
基于Bert的微博舆论分析Web系统
基于Bert的微博舆情分析Web系统
效果演示(gif演示)
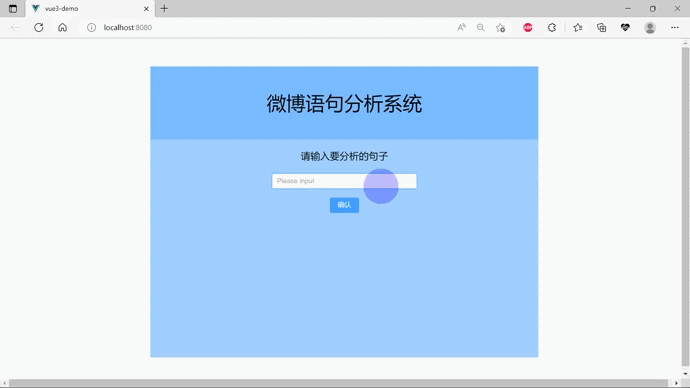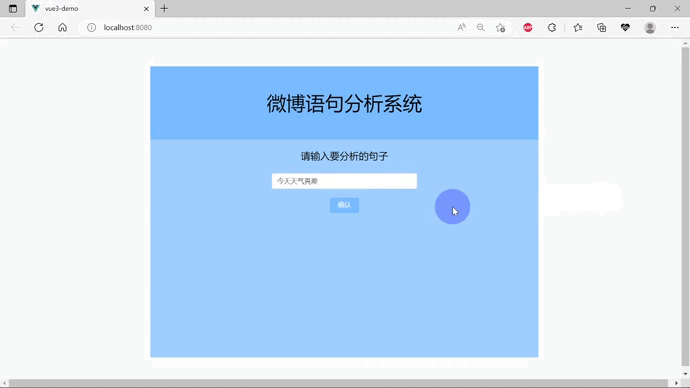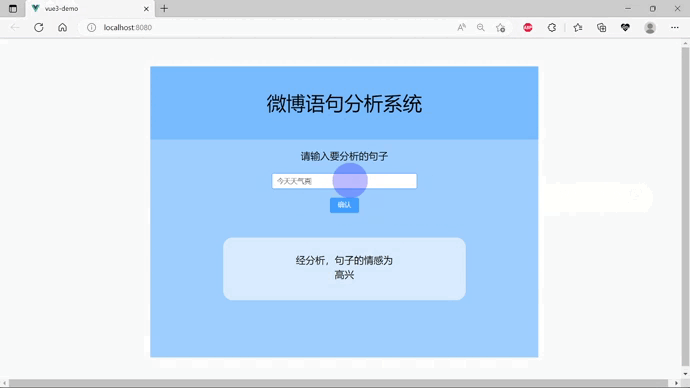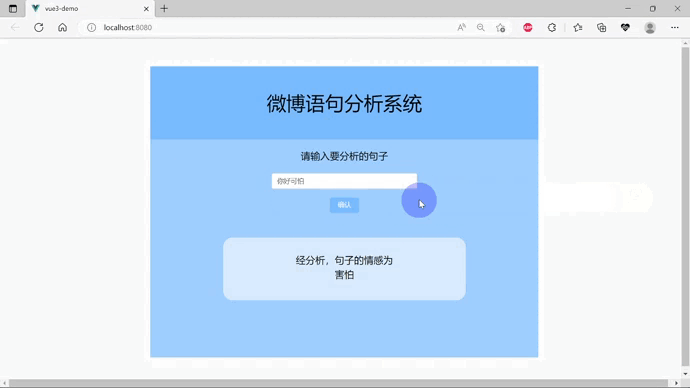
一.项目介绍
1.1 项目简介
本次项目是基于Bert模型搭建一个能够对于微博的言论进行情感分析的一个Web系统,这样人们就能够快速的通过社交媒体来判断一件事情的舆情的情况,看看人们对于一件事情的看法是好是坏,这样的系统也能够用于社会学的分析之中
1.2 项目方案
首先,对于句子的情感分析分类问题,我们采用Bert模型来对语句进行情感的分类。对于Web系统的搭建,我们打算采用使用网络API接口的方式来传递后端的数据,使用vue+element-plus来搭建前端的界面
二.基于PaddleNLP搭建情感6分类模型
2.1 导入所需要的PaddleNLP依赖
import paddle
import paddle.nn as nn
import paddlenlp
from paddlenlp.transformers import BertPretrainedModel,BertTokenizer,BertForSequenceClassification
from sklearn.metrics import f1_score, accuracy_score
from paddle.io import Dataset,DataLoader
from paddle.optimizer import AdamW
from paddlenlp.trainer import Trainer, TrainingArguments
paddle.device.set_device('gpu:0')
Place(gpu:0)
print(paddle.__version__)
print(paddlenlp.__version__)
2.4.0
2.4.2
2.2 导入所需的数据集
这里我们已经先把数据集加入到了home文件下alstudio目录下的work路径里,我们显示一下这里的路径里都有哪些文件
!ls /home/aistudio/work
PATH="/home/aistudio/work/"
best_model1 usual_test_labeled.csv virus_test_labeled.csv
output usual_train.csv virus_train.csv
usual_eval_labeled.csv virus_eval_labeled.csv
2.3 对数据进行读取和分析
这里是对数据进行读取,我们使用pandas库,读取三份数据,分别为训练集,验证集和测试集
import pandas as pd
train_data=pd.read_csv(PATH+"usual_train.csv")
eval_data=pd.read_csv(PATH+"usual_eval_labeled.csv")
test_data=pd.read_csv(PATH+"usual_test_labeled.csv")
首先我们来看一下数据集长什么样子,这里我们以训练集为例。
train_data.head(10)
| 数据编号 | 文本 | 情绪标签 | |
|---|---|---|---|
| 0 | 1 | 气死姐姐了,快二是阵亡了吗,尼玛,一个半小时过去了也没上车 | angry |
| 1 | 2 | 妞妞啊,今天又承办了一个发文登记文号是126~嘻~么么哒~晚安哟 | happy |
| 2 | 3 | 这里还值得注意另一个事实,就是张鞠存原有一个东溪草堂为其读书处。 | neutral |
| 3 | 4 | 这在前华约国家(尤其是东德)使用R-73的首次联合演习期间,被一些北约组织的飞行员所证实。 | neutral |
| 4 | 5 | TinyThief上wii了?! | surprise |
| 5 | 6 | 每天都以紧张的心情工作,真的是太累,太不放松了,想要爆发一下 | angry |
| 6 | 7 | 语文军,数学军,英语军,物理军,政治军,历史军,生物军,地理军,八科联军,侵犯我班,我班战败... | angry |
