
七步理解深度学习
七步理解深度学习By Matthew Mayo 翻译by Andrewseu深度学习是机器学习的一个分支,拥有很多的相似性,但是却也不同,深度神经网络结构在自然语言处理、计算机视觉、生物信息学和其他领域解决了各种各样的问题。
七步理解深度学习
By Matthew Mayo 翻译by Andrewseu
网上有很多的深度学习的免费学习资源,但是可能会对从哪里开始有些困惑。七步内从对深度神经网络的模糊理解到知识渊博的从业者(knowledgeable practitioner)!
深度学习是机器学习的一个分支,拥有很多的相似性,但是却也不同,深度神经网络结构在自然语言处理、计算机视觉、生物信息学和其他领域解决了各种各样的问题。深度学习经历了一场巨大的最近研究的重现,并且在很多领域中已经展现出最先进的成果。
本质上,深度学习是超过一层隐藏神经元的神经网络的执行。但是,这是对深度学习的一个简单的看法,并且不是一个没有争议的观点。这些深层构架也非常不同,对不同任务或目标优化会有不同的执行。在这样一个恒定速率进行着的大量研究在以史上未有的速度展现新的和创新的深度学习模型。
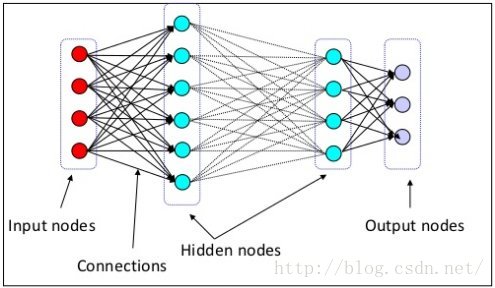
最近的一个白热化的研究课题,深度学习似乎影响着机器学习的所有领域,相关的还有数据科学。粗略看看相关arXiv目录下最近的论文,很容易看出大量正在被发表的论文都是深度学习相关的。鉴于已经产生的令人惊叹的成果,很多研究者,从业者和外行都在想深度学习是否是真正的人工智能的边界。
这系列的阅读材料和教程旨在给深度神经网络的新人提供一条路径去理解这个巨大而复杂的课题。尽管我不假设对神经网络和深度学习真正的理解,但是我假设你对一般的机器学习理论和实践具有某种程度的熟悉度。为了克服在一般机器学习理论和实践的不足,你可以看看最近KDnuggets发布的7 Steps to Mastering Machine Learning With Python。由于我们也看用Python写的例子的执行,对语言有些熟悉会很有用。介绍和综述的资源在previodsly mentioned post也是提供的。
这篇博客将以紧密结合的顺序使用网络上免费提供的材料在理论层面上获得对深度神经网络的一些理解,然后继续转向一些实际的执行。同样的,借鉴过来的引用材料只属于创建者,跟资源会一起被标注。如果你看到有人因为他们的工作没有被正确引用,请告知我,我会很快修改的。
一个完全诚实的免责申明:深度学习是一个复杂而在广度和深度(pun unintended?)变化很快的领域,因此这篇博客不保证包括所有成为深度学习专家的手册;这样的一个转化将会需要更多的时间,很多附加材料和很多实际建立和测试的模型。但是,我相信的是,使用这里的资源可以帮你在这样一个路径下开始。
第一步:介绍深度学习
如果你正在读这个并且对这个课题感兴趣,你可能已经对深度神经网络已经熟悉,甚至在一个很基础的层次。神经网络有一个故事性的历史,但是我们将不会深入。但是,我们需要如果在开始就有一个普遍高层次的理解。
首先,看看DeepLearning .tv精彩的介绍视频。在 写完这个的时候已经有14个视频了;如果你喜欢看完他们,但是一定要看前五个,包含了神经网络的基础和一些更常见的结构。
然后,仔细阅读Geoff Hinton,Yoshua Bengioh和Yann LeCun的NIPS 2015 Deep Learning Tutorial,一个稍微更低层次的介绍。
完成我们的第一步,读the first chapter of Neural Networks and Deep Learning,这个由Michael Nielden写的精妙的,不断更新的在线书,这会更近一步但是依然很粗浅。
第二步:学习技术
深度神经网络依赖代数和微积分的数学基础。然而这篇博客不会产生任何理论上的数学,在继续之前有一些理解将会很有帮助。
第一,看Andrew Ng的linear algebra review videos。但是不是绝对的必要,想要对线性代数了解更深的话,从Ng的斯坦福课程看看Zico Kolter 和Chuong Do写的Linear Algebra Review and Reference.
