
李宏毅《深度学习》- Self-attention 自注意力机制
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量(序列),同时长度会改变,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样:将单词表示为向量的方法:One-hot Encoding(独热编码)。向量的长度就是世界上所有词汇的数目,用不同位的1(其余位置为0)表示一个词汇,如下所示:但是它并不能区分
Transformer & BERT PPT: https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/self_v7.pdf
【李宏毅《机器学习/深度学习》2021课程(国语版本,已授权)-哔哩哔哩】
一、问题分析
1. 模型的输入
无论是预测视频观看人数还是图像处理,输入都可以看作是一个向量,输出是一个数值或类别。然而,若输入是一系列向量(序列),同时长度会改变,例如把句子里的单词都描述为向量,那么模型的输入就是一个向量集合,并且每个向量的大小都不一样: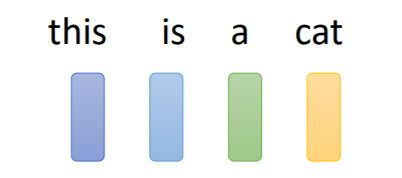
将单词表示为向量的方法:One-hot Encoding(独热编码)。向量的长度就是世界上所有词汇的数目,用不同位的1(其余位置为0)表示一个词汇,如下所示:
- apple = [1, 0, 0, 0, 0, …]
- bag = [0, 1, 0, 0, 0, …]
- cat = [0, 0, 1, 0, 0, …]
- dog = [0, 0, 0, 1, 0, …]
- computer = [0, 0, 0, 0, 1, …]
但是它并不能区分出同类别的词汇,里面没有任何有意义的信息。
另一个方法是Word Embedding:给单词一个向量,这个向量有语义的信息,一个句子就是一排长度不一的向量。将Word Embedding画出来,就会发现同类的单词就会聚集,因此它能区分出类别: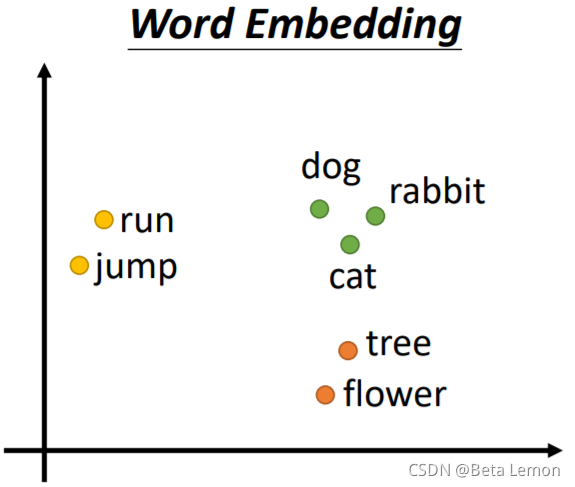
