
基于飞桨的敏感信息隐藏与恢复系统
基于飞桨的敏感信息隐藏与恢复系统
一、项目背景
(一) 设计背景及其目的
中国在向现代化不断迈进的步伐,人们的生活水平逐渐提高,并且不再只注重物质层面的东西,公民开始对个人信息隐私有所重视。然而飞速发展的互联网技术和大数据的应用,对公民的隐私安全产生了不小的挑战,越来越多的非法商家,甚至是合法平台,秘密地盗取用户信息,个人隐私并批量低价售卖给不法机构,如诈骗组织等。层出不穷的用户信息泄漏,电信诈骗案例为公民个人隐私带来了巨大隐患。
大数据背景下,个人信息与隐私泄露途径多种多样,主要有三种方式:第一种方式是商家泄犯罪分子通过购买公民的身份证号、家庭住址等露出的个人信息。在当今时代,许多商家都会记录下顾客的基本信息,以此来识别新老客户以及分析客户需求,但是商家对用户信息安全并不重视,很有可能被员工拿去网上交易。例如,淘宝网出现的个人信息泄露事件,不仅让用户的账户被冻结,而且让用户损失了大量金钱。第二种是病毒或是非法软件截取个人信息。手机是最受欢迎的移动设备,而用户在使用手机时很有可能下载一些非法软件或是浏览非法网站,从而沾染手机病毒或是安装非法软件,造成了个人信息安全和隐私安全问题
(二) 市场调研情况
目前市场上暂未出现将文本提取擦除,图片修复,图片的隐藏和恢复三者结合起来的项目系统,我们项目将三者结合,为用户提供了新型的隐私安全加密方法,提高了隐私信息的安全性。
(三) 设计目的及理念
利用图片文本提取和隐藏技术,在包含隐私内容的图片上对图片进行修改,使原本可见的隐私信息变得不可见,并且在允许的情况下可通过特定的解码方式将原图信息复原,提供安全可靠的中介服务,加强隐私安全性。
二、技术方案
(一) 数据集
1.1 数据集
我们所使用的是自己的数据集分为img部分,mask部分和inpaint部分
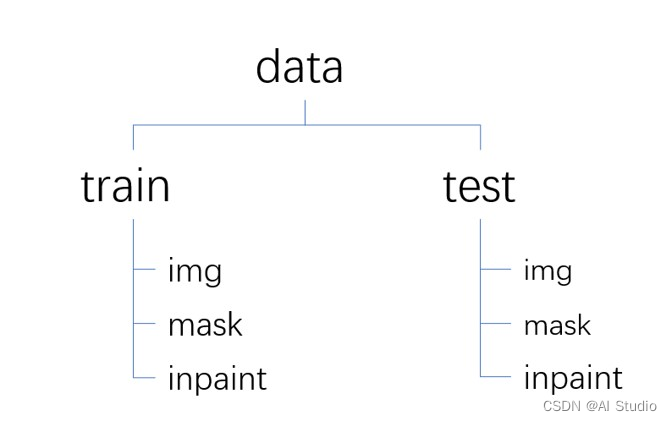
图1 数据集结构
1.2 img
图2 img数据集
1.3 mask

图3 mask数据集
1.4 inpaint

图4 inpaint数据集
(二) 模块详解
基于飞桨深度学习平台,我们设计了一套基于飞桨的敏感信息隐藏与恢复系统,整体框架主要分为3个模块,分别为文本的提取与擦除模块,图像修复模块,图片文本的隐藏和恢复模块。图片中的文字会被识别,然后通过第一个模块生成三张图:被扣除的文字图(text),文字对应二值图(mask),扣除文字后的图片(result)(后面会介绍);然后进入第二个模块,根据mask和result生成修复后的图片(cover);接着会进入到第三个模块将第一个模块中的text隐藏到cover中,通过特定的解码方式会将隐藏的图片拆解,最后还原到原图。
2.1 总体框架
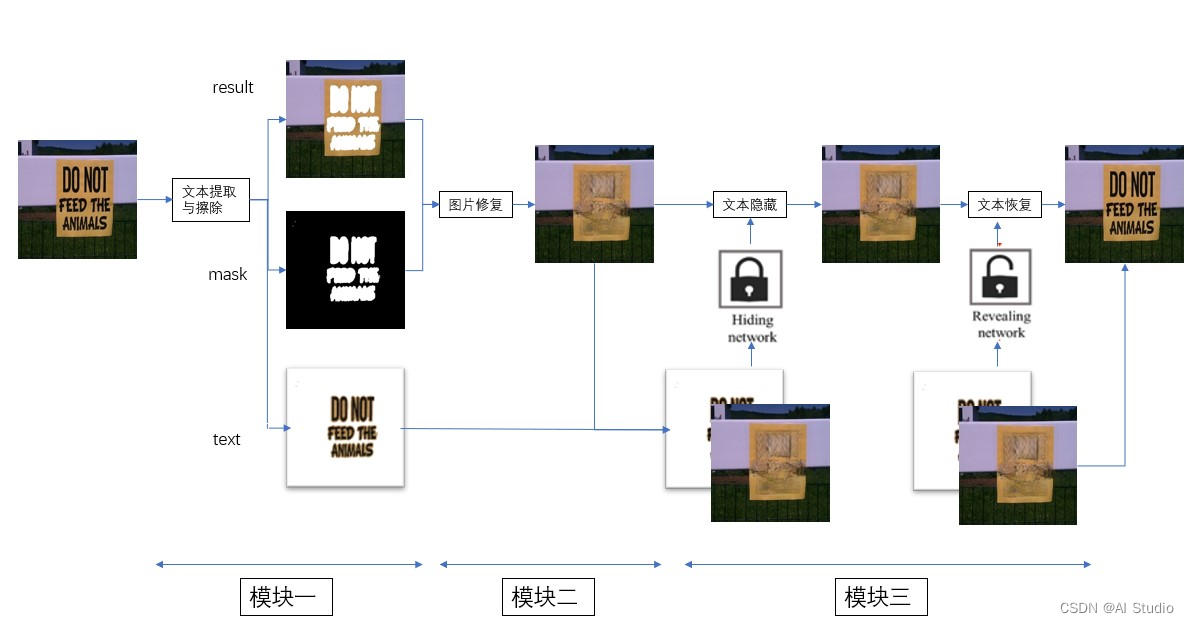
图5 系统总体框图
2.2 模块一 文本提取与擦除
图片的提取和擦除部分是依据paddle的套件进行网络搭建和模型训练,数据集分为image和对应的mask,mask是预先扣好的文字二值图,在迭代多次后得到loss最小的一个模型,然后用该模型进行文本提取。这时将要文字提取的图片放入对应文件夹中,根据程序会自动生成一个预测的pre_mask灰度图,之后将灰度图进行一个阈值处理,pre_mask中大于阈值的数会被设为1,该位置将被识别为文字区域,然后对原图分别进行三种不同的处理,通过比对pre_mask的对应位置的值来生成result(文字提取并删除后的图片),mask(用于第二个模块的掩码),text(用于第三个模块,隐藏于第二个模块生成的修复图中)。
图6 img

图7 result
图8 mask
图9 text
2.3 模块二 图片的修复
