
2022-C4-AI-基于飞桨的智慧书桌系统
1.项目背景

2020年,我国儿童青少年总体近视率为52.7%;其中6岁儿童为14.3%,小学生为35.6%,初中生为71.1%,高中生为80.5%,总体近视率较高。
新冠疫情爆发以来,线上网课成为一种常态,随着学生接触电子设备的机会和时间明显增加,给近视防控工作带来了较大的难度。
统计结果显示,目前我国预计超500万中小学生脊柱侧弯。我国中小学生脊柱侧弯发生率为1%-3%,并以每年30万左右的速度递增。
研究表明,近视和脊柱侧弯与学生平常的不良坐姿习惯有很大关系,学生不正确的坐姿是造成近视和脊柱侧弯的主要原因。
基于上述背景,本团队开发了一款智慧书桌系统,该系统利用关键点检测算法判定学生的坐姿是否正确,若坐姿错误,则给予学生灯光和语音提醒,并将坐姿数据保存到云端,以帮助其纠正坐姿。
2.创作思路
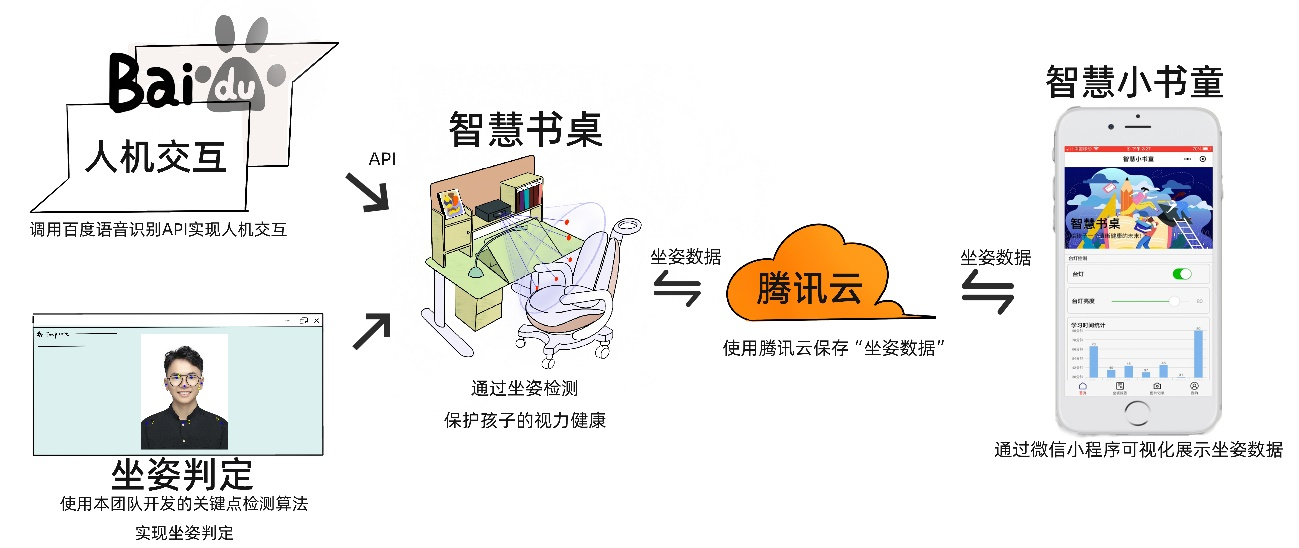
智慧书桌通过本团队开发的坐姿检测算法实现坐姿判定保护孩子的视力和脊柱健康,此外还通过调用百度语音识别API实现对书桌的控制。若孩子坐姿错误,则书桌将会将错误坐姿图片、错误坐姿时间等相关信息上传至腾讯云平台,家长和孩子可以在微信小程序—智慧小书童上查看坐姿报告,家长也可以远程观察孩子学习状态、控制书桌。书桌和家长一同守护孩子的健康成长,给予孩子一个光明的未来!
