
基于PaddleTS的土壤湿度预测
1.项目简介
属于机器学习范畴,根据多特征数据集(包含土壤不同深度的湿度逐年变化、降水天数逐年变化、土壤降雨量逐年变化等因素)搭建合适的网络模型对未来几年10cm土壤湿度进行预测。
本项目使用paddlets构建集成学习模型对10cm土壤湿度进行回归预测,主要包括数据处理、数据预处理、模型构建、模型训练、模型预测、可视化结果等过程。
PaddleTS是一个易用的深度时序建模的Python库,它基于飞桨深度学习框架PaddlePaddle,专注业界领先的深度模型,旨在为领域专家和行业用户提供可扩展的时序建模能力和便捷易用的用户体验。PaddleTS的主要特性包括:
设计统一数据结构,实现对多样化时序数据的表达,支持单目标与多目标变量,支持多类型协变量
封装基础模型功能,如数据加载、回调设置、损失函数、训练过程控制等公共方法,帮助开发者在新模型开发过程中专注于网络结构本身
内置业界领先的深度学习模型,例如NBEATS、NHiTS、LSTNet、TCN、Transformer 等
内置经典数据转换算子,支持数据处理与转换,包括缺失值填充、异常值处理、归一化、时间相关的协变量提取等
内置时序数据分析算子,帮助开发者便捷实现数据探索,包括数据统计量信息及数据摘要等功能
支持自动超参寻优,自动、高效满足效果调优需求
在本项目中,我们就通过一个典型示例,介绍如何在实际场景应用PaddleTS。
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
2 .数据集介绍
数据集统计了某草原从2012年1月-2022年3月的土壤数据,包括10cm湿度(kg/m2),40cm湿度(kg/m2),100cm湿度(kg/m2) ,土壤蒸发量(W/m2),降水天数字段等等。需要对数据集按照时间顺序进行排序处理方可进行时间序列预测。
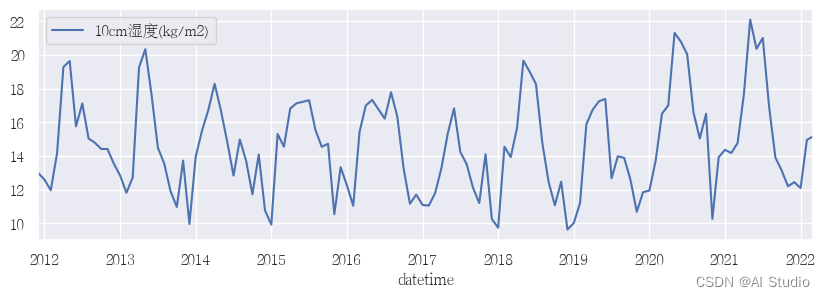
经过初步分析随着时间变化,土壤湿度同样呈现规律性变化
数据集中的样本是乱序的,需要自己按照时间顺序进行排序处理
数据集所包含字段以及该字段的数据类型如下所示:
筛选合适的字段进行预测即可
重点需要根据10cm湿度进行预测
2.1数据的读取
import pandas as pd
df=pd.read_excel(r"/home/aistudio/data/data179898/soil_humidity.xlsx")
3.数据处理
df.head()
| 10cm湿度(kg/m2) | 40cm湿度(kg/m2) | 100cm湿度(kg/m2) | 200cm湿度(kg/m2) | datetime | 土壤蒸发量(W/m2) | 土壤蒸发量(mm) | month | year | 经度(lon) | 纬度(lat) | 植被指数(NDVI) | 降水量(mm) | 最大单日降水量(mm) | 降水天数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 15.17 | 50.40 | 82.44 | 165.92 | 2022-03-31 | 1.050 | 1.13 | 4 | 2022 | 115.375 | 44.125 | 0.191 | 4.57 | 2.54 | 6 |
| 2 | 14.96 | 52.13 | 93.44 | 164.48 | 2022-02-28 | 0.665 | 0.70 | 3 | 2022 | 115.375 | 44.125 | 0.187 | 115.57 | 50.04 | 9 |
| 1 | 12.10 | 52.14 | 93.45 | 164.48 | 2022-01-31 | 0.280 | 0.27 | 2 | 2022 | 115.375 | 44.125 | 0.010 | 796.04 | 70.10 | 21 |
| 0 | 12.45 | 52.14 | 93.45 | 164.48 | 2021-12-31 | 0.410 | 0.44 | 1 | 2022 | 115.375 | 44.125 | 0.010 | 607.31 | 39.88 | 29 |
| 15 | 12.21 | 33.85 | 47.07 | 166.70 | 2021-11-30 | 0.330 | 0.36 | 12 | 2021 | 115.375 | 44.125 | 0.026 | 4.06 | 2.79 | 3 |
