

中文电子病历命名实体识别
中文电子病历命名实体识别
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
1 项目介绍
在本项目中将会介绍如何使用BERT+BiLSTM+CRF模型,实现对中文电子病历中病症、体征、疾病、身体部位等命名实体进行抽取。
1.1 项目背景
电子病历主要有入院记录、出院记录、病程记录、手术记录、护理记录、查房记 录等组成,除部分字段进行了前结构化,还有大量的字段没有进行结构化,以自由文本的方式进 行记录,比如主诉,现病史,既往史,查房记录,用药信息等。该部分记录中含有大量的有用信息,是进行医疗大数据挖掘、临床辅助决策系统、AI 电子病历质控系统构建等的基础工作。命名实体的结果可以辅助人们识别并解释晦涩难懂的医疗术语,方便人们了解和认识医学知识,因此,电子病历命名实体识别对医学研究、医疗诊断和患者都具有重要意义。
1.2 应用场景
- 医疗大数据挖掘
- 构建医疗知识图谱
- 临床辅助决策系统
- AI 电子病历质控系统构
- 多病因联合分析
2 数据集
本项目开放了标注数据,data_origin.zip文件,数据集中包含一般情况、出院情况、病史特点、诊疗经过四种数据。以txtoriginal.txt结尾的文件是原始文本数据,直接是.txt结尾的文件是标注数据。
数据集包含的实体类型:
- 检查和检验-CHECK
- 症状和体征-SIGNS
- 疾病和诊断-DISEASE
- 治疗-TREATMENT
- 身体部位-BODY
数据集采用了BIO标注方式。BIO标注方式是一种常用的序列标注方法,用于对文本或语音等序列数据中的实体或事件进行标注。在BIO标注方式中,每个标记表示一个词或字符是否属于某个实体或事件,标记由三个部分组成:B(开始)、I(内部)和O(外部)。B表示该词或字符是某个实体或事件的开头(Beginning),I表示该词或字符属于某个实体或事件的中间部分(Inside),O表示该词或字符不属于任何实体或事件(Outside)。
对“全腹部压痛。”标注结果如下图所示:

其中B-BODY表示身体部位实体的开始,I-BODY表示身体部位实体的内部,O表示不属于任何实体部分。
2.1数据处理
通过构造TransferData对象,并调用transfer()方法将标注数据转换成BIO标注格式的数据,同时以7:3的比例划分训练集和验证集,再调用save_label_files()方法生成标签名,标签等映射文件,这些训练集(train.txt),验证集(eval.txt)和映射文件都保存在paddle_ner/data目录。data目录中的文件都会公开出来,没有其他需求可直接使用处理好的数据集,如果要修改数据集划分比例,请修改TransferData.divide_dataset()方法中的数据,并找到处理数据的cell执行即可。
在调用时注意相关文件路径。
3 模型选择
本项目使用BERT+BiLSTM+CRF实现命名实体识别
3.1 BERT模型
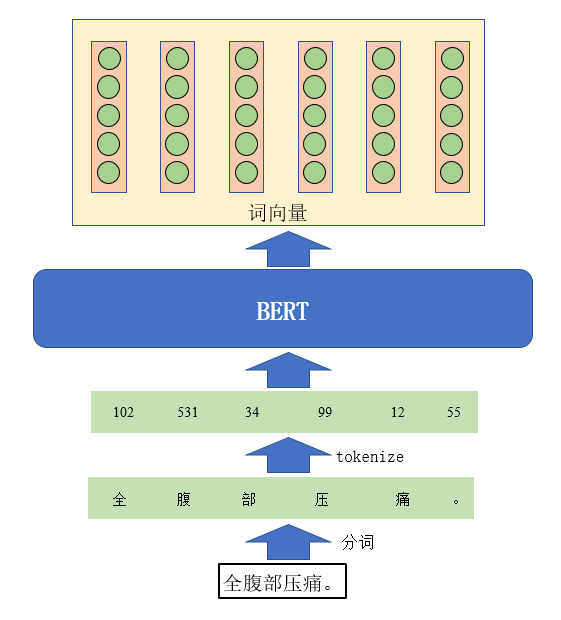
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言模型,由Google在2018年提出。它的核心思想是在大规模文本数据上进行预训练,从而得到丰富的上下文相关的词向量表示。这些预训练的模型参数可以通过微调来适应各种自然语言处理任务,如文本分类、问答系统、命名实体识别等。
BERT的模型架构基于Transformer模型,它使用Transformer编码器来对输入的文本进行处理。其中,BERT模型分别在单词级别和句子级别上进行预训练,以获得上下文相关的词向量表示。
本实验利用BERT模型获取输入文本中每个词的Embedding向量,主要过程如上图所示。
数据处理的第一步就是将输入的文本进行分词,分词通常分为词级和字级分词,实验中选用的字级分词,即将句子中每一个字符分隔开,BERT模型比较大且复杂再加上使用的预训练模型,很容易学会字之间的关系。
经过分词处理之后,需要将其进行tokenize,此操作十分简单,BertTokenizer中通常会维护一个包含了大量字、词的词典,进行tokenize时,Tokenizer会根据字或词去查找其对应的ID,然后用ID来表达这个词,此操作的目的是将文本字符ID化,方便模型的处理。
然后只需要将tokenize的结果送入到BERT模型,经过模型的运算就能得到输入句子中每一个字符的词向量。通常词向量的维度不是一个固定值,可以根据具体情况进行设置。
3.2 BiLSTM+CRF
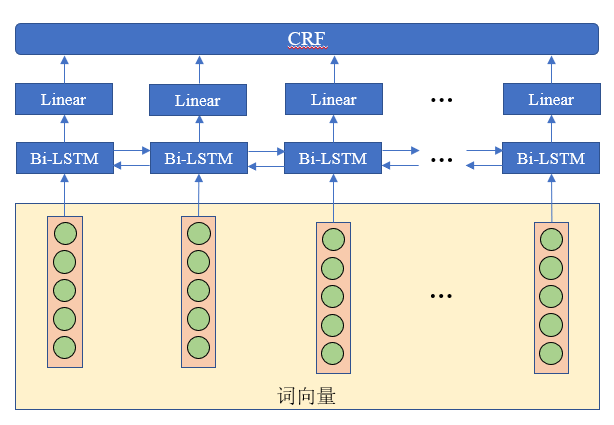
实验中使用BiLSTM网络实现对序列双向特征提取,使用CRF实现对标注序列解码。
BiLSTM模型能够对输入序列进行双向建模,即同时考虑从前往后和从后往前的上下文信息,并输出每个时刻的隐状态。这些隐状态可以被看作是对输入序列的抽象表示,用于捕捉序列的双向特征信息。
CRF是一种序列标注方法,它考虑了标签之间的依赖关系,通过在所有可能的标注序列中选择概率最大的标注序列来进行预测。在BiLSTM-CRF中,BiLSTM输出的隐状态序列通过一个线性层,CRF接受线形层的输出,对每个时刻预测对应的标签,同时考虑标签间的依赖关系,得到最终的标注序列。
3.3 模型整体结构
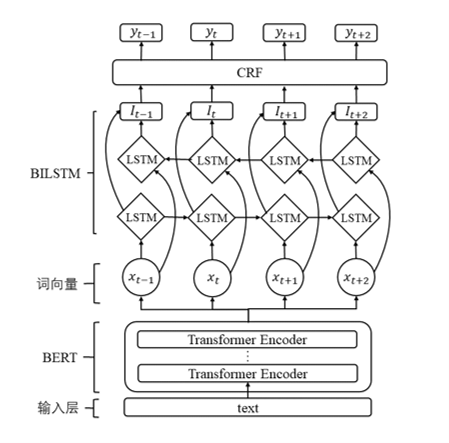
项目的主要任务是从大量的文本数据中提取出命名实体,模型上选用BERT+BiLSTM+CRF网络,首先使用数据集对BERT-wwm模型进行微调,用微调后的BERT模型对输入做Embedding来获得句向量,最后使用双向长短期记忆网络(BiLSTM)和条件随机场(CRF)实现实体识别。
4 项目实施
4.1 解压数据文件
# 解压数据文件
!unzip -oq /home/aistudio/paddle_ner/data_origin.zip -d paddle_ner
# 更新依赖paddlenlp==2.3.4,旧版本会报错
!pip install paddlenlp==2.3.4
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting paddlenlp==2.3.4
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/8e/e1/94cdbaca400a57687a8529213776468f003b64b6e35a6f4acf6b6539f543/paddlenlp-2.3.4-py3-none-any.whl (1.4 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m1.4/1.4 MB[0m [31m1.9 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0mm
[?25hCollecting datasets>=2.0.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/24/57/6b07e4dc51479ae3e9bbc774af348b0307e2b66957ceae94d25e3f9d7dcf/datasets-2.8.0-py3-none-any.whl (452 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m452.9/452.9 kB[0m [31m1.1 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: dill<0.3.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (0.3.3)
Requirement already satisfied: seqeval in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (1.2.2)