| 7 | 8 | 我不是一个优秀的演员……不能微笑着旁观你们幸福。 | sad |
| 8 | 9 | 当你变优秀时,你想要的都会来找你 | happy |
| 9 | 10 | 累了一天!会宿舍听下我搞基新歌!在看看我段宜恩美图!心都被治愈了 | happy |
然后我们分析一下数据的规模以及各种情绪的分布
先看一下数据的规模,还是以训练集为例
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27768 entries, 0 to 27767
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 数据编号 27768 non-null int64
1 文本 27766 non-null object
2 情绪标签 27768 non-null object
dtypes: int64(1), object(2)
memory usage: 650.9+ KB
这里我们可以看出,训练集里共有27768条信息,数据规模属于中等规模
然后我们来看一下各种情绪的分布,并将其可视化
%matplotlib inline
train_data["情绪标签"].value_counts().plot(kind='bar')
<matplotlib.axes._subplots.AxesSubplot at 0x7f6c612eafd0>
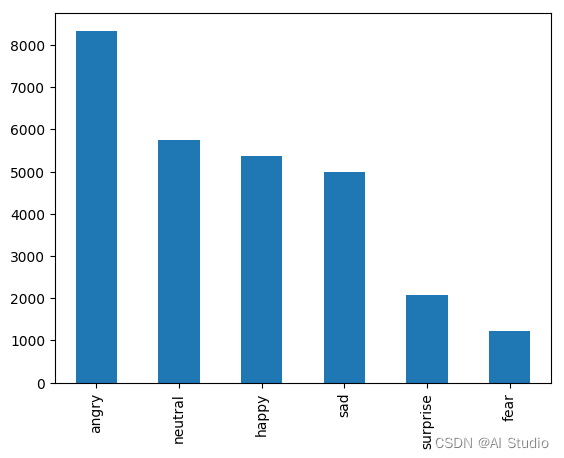
从图像中可以看出,类别的标签并不是非常的均匀,但没有达到小样本的程度,都还是1000条以上的
2.4 对数据进行预处理
首先判断一下数据中是否有空数据之类的脏数据
print(train_data.isnull().sum())
print(test_data.isnull().sum())
print(eval_data.isnull().sum())
数据编号 0
文本 2
情绪标签 0
dtype: int64
数据编号 0
文本 0
情绪标签 0
dtype: int64
数据编号 0
文本 0
情绪标签 0
dtype: int64
从输出结果可知,训练数据中有2条空数据,接下来我们去除这些脏数据
#删除有NAN的行
print(len(train_data))
# print(train_data[train_data.isnull().T.any()])
train_data=train_data.drop(train_data[train_data.isnull().T.any()].index)
print(len(train_data))
print(train_data.isnull().sum())
27768
27766
数据编号 0
文本 0
情绪标签 0
dtype: int64
脏数据去除完成之后,我们给数据加上分类的标签,比如angry,就把它变成类别0,方便之后Bert网络的处理
def get_label(motion):
hashmap={"angry":0,"fear":1,"happy":2,"neutral":3,"sad":4,"surprise":5}
return hashmap[motion]
train_data["标签"]=train_data.apply(lambda x:get_label(x["情绪标签"]),axis=1)
test_data["标签"]=test_data.apply(lambda x:get_label(x["情绪标签"]),axis=1)
eval_data["标签"]=eval_data.apply(lambda x:get_label(x["情绪标签"]),axis=1)
#数据准备
import numpy as np
train_sentence=np.array(train_data["文本"])
train_label=np.array(train_data["标签"])
eval_sentence=np.array(eval_data["文本"])
eval_label=np.array(eval_data["标签"])
test_sentence=np.array(test_data["文本"])
test_label=np.array(test_data["标签"])
