相当不错。太喜欢了,下次还买这家!',
'result': "[{'属性': '服务', '观点': ['好'], '情感倾向': '正向'}, {'属性': '质量', '观点': ['不错'], '情感倾向': '正向'}]"},
{'text': '店家货物做工精美,质量不错,就是发货太慢了!',
'result': "[{'属性': '做工', '观点': ['精美'], '情感倾向': '正向'}, {'属性': '质量', '观点': ['不错'], '情感倾向': '正向'}, {'属性': '发货', '观点': ['慢'], '情感倾向': '负向'}]"}]
三.前后端分离式项目部署
完整项目源码为便于管理与下载,已通过数据集的方式项目挂载。源码地址: https://aistudio.baidu.com/aistudio/datasetdetail/178356
感兴趣的可以将其下载到本地解压后根据提供的"项目说明文档.txt"进行项目环境配置操作。项目运行过程中遇到问题欢迎在评论区向我反馈!
希望本项目能够对大家有所帮助,感兴趣的希望可以Fork、喜欢、关注三连❤
# 完整系统源码通过数据集的方式挂载项目
# 下面对其进行解压与查看
%cd /home/aistudio/data/data178356/
!unzip EmotionAnalysisWebSystem.zip
解压后完整系统源码详见data/data178356/目录!
源码目录文件说明:
1.backend文件夹为后端API服务模块,main.py为后端API服务主程序。
2.frontend文件夹为属性级情感分析系统Web前端界面模块,/src/views下存放搭建的新界面。
3.项目说明文档.txt:对项目环境配置进行了详细地介绍,项目必看!
3.1 基于FastAPI完成后端API搭建
本模块将核心介绍如何基于FastAPI完成模型部署与后端Restful API搭建,并通过Postman对接口功能进行测试。
