
人脸识别实战:使用Python OpenCV 和深度学习进行人脸识别
在本教程中,您将学习如何使用 OpenCV、Python 和深度学习执行面部识别。我们将首先简要讨论基于深度学习的面部识别的工作原理,包括“深度度量学习”的概念。 从那里,我将帮助您安装实际执行人脸识别所需的库。 最后,我们将为静止图像和视频流实现人脸识别。
在本文中,将学习如何使用 OpenCV、Python 和深度学习执行面部识别。
首先简要讨论基于深度学习的面部识别的工作原理,包括“深度度量学习”的概念。 然后,我将帮助您安装实际执行人脸识别所需的库。 最后,我们将为静止图像和视频流实现人脸识别。
安装人脸识别库
为了使用 Python 和 OpenCV 执行人脸识别,我们需要安装两个额外的库:
安装 dlib
pip install dlib
或者你可以从源代码编译:
git clone https://github.com/davisking/dlib.git
cd dlib
mkdir build
cd build
cmake .. -DUSE_AVX_INSTRUCTIONS=1
cmake --build .
cd ..
python setup.py install --yes USE_AVX_INSTRUCTIONS
如果安装失败可以尝试:
pip install dlib-bin
效果一样,但是这样做只有能安装CPU版本,缺点就是慢。
安装支持 GPU 的 dlib(可选)
如果你有一个兼容 CUDA 的 GPU,你可以安装支持 GPU 的 dlib,使面部识别更快、更高效。 为此,我建议从源代码安装 dlib,因为您可以更好地控制构建:
$ git clone https://github.com/davisking/dlib.git
$ cd dlib
$ mkdir build
$ cd build
$ cmake .. -DDLIB_USE_CUDA=1 -DUSE_AVX_INSTRUCTIONS=1
$ cmake --build .
$ cd ..
$ python setup.py install --yes USE_AVX_INSTRUCTIONS --yes DLIB_USE_CUDA
建议用GPU版本,如果安装失败参考这篇文章:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/121470556?spm=1001.2014.3001.5501
安装 face_recognition 包
face_recognition 模块可以通过一个简单的 pip 命令安装:
pip install face_recognition
安装 imutils
您还需要我的便利功能包 imutils。 你可以通过 pip 将它安装在你的 Python 虚拟环境中:
pip install imutils
人脸识别数据集
数据集来源网络搜索,我选取了几名大家认识的人物,有Biden、chenglong、mayun、Trump、yangmi、zhaoliying等。每个人物放入3-4张图片,如下图:
获得此图像数据集,我们将:
- 为数据集中的每个人脸创建 128 维嵌入
- 使用这些嵌入来识别图像和视频流中人物的面部
制作数据集的方法:
人脸识别项目结构
myface
├── dataset
├─dataset
│ ├─Biden
│ ├─chenglong
│ ├─mayun
│ ├─Trump
│ ├─yangmi
│ └─zhaoliying
├── encode_faces.py
├── recognize_faces_image.py
├── recognize_faces_video.py
└── encodings.pickle
我们的项目有 4 个顶级目录:
- dataset/ :包含六个字符的面部图像,根据它们各自的名称组织到子目录中。 。
- output/ :这是您可以存储处理过的人脸识别视频的地方。 我要把我的一个留在文件夹里——原侏罗纪公园电影中的经典“午餐场景”。
- videos/ :输入视频应存储在此文件夹中。 该文件夹还包含“午餐场景”视频,但尚未经过我们的人脸识别系统。
我们在根目录下还有 6 个文件:
- encode_faces.py :人脸的编码(128 维向量)是用这个脚本构建的。
- identify_faces_image.py :识别单个图像中的人脸(基于数据集中的编码)。
- identify_faces_video.py :识别来自网络摄像头的实时视频流中的人脸并输出视频。
- encodings.pickle :面部识别编码通过 encode_faces.py 从您的数据集生成,然后序列化到磁盘。
创建图像数据集后(使用 search_bing_api.py ),我们将运行 encode_faces.py 来构建嵌入。 然后,我们将运行识别脚本来实际识别人脸。
使用 OpenCV 和深度学习对人脸进行编码
在识别图像和视频中的人脸之前,我们首先需要量化训练集中的人脸。 请记住,我们实际上并不是在这里训练网络——网络已经被训练为在大约 300 万张图像的数据集上创建 128 维嵌入。
当然可以从头开始训练网络,甚至可以微调现有模型的权重。一般情况。
使用预训练网络然后使用它为我们数据集中的 29张人脸中的每一张构建 128 维嵌入更容易。
然后,在分类过程中,我们可以使用一个简单的 k-NN 模型 + 投票来进行最终的人脸分类。 其他传统的机器学习模型也可以在这里使用。 要构建我们的人脸嵌入,
请新建 encode_faces.py:
# import the necessary packages
from imutils import paths
import face_recognition
import argparse
import pickle
import cv2
import os
dataset_path='dataset'
encodings_path='encodings.pickle'
detection_method='cnn'
# 获取数据集中输入图像的路径
print("[INFO] quantifying faces...")