需要把一些object或者是字符、整型等某列进行转换为pandas可识别的datetime时间类型数据,方便时间的运算等操作。
pandas.to_datetime函数可以将一个标量,数组,Series或者是DataFrame/字典类型的数据转换为pandas中datetime类型的时间类型数据。
df['day']=1
df['datetime']=pd.to_datetime(df[['year', 'month','day']])
del df['day']
观察数据发现2012-12-1的数据缺失,不能构成时间序列
将2012-11-1的数据复制到12月,并按照时间早晚的方式排序,方便后续进行处理预测等
df=df.append(df.iloc[122],ignore_index=True)
df.iloc[123,4]='2012-12-1'
df['datetime']=pd.to_datetime(df['datetime'])
df['datetime'] = df['datetime'] - datetime.timedelta(1)
df = df.sort_values(by='datetime', ascending=False)
相关性分析
from pylab import mpl
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'/usr/share/fonts/fangzheng/FZSYJW.TTF',size=12)
sns.set(font=myfont.get_name())
corr = df.corr()
# 调用热力图绘制相关性关系
plt.figure(figsize=(10,10),dpi=100)
sns.heatmap(corr, square=True, linewidths=0.1, annot=True)
<AxesSubplot:>
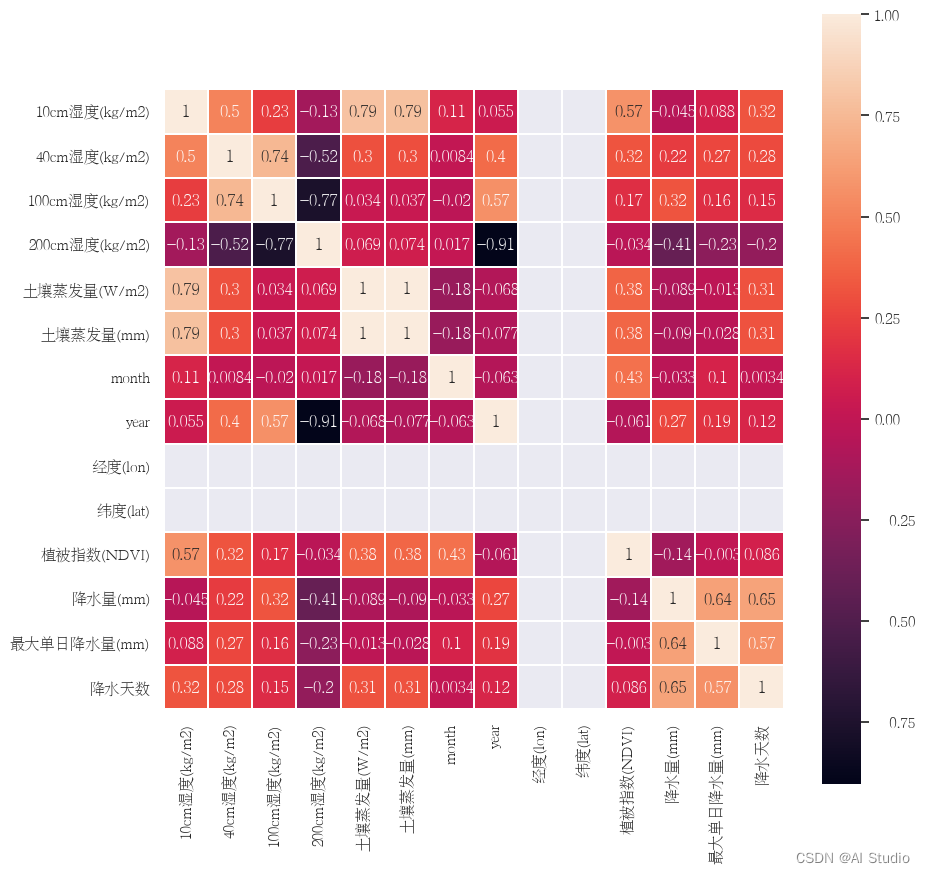
观察数据的分布情况
ax = plt.figure(figsize=(24,35))
for i in range(len(df.columns[:-1])):
ax.add_subplot(5,5,i+1)
sns.kdeplot(df.iloc[:,i],shade=True)
plt.title(df.columns[i])
plt.tight_layout();
画图个特征的折线图,查看其时序期况
observed_cov_cols=[
'40cm湿度(kg/m2)',
'100cm湿度(kg/m2)',
'200cm湿度(kg/m2)',
'土壤蒸发量(W/m2)',
'土壤蒸发量(mm)',
'month',
'经度(lon)',
'纬度(lat)',
'植被指数(NDVI)',
'降水量(mm)',
'最大单日降水量(mm)',
'降水天数']
ax = plt.figure(figsize=(24,35))
for i in range(len(observed_cov_cols)):
ax.add_subplot(5,5,i+1)
df[observed_cov_cols[i]].plot()
plt.title(i)
.plot()
plt.title(i)
plt.tight_layout();
4.数据集的构建
TSDataset 是 PaddleTS 中最主要的类之一,其被设计用来表示绝大多数时序样本数据。通常,时序数据可以分为以下几种:
单变量数据,只包含单列的预测目标,同时可以包涵单列或者多列协变量
多变量数据,包涵多列预测目标,同时可以包涵单列或者多列协变量
TSDataset 需要包含time_index属性,time_index支持 pandas.DatetimeIndex 和 pandas.RangeIndex 两种类型。
from paddlets.datasets import TSDataset
# 构建数据集
dataset = TSDataset.load_from_dataframe(
df, # pd.DataFrame
time_col="datetime", # 索引
observed_cov_cols=[
'40cm湿度(kg/m2)',
'100cm湿度(kg/m2)',
'200cm湿度(kg/m2)',
'土壤蒸发量(W/m2)',
'土壤蒸发量(mm)',
'month',
'经度(lon)',
'纬度(lat)',
'植被指数(NDVI)',
