
【数学建模分类预测实战】用Keras训练DNN神经网络并将模型用于回归预测
本文记录了笔者用Keras框架编写BP神经网络,训练并预测秦皇岛未来煤价数据,共分为三部分:训练、验证和预测。
本文记录了笔者用Keras框架编写BP神经网络,训练并预测秦皇岛未来煤价数据,共分为三部分:训练、验证和预测。本文编写于2020年5月19日,文中代码全为Python 3代码,并在Jupyter中测试通过。
点击跳转至本文数据集下载链接
献给新手!大家有疑问可以在评论区留言,一起进步~
1、数据读入
数据集下载链接:戳这里
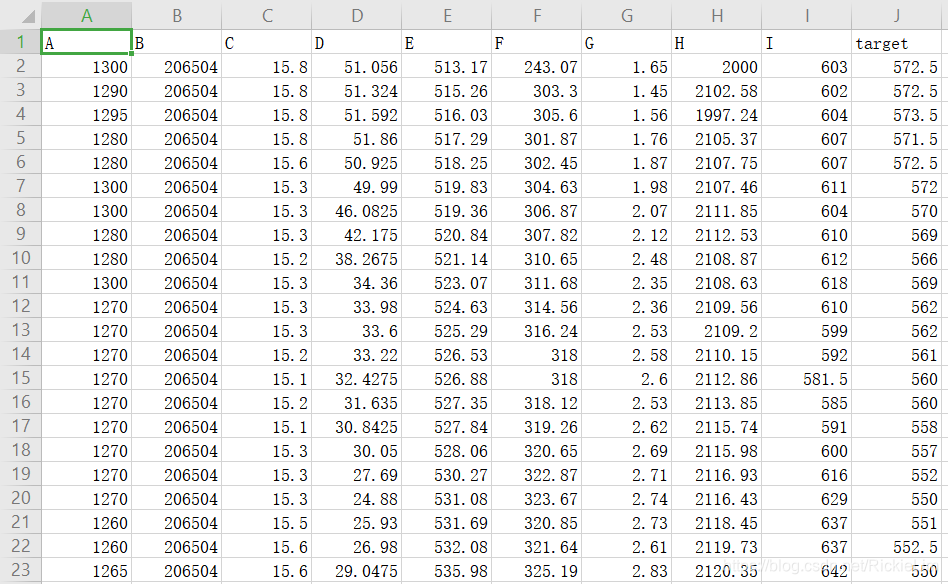
训练集一共62条,每条包含了9个属性(A~I)和目标值target,我们将用他们来训练模型:根据A-I的值来预测target的值。
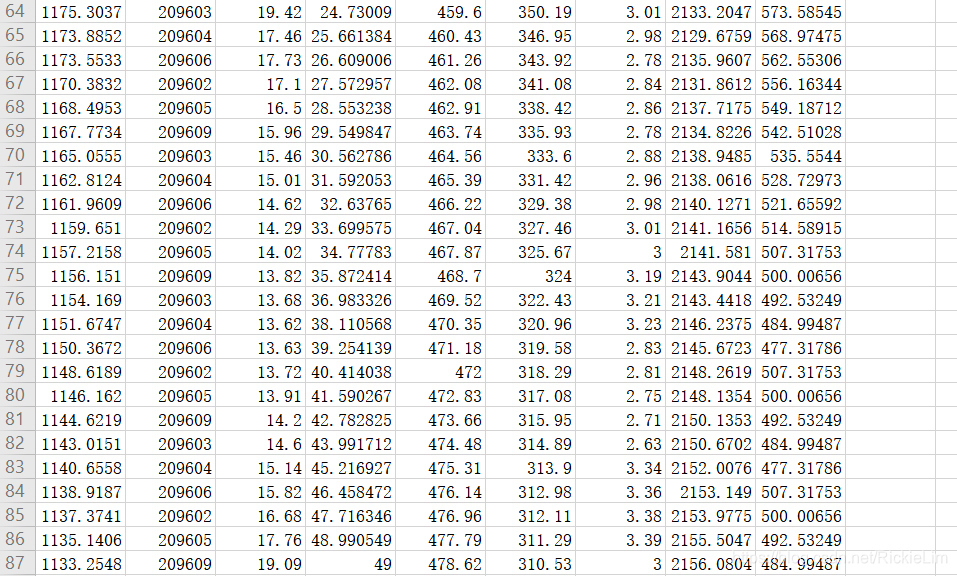
以下是需要预测的数据,我们将它放置在数据集的64~94行:
(仅有A-I属性的数据,无target值,我们将用训练好的模型来预测其target)
首先用Pandas读入全部数据——
import pandas as pd
data = pd.read_csv("C:/Users/LRK/Desktop/0518.csv")
注意,用Pandas读取的数据会是一个Numpy数组,在这种数据集上非常好用!!