在数据处理完成之后,我们来判断一下每份数据的句子中最长的长度是多少,方便之后对句子进行Padding操作
#判断一下文本长度
print(np.max(np.array([len(x) for x in train_sentence])))
print(np.max(np.array([len(x) for x in eval_sentence])))
print(np.max(np.array([len(x) for x in test_sentence])))
#可知最长为331,那我们使用512来截取句子
213
162
331
2.5 搭建Bert模型
首先也是导入必要的包
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
自定义数据集的数据结构,方便之后进行处理
class BertDataSet(Dataset):
def __init__(self, data, label, tokenizer):
self.data = data
self.label = label
self.input_data = tokenizer(
[sentence for sentence in data],
max_seq_len=512,
pad_to_max_seq_len=True
)
def __len__(self):
return len(self.label)
def __getitem__(self, item):
return {
"input_ids": self.input_data['input_ids'][item],
"token_type_ids": self.input_data['token_type_ids'][item],
"labels": self.label[item],
}
导入预训练的Bert模型,并且产生训练集和验证集的指定数据结构
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_classes=6,cache_dir=PATH)
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
train_ds1=BertDataSet(train_sentence,train_label,tokenizer)
eval_ds1=BertDataSet(eval_sentence,eval_label,tokenizer)
[2022-12-06 12:57:23,353] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load 'bert-base-chinese'.
[2022-12-06 12:57:23,356] [ INFO] - Downloading http://bj.bcebos.com/paddlenlp/models/transformers/bert/bert-base-chinese.pdparams and saved to /home/aistudio/.paddlenlp/models/bert-base-chinese
[2022-12-06 12:57:23,358] [ INFO] - Downloading bert-base-chinese.pdparams from http://bj.bcebos.com/paddlenlp/models/transformers/bert/bert-base-chinese.pdparams
100%|██████████| 680M/680M [00:37<00:00, 19.0MB/s]
W1206 12:58:01.015071 165 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W1206 12:58:01.021207 165 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2022-12-06 12:58:08,181] [ INFO] - We are using <class 'paddlenlp.transformers.bert.tokenizer.BertTokenizer'> to load 'bert-base-chinese'.