'降水量(mm)',
'最大单日降水量(mm)',
'降水天数'],
target_cols='10cm湿度(kg/m2)', # 需要预测的结果
freq='M'
)
# 数据统计与展示
dataset.plot()
dataset.summary()
| 10cm湿度(kg/m2) | 40cm湿度(kg/m2) | 100cm湿度(kg/m2) | 200cm湿度(kg/m2) | 土壤蒸发量(W/m2) | 土壤蒸发量(mm) | month | 经度(lon) | 纬度(lat) | 植被指数(NDVI) | 降水量(mm) | 最大单日降水量(mm) | 降水天数 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| missing | 0.000000 | 0.000000 | 0.000000 | 0.00000 | 0.000000 | 0.000000 | 0.000000 | 0.000 | 0.000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| count | 124.000000 | 124.000000 | 124.000000 | 124.00000 | 124.000000 | 124.000000 | 124.000000 | 124.000 | 124.000 | 124.000000 | 124.000000 | 124.000000 | 124.000000 |
| mean | 14.612298 | 42.334516 | 55.348387 | 167.22750 | 9.142863 | 9.594960 | 6.362903 | 115.375 | 44.125 | 0.239315 | 65.218831 | 17.360081 | 9.709677 |
| std | 2.849156 | 7.417712 | 14.477104 | 0.97781 | 9.133971 | 9.530454 | 3.476599 | 0.000 | 0.000 | 0.146182 | 115.034612 | 19.718646 | 5.479858 |
| min | 9.640000 | 29.710000 | 42.360000 | 164.48000 | 0.280000 | 0.270000 | 1.000000 | 115.375 | 44.125 | -0.017000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 12.465000 | 35.227500 | 44.732500 | 166.79750 | 1.122500 | 1.197500 | 3.000000 | 115.375 | 44.125 | 0.176000 | 6.100000 | 3.810000 | 6.000000 |
| 50% | 14.395000 | 42.710000 | 48.605000 | 167.37000 | 6.260000 | 6.690000 | 6.000000 | 115.375 | 44.125 | 0.205000 | 29.975000 | 10.225000 | 9.000000 |
| 75% | 16.735000 | 46.760000 | 60.815000 | 167.89000 | 14.735000 | 15.783750 | 9.000000 | 115.375 | 44.125 | 0.325000 | 63.817500 | 21.020000 | 13.000000 |
| max | 22.100000 | 61.700000 | 93.450000 | 168.56000 | 37.170000 | 39.260000 | 12.000000 | 115.375 | 44.125 | 0.605000 | 796.040000 | 89.920000 | 29.000000 |
划分数据集
按照0.8:0.2的比例划分训练集与测试集数据
并对划分后的数据集进行可视化
# 划分训练集和验证集
train_dataset, val_test_dataset = dataset.split(0.8) # 8:2
val_dataset, test_dataset = val_test_dataset.split(0.5)
