
基于飞桨的“小书虫”儿童电子阅读器
本项目面向儿童开发出一种基于云上人工智能推荐系统,将电子纸显示技术与有声画书相结合的多媒体电子书设备,具备纸张显示效果、互联网+个性推荐、多感官阅读等优势,能够在保护儿童视力的同时,培养其阅读习惯。
项目背景
教育学和心理学的研究表明,幼儿的阅读能力对认知能力的发展影响最大,尤其是0—6岁阶段的早期阅读能力,是影响幼儿未来学习能力和水平的关键。
可是如今,快餐式媒体信息的爆发,导致儿童的精神世界日益匮乏。很多六七岁的儿童只知道流行动画片里的人物,每天刷短视频、玩游戏,与书中精彩纷呈世界的距离却越来越遥远。对智能手机、平板电脑的过度依赖不仅严重影响儿童的视力,更扼杀了他们的精神世界。因而,越来越多的家长选择回归传统的教育模式,以书籍作为培养儿童阅读能力的主要途径。
然而,不论是纸质书籍还是电子产品,都存在着许多问题。第一,纸质书籍仅有图画和文字,缺少声音的辅助,且由于识字不多,学龄前儿童难以独立阅读。而家长们往往并没有太多时间陪同儿童阅读书本,无法带领其领略书中那精彩纷呈的世界。第二,对于儿童而言,电子产品中的有声媒体(如动画片)虽更易接受,但其显示效果与书籍差异较大,长时间注视背光液晶屏的会严重影响儿童的视力健康,不利于儿童良好阅读习惯的培养。此外,现有的电子书产品缺少针对儿童开发的图画、文字与声音同步显示功能,亦无法根据学龄前儿童的个人喜好为其推荐个性化图书,且大多数产品的外型不适合儿童使用。
如图,针对于市面上目前存在的各种可供儿童阅读的用具的缺点,我们需要一种既能够为儿童提供视觉、听觉等多感官阅读体验,激发儿童阅读兴趣,还能够根据儿童阅读兴趣进行个性化推荐,培养儿童阅读能力,更能够保护儿童健康视力的阅读途径。
技术方案
1. 技术方向
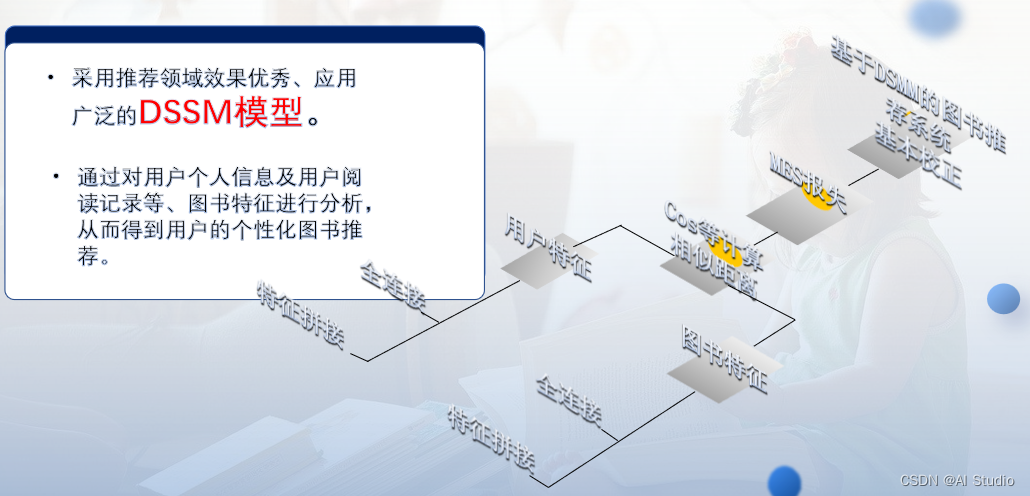
为更好地了解儿童的阅读兴趣,并根据儿童阅读习惯计算并推荐适合儿童阅读的书籍,培养儿童的阅读能力。本作品采用人工智能推荐算法。推荐算法使用工业界广泛应用、推荐效果十分优秀的DSSM双塔模型。
2. 技术平台及方案
- 技术平台
本作品基于百度飞桨平台进行人工智能推荐算法开发,在飞桨平台中构建基于深度学习的推荐算法。
- 技术方案
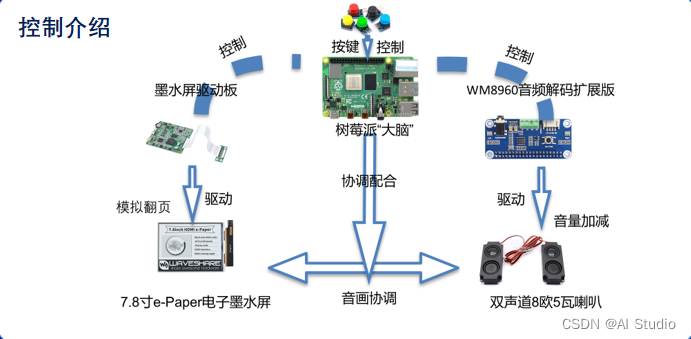
①控制电路介绍
②屏幕显示
屏幕上上使用电子墨水屏模块,6英寸,分辨率为1448×1072,使用IT8951作为控制器,使用SPI接口进行控制。具有功耗低、视角宽、阳光直射下仍可清晰显示等优点。
③音频
采用WM8960低功耗立体声编解码器,通过I2C接口控制,I2S接口传输音频。板载标准3.5mm耳机接口,可通过外接耳机播放音乐,同时也可通过双通道喇叭接口外接喇叭播放。采用多线程控制保证视频音频同步播放。
④按键电路
使用按键中断完成翻页、换书、音量控制等功能的实现,对按键上拉输入树莓派,按下按键时候检测到下降沿,经过延时防抖后接入按键中断。
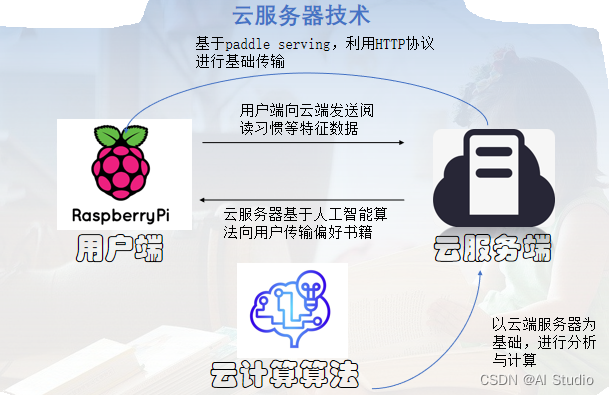
⑤云技术
本作品采用云技术,能够不断更新书库资源。此外,当儿童阅读书籍时,其阅读信息传输至云端服务器,云端部署有推荐算法,对数据进行训练生成个性化推荐模型,并将该用户个性化推荐结果传输至树莓派,从而完成个性化阅读书籍的推荐。
3. 数据获取及处理途径
通过构建user和item两个独立的子网络,将训练好的两个“塔”中的user embedding 和item embedding各自缓存到内存数据库中。线上预测的时候只需要在内存中进行相似度运算即可。
在我们的书籍推荐算法中,数据集主要分为三个文件,分别为用户数据文件、书籍数据文件、评分数据文件。用户数据文件的数据格式为用户序号、性别、年龄。
书籍数据文件中数据格式为书籍序号、书籍标题、书籍种类。评分数据文件中数据格式为用户序号、书籍序号、用户评分。
通过以下过程得到各特征之间的相似度:
①分别将用户、书籍的多个特征数据转换成特征向量。
②对这些特征向量,使用全连接层进一步提取特征。
③将用户、书籍多个数据的特征向量融合成一个向量表示,方便进行相似度计算。
④计算特征之间的相似度。
根据用户的阅读历史记录、收藏等,能够将这些用户原始数据传输至云服务器,云服务器使用上述推荐算法进行训练,得到用户的阅读特征,并在我们现有书库中进行特征匹配,为用户进行个性化推荐。根据推荐结果将相关图书传输至用户使用端。
创新亮点
1. 互联网+个性化推荐
我们的作品基于大数据、云计算等先进技术。在未来我们的书库计划设立近万本图书,并且根据儿童对于不同类别的书观看的时间进行处理,迅速判断儿童喜欢什么样类别的书籍,并且根据其喜爱类别推荐下一本书籍,让其真正喜爱上阅读。
2. 高稳定性阅读环境
我们的作品使用了C语言进行开发,采用树莓派作为整体的开发环境,使用3d打印技术完成了作品外壳,令其具有较高的稳定性,适合长时间的观看。
3. 原生态纸张显示效果
与传统阅读器不同,我们的作品使用了墨水屏,相较于传统屏幕,墨水屏显示效果接近传统纸张。这能够让儿童更加适应传统的纸质书籍,也能够切实有效地保护儿童的眼睛。
4. 按键式操作布局—更适宜儿童
根据学龄前儿童不易操作电子产品的特点,我们初步没有采用触屏方案,相对的,我们采用了按键进行控制。一方面,按键相对于触屏来说更为简单易用,另一方面,按键也能让家长更方便的控制儿童使用本作品的时间。
5. 多感官阅读—提供更优质的阅读
与市面上的其他产品不同,我们的阅读文件采用了插画+文字+声音的形式,相较于文字,一幅幅精美的原创插画更能够起儿童的兴趣。耳边是温柔的故事,眼中是精美的图画。配合着文字,一幅幅生动的画卷徐徐展开。我们希望能在孩子们的心中树立起对于书本的美好印象,让他们真正的爱上读书。
配套代码
1. 数据处理
数据集主要分为三个文件,分别为 user.dat、book.dat、ratings.dat文件
-
用户数据文件user.dat中的数据格式为:UserID::Gender::Age,分别代表其用户序号、性别、年龄
-
书籍数据文件book.dat中数据格式为:BookID::BookTitle::BookCat,分别代表书籍序号、书籍标题、书籍种类
-
评分数据文件ratings.dat中数据格式为:UserID::BookID::Rating,分别代表用户序号、书籍序号、用户评分
import paddle
from paddle.nn import Linear, Embedding, Conv2D
import paddle.nn.functional as F
import math
import random
import numpy as np
from PIL import Image
import math
class BookLen(object):
def __init__(self, use_poster):
self.use_poster = use_poster
# 声明每个数据文件的路径
usr_info_path = "./work/user.dat"
if use_poster:
rating_path = "./work/new_rating.txt"
else:
rating_path = "./work/ratings.dat"
book_info_path = "./work/book.dat"
self.poster_path = "./work/posters/"
# 得到书籍数据
self.book_info, self.book_cat, self.book_title = self.get_book_info(book_info_path)
# 记录书籍的最大ID
self.max_book_cat = np.max([self.book_cat[k] for k in self.book_cat])
self.max_book_tit = np.max([self.book_title[k] for k in self.book_title])
self.max_book_id = np.max(list(map(int, self.book_info.keys())))
# 记录用户数据的最大ID
self.max_usr_id = 0
self.max_usr_age = 0
self.max_usr_job = 0
# 得到用户数据
self.usr_info = self.get_usr_info(usr_info_path)
