
【AI达人特训营第二期】 食物咀嚼声音分类
【AI达人特训营第二期】 食物咀嚼声音分类
项目简介
数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音,任务是给这些声音数据建模,准确分类。作为零基础入门语音识别的新人赛,本次任务不涉及复杂的声音模型、语言模型,希望大家通过两种baseline的学习能体验到语音识别的乐趣。
项目任务
使用paddlespeech,对声音数据建模,搭建一个声音分类网络,进行分类任务,完成一个食物咀嚼语音分类任务。
1.环境依赖安装
# 如果需要进行持久化安装, 需要使用持久化路径, 如下方代码示例:
# If a persistence installation is required,
# you need to use the persistence path as the following:
!mkdir /home/aistudio/external-libraries
!pip install paddlespeech==1.2.0 -t /home/aistudio/external-libraries
!pip install paddleaudio==1.0.1 -t /home/aistudio/external-libraries
!pip install pydub -t /home/aistudio/external-libraries
mkdir: 无法创建目录"/home/aistudio/external-libraries": 文件已存在
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlespeech==1.2.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/64/cd/5a19f23a9be36cc8e3cf3c3791aeb23ae44452d141ec10419e355c319135/paddlespeech-1.2.0-py3-none-any.whl (1.4 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.4/1.4 MB[0m [31m1.5 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hCollecting visualdl
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/8a/e5/940426714a10c916466764eaea51ab7e10bd03896c625fcc4524a0855175/visualdl-2.4.1-py3-none-any.whl (4.9 MB)
[2K [91m━[0m[90m╺[0m[90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m0.1/4.9 MB[0m [31m374.4 kB/s[0m eta [36m0:00:13[0m
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可:
# Also add the following code,
# so that every time the environment (kernel) starts,
# just run the following code:
import sys
sys.path.append('/home/aistudio/external-libraries')
2、数据集准备
数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音
芦荟 炸薯条 肋骨 泡菜 冰淇淋 糖果 水果 汉堡 面条 软糖
甘蓝 炸薯条 胡萝卜 披萨 巧克力 鲑鱼 饮料 翅膀 果冻 汤 葡萄
这里有两个数据集,train_sample和train,train_sample是train的子集,如果不想下载太多文件可以选择train_sample
%cd /home/aistudio/work
# !wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/train_sample.zip
!wget http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/train.zip
/home/aistudio/work
--2022-12-05 20:21:12-- http://tianchi-competition.oss-cn-hangzhou.aliyuncs.com/531887/train.zip
正在解析主机 tianchi-competition.oss-cn-hangzhou.aliyuncs.com (tianchi-competition.oss-cn-hangzhou.aliyuncs.com)... 183.131.227.248
正在连接 tianchi-competition.oss-cn-hangzhou.aliyuncs.com (tianchi-competition.oss-cn-hangzhou.aliyuncs.com)|183.131.227.248|:80... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度: 3793765027 (3.5G) [application/zip]
正在保存至: “train.zip”
train.zip 100%[===================>] 3.53G 1.98MB/s in 25m 6s
2022-12-05 20:46:19 (2.40 MB/s) - 已保存 “train.zip” [3793765027/3793765027])
!mkdir /home/aistudio/dataset
# !unzip -oq /home/aistudio/work/train_sample.zip -d /home/aistudio/dataset
!unzip -oq /home/aistudio/work/train.zip -d /home/aistudio/dataset
