
神经网络中如何确定隐藏层的层数和大小
在前馈神经网络中,隐藏层的数量和层数的确定尚无依据,一般是由经验决定。查阅了大量相关的文章之后我对其进行了综合梳理。这里需要明确的一点是,这些只是根据经验提出的一些参考的方法,具体的层数和大小还是要在实际实验中进行验证。二分类问题方法出自:Beginners Ask “How Many Hidden Layers/Neurons to Use in Artificial Neural Networ
在前馈神经网络中,隐藏层的数量和层数的确定尚无依据,一般是由经验决定。
查阅了大量相关的文章之后我对其进行了综合梳理。
这里需要明确的一点是,这些只是根据经验提出的一些参考的方法,具体的层数和大小还是要在实际实验中进行验证。
在此之前我们还需要理解一点,就是当我们神经元足够多,隐藏层足够多的时候我们甚至能完美拟合所有的点,但是也会带来过拟合的问题。因此我们要把握一个适中的度。
二分类问题
方法出自:Beginners Ask “How Many Hidden Layers/Neurons to Use in Artificial Neural Networks?”1
对于二分类比较好理解。但是我对这个方法持保留态度。
先看下边这两类,我们只需要一条斜线就可以完成映射。所以不需要隐藏层,直接input到output即可。


对于这样要靠两个方向的直线才能分开的这样想:一个神经元只能学习一条方向的直线,所以两个方向需要两个神经元,最后把两个方向的神经元拼起来获得最后的分割线。
