
pytorch实现GAN网络及训练自己的数据集
文章目录前言一、GAN网络介绍二、网络训练总结前言前不久在一个项目里面用GAN网络做了一下数据增强,目的就是通过给定的真实图片,得到一些模拟的假图片,达到以假乱真的目的,文章结尾有完整代码。GAN网络论文地址:https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf一、GAN网
前言
前不久在一个项目里面用GAN网络做了一下数据增强,目的就是通过给定的真实图片,得到一些模拟的假图片,达到以假乱真的目的,文章结尾有完整代码。
GAN网络论文地址:https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
一、GAN网络介绍
GAN网络即生成对抗网络,顾名思义,由生成网络(generative network)和与生成网络对抗的网络即判别网络(discriminative network)组成。
- 生成网络G目的是生成以假乱真的图片,它的输入是一个随机的噪声z,输出生成的模拟图片G(z)。
- 判别网络D的目的是判别输入的图像是真还是假,它的实质就是一个分类器,输入带标签的真假图片x,输出判断为真实图片的概率D(x)。
因为我们的目的是生成以假乱真的图片,所以我们希望两个网络对抗的结果是生成网络能够骗过判别网络,让它觉得我们生成的图片也是真实图片。即一个博弈过程。
二、网络训练
目标函数:
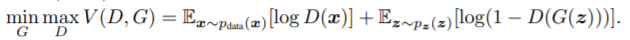
其中判别网络D要求最大概率地分对训练样本的标签,即最大化log D(x)和log(1 – D(G(z))),训练网络G最小化log(1 – D(G(z))),即最大化D的损失。在训练过程中固定某一网络,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布,也就是生成的样本更加的真实。
三、代码解析
生成网络与判别网络:
- 生成网络G:输入一维噪声向量,通过四层全连接层,输出生成图片的一维展开向量
- 判别网络D:输入图片的一维展开向量,通过三层全连接层,输出判别概率
网络参数可自行调节至适用数据集
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
附录
完整代码,改成自己的数据集需改更改参数设置中图片尺寸以及图片所在文件夹
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets
from torch.autograd import Variable
from PIL import Image
import torch.nn as nn
import torch.nn.functional as F
import torch
# 输出图片保存路径
os.makedirs("img2", exist_ok=True)
#参数设置
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=8, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
# 输入噪声向量维度,默认100
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
# 输入图片维度,默认64*64*3
parser.add_argument("--img_size1", type=int, default=64, help="size of each image dimension")
parser.add_argument("--img_size2", type=int, default=64, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=10, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size1, opt.img_size2)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
nn.Sigmoid(),
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validity
# Loss function
adversarial_loss = torch.nn.BCELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
img_transform = transforms.Compose([
# transforms.ToPILImage(),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # (x-mean) / std
])
class MyData(Dataset): # 继承Dataset
def __init__(self, root_dir, transform=None): # __init__是初始化该类的一些基础参数
self.root_dir = root_dir # 文件目录
self.transform = transform # 变换
self.images = os.listdir(self.root_dir) # 目录里的所有文件
def __len__(self): # 返回整个数据集的大小
return len(self.images)
def __getitem__(self, index): # 根据索引index返回dataset[index]
image_index = self.images[index] # 根据索引index获取该图片
img_path = os.path.join(self.root_dir, image_index) # 获取索引为index的图片的路径名
img = Image.open(img_path) # 读取该图片
if self.transform:
img = self.transform(img)
return img # 返回该样本
# 输入图片所在文件夹
mydataset = MyData(
root_dir='./images/', transform=img_transform
)
# data loader 数据载入
dataloader = DataLoader(
dataset=mydataset, batch_size=opt.batch_size, shuffle=True
)
# os.makedirs("./data/MNIST", exist_ok=True)
# dataloader = torch.utils.data.DataLoader(
# datasets.MNIST(
# "./data/MNIST",
# train=True,
# download=True,
# transform=transforms.Compose(
# [transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
# ),
# ),
# batch_size=opt.batch_size,
# shuffle=True,
# )
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, img in enumerate(dataloader):
imgs = img
# Adversarial ground truths
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False)
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
gen_imgs = generator(z)
# Loss measures generator's ability to fool the discriminator
g_loss = adversarial_loss(discriminator(gen_imgs), valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(real_imgs), valid)
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data[:25], "img2/%d.png" % batches_done, nrow=5, normalize=True)
总结
原始GAN网络直接将图片展开成一维向量,忽略了图片之间的相关性,之后DCGAN出现,可以将图片直接应用,无需展成一维向量。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)