mkdir: 无法创建目录"/home/aistudio/dataset": 文件已存在
3、音频加载和特征提取
观察数据集文件夹格式,每一个文件夹分别代表每一类,文件均为 .wav 格式,所以接下来进行音频文件的加载和音频信号特征的提取
3.1 数字音频
3.1.1 加载声音信号和音频文件
加载声音文件(.wav)的方式有很多
下面列举一下
-
librosa
-
PySoundFile
-
ffmpy
-
AudioSegment/pydub
-
paddleaudio
-
音频切分 auditok
本次项目采用paddleaudio库来加载wav文件
from paddleaudio.features import LogMelSpectrogram
from paddleaudio import load
import paddle
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
data, sr = load(file='/home/aistudio/dataset/train/aloe/02ZL4MY497.wav', mono=True, dtype='float32')
print('wav shape: {}'.format(data.shape))
print('sample rate: {}'.format(sr))
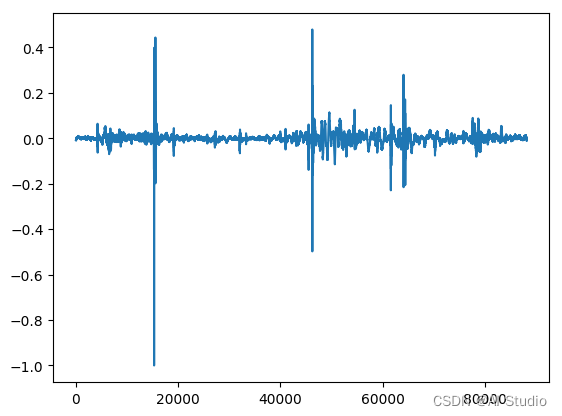
# 展示音频波形
plt.figure()
plt.plot(data)
plt.show()
wav shape: (88211,)
sample rate: 44100
3.2 音频特征提取
接下来介绍一下两种音频特征提取的方法,短时傅里叶变换、LogFBank
3.2.1 短时傅里叶变换
对于一段音频,一般会将整段音频进行分帧,每一帧含有一定长度的信号数据,一般使用 25ms,帧与帧之间的移动距离称为帧移,一般使用 10ms,然后对每一帧的信号数据加窗后,进行离散傅立叶变换(DFT)得到频谱图。
通过按照上面的对一段音频进行分帧后,我们可以用傅里叶变换来分析每一帧信号的频率特性。将每一帧的频率信息拼接后,可以获得该音频不同时刻的频率特征——Spectrogram,也称作为语谱图。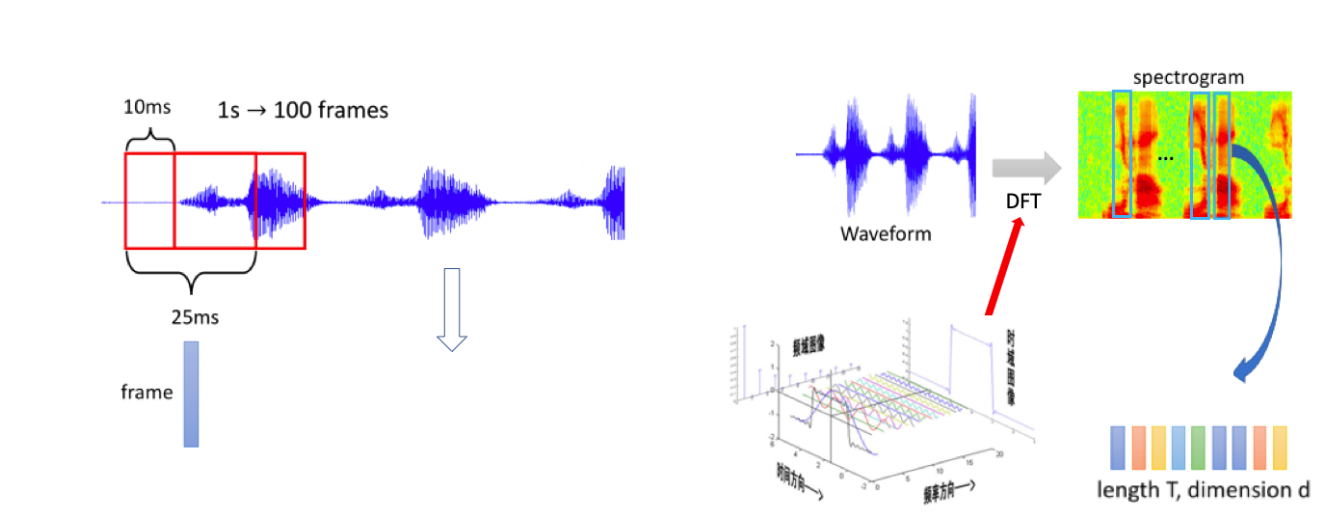
下面例子采用 paddle.signal.stft 演示如何提取示例音频的频谱特征,并进行可视化:
import paddle
import numpy as np
from paddleaudio import load
try:
data, sr = load(file='/home/aistudio/dataset/train/aloe/02ZL4MY497.wav', mono=True, dtype='float32')
except:
print("文件打开失败,检查路径")
x = paddle.to_tensor(data)
n_fft = 1024
win_length = 1024
hop_length = 320
# [D, T]
spectrogram = paddle.signal.stft(x, n_fft=n_fft, win_length=win_length, hop_length=512, onesided=True)
print('spectrogram.shape: {}'.format(spectrogram.shape))
print('spectrogram.dtype: {}'.format(spectrogram.dtype))
spec = np.log(np.abs(spectrogram.numpy())**2)
plt.figure()
plt.title("Log Power Spectrogram")
plt.imshow(spec[:100, :], origin='lower')
plt.show()
spectrogram.shape: [513, 1723]
spectrogram.dtype: paddle.complex64

3.2.2 LogFBank
研究表明,人类对声音的感知是非线性的,随着声音频率的增加,人对更高频率的声音的区分度会不断下降。
例如同样是相差 500Hz 的频率,一般人可以轻松分辨出声音中 500Hz 和 1,000Hz 之间的差异,但是很难分辨出 10,000Hz 和 10,500Hz 之间的差异。
因此,学者提出了梅尔频率,在该频率计量方式下,人耳对相同数值的频率变化的感知程度是一样的。
关于梅尔频率的计算,其会对原始频率的低频的部分进行较多的采样,从而对应更多的频率,而对高频的声音进行较少的采样,从而对应较少的频率。使得人耳对梅尔频率的低频和高频的区分性一致。
Mel Fbank 的计算过程如下,而我们一般都是使用 LogFBank 作为识别特征:
下面例子采用 paddleaudio.features.LogMelSpectrogram 演示如何提取示例音频的 LogFBank:
注:n_mels: 梅尔刻度数量和生成向量的第一维度相同
from paddleaudio.features import LogMelSpectrogram
from paddleaudio import load
import paddle
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
data, sr = load(file='/home/aistudio/dataset/train/aloe/02ZL4MY497.wav', mono=True, dtype='float32')
n_fft = 1024
f_min=50.0
f_max=14000.0
win_length = 1024
hop_length = 320
# - sr: 音频文件的采样率。
# - n_fft: FFT样本点个数。
# - hop_length: 音频帧之间的间隔。
# - win_length: 窗函数的长度。
# - window: 窗函数种类。
# - n_mels: 梅尔刻度数量。
feature_extractor = LogMelSpectrogram(
