
PaddleTS:风电功率时序预测模型应用
以Baidu KDD Cup 2022 风电预测任务为例,介绍PaddleTS时序预测模型的多种应用
0 项目背景
0.1 任务介绍
2022年kdd cup提供了龙源电力集团有限公司独特的空间动态风力预测数据集:其中包括风力涡轮机的空间分布,以及时间、天气和涡轮机内部状态等动态背景因素。
该数据集的预测目标是134个风机各自在未来时刻下的输出功率。
数据中各字段含义如下:
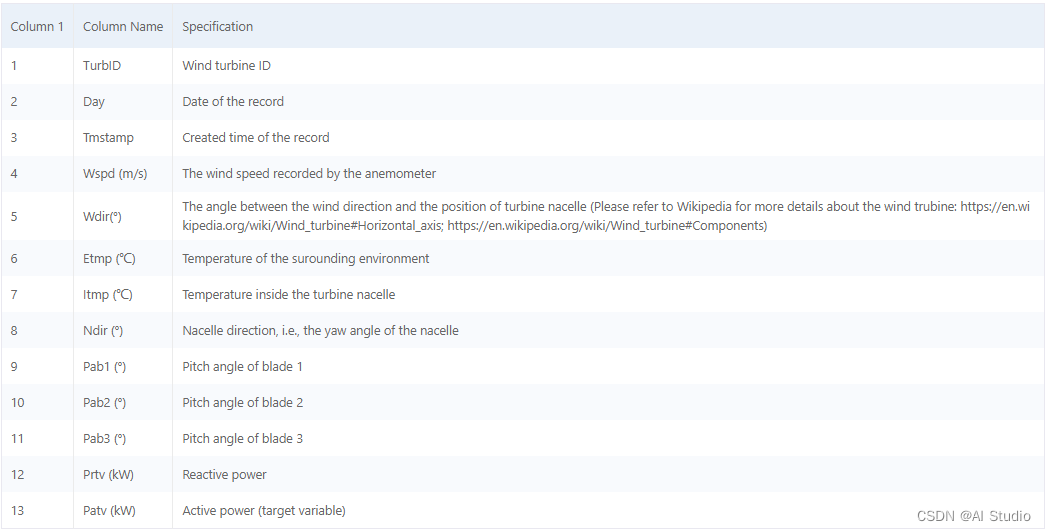
考虑到风电场的特殊性,不同风机间的地理位置也是序列预测的一个重要参考价值。不过本文更关注于与该项目类似的场景,多时间序列预测其实在各个企业里非常常见,比如生产企业不同电机的工况、不同产品在不同地区的销量预测,如果关联性不是特别大的情况,我们可以考虑用纯时间序列预测生成最初始的结果。
0.2 PaddleTS模型库更新介绍
PaddleTS是一款基于飞桨深度学习框架的开源时序建模算法库,其具备统一的时序数据结构、全面的基础模型功能、丰富的数据处理和分析算子以及领先的深度时序算法,可以帮助开发者实现时序数据处理、分析、建模、预测全流程,在预测性维护、智慧能耗分析、价格销量预估等场景中有重要应用价值。
在PaddleTS的最近更新中,新增了时序模型集成Ensemble功能,并且已经支持基于多时序数据集的组合训练。
本文就以风机功率预测为例,介绍PaddleTS模型库的一个典型应用场景,它可以快速、批量生成多路时间序列的预测结果,也可以高效完成时间序列预测的集成学习任务。
1 环境配置
# 安装模型库
!pip install paddlets
#导入需要的包
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler, MinMaxScaler
import datetime
import paddlets
from paddlets import TSDataset
from paddlets import TimeSeries
from paddlets.models.forecasting import MLPRegressor, LSTNetRegressor
from paddlets.transform import Fill, StandardScaler
from paddlets.metrics import MSE, MAE
import warnings
warnings.filterwarnings('ignore')
2 数据集配置
# 读取数据文件
df = pd.read_csv('data/data138339/sdwpf_baidukddcup2022_full.CSV', encoding='gbk')
# 查看1号风机的运行工况数据
df[df.TurbID==1].head()
| TurbID | Day | Tmstamp | Wspd | Wdir | Etmp | Itmp | Ndir | Pab1 | Pab2 | Pab3 | Prtv | Patv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 00:00 | 12.23 | -0.83 | 29.08 | 41.90 | -23.73 | 1.07 | 1.07 | 1.07 | -0.21 | 1549.53 |
| 1 | 1 | 1 | 00:10 | 11.58 | -3.32 | 29.01 | 42.01 | -23.70 | 1.06 | 1.06 | 1.06 | -0.25 | 1549.71 |
| 2 | 1 | 1 | 00:20 | 11.21 | -1.38 | 29.17 | 42.24 | -28.84 | 1.04 | 1.04 | 1.04 | -0.25 | 1534.77 |
| 3 | 1 | 1 | 00:30 | 10.84 | 0.06 | 29.46 | 42.43 | -31.39 | 1.03 | 1.03 | 1.03 | -0.25 | 1508.20 |
| 4 | 1 | 1 | 00:40 | 11.03 | 2.03 | 29.82 | 42.77 | -31.39 | 1.03 | 1.03 | 1.03 | -66.01 | 1517.76 |
在原数据集中,第(X)天和运行时间是分开的字段,而在PaddleTS中,我们一般需要输入一个时间戳,下面就进行数据转换(日期开始计算时间就以2022-01-01为例)。
def serial_date_to_string(srl_no):
new_date = datetime.datetime(2022,1,1) + datetime.timedelta(srl_no - 1)
return new_date.strftime("%Y-%m-%d")
def concat_timestamp(a, b):
return datetime.datetime.strptime(a + ' ' + b, '%Y-%m-%d %H:%M')
