
一只爬虫是如何炼成的-爬虫基础流程介绍
AI达人特训营第二期,比较系统的介绍了一个网络爬虫的基本工作流程:数据爬取、数据清洗到数据可视化。希望此项目可以为大家学习爬虫指引方向!
1. 一只爬虫是怎样炼成的
对于没接触过爬虫的伙伴们,肯定很好奇什么是网络爬虫?爬虫有什么用?它的整个流程是什么?本教程将会介绍并展示一些典型爬虫手段,相信可以为你的爬虫学习道路点亮一座灯塔。
代码和图片调整至鼠标移上去放大,有BUG就是俺的,,,非BML的…
爬虫是一种在网页上获取数据的工具;
当你想要训练一个模型,但是缺少数据的时候,你是否渴望过把网页上你所见到的数据都下载下来?但是手动一个个下载、一个个CV会很慢很麻烦;
当你想要购买一个商品的时候,你是否想过把它从各个商城平台上拿下来,快捷的进行比价、分析性价比?
当你需要训练一个计算机视觉模型,除了常用的数据集以外,你也可以通过爬取各大图库网站来组建自己的数据集;
当你学会它的时候,你可以在各大网站上为所欲为(bushi,相信大家都是合法公民,有良好的道德底线,还有很棒的自觉性,这里仅仅是玩笑)。
它一般有以下几个步骤:
- 寻找数据
- 爬取数据
- 数据处理与清洗
- 数据存储
这些会在之后一一介绍,当然在此之前将先介绍可能会使用的爬虫工具,可以直接跳过代码部分直达
爬虫工具的使用!
每个模块的介绍方式为:
- 知识点/工具介绍
- 简单实战/练习
- 总结与推荐学习资料
相比于各大教程,本教程更像是带大家走个流程,看个过程,目的是让大家了解爬虫的工作方式,一般没有其他教程详细,所以大家要结合其他教程食用!
接下来将以图文展示+代码实战来介绍爬虫的基本流程,包含代码爬虫和爬虫软件
1.1 什么是爬虫?
爬虫,即网络爬虫,大家可以理解为在网络上爬行的一只蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛
如果它遇到自己的猎物(所需要的资源),那么它就会将其抓取下来。 『—解释来源于php.cn』
定义再多也不好理解,我们直接先上手来体验一下
1.1.1 网络请求的过程
在此之前先来认识一下网络请求:
你访问一个页面的过程本质是你浏览器问相应的服务器要相应数据的过程,整个流程就像送信一样:
你的浏览器:
我是U浏览器,我的地址是xxx。我的使用者要看你的主页! —送至服务器A
服务器A:
好的,我给你邮过去,包裹里面有架子;说明书和装饰品、架子的控制器等等你看着要,你自己按照说明书摆好!别把东西丢了!说明书没有的再问我要! —回送给浏览器U,地址是xxx
你的浏览器:
架子这里差一个图片!
服务器A:
好的亲,已发送!
你的浏览器:
控制器少了燃料!没有燃料动不起来!
服务器A:
亲亲,已发送!
你的浏览器:
还少了个东西!
服务器A:
问服务器B要去!
…
你的浏览器:
拆行李 + 摆好:芜湖!一番折腾终于摆好这些东西了!小东西甄别致
如果稍微转换一下用词:
你的浏览器:
user-agent: U;:method: GET;:authority: 基本地址;:path:基本地址基础下的主页地址; —TCP连接时作为请求送至服务器A
服务器A:
好的,我给你邮过去,包裹里面有HTML(架子);CSS(说明书和装饰品)、Js(架子的控制器)等等你看着要,你自己按照说明书摆好!别把东西丢了!说明书没有的再问我要! —作为相应将数据送回
你的浏览器:
get 图片
get 数据
get js
post 数据
…服务器A:
…
你的浏览器:
拼架子、渲染!页面出来了!
1.1.2 爬虫的奇妙比喻
当你打开浏览器访问一个网址时,你的浏览器会先根据你输入的网址去寻找到服务器的地址,然后疯狂的问服务器要零件,最后拼凑出整个页面!
为了得到数据,我们常常要伪装成浏览器问相应服务器要东西,如果两者之间没有什么约定好的验证手段(如果有也可以找规律破解),那么就像你QQ被盗了一样:
平时:
你:A,借我你的号玩玩!我想体验一下你刚买的新皮肤!
A:可以呀,给你
你的号被盗后:
盗你号的人模仿你:A,借我你号玩一下,我想体验新皮肤!
A:可以呀,给你
现在一定看累了吧,那么我们小实战一下吧!
pypi是众多Python爱好者上传第三方库的平台,你可以看到目前最新的类库以及开发者数
可以看到这个网页灰色条中有四个数据,虽然你可能对他四个不太感兴趣,但我们仍然先尝试把他们想办法扒拉下来
因为这种玩意儿大体都相同,会扒拉一个就会扒拉一堆!