sr=sr,
n_fft=n_fft,
hop_length=hop_length,
win_length=win_length,
window='hann',
f_min=f_min,
f_max=f_max,
n_mels=64)
x = paddle.to_tensor(data).unsqueeze(0) # [B, L]
log_fbank = feature_extractor(x) # [B, D, T]
log_fbank = log_fbank.squeeze(0) # [D, T]
print('log_fbank.shape: {}'.format(log_fbank.shape))
plt.figure()
plt.imshow(log_fbank.numpy(), origin='lower')
plt.show()
log_fbank.shape: [64, 2757]

3.3、声音分类方法
3.3.1 传统机器学习
在传统的声音和信号的研究领域中,声音特征是一类包含丰富先验知识的手工特征,如频谱图、梅尔频谱和梅尔频率倒谱系数等。
因此在一些分类的应用上,可以采用传统的机器学习方法例如决策树、svm和随机森林等方法。
3.3.2 深度学习方法
传统机器学习方法可以捕捉声音特征的差异(例如男声和女声的声音在音高上往往差异较大)并实现分类任务。
而深度学习方法则可以突破特征的限制,更灵活的组网方式和更深的网络层次,可以更好地提取声音的高层特征,从而获得更好的分类指标。
通过特征提取,获取到语谱图,也可以通过一些图像分类网络来进行一个分类,也可以用一些流行的声音分类模型,如:AudioCLIP、PANNs、Audio Spectrogram Transformer等
4、实践:食物咀嚼分类
4.1 数据集处理
数据集来自Eating Sound Collection,数据集中包含20种不同食物的咀嚼声音,原数据集过大,本次采用train_sample数据集,其中20类分别为
4.1.1 数据集归一化
首先对数据集进行统计
# 统计音频
# 查音频长度
import contextlib
import wave
def get_sound_len(file_path):
with contextlib.closing(wave.open(file_path, 'r')) as f:
frames = f.getnframes()
rate = f.getframerate()
wav_length = frames / float(rate)
return wav_length
# 编译wav文件
import glob
sound_files=glob.glob('/home/aistudio/dataset/train/*/*.wav')
# print(sound_files[0])
print(len(sound_files))
# 统计最长、最短音频
sounds_len=[]
for sound in sound_files:
sounds_len.append(get_sound_len(sound))
print("音频最大长度:",max(sounds_len),"秒")
print("音频最小长度:",min(sounds_len),"秒")
7000
音频最大长度: 21.999931972789117 秒
音频最小长度: 0.9958049886621315 秒
# 定义函数,如未达到最大长度,则重复填充,最终从超过20s的音频中截取
from pydub import AudioSegment
from tqdm import tqdm
def convert_sound_len(filename):
audio = AudioSegment.from_wav(filename)
i = 1
padded = audio*i
while padded.duration_seconds * 1000 < 20000:
i = i + 1
padded = audio * i
# 采样率设置为16KHz
# print(audio.duration_seconds)
padded[0:20000].set_frame_rate(44100).export(filename, format='wav')
# 统一所有音频到定长
for sound in tqdm(sound_files):
convert_sound_len(sound)
100%|██████████| 7000/7000 [09:02<00:00, 12.91it/s]
4.1.2 数据集切分
观察对应的数据集文件夹分布,每一类放在同一个文件夹中,在图像分类中经常有类似的脚本,稍加修改即可
接下来运行脚本
%cd /home/aistudio/dataset
!python /home/aistudio/dataset_precess.py
/home/aistudio/dataset
生成txt文件
4.1.3 自定义数据读取
import cv2
import paddle
import numpy as np
import os
from paddle.io import Dataset
from paddle.vision.transforms import transforms as T
import io
from paddleaudio import load
import paddleaudio
# step1: 定义MyDataset类, 继承Dataset, 重写抽象方法:__len()__, __getitem()__
class MyDataset(Dataset):
def __init__(self, root_dir, names_file):
self.root_dir = root_dir
self.names_file = names_file
self.size = 0
self.names_list = []
self.min_size=[]
if not os.path.isfile(self.names_file):
print(self.names_file + 'does not exist!')