df['Date'] = df['Day'].apply(serial_date_to_string)
# 拼接处日期时间的时间戳
df['Date Time'] = df.apply(lambda row: concat_timestamp(row['Date'], row['Tmstamp']), axis=1)
df.head(10)
| TurbID | Day | Tmstamp | Wspd | Wdir | Etmp | Itmp | Ndir | Pab1 | Pab2 | Pab3 | Prtv | Patv | Date | Date Time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 00:00 | 12.23 | -0.83 | 29.08 | 41.90 | -23.73 | 1.07 | 1.07 | 1.07 | -0.21 | 1549.53 | 2022-01-01 | 2022-01-01 00:00:00 |
| 1 | 1 | 1 | 00:10 | 11.58 | -3.32 | 29.01 | 42.01 | -23.70 | 1.06 | 1.06 | 1.06 | -0.25 | 1549.71 | 2022-01-01 | 2022-01-01 00:10:00 |
| 2 | 1 | 1 | 00:20 | 11.21 | -1.38 | 29.17 | 42.24 | -28.84 | 1.04 | 1.04 | 1.04 | -0.25 | 1534.77 | 2022-01-01 | 2022-01-01 00:20:00 |
| 3 | 1 | 1 | 00:30 | 10.84 | 0.06 | 29.46 | 42.43 | -31.39 | 1.03 | 1.03 | 1.03 | -0.25 | 1508.20 | 2022-01-01 | 2022-01-01 00:30:00 |
| 4 | 1 | 1 | 00:40 | 11.03 | 2.03 | 29.82 | 42.77 | -31.39 | 1.03 | 1.03 | 1.03 | -66.01 | 1517.76 | 2022-01-01 | 2022-01-01 00:40:00 |
| 5 | 1 | 1 | 00:50 | 12.23 | 2.65 | 30.22 | 43.10 | -27.37 | 1.07 | 1.07 | 1.07 | -61.25 | 1549.79 | 2022-01-01 | 2022-01-01 00:50:00 |
| 6 | 1 | 1 | 01:00 | 12.19 | -1.50 | 30.52 | 43.23 | -23.69 | 1.07 | 1.07 | 1.07 | -0.26 | 1529.05 | 2022-01-01 | 2022-01-01 01:00:00 |
| 7 | 1 | 1 | 01:10 | 13.51 | -2.80 | 30.87 | 43.55 | -23.69 | 1.10 | 1.10 | 1.10 | -0.27 | 1549.62 | 2022-01-01 | 2022-01-01 01:10:00 |
| 8 | 1 | 1 | 01:20 | 11.93 | -2.88 | 31.10 | 43.63 | -23.69 | 1.06 | 1.06 | 1.06 | -0.28 | 1546.67 | 2022-01-01 | 2022-01-01 01:20:00 |
| 9 | 1 | 1 | 01:30 | 11.31 | -0.08 | 31.44 | 43.92 | -23.69 | 1.04 | 1.04 | 1.04 | -0.20 | 1508.70 | 2022-01-01 | 2022-01-01 01:30:00 |
3 模型应用
3.1 单路时间序列预测
以1号风机为例,我们用PaddleTS进行时间序列预测,风机数据集是单变量数据,只包含单列的预测目标,但是包含了多列协变量,这里就用到对协变量的设定,同时使用前值填充缺失值。
target_cov_dataset = TSDataset.load_from_dataframe(
df[df.TurbID==1],
time_col='Date Time',
target_cols='Patv',
observed_cov_cols=['Wspd', 'Wdir', 'Etmp', 'Itmp', 'Ndir',
'Pab1', 'Pab2', 'Pab3', 'Prtv'],
freq='10min',
fill_missing_dates=True,
fillna_method='pre'
)
target_cov_dataset.plot(['Prtv', 'Wspd', 'Wdir', 'Etmp', 'Itmp', 'Ndir',
'Pab1', 'Pab2', 'Pab3', 'Prtv'])
<AxesSubplot:xlabel='Date Time'>