[2022-12-06 12:58:08,185] [ INFO] - Downloading https://bj.bcebos.com/paddle-hapi/models/bert/bert-base-chinese-vocab.txt and saved to /home/aistudio/.paddlenlp/models/bert-base-chinese
[2022-12-06 12:58:08,187] [ INFO] - Downloading bert-base-chinese-vocab.txt from https://bj.bcebos.com/paddle-hapi/models/bert/bert-base-chinese-vocab.txt
100%|██████████| 107k/107k [00:00<00:00, 3.03MB/s]
[2022-12-06 12:58:08,316] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/bert-base-chinese/tokenizer_config.json
[2022-12-06 12:58:08,320] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/bert-base-chinese/special_tokens_map.json
2.6 配置模型的训练参数
我们现在来配置一下我们模型所需要的训练的参数
- 训练轮次设为2轮
- 训练时的batch_size的大小设置为8,验证时的batch_size的大小设置为16
- 每次保存效果最好的模型
- 模型的评价指标采用f1指标
training_args = TrainingArguments(
output_dir=PATH+'output',
num_train_epochs=2,
per_device_train_batch_size=8,
gradient_accumulation_steps=2,
per_device_eval_batch_size=16,
dataloader_num_workers=0,
logging_dir=PATH+'logs',
logging_steps=50,
evaluation_strategy="steps",
eval_steps=50,
save_steps=50,
save_total_limit=10,
load_best_model_at_end=True,
metric_for_best_model='f1',
report_to=[],
)
我们定义一个辅助函数,用来获得模型的准确率和F1分数
def compute_metrics(pred):
lables = pred.label_ids
preds = pred.predictions.argmax(-1)
acc = accuracy_score(lables, preds)
f1 = f1_score(lables, preds, average="macro")
return {
"accuracy": acc,
"f1": f1,
}
trainer=Trainer(
model=model,
criterion=paddle.nn.CrossEntropyLoss(),
args=training_args,
train_dataset=train_ds1,
eval_dataset=eval_ds1,
compute_metrics=compute_metrics
)
[2022-12-06 12:58:20,248] [ INFO] - ============================================================
[2022-12-06 12:58:20,251] [ INFO] - Training Configuration Arguments
[2022-12-06 12:58:20,253] [ INFO] - paddle commit id :3fa7a736e32508e797616b6344d97814c37d3ff8
[2022-12-06 12:58:20,256] [ INFO] - _no_sync_in_gradient_accumulation:True
[2022-12-06 12:58:20,258] [ INFO] - adam_beta1 :0.9
[2022-12-06 12:58:20,260] [ INFO] - adam_beta2 :0.999
[2022-12-06 12:58:20,262] [ INFO] - adam_epsilon :1e-08
[2022-12-06 12:58:20,264] [ INFO] - current_device :gpu:0
[2022-12-06 12:58:20,266] [ INFO] - dataloader_drop_last :False
[2022-12-06 12:58:20,269] [ INFO] - dataloader_num_workers :0
[2022-12-06 12:58:20,271] [ INFO] - device :gpu
[2022-12-06 12:58:20,273] [ INFO] - disable_tqdm :False
[2022-12-06 12:58:20,276] [ INFO] - do_eval :True
[2022-12-06 12:58:20,278] [ INFO] - do_export :False
[2022-12-06 12:58:20,280] [ INFO] - do_predict :False
[2022-12-06 12:58:20,282] [ INFO] - do_train :False
[2022-12-06 12:58:20,284] [ INFO] - eval_batch_size :16
[2022-12-06 12:58:20,286] [ INFO] - eval_steps :50
[2022-12-06 12:58:20,288] [ INFO] - evaluation_strategy :IntervalStrategy.STEPS
[2022-12-06 12:58:20,290] [ INFO] - fp16 :False
[2022-12-06 12:58:20,293] [ INFO] - fp16_opt_level :O1
[2022-12-06 12:58:20,295] [ INFO] - gradient_accumulation_steps :2
[2022-12-06 12:58:20,298] [ INFO] - greater_is_better :True
[2022-12-06 12:58:20,300] [ INFO] - ignore_data_skip :False
[2022-12-06 12:58:20,301] [ INFO] - label_names :None
[2022-12-06 12:58:20,303] [ INFO] - learning_rate :5e-05
[2022-12-06 12:58:20,305] [ INFO] - load_best_model_at_end :True
[2022-12-06 12:58:20,307] [ INFO] - local_process_index :0
[2022-12-06 12:58:20,309] [ INFO] - local_rank :-1
[2022-12-06 12:58:20,311] [ INFO] - log_level :-1
[2022-12-06 12:58:20,313] [ INFO] - log_level_replica :-1
[2022-12-06 12:58:20,315] [ INFO] - log_on_each_node :True
[2022-12-06 12:58:20,317] [ INFO] - logging_dir :/home/aistudio/work/logs