3.硬件实现
3.1设备介绍
NVIDIA® Jetson Nano™ 开发人员套件是一款面向创客、学习者和开发人员的小型 AI计算机,如图 2 所示。
本团队提出了一种改进的轻量级人体关键点检测模型,并将其部署在 Jetson Nano 板卡上。我们将系统烧入到 U 盘中使用,对于 U 盘启动方式,有以下几点需要注意:
(1)Jetson Nano 的核心板的系统版本和U 盘的系统版本要对应,比如 U 盘已经烧录了V4.5.1版本,那么 Jetson Nano 核心板的系统版本也必须是 V4.5.1,否则无法 USB 启动。
(2)USB 启动的思路是先启动核心板里的系统,再由核心板的系统引导到 U 盘上启动。
(3)核心板里的系统需要使用 SDKManger 来烧录系统, U 盘里的系统需要使用Win32DiskImager 来烧录系统。
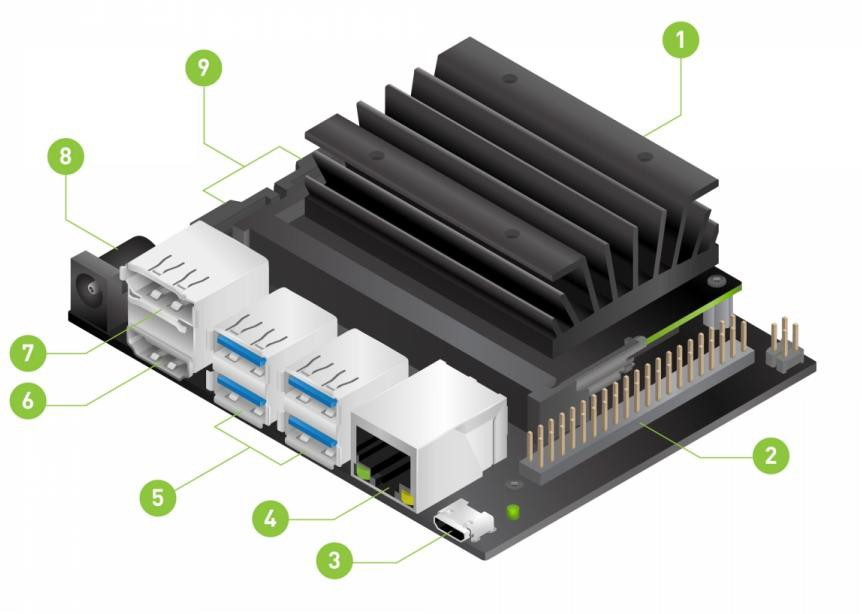
上图标号:
①用于主存储的 microSD 卡插槽
②40 针扩展接头
③用于 5V 电源输入或设备模式的微型 USB 端口 (一般不用此口作为电源输入)
④千兆网口
⑤USB 3.0 端口 (x4)
⑥HDMI 输出端口
⑦显示端口连接器
⑧用于 5V 电源输入的 DC 桶形插孔
⑨MIPI CSI-2 摄像头连接器
实物图片如图3所示

3.2灯控系统的设计与实现
电路组成:1路LED照明调光电路,3路彩色氛围LED灯带控制电路,1路RS485/TTL_UART通信接口。
电路功能:照明LED恒流无级调光、3路RGB灯带PWM无级调光、RS485接收主控板发送来的调光指令。
模块特点:15~24V宽电压输入,调光电路无级、无频闪、高效率、直流可调恒流驱动。
(1)灯控板电路原理/PCB图项目
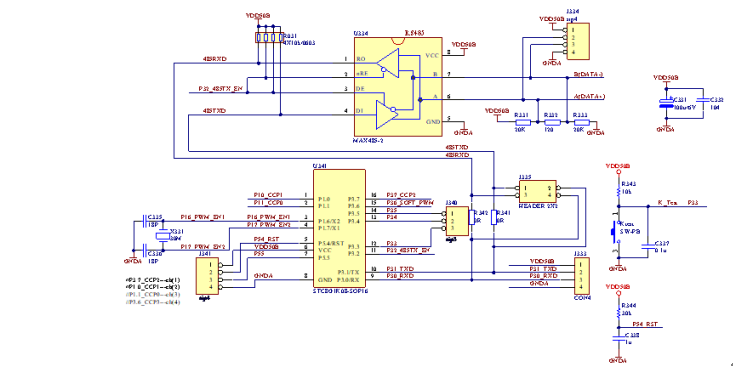
下面是灯控CPU模块电路原理图,如图4所示。
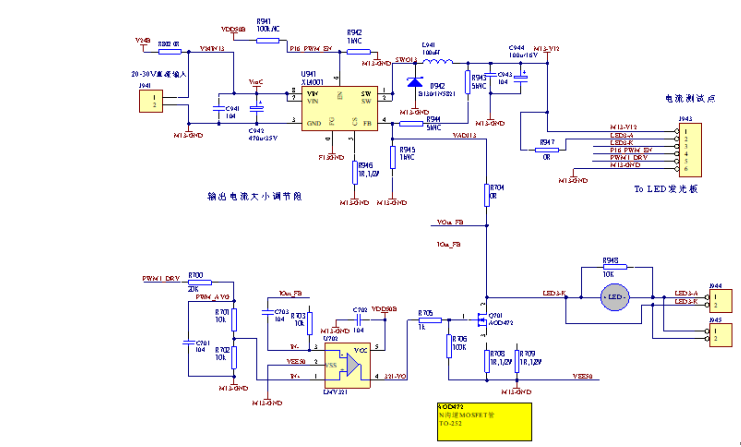
下面是可调恒流主灯控制电路,如图5所示。
下面是灯控板接口引脚图,如图6所示。
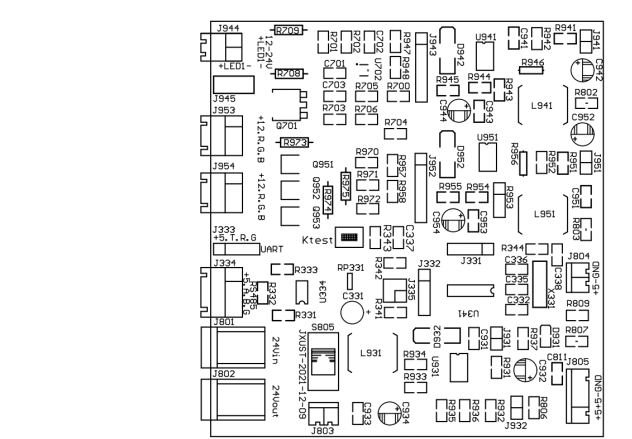
(2)灯控电路板打样结果
下面是灯控板打样实物图,如图7所示。

4.技术方案
本产品通过构建一个人体关键点检测网络架构和损失函数,并通过图像样本反复训练得到人体关键点检测模型,通过该模型对人体关键点进行检测,该产品的开发,有助于预防由于坐姿不良而导致的近视、脊柱侧弯等健康问题。ResNet网络通过残差学习解决了深度网络的退化问题,而深度可分离卷积对小样本的特征提取效果较好,相比普通的卷积操作,其参数量和运算成本比较低。因此本产品的网络结构在ResNet网络的基础上,引入深度可分离卷积网络。
整体网络结构(红色标记为本团队改进地方):


使用通道注意力模块的目的:为了让输入的图像更有意义,大概理解就是,通过网络计算出输入图像各个通道的重要性(权重),也就是哪些通道包含关键信息就多加关注,少关注没什么重要信息的通道,从而达到提高特征表示能力的目的。使用空间注意力的目的:找到关键信息在特征图上哪个位置上最多,是对通道注意力的补充,简单来说,通道注意力是为了找到哪个通道上有重要信息,
而空间注意力则是在这个基础上,基于通道的方向,找到哪一块位置信息聚集的最多。
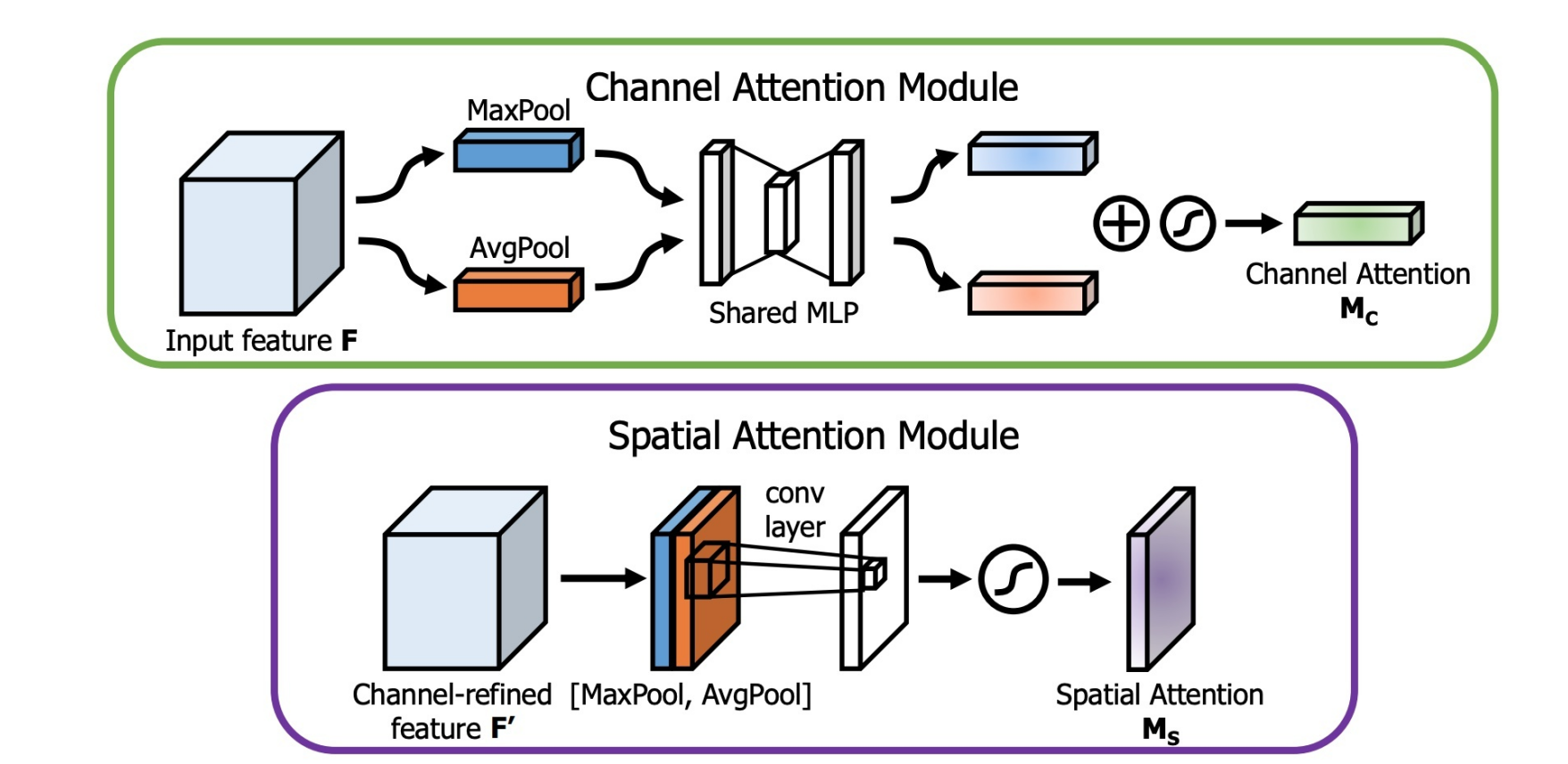
考虑到需要将模型整体进行终端设备的部署,兼顾人体关键点检测整体网络的速度与精确度,在网络结构的最后几层增加了深度可分离卷积模块。在整体网络结构在实际使用时平衡了精度与速度的关系。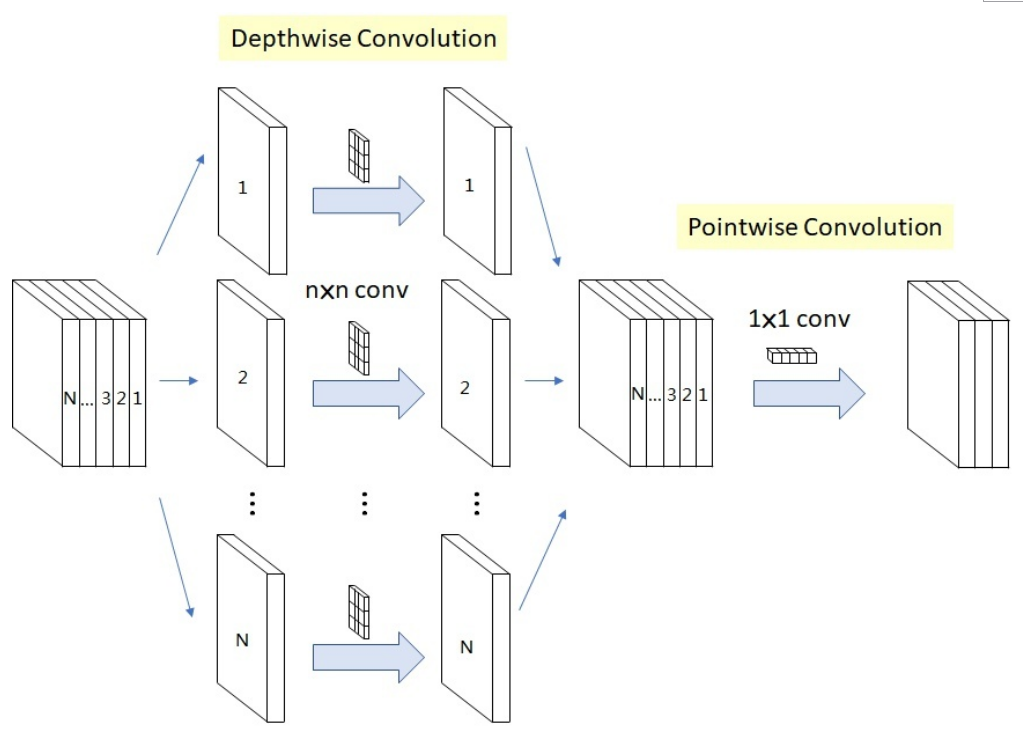
5.数据集
COCO:
目前COCO keypoint track是人体关键点检测的权威公开比赛之一,COCO数据集中把人体关键点表示为17个关节,分别是鼻子,左右眼,左右耳,左右肩,左右肘,左右腕,左右臀,左右膝,左右脚踝。而人体关键点检测的任务就是从输入的图片中检测到人体及对应的关键点位置。
其中数据集中包含的文件路径如下:
`-- coco
`-- annotations
|-- person_keypoints_train2017.json
|-- person_keypoints_val2017.json
`-- images
|-- train2017