file = open(self.names_file)
for f in file:
self.names_list.append(f)
self.size += 1
def __len__(self):
return self.size
def __getitem__(self, idx):
image_path = self.names_list[idx].split(' ')[0]
# print(image_path)
if not os.path.isfile(image_path):
print(image_path + ' does not exist!')
return None
wav_file, sr = load(file=image_path, mono=True, dtype='float32') # 单通道,float32音频样本点
label = int(self.names_list[idx].split(' ')[1])
return wav_file, label
4.2 模型
4.2.1模型组网
在数据经过音频特征提取后,得到了语谱图,可以转化为一个图像分类问题,用卷积神经网络去搭建模型,本次采用图像分类网络中经典的ResNet18网络
import paddle
import paddle.nn as nn
class Identity(nn.Layer):
def __init__(self):
super().__init__()
def forward(self,x):
return x
class Block(nn.Layer):
def __init__(self, in_dim, out_dim, stride):
super().__init__()
self.conv1 = nn.Conv2D(in_dim, out_dim, 3, stride=stride, padding=1, bias_attr=False)
self.bn1 = nn.BatchNorm2D(out_dim)
self.conv2 = nn.Conv2D(out_dim, out_dim, 3, stride=1, padding=1, bias_attr=False)
self.bn2 = nn.BatchNorm2D(out_dim)
self.relu = nn.ReLU()
if stride == 2 or in_dim != out_dim:
self.downsample = nn.Sequential(*[
nn.Conv2D(in_dim, out_dim, 1, stride=stride),
nn.BatchNorm2D(out_dim)])
else:
self.downsample = Identity()
def forward(self, x):
h = x
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
identity = self.downsample(h)
x = x + identity
x = self.relu(x)
return x
class ResNet(nn.Layer):
def __init__(self, in_dim=64, num_classes=10):
super().__init__()
self.in_dim = in_dim
# stem layers
self.conv1 = nn.Conv2D(in_channels=1,
out_channels=in_dim,
kernel_size=3,
stride=1,
padding=1,
bias_attr=False)
self.bn1 = nn.BatchNorm2D(in_dim)
self.relu = nn.ReLU()
# blocks
self.layers1 = self._make_layer(dim=64, n_blocks=2, stride=1)
self.layers2 = self._make_layer(dim=128, n_blocks=2, stride=2)
self.layers3 = self._make_layer(dim=256, n_blocks=2, stride=2)
self.layers4 = self._make_layer(dim=512, n_blocks=2, stride=2)
# head layer
self.avgpool = nn.AdaptiveAvgPool2D(1) # 根据实际调整大小,变成我们想要的尺寸
self.classifier = nn.Linear(512, num_classes)
def _make_layer(self, dim, n_blocks, stride):
layer_list = []
layer_list.append(Block(self.in_dim, dim, stride=stride))
self.in_dim = dim
for i in range(1, n_blocks):
layer_list.append(Block(self.in_dim, dim, stride=1))
return nn.Sequential(*layer_list)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.layers1(x)
x = self.layers2(x)
x = self.layers3(x)
x = self.layers4(x)
x = self.avgpool(x)
x = x.flatten(1)
x = self.classifier(x)
return x
4.2.1 模型输入输出验证
model = ResNet(num_classes=20)
t = paddle.randn([4, 1, 64, 2757])
out = model(t)
print(out.shape)
[4, 20]
4.3 训练流程
4.3.1 读取数据集
创建data_loader,选取训练集和测试集
audio_class_train= MyDataset(root_dir='/home/aistudio/dataset/train',
names_file='/home/aistudio/dataset/train_list.txt',
)
audio_class_test= MyDataset(root_dir='/home/aistudio/dataset/train',
names_file='/home/aistudio/dataset/val_list.txt',
)