imagePaths = list(paths.list_images(dataset_path))
# 初始化已知编码和已知名称的列表
knownEncodings = []
knownNames = []
# 遍历图像路径
for (i, imagePath) in enumerate(imagePaths):
# 从图片路径中提取人名
print("[INFO] processing image {}/{}".format(i + 1,
len(imagePaths)))
name = imagePath.split(os.path.sep)[-2]
# 加载输入图像并从 BGR 转换(OpenCV 排序)
# 到 dlib 排序(RGB)
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 检测边界框的 (x, y) 坐标
# 对应输入图像中的每个人脸
boxes = face_recognition.face_locations(rgb, model=detection_method)
# 计算人脸的嵌入
encodings = face_recognition.face_encodings(rgb, boxes)
# 遍历 encodings
for encoding in encodings:
# 将每个编码 + 名称添加到我们的已知名称集中
# 编码
knownEncodings.append(encoding)
knownNames.append(name)
导入包,定义全局变量
变量的含义:
- dataset_path:数据集的路径。
- encodings_path :我们的人脸编码被写入这个参数指向的文件路径。
- detection_method :在我们对图像中的人脸进行编码之前,我们首先需要检测它们。 或者两种人脸检测方法包括 hog 或 cnn 。
现在我们已经定义了我们的参数,让我们获取数据集中文件的路径(以及执行两个初始化):
输入数据集目录的路径来构建其中包含的所有图像路径的列表。
在循环之前分别初始化两个列表 knownEncodings 和 knownNames 。 这两个列表将包含数据集中每个人的面部编码和相应的姓名。
这个循环将循环 19次,对应于我们在数据集中的 19张人脸图像。
遍历每个图像的路径。从 imagePath中提取人名。 然后让我们加载图像,同时将 imagePath 传递给 cv2.imread。 OpenCV 使用BGR 颜色通道,但 dlib 实际上期望 RGB。 face_recognition 模块使用 dlib ,交换颜色空间。 接下来,让我们定位人脸并计算编码:
对于循环的每次迭代,我们将检测一张脸,查找/定位了她的面孔,从而生成了面孔框列表。 我们将两个参数传递给 face_recognition.face_locations 方法:
-
rgb :我们的 RGB 图像。
-
model:cnn 或 hog(该值包含在与“detection_method”键关联的命令行参数字典中)。 CNN方法更准确但速度更慢。 HOG 速度更快,但准确度较低。
然后,将面部的边界框转换为 128 个数字的列表。这称为将面部编码为向量,而 face_recognition.face_encodings 方法会处理它。 编码和名称附加到适当的列表(knownEncodings 和 knownNames)。然后,将继续对数据集中的所有 19张图像执行此操作。
# dump the facial encodings + names to disk
print("[INFO] serializing encodings...")
data = {"encodings": knownEncodings, "names": knownNames}
f = open(args["encodings"], "wb")
f.write(pickle.dumps(data))
f.close()
构造了一个带有两个键的字典—— “encodings” 和 “names” 。
将名称和编码转储到磁盘以备将来调用。运行encode_faces.py
D:\ProgramData\Anaconda3\python.exe D:/cv/myface/encode_faces.py
[INFO] quantifying faces...
[INFO] processing image 1/19
[INFO] processing image 2/19
[INFO] processing image 3/19
[INFO] processing image 4/19
[INFO] processing image 5/19
[INFO] processing image 6/19
[INFO] processing image 7/19
[INFO] processing image 8/19
[INFO] processing image 9/19
[INFO] processing image 10/19
[INFO] processing image 11/19
[INFO] processing image 12/19
[INFO] processing image 13/19
[INFO] processing image 14/19
[INFO] processing image 15/19
[INFO] processing image 16/19
[INFO] processing image 17/19
[INFO] processing image 18/19
[INFO] processing image 19/19
[INFO] serializing encodings...