|-- val2017
在COCO中,关键点序号与部位的对应关系为:
COCO keypoint indexes:
0: 'nose',
1: 'left_eye',
2: 'right_eye',
3: 'left_ear',
4: 'right_ear',
5: 'left_shoulder',
6: 'right_shoulder',
7: 'left_elbow',
8: 'right_elbow',
9: 'left_wrist',
10: 'right_wrist',
11: 'left_hip',
12: 'right_hip',
13: 'left_knee',
14: 'right_knee',
15: 'left_ankle',
16: 'right_ankle'
与Detection任务不同,KeyPoint任务的标注文件为person_keypoints_train2017.json和person_keypoints_val2017.json两个json文件。json文件中包含的info、licenses和images字段的含义与Detection相同,而annotations和categories则是不同的。
在categories字段中,除了给出类别,还给出了关键点的名称和互相之间的连接性。
在annotations字段中,标注了每一个实例的ID与所在图像,同时还有分割信息和关键点信息。其中与关键点信息较为相关的有:
keypoints:[x1,y1,v1 ...],是一个长度为17*3=51的List,每组表示了一个关键点的坐标与可见性,v=0, x=0, y=0表示该点不可见且未标注,v=1表示该点有标注但不可见,v=2表示该点有标注且可见。bbox:[x1,y1,w,h]表示该实例的检测框位置。num_keypoints: 表示该实例标注关键点的数目。
MPII:
MPII人体姿势数据集是人体姿势预估的一个 benchmark,数据集包括了超过40k人的25000张带标注图片,这些图片是从YouTube video中抽取出来的。MPII 地址: http://human-pose.mpi-inf.mpg.de/#overview。
16类标注: (0 - r ankle, 1 - r knee, 2 - r hip, 3 - l hip, 4 - l knee, 5 - l ankle, 6 - pelvis, 7 - thorax, 8 - upper neck, 9 - head top, 10 - r wrist, 11 - r elbow, 12 - r shoulder, 13 - l shoulder, 14 - l elbow, 15 - l wrist)
其中数据集中包含的文件路径如下:
`-- mpii
`-- annot
|-- gt_valid.mat
|-- test.json
|-- train.mat
|-- trainval.json
|-- valid.mat
`-- images
在MPII中,关键点序号与部位的对应关系为:
MPII keypoint indexes:
0: 'right_ankle',
1: 'right_knee',
2: 'right_hip',
3: 'left_hip',
4: 'left_knee',
5: 'left_ankle',
6: 'pelvis',
7: 'thorax',
8: 'upper_neck',
9: 'head_top',
10: 'right_wrist',
11: 'right_elbow',
12: 'right_shoulder',
13: 'left_shoulder',
14: 'left_elbow',
15: 'left_wrist',
下面以一个解析后的标注信息为例,说明标注的内容,其中每条标注信息标注了一个人物实例:
{
'joints_vis': [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'joints': [
[-1.0, -1.0],
[-1.0, -1.0],
[-1.0, -1.0],
[-1.0, -1.0],
[-1.0, -1.0],
[-1.0, -1.0],
[-1.0, -1.0],
[1232.0, 288.0],
[1236.1271, 311.7755],
[1181.8729, -0.77553],