后端服务主程序核心关注backend/main.py 主程序!
对FastAPI后端框架不熟悉的话,建议先学习下其官方文档:https://fastapi.tiangolo.com/zh/
3.1.1 解决跨域问题
# 创建一个 FastAPI「实例」,名字为app
app = FastAPI()
# 设置允许跨域请求,解决跨域问题
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 启动创建的实例app,设置启动ip和端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
3.1.2 单文本情感分析接口搭建
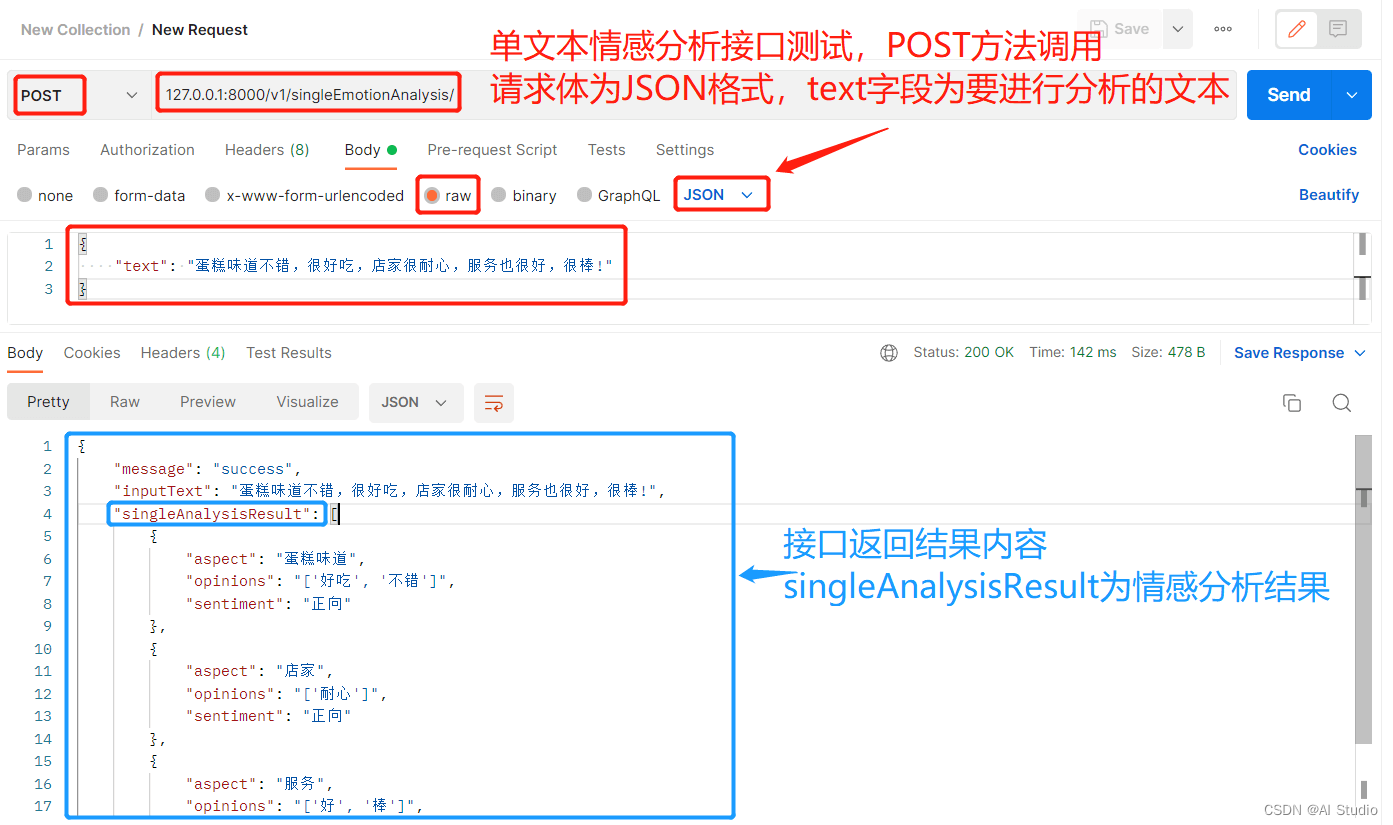
请求接口路径:http://127.0.0.1:8000/v1/singleEmotionAnalysis ,请求方法为POST,请求体格式为json,字段”text“为要进行情感分析的文本内容。
# 定义请求体数据类型:text 用户输入的要进行属性级情感分析的文本
class Document(BaseModel):
text: str
# 单文本情感分析接口:
# 定义路径操作装饰器:POST方法 + API接口路径
@app.post("/v1/singleEmotionAnalysis/", status_code=200)
# 定义路径操作函数,当接口被访问将调用该函数
async def SingleEmotionAnalysis(document: Document):
try:
# 获取用户输入的要进行属性级情感分析的文本内容
input_text = document.text
# 调用加载好的模型进行属性级情感分析
singleAnalysisResult = predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512)