# 得到评分数据
self.rating_info = self.get_rating_info(rating_path)
# 构建数据集
self.dataset = self.get_dataset(usr_info=self.usr_info,
rating_info=self.rating_info,
book_info=self.book_info)
# 划分数据集,获得数据加载器
self.train_dataset = self.dataset[:int(len(self.dataset)*0.9)]
self.valid_dataset = self.dataset[int(len(self.dataset)*0.9):]
print("##Total dataset instances: ", len(self.dataset))
print("##BookLens dataset information: \nusr num: {}\n"
"book num: {}".format(len(self.usr_info),len(self.book_info)))
# 得到书籍数据
def get_book_info(self, path):
# 打开文件,读取所有数据到data中
with open(path, 'r') as f:
data = f.readlines()
# 建立三个字典,分别用户存放书籍所有信息,书籍的名字信息、类别信息
book_info, book_titles, book_cat = {}, {}, {}
# 对书籍名字、类别中不同的文字计数
t_count, c_count = 1, 1
count_tit = {}
# 按行读取数据并处理
for item in data:
item = item.strip().split("::")
v_id = item[0]
v_title = item[1]
cats = item[2].split('|')
# titles = v_title.split()
# 统计书籍名字的汉字,并给每个汉字一个序号,放在book_titles中
for t in v_title:
if t not in book_titles:
book_titles[t] = t_count
t_count += 1
# 统计书籍类别单词,并给每个单词一个序号,放在book_cat中
for cat in cats:
if cat not in book_cat:
book_cat[cat] = c_count
c_count += 1
# 补0使书籍名称对应的列表长度为12
v_tit = [book_titles[k] for k in v_title]
while len(v_tit)<12:
v_tit.append(0)
# 补0使电影种类对应的列表长度为3
v_cat = [book_cat[k] for k in cats]
while len(v_cat)<3:
v_cat.append(0)
# 保存电影数据到book_info中
book_info[v_id] = {'book_id': int(v_id),
'title': v_tit,
'category': v_cat}
return book_info, book_cat, book_titles
def get_usr_info(self, path):
# 性别转换函数,M-0, F-1
def gender2num(gender):
return 1 if gender == 'F' else 0
# 打开文件,读取所有行到data中
with open(path, 'r') as f:
data = f.readlines()
# 建立用户信息的字典
use_info = {}
max_usr_id = 0
#按行索引数据
for item in data:
# 去除每一行中和数据无关的部分
item = item.strip().split("::")
usr_id = item[0]
# 将字符数据转成数字并保存在字典中
use_info[usr_id] = {'usr_id': int(usr_id),
'gender': gender2num(item[1]),
'age': int(item[2])}
self.max_usr_id = max(self.max_usr_id, int(usr_id))
self.max_usr_age = max(self.max_usr_age, int(item[2]))
# self.max_usr_job = max(self.max_usr_job, int(item[3]))
return use_info
# 得到评分数据
def get_rating_info(self, path):
# 读取文件里的数据
with open(path, 'r') as f:
data = f.readlines()
# 将数据保存在字典中并返回
rating_info = {}
for item in data:
item = item.strip().split("::")
usr_id,book_id,score = item[0],item[1],item[2]
if usr_id not in rating_info.keys():
rating_info[usr_id] = {book_id:float(score)}
else:
rating_info[usr_id][book_id] = float(score)
return rating_info
# 构建数据集
def get_dataset(self, usr_info, rating_info, book_info):
trainset = []
for usr_id in rating_info.keys():
usr_ratings = rating_info[usr_id]
for book_id in usr_ratings:
trainset.append({'usr_info': usr_info[usr_id],
'book_info': book_info[book_id],
'scores': usr_ratings[book_id]})
return trainset
def load_data(self, dataset=None, mode='train'):
use_poster = False
# 定义数据迭代Batch大小
BATCHSIZE = 10
data_length = len(dataset)
index_list = list(range(data_length))
# 定义数据迭代加载器
def data_generator():
# 训练模式下,打乱训练数据
if mode == 'train':
random.shuffle(index_list)
# 声明每个特征的列表
usr_id_list,usr_gender_list,usr_age_list = [], [], []
book_id_list,book_tit_list,book_cat_list,book_poster_list = [], [], [], []
score_list = []
# 索引遍历输入数据集
for idx, i in enumerate(index_list):
# 获得特征数据保存到对应特征列表中
usr_id_list.append(dataset[i]['usr_info']['usr_id'])
usr_gender_list.append(dataset[i]['usr_info']['gender'])
usr_age_list.append(dataset[i]['usr_info']['age'])
book_id_list.append(dataset[i]['book_info']['book_id'])
book_tit_list.append(dataset[i]['book_info']['title'])
book_cat_list.append(dataset[i]['book_info']['category'])
book_id = dataset[i]['book_info']['book_id']
if use_poster:
# 不使用图像特征时,不读取图像数据,加快数据读取速度
poster = Image.open(self.poster_path+'book_id{}.jpg'.format(str(mov_id[0])))
