
利用PP-OCR对街道门牌号进行识别
利用PP-OCR对街道门牌号进行识别
【AI达人特训营二期】PaddleOCR街景地图门牌号识别
一、背景介绍
1、街景地图
我们平时使用的地图软件,例如百度地图,高德地图等,在地图的显示上都会提供两种方案:
-
一个是标准地图方案,即在图层上显示所有重要的建筑物名称、主要的交通网络、行政区域划分线等数据。
-
另一个是卫星地图方案,即卫星在太空中探测地球地表物体对电磁波的反射和其发射的电磁波,从而提取这些地表信息,加之转化,得到的能够表述目前详细地理状况的地图。
2007年,美国的谷歌公司在自己的谷歌地图服务中,添加了街景地图的功能。
所谓的街景地图不同于卫星地图,其使用了专门的采集摄像头,并通过搭载于其他交通工具的形式,收集每一个街头的全景照片,最终生成每一个地方都覆盖,由无数全景照片拼凑而成的街景地图。
从成本角度上看,街景地图的生成成本比卫星地图要昂贵得多。但是相应的,街景地图能够更好地反映真实的道路结构,甚至可以以人类的角度迅速观察四周,为地图的查看增加趣味性。
使用街景地图,人们可以精细地浏览前方的道路结构,查看周边店铺的真实情况,偶尔也能够通过街景地图,进行一次线上的“旅行”。与当前的元宇宙概念相结合的话,便存在较大的市场潜力。
在街景地图的应用中,分析每一个街景中存在的门牌号有利于快速理清道路的结构信息,这也使得自然场景的门牌识别成为了街景地图制作的一个重要组成部分。
若能够训练出性能优秀的门牌号识别神经网络,那么街景地图的分析效率将会大大提升,能够给用户带来更优秀的体验。

2、OCR
本项目主要使用的是OCR技术,是目标检测算法中的一环。OCR常见于日常文档的文字扫描识别,而对于背景复杂,字体多样化的街景门牌号,其识别的精度是十分有限的。
在项目中,我们所使用的开发套件为paddlepaddle开源的PaddleOCR。PaddleOCR集成了很多轻量型检测模型以及识别模型:
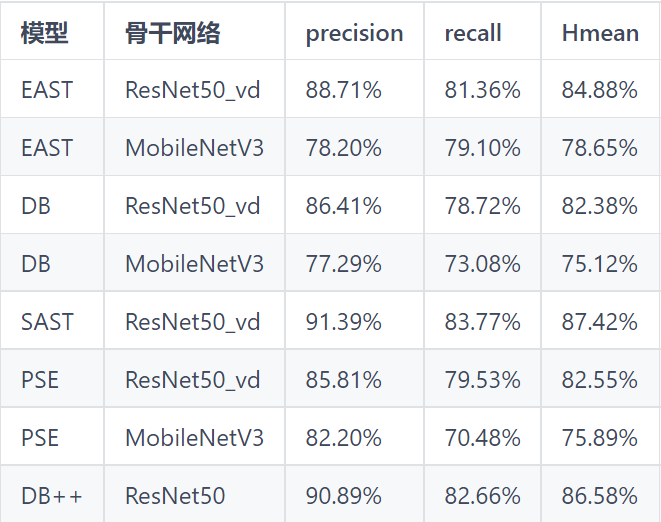
PaddleOCR不仅能够应对一般的文档识别问题,对复杂场景中的文字识别也能够发挥较大的能力。

最重要的是PaddleOCR中大多数为超轻量模型,能够部署在移动端的机器上,使得使用手机快速识别日常物体上的文字成为可能。
3、街景地图门牌号数据集
数据集地址如下:https://aistudio.baidu.com/aistudio/datasetdetail/144337
该数据集中包含了30000张训练图片,10000张验证图片,以及40000张测试图片。每一张图片都包含有1个或者多个紧靠在一起的数字字符,不包含中文。
测试图片原本用于模型预测以及计分,此项目中并没有相应指标,因此不使用测试集进行测试,而使用验证集验证模型的效果。

以下开始搭建环境并且训练~
二、环境配置
-
首先需要获取PaddleOCR相关套件,gitee地址:https://gitee.com/paddlepaddle/PaddleOCR
-
安装相关依赖⬇️
# 码云拉取PaddleOCR
! git clone https://gitee.com/paddlepaddle/PaddleOCR
! pip install -r /home/aistudio/PaddleOCR/requirements.txt
! pip install paddleslim editdistance
# 安装相关库。scikit-image和imgaug在requirements.txt均有提及,但不知为何训练时报错便再次install了
! pip install scikit-image
! pip install imgaug
! pip install Polygon3
# 改变工作区至PaddleOCR目录
import os
os.chdir('PaddleOCR')
三、数据集处理
-
方便起见,数据集已经通过wget下载至/home/aistudio/datasets目录中,之后将数据集进行解压并规范命名即可。
-
训练集文件夹为train_image, 验证集文件夹为val_image。
# 解压数据集并重命名
# !unzip -d /home/aistudio/datasets /home/aistudio/datasets/mchar_test_a.zip
!unzip -d /home/aistudio/datasets /home/aistudio/datasets/mchar_train.zip
!unzip -d /home/aistudio/datasets /home/aistudio/datasets/mchar_val.zip
!mv /home/aistudio/datasets/mchar_train /home/aistudio/datasets/train_image