# train_dataset.plot(add_data=[val_dataset,test_dataset], labels=['Val', 'Test'])
# transform
from paddlets.transform import StandardScaler
from paddlets.transform import MinMaxScaler
#scaler = MinMaxScaler()
scaler = StandardScaler()#数据归一化
scaler.fit(train_dataset)
ts_train_scaled = scaler.transform(train_dataset)
ts_val_scaled = scaler.transform(val_dataset)
ts_test_scaled = scaler.transform(test_dataset)
ts_val_test_scaled = scaler.transform(val_test_dataset)
ts_train_scaled.plot(add_data=[ts_val_scaled,ts_test_scaled], labels=['val_sacled', 'test_scaled'])
<AxesSubplot:xlabel='datetime'>

标准化的接口。 这些在 PaddleBaseModel 中声明的 fit、predict 标准化接口接收、返回统一的 TSDataset 数据集,作为其输入输出,以便将一些数据集处理和样本构建的复杂细节封装起来,简化API的使用,降低学习成本。
PaddleTS 设计了 PaddleBaseModelImpl 类,该类包含一组覆盖整个建模生命周期的通用函数与组件(如 准备样本,初始化模型性能指标, 计算损失等)。这使得用户可以更关注深度网络架构本身,同时也为广大开发者基于PaddleTS构建新的时序模型提供了最大程度的便利。
开箱即用的模型。PaddleTS提供一组预定义的,开箱即用的时序深度学习模型:
paddlets.models.forecasting选取了三个模型
5.集成模型的构建
集成模型是用集成学习的思想去把多个PaddleTS的预测器集合成一个预测器。目前PaddleTS支持两种集成预测器StackingEnsembleForecaster 和 WeightingEnsembleForecaster
步骤包括:
1.准备数据
2.准备模型
3.组装和拟合模型
4.进行回测
5.模型保存与加载
接下来,我们用集成模型来预测10cm土壤湿度。首先是准备集成预测器需要的底层模型,这里我们选择RNN,LSTM和MLP
from paddlets.models.forecasting import MLPRegressor
from paddlets.models.forecasting import LSTNetRegressor
from paddlets.models.forecasting import RNNBlockRegressor
lstm_params = {
'sampling_stride':1,
'eval_metrics':["mse", "mae"],
'batch_size': 32,
'max_epochs': 50,
'patience': 100
}
rnn_params = {
'sampling_stride': 1,
'eval_metrics': ["mse", "mae"],
'batch_size': 32,
'max_epochs': 50,
'patience': 100,
}
mlp_params = {
'sampling_stride': 1,
'eval_metrics': ["mse", "mae"],
'batch_size': 32,
'max_epochs': 50,
'patience': 100,
'use_bn': True,
}
指定一个序列的12个连续数据为1个卷积窗,进行集成预测,得出的值需要与该序列的第13个数据进行比较,从而计算损失。
模型训练,这里使用默认参数,没有进行调参,要调参可以参考https://paddlets.readthedocs.io/zh_CN/latest/index.html
集成方式的选择(集成方式有多种)
组装和拟合模型,WeightingEnsembleForecaster 或者 StackingEnsembleForecaster.