poster = poster.resize([64, 64])
if len(poster.size) <= 2:
poster = poster.convert("RGB")
mov_poster_list.append(np.array(poster))
score_list.append(int(dataset[i]['scores']))
# 如果读取的数据量达到当前的batch大小,就返回当前批次
if len(usr_id_list)==BATCHSIZE:
# 转换列表数据为数组形式,reshape到固定形状
usr_id_arr = np.array(usr_id_list)
usr_gender_arr = np.array(usr_gender_list)
usr_age_arr = np.array(usr_age_list)
book_id_arr = np.array(book_id_list)
book_cat_arr = np.reshape(np.array(book_cat_list), [BATCHSIZE, 3]).astype(np.int64)
book_tit_arr = np.reshape(np.array(book_tit_list), [BATCHSIZE, 1, 12]).astype(np.int64)
if use_poster:
book_poster_arr = np.reshape(np.array(mov_poster_list)/127.5 - 1, [BATCHSIZE, 3, 64, 64]).astype(np.float32)
else:
mov_poster_arr = np.array([0.])
scores_arr = np.reshape(np.array(score_list), [-1, 1]).astype(np.float32)
# 放回当前批次数据
yield [usr_id_arr, usr_gender_arr, usr_age_arr], \
[book_id_arr, book_cat_arr, book_tit_arr], scores_arr
# 清空数据
usr_id_list, usr_gender_list, usr_age_list = [], [], []
book_id_list, book_tit_list, book_cat_list, score_list = [], [], [], []
book_poster_list = []
return data_generator
2. 模型设计
神经网络模型的设计包含如下步骤:
-
分别将用户、书籍的多个特征数据转换成特征向量。
-
对这些特征向量,使用全连接层或者卷积层进一步提取特征。
-
将用户、书籍多个数据的特征向量融合成一个向量表示,方便进行相似度计算。
-
计算特征之间的相似度。
class Model(paddle.nn.Layer):
def __init__(self, use_poster, use_book_title, use_book_cat, use_age_job,fc_sizes):
super(Model, self).__init__()
# 将传入的name信息和bool型参数添加到模型类中
self.use_book_poster = use_poster
self.use_book_title = use_book_title
self.use_usr_age_job = use_age_job
self.use_book_cat = use_book_cat
self.fc_sizes=fc_sizes
# 获取数据集的信息,并构建训练和验证集的数据迭代器
Dataset = BookLen(self.use_book_poster)
self.Dataset = Dataset
self.trainset = self.Dataset.train_dataset
self.valset = self.Dataset.valid_dataset
self.train_loader = self.Dataset.load_data(dataset=self.trainset, mode='train')
self.valid_loader = self.Dataset.load_data(dataset=self.valset, mode='valid')
usr_embedding_dim=32
gender_embeding_dim=16
age_embedding_dim=16
# job_embedding_dim=16
book_embedding_dim=16
category_embedding_dim=16
title_embedding_dim=32
""" define network layer for embedding usr info """
USR_ID_NUM = Dataset.max_usr_id + 1
# 对用户ID做映射,并紧接着一个Linear层
self.usr_emb = Embedding(num_embeddings=USR_ID_NUM, embedding_dim=usr_embedding_dim, sparse=False)
self.usr_fc = Linear(in_features=usr_embedding_dim, out_features=32)
# 对用户性别信息做映射,并紧接着一个Linear层
USR_GENDER_DICT_SIZE = 2
self.usr_gender_emb = Embedding(num_embeddings=USR_GENDER_DICT_SIZE, embedding_dim=gender_embeding_dim)
self.usr_gender_fc = Linear(in_features=gender_embeding_dim, out_features=16)
# 对用户年龄信息做映射,并紧接着一个Linear层
USR_AGE_DICT_SIZE = Dataset.max_usr_age + 1
self.usr_age_emb = Embedding(num_embeddings=USR_AGE_DICT_SIZE, embedding_dim=age_embedding_dim)
self.usr_age_fc = Linear(in_features=age_embedding_dim, out_features=16)
# # 对用户职业信息做映射,并紧接着一个Linear层
# USR_JOB_DICT_SIZE = Dataset.max_usr_job + 1
# self.usr_job_emb = Embedding(num_embeddings=USR_JOB_DICT_SIZE, embedding_dim=job_embedding_dim)
# self.usr_job_fc = Linear(in_features=job_embedding_dim, out_features=16)
# 新建一个Linear层,用于整合用户数据信息
self.usr_combined = Linear(in_features=64, out_features=200)
""" define network layer for embedding usr info """
# 对书籍ID信息做映射,并紧接着一个Linear层
BOOK_DICT_SIZE = Dataset.max_book_id + 1
self.book_emb = Embedding(num_embeddings=BOOK_DICT_SIZE, embedding_dim=book_embedding_dim)
self.book_fc = Linear(in_features=book_embedding_dim, out_features=32)
# 对书籍类别做映射
CATEGORY_DICT_SIZE = len(Dataset.book_cat) + 1
self.book_cat_emb = Embedding(num_embeddings=CATEGORY_DICT_SIZE, embedding_dim=category_embedding_dim, sparse=False)