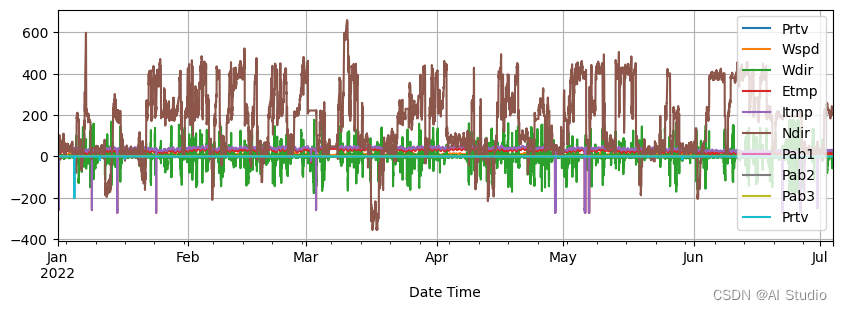
1号风机工况的数据分析结果如下,从分析结果可以看出,目标列风机功率Patv的变化还是非常大的。
target_cov_dataset.summary()
| Patv | Wspd | Wdir | Etmp | Itmp | Ndir | Pab1 | Pab2 | Pab3 | Prtv | |
|---|---|---|---|---|---|---|---|---|---|---|
| missing | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| count | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 | 26496.000000 |
| mean | 483.162403 | 5.672956 | 0.293192 | 26.156749 | 36.125681 | 170.873253 | 1.247933 | 1.244720 | 1.253794 | -0.249082 |
| std | 530.258304 | 3.591174 | 35.825403 | 19.856172 | 20.364632 | 161.206202 | 0.389222 | 0.387531 | 0.392216 | 1.862634 |
| min | -5.430000 | 0.000000 | -177.410000 | -272.970000 | -272.970000 | -355.460000 | 0.750000 | 0.750000 | 0.750000 | -201.280000 |
| 25% | 0.000000 | 2.580000 | -2.780000 | 21.870000 | 32.340000 | 41.350000 | 0.990000 | 0.990000 | 0.990000 | -0.280000 |
| 50% | 269.805000 | 5.160000 | 0.000000 | 28.350000 | 38.460000 | 185.080000 | 1.000000 | 1.000000 | 1.000000 | -0.250000 |
| 75% | 851.077500 | 8.210000 | 2.870000 | 33.020000 | 42.870000 | 283.580000 | 1.812500 | 1.760000 | 1.880000 | -0.220000 |
| max | 1551.170000 | 23.200000 | 175.910000 | 44.200000 | 56.080000 | 658.490000 | 1.900000 | 1.900000 | 1.900000 | 0.380000 |
划分训练集、验证集、测试集
train_dataset, val_test_dataset = target_cov_dataset.split(0.7)
val_dataset, test_dataset = val_test_dataset.split(0.5)
train_dataset.plot(add_data=[val_dataset,test_dataset], labels=['Val', 'Test'])
<AxesSubplot:xlabel='Date Time'>
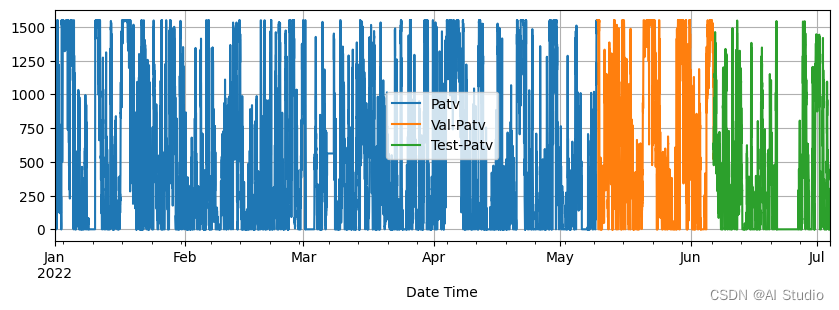
数据处理时,可以将指定列的值缩放为零均值和单位方差来实现归一化转换。
# scaler = StandardScaler()
# scaler.fit(train_dataset)
# train_dataset_scaled = scaler.transform(train_dataset)
# val_test_dataset_scaled = scaler.transform(val_test_dataset)
# val_dataset_scaled = scaler.transform(val_dataset)
# test_dataset_scaled = scaler.transform(test_dataset)
我们先引入LSTM模型,做单模型的单时间序列预测任务示例。
lstm = LSTNetRegressor(
in_chunk_len = 6 * 12,
out_chunk_len = 12,
max_epochs=50
)
lstm.fit(train_dataset, val_dataset)
subset_test_pred_dataset = lstm.predict(val_dataset)
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
# 模型评估
mae = MAE()
mae(subset_test_dataset, subset_test_pred_dataset)