# shell 命令 echo 类似于 python 的 print 。由于输出太长所以在此截断
!echo 开始升级/下载 pip
!pip install --upgrade pip > /dev/null # > 符号将输出重定向到 /dev/null 文件中(黑洞文件)以达到阶段的效果
!echo pip 升级/下载完成!
!echo 开始升级/下载 requests
!pip install -U requests > /dev/null # 先下载/升级相关工具库
!echo requests 升级/下载完成!
开始升级/下载 pip
pip 升级/下载完成!
开始升级/下载 requests
升级/下载完成!
1.1.3 模拟发送请求-py的requests库
import requests as rq
response = rq.get("https://pypi.org/") # 我们使用 `requests` 库模拟浏览器向服务器发送 `GET` 请求
if response.status_code == 200:
print(f'请求成功,状态码为:{response.status_code}')
with open('pypi_source.html', 'w') as f: # 将结果保存
f.write(response.text)
print('结果保存完成!')
else:
print(f'请求失败,状态码为:{response.status_code}')
print('源代码前20行为:', '-'*80, sep='\n')
# 尝试看一下刚刚保存的网页源代码
!head pypi_source.html -n 20
print('-'*80)
请求成功,状态码为:200
结果保存完成!
源代码前20行为:
--------------------------------------------------------------------------------
<!DOCTYPE html>
<html lang="en" dir="ltr">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="defaultLanguage" content="en">
<meta name="availableLanguages" content="en, es, fr, ja, pt_BR, uk, el, de, zh_Hans, zh_Hant, ru, he, eo">
--------------------------------------------------------------------------------
1.1.3.1 requests库介绍
python的requests库是基于标准库urllib封装的一个操作简单、功能强大的第三方库,模拟浏览器发送请求后返回 responce 对象
requests 常用方法:
| 方法 | 用途 | 参数 |
|---|---|---|
| get | 模拟发送get请求 | url, params=None, **kwargs |
| post | 模拟发送post请求 | url, data=None, json=None, **kwargs |
| session | 创建一个会话对象,会保存cookies |
kwargs: 公共参数如:headers(头部信息): dict、proxies: {‘http’: ‘ip, 如:xxx.xxx.xx.xxx:xx’}、timeout(超时时间): int
responce 对象常用方法/属性:
| 属性 | 介绍 | 例子 |
|---|---|---|
| text | 自动解析后的文本数据 | str: ‘<!DOCU…>’ |
| encoding | 自动解析出的编码方式 | str: ‘UTF-8’ |
| url | 所请求的url | str: ‘https://pypi.org/’ |
| content | 响应得到的内容(二进制) | bytes: b’<!DOCU…’ |
| status_code | 响应的状态码 | int:200 |
| headers | 响应的头部信息 | dict:{‘Connection’: ‘keep-alive’, …} |
| json() | 将返回的数据按 json 格式解析 | dict: {‘msg’: ‘ok’, …} |
| cookies | 返回的cookies | 一个类列表对象:<RequestsCookieJar[…]> |
接下来将着重讲述get(常用于请求资源)、post(常用于发送数据和获取数据处理后的结果)方法和session(得到cookies后每次访问都自动携带cookies)对象
其他请求方式如:patch(部分字段修改)、put(字段全改)、head(请求头部)、delete(对象删除)、options(操作)将不再赘述
更多的方法与参数请使用 dir 函数与 help 函数查看
1.1.3.2 requests小任务
在上面我们演示请求了 pypi.org ,那么现在请你利用 requests 库直接请求和利用 session 对象请求 https://www.baidu.com/
并将请求结果保存至 baidu_source.html 中,且查看
import requests as rq
responce1 = rq.get('补全代码')
print(responce1.status_code)
session_obj = rq.session()
responce2 = session_obj.get('补全代码')
...
'UTF-8'
相信你已经完成了上述任务,而且还是用代码完成的。那么,你有没有设想过一条道路…


CTRL+A -> CTRL+C -> 新建文件 -> CTRL+V -> 保存 -> 完成任务!
拿到源代码/数据的手段千千万,不要拘泥于任何一种方法。八仙过海各显神通即可 😃
1.1.3.4 模拟发送请求小结
根据上述的学习我们知道一个web页面显示的一切都是浏览器发送请求到服务器后经过渲染显示出来的,那么爬虫的难点之一就在如何去模仿浏览器发送请求
- 或许是请求头携带浏览器的版本标识,即User-Agent
- 或许是每一次请求都携带cookies保持自己的登录状态
- 或许是携带自己上一次访问的地址(防盗链),表示自己是“本站”访问的
爬虫的另一个难点就是寻找请求数据的地址。
这时我们往往需要追踪浏览器访问网页的请求过程,看某部分数据是浏览器请求的哪个接口得到的。直接爬取接口要比爬取整个页面更高效。

那么现在除了上述提到的 urllib, requests 库外大家还知道哪些用于web请求的库呢?
学习资料:
requests: W3Cschool
1.1.4 尝试提取数据
经过上面的操作,我们拿到了网页的源代码。然后接下来的问题就是:如何拿到想要的数据呢?
1.1.4.1 "推荐"的方法-手动CV…
面向上帝:

面向结果:

面向毒打:
text = open('pypi_source.html').read()
for i in text.split():
if i == '421,508 projects' or i == '4,012,522 releases' or ...:
...
面向正则:
import re # 正则:标准库,在后面数据处理部分介绍
re.findall(r'(\d[0-9,]+[ ][a-z]+)', response.text) # 找到大部分数据重复的规律写正则,少部分特判即可
1.1.4.2 真正推的方法-解析库
实话说,上面的方法真的可以。当数据量成千上万的时候,当解析规则写正则很复杂的时候,总有肝帝会利用上述方式达成他们的目的。既然拿到了数据,那么我们看下一个…哎哎哎,别打,我错了!
那么接下来考虑如何更方便的拿到数据:
在浏览器渲染之前,DOM树就已经被渲染完毕。在 Js 中,我们只需要利用这棵DOM树便可以很方便的拿到想要的节点:
for(let i of document.getElementsByClassName('statistics-bar__statistic')) {
console.log(i.innerHTML)
}