batch_size = 16
train_loader = paddle.io.DataLoader(audio_class_train, batch_size=batch_size, shuffle=True)
dev_loader = paddle.io.DataLoader(audio_class_test, batch_size=batch_size)
for batch_idx, batch in enumerate(train_loader):
waveforms, labels = batch
print(waveforms.shape)
break
[16, 882000]
4.3.2 定义优化器和损失函数
# 优化器和损失函数
model = ResNet(num_classes=20)
optimizer = paddle.optimizer.Adam(learning_rate=1e-4, parameters=model.parameters())
criterion = paddle.nn.loss.CrossEntropyLoss()
# paddle.save(model.state_dict(), 'SoundClassifier.pdparams')
4.3.3 开始训练
采用paddle基础API进行训练
print("开始")
from paddleaudio.utils import logger
epochs = 10
steps_per_epoch = len(train_loader)
log_freq = 100
eval_freq = 5
for epoch in range(1, epochs + 1):
model.train()
avg_loss = 0
num_corrects = 0
num_samples = 0
for batch_idx, batch in enumerate(train_loader):
waveforms, labels = batch
feats = feature_extractor(waveforms)
feats = paddle.transpose(feats, [0, 2, 1]) # [B, N, T] -> [B, T, N]
feats = feats.unsqueeze(1)
# print("shape:",feats.shape)
logits = model(feats)
loss = criterion(logits, labels)
loss.backward()
optimizer.step()
if isinstance(optimizer._learning_rate,
paddle.optimizer.lr.LRScheduler):
optimizer._learning_rate.step()
optimizer.clear_grad()
# Calculate loss
avg_loss += loss.numpy()[0]
# Calculate metrics
preds = paddle.argmax(logits, axis=1)
num_corrects += (preds == labels).numpy().sum()
num_samples += feats.shape[0]
if (batch_idx + 1) % log_freq == 0:
lr = optimizer.get_lr()
avg_loss /= log_freq
avg_acc = num_corrects / num_samples
print_msg = 'Epoch={}/{}, Step={}/{}'.format(
epoch, epochs, batch_idx + 1, steps_per_epoch)
print_msg += ' loss={:.4f}'.format(avg_loss)
print_msg += ' acc={:.4f}'.format(avg_acc)
print_msg += ' lr={:.6f}'.format(lr)
logger.train(print_msg)
avg_loss = 0
num_corrects = 0
num_samples = 0
if epoch % eval_freq == 0 and batch_idx + 1 == steps_per_epoch:
model.eval()
num_corrects = 0
num_samples = 0
# with logger.processing('Evaluation on validation dataset'):
for batch_idx, batch in enumerate(dev_loader):
waveforms, labels = batch
feats = feature_extractor(waveforms)
feats = paddle.transpose(feats, [0, 2, 1])
feats = feats.unsqueeze(1) ### 增加维度
logits = model(feats)
preds = paddle.argmax(logits, axis=1)
num_corrects += (preds == labels).numpy().sum()
num_samples += feats.shape[0]
print_msg = '[Evaluation result]'
print_msg += ' dev_acc={:.4f}'.format(num_corrects / num_samples)
logger.eval(print_msg)
开始
[2022-12-08 13:53:08,322] [ TRAIN] - Epoch=1/10, Step=100/744 loss=2.5150 acc=0.2525 lr=0.000100
[2022-12-08 13:54:17,397] [ TRAIN] - Epoch=1/10, Step=200/744 loss=1.8733 acc=0.4175 lr=0.000100
[2022-12-08 13:55:26,534] [ TRAIN] - Epoch=1/10, Step=300/744 loss=1.5217 acc=0.5256 lr=0.000100
[2022-12-08 13:56:35,503] [ TRAIN] - Epoch=1/10, Step=400/744 loss=1.2880 acc=0.5950 lr=0.000100