[692.0, 464.0],
[902.0, 417.0],
[1059.0, 247.0],
[1405.0, 329.0],
[1498.0, 613.0],
[1303.0, 562.0]
],
'image': '077096718.jpg',
'scale': 9.516749,
'center': [1257.0, 297.0]
}
joints_vis:分别表示16个关键点是否标注,若为0,则对应序号的坐标也为[-1.0, -1.0]。joints:分别表示16个关键点的坐标。image:表示对应的图片文件。center:表示人物的大致坐标,用于定位人物在图像中的位置。scale:表示人物的比例,对应200px。
考虑到训练成本和时间,本项目采用MPII数据集进行训练。
5.1数据集下载与解压
在百度深度学习框架中COCO数据集提供了两个数据集
- COCO2017数据集,对应data/data7122
- coco-关键点检测,对应data/data9663
第一个是完整的coco数据集,包含了用于多种任务的完整标注。本示例由于展示需要,第二个数据集仅从coco数据集中抽取出了100张包含人体图像,仅包含人体关键点的标注。
如果需要训练自己的数据集可以参照coco数据集格式,将自己的数据集转化为coco数据集的格式,然后使用COCOPose来读取。
在百度深度学习框架中MPII数据集下载地址:MPII:https://aistudio.baidu.com/aistudio/datasetdetail/107551
数据集解压
%cd /home/aistudio/
!tar -zxvf /home/aistudio/data/data166977/data.zip
!unzip /home/aistudio/data/data166977/data.zip -d /home/aistudio/work/
5.2数据集定义
使用paddle.io.Dataset对数据集进行定义操作,用于后续程序整体的训练使用。
import json
import random
import paddle
import paddle.vision.transforms as T
def data_augmentation(sample, cfg, is_train):
image_file = sample['image']
filename = sample['filename'] if 'filename' in sample else ''
joints = sample['joints_3d']
joints_vis = sample['joints_3d_vis']
c = sample['center']
s = sample['scale']
score = sample['score'] if 'score' in sample else 1
# imgnum = sample['imgnum'] if 'imgnum' in sample else ''
r = 0
data_numpy = cv2.imread(
image_file, cv2.IMREAD_COLOR | cv2.IMREAD_IGNORE_ORIENTATION)
if is_train:
sf = cfg['scale_factor']
rf = cfg['rotation_factor']
s = s * np.clip(np.random.randn()*sf + 1, 1 - sf, 1 + sf)
r = np.clip(np.random.randn()*rf, -rf*2, rf*2) \
if random.random() <= 0.6 else 0
if cfg['flip'] and random.random() <= 0.5:
data_numpy = data_numpy[:, ::-1, :]
joints, joints_vis = fliplr_joints(
joints, joints_vis, data_numpy.shape[1], cfg['flip_pairs'])
c[0] = data_numpy.shape[1] - c[0] - 1
trans = get_affine_transform(c, s, r, cfg['image_size'])
input = cv2.warpAffine(
