
决策树———用基尼系数建立决策树
第一、什么是决策树?简单来说就是用于解决分类问题的算法。第二、什么是基尼指数?是用于划分属性纯度的一个工具(基尼指数越小,则纯度越高说明该属性越优)公式如下对于各种不同的属性来计它的基尼指数,然后来创建一棵决策树。例如label=0和 label=1 都是5份的时候,每份的概率是0.5 使用基尼指数公式计算后,算出该属性的基尼指数为0.5同理可得后面的两个例子,Gi...
第一、什么是决策树?
简单来说就是用于解决分类问题的算法。
第二、什么是基尼指数?
是用于划分属性纯度的一个工具(基尼指数越小,则纯度越高说明该属性越优)
公式如下
 对于各种不同的属性来计它的基尼指数,然后来创建一棵决策树。
对于各种不同的属性来计它的基尼指数,然后来创建一棵决策树。
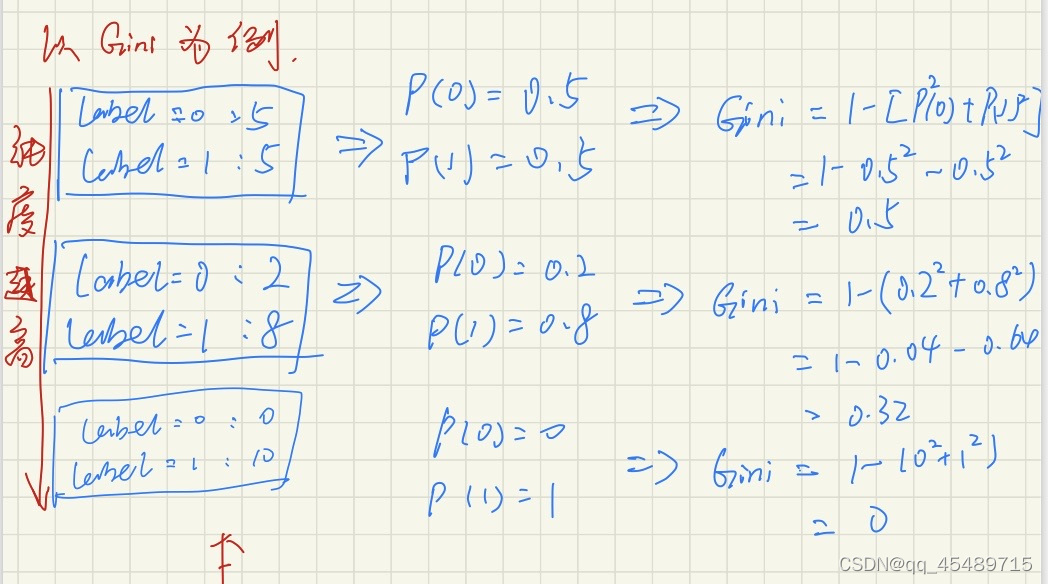
例如label=0 和 label=1 都是5份的时候,每份的概率是0.5 使用基尼指数公式计算后,算出该属性的基尼指数为0.5
