
强化学习(Q-learning)
强化学习RF简介强化学习是机器学习中的一种重要类型,一个其中特工通过 执行操作并查看查询查询结果来学习如何在环境中表现行为。机器学习算法可以分为3种:有监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning),如下图所示:有监督学习、无监督学习、强化学习具有不同的特点:有监督学习是有一个l
强化学习RF简介
强化学习是机器学习中的一种重要类型,一个其中特工通过 执行操作并查看查询查询结果来学习如何在环境中表现行为。
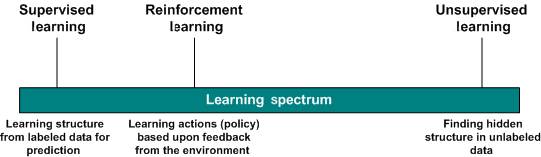
机器学习算法可以分为3种:有监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning),如下图所示:
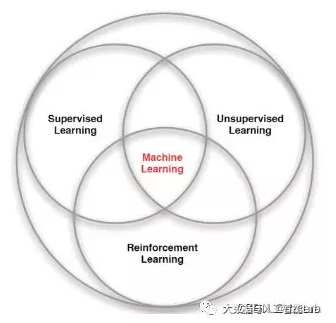 有监督学习、无监督学习、强化学习具有不同的特点:
有监督学习、无监督学习、强化学习具有不同的特点:
有监督学习是有一个label(标记)的,这个label告诉算法什么样的输入对应着什么样的输出,常见的算法是分类、回归等;
无监督学习则是没有label(标记),常见的算法是聚类;
强化学习强调如何基于环境而行动,以取得最大化的预期利益。
主要学习内容:
强化学习是什么,奖励思想。
强化学习的三种途径。
深度强化学习的“深”是什么意思
强化学习基础知识
①强化学习是做出最佳决策的科学。它可以帮助我们制定活的物种所表现出的奖励动机行为。比方说,你想让一个孩子坐下来学习考试。要做到这一点非常困难,但是如果每次完成一章/主题时都给他一块巧克力,他就会明白,如果他继续学习,他会得到更多的巧克力棒。所以他会有一些学习考试的动机。
②孩子代表着Agent代理 。奖励制度和考试代表了Environment环境。今天的题目是类似于强化学习的States状态。所以,孩子必须决定哪些话题更重要(即计算每种行为的价值)。这将是我们的工作的 Value-Function价值方程。所以,每次他从一个国家到另一个国家旅行时,他都会得到Reward奖励,他用来在时间内完成主题的方法就是我们的Policy决策。
与其他机器学习的不同
没有主管在场。所以,没有人会告诉你最好的行动。您只需为每个动作获得奖励。
时间的重要性。强化学习不同于其他您接收随机输入的范例时对顺序数据的关注。这里下一步的输入将始终取决于之前状态的输入。
延迟奖励的概念。您可能无法在每一步获得奖励。只有在完成整个任务后才能给予奖励。另外,假设你只是在一个步骤中获得奖励,才能发现你在未来的一步中犯了大错。