self.book_cat_fc = Linear(in_features=category_embedding_dim, out_features=32)
# 对书籍名称做映射
BOOK_TITLE_DICT_SIZE = len(Dataset.book_title) + 1
self.book_title_emb = Embedding(num_embeddings=BOOK_TITLE_DICT_SIZE, embedding_dim=title_embedding_dim, sparse=False)
self.book_title_conv = Conv2D(in_channels=1, out_channels=1, kernel_size=(3, 1), stride=(2,1), padding=0)
self.book_title_conv2 = Conv2D(in_channels=1, out_channels=1, kernel_size=(3, 1), stride=1, padding=0)
# 新建一个Linear层,用于整合书籍特征
self.book_concat_embed = Linear(in_features=96, out_features=200)
user_sizes = [200] + self.fc_sizes
acts = ["relu" for _ in range(len(self.fc_sizes))]
self._user_layers = []
for i in range(len(self.fc_sizes)):
linear = paddle.nn.Linear(
in_features=user_sizes[i],
out_features=user_sizes[i + 1],
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(
std=1.0 / math.sqrt(user_sizes[i]))))
self.add_sublayer('linear_user_%d' % i, linear)
self._user_layers.append(linear)
if acts[i] == 'relu':
act = paddle.nn.ReLU()
self.add_sublayer('user_act_%d' % i, act)
self._user_layers.append(act)
#书籍特征和用户特征使用了不同的全连接层,不共享参数
book_sizes = [200] + self.fc_sizes
acts = ["relu" for _ in range(len(self.fc_sizes))]
self._book_layers = []
for i in range(len(self.fc_sizes)):
linear = paddle.nn.Linear(
in_features=book_sizes[i],
out_features=book_sizes[i + 1],
weight_attr=paddle.ParamAttr(
initializer=paddle.nn.initializer.Normal(
std=1.0 / math.sqrt(book_sizes[i]))))
self.add_sublayer('linear_book_%d' % i, linear)
self._book_layers.append(linear)
if acts[i] == 'relu':
act = paddle.nn.ReLU()
self.add_sublayer('book_act_%d' % i, act)
self._book_layers.append(act)
# 定义计算用户特征的前向运算过程
def get_usr_feat(self, usr_var):
""" get usr features"""
# 获取到用户数据
usr_id, usr_gender, usr_age = usr_var
# 将用户的ID数据经过embedding和Linear计算,得到的特征保存在feats_collect中
feats_collect = []
usr_id = self.usr_emb(usr_id)
usr_id = self.usr_fc(usr_id)
usr_id = F.relu(usr_id)
feats_collect.append(usr_id)
# 计算用户的性别特征,并保存在feats_collect中
usr_gender = self.usr_gender_emb(usr_gender)
usr_gender = self.usr_gender_fc(usr_gender)
usr_gender = F.relu(usr_gender)
feats_collect.append(usr_gender)
# 选择是否使用用户的年龄-职业特征
if self.use_usr_age_job:
# 计算用户的年龄特征,并保存在feats_collect中
usr_age = self.usr_age_emb(usr_age)
usr_age = self.usr_age_fc(usr_age)
usr_age = F.relu(usr_age)
feats_collect.append(usr_age)
# # 计算用户的职业特征,并保存在feats_collect中
# usr_job = self.usr_job_emb(usr_job)
# usr_job = self.usr_job_fc(usr_job)
# usr_job = F.relu(usr_job)
# feats_collect.append(usr_job)
# 将用户的特征级联,并通过Linear层得到最终的用户特征
usr_feat = paddle.concat(feats_collect, axis=1)
user_features = F.tanh(self.usr_combined(usr_feat))
#通过3层全链接层,获得用于计算相似度的用户特征和书籍特征
for n_layer in self._user_layers:
user_features = n_layer(user_features)
return user_features
# 定义书籍特征的前向计算过程
def get_book_feat(self, book_var):
""" get book features"""
# 获得书籍数据
book_id, book_cat, book_title = book_var
feats_collect = []
# 获得batchsize的大小
batch_size = book_id.shape[0]
# 计算书籍ID的特征,并存在feats_collect中
book_id = self.book_emb(book_id)
book_id = self.book_fc(book_id)
book_id = F.relu(book_id)
feats_collect.append(book_id)
# 如果使用书籍的种类数据,计算书籍种类特征的映射
if self.use_book_cat:
# 计算书籍种类的特征映射,对多个种类的特征求和得到最终特征
book_cat = self.book_cat_emb(book_cat)
book_cat = paddle.sum(book_cat, axis=1, keepdim=False)
book_cat = self.book_cat_fc(book_cat)
feats_collect.append(book_cat)
if self.use_book_title:
# 计算书籍名字的特征映射,对特征映射使用卷积计算最终的特征
book_title = self.book_title_emb(book_title)
book_title = F.relu(self.book_title_conv2(F.relu(self.book_title_conv(book_title))))
book_title = paddle.sum(book_title, axis=2, keepdim=False)
book_title = F.relu(book_title)