# 接口结果返回
results = {"message": "success", "inputText": document.text, "singleAnalysisResult": singleAnalysisResult}
return results
# 异常处理
except Exception as e:
print("异常信息:", e)
raise HTTPException(status_code=500, detail=str("请求失败,服务器端发生异常!异常信息提示:" + str(e)))
3.1.3 批量文本情感分析接口搭建
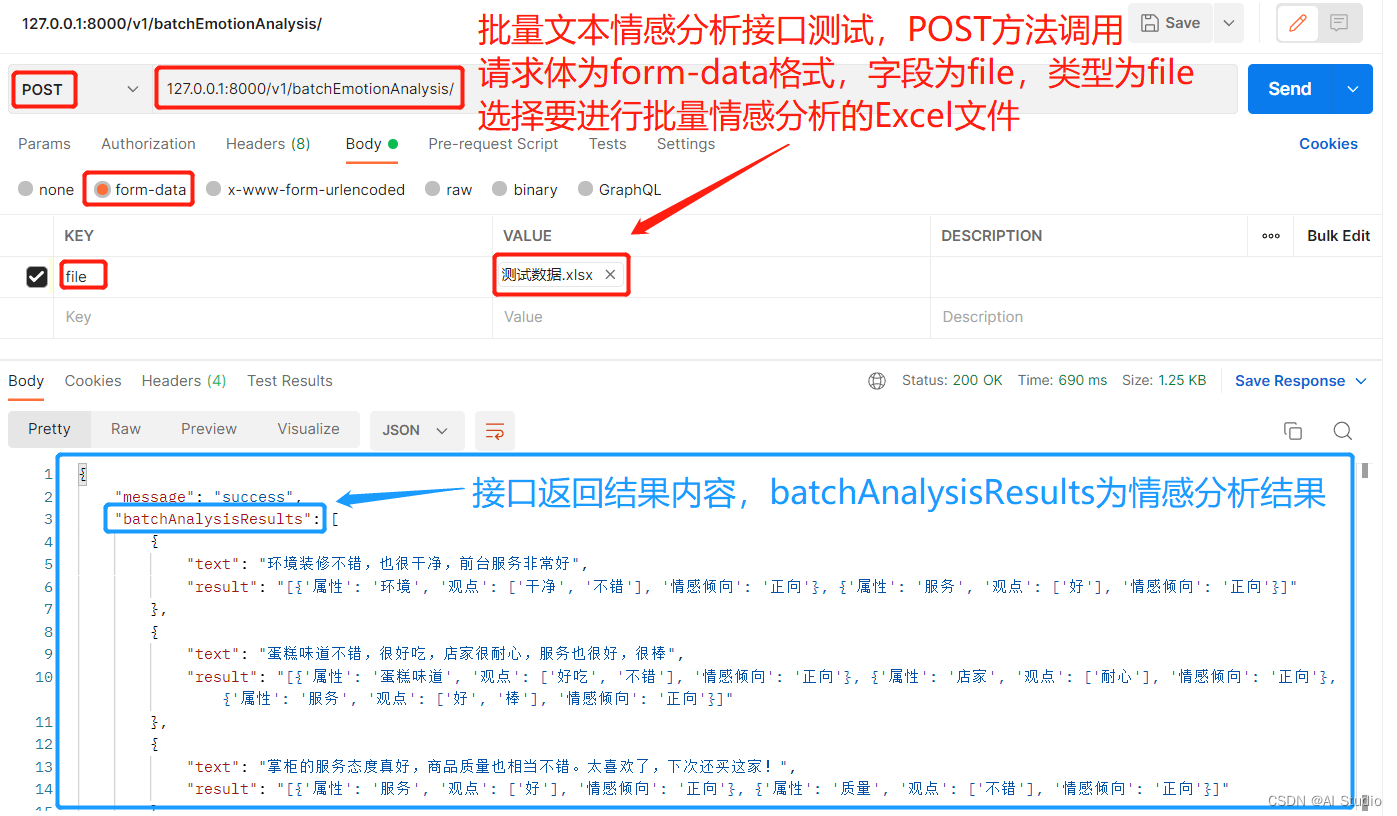
请求接口路径:http://127.0.0.1:8000/v1/batchEmotionAnalysis ,请求方法为POST,请求体格式为form-data,字段为"file",字段类型也为file,内容为要进行批量分析Excel文件。
# 批量文本情感分析接口:
# 定义路径操作装饰器:POST方法 + API接口路径
@app.post("/v1/batchEmotionAnalysis/", status_code=200)
# 定义路径操作函数,当接口被访问将调用该函数
async def BatchEmotionAnalysis(file: UploadFile):
# 读取上传的文件
fileBytes = file.file.read()
fileName = file.filename
# 判断上传文件类型
fileType = fileName.split(".")[-1]
if fileType != "xls" and fileType != "xlsx":
raise HTTPException(status_code=406, detail=str("请求失败,上传文件格式不正确!请上传Excel文件!"))