同理可得后面的两个例子,Gini=0.32 和0 。从这三个样本中看,我们可以观察出这个属性的纯度是越来越高的过程,而我们就是要使用基尼指数去判别某一个属性的纯度,或者说Gini值的大小,选择其为区分的属性节点。

例如此表中有各种各样的属性,最后又一个判定标签即是否拖欠贷款。
我们应该先分析有房者,婚姻,年收入三个属性哪一个更优一点,然后来判断谁可以来充当根节点。
那我们就来,从年收入开始用基尼指数来建立一棵决策树,label的值为是否拖欠贷款

第一选择有房者这个属性,按照是否有房分为两类并记下其数量如图 有房的有3人,没有房的有7人,然后根据标签值分为四类人
有房拖欠贷款的0人,有房不拖欠贷款的3人,无房拖欠贷款的3人,无房不拖欠贷款的4人。分别计算有房者的基尼指数为0和无房者的基尼指数为24/49。最后进行加权平均如上图所示,可以得到有房这个属性的Gini加权值为12/35。
同理我们可以得到婚姻的Gini加权值为3/10,年收入的加权值为12/35。由于婚姻的Gini指数最低,或者说婚姻这个属性更纯,所以我们选择婚姻这个属性来当作根节点。
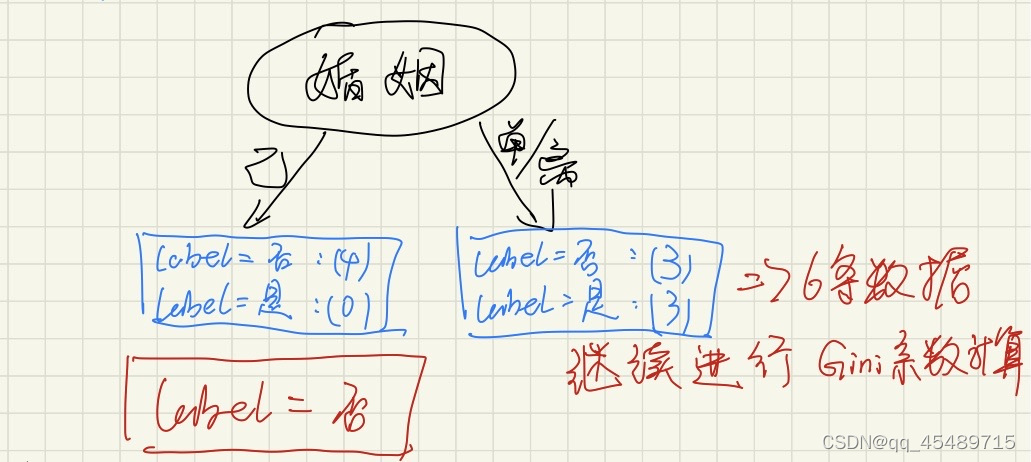
根据已婚 和(单身/离异)这两个条件分析它们label值,在已婚这边我们可以看到,四个人的标签均为否,所以可以直接把它的标签标记为否,剩下的6条数据继续进行基尼指数的计算来划分出一个更纯的属性。计算结果如下,计算过程与上面同理。
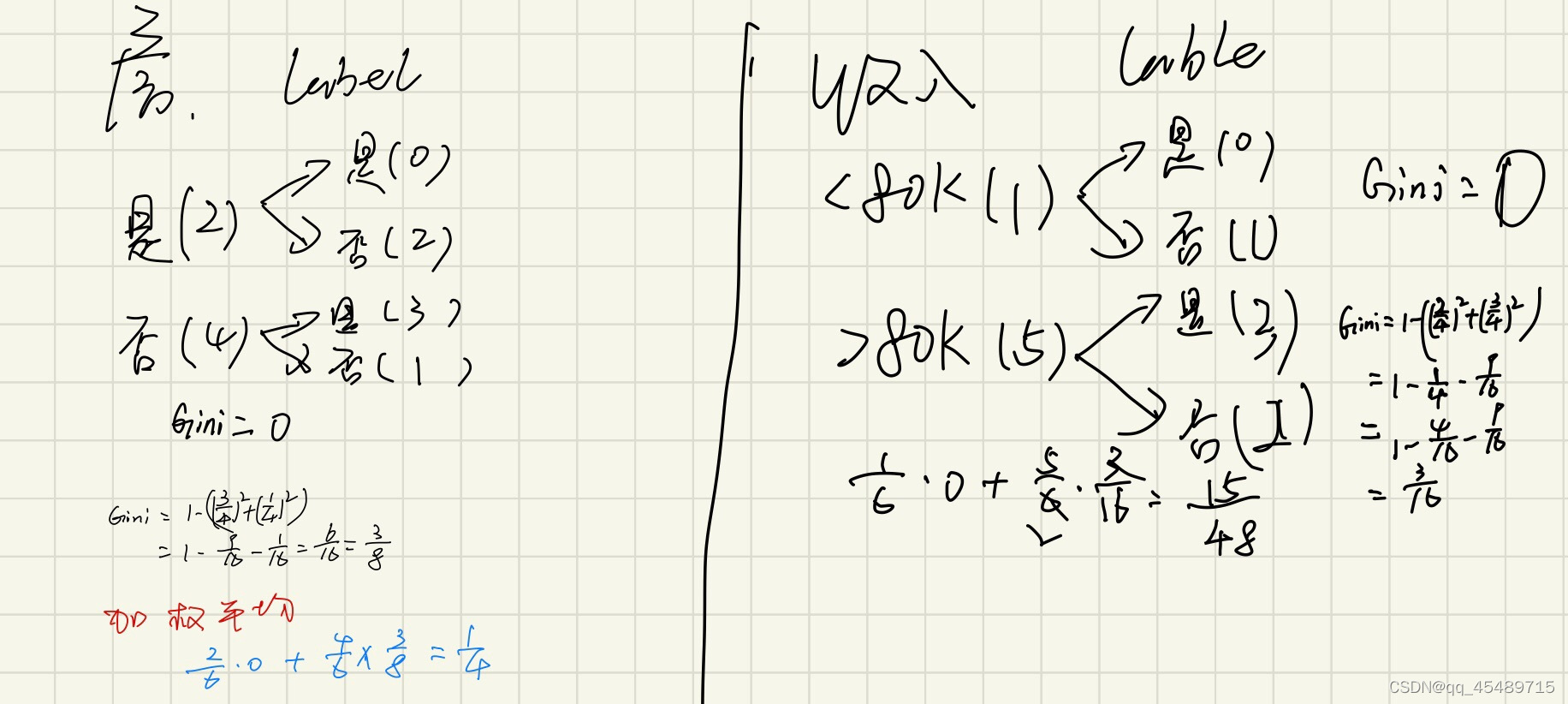
故有房成为第二个选择的属性节点。因为已经只剩下了一个属性,所以它成为了第三个属性节点,我们最终构建的决策树如下:
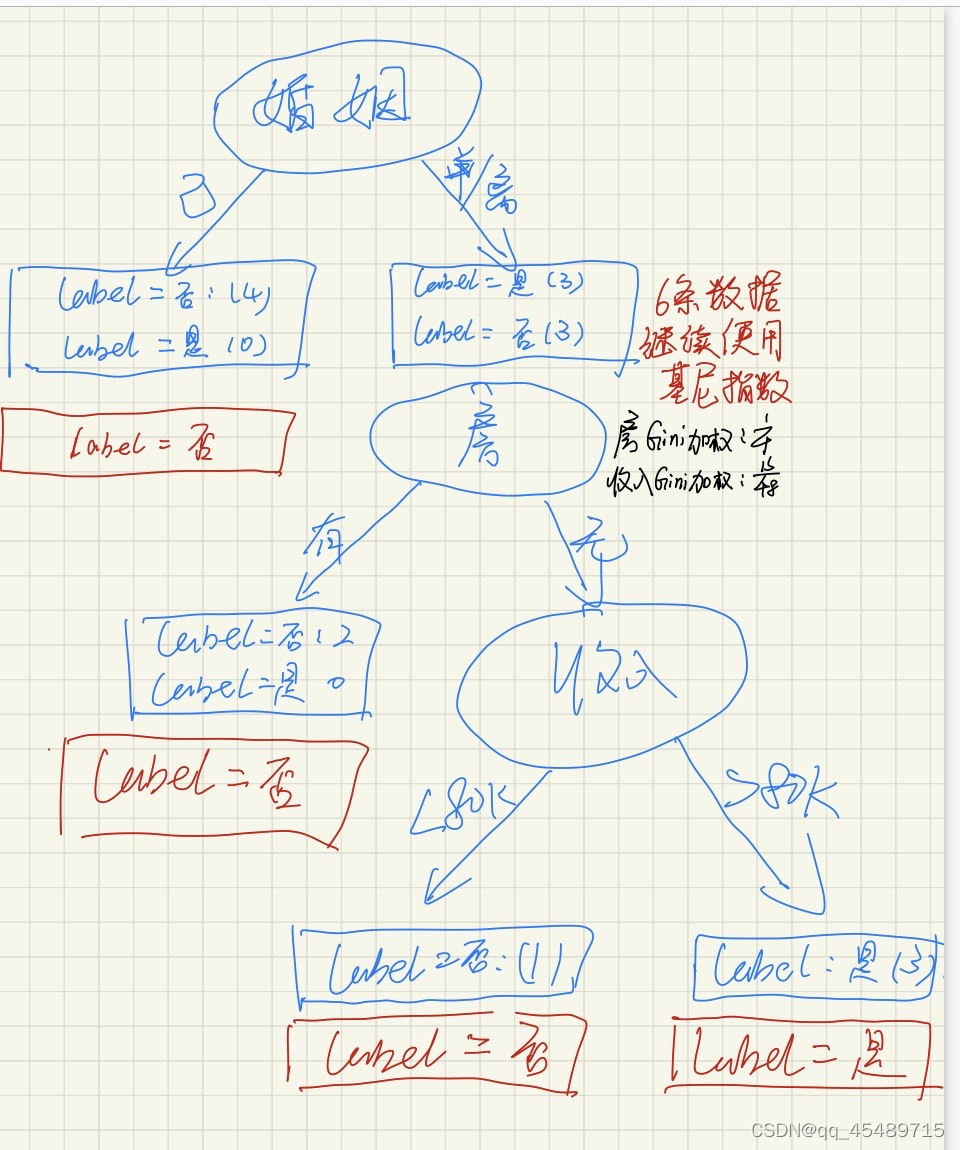
如果此时有了新的数据到来,我们就可以直接按照这棵决策树的判断条件,一直判断直到可以知道它的label值为是或者否为止。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)