[2022-12-06 12:58:20,319] [ INFO] - logging_first_step :False
[2022-12-06 12:58:20,321] [ INFO] - logging_steps :50
[2022-12-06 12:58:20,323] [ INFO] - logging_strategy :IntervalStrategy.STEPS
[2022-12-06 12:58:20,325] [ INFO] - lr_scheduler_type :SchedulerType.LINEAR
[2022-12-06 12:58:20,327] [ INFO] - max_grad_norm :1.0
[2022-12-06 12:58:20,329] [ INFO] - max_steps :-1
[2022-12-06 12:58:20,331] [ INFO] - metric_for_best_model :f1
[2022-12-06 12:58:20,333] [ INFO] - minimum_eval_times :None
[2022-12-06 12:58:20,335] [ INFO] - no_cuda :False
[2022-12-06 12:58:20,337] [ INFO] - num_train_epochs :2
[2022-12-06 12:58:20,338] [ INFO] - optim :OptimizerNames.ADAMW
[2022-12-06 12:58:20,340] [ INFO] - output_dir :/home/aistudio/work/output
[2022-12-06 12:58:20,342] [ INFO] - overwrite_output_dir :False
[2022-12-06 12:58:20,344] [ INFO] - past_index :-1
[2022-12-06 12:58:20,346] [ INFO] - per_device_eval_batch_size :16
[2022-12-06 12:58:20,348] [ INFO] - per_device_train_batch_size :8
[2022-12-06 12:58:20,350] [ INFO] - prediction_loss_only :False
[2022-12-06 12:58:20,352] [ INFO] - process_index :0
[2022-12-06 12:58:20,354] [ INFO] - recompute :False
[2022-12-06 12:58:20,356] [ INFO] - remove_unused_columns :True
[2022-12-06 12:58:20,358] [ INFO] - report_to :[]
[2022-12-06 12:58:20,360] [ INFO] - resume_from_checkpoint :None
[2022-12-06 12:58:20,362] [ INFO] - run_name :/home/aistudio/work/output
[2022-12-06 12:58:20,364] [ INFO] - save_on_each_node :False
[2022-12-06 12:58:20,366] [ INFO] - save_steps :50
[2022-12-06 12:58:20,369] [ INFO] - save_strategy :IntervalStrategy.STEPS
[2022-12-06 12:58:20,371] [ INFO] - save_total_limit :10
[2022-12-06 12:58:20,373] [ INFO] - scale_loss :32768
[2022-12-06 12:58:20,375] [ INFO] - seed :42
[2022-12-06 12:58:20,377] [ INFO] - should_log :True
[2022-12-06 12:58:20,379] [ INFO] - should_save :True
[2022-12-06 12:58:20,381] [ INFO] - train_batch_size :8
[2022-12-06 12:58:20,383] [ INFO] - warmup_ratio :0.0
[2022-12-06 12:58:20,385] [ INFO] - warmup_steps :0
[2022-12-06 12:58:20,387] [ INFO] - weight_decay :0.0
[2022-12-06 12:58:20,389] [ INFO] - world_size :1
[2022-12-06 12:58:20,391] [ INFO] -
开始训练并且保存模型
trainer.train()
trainer.save_model(PATH+"best_model1")
2.7测试模型的结果
这里说一下在训练集上验证结果时所遇到的坑。主要是关于no_grad的使用的问题,如果不使用这个函数,那么在测试的时候梯度就会累计,这样会造成显卡的压力很大,会直接爆显卡导致Notebook崩溃,加上了这个之后,显存的使用明显下降了许多,但是就算是这样,这个也需要每小时1算力的那个GPU平台才能够跑起来,也就是显存大小为32G,低于这个算力的Notebook建议不要尝试,有极大可能会直接崩溃
import time
class TokenItem:
def __init__(self,sentence,tokenizer):
self.tokenizer=tokenizer
self.token=tokenizer(
[sentence],
max_seq_len=512,
pad_to_max_seq_len=True
)
def __del__(self):
pass
def get_test_acc():
model1=AutoModelForSequenceClassification.from_pretrained(PATH+"best_model1/",num_classes=6)
ans = []
tokenizer=AutoTokenizer.from_pretrained("bert-base-chinese")
with paddle.no_grad():
for i in range(len(test_label)):
tokenItem=TokenItem(test_sentence[i],tokenizer)
outputs = model1(input_ids=paddle.to_tensor(tokenItem.token.input_ids,dtype='int64'),
token_type_ids=paddle.to_tensor(tokenItem.token.token_type_ids,dtype='int64'))
del tokenItem
result = paddle.argmax(outputs[0])
del outputs
ans.append(result)
# print(i)
if i % 100 == 0:
print("已处理", i, "条")
return ans
ans=get_test_acc()
[2022-12-06 12:59:33,586] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load '/home/aistudio/work/best_model1/'.
[2022-12-06 12:59:34,779] [ INFO] - We are using <class 'paddlenlp.transformers.bert.tokenizer.BertTokenizer'> to load 'bert-base-chinese'.