这里使用默认集成
#开始模型训练
from paddlets.ensemble import WeightingEnsembleForecaster
from sklearn.linear_model import Ridge
#get mode list
WeightingEnsembleForecaster.get_support_modes()
#Supported ensemble modes:['mean', 'min', 'max', 'median']
'''为了保持模型预测的一致性, in_chunk_len, out_chunk_len, skip_chunk_len, 这三个参数已经被提取到集成模型中,在组装模型时统一设定。'''
#select mode
reg = WeightingEnsembleForecaster(
in_chunk_len=12,
out_chunk_len=1,
skip_chunk_len=0,
estimators=[(LSTNetRegressor, lstm_params),(RNNBlockRegressor, rnn_params), (MLPRegressor, mlp_params)],
mode = "max")
reg.fit(ts_train_scaled, ts_val_scaled)
6.模型预测
模型回测
from paddlets.utils import backtest
from paddlets.metrics import MAE
mae, ts_pred = backtest(data=ts_val_test_scaled ,
model=reg,
# start="2022-03-01 00:00:00", # the point after "start" as the first point
metric=MAE(),
# predict_window=24,
# stride=24,
return_predicts=True
)
print(mae)
print(ts_pred)
ts_pred
7.预测结果反归一化
因为我们之前将训练集数据进行了归一化处理
在我们使用训练好的模型进行预测时,输出的结果同样为归一化后的结果
要想得到原来的值,需要进行反归一化(逆归一化)处理
true=scaler.inverse_transform(ts_pred)
预测结果可视化
我们将原始数据与预测结果放在一张图中进行可视化显示
从而观察预测后的结果
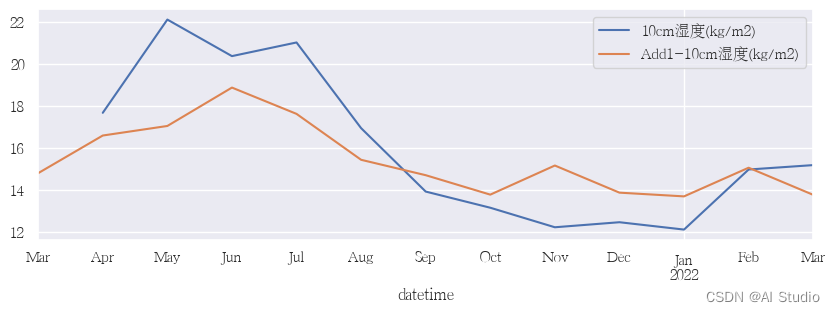
test_dataset.plot(add_data=true)
<AxesSubplot:xlabel='datetime'>
8.总结
本项目使用PaddleTS中LSTNet模型进行了完整预测流程,训练后的模型达到了较为不错的效果。
由于本数据集样本量有限,今后可以选择在样本更充分的数据集进行实验。
今后可以尝试手搭网络实现LSTM神经网络预测
- 再一次感谢项目导师张宏理的指导
- 本项目成员来自五邑大学
此文章为搬运
[原项目链接](https://aistudio.baidu.com/aistudio/projectdetail/5332241)

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 2
2 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)