book_title = paddle.reshape(book_title, [batch_size, -1])
feats_collect.append(book_title)
# 使用一个全连接层,整合所有书籍特征,映射为一个200维的特征向量
book_feat = paddle.concat(feats_collect, axis=1)
book_features = F.tanh(self.book_concat_embed(book_feat))
for n_layer in self._book_layers:
book_features = n_layer(book_features)
return book_features
# 定义个性化推荐算法的前向计算
def forward(self, usr_var, book_var):
# 计算用户特征和书籍特征
user_features = self.get_usr_feat(usr_var)
book_features = self.get_book_feat(book_var)
# 根据计算的特征计算相似度
sim = F.common.cosine_similarity(user_features, book_features).reshape([-1, 1])
#使用余弦相似度算子,计算用户和书籍的相似程度
# sim = F.cosine_similarity(user_features, book_features, axis=1).reshape([-1, 1])
# 将相似度扩大范围到和书籍评分相同数据范围
res = paddle.scale(sim, scale=5)
return user_features, book_features, res
3. 模型训练
def train(model):
# 配置训练参数
lr = 0.001
Epoches = 100
#开启GPU
use_gpu = False
paddle.set_device('gpu:0') if use_gpu else paddle.set_device('cpu')
# 启动训练
model.train()
# 获得数据读取器
data_loader = model.train_loader
# 使用adam优化器,学习率使用0.01
opt = paddle.optimizer.Adam(learning_rate=lr, parameters=model.parameters())
for epoch in range(0, Epoches):
for idx, data in enumerate(data_loader()):
# 获得数据,并转为tensor格式
usr, book, score = data
usr_v = [paddle.to_tensor(var) for var in usr]
book_v = [paddle.to_tensor(var) for var in book]
scores_label = paddle.to_tensor(score)
# 计算出算法的前向计算结果
_, _, scores_predict = model(usr_v, book_v)
# 计算loss
loss = F.square_error_cost(scores_predict, scores_label)
avg_loss = paddle.mean(loss)
if idx % 1000 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, idx, avg_loss.numpy()))
# 损失函数下降,并清除梯度
avg_loss.backward()
opt.step()
opt.clear_grad()
# 每10个epoch 保存一次模型
if epoch % 10 == 0:
paddle.save(model.state_dict(), './checkpoint/epoch'+str(epoch)+'.pdparams')
# 启动训练
fc_sizes=[128, 64, 32]
use_poster, use_book_title, use_book_cat, use_age_job = False, True, True, True
model = Model(use_poster, use_book_title, use_book_cat, use_age_job, fc_sizes)
train(model)
##Total dataset instances: 622
##BookLens dataset information:
usr num: 120
book num: 292
epoch: 0, batch_id: 0, loss is: [4.17028]
epoch: 1, batch_id: 0, loss is: [1.9047146]
epoch: 2, batch_id: 0, loss is: [0.7461074]
epoch: 3, batch_id: 0, loss is: [1.5499896]
epoch: 4, batch_id: 0, loss is: [1.5756546]
epoch: 5, batch_id: 0, loss is: [1.5339775]
epoch: 6, batch_id: 0, loss is: [0.48119536]
epoch: 7, batch_id: 0, loss is: [2.130187]
epoch: 8, batch_id: 0, loss is: [0.7817024]
epoch: 9, batch_id: 0, loss is: [0.46116963]
epoch: 10, batch_id: 0, loss is: [0.83575314]
epoch: 11, batch_id: 0, loss is: [0.21608064]
epoch: 12, batch_id: 0, loss is: [0.3550441]
epoch: 13, batch_id: 0, loss is: [0.18410006]
epoch: 14, batch_id: 0, loss is: [0.32895657]
epoch: 15, batch_id: 0, loss is: [0.22927241]
epoch: 16, batch_id: 0, loss is: [0.17777193]
epoch: 17, batch_id: 0, loss is: [0.42232656]
epoch: 18, batch_id: 0, loss is: [0.26365492]
epoch: 19, batch_id: 0, loss is: [0.11804922]
epoch: 20, batch_id: 0, loss is: [0.15374365]
epoch: 21, batch_id: 0, loss is: [0.07359996]
epoch: 22, batch_id: 0, loss is: [0.15296113]
epoch: 23, batch_id: 0, loss is: [0.07737824]
epoch: 24, batch_id: 0, loss is: [0.08948071]
epoch: 25, batch_id: 0, loss is: [0.0607689]
epoch: 26, batch_id: 0, loss is: [0.1715309]
epoch: 27, batch_id: 0, loss is: [0.1659071]
epoch: 28, batch_id: 0, loss is: [0.08382701]
epoch: 29, batch_id: 0, loss is: [0.03567206]
epoch: 30, batch_id: 0, loss is: [0.13538584]
epoch: 31, batch_id: 0, loss is: [0.06940095]
epoch: 32, batch_id: 0, loss is: [0.09211605]
epoch: 33, batch_id: 0, loss is: [0.07237571]
epoch: 34, batch_id: 0, loss is: [0.02138581]