!mv /home/aistudio/datasets/mchar_val /home/aistudio/datasets/val_image
# !mv /home/aistudio/datasets/mchar_test_a /home/aistudio/datasets/test_image
- paddleOCR的detect模型支持的标注格式为
" 图像文件名 json.dumps编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]], ...}]
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 p o i n t s points points表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。
t r a n s c r i p t i o n transcription transcription表示当前文本框的文字,在文本检测任务中并不需要这个信息。
- 而数据集提供的标注格式为
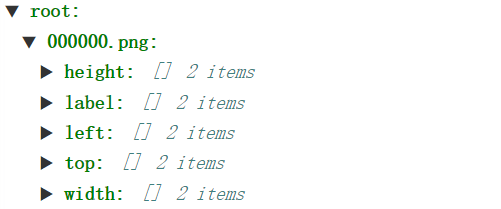
因此需要做一定的处理。
- paddleOCR的recognition模型支持的标注格式为
/home/aistudio/datasets/crop_image/val_image/000000_0.png 5
-
其中前一个字段为对应图片的绝对路径或相对路径,后一个字段为图片对应的分类编码。
-
该标注文件的生成只需要根据detect模型的标注文件进行提取关键字段即可。
-
相关方法已经整合成py文件,只需运行即可。⬇️
# 生成PaddleOCR支持的标注文件格式
%cd /home/aistudio/datasets
!mkdir crop_image
%cd crop_image
!mkdir train_image
!mkdir val_image
!python /home/aistudio/get_label.py
%cd /home/aistudio/PaddleOCR
/home/aistudio/datasets
mkdir: 无法创建目录"crop_image": 文件已存在
/home/aistudio/datasets/crop_image
mkdir: 无法创建目录"train_image": 文件已存在
mkdir: 无法创建目录"val_image": 文件已存在
/home/aistudio/PaddleOCR
四、构建模型并训练
1、训练流程:
(1)导入预训练模型
(2)训练detect模型
(3)训练recognition模型
(4)各自导出inference模型
(5)进行串联预测
2、导入预训练模型
- 本次使用的detect模型为ch_PP-OCRv3,检测算法为DB,介绍链接:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/PP-OCRv3_introduction.md
虽然该模型原用于中文的检测,但由于是检测模型,因此无需担心数字字符的定位问题,原理是可迁移的。
- 本次使用的recognition模型为en_PP-OCRv3,识别算法为SVTR,介绍链接:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/algorithm_rec_svtr.md
由于在门牌号识别的任务中,识别的内容仅有10类数字字符。因此使用英文模型即可。
不一一介绍了,直接开始!
# 获取预训练模型·detect模型
! mkdir models
%cd models
! wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
! tar -xf ch_PP-OCRv3_det_distill_train.tar
%cd /home/aistudio/PaddleOCR
# 获取预训练模型·recognition模型
! wget https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_train.tar
! tar -xvf en_PP-OCRv3_rec_train.tar
%cd /home/aistudio/PaddleOCR
3、训练detect模型
(1)经过对整个数据集的计算可知:
-
训练集每张图片的平均大小仅为(71,71,3)
-
最大的图片大小为(516,1083,3)
-
推断图片大小多集中在(71,71,3)以下
(2)修改配置文件:
...