★ 手动划分训练集(train_data)、训练目标(train_targets),他们都是Numpy数组。
train_data = data.loc[0:61, ['A','B','C','D','E','F','G','H','I']]
train_data.shape
# 读取数据集的0~61行、A~I列的数据
Output:(62, 9)
train_targets = data.loc[0:61, ['target']]
train_targets.shape
# 读取数据集的0~61行、target列的数据
Output:(62, 1)
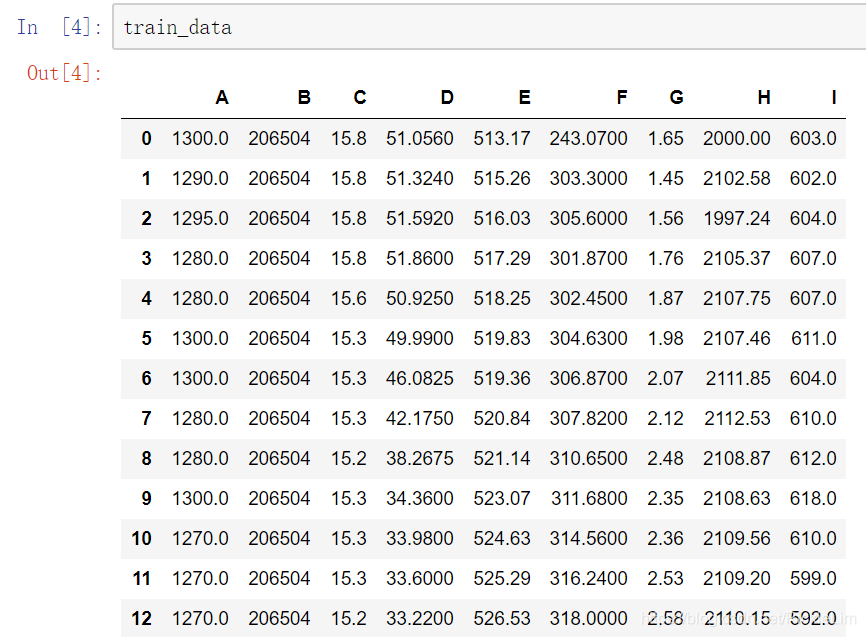
用Pandas读取train_data是这样的,非常美观:
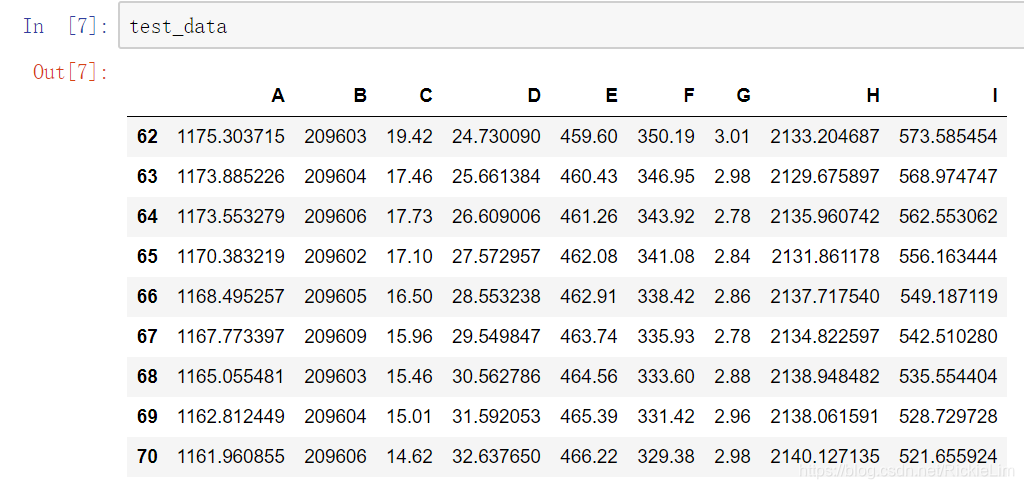
★ 读取需要预测的数据的A-I特征:
test_data = data.loc[62:92, ['A','B','C','D','E','F','G','H','I']]
2、数据预处理
在这里,我们采用“数据标准化处理”,即:每个数据减去该列平均值,再除以该列的标准差。这是机器学习中常见的数据处理方式,一定程度上缩小了A~I列不同属性的数据大小范围,方便神经网络进行训练。
(这里不明白的可以参考Andrew Ng的视频课程)
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
警告:test_data进行预处理的时候,减去的平均值和除以的标准差,都是在训练集上得出的,而非测试集上!!否则会影响准确性。
3、编写模型(深度神经网络)
DNN(深度神经网络),是BP神经网络的变种。
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1" # GTX 1050 Ti
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
用MAE(平均绝对误差)来衡量训练效果。MAE是指实际值与预测值的差值大小。
4、划分验证集
考虑到训练数据很少,我们采用K折交叉验证(k=4)
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