epoch: 35, batch_id: 0, loss is: [0.02448878]
epoch: 36, batch_id: 0, loss is: [0.12813365]
epoch: 37, batch_id: 0, loss is: [0.15136755]
epoch: 38, batch_id: 0, loss is: [0.0616869]
epoch: 39, batch_id: 0, loss is: [0.06575496]
epoch: 40, batch_id: 0, loss is: [0.07189639]
epoch: 41, batch_id: 0, loss is: [0.04775456]
epoch: 42, batch_id: 0, loss is: [0.01638624]
epoch: 43, batch_id: 0, loss is: [0.03363843]
epoch: 44, batch_id: 0, loss is: [0.02819246]
epoch: 45, batch_id: 0, loss is: [0.02556055]
epoch: 46, batch_id: 0, loss is: [0.0485466]
epoch: 47, batch_id: 0, loss is: [0.14426994]
epoch: 48, batch_id: 0, loss is: [0.00691183]
epoch: 49, batch_id: 0, loss is: [0.07448427]
epoch: 50, batch_id: 0, loss is: [0.06333739]
epoch: 51, batch_id: 0, loss is: [0.05606419]
epoch: 52, batch_id: 0, loss is: [0.02504155]
epoch: 53, batch_id: 0, loss is: [0.06804784]
epoch: 54, batch_id: 0, loss is: [0.06871384]
epoch: 55, batch_id: 0, loss is: [0.07204606]
epoch: 56, batch_id: 0, loss is: [0.0304878]
epoch: 57, batch_id: 0, loss is: [0.0189317]
epoch: 58, batch_id: 0, loss is: [0.03077856]
epoch: 59, batch_id: 0, loss is: [0.07299428]
epoch: 60, batch_id: 0, loss is: [0.05836454]
epoch: 61, batch_id: 0, loss is: [0.06750873]
epoch: 62, batch_id: 0, loss is: [0.06627946]
epoch: 63, batch_id: 0, loss is: [0.02012284]
epoch: 64, batch_id: 0, loss is: [0.04086507]
epoch: 65, batch_id: 0, loss is: [0.01258313]
epoch: 66, batch_id: 0, loss is: [0.02361046]
epoch: 67, batch_id: 0, loss is: [0.02590574]
epoch: 68, batch_id: 0, loss is: [0.05788648]
epoch: 69, batch_id: 0, loss is: [0.13692534]
epoch: 70, batch_id: 0, loss is: [0.04251902]
epoch: 71, batch_id: 0, loss is: [0.02980524]
epoch: 72, batch_id: 0, loss is: [0.03573945]
epoch: 73, batch_id: 0, loss is: [0.04036443]
epoch: 74, batch_id: 0, loss is: [0.02487365]
epoch: 75, batch_id: 0, loss is: [0.16449247]
epoch: 76, batch_id: 0, loss is: [0.01489545]
epoch: 77, batch_id: 0, loss is: [0.03338253]
epoch: 78, batch_id: 0, loss is: [0.03407313]
epoch: 79, batch_id: 0, loss is: [0.02788509]
epoch: 80, batch_id: 0, loss is: [0.01425998]
epoch: 81, batch_id: 0, loss is: [0.05642505]
epoch: 82, batch_id: 0, loss is: [0.0104793]
epoch: 83, batch_id: 0, loss is: [0.01036843]
epoch: 84, batch_id: 0, loss is: [0.0570774]
epoch: 85, batch_id: 0, loss is: [0.0096895]
epoch: 86, batch_id: 0, loss is: [0.02637998]
epoch: 87, batch_id: 0, loss is: [0.01522477]
epoch: 88, batch_id: 0, loss is: [0.03692281]
epoch: 89, batch_id: 0, loss is: [0.04502665]
epoch: 90, batch_id: 0, loss is: [0.0479662]
epoch: 91, batch_id: 0, loss is: [0.08084913]
epoch: 92, batch_id: 0, loss is: [0.01147039]
epoch: 93, batch_id: 0, loss is: [0.02813186]
epoch: 94, batch_id: 0, loss is: [0.03969964]
epoch: 95, batch_id: 0, loss is: [0.01681328]
epoch: 96, batch_id: 0, loss is: [0.03814338]
epoch: 97, batch_id: 0, loss is: [0.03696106]
epoch: 98, batch_id: 0, loss is: [0.03102725]
epoch: 99, batch_id: 0, loss is: [0.02521455]
4. 模型评估
#使用验证集评估
from math import sqrt
def evaluation(model, params_file_path):
model_state_dict = paddle.load(params_file_path)
model.load_dict(model_state_dict)
model.eval()
acc_set = []
avg_loss_set = []
squaredError=[]
for idx, data in enumerate(model.valid_loader()):
usr, book, score_label = data
usr_v = [paddle.to_tensor(var) for var in usr]
book_v = [paddle.to_tensor(var) for var in book]
_, _, scores_predict = model(usr_v, book_v)
pred_scores = scores_predict.numpy()
avg_loss_set.append(np.mean(np.abs(pred_scores - score_label)))
squaredError.extend(np.abs(pred_scores - score_label)**2)
diff = np.abs(pred_scores - score_label)
diff[diff>0.5] = 1
acc = 1 - np.mean(diff)