另外还有语音信号、图像信号也能描述为一串向量:
| 语音信号 | 图论 |
|---|---|
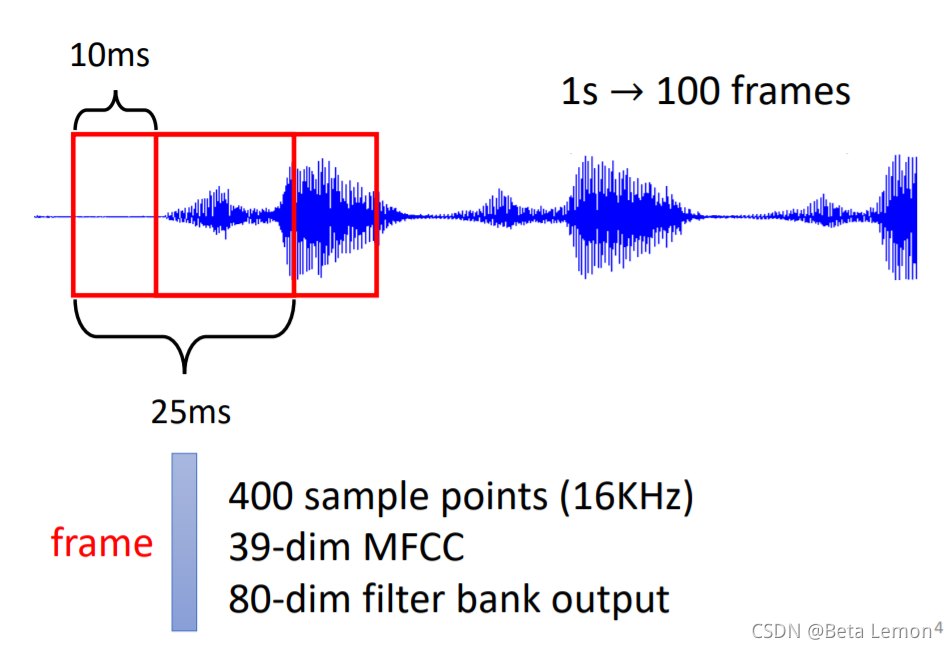
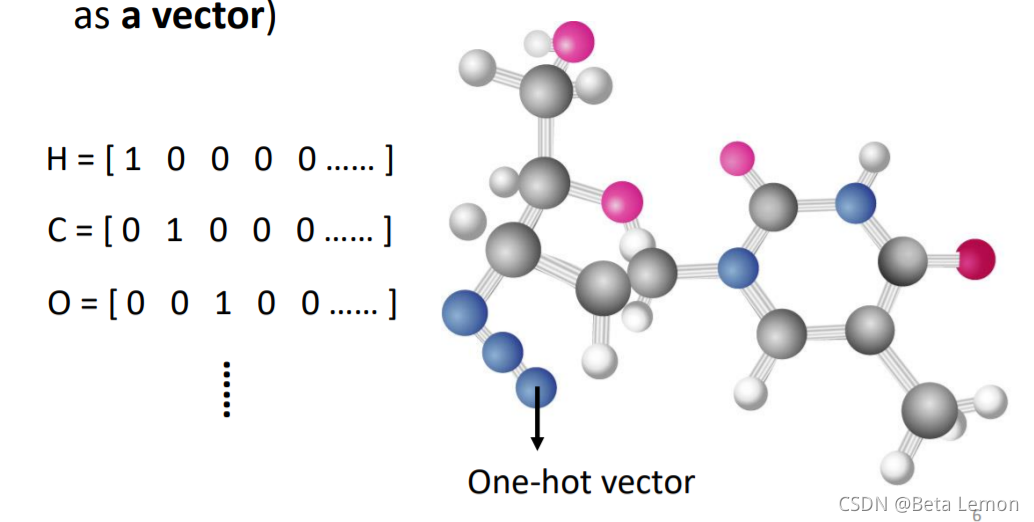
| 取一段语音信号作为窗口,把其中的信息描述为一个向量(帧),滑动这个窗口就得到这段语音的所有向量 | ①社交网络的每个节点就是一个人,节点之间的关系用线连接。每一个人就是一个向量 ②分子上的每个原子就是一个向量(每个元素可用One-hot编码表示),分子就是一堆向量 |
 |
  |
2. 模型的输出

类型一:一对一(Sequence Labeling)
每个输入向量对应一个输出标签。
- 文字处理:词性标注(每个输入的单词都输出对应的词性)。
- 语音处理:一段声音信号里面有一串向量,每个向量对应一个音标。
- 图像处理:在社交网络中,推荐某个用户商品(可能会买或者不买)。
类型二:多对一
多个输入向量对应一个输出标签。
- 语义分析:正面评价、负面评价。
- 语音识别:识别某人的音色。
- 图像:给出分子的结构,判断其亲水性。
类型三:由模型自定(seq2seq)
不知道应该输出多少个标签,机器自行决定。
- 翻译:语言A到语言B,单词字符数目不同
- 语音识别
3. 序列标注 (Sequnce Labeling) 的问题
利用全连接网络,输入一个句子,输出对应单词数目的标签。当一个句子里出现两个相同的单词,并且它们的词性不同(例如:I saw a saw. 我看见一把锯子),这个时候就需要考虑上下文:利用滑动窗口,每个向量查看窗口中相邻的其他向量的性质。

但是这种方法不能解决整条语句的分析问题,即语义分析。这就引出了 Self-attention 技术。
二、Self-attention 自注意力机制