Requirement already satisfied: protobuf<=3.20.0,>=3.1.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (3.20.0)
Requirement already satisfied: tqdm in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (4.64.1)
Requirement already satisfied: sentencepiece in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (0.1.96)
Requirement already satisfied: colorama in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (0.4.4)
Requirement already satisfied: multiprocess<=0.70.12.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (0.70.11.1)
Requirement already satisfied: paddle2onnx in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (1.0.0)
Requirement already satisfied: colorlog in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (4.1.0)
Requirement already satisfied: paddlefsl in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (1.0.0)
Requirement already satisfied: jieba in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlenlp==2.3.4) (0.42.1)
Requirement already satisfied: numpy>=1.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (1.19.5)
Requirement already satisfied: importlib-metadata in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (4.2.0)
Requirement already satisfied: packaging in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (21.3)
Collecting aiohttp
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7a/48/7882af39221fee58e33eee6c8e516097e2331334a5937f54fe5b5b285d9e/aiohttp-3.8.3-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (948 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m948.0/948.0 kB[0m [31m1.5 MB/s[0m eta [36m0:00:00[0m00:01[0m00:01[0m
[?25hRequirement already satisfied: requests>=2.19.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (2.24.0)
Requirement already satisfied: pyarrow>=6.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (10.0.1)
Collecting huggingface-hub<1.0.0,>=0.2.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/a0/0b/e4c1165bb954036551e61e1d7858e3293347f360d8f84854092f3ad38446/huggingface_hub-0.11.1-py3-none-any.whl (182 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m182.4/182.4 kB[0m [31m655.8 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: pandas in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (1.1.5)
Collecting xxhash
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/7f/9f/8645235cc0913d54eb38599e9bfbd884de6f430cd1a3217530ccb6cc1800/xxhash-3.2.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (213 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m213.1/213.1 kB[0m [31m640.7 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hCollecting responses<0.19
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/79/f3/2b3a6dc5986303b3dd1bbbcf482022acb2583c428cd23f0b6d37b1a1a519/responses-0.18.0-py3-none-any.whl (38 kB)
Collecting fsspec[http]>=2021.11.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/37/57/eb7c3c10b187d3b8565946772ce0229c79e3c623010eda0aeb5032ff56f4/fsspec-2022.11.0-py3-none-any.whl (139 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m139.5/139.5 kB[0m [31m614.2 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: pyyaml>=5.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from datasets>=2.0.0->paddlenlp==2.3.4) (5.1.2)
Requirement already satisfied: pillow==8.2.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from paddlefsl->paddlenlp==2.3.4) (8.2.0)
Collecting paddlefsl