然后看看Professor Leonard的Introduction to the Derivative of a Function. 视频是很简洁的,例子是很清晰的,并且提供了从数学的视角来看在反向传播的过程中到底发生了什么。一会儿会更多。
接下来迅速浏览下维基Sigmoid function的词条,一个在神经网络中经常通过单个神经元应用的边界差分函数。
最后,从数学上休息下阅读谷歌研究科学家 Quoc Le的Deep Learning Tutorial.
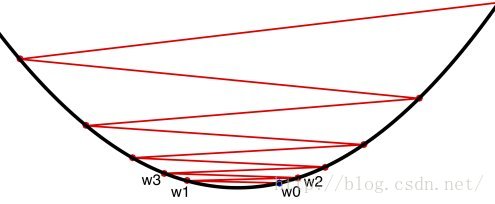
第三步:反向传播和梯度下降
神经网络包括现代深度构架重要的一部分是反向传播算法的错误,使用离输入更近的神经元通过网络更新权重。非常坦率的说,这就是神经网络继承他们”力量“(缺乏更好的术语)的地方。反向传播和一个随后分布式的最小化权重的优化方法,为了最小化损失函数。在深度学习中一个常见的优化方法是梯度下降。
首先,看看这些斯图加特大学Marc Toussaint 写的关于梯度下降的介绍笔记。
然后,看看Matt Mazur写的this step by step example of backpropagation in action.
继续,阅读Jeremy Kun关于 coding backpropagation in Python的信息博客。仔细看看完整代码也是建议的,尝试自己写一遍代码。
最后,读Quoc Le写的Deep Learning Tutorial的第二部分,为了获取一些更具体更常见的深度结构和他们用途的介绍。
第四步:实践
具体的神经网络结构的下一步介绍将会使用在现在研究中最流行的python深度学习库包括实际执行。在一些情况下,一些不同的库的优化是为了某个特定的神经网络结构,并且已经在某些特定的领域立足,我们将会使用三个不同的深度学习库。这不是多余的,在特定领域的实践中与最新的库保持一致时学习时很重要的一步。接下来的训练也将会让你自己评价不同的库,并且形成一个在哪些问题上用哪个的直觉。
现在欢迎你选择一个库或者联合库进行安装,是否继续那些教程取决于你的选择。如果你希望尝试一个库并且使用它来执行接下来步骤的教程,我会推荐TensorFlow,原因如下,我会提到最相关的(至少是在我的眼中):它执行自动分化(autodifferentiation),意味着你不需要担心从头执行反向传播,更可能使代码更容易理解(尤其是对一个初学者来说)。
我写关于TensorFlow的文章是在刚出来的时候TensorFlow Disappoints – Google Deep Learning Falls Shallow,这个标题暗示着比在实际中更失望;我最初关注的是它缺少GPU集丛的网络训练(很可能很快会有它自己的方式).无论如何,如果你没有看列在下面的白皮书但是想看更多关于TensotFlow的材料,我建议读我原始的文章,然后跟着Zachary Lipton's 写的很好的部分,TensorFlow is Terrific – A Sober Take on Deep Learning Acceleration.
TensorFlow
Google的TensorFlow是基于数据流图展现的一个通用的机器i学习库。
- Keras---一个用于Theano和TensorFlow高层、极简Python神经网络库
- Lasagne---Theano顶上的轻量级python库
- Torch---Lua机器学习算法库
- DeepLearning4j---Jaav和Scala开源、分布式深度学习库
- Chainer---一个灵活的、直观的python神经网络库
- Mocha---Juliade的一个深度学习框架
第五步:卷积神经网络和计算机视觉
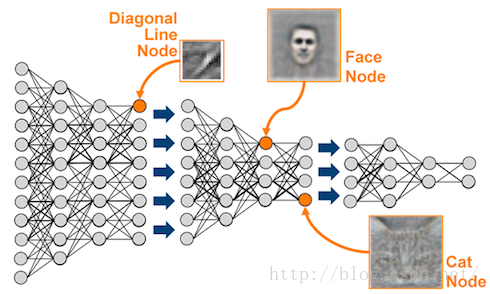
第六步:递归网和语言处理
第七步:更深入的课题

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)