Train:
dataset:
name: SimpleDataSet
...
transforms:
...
- EastRandomCropData:
size:
- 480 #原为960
- 480 #原为960
max_tries: 50
keep_ratio: true
...
loader:
shuffle: true
drop_last: false
batch_size_per_card: 12
num_workers: 4
use_shared_memory: false #不使用共享内存
Eval:
...
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 2
use_shared_memory: false #不使用共享内存
-
这里将(960,960)的resize输入尺寸,更改为(480,480),主要的目的是通过减小输入的尺寸,来加快训练的速度。
-
而为什么不再继续减小呢?因为继续减小的话,可能会因为网络结构中下采样的倍数较大,导致了再继续减小模型尺寸,会使得部分结构的特征图输出过小,导致训练报错。
-
经过检验,减小输入的大小确实有利于加快训练,而对于模型收敛并无较大影响。
-
取消共享内存,有利于后期训练时,不会因为共享内存溢出导致提前结束训练。
-
其余的超参数设定为了方便修改,直接在notebook中进行配置。⬇️
-
训练过程:
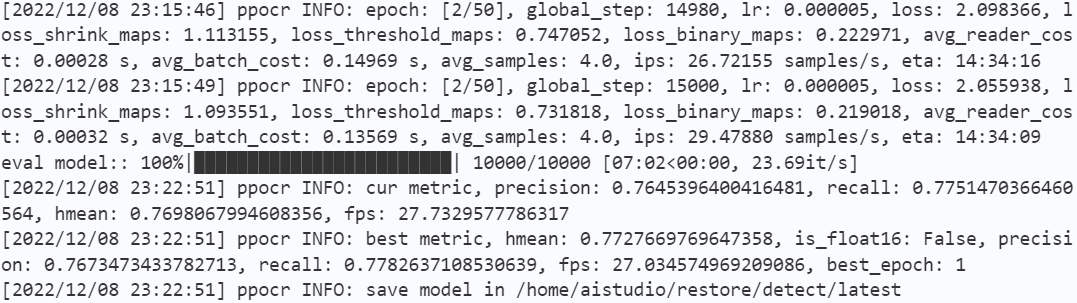
! python tools/train.py -c /home/aistudio/restore/configs/ch_PP-OCRv3_det_student.yml -o \
Global.pretrained_model=/home/aistudio/restore/detect/best_accuracy.pdparams \
Global.save_model_dir=/home/aistudio/restore/detect/ \
Global.eval_batch_step="[0, 3000]" \
Optimizer.lr.name=Cosine \
Optimizer.lr.learning_rate=0.000005 \
Optimizer.lr.warmup_epoch=0 \
Train.dataset.data_dir=/home/aistudio/datasets/train_image \
Train.dataset.label_file_list=[/home/aistudio/datasets/train_label/train_label.txt] \
Train.loader.batch_size_per_card=4 \
Train.loader.num_workers=2 \
Train.loader.use_shared_memory=false \
Eval.dataset.data_dir=/home/aistudio/datasets/val_image \
Eval.dataset.label_file_list=[/home/aistudio/datasets/val_label/val_label.txt] \
Eval.loader.batch_size_per_card=1 \
Eval.loader.num_workers=3 \
Eval.loader.use_shared_memory=false
# 验证一下detect模型
! python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \
Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams \
Eval.dataset.data_dir=/home/aistudio/datasets/train_image \
Eval.dataset.label_file_list=[/home/aistudio/datasets/val_label/val_label.txt] \
Eval.loader.num_workers=5
4、训练recognition模型
修改配置文件:
...