data_numpy,
trans,
(int(cfg['image_size'][0]), int(cfg['image_size'][1])),
flags=cv2.INTER_LINEAR)
for i in range(cfg['num_joints']):
if joints_vis[i, 0] > 0.0:
joints[i, 0:2] = affine_transform(joints[i, 0:2], trans)
# Numpy target
target, target_weight = generate_target(cfg, joints, joints_vis)
# Normalization
input = input.astype('float32').transpose((2, 0, 1)) / 255
input -= np.array(cfg['mean']).reshape((3, 1, 1))
input /= np.array(cfg['std']).reshape((3, 1, 1))
if is_train:
return input, target, target_weight
else:
return input, target, target_weight, c, s, score
class MpiiDataset(paddle.io.Dataset):
def __init__(self, mode='train'):
self.images_path = "images"
self.annot_path = "annot"
self.num_joints = 16
self.cfgs = {
'num_workers': 1,
'image_path': 'images',
'num_joints': 16,
'flip_pairs': [[0, 5], [1, 4], [2, 3], [10, 15], [11, 14], [12, 13]],
'parent_ids': [1, 2, 6, 6, 3, 4, 6, 6, 7, 8, 11, 12, 7, 7, 13, 14],
'scale_factor': 0.3,
'rotation_factor': 40,
'flip': True,
'target_type': 'gaussian',
'sigma': 3,
'image_size': [384, 384],
'heatmap_size': [96, 96],
'mean': [0.485, 0.456, 0.406],
'std': [0.229, 0.224, 0.225]
}
file_map = {
'train': 'train',
'eval': 'trainval',
'test': 'valid'
}
with open("{}/{}.json".format(self.annot_path, file_map[mode])) as anno_file:
self.annotlist = json.load(anno_file)
print('=> load {} samples of {} dataset'.format(len(self.annotlist), mode))
self.transofrms = T.Compose([
T.Transpose(),
T.RandomRotation(40),
T.Normalize(mean=self.cfgs['mean'], std=self.cfgs['std'])
])
def __getitem__(self, idx):
annot_item = self.annotlist[idx] #取出对应索引的图片标注信息
image_name = annot_item['image'] # 图片文件名称
center = np.array(annot_item['center'], dtype=np.float) # 图像中人的中心点
scale = np.array([annot_item['scale'], annot_item['scale']], dtype=np.float) # 缩放比例
# Adjust center/scale slightly to avoid cropping limbs
if center[0] != -1:
center[1] = center[1] + 15 * scale[1]