那么用 Python 可不可做到相同的事情呢?
这就要提到几个常用的解析库了:
- lxml
- jsonpath
- bs4
我们以 lxml 和 bs4 为例
!pip install -U lxml bs4 # 安装/升级工具库
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Requirement already satisfied: lxml in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (4.9.1)
Requirement already satisfied: bs4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (0.0.1)
Requirement already satisfied: beautifulsoup4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from bs4) (4.11.1)
Requirement already satisfied: soupsieve>1.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from beautifulsoup4->bs4) (2.3.2.post1)
1.1.4.2.1 lxml解析库介绍
XML和HTML的解析器,可以通过简单的 xpath 描述来获取节点对象,从而提取数据
from lxml import etree
with open('pypi_source.html', 'r') as f:
text = f.read()
tree = etree.HTML(text) # 指定解析器HTML来解析text,将文档生成树。同理,可以利用XML解析器解析XML
tree.xpath('//p[@class="statistics-bar__statistic"]/text()')
['\n 421,493 projects\n ',
'\n 4,012,294 releases\n ',
'\n 7,223,729 files\n ',
'\n 648,373 users\n ']
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。 『—解释来源于百度百科』
1.1.4.2.2 XPath语法介绍
| 符号 | 意义 | 举例 |
|---|---|---|
| // | 表示所有后代节点的缩写 | /html//p 代表的意义有且不限于:/html/body/p、/html/body/div/p、/html/body/article/p、… |
| / | 取子元素 | <div><span>123</span></div> 取span://div/span |
| … | 取父元素,和目录一个道理 | class为code的父节点://div[@class=“code”]/…/ |
| ./ | 从当前节点查找 | 略 |
| * | 任意节点,但是只表示一个节点 | //body/*/p 代表的意义有且不限于://body/div/p、//body/article/p、… |
| num | 表示第几个节点(从 1 开始) | //div//li[1] |
| @ | 取属性值 | 如取div下a的链接://div/a/@href |
| [@] | 按属性值查找 | 如所有有name属性的div://div[@name]、name为abc的div://div[@name=“abc”] |
| text() | 取标签中间的文本 | //div/text() |
| | | 或 | 结果合并其他节点的集合 |
| () | 分组 | 略 |
xpath的其余轴参考:CSDN
好了,先了解这些,过来实战一下吧!
# 请写出 xpath语句 取到要求取到的元素
from lxml import etree
tree = etree.HTML('''
<div>
<div></div>
<div class="code">
<a href="#QAQ#">取到此标签的🔗链接和此段文本</a>
</div>
<div></div>
</div>''')
res = tree.xpath('补全此代码!!!')
res # 结果参考:['#QAQ#']
['#QAQ#']
1.1.4.2.3 bs4解析库介绍
即BeautifulSoup,和 lxml 一样,是一个html的解析器,主要功能也是解析和提取数据 。
可以自动补全缺失一半的标签,效率没有 lxml 高,但是接口人性化,方便使用
bs4 的节点对象可以直接使用 . 来取包括但不限于:子对象、属性、文本等等
常用方法:
| 方法 | 描述 | 例子 |
|---|---|---|
| find | 找一个标签 | 找第一个 a标签 节点对象soup.find(‘a’) |
| find_all | 将满足描述的加入列表返回 | 略 |
| select | 用CSS选择器的语法解析节点 | soup.select(‘#code’) |
公共参数:attrs
sttrs 用来辅助描述节点,如 class 为 code 、 name 为 abc 的 div 节点:
soup.find_all('div', attrs={'class': 'code', 'name': 'abc'})
# 上面的代码等效于:
soup.find_all('div', class_='code', name='abc') # `属性=值` 的形式,因为class在py中是保留字,所以加下划线避嫌
节点对象常用方法/属性:
| 方法 | 介绍 | 例子 |
|---|---|---|
| text | 取中间的text | node.string |
| get_text() | 取中间的text | node.get_text() |
| attrs | 看单词就是到是属性们的键值对 | node.attrs.get(‘href’) |
| get | 直接取属性 | node.get(‘href’) |
| [ ] | 更直接的取属性 | node[‘href’] |
from bs4 import BeautifulSoup as bs4
with open('pypi_source.html') as f:
text = f.read()
page = bs4(text, 'html.parser') # 设置解析器解析网页
nodes = page.find_all("p", class_='statistics-bar__statistic')
for i in nodes:
print(i.text)
421,493 projects
4,012,294 releases
7,223,729 files
648,373 users
1.1.4.2.4 解析库介绍小结
可以看到,我们可以通过各种手段通过解析网页源代码来得到想要的结果
那么解析时用到的的class="statistics-bar__statistic"又是在哪里找到的呢?
接下来我们先介绍一个web开发中必不可少的工具
打开方式:设置 -> 其他 -> 开发者工具

Tip:有些浏览器的快捷键是F12

可以看到我们很轻易就找到了我们想要的数据在源代码中的位置

可以看到描述一个网页元素的方法有很多种,Xpath,CSS选择器等等,我们任意选择一个熟悉的描述方式来取得我们需要的元素或元素们,也就是上面的各种“手段”。

Tip:有时候只会复制 xpath 还不够,还得找规律和学会自己写!比如:用类名直接 //div[class="xxx"]/ 就能找到的节点往往在浏览器复制出的 xpath 很复杂,很长,常常导致解析失败,泛用性不强。
1.2 代码爬取数据补充
1.2.1 自动化爬虫框架介绍Scrapy
上面我们学会了提取一个页面中的数据,但是有些信息他不是分布在一个页面的:
比如:
哔哩哔哩的视频头图在搜索结果页中,但是点赞投币吃灰数却在视频详情页
新闻列表在第一页,每个新闻的详细内容在第二页