[2022-12-06 12:59:34,782] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-base-chinese/bert-base-chinese-vocab.txt
[2022-12-06 12:59:34,797] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/bert-base-chinese/tokenizer_config.json
[2022-12-06 12:59:34,799] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/bert-base-chinese/special_tokens_map.json
已处理 0 条
已处理 100 条
已处理 200 条
已处理 300 条
已处理 400 条
已处理 500 条
已处理 600 条
已处理 700 条
已处理 800 条
已处理 900 条
已处理 1000 条
已处理 1100 条
已处理 1200 条
已处理 1300 条
已处理 1400 条
已处理 1500 条
已处理 1600 条
已处理 1700 条
已处理 1800 条
已处理 1900 条
已处理 2000 条
已处理 2100 条
已处理 2200 条
已处理 2300 条
已处理 2400 条
已处理 2500 条
已处理 2600 条
已处理 2700 条
已处理 2800 条
已处理 2900 条
已处理 3000 条
已处理 3100 条
已处理 3200 条
已处理 3300 条
已处理 3400 条
已处理 3500 条
已处理 3600 条
已处理 3700 条
已处理 3800 条
已处理 3900 条
已处理 4000 条
已处理 4100 条
已处理 4200 条
已处理 4300 条
已处理 4400 条
已处理 4500 条
已处理 4600 条
已处理 4700 条
已处理 4800 条
已处理 4900 条
def compute_test():
acc = accuracy_score(test_label, ans)
f1 = f1_score(test_label, ans, average="macro")
return {
"accuracy": acc,
"f1": f1,
}
print(compute_test())
{'accuracy': 0.7676, 'f1': 0.7401780726494455}
2.8 模型的最终效果
最后,我们可以看出,这个模型在测试集上的准确率到达了0.768,F1分数达到了0.737,说明这个模型还算不错
def get_sentiment(label):
# hashmap={0:"angry",1:"fear",2:"happy",3:"neutral",4:"sad",5:"surprise"}
hashmap={0:"生气",1:"害怕",2:"高兴",3:"中性",4:"悲伤",5:"惊讶"}
return hashmap[label]
def predict_sentence(sentence):
model1=AutoModelForSequenceClassification.from_pretrained(PATH+"best_model1/",num_classes=6)
with paddle.no_grad():
tokenItem=TokenItem(sentence,tokenizer)
outputs = model1(input_ids=paddle.to_tensor(tokenItem.token.input_ids,dtype='int64'),
token_type_ids=paddle.to_tensor(tokenItem.token.token_type_ids,dtype='int64'))
del tokenItem
result = paddle.argmax(outputs[0])
label=result.numpy()[0]
sentiment=get_sentiment(label)
return sentiment
然后,我们随便写一个句子来测试一下模型的效果
print(predict_sentence("欸,真高!"))
print(predict_sentence("今天天气真好"))
print(predict_sentence("进不去,这么想都进不去吧"))
print(predict_sentence("诶呦,你干嘛~~"))
[2022-12-06 13:15:15,958] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load '/home/aistudio/work/best_model1/'.
惊讶
[2022-12-06 13:15:17,209] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load '/home/aistudio/work/best_model1/'.
高兴
[2022-12-06 13:15:18,426] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load '/home/aistudio/work/best_model1/'.
生气
[2022-12-06 13:15:19,627] [ INFO] - We are using <class 'paddlenlp.transformers.bert.modeling.BertForSequenceClassification'> to load '/home/aistudio/work/best_model1/'.
惊讶
2022-12-06 13:15:19,627] [ INFO] - We are using <class ‘paddlenlp.transformers.bert.modeling.BertForSequenceClassification’> to load ‘/home/aistudio/work/best_model1/’.