scale = scale * 1.25
# MPII uses matlab format, index is based 1,
# we should first convert to 0-based index
center = center - 1
joints_3d = np.zeros((self.cfgs['num_joints'], 3), dtype=np.float)
joints_3d_vis = np.zeros((self.cfgs['num_joints'], 3), dtype=np.float)
joints = np.array(annot_item['joints'])
joints[:, 0:2] = joints[:, 0:2] - 1
joints_vis = np.array(annot_item['joints_vis'])
assert len(joints) == self.cfgs['num_joints'], \
'joint num diff: {} vs {}'.format(len(joints), self.cfgs['num_joints'])
joints_3d[:, 0:2] = joints[:, 0:2]
joints_3d_vis[:, 0] = joints_vis[:]
joints_3d_vis[:, 1] = joints_vis[:]
sample = dict(
image="{}/{}".format(self.images_path, image_name),
center=center,
scale=scale,
joints_3d=joints_3d,
joints_3d_vis=joints_3d_vis,
filename=image_name,
test_mode=False,
imagenum=0)
return data_augmentation(sample, self.cfgs, True)
def __len__(self):
return len(self.annotlist)
6.准备操作
6.1安装依赖
本项目下的代码均在4卡 Tesla p100 GPU, Ubuntu16.04系统,CUDA-11.1, cuDNN-8.1环境下测试运行无误
- Python == 3.7
- PaddlePaddle >= 2.1.0
- COCOAPI
- opencv-python >= 4.6
- scipy
- sys
- matplotlib
6.2安装 COCOAPI
# COCOAPI=/path/to/clone/cocoapi
git clone https://github.com/cocodataset/cocoapi.git $COCOAPI
cd $COCOAPI/PythonAPI
# if cython is not installed
pip install Cython
# Install into global site-packages
!make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python2 setup.py install --user
%cd /home/aistudio/work/cocoapi/PythonAPI
pip install Cython
!make install
7.模型的训练
详细参数配置已保存到lib/mpii_reader.py 和 lib/coco_reader.py文件中,通过设置dataset来选择使用具体的参数配置
训练使用的数据集为MPII数据集,总共具有16个关键点。训练的总的相片数为22246,设置为gpu进行训练代码,每个gpu设置的batch_size设置为128,总共进行训练140轮。在进行训练的过程中采取piecewise_decay的学习率下降的优化算法,并且程序进行每10轮训练进行参数的保存操作。
%cd /home/aistudio/work/
!python train.py --dataset 'mpii'
在训练过程中,每一轮中的一批batch_size进行保存了一批次的热力图生成。下方代码可直观展示一个batch_size中每张图片通过模型后预测得到的热力图。
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('visualization@train.jpg')