{'Patv': 79.91336100260416}
# 预测结果可视化
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
subset_test_dataset.plot(add_data=subset_test_pred_dataset, labels=['Pred'])
<AxesSubplot:xlabel='Date Time'>
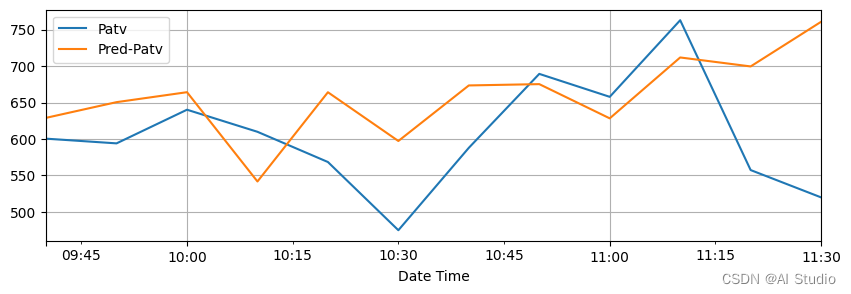
上图显示的是训练模型对1号风机未来2小时预测结果与测试集实际趋势的对比。
# 模型保存
lstm.save("lstm")
# 模型加载
from paddlets.models.model_loader import load
loaded_lstm = load("lstm")
# 模型预测
loaded_lstm.predict(test_dataset)
Patv
2022-07-04 00:00:00 -39.559624
2022-07-04 00:10:00 -0.741657
2022-07-04 00:20:00 -30.599289
2022-07-04 00:30:00 11.109373
2022-07-04 00:40:00 8.678387
2022-07-04 00:50:00 -18.625191
2022-07-04 01:00:00 10.848251
2022-07-04 01:10:00 33.485470
2022-07-04 01:20:00 -10.060726
2022-07-04 01:30:00 14.956402
2022-07-04 01:40:00 38.031429
2022-07-04 01:50:00 37.511040
3.2 单路时间序列预测-集成模型
集成模型是用集成学习的思想去把多个PaddleTS的预测器集合成一个预测器。目前PaddleTS支持两种集成预测器StackingEnsembleForecaster 和 WeightingEnsembleForecaster
步骤包括:
1.准备数据
2.准备模型
3.组装和拟合模型
4.进行回测
5.模型保存与加载
接下来,我们用集成模型来预测1号风机的输出功率变化。首先是准备集成预测器需要的底层模型,这里我们选择RNN,LSTM和MLP
from paddlets.models.forecasting import MLPRegressor
from paddlets.models.forecasting import LSTNetRegressor
from paddlets.models.forecasting import RNNBlockRegressor
lstm_params = {
'sampling_stride': 24,
'eval_metrics':["mse", "mae"],
'batch_size': 8,
'max_epochs': 20,
'patience': 100
}
rnn_params = {
'sampling_stride': 24,
'eval_metrics': ["mse", "mae"],
'batch_size': 8,
'max_epochs': 20,
'patience': 100,
}
mlp_params = {
'sampling_stride': 24,
'eval_metrics': ["mse", "mae"],
'batch_size': 8,
'max_epochs': 20,
'patience': 100,
'use_bn': True,
}
为了保持模型预测的一致性, in_chunk_len, out_chunk_len, skip_chunk_len, 这三个参数已经被提取到集成模型中,在组装模型时统一设定。
from paddlets.ensemble import StackingEnsembleForecaster
reg = StackingEnsembleForecaster(
in_chunk_len= 10 * 12,
out_chunk_len= 12,
skip_chunk_len=0,
estimators=[(LSTNetRegressor, lstm_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)])
# 模型拟合
reg.fit(train_dataset, val_dataset)
subset_test_pred_dataset = reg.predict(val_dataset)
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
# 模型评估
mae = MAE()
mae(subset_test_dataset, subset_test_pred_dataset)
{'Patv': 124.78068320888026}
subset_test_dataset, _ = test_dataset.split(len(subset_test_pred_dataset.target))