对于提取并擦除文本后图片内容的修复,是基于预训练模型进行测试。此神经网络通过从目录读取预训练好的模型,以及从相应文件夹读取上一步文本分割所得到的mask以及被切割掉文字部分的result,分别输入到网络中,完成对图像的修复。在进行测试之前还需要对mask进行膨胀操作,经测试,直接进行图像修复的mask仍会保有原有的形状,只是颜色上发生了改变,本质上并不能算对敏感信息做了保护。膨胀之后,字体的形状模糊不清,修复好的图片效果也不错。前面已经说到,在对图像中的文字进行分割时,得到的分割后图像是文字的二值图和分割后文字部分被挖空的原图像,显然,利用这种被挖空过的带有白色涂鸦的图像作为模板图显然是非常不自然的,所以在进行图像隐藏之前还需要将带有白色涂鸦的图像修复(image inpainting)。
在这里为了完成图像修复的工作,我们选用了MEDFE,即Mutual Encoder-Decoder with Feature Equalizations,带有特征均衡的相互编解码器。
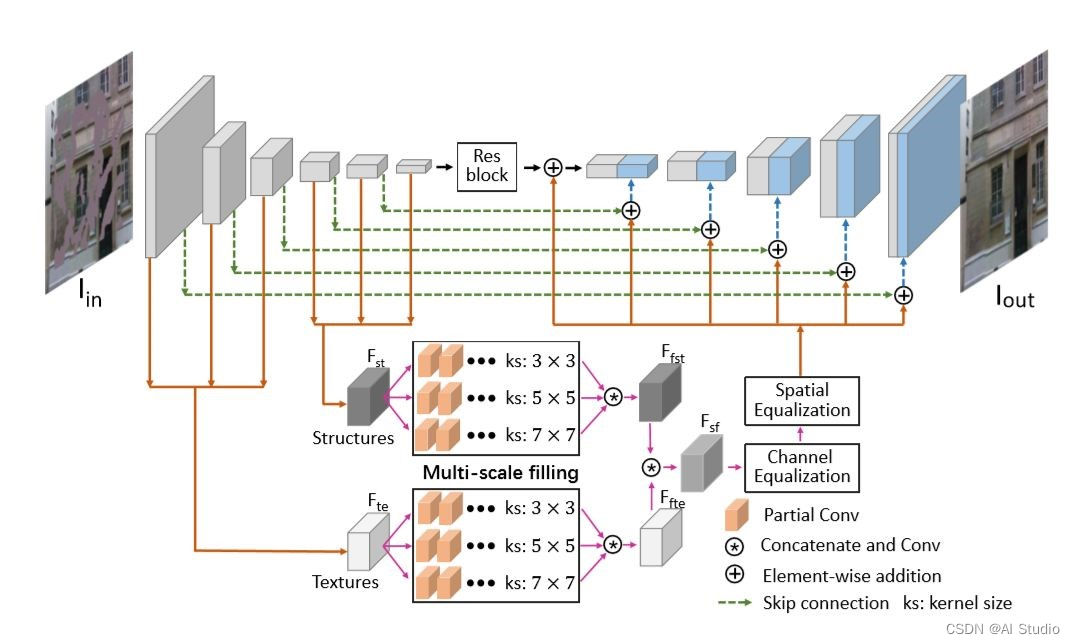
图10 MEDFE
越深的卷积层代表着结构信息(高级语义信息),越浅的卷积层代表纹理以及细节信息(低层级信息)。利用这种概念,将编码器的特征分成两个部分(流),前3层代表纹理信息,后3层代表结构信息,前三层和后三层分别integrate起来变成32×32×256大小的卷积,其中Fte代表前三层的integrated features也就是充满纹理的feature, Fst代表后三层的integrated features也就是充满结构信息的feature。
修复的方法则是将Fst和Fte分别通过多尺度修复模块来修复孔洞区域,修复后就是图中的Ffst以及Ffte。
同时为了保证特征能够关注到纹理或者结构,这里用了非常简单的约束,我们将Ffst以及Ffte用1×1的卷积映射到RGB层(Ffst映射后的图为Iost,Ffte映射后的图为Iote)并于ground truth计算L1 loss,其中Iost的ground truth是结构图(Ist),这张结构图是将原图通过RTV[2]后抹去纹理生成的,而Iost的ground truth就是原图(Igt, 有纹理和细节的图)。
那么通过这种设计,解码器就分出两个流,一个是结构流一个是纹理流,这两个流分别通过多尺度修复模块进行孔洞填充,并且分别有自己的constrain保证孔洞填充效果并且促使每个流关注纹理或者结构。
结构和纹理的feature到此时一直是分开的并且都被填充完了,但是一张图是由结构和纹理一起构成,为了将其融合并且形成一张完整的特征图,需将Ffst以及Ffte拼接并且通过1×1的conv后得到了一个简单融合Fsf, 接着Fsf通过特征均衡化来进行更好的融合,特征均衡化包括两个维度的均衡,一个是channel上的一个是spatial上的,其中channel上的均衡我们通过SE-block实现,因为其中的attention值是由Fsf得到,而Fsf已经包含了结构和纹理的特征信息,所以这些attention是由结构和纹理信息一起得来从而保证了均衡化。在spatial上,对于每个特征点,利用周围的特征点(3×3)以及全局的特征点(32×32)来融合成新的特征点。
2.4 模块三 图片文本的隐藏和恢复
2.4.1 图片文本的隐藏
文本的提取和删除,图片的修复,这些已经被大家广为应用,接下来的文本隐藏和恢复才是我们要着重介绍的地方。并且在删除的同时保留了删除文本图像的副本,那么在接下来文本图像隐藏的工作中就是简单的单张图像隐藏,现在在图像隐藏领域的SOTA模型为DeepMIH,即基于可逆神经网络的多图像隐藏算法。

图11 前向隐藏示意图
DeepMIH由两个子结构组成,分别是基于可逆网络、用于隐藏和恢复的网络结构IHNN和基于注意力机制、获取前级先验信息用于指导下级隐藏的重要性图模块IM。
如上图所示,IHNN的结构可以分为最前端和最后端的DWT/IWT部分和中间的可逆隐藏模块。经过对频域隐藏特性的分析我们知道,将秘密信息隐藏在载体图像的高频部分能够实现更好的效果。这也是我们使用小波变换模块的动机,通过设计损失函数能够让秘密信息更趋向于隐藏在高频部分。此外,我们在溶解实验中也发现在频域上进行图像隐藏能减少参数量,提高整体性能。