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/fb/4a/25d1959a8f1fe5ee400f32fc9fc8b56d4fd6fc25315e23c0171f6e705e2a/paddlefsl-1.1.0-py3-none-any.whl (101 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m101.0/101.0 kB[0m [31m365.5 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: scikit-learn>=0.21.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from seqeval->paddlenlp==2.3.4) (0.24.2)
Requirement already satisfied: typing-extensions>=3.7.4 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->datasets>=2.0.0->paddlenlp==2.3.4) (4.3.0)
Collecting multidict<7.0,>=4.5
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/47/e4/745fb4cc79b439b1c1d1f441f2aa65f6250b77052d2bf4d8d8b5970ee672/multidict-6.0.4-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (94 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m94.8/94.8 kB[0m [31m362.1 kB/s[0m eta [36m0:00:00[0m [36m0:00:01[0m
[?25hCollecting asynctest==0.13.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/e8/b6/8d17e169d577ca7678b11cd0d3ceebb0a6089a7f4a2de4b945fe4b1c86db/asynctest-0.13.0-py3-none-any.whl (26 kB)
Collecting charset-normalizer<3.0,>=2.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/db/51/a507c856293ab05cdc1db77ff4bc1268ddd39f29e7dc4919aa497f0adbec/charset_normalizer-2.1.1-py3-none-any.whl (39 kB)
Collecting frozenlist>=1.1.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/b2/18/3b0eb2690b3bf4d340a221d0e76b6c5f4cac9d5dd37fb8c7b6ec25c2f510/frozenlist-1.3.3-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (148 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m148.0/148.0 kB[0m [31m1.1 MB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hCollecting yarl<2.0,>=1.0
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/02/c6/13751bb69244e4835fa8192a20d1d1110091f717f1e1b0168320ed1a29c9/yarl-1.8.2-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (231 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m231.4/231.4 kB[0m [31m672.4 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hCollecting aiosignal>=1.1.2
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/76/ac/a7305707cb852b7e16ff80eaf5692309bde30e2b1100a1fcacdc8f731d97/aiosignal-1.3.1-py3-none-any.whl (7.6 kB)
Requirement already satisfied: attrs>=17.3.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from aiohttp->datasets>=2.0.0->paddlenlp==2.3.4) (22.1.0)
Collecting async-timeout<5.0,>=4.0.0a3
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/d6/c1/8991e7c5385b897b8c020cdaad718c5b087a6626d1d11a23e1ea87e325a7/async_timeout-4.0.2-py3-none-any.whl (5.8 kB)
Requirement already satisfied: filelock in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from huggingface-hub<1.0.0,>=0.2.0->datasets>=2.0.0->paddlenlp==2.3.4) (3.0.12)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from packaging->datasets>=2.0.0->paddlenlp==2.3.4) (3.0.9)
Requirement already satisfied: chardet<4,>=3.0.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.19.0->datasets>=2.0.0->paddlenlp==2.3.4) (3.0.4)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.19.0->datasets>=2.0.0->paddlenlp==2.3.4) (1.25.6)
Requirement already satisfied: idna<3,>=2.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.19.0->datasets>=2.0.0->paddlenlp==2.3.4) (2.8)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from requests>=2.19.0->datasets>=2.0.0->paddlenlp==2.3.4) (2019.9.11)
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1
Downloading https://pypi.tuna.tsinghua.edu.cn/packages/56/aa/4ef5aa67a9a62505db124a5cb5262332d1d4153462eb8fd89c9fa41e5d92/urllib3-1.25.11-py2.py3-none-any.whl (127 kB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m128.0/128.0 kB[0m [31m769.4 kB/s[0m eta [36m0:00:00[0ma [36m0:00:01[0m