subset_test_dataset.plot(add_data=subset_test_pred_dataset, labels=['Pred'])
<AxesSubplot:xlabel='Date Time'>
3.3 多路时序联合训练
当我们需要对多路时序数据进行训练以及预测的时候,其中的一个方法即是对每组时序数据分别创建模型进行独立的训练以及预测;但是在很多实际的场景中,我们希望针对多组时序数据去联合训练一个模型,这样能更好的提升效率以及获得更好的模型效果。针对多时序数据组合训练的需求,PaddleTS提供了从数据导入、数据转换以及模型训练的全流程支持。
PaddleTS支持基于原始数据中的group_id属性进行自动的数据分组导入,如设备id等属性,相同的group_id代表一组时间序列,不同组时间序列时间的时间索引可以重复。在风机功率预测这个项目中,group_id对应地就是每个风机的TurbID。
# 由于static_cov_cols不支持int模式,需要对df.TurbID数据格式进行调整
df.TurbID = df.TurbID.astype ('float32')
tsdatasets = TSDataset.load_from_dataframe(
df=df[df.TurbID < 5],
group_id='TurbID',
time_col='Date Time',
target_cols='Patv',
observed_cov_cols=['Wspd', 'Wdir', 'Etmp', 'Itmp', 'Ndir',
'Pab1', 'Pab2', 'Pab3', 'Prtv'],
static_cov_cols='TurbID',
freq='10min',
fill_missing_dates=True,
fillna_method='pre'
)
print(f"The type of tsdatasets is {type(tsdatasets)},\n and the length of tsdatasets is {len(tsdatasets)},\n the length of first tsdataset target is {len(tsdatasets[0].target)},\n the length of second tsdataset target is {len(tsdatasets[1].target)}")
The type of tsdatasets is <class 'list'>,
and the length of tsdatasets is 4,
the length of first tsdataset target is 26496,
the length of second tsdataset target is 26496
上述配置中的static_cov_cols是否传递并指定为group_id是可选的,如果设置了改选项,group_id 将作为静态协变量加入模型的训练。需要注意两个地方:
static_cov_cols不支持int格式,使用时需要进行转换- PaddleTS当前不是所有的模型都支持静态协变量的输入,详情请参考模型文档介绍。
lstm = LSTNetRegressor(
in_chunk_len = 20 * 12,
out_chunk_len = 12,
max_epochs=20
)
lstm.fit(tsdatasets)
[2022-11-21 20:14:04,066] [paddlets.models.forecasting.dl.paddle_base_impl] [WARNING] No early stopping will be performed, last training weights will be used.
[2022-11-21 20:14:55,465] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 000| loss: 96393.502945| 0:00:51s
[2022-11-21 20:15:46,277] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 001| loss: 76399.481935| 0:01:42s
[2022-11-21 20:16:37,737] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 002| loss: 74530.338250| 0:02:33s
[2022-11-21 20:17:30,884] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 003| loss: 73814.142585| 0:03:26s
[2022-11-21 20:18:20,680] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 004| loss: 73876.998849| 0:04:16s