plt.rcParams['figure.figsize'] = (20.0, 8.0)
plt.figure('image')
plt.imshow(img)
plt.show()
8.模型的验证
模型的训练过程每10轮会自动保存参数信息。后续可以调用相关语句进行模型的整体验证操作,具体代码如下。
–data 为验证的数据集
–checkpoint为模型训练时自动保存的参数信息,其中下面的参考语句中output/simplebase-mpii/val/中的参数为本项目训练完后得到的参数信息。可改为自行训练的参数信息,默认为每10轮保留一次。
–data_root为验证数据集所在的位置
%cd /home/aistudio/work/output/simplebase-mpii/
!tar -zxvf /home/aistudio/work/output/simplebase-mpii/val.zip
!unzip /home/aistudio/work/output/simplebase-mpii/val.zip -d /home/aistudio/work/output/simplebase-mpii/
%cd /home/aistudio/work/
!python val.py --dataset 'mpii' --checkpoint 'output/simplebase-mpii/val/' --data_root 'data/mpii'
在训练过程中,每一轮中的一批batch_size进行保存了一批次的热力图生成。下方代码可直观展示一个batch_size中每张图片通过模型后预测得到的热力图。
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('visualization@val.jpg')
plt.rcParams['figure.figsize'] = (20.0, 8.0)
plt.figure('image')
plt.imshow(img)
plt.show()
9.模型的推理
对模型进行加载后可以进行模型的推理操作。
–image 为需要进行人体关键点检测操作的推理图像(本项目路径下提供了1.jpg,2.jpg和3.jpg图片)
%cd /home/aistudio/work/
!python test_pose.py --image 1.jpg
/home/aistudio/work
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/setuptools/depends.py:2: DeprecationWarning: the imp module is deprecated in favour of importlib; see the module's documentation for alternative uses
import imp
start processing...
processing time is 10.87645
7645
推理完成以后调用结果图进行显示
from PIL import Image
import matplotlib.pyplot as plt
img = Image.open('result.png')
plt.rcParams['figure.figsize'] = (20.0, 8.0)
plt.figure('image')
plt.imshow(img)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4lxK4WUI-1671080159457)(main_files/main_44_0.png)]
10.实验结果
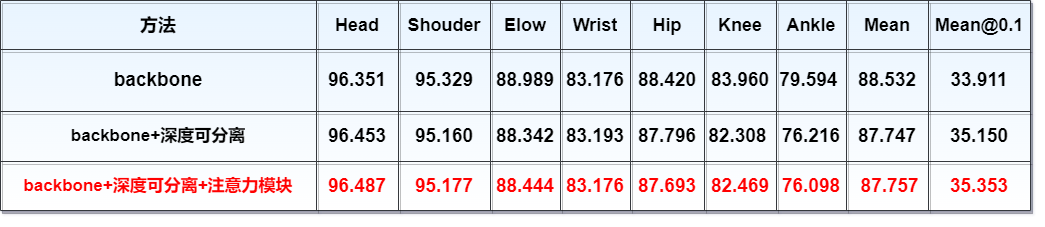
通过实验表明在整体网络结构中加入前文提出注意力模块和深度可分离模块能够到达较高的精确度。(Mean表示计算检测的关键点与其对应的groundtruth间的归一化距离小于设定阈值(0.5)的比例(the percentage of detections that fall within a normalized distance of the ground truth),而Mean @0.1设置的阈值比例为0.1).