[?25hRequirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.3.4) (2.1.0)
Requirement already satisfied: scipy>=0.19.1 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.3.4) (1.6.3)
Requirement already satisfied: joblib>=0.11 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from scikit-learn>=0.21.3->seqeval->paddlenlp==2.3.4) (0.14.1)
Requirement already satisfied: zipp>=0.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from importlib-metadata->datasets>=2.0.0->paddlenlp==2.3.4) (3.8.1)
Requirement already satisfied: pytz>=2017.2 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pandas->datasets>=2.0.0->paddlenlp==2.3.4) (2019.3)
Requirement already satisfied: python-dateutil>=2.7.3 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from pandas->datasets>=2.0.0->paddlenlp==2.3.4) (2.8.2)
Requirement already satisfied: six>=1.5 in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (from python-dateutil>=2.7.3->pandas->datasets>=2.0.0->paddlenlp==2.3.4) (1.16.0)
Installing collected packages: xxhash, urllib3, multidict, fsspec, frozenlist, charset-normalizer, asynctest, async-timeout, yarl, aiosignal, responses, paddlefsl, huggingface-hub, aiohttp, datasets, paddlenlp
Attempting uninstall: urllib3
Found existing installation: urllib3 1.25.6
Uninstalling urllib3-1.25.6:
Successfully uninstalled urllib3-1.25.6
Attempting uninstall: paddlefsl
Found existing installation: paddlefsl 1.0.0
Uninstalling paddlefsl-1.0.0:
Successfully uninstalled paddlefsl-1.0.0
Attempting uninstall: paddlenlp
Found existing installation: paddlenlp 2.1.1
Uninstalling paddlenlp-2.1.1:
Successfully uninstalled paddlenlp-2.1.1
[31mERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
parl 1.4.1 requires pyzmq==18.1.1, but you have pyzmq 23.2.1 which is incompatible.[0m[31m
[0mSuccessfully installed aiohttp-3.8.3 aiosignal-1.3.1 async-timeout-4.0.2 asynctest-0.13.0 charset-normalizer-2.1.1 datasets-2.8.0 frozenlist-1.3.3 fsspec-2022.11.0 huggingface-hub-0.11.1 multidict-6.0.4 paddlefsl-1.1.0 paddlenlp-2.3.4 responses-0.18.0 urllib3-1.25.11 xxhash-3.2.0 yarl-1.8.2
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m A new release of pip available: [0m[31;49m22.1.2[0m[39;49m -> [0m[32;49m22.3.1[0m
[1m[[0m[34;49mnotice[0m[1;39;49m][0m[39;49m To update, run: [0m[32;49mpip install --upgrade pip[0m
4.2 导入依赖包
# 导入依赖
import codecs
import json
import os
import random
from tqdm import tqdm
import paddle
from paddle import nn
from paddlenlp.layers import LinearChainCrf, LinearChainCrfLoss, ViterbiDecoder
from paddlenlp.metrics import ChunkEvaluator
from paddlenlp.transformers import BertModel, BertTokenizer
import numpy as np
from paddle.fluid.reader import DataLoader
from paddle.io import Dataset
from paddle.static import InputSpec
from paddle.callbacks import VisualDL, EarlyStopping, ReduceLROnPlateau
# 设置GPU
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
4.3 标注数据转换
此类将原始的标注数据进行转换,即将文本数据和标注标签分离开
# 将标注数据转换为BIO格式的类
class TransferData:
def __init__(self , project_root_dir):
# 获取项目文件所在目录
cur = project_root_dir
self.label_dict = {
'检查和检验': 'CHECK',
'症状和体征': 'SIGNS',
'疾病和诊断': 'DISEASE',
'治疗': 'TREATMENT',
'身体部位': 'BODY'}
# 标签 id关系映射
self.cate_dict = {
'[PAD]': 0,
'[CLS]': 1,
'[SEP]': 2,
'O': 3,
'I-TREATMENT': 4,
'B-TREATMENT': 5,
'B-BODY': 6,
'I-BODY': 7,
'I-SIGNS': 8,
'B-SIGNS': 9,
'B-CHECK': 10,
'I-CHECK': 11,
'I-DISEASE': 12,
'B-DISEASE': 13