[2022-12-08 13:57:44,547] [ TRAIN] - Epoch=1/10, Step=500/744 loss=1.1276 acc=0.6512 lr=0.000100
[2022-12-08 13:58:53,678] [ TRAIN] - Epoch=1/10, Step=600/744 loss=1.0354 acc=0.6769 lr=0.000100
[2022-12-08 14:00:02,900] [ TRAIN] - Epoch=1/10, Step=700/744 loss=0.8890 acc=0.7256 lr=0.000100
[2022-12-08 14:01:42,197] [ TRAIN] - Epoch=2/10, Step=100/744 loss=0.7407 acc=0.7775 lr=0.000100
[2022-12-08 14:02:51,425] [ TRAIN] - Epoch=2/10, Step=200/744 loss=0.6178 acc=0.8275 lr=0.000100
[2022-12-08 14:04:00,645] [ TRAIN] - Epoch=2/10, Step=300/744 loss=0.5716 acc=0.8300 lr=0.000100
[2022-12-08 14:05:09,904] [ TRAIN] - Epoch=2/10, Step=400/744 loss=0.5241 acc=0.8581 lr=0.000100
[2022-12-08 14:06:19,097] [ TRAIN] - Epoch=2/10, Step=500/744 loss=0.4832 acc=0.8531 lr=0.000100
[2022-12-08 14:07:28,240] [ TRAIN] - Epoch=2/10, Step=600/744 loss=0.4426 acc=0.8762 lr=0.000100
[2022-12-08 14:08:37,389] [ TRAIN] - Epoch=2/10, Step=700/744 loss=0.3798 acc=0.8944 lr=0.000100
[2022-12-08 14:10:16,544] [ TRAIN] - Epoch=3/10, Step=100/744 loss=0.3229 acc=0.9175 lr=0.000100
[2022-12-08 14:11:25,665] [ TRAIN] - Epoch=3/10, Step=200/744 loss=0.2881 acc=0.9263 lr=0.000100
[2022-12-08 14:12:34,770] [ TRAIN] - Epoch=3/10, Step=300/744 loss=0.2998 acc=0.9213 lr=0.000100
[2022-12-08 14:13:43,923] [ TRAIN] - Epoch=3/10, Step=400/744 loss=0.2659 acc=0.9225 lr=0.000100
[2022-12-08 14:14:53,028] [ TRAIN] - Epoch=3/10, Step=500/744 loss=0.2408 acc=0.9369 lr=0.000100
[2022-12-08 14:16:02,094] [ TRAIN] - Epoch=3/10, Step=600/744 loss=0.2305 acc=0.9375 lr=0.000100
[2022-12-08 14:17:11,226] [ TRAIN] - Epoch=3/10, Step=700/744 loss=0.2488 acc=0.9319 lr=0.000100
[2022-12-08 14:18:50,412] [ TRAIN] - Epoch=4/10, Step=100/744 loss=0.1439 acc=0.9750 lr=0.000100
[2022-12-08 14:19:59,543] [ TRAIN] - Epoch=4/10, Step=200/744 loss=0.1571 acc=0.9619 lr=0.000100
[2022-12-08 14:21:08,687] [ TRAIN] - Epoch=4/10, Step=300/744 loss=0.1813 acc=0.9519 lr=0.000100
[2022-12-08 14:22:17,873] [ TRAIN] - Epoch=4/10, Step=400/744 loss=0.1454 acc=0.9669 lr=0.000100
[2022-12-08 14:23:27,004] [ TRAIN] - Epoch=4/10, Step=500/744 loss=0.1627 acc=0.9606 lr=0.000100
[2022-12-08 14:24:36,172] [ TRAIN] - Epoch=4/10, Step=600/744 loss=0.1724 acc=0.9575 lr=0.000100
[2022-12-08 14:25:45,287] [ TRAIN] - Epoch=4/10, Step=700/744 loss=0.1434 acc=0.9625 lr=0.000100
[2022-12-08 14:27:24,561] [ TRAIN] - Epoch=5/10, Step=100/744 loss=0.1112 acc=0.9738 lr=0.000100
[2022-12-08 14:28:33,792] [ TRAIN] - Epoch=5/10, Step=200/744 loss=0.1083 acc=0.9781 lr=0.000100
[2022-12-08 14:29:43,087] [ TRAIN] - Epoch=5/10, Step=300/744 loss=0.0815 acc=0.9875 lr=0.000100
[2022-12-08 14:30:52,357] [ TRAIN] - Epoch=5/10, Step=400/744 loss=0.1077 acc=0.9744 lr=0.000100
[2022-12-08 14:32:01,714] [ TRAIN] - Epoch=5/10, Step=500/744 loss=0.1280 acc=0.9637 lr=0.000100
[2022-12-08 14:33:10,957] [ TRAIN] - Epoch=5/10, Step=600/744 loss=0.1057 acc=0.9756 lr=0.000100