acc_set.append(acc)
RMSE=sqrt(np.sum(squaredError) / len(squaredError))
return np.mean(acc_set), np.mean(avg_loss_set),RMSE
param_path = "./checkpoint/epoch"
for i in range(10, 100, 10):
acc, mae,RMSE = evaluation(model, param_path+str(i)+'.pdparams')
print("ACC:", acc, "MAE:", mae,'RMSE:',RMSE)
ACC: 0.17182029287020364 MAE: 1.1997116 RMSE: 1.475322158028782
ACC: 0.19211931029955545 MAE: 1.2133589 RMSE: 1.507057456814861
ACC: 0.17072982589403787 MAE: 1.2733771 RMSE: 1.5482858511081008
ACC: 0.16275082031885782 MAE: 1.2313476 RMSE: 1.5054256225173135
ACC: 0.16929025451342264 MAE: 1.2491957 RMSE: 1.5280627237331459
ACC: 0.18736409147580466 MAE: 1.2148415 RMSE: 1.4847097347358071
ACC: 0.21810143192609152 MAE: 1.1934332 RMSE: 1.476677805655484
ACC: 0.20665311813354492 MAE: 1.2063422 RMSE: 1.4829182647727908
ACC: 0.19917185107866922 MAE: 1.2284497 RMSE: 1.5081138718140858
5. 推荐范例
import pickle
# 定义根据用户兴趣推荐电影
def recommend_book_for_usr(usr_id, top_k, pick_num, usr_feat_dir, book_feat_dir, book_info_path):
assert pick_num <= top_k
# 读取电影和用户的特征
usr_feats = pickle.load(open(usr_feat_dir, 'rb'))
book_feats = pickle.load(open(book_feat_dir, 'rb'))
usr_feat = usr_feats[str(usr_id)]
cos_sims = []
# with dygraph.guard():
paddle.disable_static()
# 索引电影特征,计算和输入用户ID的特征的相似度
for idx, key in enumerate(book_feats.keys()):
book_feat = book_feats[key]
usr_feat = paddle.to_tensor(usr_feat)
book_feat = paddle.to_tensor(book_feat)
# 计算余弦相似度
sim = paddle.nn.functional.common.cosine_similarity(usr_feat, book_feat)
cos_sims.append(sim.numpy()[0])
# 对相似度排序
index = np.argsort(cos_sims)[-top_k:]
book_info = {}
# 读取电影文件里的数据,根据电影ID索引到电影信息
with open(book_info_path, 'r') as f:
data = f.readlines()
for item in data:
item = item.strip().split("::")
book_info[str(item[0])] = item
print("当前的用户是:")
print("usr_id:", usr_id)
print("推荐可能喜欢的电影是:")
res = []
# 加入随机选择因素,确保每次推荐的都不一样
while len(res) < pick_num:
val = np.random.choice(len(index), 1)[0]
idx = index[val]
book_id = list(book_feats.keys())[idx]
if book_id not in res:
res.append(book_id)
for id in res:
print("book_id:", id, book_info[str(id)])
book_data_path = "./work/book.dat"
top_k, pick_num = 10, 6
usr_id = 2
recommend_book_for_usr(usr_id, top_k, pick_num, './work/usr_feat.pkl', './work/book_feat.pkl', book_data_path)
当前的用户是:
usr_id: 2
推荐可能喜欢的电影是:
book_id: 160 ['160', '神们自己', '科幻']
book_id: 181 ['181', '红星照耀中国', '历史']
book_id: 184 ['184', '覆雨翻云', '武侠']
book_id: 26 ['26', '铁剑红颜', '武侠']
book_id: 182 ['182', '明日杀机', '科幻']
book_id: 108 ['108', '快乐王子', '王尔德童话']
问题分析
通过对现有市场及产品的细致观察与分析,我们团队的成员总结并发现了诸多问题,以下列举四个主要问题:
1. 市面上的电子产品多半采用LCD作为显示媒介
LCD 的构造是在两片平行的玻璃基板当中放置液晶盒,下基板玻璃上设置TFT(薄膜晶体管),上基板玻璃上设置彩色滤光片,通过TFT上的信号与电压改变来控制液晶分子的转动方向,从而达到控制每个像素点偏振光出射与否而达到显示目的。LCD的特性就决定了其想要显示画面就必须拥有屏幕背光。这就使得在长时间使用这些设备的时候孩子的视力会被严重的损伤。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7J21dShu-1669557832329)(https://ai-studio-static-online.cdn.bcebos.com/8364a8eae91b4af8bfd3390214d486a6698351250e52499bbe0e424a2d81e3f3)]
2. 多媒体设备与书籍相差较大
学龄前儿童尚未形成自己对世界独立的认知。家长希望借助多媒体设备来培养孩子的阅读习惯,但最终很可能事与愿违,不但没有培养起孩子的阅读兴趣,反而加强了孩子对多媒体设备的依赖。
-
多媒体设备在形态上与传统书籍相差较大,长期使用后,儿童易形成这些设备的肌肉记忆,导致其可能无法对传统书籍产生兴趣。
-
多媒体设备的显示效果与繁多的功能更易加重儿童对其的依赖性。尤其随着近年来短视频平台的兴起,越来越多的儿童沉迷其中,往往数个小时无法脱身。久而久之,儿童与书籍之间的距离越来越远,从而难以养成阅读书籍的良好习惯。
3. 现有的儿童教育电子产品存在诸多问题
儿童早期阅读习惯的养成,与其对阅读的兴趣程度有着密不可分的关系。而良好的阅读环境与阅读体验,能极大地刺激儿童对阅读的兴趣。传统书籍虽然更利于儿童专注于阅读,不受多媒体设备中纷繁杂多的软件影响,但长久地注视于书籍的文墨,易造成儿童眼睛的疲劳,更易使儿童产生乏味感,从而渐渐失去对阅读的兴趣。因而,我们不仅应关注儿童的视觉体验,也要注重如听觉等方面的体验。随着时代的进步,越来越多的儿童早教产品涌入市场,而不少产品仍存在诸多问题,我们以早教市场常见的点读机、故事机、投影仪为例。
- 点读机