}
# 标注文件目录
self.origin_path = os.path.join(cur, 'data_origin')
# 训练集文件路径
self.train_filepath = os.path.join(cur, 'data/train.txt')
# 验证集文件路径
self.eval_filepath = os.path.join(cur, "data/eval.txt")
# 项目文件根目录
self.cur = cur
def divide_dataset(self, all_sentence):
"""
划分数据集 train:eval=7:3
:param all_sentence:
:return:
"""
dataset_size = len(all_sentence)
divide_point = int(dataset_size * 0.7)
# 打乱数据集
random.shuffle(all_sentence)
# 训练集
train_sentence = all_sentence[0:divide_point]
# 验证集
eval_sentence = all_sentence[divide_point:-1]
return train_sentence, eval_sentence
def transfer(self):
"""
将标注文件转换为BIO格式
:return:
"""
all_sentence = []
print("处理数据中********")
for root, dirs, files in os.walk(self.origin_path):
for file in tqdm(files):
filepath = os.path.join(root, file)
if 'original' not in filepath: # 找到源文件
continue
label_filepath = filepath.replace('.txtoriginal', '') # 找到对应的标注文件
# 打开源文件,读出文本数据
with open(filepath, 'r', encoding='utf-8') as origin_file:
content = origin_file.read().strip()
res_dict = {}
# 打开标注文件
for line in open(label_filepath, 'r', encoding='utf-8'):
# 拆分标注信息
res = line.strip().split(' ')
# 标签开始位置
start = int(res[1])
# 标签结束位置
end = int(res[2])
# 获取标签名称
label = res[3]
# 根据标签名称获取英文标签
label_id = self.label_dict.get(label)
# 将标签转换为BIO风格
for i in range(start, end + 1):
if i == start:
label_cate = 'B-' + label_id
else:
label_cate = 'I-' + label_id
# 标注信息保存在字典中,i是位置索引,label_cate是标签
res_dict[i] = label_cate
sentence = []
for indx, char in enumerate(content):
# 如果获取不到值,默认就威为O
char_label = res_dict.get(indx, 'O')
# 拼接形成BIO标注行
row = char + '\t' + char_label + '\n'
sentence.append(row)
if char in ['。', '?', '!', '!', '?']:
# 表示一个完整的句子结束了
# 每句话结束后都插入一个空行,方便拆分数据集
sentence.append("\n")
all_sentence.append(sentence)
# 划分数据集
train_sentence, eval_sentence = self.divide_dataset(all_sentence)
with open(self.train_filepath, 'w+', encoding='utf-8') as train_file:
for sentence in train_sentence:
train_file.writelines(sentence)
with open(self.eval_filepath, "w+", encoding="utf-8") as eval_file:
for sentence in eval_sentence:
eval_file.writelines(sentence)
def save_label_files(self):
# 保存标签名称与标签映射文件
label_dict_str = json.dumps(self.label_dict, ensure_ascii=False)
with open(os.path.join(self.cur,"data/name2label.json"), "w", encoding="utf-8") as f:
f.write(label_dict_str)
# 保存标签与标签名称映射文件
label2name = {}
for k, v in self.label_dict.items():
label2name[v] = k
with open(os.path.join(self.cur,"data/label2name.json"), "w", encoding="utf-8") as f:
label2name_str = json.dumps(label2name, ensure_ascii=False)
f.write(label2name_str)
# 保存label id映射文件
labels2id = json.dumps(self.cate_dict)
with open(os.path.join(self.cur,"data/labels2id.json"), "w", encoding="utf-8") as f:
f.write(labels2id)
# 保存id label映射文件
id2labels = {}
for k, v in self.cate_dict.items():
id2labels[v] = k
id2labels_str = json.dumps(id2labels)
with open(os.path.join(self.cur,"data/id2labels.json"), "w", encoding="utf-8") as f:
f.write(id2labels_str)
4.4 从数据集文件中读取数据
# 从数据集文件中读取数据
def read_data(input_file, max_seq_length):
"""Reads a BIO data.读取每一句话"""
with codecs.open(input_file, 'r', encoding='utf-8') as f:
lines = []
words = []
labels = []
for line in f:
# 去除前后的空格
contends = line.strip()
# 根据tab拆分
tokens = contends.split('\t')
if len(tokens) == 2:
# 分离一行的word和label
words.append(tokens[0])
labels.append(tokens[-1])
else:
# 表示一句话结束了
if len(contends) == 0 and len(words) > 0:
# [CLS] [SEP]表示句子开头和结尾
label = ["[CLS]"]
word = ["[CLS]"]
for l, w in zip(labels, words):