这个时候我们怎么办?
方法1:解析出地址后自己再发一个请求进行解析
# 伪代码,看个乐呵即可
# 对待储存的数据对象建模,有第一页的标题和点进去的正文两部分内容
class InfoObj:
title : '第一页的标题字段'
info : '点进去后的正文字段'
request_queue = ['xxx'] # 请求队列
has_view = set() # 去重
info_objs = [] # 结果对象存在这里
while request_queue:
url = request_queue.pop(0) # 取出一个待访问的网址
if url in has_view: # 如果访问过就跳过
continue
responce = rq.get(url) # 没有访问过就访问 + 标记已访问
has_view.add(url)
tree = etree.HTML(responce.text) # 构建解析后的文档树
title = tree.xpath('...') # 解析出 title
info_urls = tree.xpath('...') # 解析出 info 的页面链接
info_responce = rq.get(info_urls) # 使用 GET 请求 `点进去`
inner_tree = etree.HTML(info_responce.text) # 同上
info = inner_tree.xpath('...')
info_objs.append(InfoObj( # 将解析出的信息作为对象保存到列表
title=title,
info=info,
))
new_urls = tree.xpath('...') # 模拟翻页
request_queue.extern(new_urls) # 将解析出的下一页地址放入解析队列中
import pickle
with open('objects.pkl', 'wb') as save_file: # 这里将列表和对象序列化保存至 pkl 文件中
pickle.dump(info_objs, save_file)
方法2:将上述方法封装为一个泛用的爬虫框架,或者直接使用爬虫框架 scrapy
1.2.2 Scrapy介绍小结
scrapy 将爬虫的四个基本步骤抽象为四个不同模块:
| 基本概念 | scrapy |
|---|---|
| 访问网页 | 爬虫 |
| 爬取数据 | 解析 |
| 储存数据 | 管道 |
| 请求队列 | 请求队列 |
感兴趣的小伙伴跟随下面的资料进行自行学习吧!
学习资料:
Scrapy框架: 哔哩哔哩
1.2.3 自动化测试框架Selenium介绍
Selenium是一个WEB自动化测试框架,测试工程师常常带着这个去前后端工程师的酒吧点炒饭
他可以通过浏览器驱动开启一个浏览器窗口,你可以用鼠标操控该窗口,也可以利用代码操控,所以他就被广大网友强制从自动化测试工具跳槽到了爬虫工具…
因此,你不必用代码先post拿cookies后再get拿数据,取而代之的是直接扫码登陆,鼠标移动到想要的数据旁
右键->复制xpath
pip install -U selenium
from selenium import webdriver
# 绑定驱动,注意浏览器和驱动的版本号对应关系!
browser = webdriver.浏览器的名字('这里是驱动的位置') # 如:webdriver.chrome('c:\\xxx\\driver.exe') 之类的
browser.get('url') # 打开浏览器看网址
# 取节点对象
browser.find_element_by_xpath('xpath')
browser.find_elements_by_xpath('xpath')
'''
也可以通过css选择器、id、name来找:
就是原来是by_xpath
现在是by_id, by_name, by_css_selector
如:通过id来找就是
browser.find_element_by_id("这里写元素id")
'''
# 拿到节点对象后可以通过以下常用属性来取内容
'''
获取文本:
.text
获取标签名:
.tag_name
获取元素属性:
.get_attribute('属性字段')
'''
# 直接了当拿源代码:
print(f'源代码:\n{browser.page_source}')
另外还能控制页面滑动,点击,输入等等骚操作!
'''
获取到元素后:
输入文字用send_keys()
清空文字用clear()
点击按钮用click()
'''
browser.find_element_by_id("这里写元素id").click()
1.2.4 Selenium小结
学习资料:
Selenium: CSDN
1.3 代码爬虫小结
感兴趣的同学们可以自行了解:
请求网页:urllib,requests,aiohttp等等
解析网页:lxml,bs4,jsonpath等等
浏览器模拟:selenium等等
爬虫开发框架:scrapy等等
以及HTML和CSS基础相关内容
2. 爬虫工具软件的使用
难不成我要搞个数据集还得那么麻烦的写那么多代码???
一般不用,平时的需求使用爬虫工具软件无脑爬即可,上面的代码仅仅是为了让你了解爬虫的工作流程
现在我们开始介绍使用工具批量爬取网页数据,常用的工具有:八爪鱼采集器,后羿采集器等等
2.1 后羿采集器爬取网易新闻