整个隐藏的过程就是将载体图像和秘密图像喂入IHNN,此时输入会进入到DWT模块进行小波变换,得到载体图像和秘密图像的小波子带,随后小波子带被喂入可逆隐藏模块中,可逆隐藏模块的输出是Xstego和R,R是在小波域上丢失的信息,再经过IWT模块得到隐藏后的图像和丢失的信息r。
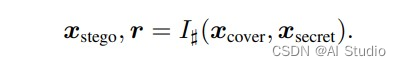
然而,在随后的恢复工作中,丢失信息r是无从可知的,因此一个辅助变量z被引入,来帮助图像的恢复,在恢复工作中的总过程可以表述为
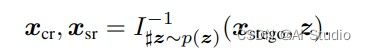
2.4.2 图片文本的恢复
由前面的介绍我们可以知道,我们所使用的DeepMIH在结构上由两个可逆隐藏神经网络组成。我们称它们为IHNN1和IHNN2。在这个神经网络模型中,将文字部分融合到封面图中使得肉眼无法观察到这个功能通过可逆隐藏神经网络前向传播来实现,用于图像恢复功能的是它的后向传播。
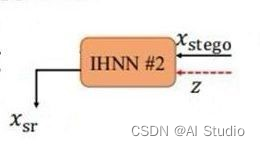
图12 后向恢复示意图
从前面文字部分的隐藏可知,我们提取出文字部分之后通过前向传播文字信息隐藏于封面图片之中。那么很显然,解码我们就需要用它的逆过程,后向传播进行复原。我们需要使用高斯白噪声也就是随机取样得到样本z,将其与隐蔽图片一起向可逆隐藏神经网络进行后向传播。通过这样的方式进行解码。
它的具体实现,是在每个IHNN的内部结构中。包含若干个可逆隐藏模块,以及DWT和IWT模块,负责对数据波段进行处理。经过DWT大小(B,C,H,W)的图片可以变为大小(B,4C,H/2,W/2)的小波段,其中B、C、H、W分别代表大小、高度、宽度、通道数量。这有利于节约计算成本,提高训练效率。同时根据一定 的研究结果表明,高频子带相比于低频子带更适合进行图像隐藏工作,因此使用DWT对输入的图片做一定的变换处理,使得隐藏和恢复工作更有效。
如图在后向传播中,随机的高斯白噪声和我们的隐蔽图像被传入DWT模块进行一系列变换,之后就被传入可逆隐藏模块进行后向传播。对于被传入第M块(假设一个可逆隐藏神经网络只有M个可逆隐藏模块)可逆隐藏模块的经过变换的隐蔽图像和噪声z。都有输出:
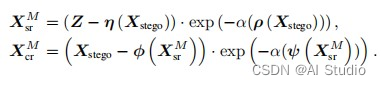
第M块再向前继续做后向传播时,X_srM,X_crM就作为参数传入下一个模块,对于接下来的每一个所要进行后向传播的M-1个可逆隐藏模块,可以得到普遍的数学推导规律:
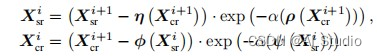
由后向传播整个过程最后得到了X_sr ,X_cr记为:
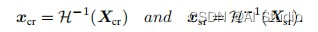
最后因为此时的结果还是低频子带,我们需要让它经过IWT模块就可以把它恢复为原来的图片,得到带有文字部分的图片。在得到了隐藏的文字图片后,我们就可以依照类似第一模块的方法,对照着文字图片将图片修复后的图片恢复为原图的样子。
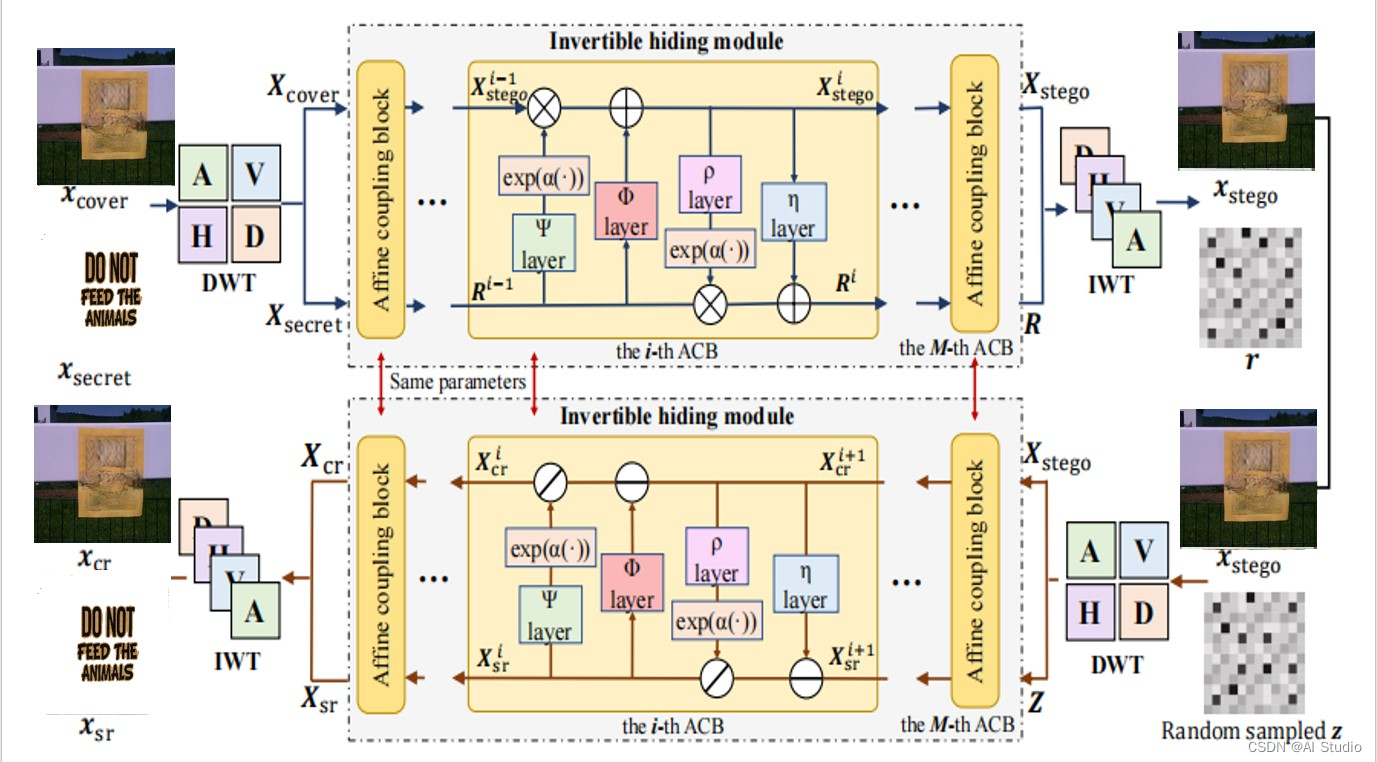
图13 图片的文本隐藏与恢复总结构图
三、核心代码展示
(一) 文字的提取与删除模块
1.1 result,mask,text图片生成部分
import math
import os
import argparse
import numpy as np
import tqdm
import copy
import time
import random
import visdom
import paddle
import paddle.optimizer as optim
from paddle.io import DataLoader
import paddle.nn.functional as F
from dataloader import *
from utils import *
from model import *
from loss import *