try:
# 将添加时间标记重命名避免重复
now_time = int(time.mktime(time.localtime(time.time())))
filePath = "./resource/" + str(now_time) + "_" + fileName
# 将用户上传的文件保存到本地
fout = open(filePath, 'wb')
fout.write(fileBytes)
fout.close()
# 读取Excel文件内容进行批量情感分析
df = pd.read_excel(filePath, index_col=None)
# 读取Excel中列名为"text"或"文本"的数据,若无该列名则默认读取第一列数据
if 'text' in df.columns:
contents = df['text']
elif '文本' in df.columns:
contents = df['文本']
else: contents = df[df.columns[0]]
# 批量文本情感分析
batchAnalysisResults = batchPredict(contents, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512)
# 接口结果返回
results = {"message": "success", "batchAnalysisResults": batchAnalysisResults}
return results
# 异常处理
except Exception as e:
print("异常信息:", e)
raise HTTPException(status_code=500, detail=str("请求失败,服务器端发生异常!异常信息提示:" + str(e)))
3.1.4 启动后端服务
运行python main.py 启动后端服务:

3.1.5 Postman接口测试
Postman是一款支持http协议的接口调试与测试工具,其主要特点就是功能强大,使用简单且易用性好。
接下来将通过Postman软件对搭建的后端API进行接口测试,测试接口功能和结果返回是否正常。
单文本情感分析接口测试:
批量文本情感分析接口测试:
3.2 基于Vue+ElementUI搭建前端界面
本模块主要介绍如何基于Vue+ElementUI完成属性级情感分析系统Web界面搭建,并通过Axios发送网络请求对接后端API完成前后端的联调。
前端界面上基于vue-admin通用后台模板搭建:vue-admin-template
界面搭建细节上核心关注src/router/index.js和src/views/两块,router中定义了界面路由,views下为搭建的新界面。
对Vue或ElementUI不熟悉的建议先学习下其官方文档:
VUE官方文档:https://v3.cn.vuejs.org/
ElementUI文档:https://element.eleme.cn/#/zh-CN