输入整个语句的向量到self-attention中,输出对应个数的向量,再将其结果输入到全连接网络,最后输出标签。以上过程可多次重复:
Google 根据自注意力机制在《Attention is all you need》中提出了 Transformer 架构。
1. 运行原理
这里需要三个向量:Query,Key,Value。其解释参考文章 《如何理解 Transformer 中的 Query、Key 与 Value》- yafee123

注: b i ( 1 ≤ i ≤ 4 ) b^i (1≤i≤4) bi(1≤i≤4) 是同时计算出来的, a i , j a_{i,j} ai,j为 q i q^i qi和 k j k^j kj的内积。
上述过程可总结为:
- 输入矩阵 I I I分别乘以三个 W W W得到三个矩阵 Q , K , V Q,K,V Q,K,V
- A = Q K ⊤ A=QK^\top A=QK⊤,经过处理得到注意力矩阵 A ′ = s o f t m a x ( Q K ⊤ d k ) A' = softmax(\frac{QK^\top}{\sqrt{d_k}}) A′=softmax(dkQK⊤)
- 输出 O = A ′ V O=A'V O=A′V
即:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d k ) V Attention(Q,K,V)=softmax(\frac{QK^\top}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQK⊤)V
其中, d k \sqrt{d_k} dk为向量的长度。
注意力系数计算1:
- 阶段1:根据Query和Key计算两者的相似性或者相关性
- 阶段2:对第一阶段的原始分值进 行归一化处理
- 阶段3:根据权重系数对Value进行加权求和,得到Attention Value
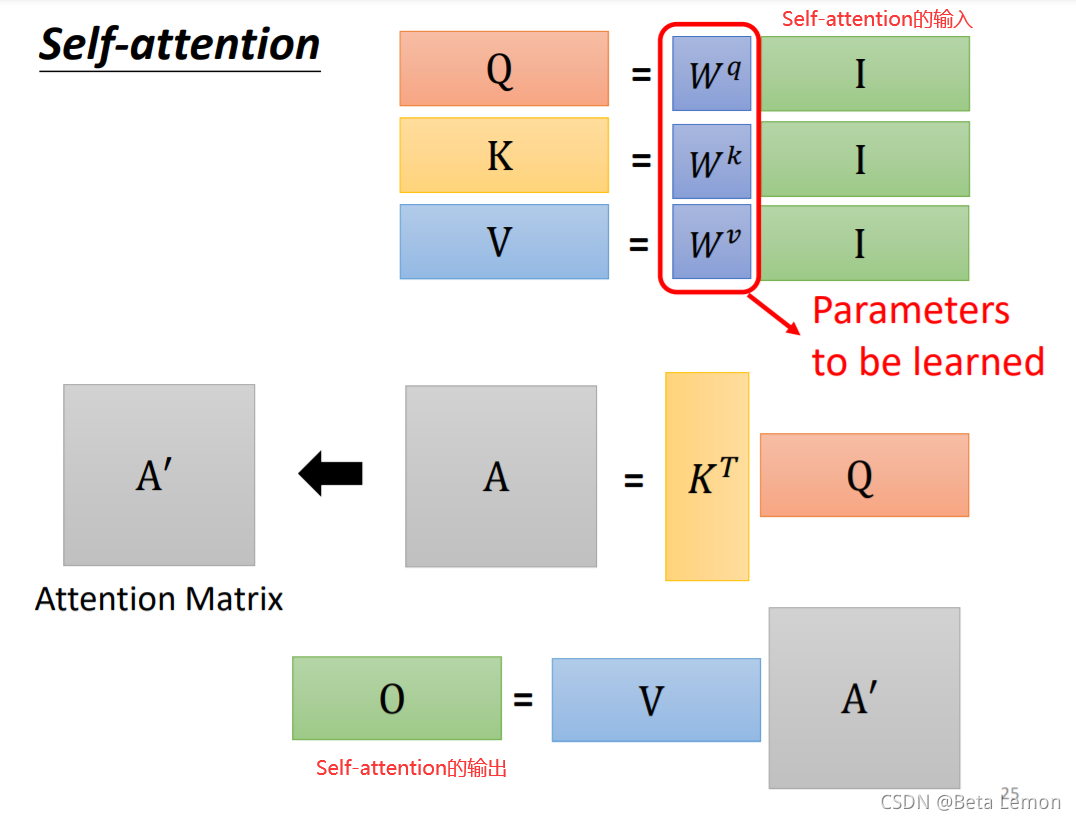
其中唯一要训练出的参数就是 W W W.