if len(label) == max_seq_length - 1 or len(word) == max_seq_length - 1:
# 当句子长度超出最大限制长度,做一个截断操作
break
# len(l) = 0 and len(w) = 0 要么是没打标记,要么就是标记打到空格上
if len(l) > 0 and len(w) > 0:
label.append(l)
word.append(w)
label.append("[SEP]")
word.append("[SEP]")
lines.append([' '.join(label), ' '.join(word)])
words = []
labels = []
continue
return lines
4.5 将标注的标签转换为id表示
# 将标注的label通过label2id文件中的键值对信息转换为label的id表示
def convert_label2id(labels, labels2id, max_seq_length):
"""
label转换为id
:param max_seq_length:
:param labels:
:param labels2id:
:return:
"""
label_ids = []
for label in labels:
# label转化为 id
label_id = labels2id[label]
label_ids.append(label_id)
# 填充到最大序列长度
while len(label_ids) < max_seq_length:
label_ids.append(0)
return label_ids
# 封装特征数据类
class Feature:
def __init__(self, input_ids, token_type_ids, labels, seq_length):
"""
封装特征数据
:param input_ids:
:param token_type_ids:
:param label_ids:
:param seq_length:
"""
self.seq_length = seq_length
self.labels = labels
self.token_type_ids = token_type_ids
self.input_ids = input_ids
# 将单个line转换为feature,对数据进行tokenize,填充,截断,格式转化等
def convert_signal_line_to_features(line, tokenizer, max_seq_length, labels2id):
"""
将单个line转换为feature,对数据进行tokenize,填充,截断,格式转化等
:param tokenizer:
:param max_seq_length:
:param labels2id:
:return:
"""
text = line[1].split(" ")
labels = line[0].split(" ")
seq_length = np.asarray(min(len(text), max_seq_length), dtype="int64")
# tokenize
tokenized_text = tokenizer(text, max_length=max_seq_length, pad_to_max_seq_len=True,
is_split_into_words=True, add_special_tokens=False,
return_token_type_ids=False)
# 格式转换
input_ids = np.asarray(tokenized_text["input_ids"], dtype="int64")
token_type_ids = np.asarray([0] * max_seq_length, dtype="int64")
# label转换为id
labels = np.asarray(convert_label2id(labels, labels2id, max_seq_length), dtype="int64")
return Feature(input_ids, token_type_ids, labels, seq_length)
# 将标注的lines转为features
def convert_lines_to_features(lines, tokenizer, max_seq_length, labels2id):
"""
lines转为features
:param lines:
:param tokenizer:
:param max_seq_length:
:param labels2id:
:return:
"""
features = []
for line in lines:
# 转换
feature = convert_signal_line_to_features(line, tokenizer, max_seq_length, labels2id)
features.append(feature)
return features
4.6 自定义数据集
# 自定义数据集,继承了paddle.io.Dataset类,需要实现__getitem__()和__len()__方法
class MyDataset(Dataset):
"""
自定义数据集
Args:
features: 特征数据
"""
def __init__(self, features):
super().__init__()
self.features = features
def __getitem__(self, idx):
"""
通过id获取一条feature
:param idx:
:return:
"""
feature = self.features[idx]
return feature.input_ids, feature.token_type_ids, feature.seq_length, feature.labels
def __len__(self):
return len(self.features)
4.7 创建dataloader
# 根据文件创建dataloader,先构建根据文件构建数据集,在把数据集封装成DataLoader
def create_dataloader(file_path, tokenizer, labels2id, batch_size, max_seq_length, shuffle=False):
"""
根据文件创建dataloader
:param file_path:
:param tokenizer:
:param labels2id:
:param batch_size:
:param max_seq_length:
:return:
"""
# 读取文件数据
lines = read_data(file_path, max_seq_length=max_seq_length)
# 一系列封装
# examples = create_example(lines)
# features = convert_examples_to_features(examples, tokenizer, max_seq_length, labels2id)
features = convert_lines_to_features(lines, tokenizer, max_seq_length, labels2id)
print(file_path.split("/")[-1] + " features:", len(features))
# 创建数据集
dataset = MyDataset(features)
# 创建dataloader
dataloader = DataLoader(dataset, batch_size=batch_size, drop_last=True, shuffle=shuffle)
return dataloader
4.8 自定义模型
4.8.1 超参数