def mask_pred(self, Trans, img):
raw_size = img.shape[:-1]
img = Trans(img)[None, ...]
pred_mask = self.net(1 - img)
pred_mask = F.interpolate(pred_mask, size=raw_size, mode='bicubic').cpu().numpy()[0]
return pred_mask.transpose(1, 2, 0)
def generate(self, dataRoot, modelLog):
import cv2
import os
from paddleseg.utils import utils
from paddle.vision.transforms import Compose, ToTensor, Resize
# load model
net = MODEL[self.config.arch](num_classes=1)
utils.load_entire_model(net, modelLog)
self.net = net
# load target file list
with open(os.path.join(dataRoot, 'test.csv'), 'r') as f:
imageFiles = [l.strip('\n') for l in f.readlines()]
os.makedirs(os.path.join(dataRoot, 'pred_mask'), exist_ok=True)
os.makedirs(os.path.join(dataRoot, 'result'), exist_ok=True)
os.makedirs(os.path.join(dataRoot, 'mask'), exist_ok=True)
os.makedirs(os.path.join(dataRoot, 'text'), exist_ok=True)
# start to generate mask
self.net.eval()
with paddle.no_grad():
for imgName in tqdm.tqdm(imageFiles, ncols=80):
img = cv2.imread(imgName)
raw_img = img / 255
raw_size = img.shape[:-1]
img, square_mask = expand2square(img)
crop_size = 1024
if max(img.shape[:2]) > crop_size:
ratio = min(np.log2(min(img.shape[:2]) / crop_size) + 1, 4)
factor = 16
size = int(math.ceil(int(self.config.loadSize * ratio) / factor) * factor)
loadSize = (size, ) * 2
else:
loadSize = (self.config.loadSize, ) * 2
Trans = Compose([
Resize(size=loadSize, interpolation='bicubic'),
ToTensor(), # h * w * c --> c * h * w
])
pred_mask = self.mask_pred(Trans, img)
pred_mask = pred_mask[square_mask].reshape(*raw_size, 1)
np.save(imgName.replace('images', 'pred_mask').replace('jpg', 'npy'), pred_mask)
cred = min(np.mean(pred_mask[pred_mask > 0.01]), 0.25)#阈值处理
pred_mask[pred_mask > cred] = 1