具体计算参考:动手推导Self-Attention
2. 多头注意力机制 (Multi-head Self-attention)
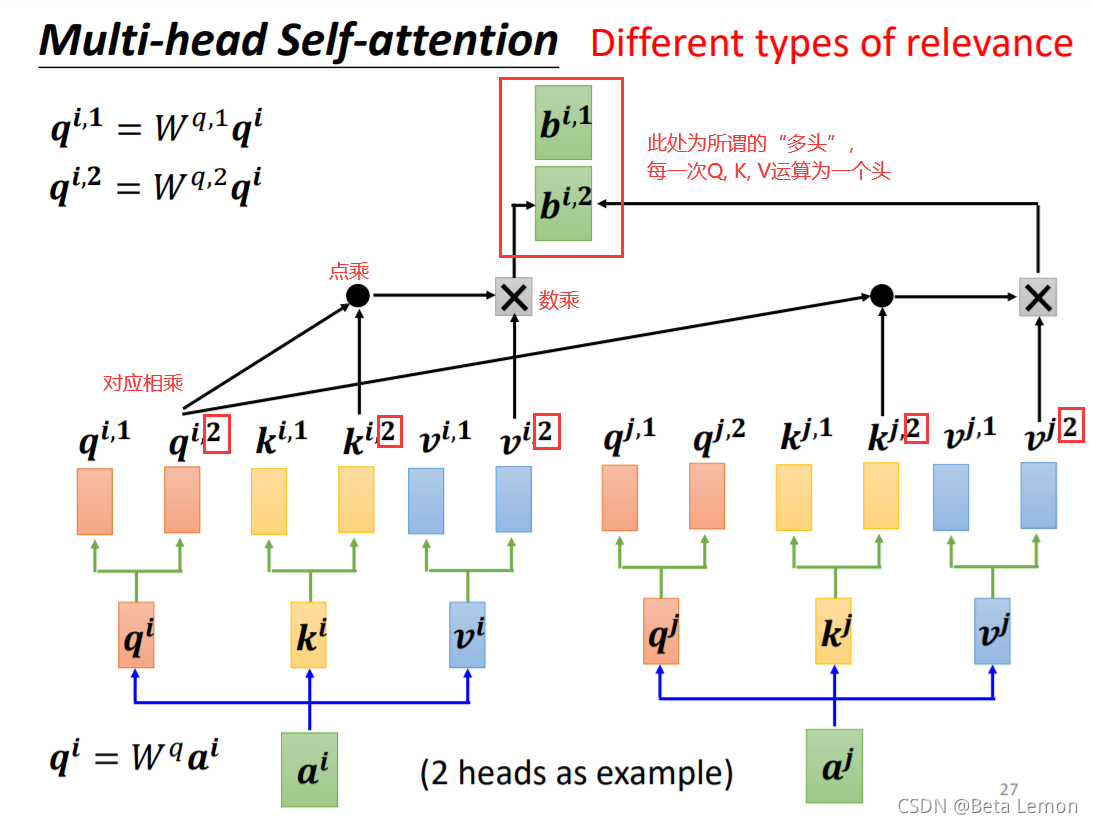
b i = W 0 [ b i , 1 b i , 2 ] b^i=W^0\left[ \begin{array}{c} b^{i,1} \\ b^{i,2} \end{array} \right] bi=W0[bi,1bi,2]
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i V ) MultiHead(Q, K, V)=Concat(head_1, ..., head_h)W^O \\ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) MultiHead(Q,K,V)=Concat(head1,...,headh)WOheadi=Attention(QWiQ,KWiK,VWiV)
如上述公式,在Multi-head的情况下,输入还是 Q , K , V Q,K,V Q,K,V,输出是不同head的输出的拼接结果,再投影到 W O W^O WO 中。其中,对每一个head,可以将 Q , K , V Q,K,V Q,K,V 通过不同的可学习的参数 W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV 投影到一个低维上面,再做注意力函数 A t t e n t i o n Attention Attention,最后输出结果。
Query,Key,Value首先经过一个线性变换,然后输入到放缩点积attention,注意这里要做 h h h 次,其实也就是所谓的多头,每一次算一个头。而且每次Q,K,V进行线性变换的参数 W W W是不一样的( W q , W k , W v W^q,W^k,W^v Wq,Wk,Wv)。然后将 h h h 次的放缩点积attention结果进行拼接,再进行一次线性变换得到的值作为多头attention的结果。2
对于Self-attention来说,并没有序列中字符位置的信息。例如动词是不太可能出现在句首的,因此可以降低动词在句首的可能性,但是自注意力机制并没有该能力。因此需要加入 Positional Encoding 的技术来标注每个词汇在句子中的位置信息。
自注意力中为何要缩放?3