Train:
loader:
shuffle: true
drop_last: false
batch_size_per_card: 12
num_workers: 4
use_shared_memory: false #不使用共享内存
Eval:
...
loader:
shuffle: false
drop_last: false
batch_size_per_card: 1
num_workers: 2
use_shared_memory: false #不使用共享内存
-
取消共享内存,有利于后期训练时,不会因为共享内存溢出导致提前结束训练。
-
其余的超参数设定为了方便修改,直接在notebook中进行配置。⬇️
-
训练过程:
! python tools/train.py -c /home/aistudio/restore/configs/rec_en_ppocrv3.yml -o \
Global.pretrained_model=/home/aistudio/restore/rec/best_accuracy.pdparams \
Global.save_model_dir=/home/aistudio/restore/rec \
Global.eval_batch_step="[0, 500]" \
Optimizer.lr.name=Cosine \
Optimizer.lr.learning_rate=0.000001 \
Optimizer.lr.warmup_epoch=0 \
Train.dataset.data_dir=/home/aistudio/datasets/crop_image/train_image \
Train.dataset.label_file_list=[/home/aistudio/datasets/crop_image/rec_gt_train.txt] \
Train.loader.batch_size_per_card=128 \
Train.loader.num_workers=2 \
Train.loader.use_shared_memory=false \
Eval.dataset.data_dir=/home/aistudio/datasets/crop_image/val_image \
Eval.dataset.label_file_list=[/home/aistudio/datasets/crop_image/rec_gt_eval.txt] \
Eval.loader.batch_size_per_card=128 \
Eval.loader.num_workers=3 \
Eval.loader.use_shared_memory=false
# 验证一下recognition模型
! python tools/eval.py -c /home/aistudio/restore/configs/rec_en_ppocrv3.yml -o \
Global.pretrained_model=/home/aistudio/restore/rec/best_accuracy.pdparams \
Eval.dataset.data_dir=/home/aistudio/datasets/crop_image/val_image \
Eval.dataset.label_file_list=[/home/aistudio/datasets/crop_image/rec_gt_eval.txt] \
Eval.loader.batch_size_per_card=1 \
Eval.loader.num_workers=3 \
Eval.loader.use_shared_memory=false
5、导出inference模型
-
由于训练时间不足,加之多次的调参,最终得到的detect模型的验证集指标为
|hmean|
|:–😐
|0.773| -
最终得到的recognition模型的验证集指标为
|acc|
|:–😐
|0.937| -
直接将最好的参数,配合网络结构,导出为推理模型,并存放在/home/aistudio/restore/inference_xxx中。

共生成三个文件
# 将detect模型导出为inference模型
!python tools/export_model.py -c /home/aistudio/restore/configs/ch_PP-OCRv3_det_student.yml -o \
Global.pretrained_model=/home/aistudio/restore/detect/best_accuracy.pdparams \
Global.save_inference_dir=/home/aistudio/restore/inference_det
# 将recognition模型导出为inference模型
!python tools/export_model.py -c /home/aistudio/restore/configs/rec_en_ppocrv3.yml -o \
Global.pretrained_model=/home/aistudio/restore/rec/best_accuracy.pdparams \
Global.save_inference_dir=/home/aistudio/restore/inference_rec
6、进行串联预测
-
在串联之前,先对两个导出的模型分别进行预测…
-
detect模型对000011.png的预测结果如下:
000011.png [[[25.0, 11.0], [37.0, 10.0], [38.0, 30.0], [25.0, 31.0]], [[36.0, 10.0], [48.0, 10.0], [48.0, 30.0], [36.0, 30.0]]]

- recognition模型对000000_0.png的预测结果如下:
Predicts of /home/aistudio/datasets/crop_image/val_image/000000_0.png:('5', 0.9989054203033447)
# detect模型预测
! python tools/infer/predict_det.py \
--det_limit_type="resize_long" \
--det_algorithm="DB" \
--det_model_dir="/home/aistudio/restore/inference_det" \
--image_dir="/home/aistudio/datasets/val_image/000011.png" \
--use_gpu=True
# 显示预测结果
import matplotlib.pyplot as plt
img1 = plt.imread("./inference_results/det_res_000011.png")
plt.imshow(img1)
# recognition模型预测
! python tools/infer/predict_rec.py \
--rec_algorithm="" \
--rec_char_dict_path="/home/aistudio/PaddleOCR/ppocr/utils/en_dict.txt" \
--rec_model_dir="/home/aistudio/restore/inference_rec" \
--image_dir="/home/aistudio/datasets/crop_image/val_image/000000_0.png" \
--use_gpu=True
# 显示原图
img = plt.imread("/home/aistudio/datasets/crop_image/val_image/000000_0.png")
plt.imshow(img)
串联预测!
