
Python文本情感分析实战【源码】
Python文本情感分析引言: 情感分析:又称为倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,其中情感分析还可以细分为情感极性(倾向)分析,情感程度分析,主客观分析等。情感极性分析的目的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。比如我们标注数据集,标签为1表示积极情感,0位中立
Python文本情感分析
引言: 情感分析:又称为倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程,其中情感分析还可以细分为情感极性(倾向)分析,情感程度分析,主客观分析等。
情感极性分析的目的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
比如我们标注数据集,标签为1表示积极情感,0位中立情感,-1为消极情感。
一、实验前的准备:
其中数据集如下所示:

二、数据分析
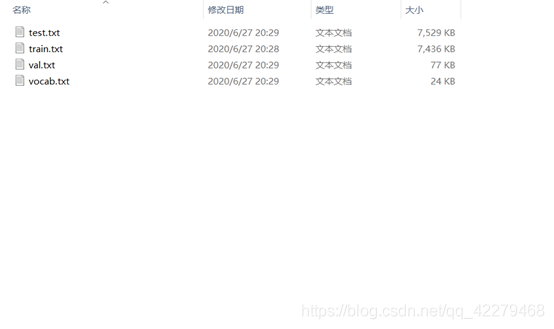
首先读取csv文件数据,存储入变量。统一存入TXT文件,以方便和清晰的看到训练和测试数据。见代码data.py。
'''生成TXT文件'''
for i in range(len(x_train)):
f=open("cnews/train.txt","a+",encoding='utf-8')
f.write(str(y_train.values[i])+"\t"+str(x_train [i])+"\n")
f.close()
print("train数据集生成完成!")
for i in range(len(x_test)):
f=open("cnews/test.txt","a+",encoding='utf-8')
f.write(str(float(y_test.values[i]))+"\t"+str(x_test [i])+"\n")
f.close()
print("test数据集生成完成!")
for i in range(len(x_train1)):
f=open("cnews/val.txt","a+",encoding='utf-8')
f.write(str(y_train1.values[i])+"\t"+str(x_train1 [i])+"\n")
f.close()
print("val数据集生成完成!")
最终生成了以下几个文档:
三、CNN算法分类
1、 特征提取流程:
详细见代码cnews_loader.py。
其中定义了以下函数,即为其整体流程。主要目的就是把文本转为词向量,建立id对应,因为只有数字才能计算。
read_file(): 读取文件数据;
build_vocab(): 构建词汇表,使用字符级的表示,这一函数会将词汇表存储下来,避免每一次重复处理;
read_vocab(): 读取上一步存储的词汇表,转换为{词:id}表示;
read_category(): 将分类目录固定,转换为{类别: id}表示;
to_words(): 将一条由id表示的数据重新转换为文字;
process_file(): 将数据集从文字转换为固定长度的id序列表示;
2、 模型算法:
主要见代码cnn_model.py。
这里我们使用深度学习模型CNN卷积神经网络提取特征。
其中需要设定的参数:
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 4 # 类别数
num_filters = 128 # 卷积核数目
kernel_size = 5 # 卷积核尺寸
vocab_size = 5000 # 词汇表达小
hidden_dim = 128 # 全连接层神经元
dropout_keep_prob = 0.5 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
然后是模型的初始化:
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.cnn()
神经网络整体定义,包括训练器的选择、卷积层、全连接等定义。
def cnn(self):
"""CNN模型"""
# 词向量映射
with tf.device('/cpu:0'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("cnn"):
# CNN layer
conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv')
# global max pooling layer
gmp = tf.reduce_max(conv, reduction_indices=[1], name='gmp')
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(gmp, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
3、 模型训练:
模型的训练和测试都在代码test.py。218行注释掉test()函数,216行启用train()函数就是训练。
这里整体流程就是按照上面说的进行执行调用而言:
def train():
print("Configuring TensorBoard and Saver...")
# 配置 Tensorboard,重新训练时,请将tensorboard文件夹删除,不然图会覆盖
tensorboard_dir = 'tensorboard/textcnn'
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
tf.summary.scalar("loss", model.loss)
tf.summary.scalar("accuracy", model.acc)
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter(tensorboard_dir)
# 配置 Saver
saver = tf.train.Saver()
if not os.path.exists(save_dir):
os.makedirs(save_dir)
print("Loading training and validation data...")