维度较大时,向量内积容易使得 SoftMax 将概率全部分配给最大值对应的 Label,其他 Label 的概率几乎为 0,反向传播时这些梯度会变得很小甚至为 0,导致无法更新参数。因此,一般会对其进行缩放,缩放值一般使用维度 dk 开根号,是因为点积的方差是 dk,缩放后点积的方差为常数 1,这样就可以避免梯度消失问题。
另外,Hinton 等人的研究发现,在知识蒸馏过程中,学生网络以一种略微不同的方式从教师模型中抽取知识,它使用大模型在现有标记数据上生成软标签,而不是硬的二分类。直觉是软标签捕获了不同类之间的关系,这是大模型所没有的。这里的软标签就是缩放的 SoftMax。
至于为啥最后一层为啥一般不需要缩放,因为最后输出的一般是分类结果,参数更新不需要继续传播,自然也就不会有梯度消失的问题。
3. 位置编码 (Positional Encoding)
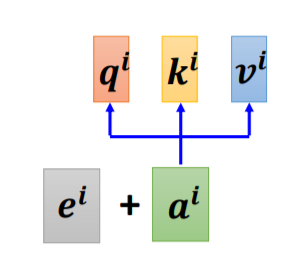
每一个不同的位置都有一个专属的向量 e i e^i ei,然后再做 e i + a i e^i+a^i ei+ai 的操作即可。但是这个 e i e^i ei 是人工标注的,就会出现很多问题:在确定 e i e^i ei的时候只定到128,但是序列长度是129。在最早的论文4中是没有这个问题的,它通过某个规则(sin、cos函数)5 产生。尽管如此,位置编码也可以通过学习来得出。
BERT6 模型也用到了自注意力机制
Self-attention 还可以用在除NLP以外的问题上:语音处理,图像处理。
三、其他应用
1. 语音识别
2. 图像识别
在做CNN的时候,一张图片可看做一个很长的向量。它也可看做 一组向量:一张 5 ∗ 10 5*10 5∗10的RGB图像可以看做 5 ∗ 10 5*10 5∗10的三个(通道)矩阵,把三个通道的相同位置看做一个三维向量。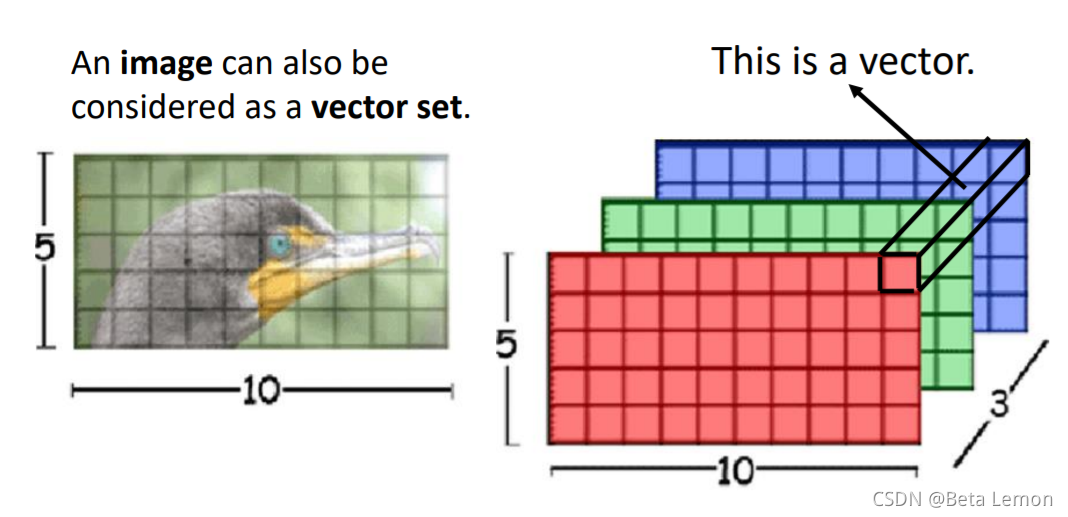
具体应用:GAN、DETR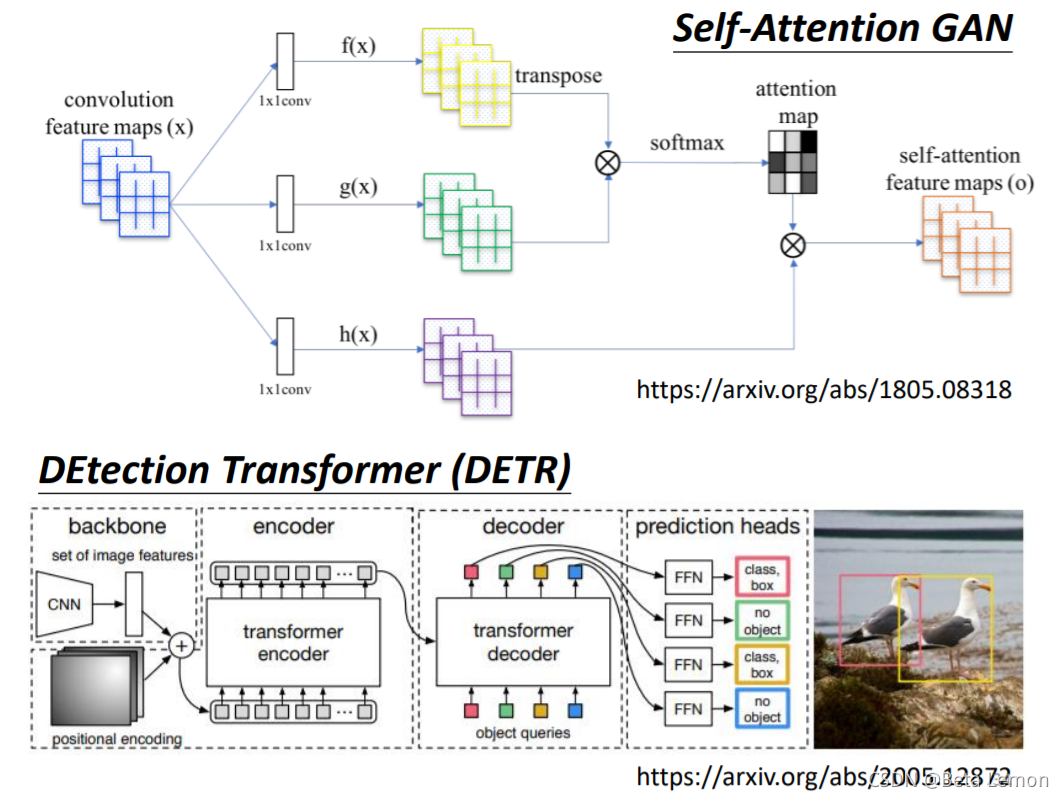
2.1 自注意力机制和CNN的差异
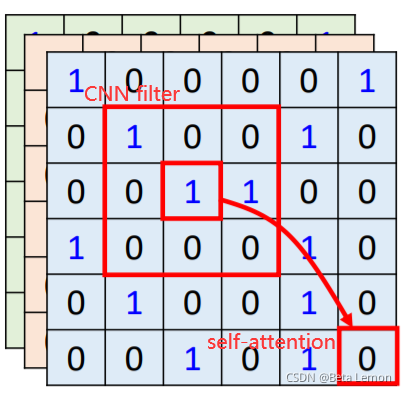
- CNN看做简化版的self-attention:CNN只考虑一个感受野里的信息,self-attention考虑整张图片的信息
- self-attention是复杂版的CNN:CNN里面每个神经元只考虑一个感受野,其范围和大小是人工设定的;自注意力机制中,用attention去找出相关的像素,感受野就如同自动学出来的。