代理人行为影响其下一个输入。说,你可以选择向左或向右。在你采取行动之后,如果你选择了正确的而不是离开,下一步的输入将会不同。
简单实例
与环境相互作用的学习来自我们的自然体验。想象一下,你是一个起居室里的孩子。你看到一个壁炉,然后你接近它。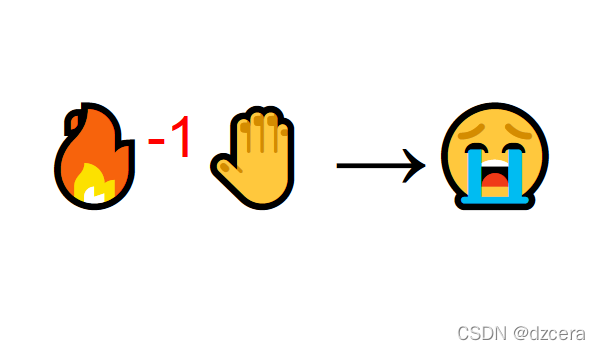
这是温暖的,这是积极的,你感觉很好(正面奖励+1)。你明白,火是一件好事。
但是,然后你尝试触摸火灾。哎哟! 它烧你的手(负面奖励-1)。你刚刚明白,当你离开足够的距离时,火是正面的,因为它会产生温暖。但太接近它,你会被烧毁。
这就是人类通过互动学习的方式。强化学习只是一种从行动中学习的计算方法。
强化学习过程
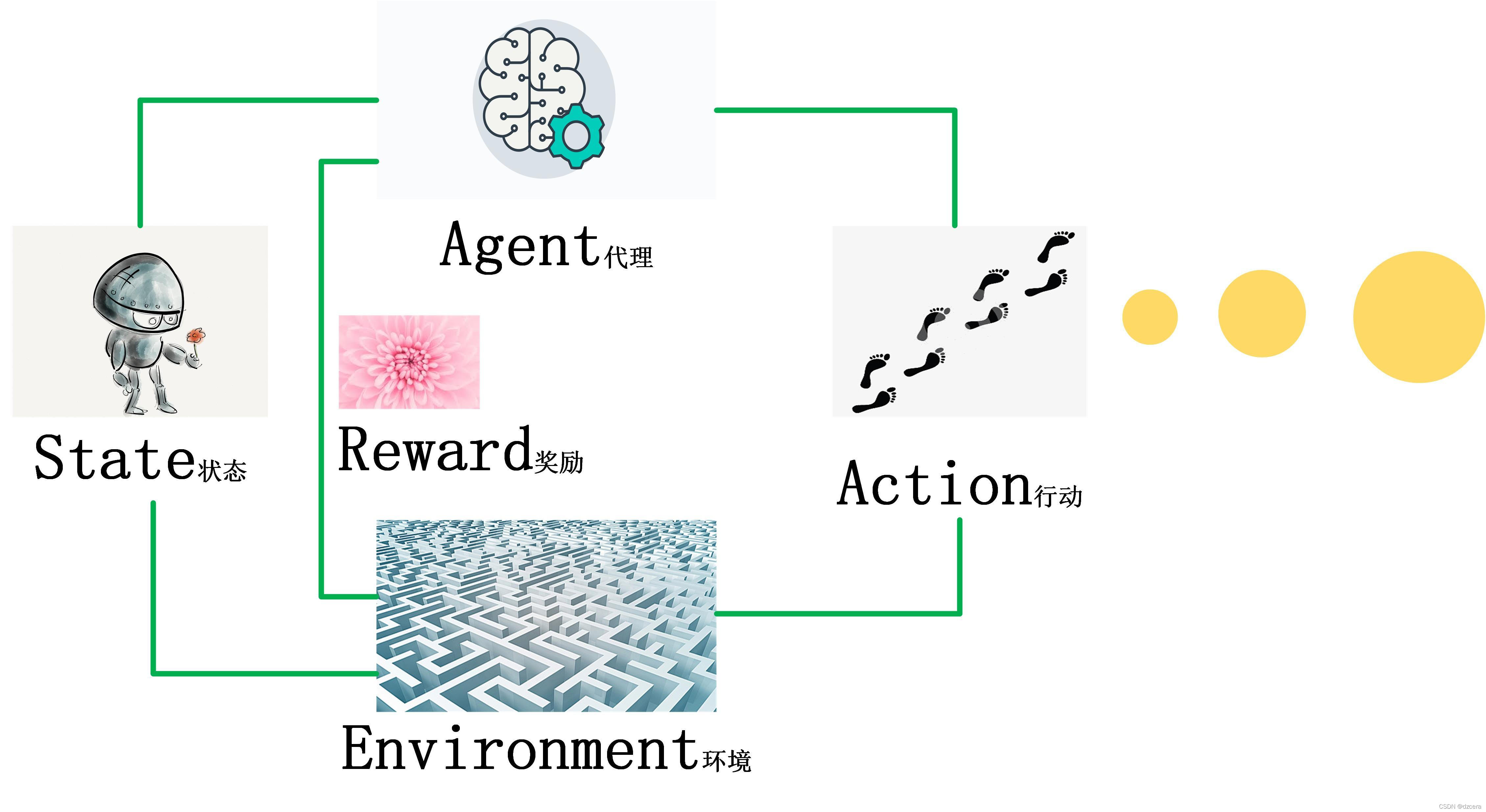
agent从环境中收集机器人的初始状态S0;
基于S0状态,采取行动A0;
转换到新的环境,状态S1;
从环境中获取奖励R1,以此循环。
{S0,A0,R1,S1,A1,R2,S2,…}
这意味着Agent处于状态S0并且采取行动A0,从而导致其获得奖励R1并处于状态S1; 那么它执行了A1,收到奖励R2,最后进入状态S2; 那么它执行了A2,收到奖励R3,并最终进入状态S3、、、等等。我们把这种互动的历史看作是一系列经验的体验,其中经验是一个元组: ⟨S,A,R,S⟩。
相应的Q-LEARNING算法就是由一些列的【状态、动作、奖励】组成,Agent的最终目标是最大限度地提高总体的回报。
Q函数 状态动作函数
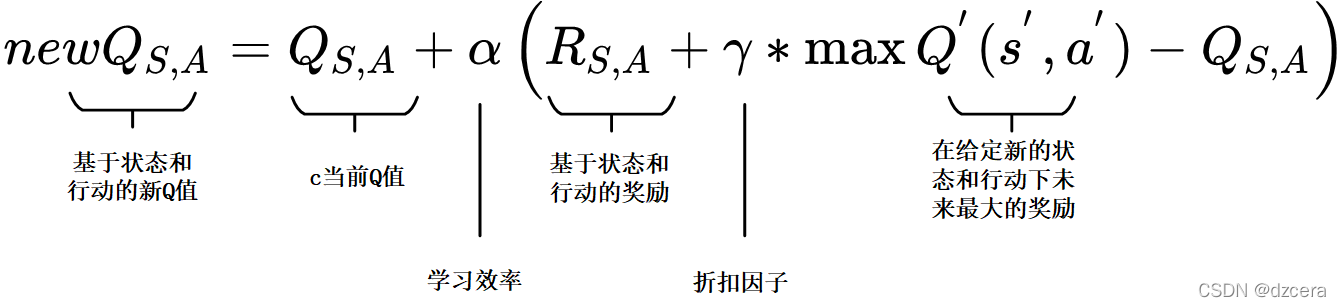
在Q -值函数包含了两个可以操作的因素。
首先是一个学习率 learning rate(alpha),它定义了一个旧的Q值将从新的Q值哪里学到的新Q占自身的多少比重。值为0意味着代理不会学到任何东西(旧信息是重要的),值为1意味着新发现的信息是唯一重要的信息。
下一个因素被称为折扣因子discount factor(伽马),它定义了未来奖励的重要性。值为0意味着只考虑短期奖励,其中1的值更重视长期奖励。

主要算法
- Sarsa
Q 为动作效用函数(action-utility function),用于评价在特定状态下采取某个动作的优劣,可以将之理解为智能体(Agent)的大脑。
SARSA 利用马尔科夫性质,只利用了下一步信息, 让系统按照策略指引进行探索,在探索每一步都进行状态价值的更新。
s 为当前状态,a 是当前采取的动作,s’ 为下一步状态,a’ 是下一个状态采取的动作,r 是系统获得的奖励, α 是学习率, γ 是衰减因子。