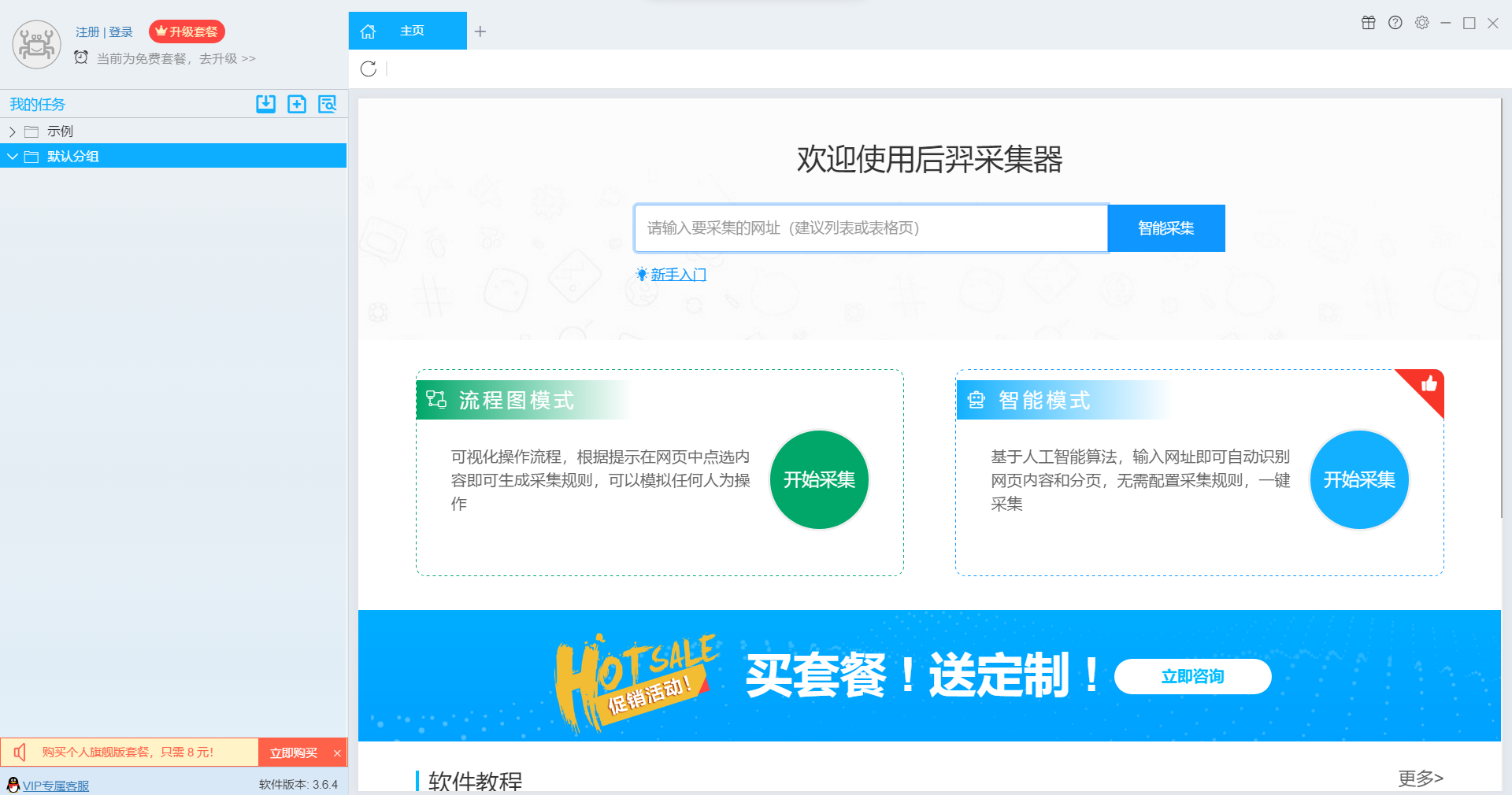
我们先来新建一个项目

我们输入待爬取网站的网址:https://news.163.com/

点击立即创建,等待网页打开

可以看到,一些内容已经被红线自动框选,且生成了相应的字段,如果没有特殊需求我们仅仅只需要改一下字段名即可

由下图可以看到,有一些网页中内容没有被红线框选,这说明此部分内容未被采集器选中
此时我们点击添加字段,拖动瞄准符号直到选中想要爬取的内容,之后给已经选中的字段重命名