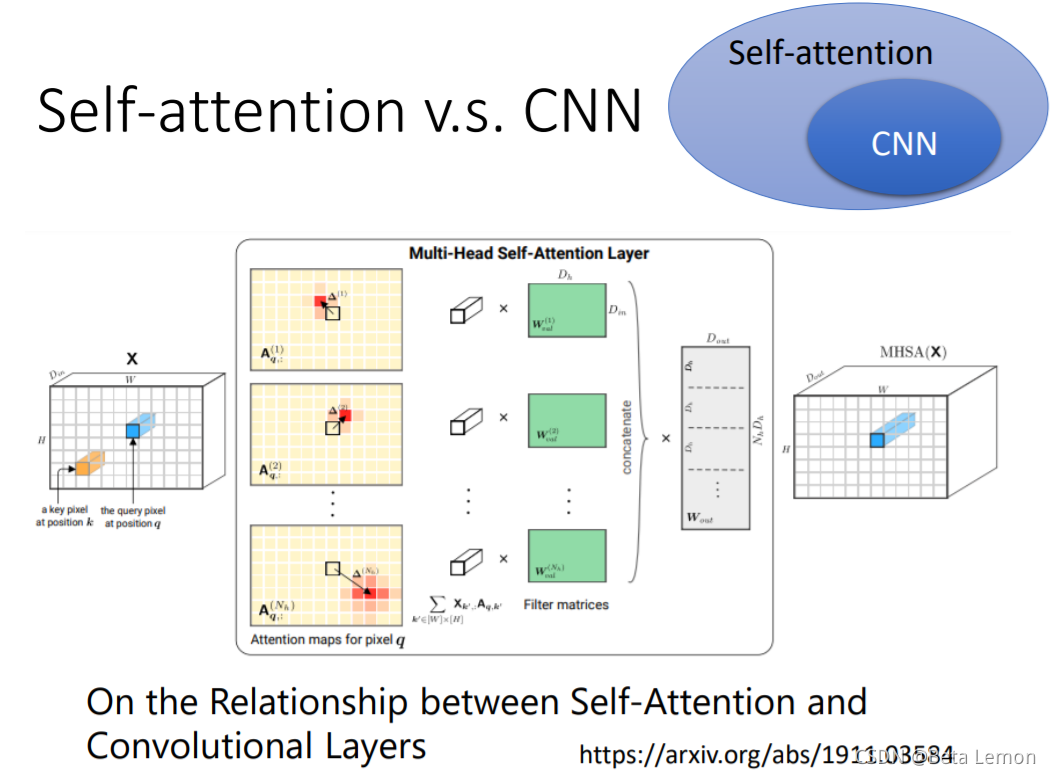
如果用不同的数据量来训练CNN和self-attention,会出现不同的结果。大的模型self-attention如果用于少量数据,容易出现过拟合;而小的模型CNN,在少量数据集上不容易出现过拟合。7
2.2 与RNN的差异
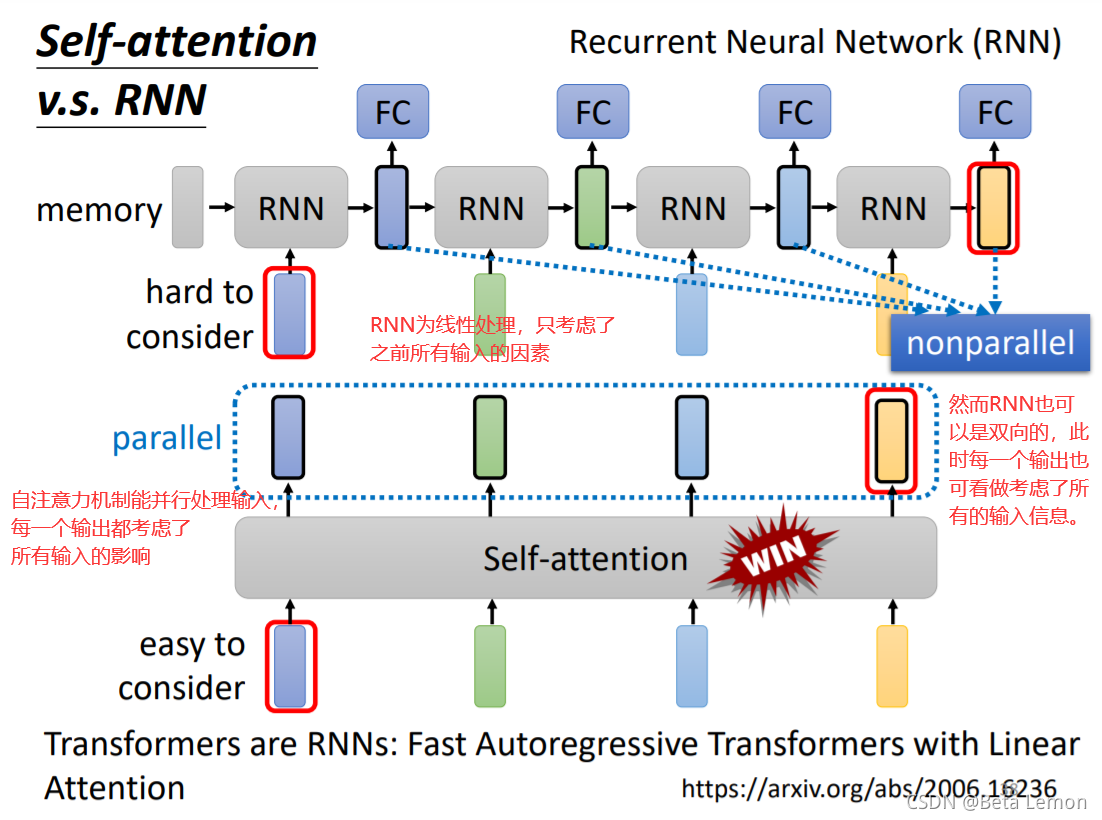
因此很多的应用逐渐把RNN的架构改为Self-attention架构。8
3. 应用于图论(GNN)
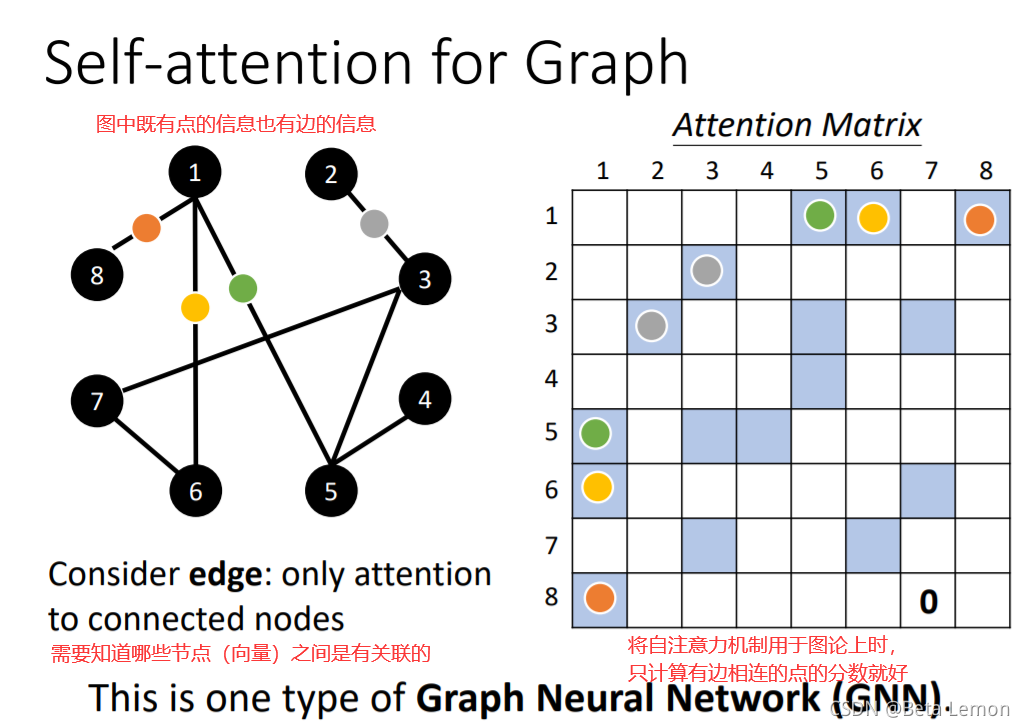
自注意力机制的缺点就是计算量非常大,因此如何优化其计算量是未来研究的重点。
四、代码实现
1. Self-Attention
根据公式
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K ⊤ d k ) V Attention(Q,K,V)=softmax(\frac{QK^\top}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQK⊤)V
因为 Q Q Q 与 K ⊤ K^\top K⊤ 做矩阵乘法,所以 Q Q Q 列的维度等于 K K K 列的维度,即 d i m q = = d i m k dim_q == dim_k dimq==dimk. 在BERT中, d i m q = = d i m k = = d i m v = = h i d d e n _ s i z e dim_q == dim_k == dim_v == hidden\_size dimq==dimk==dimv==hidden_size.
import torch
import torch.nn as nn
import math
class SelfAttention(nn.Module):
"""
input : batch_size * seq_len * input_dim
q : batch_size * input_dim * dim_k
k : batch_size * input_dim * dim_k
v : batch_size * input_dim * dim_v
"""
def __init__(self, input_dim, dim_k, dim_v):
super().__init__()