[2022-11-21 20:19:11,718] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 005| loss: 73382.229734| 0:05:07s
[2022-11-21 20:20:02,187] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 006| loss: 73521.237403| 0:05:58s
[2022-11-21 20:20:51,846] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 007| loss: 73424.669836| 0:06:47s
[2022-11-21 20:21:43,394] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 008| loss: 73413.131330| 0:07:39s
[2022-11-21 20:22:34,030] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 009| loss: 73068.617749| 0:08:29s
[2022-11-21 20:23:23,069] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 010| loss: 73203.213249| 0:09:18s
[2022-11-21 20:24:14,081] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 011| loss: 73100.656483| 0:10:10s
[2022-11-21 20:25:03,380] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 012| loss: 73278.646346| 0:10:59s
[2022-11-21 20:25:53,929] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 013| loss: 72921.548220| 0:11:49s
[2022-11-21 20:26:45,498] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 014| loss: 73027.688968| 0:12:41s
[2022-11-21 20:27:36,459] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 015| loss: 72949.607424| 0:13:32s
[2022-11-21 20:28:30,626] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 016| loss: 73037.687535| 0:14:26s
[2022-11-21 20:29:24,743] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 017| loss: 73102.007127| 0:15:20s
[2022-11-21 20:30:14,443] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 018| loss: 73060.095143| 0:16:10s
[2022-11-21 20:31:04,961] [paddlets.models.common.callbacks.callbacks] [INFO] epoch 019| loss: 72979.538584| 0:17:00s
# 打印预测结果
for i, tsdataset in enumerate(tsdatasets):
print(f"The TurbID {i}, future Patv prediction is \n {lstm.predict(tsdataset)}")
The TurbID 0, future Patv prediction is
Patv
2022-07-04 00:00:00 40.926163
2022-07-04 00:10:00 30.100666
2022-07-04 00:20:00 30.321606
2022-07-04 00:30:00 43.445236
2022-07-04 00:40:00 41.291222
2022-07-04 00:50:00 40.430859
2022-07-04 01:00:00 57.008026
2022-07-04 01:10:00 109.433533
2022-07-04 01:20:00 145.056900
2022-07-04 01:30:00 168.143448