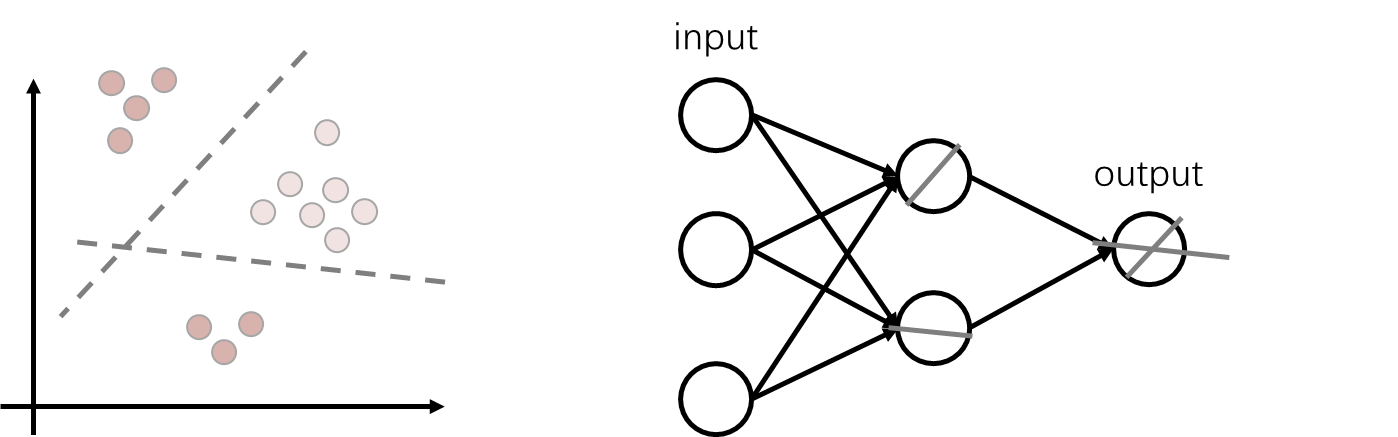
以此类推,第一个隐藏层学到单方向的直线,第二个隐藏层将两条线拼接,以此类推直到最后都拼接起来。
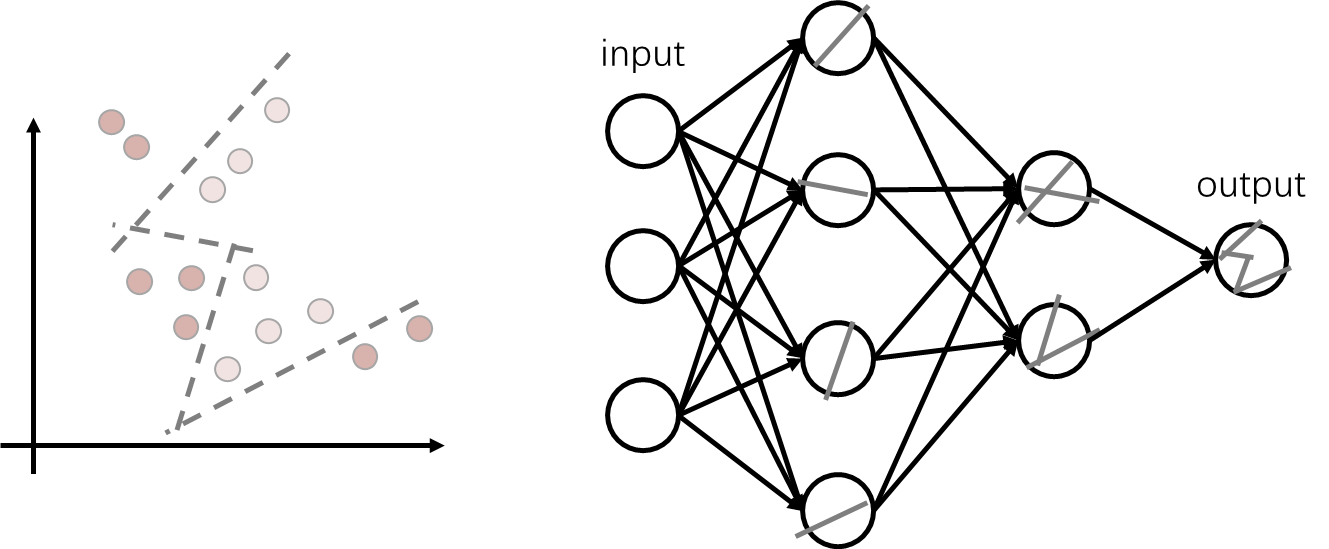
但是对于这个我存在一个疑问,二分类问题本来就很简单了,需要那么多层隐藏层吗?我觉得根本没必要那么多层隐藏层。
虽然从理论上说,层数越多拟合函数越强,但是实际上更深的层数可能会带来过拟合的问题,同时也会增加训练难度,使模型难以收敛。
回归问题
评论区有人问回归问题怎么设置网络。
❓ 不就是画一条线 把他们分开变成画一条线把他们连起来吗……
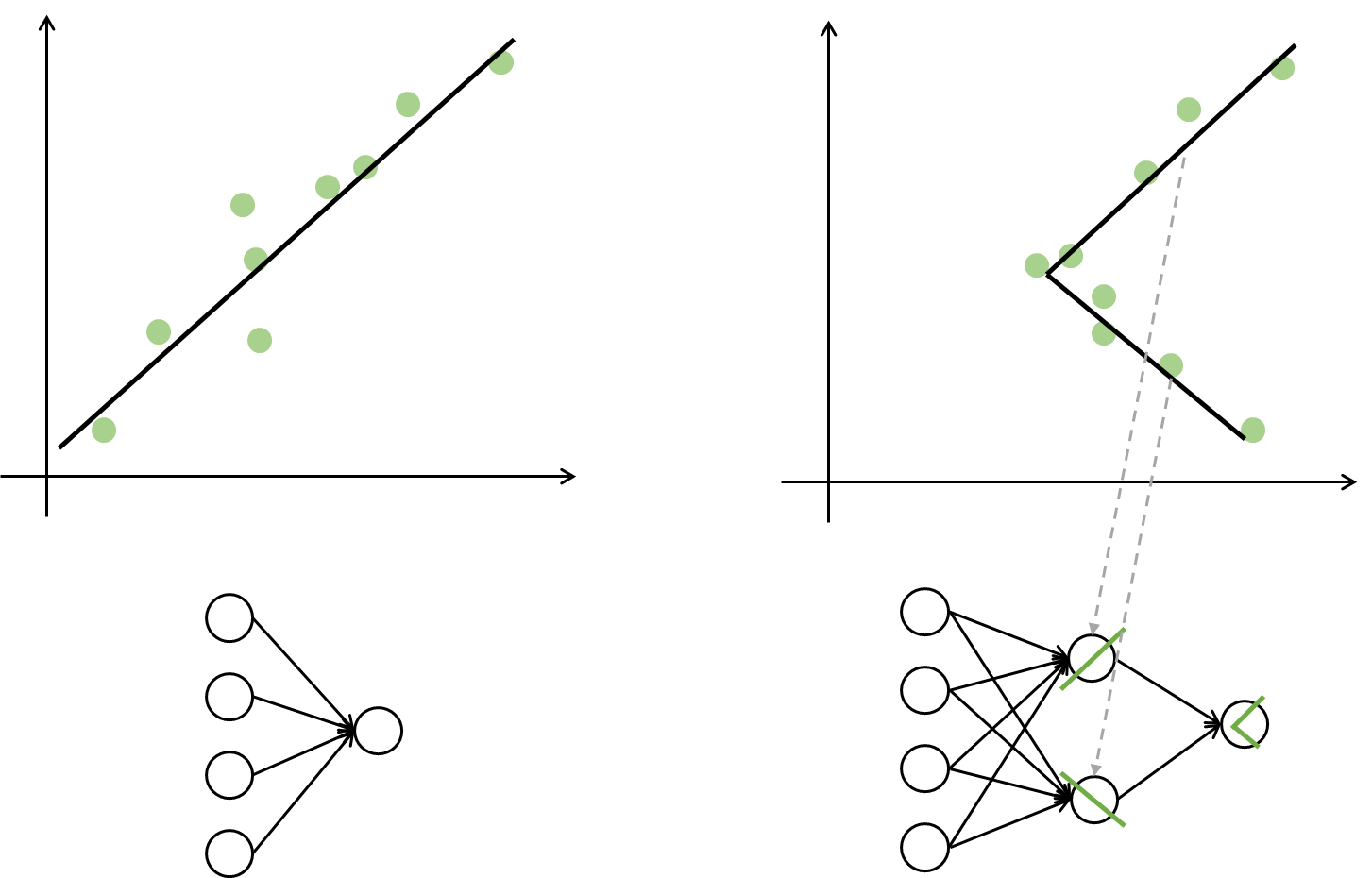
隐藏层数量
从上边我们可以得到一个结论:在神经网络中,当数据需要非线性分离的时候才需要隐藏层。
什么是线性?
2
对于隐藏层的层数我找到一个说法:
Table: Determining the Number of Hidden Layers3
| Num Hidden Layers | Result |
|---|---|
| none | Only capable of representing linear separable functions or decisions. |