# 准备验证数据:第 k 个分区的数据
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
# 准备训练数据:其他所有分区的数据
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
# 构建 Keras 模型(已编译)
model = build_model()
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=1, verbose=1)
# 在验证数据上评估模型
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae)
查看MAE的平均值:
np.mean(all_scores)
输出:60.37001419067383
5、训练模型
先练500轮看看。
from keras import backend as K
K.clear_session()
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=1)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
查看500轮中,每一轮的各个分区上的MAE的平均值:
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
最后几轮的MAE平均值如下:
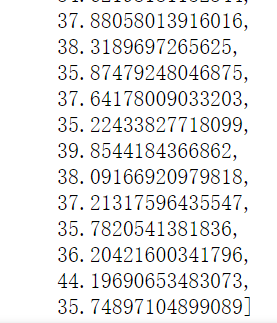
可以看出,经过训练,误差已经缩小了很多!
我们再画图来看看——
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
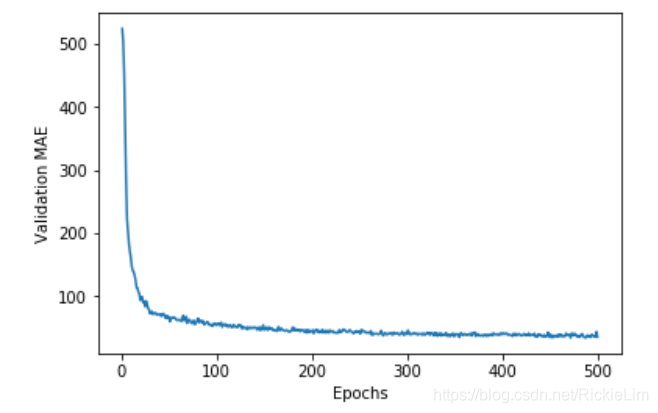
删除前40轮的数据,再重新画图,方便观察:
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[40:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
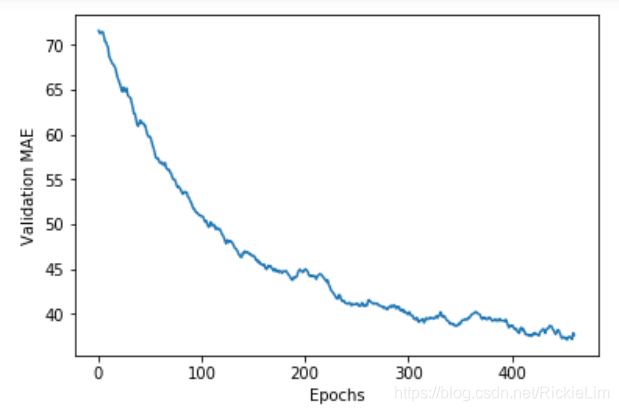
可以看出,模型并没有过拟合。
现在,我们用全部的训练数据,对模型从头开始重新训练!