涉及到“点进去爬取”,我们使用 深入采集 等待进入新页面后选中需要爬取的字段

一切就绪后,我们点击开始采集,设置相关参数后点击启动 开始爬取任务

等待爬取结束或主动停止后选择导出格式以导出数据
2.2 实战:爬取哔哩哔哩番剧信息
要求:爬取哔哩哔哩番剧页面番剧信息,至少爬取12个,保存至excel:‘bili爬取.xlsx’,上传至work文件夹
要求字段:
标题、标题链接、缩略图url、更新至、视频地址、详情标题、点赞、投币、评分
工具要求:
推荐:八爪鱼采集器、后羿采集器、代码
不推荐:一个一个数据手动CV
2.3 爬虫软件小结
可以看到爬虫软件简单易学,甚至可以创建一个爬虫项目并导出项目分享给其他小伙伴。让其他小伙伴导入后利用此项目爬取数据。
3. 数据处理与分析
# 爬取结束后的数据暂时存在了 `work` 目录,毕竟 `data` 目录的东西不能保存...
# 爬虫到此为止就告一段落了,现在我们开始处理数据
# 将爬取的内容放到data文件夹,提前在work放了一个,大家也可上传自己的,看代码时记得改相应字段名字即可
!cp ./work/bili爬取.xlsx ./data/bili爬取.xlsx
!echo 移动结束
移动结束
当我们从一个网页上爬取下所需的数据后,结果往往是不能保证的
例如:
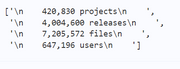 、
、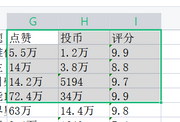
我们可以看到上图有一些爬取的数据附近有一些不需要的空白字符,或者是类似于“2千”、“2万”、“200”之类的数据需要手动处理转化为可以计算的数据类型
此时我们需要对数据进行一定的处理保证爬取的质量。
3.1 正则表达式
上面在爬取数据后我们尝试使用正则表达式来提取数据。由于网页结构复杂,在有解析库的帮助下我们不值得硬啃正则表达式
但是数据处理的时候,因为单一字段处理简单,正则表达式往往是我们的利器
3.1.1 正则表达式介绍
一种用特定符号(元字符)描述句子结构组成的表达式,python支持此表达式并封装在re正则表达式标准库中
3.1.2 元字符
| 元字符 | 描述 |
|---|---|
| . | 匹配任意字符,一般情况不匹配换行,除非特殊模式re.DOTALL |
| ^ | 匹配开头 |
| $ | 匹配结尾 |
| * | 匹配0-n次 |
| + | 匹配1-n次 |
| ? | 匹配0-1次,在*、?或+后面启动非贪婪匹配 |
| {n - m} | 匹配n-m次,默认n=0,m=∞,可在后面加?启动非贪婪,,或{n}匹配n次 |
| [ ] | 匹配里面的字符中的任意一个,例如[123.abc]将匹配123.abc中任意一个字符 |
| [^ ] | 匹配除里面的字符外的字符,放第一位才有意义,否则将会被当成普通字符对待 |
| \ | 转义字符 |
| a|b | 匹配a或b |
| ( ) | 分组匹配,起着数学中()的作用,如ab*匹配abbb (ab)*匹配abababab |
在正则表达式中,括号往往起着一个匹配取值的角色,人话就是:在匹配后取括号内匹配到的值
import re
res = re.match('abc(.)', 'abcd') # 括号里的值表示在匹配后取 . 所代替的值
print(res)
f'匹配到的结果:{res.groups()}'
<re.Match object; span=(0, 4), match='abcd'>
"匹配到的结果:('d',)"
3.1.3 书写规则举例
asd 匹配asd
asd+匹配as和{1,}个d
(asd)+匹配{1,}个asd
^asd以a开头,紧接着sd
另外(?aiLmsux)放于正则表达式开头表示匹配模式
如(?xs)就表示flags=re.X|re.S,这些在之后匹配模式会介绍
3.1.4 反斜杠转义
用一个转义来描述一堆符号以达到省力的效果,如:\d 来代替 [0-9]
| 转义符 | 含义 |
|---|---|
| \w | [0-9a-zA-Z_] |
| \W | [^0-9a-zA-Z_] |
| \d | [0-9] |
| \D | [^0-9] |
| \s | [ \t\n\r\f\v](即所有空白字符) |
| \S | [^a-zA-Z0-9_] |
| [\u4e00-\u9fa5] | 中文字符(不附带生僻字) |
| \b | 边界 |
| \B | 非边界 |
| \A | 在非多行模式等同于,多行模式为非多行的功能 |
| \Z | 只匹配字符串尾 |
| \1,\2… | 为第一组、第二组的匹配结果 |
特殊解释:
如:匹配"[0-9,.]" = “[\d,.]”,当然也可以这样"\d|,|."
\b 表示边界
单词被定义为一个字母数字字符序列,因此单词的结尾由空格或非字母数字字符表示
所以\bclass\b只能匹配到"class “而不能匹配到"asdclasscas”
如:“\b(\w+)\s\1\b” 等于 “\b(\w+)\s(前面(\w+)匹配到的字符)\b”
当然如果组有名字也可以:(?=组的名字)来代替记忆序号
如:r’\b(?P\w+)\s+(?P=word)\b’
import re
re.match(r'123(\d+)', '123456').groups() == \
re.match(r'123([0-9]+)', '123456').groups() == \
re.match(r'123(\d{1,})', '123456').groups()
True
3.1.5 常见匹配模式
匹配模式标志允许你修改正则表达式的工作方式。他们每一种模式在 re 模块中都有两个名字:全名和缩写
| 模式 | 解释 |
|---|---|
| ASCII, A | 使几个转义如 \w、\b、\s 和 \d 匹配仅与具有相应特征属性的 ASCII 字符匹配。而不匹配Unicode |
| DOTALL, S | 使 . 匹配任何字符,包括换行符 |
| IGNORECASE, I | 匹配忽略大小写 |
| MULTILINE, M | 多行匹配 |
使用方式:
re.compile(r'xxx', re.A) # 使用单个模式,只匹配ASCII码字符
re.compile(r'xxx', re.I|re.A|re.S) # 使用多个模式
import re
print(
'不忽略大小写的匹配:', re.match('asd', 'Asd'),
'\n',
'忽略大小写的匹配结果:', re.match('asd', 'Asd', re.I),
)
不忽略大小写的匹配: None
忽略大小写的匹配结果: <re.Match object; span=(0, 3), match='Asd'>
3.1.6 匹配结果的获取方法
| 方法 | 介绍 | 返回值 |
|---|---|---|
| group() | 0为返回所有组匹配在一个字符串中,用空格隔开,1为第一组,2为第二组…以此类推,也可以group(1,2,…)来返回一个元组 | |
| groups(default=None) | 直接groups()可以以元组的形式返回所有匹配的对象,没匹配上的默认为None | |
| groupdict(default=None) | 返回所有被命名的组(使用(?P<name>patten))的匹配的字典 |
# 例如:
import re
print(re.match('as(d..)', 'asd12').groups()) # 解析结果只返回括号括住的部分
print(re.match('as(?P<res>d..)', 'asd12').groupdict()) # 解析被命名的组,且返回字典
print(re.match('as(?P<res>d..)', 'asd12').groups()) # 也可以按原来的元组取值
('d12',)
{'res': 'd12'}
('d12',)
3.1.7 实战:按要求解析字符串
我们知道 markdown 是一个轻文本标记语言,最终会被渲染为HTML,那么尝试利用正则表达式来解析一部分markdown 语法吧!