[2022-12-08 14:34:20,212] [ TRAIN] - Epoch=5/10, Step=700/744 loss=0.1128 acc=0.9700 lr=0.000100
[2022-12-08 14:35:06,447] [ EVAL] - [Evaluation result] dev_acc=0.9627
[2022-12-08 14:36:15,882] [ TRAIN] - Epoch=6/10, Step=100/744 loss=0.1248 acc=0.9613 lr=0.000100
[2022-12-08 14:37:25,147] [ TRAIN] - Epoch=6/10, Step=200/744 loss=0.0884 acc=0.9806 lr=0.000100
[2022-12-08 14:38:34,440] [ TRAIN] - Epoch=6/10, Step=300/744 loss=0.0957 acc=0.9769 lr=0.000100
[2022-12-08 14:39:43,802] [ TRAIN] - Epoch=6/10, Step=400/744 loss=0.0842 acc=0.9775 lr=0.000100
[2022-12-08 14:40:52,895] [ TRAIN] - Epoch=6/10, Step=500/744 loss=0.0773 acc=0.9800 lr=0.000100
[2022-12-08 14:42:01,980] [ TRAIN] - Epoch=6/10, Step=600/744 loss=0.0554 acc=0.9906 lr=0.000100
[2022-12-08 14:43:11,140] [ TRAIN] - Epoch=6/10, Step=700/744 loss=0.0555 acc=0.9888 lr=0.000100
[2022-12-08 14:44:50,365] [ TRAIN] - Epoch=7/10, Step=100/744 loss=0.0608 acc=0.9862 lr=0.000100
[2022-12-08 14:45:59,506] [ TRAIN] - Epoch=7/10, Step=200/744 loss=0.0427 acc=0.9944 lr=0.000100
[2022-12-08 14:47:08,659] [ TRAIN] - Epoch=7/10, Step=300/744 loss=0.0568 acc=0.9900 lr=0.000100
[2022-12-08 14:48:17,843] [ TRAIN] - Epoch=7/10, Step=400/744 loss=0.0382 acc=0.9956 lr=0.000100
[2022-12-08 14:49:27,038] [ TRAIN] - Epoch=7/10, Step=500/744 loss=0.0800 acc=0.9769 lr=0.000100
[2022-12-08 14:50:36,182] [ TRAIN] - Epoch=7/10, Step=600/744 loss=0.0839 acc=0.9812 lr=0.000100
[2022-12-08 14:51:45,285] [ TRAIN] - Epoch=7/10, Step=700/744 loss=0.0469 acc=0.9919 lr=0.000100
[2022-12-08 14:53:24,476] [ TRAIN] - Epoch=8/10, Step=100/744 loss=0.0523 acc=0.9875 lr=0.000100
[2022-12-08 14:54:33,710] [ TRAIN] - Epoch=8/10, Step=200/744 loss=0.0494 acc=0.9912 lr=0.000100
[2022-12-08 14:55:42,836] [ TRAIN] - Epoch=8/10, Step=300/744 loss=0.0486 acc=0.9888 lr=0.000100
[2022-12-08 14:56:51,975] [ TRAIN] - Epoch=8/10, Step=400/744 loss=0.0495 acc=0.9888 lr=0.000100
[2022-12-08 14:58:01,163] [ TRAIN] - Epoch=8/10, Step=500/744 loss=0.0810 acc=0.9775 lr=0.000100
[2022-12-08 14:59:10,437] [ TRAIN] - Epoch=8/10, Step=600/744 loss=0.0587 acc=0.9881 lr=0.000100
[2022-12-08 15:00:19,718] [ TRAIN] - Epoch=8/10, Step=700/744 loss=0.0547 acc=0.9906 lr=0.000100
[2022-12-08 15:01:59,032] [ TRAIN] - Epoch=9/10, Step=100/744 loss=0.0636 acc=0.9900 lr=0.000100
[2022-12-08 15:03:08,270] [ TRAIN] - Epoch=9/10, Step=200/744 loss=0.0682 acc=0.9838 lr=0.000100
[2022-12-08 15:04:17,453] [ TRAIN] - Epoch=9/10, Step=300/744 loss=0.0493 acc=0.9881 lr=0.000100
[2022-12-08 15:05:26,689] [ TRAIN] - Epoch=9/10, Step=400/744 loss=0.0679 acc=0.9850 lr=0.000100
[2022-12-08 15:06:36,137] [ TRAIN] - Epoch=9/10, Step=500/744 loss=0.0600 acc=0.9856 lr=0.000100
[2022-12-08 15:07:45,319] [ TRAIN] - Epoch=9/10, Step=600/744 loss=0.0368 acc=0.9944 lr=0.000100
[2022-12-08 15:08:54,457] [ TRAIN] - Epoch=9/10, Step=700/744 loss=0.0321 acc=0.9950 lr=0.000100