点读机将儿童的视觉、触觉与听觉结合,使儿童能够多方位感知学习书籍中的内容。而点读机对文字的显示仍依赖于传统书籍,以书籍为媒介,为儿童提供文字知识的学习。这样的学习方式虽然为儿童带来了听觉效果,但在视觉上的呈现效果与传统书籍并无差别,这就导致其仅适用于拥有一定识字阅读基础的儿童,在受众人群上受到了不小的限制。此外,能够适用于某一款点读机的书籍往往是有限的,这与点读机识字效果的实现路径有着莫大的关系。这就导致儿童能从某一款点读机配套的书籍中学到的知识少之又少,想要学习更多的知识,又需要重新更换点读机的款式,这显然是不现实的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PYLZurJD-1669557832329)(https://ai-studio-static-online.cdn.bcebos.com/38571fac86b44ab2aeb5959796bebbd2099ba7d86e484dd99dd7ca2bf50e10b4)]
- 故事机
故事机着手于儿童的听觉体验效果,其受众人群较广,且一般体型较小,便于携带。但其定位往往仅作为一款能够讲故事的产品,缺乏对儿童视觉及触觉等方面的培养,因而不利于儿童阅读兴趣的产生及阅读习惯的养成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aAMHvYWG-1669557832330)(https://ai-studio-static-online.cdn.bcebos.com/c3f9d22b89664306b95a11245c1174e92720b8bd96fe49a6a2efc902211c4dd4)]
- 投影仪
投影仪的体验效果较好,一款好的投影仪能够为儿童带来身历其境的体验。但投影仪体型较大,不宜携带,这就导致其对使用场景要求较高,其往往仅能被安置在一个地方。此外,投影仪的操作过程较为繁琐,无法达到随时随地便捷使用的效果,对于年龄较小的儿童也仅能够在家长的陪护下使用投影仪,从而易导致儿童形成对其使用流程的厌烦。再者,缺乏了触觉方面的体验,不易培养儿童的自主动手能力,亦不利于其良好阅读习惯的形成。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KxeMqdjX-1669557832331)(https://ai-studio-static-online.cdn.bcebos.com/eb2e98cb6fb944d7893ca81bab81a89891f1946a959941b09d93050f1c896555)]
**4. 现有的儿童电子书产品无法根据儿童的个人喜好推荐图
现有的儿童电子书产品中的书籍种类及数量虽然多,但儿童在面临书籍选择的时候,往往要花费大量的时间去挑选出自己感兴趣的书籍。此外,年龄较小的儿童面对当今电子书产品中的书籍还不具备自主选择的能力,因而无法从中获得良好的阅读体验,更无法激起自身的阅读兴趣
创作思路
面对创作时所要解决的种种问题,我们的团队进行了数次讨论,每个人都提出了自己的想法与见解,每个环节我们都采用举手投票的方式进行选择。由于在创作时面临的问题与对应的解决思路较多,这里仅针对于上述四个主要问题进行说明。
1. 对于屏幕显示媒介,我们摒弃了传统的LCD及OLED,选择采用基于电子墨水显示技术的墨水屏
墨水屏是由两片基板组成,上面涂有一种由无数微小透明颗粒组成的电子墨水,颗粒由带正、负电的许多黑色和白色粒子密封于内部液态微胶囊内形成,不同颜色的带电粒子会因施加电场的不同,而朝不同的方向运动,在显示屏表面呈现出黑或白的效果。这样,在墨水屏的表面就可以显示出如同印物的黑白图案和文字,看起来与纸张极为类似,在阳光下没有传统液晶显示的反光现象。同时只有画素颜色变化时(例如从黑转到白)才耗电,关电源后显示屏上画面仍可保留。
得益于墨水屏优良的性能以及显示技术,我们的产品不仅拥有极佳的护眼效果,同时还兼备了功率低、耗电慢、续航好的特点。墨水屏能够尽最大可能还原纸质书籍的体验,更有利于儿童阅读习惯的养成。并且,相较于传统LCD或者OLED屏幕,墨水屏本身并不发光,切实保护了儿童的视力健康。也正是得益于墨水屏本身不需要额外的背光模块,我们产品的单次充电使用时长得到了极大的保证,儿童随时都能够使用我们的产品,感受阅读带来的快乐。
2. 对于产品外形及阅读环境,我们选择采用更贴近于书籍的外形与极简的阅读环境
我们的产品在大小上选择了介于如今市场上多数手机与平板二者的尺寸之间,大小及厚度更接近于传统书籍。
此外,为了避免诸如手机、平板中各式各样软件的干扰,我们在设计时始终坚持不添加多余的功能,尽可能设计出更适于儿童阅读的背景及功能,以“纯净”的阅读环境,为儿童提供更舒心、更便捷的阅读体验。
3. 对于当前市面上存在的儿童早教电子产品的诸多问题,我们选择在保证阅读器体型及便携性的同时,为儿童提供多种感官方面的体验效果
以第2个问题中的创作思路为基础,我们的阅读器体型适中,且便于携带,儿童随时随地都能够进行阅读。此外,墨水屏为儿童提供了护眼的视觉体验,双音响为儿童提供了立体的听觉体验,便捷操作的按键布局也为儿童提供了良好的触觉体验。在简易便捷的阅读环境的支持下,儿童能够更快地投入到阅读的氛围当中,多重感官的体验更潜移默化地培养了儿童的阅读兴趣,锻炼了儿童的自主阅读能力。
4. 对于多数儿童缺乏自主选择能力,保证图书选择的高效性及准确性,我们选择采用如今快速发展的云计算、大数据推荐算法等先进技术
我们的书库计划于未来设立近万本图书,对于儿童读物九大类别:生活认知、人际交往、品德品格、科普百科、生命教育、想象幻想、人文艺术、学习工具、益智游戏进行全方面覆盖,根据儿童对于不同类别书籍的观看时间进行计算,迅速判断出儿童感兴趣的书籍类别,从而为其推荐下一本书籍,更有利于对儿童阅读兴趣的维持,提高锻练其阅读能力的效率。具体云计算及推荐算法的实现路径,可以参考技术方案中的相关介绍。
应用前景
借助于“小书虫”儿童阅读器便携的特点,广大儿童可以在任何适于阅读的环境下打开阅读器进行阅读,如:在教室、图书馆、书桌前等等,避免了携带传统纸质版书籍的种种不便。
“小书虫”儿童阅读器能够多元化培养儿童在视觉、听觉、触觉方面的能力,更有效地激发儿童幼年时期的阅读兴趣,提高儿童的阅读水平,解决了传统纸质书籍单一培养识字阅读能力的问题。
此外,“小书虫”儿童阅读器是一款针对于儿童开发的阅读器,相较于智能手机及平板电脑,其阅读环境更纯净,操作性更简便,免去了众多复杂且不适于儿童使用的功能及软件。在提高儿童阅读效率的同时,在墨水护眼屏的加持下,更能有效保护儿童视力免受传统屏幕光线的侵害。
另一方面,凭借着人工智能推荐算法的核心技术,“小书虫”儿童阅读器更是解决了许多儿童“找书难”的问题——每当儿童阅读完一本书后,系统会根据儿童自身喜好快速推荐其他同类型的书籍,从而更有效地激发儿童的阅读兴趣。
“小书虫”儿童阅读器所具有的种种优点,在未来会有很大的发展空间,并拥有以下的潜在合作对象。
1. 学前教育机构
注重学前幼儿阅读素养养成的教育企业机构,格外注重儿童阅读媒介的选择。越来越多的教育企业机构将电子阅读器引入儿童的阅读过程中,致力于打造一个更生动、更便利、更有趣的阅读环境。而很多时候却面临着儿童阅读器的选择问题。现如今大多阅读器无法在提供多感官阅读训练的同时保护好儿童的视力,更无法针对性地提供个性化阅读建议。因而,学前教育机构将会是将来重要的合作对象。
2. 学校
为响应国家“全民阅读”的号召,很多学校将“阅读课”纳入日常的教学日常当中。然而,大多情况下,学校及教室并不了解儿童的阅读习惯及兴趣,无法有效督促学生投入到阅读的环境中。且由于担心学生分心,不专注于阅读及学习,大多学校禁止学生携带手机进入校园。面临形式单一的传统纸质书籍,许多学生无法集中注意力静心阅读,从而无法真正实现“阅读课”的目的与功效。因此,学校也会是将来的重要合作对象。
总结
通过以上的介绍,相信大家已经对“小书虫”儿童电子阅读器有了详细的了解:“小书虫”是一款针对性地面向学龄前儿童开发的电子阅读器,其基于云上人工智能推荐系统,通过对儿童阅读书籍种类的识别采集,总结出儿童的阅读兴趣及习惯,为儿童提供个性化阅读方案,并在儿童阅读完当前书籍时,自动为儿童推荐其可能感兴趣的书籍,从而持续性培养儿童的阅读能力。此外,本作品将电子纸显示技术与有声画书相结合,可以在培养儿童阅读习惯的同时,保护其视力免受传统LCD或OLED显示屏长时间照射的危害,减轻儿童的阅读负担,更有效地激发儿童阅读兴趣、锻练儿童阅读能力。
在未来,不论是学前教育辅导还是对儿童的阅读兴趣培养,“小书虫”儿童电子阅读器都有着极其广阔的应用前景。我们期待其在不久的将来,其能够面向广大儿童,改变儿童阅读领域的现状,真正让儿童发自内心地喜爱上阅读,领略阅读的无限魅力,更能够为我国儿童的视力健康带来改善。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)