- Q learning
Q Learning 的算法框架和 SARSA 类似, 也是让系统按照策略指引进行探索,在探索每一步都进行状态价值的更新。关键在于 Q Learning 和 SARSA 的更新公式不一样。
- Policy Gradients
系统会从一个固定或者随机起始状态出发,策略梯度让系统探索环境,生成一个从起始状态到终止状态的状态-动作-奖励序列,s1,a1,r1,…,sT,aT,rT,在第 t 时刻,我们让 gt=rt+γrt+1+… 等于 q(st,a) ,从而求解策略梯度优化问题。
- Actor-Critic
算法分为两个部分:Actor 和 Critic。Actor 更新策略, Critic 更新价值。Critic 就可以用之前介绍的 SARSA 或者 Q Learning 算法。
- Monte-carlo learning
用当前策略探索产生一个完整的状态-动作-奖励序列:
s1,a1,r1,…,sk,ak,rk∼π
在序列第一次碰到或者每次碰到一个状态 s 时,计算其衰减奖励,最后更新状态价值。
- Deep-Q-Network
DQN 算法的主要做法是 Experience Replay,将系统探索环境得到的数据储存起来,然后随机采样样本更新深度神经网络的参数。它也是在每个 action 和 environment state 下达到最大回报,不同的是加了一些改进,加入了经验回放和决斗网络架构。
参考资料
强化学习简介【An introduction to Reinforcement Learning】
强化学习的基础知识【The very basics of Reinforcement Learning】
计算机如何学习使用Q学习来计算预期的未来回报?
培训一名软件代理人,以加强学习的合理行为【Train a software agent to behave rationally with reinforcement learning】
强化学习:Q-learning由浅入深:简介1 - wiliken的文章 - 知乎
https://zhuanlan.zhihu.com/p/35724704
强化学习:Q-learning由浅入深:入阶2 - wiliken的文章 - 知乎
https://zhuanlan.zhihu.com/p/35770507
人工智能学习笔记一之强化学习(Q-learning)

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)