# 载入训练集与验证集
start_time = time.time()
x_train, y_train = process_file(train_dir, word_to_id, cat_to_id, config.seq_length)
x_val, y_val = process_file(val_dir, word_to_id, cat_to_id, config.seq_length)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
# 创建session
session = tf.Session()
session.run(tf.global_variables_initializer())
writer.add_graph(session.graph)
print('Training and evaluating...')
start_time = time.time()
total_batch = 0 # 总批次
best_acc_val = 0.0 # 最佳验证集准确率
last_improved = 0 # 记录上一次提升批次
require_improvement = 1000 # 如果超过1000轮未提升,提前结束训练
flag = False
for epoch in range(config.num_epochs):
print('Epoch:', epoch + 1)
batch_train = batch_iter(x_train, y_train, config.batch_size)
for x_batch, y_batch in batch_train:
feed_dict = feed_data(x_batch, y_batch, config.dropout_keep_prob)
if total_batch % config.save_per_batch == 0:
# 每多少轮次将训练结果写入tensorboard scalar
s = session.run(merged_summary, feed_dict=feed_dict)
writer.add_summary(s, total_batch)
if total_batch % config.print_per_batch == 0:
# 每多少轮次输出在训练集和验证集上的性能
feed_dict[model.keep_prob] = 1.0
loss_train, acc_train = session.run([model.loss, model.acc], feed_dict=feed_dict)
loss_val, acc_val = evaluate(session, x_val, y_val) # todo
if acc_val > best_acc_val:
# 保存最好结果
best_acc_val = acc_val
last_improved = total_batch
saver.save(sess=session, save_path=save_path)
improved_str = '*'
else:
improved_str = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>6.2}, Train Acc: {2:>7.2%},' \
+ ' Val Loss: {3:>6.2}, Val Acc: {4:>7.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss_train, acc_train, loss_val, acc_val, time_dif, improved_str))
session.run(model.optim, feed_dict=feed_dict) # 运行优化
total_batch += 1
if total_batch - last_improved > require_improvement:
# 验证集正确率长期不提升,提前结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break # 跳出循环
if flag: # 同上
break
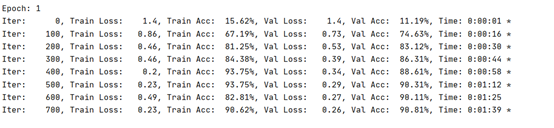
训练过程如下:
4、 模型测试:
读取test.txt评估模型准确率。216行注释掉train()函数,218行启用test()函数
def test():
print("Loading test data...")
start_time = time.time()
x_test, y_test = process_file(test_dir, word_to_id, cat_to_id, config.seq_length)
session = tf.Session()
session.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess=session, save_path=save_path) # 读取保存的模型
print('Testing...')
loss_test, acc_test = evaluate(session, x_test, y_test)
msg = 'Test Loss: {0:>6.2}, Test Acc: {1:>7.2%}'
print(msg.format(loss_test, acc_test))
batch_size = 128
data_len = len(x_test)
num_batch = int((data_len - 1) / batch_size) + 1
y_test_cls = np.argmax(y_test, 1)
y_pred_cls = np.zeros(shape=len(x_test), dtype=np.int32) # 保存预测结果
for i in range(num_batch): # 逐批次处理
start_id = i * batch_size
end_id = min((i + 1) * batch_size, data_len)
feed_dict = {
model.input_x: x_test[start_id:end_id],
model.keep_prob: 1.0
}
y_pred_cls[start_id:end_id] = session.run(model.y_pred_cls, feed_dict=feed_dict)
# 评估
print("Precision, Recall and F1-Score...")
categories = [native_content(x) for x in ['0.0', '1.0', '-1.0']]
print(metrics.classification_report(y_test_cls, y_pred_cls, target_names=categories))
# 混淆矩阵
print("Confusion Matrix...")
cm = metrics.confusion_matrix(y_test_cls, y_pred_cls)
print(cm)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
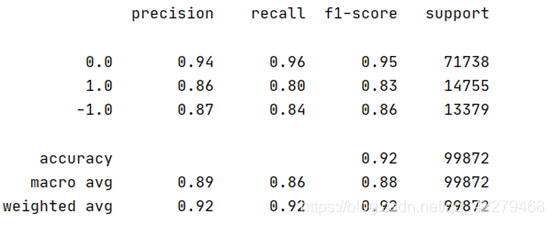
测试结果如下:最终模型准确度92%
https://blog.csdn.net/qq_42279468/article/details/129427284

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 23
23 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)