- bert:预训练BERT模型
- lstm_hidden_size:LSTM隐藏层大小,默认512
- num_class:标签的数量,默认11+3 11个标注标签,3个tokenizer中需要的标签
- crf_lr:CRF层的学习率
4.8.2 返回值
- logits:全连接层的输出,用于计算loss
- seq_len:输入句子的实际长度,不包括padding
- prediction:预测结果
4.8.3 网络介绍
- bert为预训练模型,参与模型训练进行微调,对输入数据做embedding,输出句向量
- BiLSTM主要是用来进行特征提取
- 全连接层用来将BiLSTM的输出映射到分类的维度,没有激活函数
- LinearChainCrf层寻找一条概率最大的标注路径
- ViterbiDecoder对CRF计算结果进行解码,得到标注信息
# 自定义模型
class NERModel(nn.Layer):
"""
自定义模型
Bert+BiLSTM+CRF
Args:
bert: bert模型
lstm_hidden_size: lstm隐藏层维度
num_class: 分类数量
crf_lr:CRF层的学习率
"""
def __init__(self, bert=None, lstm_hidden_size=512, num_class=14, crf_lr=0.1):
"""
:param bert: bert模型
:param lstm_hidden_size: lstm隐藏层
:param num_class: 分类数量
:param crf_lr: CRF学习率
"""
super().__init__()
self.crf_lr = crf_lr
self.num_class = num_class
self.bert = bert
# 定义双向LSTM
self.bi_lstm = nn.LSTM(self.bert.config["hidden_size"],
lstm_hidden_size,
num_layers=2,
direction='bidirect')
# 定义logits层
self.fc = nn.Linear(lstm_hidden_size * 2, self.num_class + 2)
# CRF层
self.crf = LinearChainCrf(self.num_class, crf_lr=crf_lr)
# CRF解码概率最大的路径
self.viterbi_decoder = ViterbiDecoder(self.crf.transitions)
def forward(self, input_ids=None, token_type_ids=None, seq_len=None):
# bert嵌入,有两个输出,第一个是每个token的嵌入输出,第二个是整个句子的嵌入输出
embedding = self.bert(input_ids, token_type_ids)[0]
# bilstm
bi_lstm_output, _ = self.bi_lstm(embedding)
logits = self.fc(bi_lstm_output)
# 直接返回解码结果
_, prediction = self.viterbi_decoder(logits, seq_len)
return logits, seq_len, prediction
4.9 模型构建
- 使用
BertModel.from_pretrained("bert-wwm-ext-chinese")加载预训练BERT模型,该模型是BERT-wwm的一个升级版,相比于BERT-wwm的改进是增加了训练数据集同时也增加了训练步数。 - 使用
LinearChainCrfLoss损失函数,专用于计算CRF的loss - 使用
AdamW优化器 - 学习率预热
scheduler,预热步数设置为300步,预热起始值不能从0 开始,否则收敛 - 将模型封装成
paddle.Model方便使用高级api
# 构建模型
def create_model(lstm_hidden_size, labels2id, crf_lr, learning_rate):
"""
构建模型
:param lstm_hidden_size:
:param labels2id:
:param crf_lr:
:param learning_rate:
:return:
"""
# 加载bert
bert = BertModel.from_pretrained("bert-wwm-ext-chinese")
# 创建网络
net = NERModel(bert, lstm_hidden_size=lstm_hidden_size, num_class=len(labels2id), crf_lr=crf_lr)
# CRF loss函数
crf_loss = LinearChainCrfLoss(net.crf)
# 学习率预热
scheduler = paddle.optimizer.lr.LinearWarmup(
learning_rate=learning_rate, warmup_steps=300, start_lr=0.00001, end_lr=learning_rate)
# 优化器
optimizer_adamw = paddle.optimizer.AdamW(learning_rate=scheduler, parameters=net.parameters())
# 评估
metric = ChunkEvaluator(labels2id.keys())
# 封装成Model
ner_model = paddle.Model(net)
# 模型准备,设置loss函数,优化器,评估器
ner_model.prepare(
loss=crf_loss,
optimizer=optimizer_adamw,
metrics=metric
)
return ner_model
4.10 构建训练函数
- 使用
EarlyStopping回调回调,在监控指标不发生变化4个epoch后自动停止 - 使用
ReduceLROnPlateau回调,当模型趋于收敛时降低学习率 - 使用
VisualDL回调,记录训练过程中的评估指标 - 因使用了
EarlyStopping,可将总的epoch数设置一个大一点的值
# 训练函数
def train(project_root_dir):
# project_root_dir 项目根目录
learning_rate = 0.0001
# 训练时最大句子长度
max_seq_length = 128
# LSTM隐藏层大小
lstm_hidden_size = 512
batch_size = 32
# CRF学习率
crf_lr = 0.66
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-wwm-ext-chinese")
# 加载label2id映射文件
with open(os.path.join(project_root_dir , "data/labels2id.json"), "r", encoding="utf-8") as f:
labels2id = json.load(f)
# 加载训练集
train_dataloader = create_dataloader(os.path.join(project_root_dir , "data/train.txt"), tokenizer, labels2id, batch_size, max_seq_length, shuffle=True)
# 加载验证集
eval_dataloader = create_dataloader(os.path.join(project_root_dir , "data/eval.txt"), tokenizer, labels2id, batch_size, max_seq_length, shuffle=False)