补充知识:re.compile 的作用是创建一个正则模板,此模板可以反复使用,提升效率!
import re
# 例子:
img = re.compile(r'!\[(?P<alt>.*)\]\((?P<src>.*)\)')
res = img.match(
''
).groupdict()
print(f'<img src="{res.get("src")}" alt="{res.get("alt")}">')
<img src="https://ai-studio-static-online.cdn.bcebos.com/990592bff5ba4719807dea63564649f6b016c1c939df439dad8ef667ff060e13" alt="">
请根据上述示范完成 **加粗*\*、\*斜体\*等等语法效果!
import re
# 在此完成代码!
str_a = '**加粗使用<b>标签</b>**'
str_b = '*斜体使用<i>标签</i>*'
3.2 数据处理工具-Pandas
我们掌握了正则表达式这一更灵活的方式之后,我们就可以对单一数据进行处理,那么如果面对一列的数据怎么办?
for 循环处理是一个办法,我们使用更方便的:Pandas库
3.2.1 Pandas介绍
pandas是一个强大的基于numpy的分析结构化数据的开源工具库,提供了序列形式的 Series 对象和表格形式的 DataFrame 对象,可以方便的以csv,excel,json,sql等等数据格式读取与存放数据
!echo 安装与升级相关类库中...
!pip install -U numpy openpyxl pandas matplotlib seaborn missingno > /dev/null # 安装与升级相关类库
import pandas as pd
import matplotlib
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
# sns风格的图表清新脱俗
matplotlib.style.use('seaborn')
# 分页显示数据, 设置为 False 不允许分页
pd.set_option('display.expand_frame_repr', False)
# 最多显示的列数, 设置为 None 显示全部列
pd.set_option('display.max_columns', None)
# 最多显示的行数, 设置为 None 显示全部行
pd.set_option('display.max_rows', None)
# 设置字体,避免中文显示不能
matplotlib.rcParams['font.sans-serif'] = ["FZSongYi-Z13S", "Microsoft YaHei Light UI"]
# 解决保存图像是负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
!clear
!echo 相关类库安装与升级完成,避免输出太长,已截断!
安装与升级相关类库中...
[H[2J相关类库安装与升级完成,避免输出太长,已截断!
pd.Series([66, 34, 99]) # pandas的序列对象,可以想象为一行或一列
0 66
1 34
2 99
dtype: int64
df = pd.DataFrame([[20, 30, 40], [11, 22, 33]], index=['语文', '数学'], columns=['小红', '小明', '小蓝'])
df # pandas的表格对象
| 小红 | 小明 | 小蓝 | |
|---|---|---|---|
| 语文 | 20 | 30 | 40 |
| 数学 | 11 | 22 | 33 |
df.to_excel('test.xlsx') # 存到表里
df2 = pd.read_excel('test.xlsx', index_col=0) # 再读出来
df2
| 小红 | 小明 | 小蓝 | |
|---|---|---|---|
| 语文 | 20 | 30 | 40 |
| 数学 | 11 | 22 | 33 |
df2*2+233 # 方便的数据批处理运算
| 小红 | 小明 | 小蓝 | |
|---|---|---|---|
| 语文 | 273 | 293 | 313 |
| 数学 | 255 | 277 | 299 |
df2.loc['语文', ['小红', '小蓝']] # 索引与切片
小红 20
小蓝 40
Name: 语文, dtype: int64
对pandas的简单介绍到此为止
目前在./data/ 文件夹下已经上传了在哔哔哩哩番剧页面下爬取的12个动漫信息,接下来数据分析和清洗操作将针对该数据集进行
df = pd.read_excel('./data/bili爬取.xlsx')
# 可以看到 pandas 是代码界的 excel
df.head()
| 标题 | 标题链接 | 缩略图 | num | 视频地址 | 详情标题 | 点赞 | 投币 | 评分 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 银河英雄传说:全新命题 策谋 | https://www.bilibili.com/bangumi/play/ss43149?... | https://i0.hdslb.com/bfs/bangumi/image/a0cba7b... | 更新至\n 11话 | blob:https//www.bilibili.com/77c65089-33fe-419... | 银河英雄传说:全新命题 策谋 | 5.5万 | 1.2万 | 9.9 |
| 1 | 书虫公主 | https://www.bilibili.com/bangumi/play/ss43152?... | https://i0.hdslb.com/bfs/bangumi/image/9b8e1d8... | 更新至\n 10话 | blob:https//www.bilibili.com/16fb99dd-7ac7-4e8... | 书虫公主 | 14万 | 3.8万 | 8.8 |
| 2 | 世界末日柴犬为伴 | https://www.bilibili.com/bangumi/play/ss42199?... | https://i0.hdslb.com/bfs/bangumi/image/79a3995... | 更新至\n 58话 | blob:https//www.bilibili.com/21abe78a-f4ac-438... | 世界末日柴犬为伴 | 14.2万 | 5194 | 9.7 |
| 3 | 路人超能100 III(灵能百分百 第三季) | https://www.bilibili.com/bangumi/play/ss43141?... | https://i0.hdslb.com/bfs/bangumi/image/1d9e2ff... | 更新至\n 10话 | blob:https//www.bilibili.com/70a50b4e-0342-4e2... | 路人超能100 III(灵能百分百 第三季) | 72.4万 | 34万 | 9.9 |
| 4 | 奇幻世界舅舅 | https://www.bilibili.com/bangumi/play/ss42105?... | NaN | 更新至\n 7话 | blob:https//www.bilibili.com/28376625-58a8-4ed... | 奇幻世界舅舅 | 63万 | 14.4万 | 9.8 |
import missingno as msn
import warnings
# 由于字体缺失等等千奇百怪的原因,总会出现一大片 warnning 我们暂时取消掉
warnings.filterwarnings("ignore")
# 画缺失值图,查看缺失值
msn.matrix(df, labels=True)