- 预测结果为
[2022/12/09 01:55:46] ppocr DEBUG: dt_boxes num : 3, elapse : 1.3058736324310303
[2022/12/09 01:55:46] ppocr DEBUG: rec_res num : 3, elapse : 0.48786425590515137
[2022/12/09 01:55:46] ppocr DEBUG: 0 Predict time of /home/aistudio/datasets/val_image/000001.png: 1.795s
[2022/12/09 01:55:46] ppocr DEBUG: 2, 0.998
[2022/12/09 01:55:46] ppocr DEBUG: 1, 0.890
[2022/12/09 01:55:46] ppocr DEBUG: 0, 0.972
[2022/12/09 01:55:46] ppocr DEBUG: The visualized image saved in ./inference_results/000001.png
[2022/12/09 01:55:46] ppocr INFO: The predict total time is 1.804936170578003

从该预测结果看来,两个模型的串联预测最终成功。
# 进行串联预测
import matplotlib.pyplot as plt
! python tools/infer/predict_system.py \
--det_limit_type="resize_long" \
--det_algorithm="DB" \
--det_model_dir="/home/aistudio/restore/inference_det" \
--image_dir="/home/aistudio/datasets/val_image/000001.png" \
--rec_algorithm="" \
--rec_char_dict_path="/home/aistudio/PaddleOCR/ppocr/utils/en_dict.txt" \
--rec_model_dir="/home/aistudio/restore/inference_rec"
plt.figure(figsize=(10, 8))
img = plt.imread("/home/aistudio/PaddleOCR/inference_results/000001.png")
plt.imshow(img)
分割线- . -
感言:
-
第一次在paddlepaddle做项目,也是第一次进入OCR领域,在日夜的调参和摸索之中确实学到挺多的。
-
OCR是目标检测的一个应用领域。此前本人学习yolo算法,以网络结构为学习的重点,注重深度学习理论,而没有真正地尝试过自己编写代码进行网络训练。现在看来,确实实践的难度要比纸上谈兵高得多,不仅要在意网络结构,还要考虑数据处理的可行性,超参数调节的经验等等。虽然因时间原因无法获得一个高准确率的模型,但是在编写过程中遇到问题解决问题的经历更令人受益匪浅!
Problem and Solutions:
problem1:
遇到的第一个较大的问题是,训练经过1个小时之后,没有任何预兆突然报错。查看资源监控,没看到硬件资源溢出的情况。
solutions1:
查阅了众多资料之后,才发现是共享内存溢出了,而原来的yml文件中并没有提及share_memory,share_memory默认是True的,因此在原yml文件中加入了share_memory字段,并设置为False。之后在训练过程中再也没有无故停止的情况。
problem2:
第二个问题是,导出成inference模型后,无论是detect模型还是recognition模型,预测结果全为空,串联预测后也是空的结果。
solutions2:
起初怀疑是导出程序出现故障了,对于detect模型,先通过infer_det.py程序使用导出前的模型进行预测,查看最终的输出,结果输出是正常的,之后再通过predict_det.py预测,预测结果是空,查看输出通道的维度,结果确实和导出前大为不同。最终的原因是导出时,yml中的预处理参数det_limit_type:resize_long并没有导出,而predict_det.py中的det_limit_type为max,导致了输入尺寸过小,最终输出的通道维度不满足要求,输出空结果。只要将predict_det.py中的det_limit_type重新定义即可。
对于recognition模型,发现输出通道维度和原先相同,说明预处理并没有出问题。偶然将rec_algorithm字段修改为EAST(原先为SVRT),之后就输出了一个奇怪的中文字符,并且有很高的置信度输出,这才发现问题出在后处理参数中。rec_algorithm定义为SVRT时,程序会对输出作进一步的变换,导致了原先正确的输出异常,因此将rec_algorithm重新定义为空;输出中文说明字符集错误,将rec_char_dict_path字段重新定义为英文字符集后,最终正常。
结尾:
感谢张一乔导师在我困惑时的即时指导,之后我会更加努力,在深度学习领域生根发芽!
——zzz辄止
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)