reconImg = raw_img
pred_mask = pred_mask[..., 0]
reconImg1=reconImg * 255
reconImgmask=reconImg * 255
reconImgmask[pred_mask <1 ]=0
reconImgmask[pred_mask == 1] = 255
reconImg1[pred_mask <1 ] = 255
reconImg[pred_mask == 1] = 1
cv2.imwrite(imgName.replace('images', 'mask').replace('jpg', 'jpg'), reconImgmask)#生成文字二值图mask
cv2.imwrite(imgName.replace('images', 'result').replace('jpg', 'jpg'), reconImg*255)#生成扣除文字后图片result
cv2.imwrite(imgName.replace('images', 'text').replace('jpg', 'png'), reconImg1)#生成扣掉的文字图片text
(二) 图片的修复模块
2.1 被扣除的图片修复部分
from options.test_options import TestOptions
from models.models import create_model
import os
import paddle
from PIL import Image
from glob import glob
from tqdm import tqdm
import paddle.vision.transforms as transforms
import cv2
import numpy as np
if __name__ == "__main__":
img_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
mask_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
opt = TestOptions().parse()
model = create_model(opt)
model.netEN.module.load_state_dict(paddle.load("EN.pkl"))
model.netDE.module.load_state_dict(paddle.load("DE.pkl"))
model.netMEDFE.module.load_state_dict(paddle.load("MEDEF.pkl"))
results_dir = r'./result'
if not os.path.exists( results_dir):
os.mkdir(results_dir)
mask_paths = glob('{:s}/*'.format(opt.mask_root))
de_paths = glob('{:s}/*'.format(opt.de_root))
st_path = glob('{:s}/*'.format(opt.st_root))
image_len = len(de_paths )
for i in tqdm(range(image_len)):
# only use one mask for all image
path_m = mask_paths[i]
path_d = de_paths[i]
path_s = de_paths[i]
# mask = Image.open(path_m).convert("RGB")
## a.图像的二值化 ,这里没有做阈值处理
src = cv2.imread(path_m, cv2.IMREAD_UNCHANGED)
## b.设置卷积核5*5
kernel = np.ones((5, 5), np.uint8)