实验结果表明本模型与之前先进方法相比,在MPII验证集上本模型的精确度有明显的优势,达到较高的精确度,在实际对人体的坐姿进行识别时有较好的准确度。(比较的精确度为Mean @0.5情况下的精确度)
11.引用
如果您在您的研究中使用我们的代码或模型,请引用:
@inproceedings{xiao2018simple,
author={Xiao, Bin and Wu, Haiping and Wei, Yichen},
title={Simple Baselines for Human Pose Estimation and Tracking},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2018}
}
@article{DBLP:journals/corr/HowardZCKWWAA17,
author = {Andrew G. Howard and
Menglong Zhu and
Bo Chen and
Dmitry Kalenichenko and
Weijun Wang and
Tobias Weyand and
Marco Andreetto and
Hartwig Adam},
title = {MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
Applications},
journal = {CoRR},
volume = {abs/1704.04861},
year = {2017},
eprinttype = {arXiv},
}
@article{DBLP:journals/corr/LinMBHPRDZ14,
author = {Tsung-Yi Lin and
Michael Maire and
Serge J. Belongie and
Lubomir D. Bourdev and
Ross B. Girshick and
James Hays and
Pietro Perona and
Deva Ramanan and
Piotr Dollar and
C. Lawrence Zitnick},
title = {Microsoft {COCO:} Common Objects in Context},
journal = {CoRR},
volume = {abs/1405.0312},
year = {2014},
url = {http://arxiv.org/abs/1405.0312},
eprinttype = {arXiv},
eprint = {1405.0312},
}
@inproceedings{andriluka14cvpr,
author = {Mykhaylo Andriluka and Leonid Pishchulin and Peter Gehler and Schiele, Bernt}
title = {2D Human Pose Estimation: New Benchmark and State of the Art Analysis},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2014},
month = {June}
}
@article{DBLP:journals/corr/abs-1801-04381,
author = {Mark Sandler and
Andrew G. Howard and
Menglong Zhu and
Andrey Zhmoginov and
Liang{-}Chieh Chen},
title = {Inverted Residuals and Linear Bottlenecks: Mobile Networks for Classification,
Detection and Segmentation},
journal = {CoRR},
volume = {abs/1801.04381},
year = {2018},
url = {http://arxiv.org/abs/1801.04381},
eprinttype = {arXiv},
eprint = {1801.04381},
timestamp = {Tue, 12 Jan 2021 15:30:06 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1801-04381.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-1905-02244,
author = {Andrew Howard and
Mark Sandler and
Grace Chu and
Liang{-}Chieh Chen and
Bo Chen and
Mingxing Tan and
Weijun Wang and
Yukun Zhu and
Ruoming Pang and
Vijay Vasudevan and
Quoc V. Le and
Hartwig Adam},
title = {Searching for MobileNetV3},
journal = {CoRR},
volume = {abs/1905.02244},
year = {2019},
url = {http://arxiv.org/abs/1905.02244},
eprinttype = {arXiv},
eprint = {1905.02244},
timestamp = {Thu, 27 May 2021 16:20:51 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1905-02244.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-1807-11164,
author = {Ningning Ma and
Xiangyu Zhang and
Hai{-}Tao Zheng and
Jian Sun},
title = {ShuffleNet {V2:} Practical Guidelines for Efficient {CNN} Architecture
Design},
journal = {CoRR},
volume = {abs/1807.11164},
year = {2018},
url = {http://arxiv.org/abs/1807.11164},
eprinttype = {arXiv},
eprint = {1807.11164},
timestamp = {Tue, 21 Dec 2021 10:11:08 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1807-11164.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-2104-06403,
author = {Changqian Yu and
Bin Xiao and
Changxin Gao and
Lu Yuan and
Lei Zhang and
Nong Sang and
Jingdong Wang},
title = {Lite-HRNet: {A} Lightweight High-Resolution Network},
journal = {CoRR},
volume = {abs/2104.06403},
year = {2021},
url = {https://arxiv.org/abs/2104.06403},
eprinttype = {arXiv},
eprint = {2104.06403},
timestamp = {Tue, 18 Oct 2022 08:35:30 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-06403.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)