<AxesSubplot:>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-62uW1xnp-1671684807450)(main_files/main_58_1.png)]
df.info() # 利用 pandas 查看缺失值,注意观察下表 `Non-Null Count`
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12 entries, 0 to 11
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 标题 12 non-null object
1 标题链接 12 non-null object
2 缩略图 4 non-null object
3 num 12 non-null object
4 视频地址 12 non-null object
5 详情标题 12 non-null object
6 点赞 12 non-null object
7 投币 12 non-null object
8 评分 12 non-null float64
dtypes: float64(1), object(8)
memory usage: 992.0+ bytes
at64
dtypes: float64(1), object(8)
memory usage: 992.0+ bytes
# 开始将点赞和投币转化为整型
import re
pattern = re.compile(r'([0-9]+(\.[0-9]+)?)万')
temp = list()
for i in df.loc[:, '点赞']:
num = pattern.match(i)
temp.append(float(num.groups()[0])*10_000 if num else i)
df.loc[:, '点赞'] = temp
df.loc[:, '点赞'] = df.loc[:, '点赞'].astype(np.int64, )
df.head(2)
| 标题 | 标题链接 | 缩略图 | num | 视频地址 | 详情标题 | 点赞 | 投币 | 评分 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 银河英雄传说:全新命题 策谋 | https://www.bilibili.com/bangumi/play/ss43149?... | https://i0.hdslb.com/bfs/bangumi/image/a0cba7b... | 更新至\n 11话 | blob:https//www.bilibili.com/77c65089-33fe-419... | 银河英雄传说:全新命题 策谋 | 55000 | 1.2万 | 9.9 |
| 1 | 书虫公主 | https://www.bilibili.com/bangumi/play/ss43152?... | https://i0.hdslb.com/bfs/bangumi/image/9b8e1d8... | 更新至\n 10话 | blob:https//www.bilibili.com/16fb99dd-7ac7-4e8... | 书虫公主 | 140000 | 3.8万 | 8.8 |
temp = list()
for i in df.loc[:, '投币']:
num = pattern.match(i)
temp.append(float(num.groups()[0])*10_000 if num else i)
df.loc[:, '投币'] = temp
df.loc[:, '投币'] = df.loc[:, '投币'].astype(np.int64,)
df.head(2)
| 标题 | 标题链接 | 缩略图 | num | 视频地址 | 详情标题 | 点赞 | 投币 | 评分 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 银河英雄传说:全新命题 策谋 | https://www.bilibili.com/bangumi/play/ss43149?... | https://i0.hdslb.com/bfs/bangumi/image/a0cba7b... | 更新至\n 11话 | blob:https//www.bilibili.com/77c65089-33fe-419... | 银河英雄传说:全新命题 策谋 | 55000 | 12000 | 9.9 |
| 1 | 书虫公主 | https://www.bilibili.com/bangumi/play/ss43152?... | https://i0.hdslb.com/bfs/bangumi/image/9b8e1d8... | 更新至\n 10话 | blob:https//www.bilibili.com/16fb99dd-7ac7-4e8... | 书虫公主 | 140000 | 38000 | 8.8 |
3.2.2 利用数据进行绘图
%matplotlib inline
df.loc[:, '投币率'] = df.loc[:, '投币'] / df.loc[:, '点赞']
plt.figure('tbl')
plt.title('投币率')
plt.xlabel = '番剧'
plt.ylabel = '投币率'
plt.bar(df.index, df.loc[:, '投币率'])
<BarContainer object of 12 artists>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r5gRGDmd-1671684807450)(main_files/main_63_1.png)]
感兴趣的同学可以自行学习:matplotlib,seaborn,plotly,dash,pyecharts等等绘图库
4. 数据保存
数据清洗完毕后就到了数据保存以备训练的环节了。保存的方式根据需求而定,常见有保存为/保存至:json,数据库,xlsx,csv,npy等等格式
除了利用pandas进行快捷保存外,大家也可以使用numpy、json、openpyxl、pymysql、以及一些ORM类库自定义保存数据
4.1 实战:将data中“bili爬取.xlsx”文件的数据读取后保存至任一数据库中
提示:除利用 pandas 外也可以自行利用数据库驱动或ORM来保存数据
import pandas as pd
df = pd.read_excel('...')
df.to_sql(...)
4.2 数据保存小结
没有最好的数据储存方式,之后最适合的数据储存方式。
在使用保存后的数据时常常会先将数据转化为适用于模型或框架的数据格式。
所以存数据的时候先存起来,之后用的时候在改成适合的格式。当然,一开始就有格式要求的任务除外!
5. 项目总结
本次项目向大家展示了一个爬虫项目的基本流程。代码爬虫重要的是寻找网页元素的位置特点和破解一些反爬手段。
但是使用诸如八爪鱼之类的工具的时候便完全不用担心此类问题。
教程中好多 未完成 的部分以及第三节开始的 pandas、matplotlib、sns、pyecharts部分将会在不久后优化上线!
第一版感谢
高同学 ,在我电脑宕机人也在隔离的基础上配合完成了最初版的编写(腾讯会议+我说她写QAQ,陪伴了11小时+,真的万分感谢!)
感谢飞桨导师:黄灿桦 炼丹师233的精心指导!
导师主页:https://aistudio.baidu.com/aistudio/personalcenter/thirdview/330406
项目作者:Lfan_ke 大家一起交朋友呀! 转载请注明出处!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 2
2 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)