# ## c.图像的腐蚀,默认迭代次数
# erosion = cv2.erode(src, kernel)
## 图像的膨胀
dst = cv2.dilate(src, kernel,iterations=2)
# mask = Image.open(path_m).convert("RGB")
mask=Image.fromarray(dst).convert("RGB")
detail = Image.open(path_d).convert("RGB")
structure = Image.open(path_s).convert("RGB")
mask = mask_transform(mask)
detail = img_transform(detail)
structure = img_transform(structure)
mask = paddle.unsqueeze(mask, 0)
detail = paddle.unsqueeze(detail, 0)
structure = paddle.unsqueeze(structure,0)
with paddle.no_grad():
model.set_input(detail, structure, mask)
model.forward()
fake_out = model.fake_out
fake_out = fake_out.detach().cpu() * mask + detail*(1-mask)
fake_image = (fake_out+1)/2.0
output = fake_image.detach().numpy()[0].transpose((1, 2, 0))*255
output = Image.fromarray(output.astype(np.uint8))
output.save(rf"{opt.results_dir}/{i}.png")
(三) 图片的隐藏和恢复模块
3.1 图片文字的隐藏与解码
import math
import paddle
import paddle.nn
import paddle.optimizer
import numpy as np
from model import *
import config as c
import datasets
import modules.Unet_common as common
import pathlib
import warnings
from PIL import Image
from typing import Union, Optional, List, Tuple, Text, BinaryIO
@paddle.no_grad()
def make_grid(tensor: Union[paddle.Tensor, List[paddle.Tensor]],
nrow: int=8,
padding: int=2,
normalize: bool=False,
value_range: Optional[Tuple[int, int]]=None,
scale_each: bool=False,
pad_value: int=0,
**kwargs) -> paddle.Tensor:
if not (isinstance(tensor, paddle.Tensor) or
(isinstance(tensor, list) and all(
isinstance(t, paddle.Tensor) for t in tensor))):
raise TypeError(
f'tensor or list of tensors expected, got {type(tensor)}')
if "range" in kwargs.keys():
warning = "range will be deprecated, please use value_range instead."