[2022-12-08 15:10:33,710] [ TRAIN] - Epoch=10/10, Step=100/744 loss=0.0341 acc=0.9912 lr=0.000100
[2022-12-08 15:11:42,811] [ TRAIN] - Epoch=10/10, Step=200/744 loss=0.0323 acc=0.9950 lr=0.000100
[2022-12-08 15:12:51,967] [ TRAIN] - Epoch=10/10, Step=300/744 loss=0.0337 acc=0.9938 lr=0.000100
[2022-12-08 15:14:01,112] [ TRAIN] - Epoch=10/10, Step=400/744 loss=0.0874 acc=0.9756 lr=0.000100
[2022-12-08 15:15:10,270] [ TRAIN] - Epoch=10/10, Step=500/744 loss=0.0856 acc=0.9744 lr=0.000100
[2022-12-08 15:16:19,459] [ TRAIN] - Epoch=10/10, Step=600/744 loss=0.0622 acc=0.9869 lr=0.000100
[2022-12-08 15:17:28,661] [ TRAIN] - Epoch=10/10, Step=700/744 loss=0.0285 acc=0.9950 lr=0.000100
[2022-12-08 15:18:15,100] [ EVAL] - [Evaluation result] dev_acc=0.9899
### 保存模型
# 保存Layer参数
paddle.save(model.state_dict, "model.pdparams")
4.4 评估模型
通过10轮训练,在测试集的准确率达到了 acc=0.9899
from paddleaudio.utils import logger
import tqdm
model.state_dict = paddle.load("/home/aistudio/SoundClassifier.pdparams")
model.eval()
num_corrects = 0
num_samples = 0
for batch_idx, batch in enumerate(dev_loader):
waveforms, labels = batch
feats = feature_extractor(waveforms)
feats = paddle.transpose(feats, [0, 2, 1])
feats = feats.unsqueeze(1) ### 增加维度
logits = model(feats)
preds = paddle.argmax(logits, axis=1)
num_corrects += (preds == labels).numpy().sum()
num_samples += feats.shape[0]
print_msg = '[Evaluation result]'
print_msg += ' dev_acc={:.4f}'.format(num_corrects / num_samples)
print(print_msg)
[Evaluation result] dev_acc=0.9899
4.5 推理预测
保存模型后可以进行一个推理预测
label_list = []
with open("dataset/labels.txt","r") as f:
lines = f.read()
# print(lines)
label_list= lines.split("\n")
top_k = 20
wav_file = 'dataset/train/candied_fruits/26879YMW5G.wav'
model.state_dict = paddle.load("SoundClassifier.pdparams")
model.eval()
waveform, sr = load(wav_file)
# feature_extractor = LogMelSpectrogram(
# sr=sr,
# n_fft=n_fft,
# hop_length=hop_length,
# win_length=win_length,
# window='hann',
# f_min=f_min,
# f_max=f_max,
# n_mels=64)
feats = feature_extractor(paddle.to_tensor(paddle.to_tensor(waveform).unsqueeze(0)))
feats = paddle.transpose(feats, [0, 2, 1]) # [B, N, T] -> [B, T, N]
feats = feats.unsqueeze(1)
logits = model(feats)
probs = nn.functional.softmax(logits, axis=1).numpy()
sorted_indices = probs[0].argsort()
# print(label_list)
print("result:",label_list[sorted_indices[-1]])
result: candied_fruits
sort()
print(label_list)
print(“result:”,label_list[sorted_indices[-1]])
result: candied_fruits
# 5、作者简介
江西理工大学飞桨领航团团长 大四在读 智能科学与技术专业
熟悉图像分类算法、目标检测算法和图像分割算法,最近在研究扩散模型,对AI有着浓厚的兴趣
欢迎各位大佬来和我一起交流、一起进步
请点击[此处](https://ai.baidu.com/docs#/AIStudio_Project_Notebook/a38e5576)查看本环境基本用法. <br>
Please click [here ](https://ai.baidu.com/docs#/AIStudio_Project_Notebook/a38e5576) for more detailed instructions.
此文章为搬运
[原项目链接].(https://aistudio.baidu.com/aistudio/projectdetail/5297933)

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)