
YOLOv5训练自己的数据集详解
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。一、YOLOv5源码下载网址指路:GitHub - ultralytics/yolov5: YOLOv5 ???? in PyTorch > ONNX > CoreML > TFLite用git克隆下来二、环境配置文件夹中有一个文件requirements.txt,这里是环境依
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、YOLOv5源码下载
网址指路:GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
用git克隆下来
二、环境配置
文件夹中有一个文件requirements.txt,这里是环境依赖的说明
我们在终端输入pip install -r requirements.txt下载安装依赖包
三、创建数据集
根据你的需要创建自己的数据集
这里可以看看往期博客
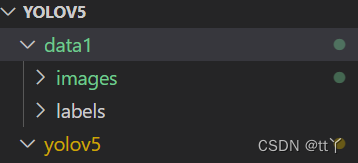
在YOLOv5目录下创建文件夹data1来装我们的数据
然后data1下是images和labels
顺便提一嘴:其中labels中的txt文件里面代表的是:每一行代表标注的一个目标,第一个数字代表着这个数的类别,后面的四个数字是归一化后的的标注的中心点坐标(x,y)和归一化标注框的宽和高(w,h)。
注:这里文件夹名尽量是images和labels,不然会有各种报错,懒得去找哪里的原因,先让他跑起来吧(label也会报错,加了个s后他就乖了)

四、更改配置
1、coco128.yaml
他的默认训练集是coco128,所以我为了偷懒,直接在coco128.yaml里改成我的![]()

coco128.yaml文件在yolov5/data文件夹里
以下是我的配置情况
path: ../data1 # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/train # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 4 # number of classes
names: ['move','point','up','down'] # class namespath:相对于在yolov5目录下而言,你的数据集文件夹的根
再次搬出这张图
我的data1在yolov5的上一个目录里,所以是../data1
train是训练的数据集路径,val是验证的数据集路径
这里我按照原来的coco128.yaml,这两个是同一份
所以相对于path而言是images/train(我的images文件夹中还有一个train文件夹,然后里面才是我的图片)
nc:是你要检测有多少类
names是这些类的名字
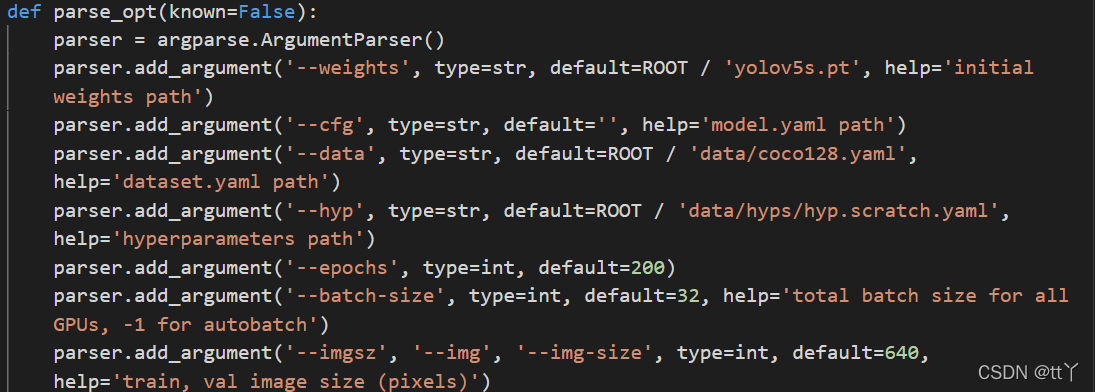
2、train.py
一般也只需要改这些了
weights是你选择的模型
data:因为我用的是coco128.yaml本身,所以我不用改~
epochs和batch-size你看着办吧
epochs是训练过程中整个数据集将被迭代多少次,显卡不行就调小些
batch-size:一次看完多少张图片才进行权重更新,同样的显卡不行就调小些
五、跑起来
在终端里cd到yolov5目录里(因为train.py在该目录下)
然后直接python train.py就好啦
接着就是等待~漫长的等待~
![]()
六、结果呈现
最终训练完毕后会在yolov5目录下生成一个runs文件夹
里面有各种各样的结果产生,我就不多说了
只说一个weights文件夹里的best.pt和last.pt
这些是权重文件,是训练后的模型保存,可以直接在detect.py文件中用起来
同样在终端输入
python detect.py --source 0 --weights runs/train/exp/weights/best.pt这里的source 0指的是电脑摄像头为源,然后就可以最直观的看看训练成果啦~
欢迎大家在评论区批评指正,谢谢~

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 40
40 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)