| 1 | Can approximate any function that contains a continuous mapping from one finite space to another. |
| 2 | Can represent an arbitrary decision boundary to arbitrary accuracy with rational activation functions and can approximate any smooth mapping to any accuracy. |
| >2 | Additional layers can learn complex representations (sort of automatic feature engineering) for layer layers. |
翻译过来就是:
- 没有隐藏层:仅能表示线性可分离函数或决策。
- 1 可以近似任何包含从一个有限空间到另一个有限空间的连续映射的函数。
- 2 可以使用有理激活函数将任意决策边界表示为任意精度,并且可以将任何平滑映射近似到任何精度。
- >2 可以学习的复杂特征。
多分类
如果二分类可以按照上述方法进行计算,那多分类如何搞?
现在比较常见的方法是根据输入层和输出层的大小进行估算。
现在假设:
- 输入层大小为 n n n
- 输出层分为 m m m类
- 样本数量为 s s s
- 一个常数 c c c
常见的观点有隐藏层神经元个数 h h h:
- h = s c ( n + m ) c ∈ [ 2 , 10 ] h = \frac{s}{c(n+m)} \quad c \in [2,10] h=c(n+m)sc∈[2,10]
- h = n + m + c c ∈ [ 1 , 10 ] h = \sqrt{n+m} + c \quad c \in [1,10] h=n+m+cc∈[1,10]
- h = n m h = \sqrt{nm} h=nm
- h = log 2 n h = \log_2n h=log2n
- h = 1.5 ∗ n h = 1.5*n h=1.5∗n
- h = 1.5 ∗ ( n + m ) h = 1.5*(n+m) h=1.5∗(n+m)
- h < 2 n h<2n h<2n
- ……
还有一些其他的观点但是我个人不太同意:
- m i n ( m , n ) < h < m a x ( m , n ) min(m,n)<h<max(m,n) min(m,n)<h<max(m,n)
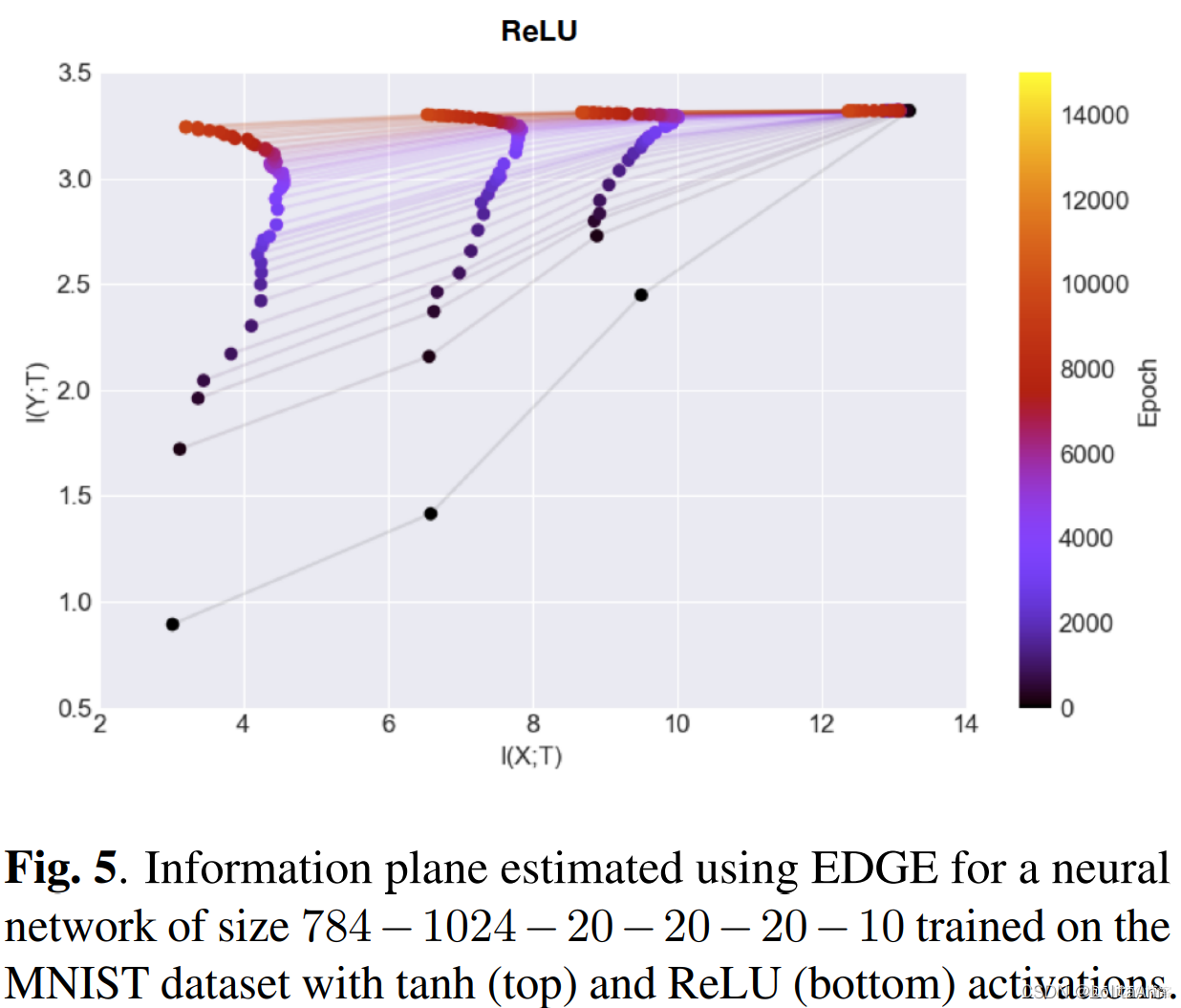
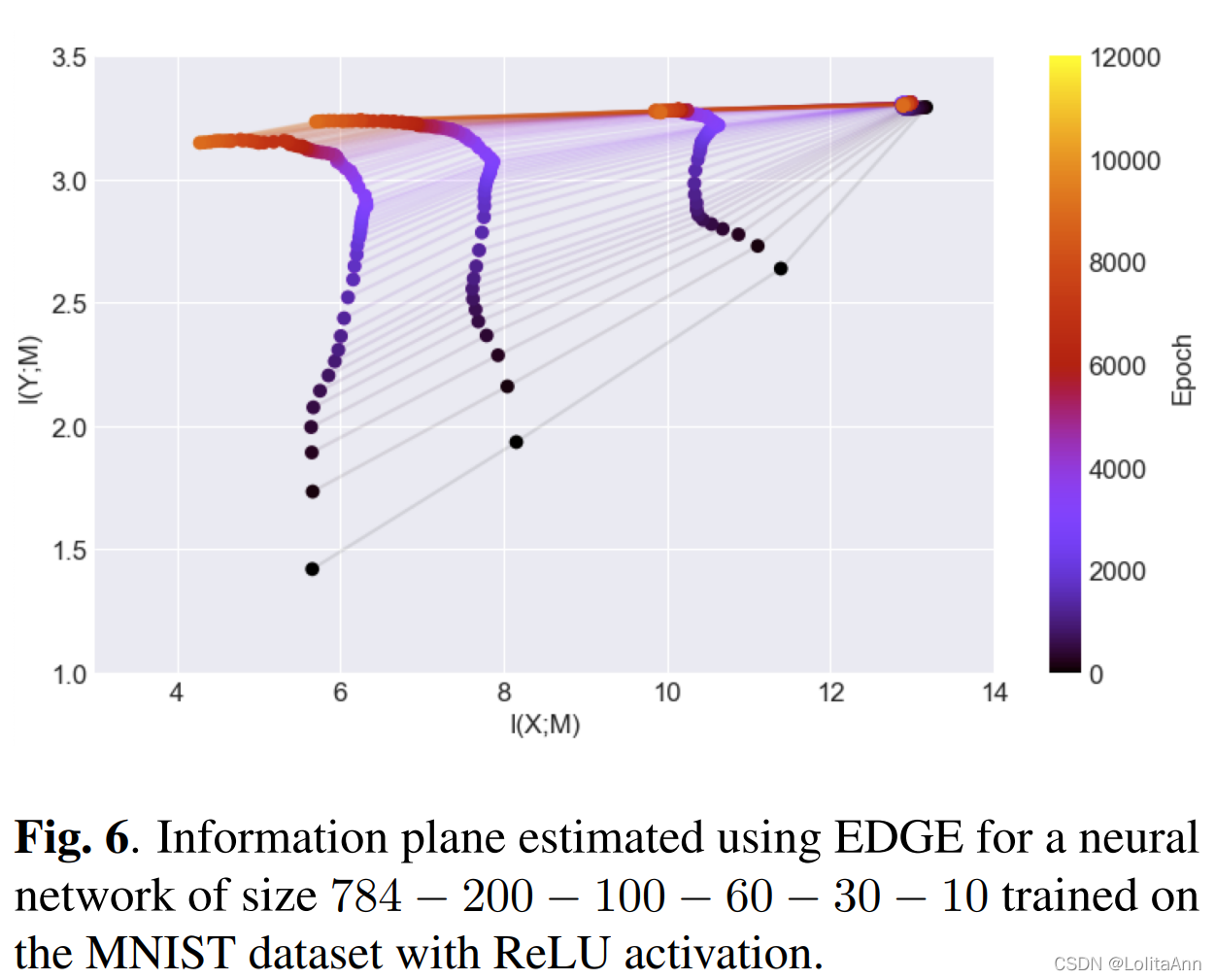
因为看了这么一个文章4,文中提到这MINST么一篇论文:SCALABLE MUTUAL INFORMATION ESTIMATION USING DEPENDENCE GRAPHS5
在下边两幅图中,都是使用ReLU做激活函数的神经网络,横坐标从右到左表示压缩率,最右边表示网络第一层,最左边表示网络最后一层,越往左表示压缩效果越好。可以看出隐藏层先增大后减小的压缩效果比逐渐减小的压缩效果更好。
由于文中使用MNIST做的实验,我们可以知道增大的过程中明显大于输入层的大小( 1024 > 28 ∗ 28 1024>28*28 1024>28∗28),更大于输出层的类别数。
这不是个例,通常在CNN中都是使用先增大后减小的隐藏层数量,并且隐藏层的大小都大于
m
a
x
(
n
,
m
)
max(n,m)
max(n,m)。
Beginners Ask “How Many Hidden Layers/Neurons to Use in Artificial Neural Networks?” ↩︎
《线性代数的几何意义》任广千 ↩︎
SCALABLE MUTUAL INFORMATION ESTIMATION USING DEPENDENCE GRAPHS ↩︎
我是萝莉安,😢我好忙我居然还在写博客。点个赞再走吧。让更多人看到这个文章。 ↩︎

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 79
79 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)