warnings.warn(warning)
value_range = kwargs["range"]
# if list of tensors, convert to a 4D mini-batch Tensor
if isinstance(tensor, list):
tensor = paddle.stack(tensor, axis=0)
if tensor.dim() == 2: # single image H x W
tensor = tensor.unsqueeze(0)
if tensor.dim() == 3: # single image
if tensor.shape[0] == 1: # if single-channel, convert to 3-channel
tensor = paddle.concat((tensor, tensor, tensor), 0)
tensor = tensor.unsqueeze(0)
if tensor.dim() == 4 and tensor.shape[1] == 1: # single-channel images
tensor = paddle.concat((tensor, tensor, tensor), 1)
if normalize is True:
if value_range is not None:
assert isinstance(value_range, tuple), \
"value_range has to be a tuple (min, max) if specified. min and max are numbers"
def norm_ip(img, low, high):
img.clip(min=low, max=high)
img = img - low
img = img / max(high - low, 1e-5)
def norm_range(t, value_range):
if value_range is not None:
norm_ip(t, value_range[0], value_range[1])
else:
norm_ip(t, float(t.min()), float(t.max()))
if scale_each is True:
for t in tensor: # loop over mini-batch dimension
norm_range(t, value_range)
else:
norm_range(tensor, value_range)
if tensor.shape[0] == 1:
return tensor.squeeze(0)
# make the mini-batch of images into a grid
nmaps = tensor.shape[0]
xmaps = min(nrow, nmaps)
ymaps = int(math.ceil(float(nmaps) / xmaps))
height, width = int(tensor.shape[2] + padding), int(tensor.shape[3] +
padding)
num_channels = tensor.shape[1]
grid = paddle.full((num_channels, height * ymaps + padding,
width * xmaps + padding), pad_value)
k = 0
for y in range(ymaps):
for x in range(xmaps):
if k >= nmaps:
break
grid[:, y * height + padding:(y + 1) * height, x * width + padding:(
x + 1) * width] = tensor[k]
k = k + 1
return grid
@paddle.no_grad()
def save_image(tensor: Union[paddle.Tensor, List[paddle.Tensor]],
fp: Union[Text, pathlib.Path, BinaryIO],
format: Optional[str]=None,
**kwargs) -> None:
grid = make_grid(tensor, **kwargs)
ndarr = paddle.clip(grid * 255 + 0.5, 0, 255).transpose(
[1, 2, 0]).cast("uint8").numpy()
im = Image.fromarray(ndarr)
im.save(fp, format=format)
def load(name):
state_dicts = paddle.load(name)
network_state_dict = {k:v for k,v in state_dicts['net'].items() if 'tmp_var' not in k}
net.load_state_dict(network_state_dict)
try:
optim.load_state_dict(state_dicts['opt'])
except:
print('Cannot load optimizer for some reason or other')
def gauss_noise(shape):
noise = paddle.zeros(shape)
for i in range(noise.shape[0]):
noise[i] = paddle.randn(noise[i].shape)
return noise
def computePSNR(origin,pred):
origin = np.array(origin)
origin = origin.astype(np.float32)
pred = np.array(pred)
pred = pred.astype(np.float32)
mse = np.mean((origin/1.0 - pred/1.0) ** 2 )
if mse < 1.0e-10:
return 100
return 10 * math.log10(255.0**2/mse)
if __name__=='__main__':
net = Model()
init_model(net)
net = paddle.DataParallel(net)