Process finished with exit code 0
正如输出中看到的,我们现在有一个名为 encodings.pickle 的文件——该文件包含我们数据集中每个人脸的 128 维人脸嵌入。
识别图像中的人脸
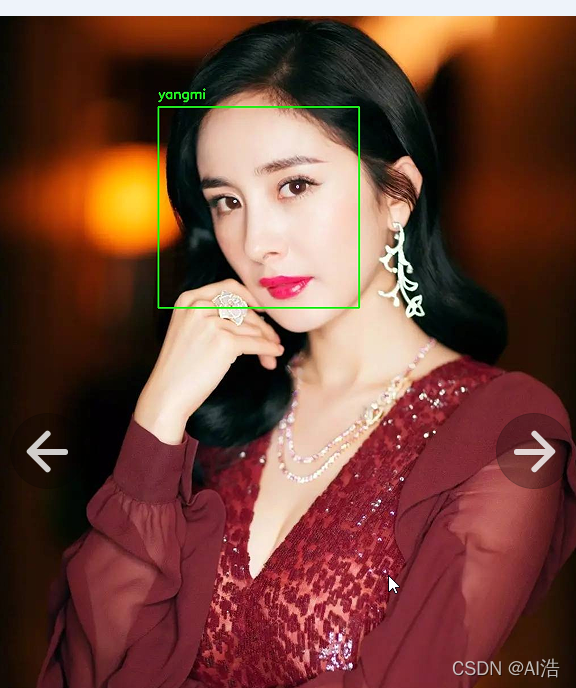
现在我们已经为数据集中的每个图像创建了 128 维人脸嵌入,现在我们可以使用 OpenCV、Python 和深度学习来识别图像中的人脸。 打开recognize_faces_image.py 并插入以下代码:
import face_recognition
import pickle
import cv2
encodings_path='encodings.pickle'
image_path='11.jpg'
detection_method='cnn'
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(encodings_path, "rb").read())
# 加载输入图像并将其从 BGR 转换为 RGB
image = cv2.imread(image_path)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 检测输入图像中每个人脸对应的边界框的 (x, y) 坐标,然后计算每个人脸的面部嵌入
print("[INFO] recognizing faces...")
boxes = face_recognition.face_locations(rgb,model=detection_method)
encodings = face_recognition.face_encodings(rgb, boxes)
# 初始化检测到的每个人脸的名字列表
names = []
# 循环面部嵌入
for encoding in encodings:
# 尝试将输入图像中的每个人脸与我们已知的编码相匹配
matches = face_recognition.compare_faces(data["encodings"],encoding)
name = "Unknown"
# 检查是否有匹配的
if True in matches:
# 找到所有匹配人脸的索引,然后初始化一个字典来计算每个人脸被匹配的总次数
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# 遍历匹配的索引并为每个识别出的人脸维护一个计数
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# 确定获得最多票数的识别人脸(注意:如果出现不太可能的平局,Python 将选择字典中的第一个条目)
name = max(counts, key=counts.get)
# 更新names
names.append(name)
# 遍历识别的人脸
for ((top, right, bottom, left), name) in zip(boxes, names):
# 在图像上绘制预测的人脸名称
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(image, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
解析三个参数:
encodings_path:包含我们的面部编码的pickle文件的路径。
image_path:这是正在进行面部识别的图像。
detection-method :你现在应该很熟悉这个了——根据你系统的能力,我们要么使用 hog 方法,要么使用 cnn 方法。 为了速度,选择 hog ,为了准确,选择 cnn 。
然后,让我们加载预先计算的编码 + 人脸名称,然后为输入图像构建 128 维人脸编码。
加载编码和人脸名称。
加载输入图像并将其转换为 rgb 颜色通道排序。
继续检测输入图像中的所有人脸,并计算它们的 128 维编码。
为检测到的每个人脸初始化names列表。
接下来,让我们遍历面部编码:
开始遍历从输入图像计算出的人脸编码。 尝试使用 face_recognition.compare_faces将输入图像(编码)中的每个人脸与我们已知的编码数据集进行匹配。
此函数返回 True / False 值列表,数据集中的每个图像对应一个值。
在内部,compare_faces 函数正在计算候选嵌入与我们数据集中所有人脸之间的欧几里德距离:
- 如果距离低于某个容差(容差越小,我们的面部识别系统就会越严格),那么我们返回 True ,表示面部匹配。
- 否则,如果距离高于容差阈值,我们将返回 False,因为人脸不匹配。
本质上利用 k-NN 模型进行分类。 name 变量最终将保存此人的姓名字符串——现在,我们将其保留为“Unknown”,以防没有“投票”。
计算每个名字的“投票”数,统计投票数,并选择对应票数最多的人的名字。
如果匹配中有任何 True 投票,确定这些 True 值在匹配中的位置的索引。
然后初始化一个名为 counts 的字典,它将以字符名称作为键,将投票数作为值。然后循环匹配的Idxs并设置与每个名称关联的值,同时根据需要在 counts 中增加它。继续并遍历每个人的边界框和标记名称,并将它们绘制在输出图像上以进行可视化:
cv2.imshow("Image", image)
cv2.imwrite("001.jpg",image)
cv2.waitKey(0)
展示图片
保存图片。
运行recognize_faces_image.py 脚本:

识别视频中的人脸

现在我们已经将人脸识别应用于图像,让我们也将人脸识别应用于视频。
新建 identify_faces_video.py 并插入以下代码:
import imutils
import pickle
import time
import cv2
# construct the argument parser and parse the arguments
encodings_path='encodings.pickle'
output='output.mp4'
display_type=0
detection_method='cnn'
导入包,然后定义全局变量
output : 输出视频的路径。
display_type :指示脚本在屏幕上显示框架的标志。 值为 1 时显示,值为 0 时不会将输出帧显示到我们的屏幕上。
加载我们的编码并启动我们的 cv2.VideoCapture:
# load the known faces and embeddings
print("[INFO] loading encodings...")