惊讶
三.进行前后端分离式Web部署
3.1 基于FastAPI来搭建API
这里使用FastAPI来搭建API的过程参考了如下项目:
https://aistudio.baidu.com/aistudio/projectdetail/5060618
3.1.1解决跨域问题
# 设置允许跨域请求,解决跨域问题
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
3.1.2 搭建用户输入语句的接口
定义接口的python代码如下
# 接下来定义用户输入的文本类型
class UserInput(BaseModel):
text: str
@app.post("/weiboSentimentAnalysis/", status_code=200)
async def SentimentAnalysis(userinput: UserInput):
try:
input_text = userinput.text
sentiment = predict_sentence(input_text)
results = {"message": "success", "input_text": input_text
, "sentence_analysis": sentiment}
return results
except Exception as e:
print("出现异常")
print("异常信息为:", e)
raise HTTPException(status_code=500, detail="请求失败,异常信息为" + str(e))
# 启动创建的实例app,设置启动ip和端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
3.1.3 Postman接口测试
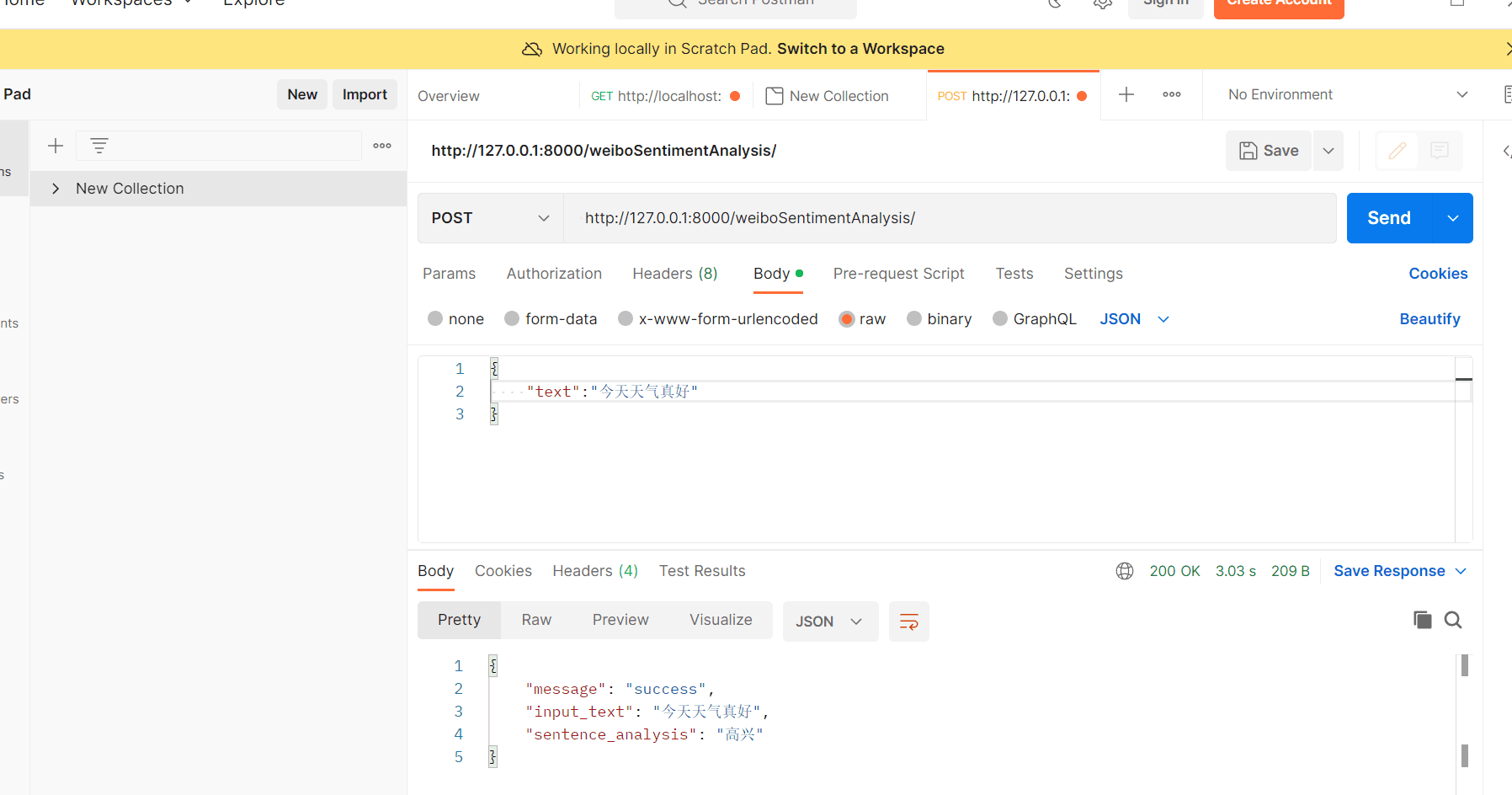
可以看出接口能够正常运行
3.2 使用Vue来搭建前端页面
最后搭建出的界面的效果如下:
因为作者对于前端界面的搭建不太熟练,所以做的有点粗糙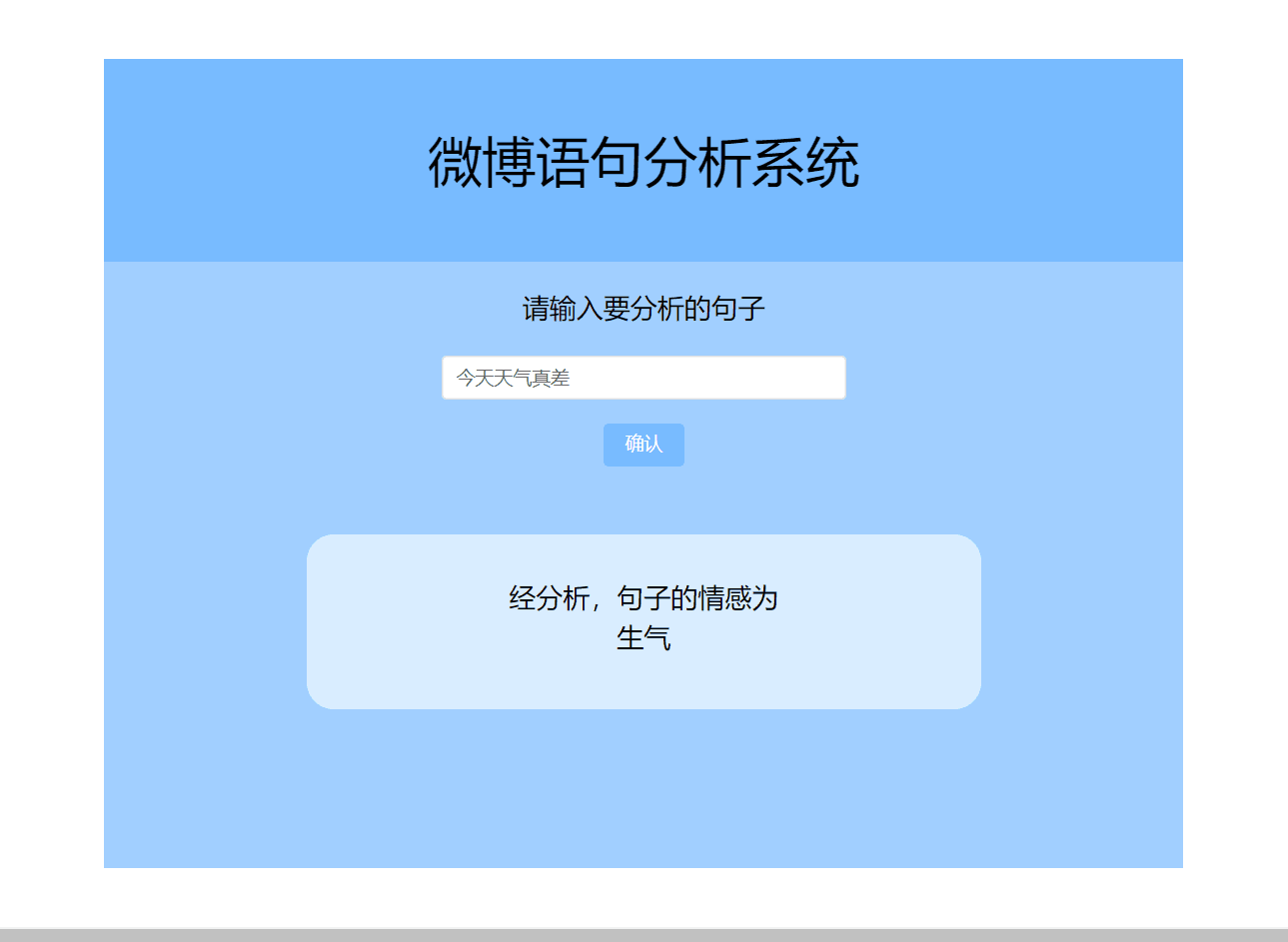
四. 项目总结
本次项目重点介绍了基于Bert模型的微博舆论分析模型的搭建,以及一些简单的前后端的部署
可以优化的一些方向
- Bert模型一直是以模型大,训练时间长而出名,可以通过一些方法来压缩Bert模型,从而达到更快的模型训练的效果以及更加小的模型
- 可以添加一个数据库,记录一下用户判断了哪些句子
- 可以增加批量处理语句的功能,这样就能够更加快捷的分析情感
参考项目
五.作者介绍
项目作者:杨博航
AI Studio昵称:潮花汐拾888
飞桨导师:黄灿桦
AI Studio昵称:炼丹师233
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 5
5 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)