self.dim_k = dim_k
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
attention = torch.bmm(self.softmax(torch.bmm(Q, K.permute(0, 2, 1)) / math.sqrt(self.dim_k)), V)
return attention
2. Multi-Head Self-Attention
在多头注意力机制中,将一个(映射后的)高维矩阵拆分成多个低维矩阵进行计算,最后再将计算结果拼接。这里注意,并不是将输入inputX拆分成多个,因为这样做会丢失原句信息!

class MultiHeadSelfAttention(nn.Module):
"""
input : batch_size * seq_len * input_dim
q : batch_size * input_dim * dim_k
k : batch_size * input_dim * dim_k
v : batch_size * input_dim * dim_v
"""
def __init__(self, input_dim, dim_k, dim_v, nums_head):
super(MultiHeadSelfAttention, self).__init__()
assert dim_k % nums_head == 0
assert dim_v % nums_head == 0
self.dim_k = dim_k
self.dim_v = dim_v
self.q = nn.Linear(input_dim, dim_k)
self.k = nn.Linear(input_dim, dim_k)
self.v = nn.Linear(input_dim, dim_v)
self.nums_head = nums_head
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
Q = self.q(x).view(-1, x.shape[1], self.nums_head, self.dim_k // self.nums_head).permute(0, 2, 1, 3) # [batch_size, n_head, seq_len, hidden_size // n_head]
K = self.k(x).view(-1, x.shape[1], self.nums_head, self.dim_k // self.nums_head).permute(0, 2, 1, 3)
V = self.v(x).view(-1, x.shape[1], self.nums_head, self.dim_v // self.nums_head).permute(0, 2, 1, 3)
attention = torch.matmul(self.softmax(torch.matmul(Q, K.permute(0, 1, 3, 2)) / math.sqrt(self.dim_k)),
V).transpose(-2, -1) # [batch_size, n_head, seq_len, hidden_size // n_head]
attention = attention.transpose(1, 2) # [batch_size, seq_len, n_head, hidden_size // n_head]
output = attention.reshape(-1, x.shape[1], x.shape[2]) # [batch_size, seq_len, hidden_size]
# 或
# attention = attention.permute(2, 0, 1, 3)
# output = torch.cat([_ for _ in attention], dim=-1)
return output
-
transformer模型中的self-attention和multi-head-attention机制 - 小镇大爱 ↩︎
-
Learning to Encode Position for Transformer with Continuous Dynamical Model ↩︎
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩︎
-
On the Relationship between Self-Attention and Convolutional Layers ↩︎
-
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention ↩︎

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 49
49 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)