data = pickle.loads(open(encodings_path, "rb").read())
# 初始化视频流和输出视频文件的指针,然后让相机传感器预热
print("[INFO] starting video stream...")
#vs = VideoStream(src=0).start()
vs=cv2.VideoCapture('1.MP4')
writer = None
time.sleep(2.0)
# loop over frames from the video file stream
while True:
# grab the frame from the threaded video stream
ret,frame = vs.read()
if not ret:
print("Can't receive frame (stream end?). Exiting ...")
break
# 将输入帧从 BGR 转换为 RGB,然后将其调整为 750 像素的宽度(以加快处理速度)
rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
rgb = imutils.resize(frame, width=750)
r = frame.shape[1] / float(rgb.shape[1])
# 检测输入帧中每个人脸对应的边界框的 (x, y) 坐标,然后计算每个人脸的人脸嵌入
boxes = face_recognition.face_locations(rgb,
model=detection_method)
encodings = face_recognition.face_encodings(rgb, boxes)
names = []
# 循环面部嵌入
for encoding in encodings:
# 尝试将输入图像中的每个人脸与我们已知的编码相匹配
matches = face_recognition.compare_faces(data["encodings"],
encoding)
name = "Unknown"
# 检查我们是否找到了匹配项
if True in matches:
# 找到所有匹配人脸的索引,然后初始化一个字典来计算每个人脸被匹配的总次数
matchedIdxs = [i for (i, b) in enumerate(matches) if b]
counts = {}
# 遍历匹配的索引并为每个识别出的人脸维护一个计数
for i in matchedIdxs:
name = data["names"][i]
counts[name] = counts.get(name, 0) + 1
# 确定获得最多票数的识别人脸(注意:如果出现不太可能的平局,Python 将选择字典中的第一个条目)
name = max(counts, key=counts.get)
# 更新names
names.append(name)
# 遍历识别的人脸
for ((top, right, bottom, left), name) in zip(boxes, names):
# 重新调整人脸坐标
top = int(top * r)
right = int(right * r)
bottom = int(bottom * r)
left = int(left * r)
# 在图像上绘制预测的人脸名称
cv2.rectangle(frame, (left, top), (right, bottom),
(0, 255, 0), 2)
y = top - 15 if top - 15 > 15 else top + 15
cv2.putText(frame, name, (left, y), cv2.FONT_HERSHEY_SIMPLEX,
0.75, (0, 255, 0), 2)
if writer is None and output is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(output, fourcc, 20,
(frame.shape[1], frame.shape[0]), True)
# 如果 writer 不是 None,则将识别出人脸的帧写入磁盘
if writer is not None:
writer.write(frame)
# 检查我们是否应该将输出帧显示到屏幕上
if display_type > 0:
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the `q` key was pressed, break from the loop
if key == ord("q"):
break
在这里我用视频代替摄像头。
第一步是从视频流中抓取一帧。 上述代码块与前一个脚本中的行几乎相同,不同之处在于这是一个视频帧而不是静态图像。
接下来,让我们遍历与我们刚刚找到的人脸相关的人脸编码。
在循环中,遍历每个编码并尝试匹配人脸。 如果找到匹配项,计算数据集中每个名字的投票数。 然后提取最高票数,即与人脸相关的名称。
然后,遍历识别出的人脸并继续在人脸周围绘制一个框,并在人脸上方显示人的姓名。
如果设置了 display 命令行参数,显示框架并检查是否按下了退出键(“q”),此时我们将跳出 循环。 最后,让我们履行我们的家政职责:
# do a bit of cleanup
cv2.destroyAllWindows()
#vs.stop()
vs.release()
# check to see if the video writer point needs to be released
if writer is not None:
writer.release()
清理并释放显示、视频流和视频编写器。
运行recognize_faces_video.py脚本查看识别效果
视频文件识别结果

完整的代码和数据集:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/46802864

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 79
79 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)