2022-07-04 01:40:00 139.902954
2022-07-04 01:50:00 145.026184
The TurbID 1, future Patv prediction is
Patv
2022-07-04 00:00:00 32.137245
2022-07-04 00:10:00 17.005648
2022-07-04 00:20:00 18.517353
2022-07-04 00:30:00 28.782478
2022-07-04 00:40:00 16.493038
2022-07-04 00:50:00 21.965120
2022-07-04 01:00:00 34.018673
2022-07-04 01:10:00 89.651764
2022-07-04 01:20:00 97.128700
2022-07-04 01:30:00 107.836067
2022-07-04 01:40:00 82.898354
2022-07-04 01:50:00 88.552048
The TurbID 2, future Patv prediction is
Patv
2022-07-04 00:00:00 64.704575
2022-07-04 00:10:00 40.593002
2022-07-04 00:20:00 43.270939
2022-07-04 00:30:00 62.650829
2022-07-04 00:40:00 58.822300
2022-07-04 00:50:00 51.228718
2022-07-04 01:00:00 58.598160
2022-07-04 01:10:00 105.977158
2022-07-04 01:20:00 123.023895
2022-07-04 01:30:00 137.165131
2022-07-04 01:40:00 119.433212
2022-07-04 01:50:00 123.936630
The TurbID 3, future Patv prediction is
Patv
2022-07-04 00:00:00 60.470425
2022-07-04 00:10:00 45.014469
2022-07-04 00:20:00 45.604843
2022-07-04 00:30:00 57.192905
2022-07-04 00:40:00 46.160336
2022-07-04 00:50:00 48.766960
2022-07-04 01:00:00 59.764709
2022-07-04 01:10:00 109.161385
2022-07-04 01:20:00 113.590012
2022-07-04 01:30:00 123.839676
2022-07-04 01:40:00 112.825729
2022-07-04 01:50:00 113.946777
839676
2022-07-04 01:40:00 112.825729
2022-07-04 01:50:00 113.946777
# 输出最后一批时序数据的时间索引
lstm.predict(tsdataset)['Patv'].index
DatetimeIndex(['2022-07-04 00:00:00', '2022-07-04 00:10:00',
'2022-07-04 00:20:00', '2022-07-04 00:30:00',
'2022-07-04 00:40:00', '2022-07-04 00:50:00',
'2022-07-04 01:00:00', '2022-07-04 01:10:00',
'2022-07-04 01:20:00', '2022-07-04 01:30:00',
'2022-07-04 01:40:00', '2022-07-04 01:50:00'],
dtype='datetime64[ns]', freq='10T')
# 输出最后一批时序数据的预测结果
lstm.predict(tsdataset)['Patv'].values
array([ 60.470425, 45.01447 , 45.604843, 57.192905, 46.160336,
48.76696 , 59.76471 , 109.161385, 113.59001 , 123.839676,
112.82573 , 113.94678 ], dtype=float32)
4 小结
本文以风电功率预测任务为例,介绍了PaddleTS模型库的两大亮点功能:集成学习与多路时间序列预测。这可能也是在日常生产中,时间序列预测最广泛、最迫切的需求了。
后续,我们将继续探索PaddleTS模型库其它强大而实用的功能,给PaddleTS的研发大佬们点赞!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 4
4 1
1- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)