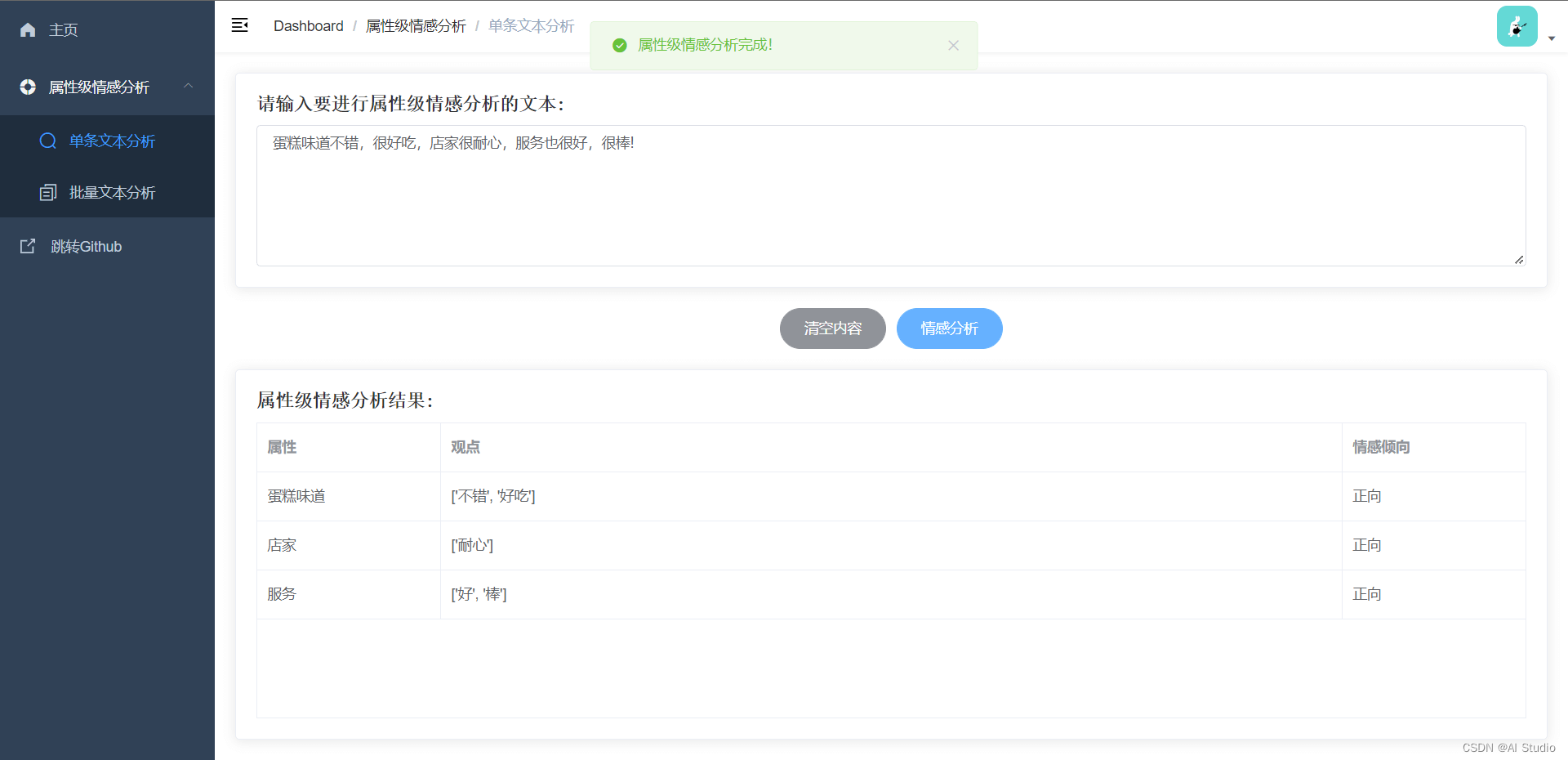
3.2.1 单条文本情感分析界面
界面效果演示:
前端交互主要功能函数:
// 单文本情感分析
emotionAnalysis() {
var that = this
// 获取用户输入框输入的要进行情感分析的文本
var context = that.textarea
if (context === '') {
this.$message({
showClose: true,
message: '输入文本内容不能为空',
type: 'warning'
})
that.analysisResult = ''
that.visible = false
} else {
// 请求后端单文本情感分析接口,请求方法为POST,请求体格式为JSON,字段text为要进行情感分析的文本
axios.post('http://127.0.0.1:8000/v1/singleEmotionAnalysis', {
text: that.textarea
}).then((response) => {
console.log(response.data)
// 获取接口返回的情感分析预测结果并更新界面数据
that.analysisResult = response.data.singleAnalysisResult
that.visible = true
that.$message({
showClose: true,
message: '属性级情感分析完成!',
type: 'success'
})
}).catch((error) => {
// 捕获异常并弹窗提示
console.log(error)
that.analysisResult = ''
that.visible = false
that.$message({
showClose: true,
message: '请求异常,请检查后端服务模块!',
type: 'error'
})
})
}
}
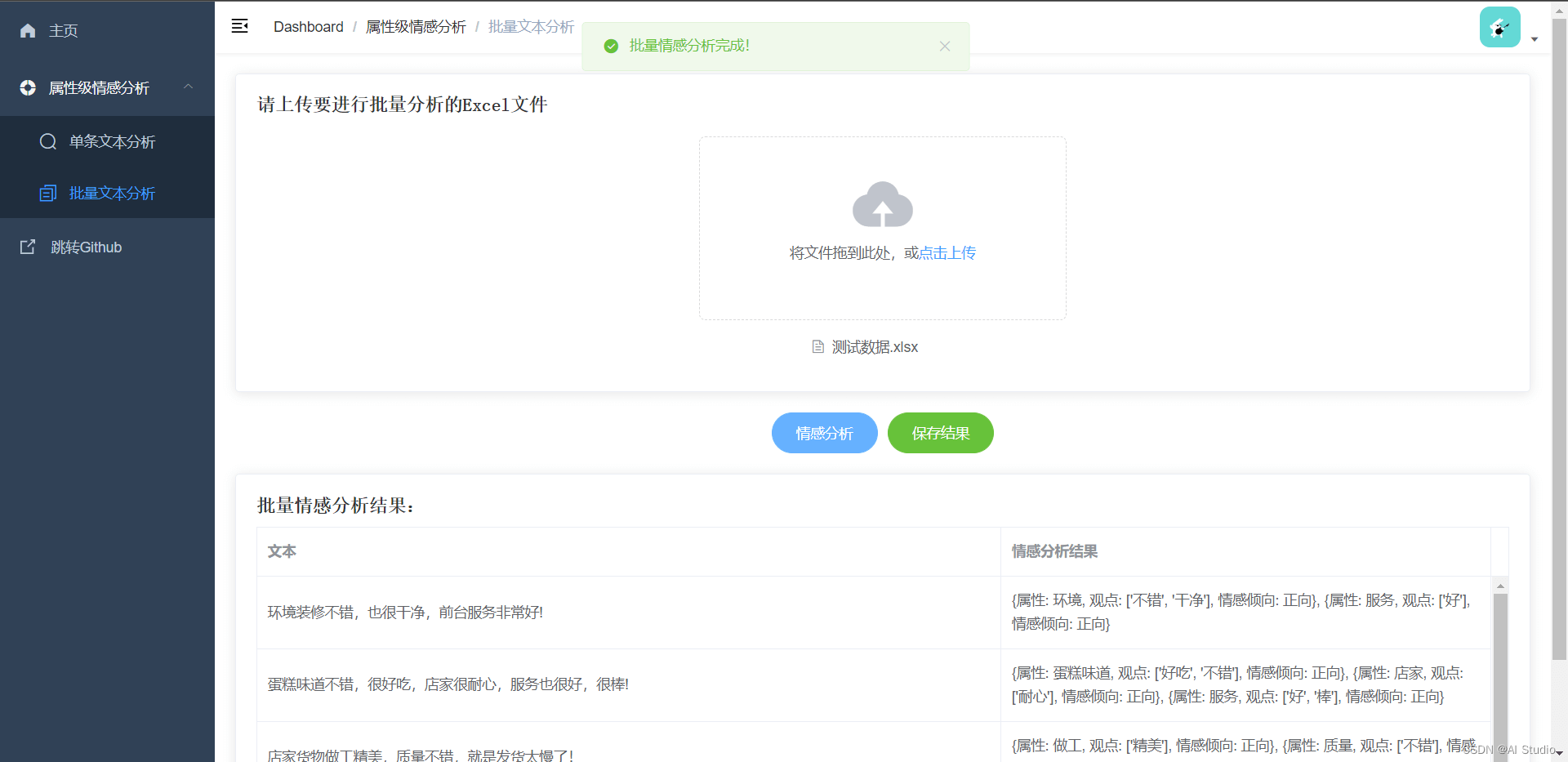
3.2.2 批量文本情感分析界面
界面效果演示:
前端交互主要功能函数:
// 批量文本情感分析
batchEmotionAnalysis() {
var that = this
// 判断用户是否已经选择要上传的文件
if (that.fileData === '') {
this.$message({
showClose: true,
message: '请先选择要进行批量情感分析的Excel文件!',
type: 'warning'
})
that.analysisResults = ''
that.visible = false
return
}
that.visible = true
that.$message({
showClose: true,
message: '批量情感分析完成!',
type: 'success'
})
// 请求后端批量情感分析接口,请求方法为POST,请求体格式为form-data,字段为file,类型也为file