model = build_model()
# Train it on the entirety of the data.
model.fit(train_data, train_targets,
epochs=600, batch_size=16, verbose=1)
分享最后几轮的训练过程如下:

由于训练集很小,效果可能没有很好。大家可以分享自己的指标或建议在评论区里~
6、用训练好的模型来预测新数据
这一块网上能搜到的代码很少,作为新手也是踩了不少坑~最后自己琢磨出来了怎么用Keras的Predict。
★ 其实!就两句话的事儿!用Keras真的非常方便了!!
predict = model.predict(test_data)
predict
接下来,就会打印出64—94行(即预测集)对应的target值,如下图所示。

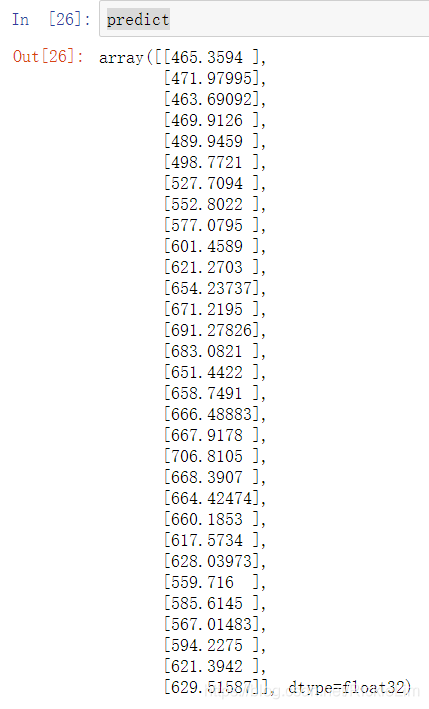
用Python可以写代码把预测数据写入到指定csv文件的指定行列上,所以应用时不必一个一个复制粘贴!具体代码自己网上一扒就有~
7、预测结果可视化
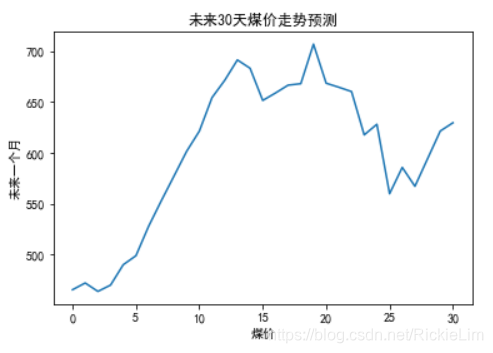
在数学建模中,经常会遇到需要以图表呈现数据。即数据可视化。这里我们顺便也演示一下。
注意:我们刚刚预测的30个值是未来30天的煤炭价格。我们将其画折线图呈现出来。代码如下。
from matplotlib import pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
x = np.arange(1,31)
plt.title("未来30天煤价走势预测")
plt.xlabel("未来一个月")
plt.ylabel("煤价")
plt.plot(range(0, 31, 1),predict)
plt.show()
效果如下图。 注意:笔者一开始横纵轴写反了所以大家看到的横纵坐标标识是反的,但图是对的。懒得改啦~
★ 既然说到python的matplotlib,那顺便解释两个新手常见的问题吧!
- Jupyter中画图,写标注时无法正常显示中文。
解决办法:加上这三条语句!别问为什么,加上去就是了!!
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
- 用matplotlib画图,显示什么<Figure …>,图没显示出来。
解决办法:加上下面的第一条语句。如果不行,把第二条也加上(加画布用的)。
%matplotlib inline
plt.figure()

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)