params_trainable = (list(filter(lambda p: p.requires_grad, net.parameters())))
optim = paddle.optimizer.Adam(parameters=params_trainable, learning_rate=c.lr, beta1=c.betas, epsilon=1e-6, weight_decay=c.weight_decay)
load(c.MODEL_PATH + c.suffix)
net.eval()
dwt = common.DWT()
iwt = common.IWT()
with paddle.no_grad():
for i, data in enumerate(datasets.testloader):
data = data.to(device)
cover = data[data.shape[0] // 2:, :, :, :]
secret = data[:data.shape[0] // 2, :, :, :]
cover_input = dwt(cover)
secret_input = dwt(secret)
input_img = paddle.concat((cover_input, secret_input), 1)
#################
# forward: #
#################
output = net(input_img)
output_steg = output.narrow(1, 0, 4 * c.channels_in)
output_z = output.narrow(1, 4 * c.channels_in, output.shape[1] - 4 * c.channels_in)
steg_img = iwt(output_steg)
backward_z = gauss_noise(output_z.shape)
#################
# backward: #
#################
output_rev = paddle.concat((output_steg, backward_z), 1)
bacward_img = net(output_rev, rev=True)
secret_rev = bacward_img.narrow(1, 4 * c.channels_in, bacward_img.shape[1] - 4 * c.channels_in)
secret_rev = iwt(secret_rev)
cover_rev = bacward_img.narrow(1, 0, 4 * c.channels_in)
cover_rev = iwt(cover_rev)
resi_cover = (steg_img - cover) * 20
resi_secret = (secret_rev - secret) * 20
save_image(cover, c.IMAGE_PATH_cover + '%.5d.png' % i)
save_image(secret, c.IMAGE_PATH_secret + '%.5d.png' % i)
save_image(steg_img, c.IMAGE_PATH_steg + '%.5d.png' % i)
)
cover_rev = iwt(cover_rev)
resi_cover = (steg_img - cover) * 20
resi_secret = (secret_rev - secret) * 20
save_image(cover, c.IMAGE_PATH_cover + '%.5d.png' % i)
save_image(secret, c.IMAGE_PATH_secret + '%.5d.png' % i)
save_image(steg_img, c.IMAGE_PATH_steg + '%.5d.png' % i)
save_image(secret_rev, c.IMAGE_PATH_secret_rev + '%.5d.png' % i)
3.2 解码文字的恢复
核心思路和第一模块基本一样,只是把pre_mask部分替换成了相应的text文件,image替换成了cover图片,以cover文件作为底,text文件作为内容,将对应text文件部分进行替换。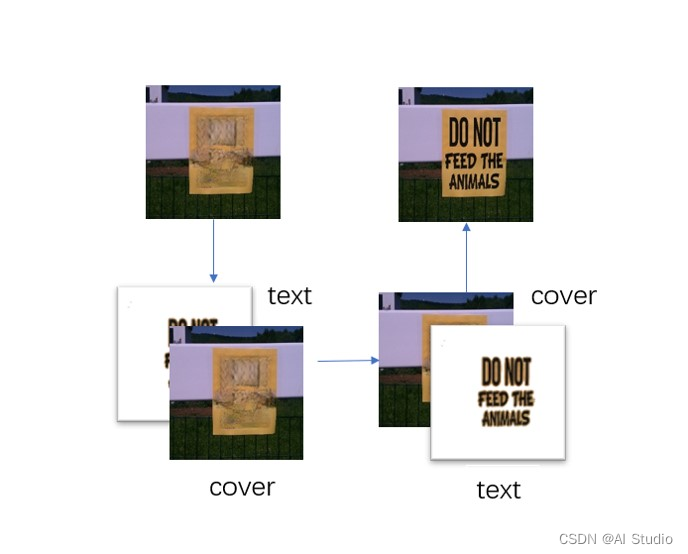
四 应用前景
(一)图片的隐藏和恢复模块
我们在用户上传一些带有敏感信息的图片时将重要信息进行提取并隐藏到原图中,例如在银行卡或者身份证认证的时候,我们时常需要拍照上传app,可这一举动也让人们心生不安,背后信息泄露的风险也是巨大的。但如果采用我们的加密方式,再为认证方提供解码方式,就可以做到在图片的认证过程中,上传方和接收方均为不可见状态,敏感文字只对其中的机器认证所透明,加强了信息安全性。
(二) 军事消息传递
传统的信息传递有很多种,例如电报,电话,网络信息传递等,其中也蕴含这密码学相关的知识。而图片隐藏技术理论上也可做到传递密文信息的作用,例如某个账号在某个公共交流平台发表一张看似很平常的图片,而其中却可隐藏着一些重要的信息,图片只作为载体,重要信息全部被隐藏在图片其中,信息的接受方可用上传方的图片,根据提前规定好的特定解码方式,将隐藏在图片中的信息进行解码,从而获得信息。信息的传递方和接收方也没有直接的联系关系,网上的海量图片也为传递的特殊图片提供了天然的掩护,加强了信息传递的隐秘性。
五 特别鸣谢
资料参考
1.Junpeng Jing, Xin Deng, Mai Xu, Jianyi Wang, Zhenyu Guan. HiNet: Deep Image Hiding by Invertible Network. Published on ICCV 2021. By MC2 Lab @ Beihang University.
2.Hongyu Liu, Bin Jiang, Yibing Song, Wei Huang and Chao Yang. Rethinking Image Inpainting via a Mutual Encoder Decoder with Feature Equalizations .In ECCV 2020 (Oral).
3.Mr.Fisher 试卷手写笔迹擦除 – 百度网盘AI大赛:手写文字擦除第5名方案
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)