
理解MaxPool最大池化的作用与反向传播
目前网络中运用最多的pool操作就是maxpool,最大池化。最开始经典的网络用的较多的是平均池化。操作与机制都差不多,一个是取最大值,一个是取平均值。作为小白的我最近看文章脑子里浮现出几个问题:池化层(我们以最大池化为例)的作用池化层如何通过反向传播池化层的最直观的作用就是降维、减少参数量、去除冗余信息、对特征进行压缩、简化网络复杂度、减少计算量、减少内存消耗等等。《动手学习深度学习》一书中还提
目前网络中运用最多的pool操作就是maxpool,最大池化。最开始经典的网络用的较多的是平均池化。操作与机制都差不多,一个是取最大值,一个是取平均值。
作为小白的我最近看文章脑子里浮现出几个问题:
- 池化层(我们以最大池化为例)的作用
- 池化层如何通过反向传播
池化层的最直观的作用就是降维、减少参数量、去除冗余信息、对特征进行压缩、简化网络复杂度、减少计算量、减少内存消耗等等。
《动手学习深度学习》一书中还提到了这样一个作用: 缓解卷积层对位置的过度敏感性,实际上就是特征不变性。以下是书上的解释(pytorch版的《动手学》):


能不能理解成增大了感受野呢?通过下采用或者不填充(padding)的卷积操作,会使感受野增大,感受野增大对特征位置的鲁棒性也强了。这也是为什么一般网络的feature map都有一定的下采样率,而没有保留原图的size。
在思考第二个问题,如何反向传播的时候,我发现了(其实有的资料早有了)它好像还有另外一个作用?后来我查阅一些资料也证实了这个作用的存在,来看看我的理解对不对。
先看看这个操作怎么反向传播?反向传播这个高大上的机制通俗一点就是在求多元微分(权重的偏导数),但是这个最大池化的操作肯定是不能进行求导操作的吧。那怎么反向传播的呢?直到动手画了下面这个图,茅塞顿开!!!我们把卷积层类比成全连层,并加入类似最大池化层的操作。
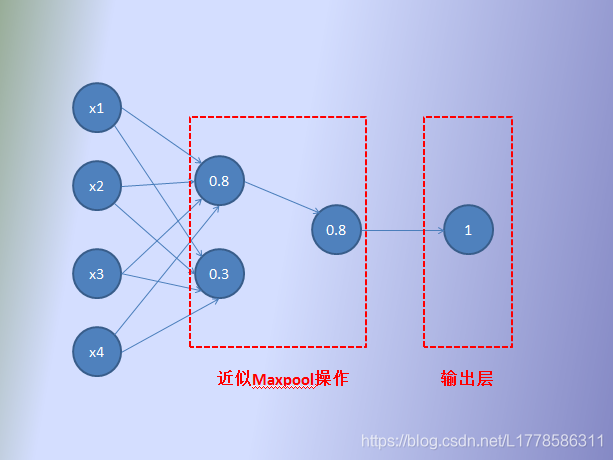
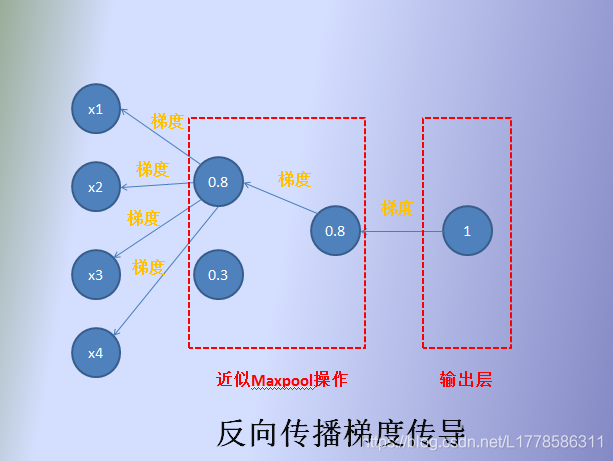
如上图所示:通过了最大池化操作保留下来的神经元对输出才有贡献,这样反向传播的时候就更新该保留下来的神经元以及与之有关的权重,其他的不更新。这是不是跟全连层某个操作很类似?dropout层!dropout层根据一定概率抛弃某些神经元使得网络不能过于依赖某些神经元的特征(万一是噪声或是其他无用的特征,多度依赖就不好了),从而达到减缓过拟合的效果。从面类似最大池化的操作没有通过概率抛弃,取而代之的是根据最大值来筛选,剩下的神经元抛弃,真有其曲同工之妙!
这也就解释了池化层的另一个作用:防止或者说缓解过拟合
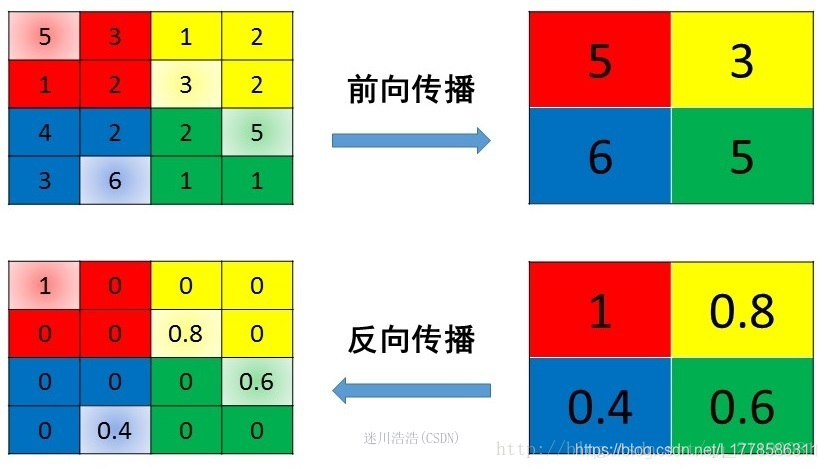
借用别人一张图,懒得画了,谢谢原图主人。最大池化在在CNN中呈现的样子类似下图。

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)