var config = {
headers: {
'Content-Type': 'multipart/form-data'
}
}
var form = new FormData()
form.append('file', that.fileData)
axios.post('http://127.0.0.1:8000/v1/batchEmotionAnalysis', form, config).then((response) => {
// 获取接口返回的情感分析预测结果并更新界面数据
that.analysisResults = response.data.batchAnalysisResults
that.visible = true
that.$message({
showClose: true,
message: '批量情感分析完成!',
type: 'success'
})
}).catch((error) => {
console.log(error)
that.analysisResults = ''
that.visible = false
that.$message({
showClose: true,
message: '请求异常,请检查后端服务模块!',
type: 'error'
})
})
}
四.项目总结
本项目核心介绍了属性级情感分析模型的搭建以及如何基于前后端分离式架构进行Web项目部署。
不同于单条句子整体情感分类存在的内部多属性褒贬不一导致分类精度下降问题,本项目通过抽取所给文本中各个属性及对应评论观点并进行细粒度情感分析从而获取文本中各个属性的情感极性,有效地细化了情感分析粒度,在真实场景中更加实用,能够给到企业用户或商家更加具体有效的建议以及帮助用户优化消费决策。
优化方向:
1.在系统中使用MySQL、MongoDB等数据库进行数据存储以便对数据整体的增删改查管理。
2.添加统计及效果可视化模块便于更加直观地展示整体情感分析分析结果。
3.添加用户评论爬虫模块,获取商家商品全部评论信息以便给出具体的建议,指导决策。
4.结合舆情分析、个性化推荐等进一步泛化应用场景,发挥细粒度情感分析价值。
5.从数据扩充、模型优化等多角度进一步优化属性级情感分析模型效果。
参考项目: 基于PaddleNLP搭建评论观点抽取和情感分析系统
参考文章: 细粒度情感分析在到餐场景中的应用
五.作者介绍
昵称:炼丹师233
Github主页:https://github.com/hchhtc123
研究方向: 全栈小菜鸡,主攻大数据开发和NLP方向,喜欢捣鼓有趣项目。
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/330406 关注我,下次带来更多精彩项目分享!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 4
4 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)