# 加载模型
print("train_steps:", len(train_dataloader))
print("eval_steps:", len(eval_dataloader))
# 模型保存路径
save_dir=os.path.join(project_root_dir, "checkpoint")
print("模型保存路径:",save_dir)
# 日志文件保存路径
los_dir=os.path.join(project_root_dir, "logs")
if not os.path.exists(los_dir):
os.mkdir(los_dir)
print("日志文件保存路径", los_dir)
# 可视化工具回调
visual_dl = VisualDL(log_dir=los_dir)
# 监测 precision 最大值变化情况,4 epoch内没变化就停止,并保存最佳模型
early_stopping = EarlyStopping(monitor="loss", mode="min", patience=4)
# 3个epoch后,precision没有变化就降低学习率
reduce_lr = ReduceLROnPlateau(monitor="loss", mode="min", patience=3, min_lr=0.00001)
# 加载模型
ner_model = create_model(lstm_hidden_size, labels2id, crf_lr, learning_rate)
# 训练
ner_model.fit(
train_data=train_dataloader,
eval_data=eval_dataloader,
epochs=30,
save_dir=save_dir,
callbacks=[visual_dl, early_stopping, reduce_lr]
)
# 从预测labels中解析出实体id范围
def parse_pred_labels_to_entity_with_ids(pred_labels):
"""
从预测labels中解析出实体在文本中的id范围
:param pred_labels:
:return:
"""
entities = []
start = None
end = None
l = None
for idx, label in enumerate(pred_labels):
# 新的实体开头
if label.startswith("B-") or label == "O":
# 保存旧的实体
if start is not None and end is not None:
entities.append((start, end, l))
start = None
end = None
if label == "O":
continue
else:
start = idx
end = idx
l = label.split("-")[-1]
continue
# 在实体中
end = idx
return entities
# 将预测结果解析为具体的实体
def parse_pred_labels_to_entity(text, pred_labels, label2name):
# 获取实体id范围
entity_with_ids = parse_pred_labels_to_entity_with_ids(pred_labels)
print(entity_with_ids)
entities = []
# 通过实体的id范围直接从输入文本中截取实体文本
for entity_msg in entity_with_ids:
start = entity_msg[0]
end = entity_msg[1]
label = entity_msg[2]
entity_name = text[start:end + 1]
entities.append({"entity": entity_name, "label": label2name[label]})
return entities
# 测试函数
def test(text, id2labels,label2name,tokenizer, model):
"""
测试单个句子
"""
# 提取输入特征
text_list = list(text.strip())
tokenized = tokenizer(text_list, is_split_into_words=True)
input_ids = tokenized["input_ids"]
token_type_ids = tokenized["token_type_ids"]
# 特征转为tensor
input_ids = paddle.to_tensor([input_ids], dtype="int64")
token_type_ids = paddle.to_tensor([token_type_ids], dtype="int64")
seq_len = paddle.to_tensor([len(text) + 2], dtype="int64")
# 预测
_, _, prediction = model(input_ids, token_type_ids, seq_len)
prediction = prediction.numpy()
prediction = np.reshape(prediction, [-1])
# label_id转 label
pred_labels = []
for idx in prediction:
label = id2labels[str(idx)]
pred_labels.append(label)
# 解析实体
entities = parse_pred_labels_to_entity(text, pred_labels[1:-2], label2name)
print(text)
print(entities)
4.11 模型训练
生成训练集和验证集,保存相关映射文件到paddle_ner/data目录
# 处理数据
# 项目根目录
project_name="paddle_ner" # 项目目录文件名
project_root_dir = os.path.join(os.path.abspath('.'),project_name)
# 处理数据
handler = TransferData(project_root_dir)
handler.transfer()
handler.save_label_files()
# 训练,以precision作为指标训练
project_dir_name="paddle_ner" # 项目文件目录
project_root_dir = os.path.join(os.path.abspath('.'), project_dir_name) # 项目路径
train(project_root_dir)
[2022-07-17 01:37:21,919] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/bert-wwm-ext-chinese-vocab.txt
[2022-07-17 01:37:21,934] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/tokenizer_config.json
[2022-07-17 01:37:21,936] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/special_tokens_map.json
train.txt features: 5462
eval.txt features: 2368
train_steps: 170
eval_steps: 74
模型保存路径: /home/aistudio/paddle_ner/checkpoint
日志文件保存路径 /home/aistudio/paddle_ner/logs
[2022-07-17 01:37:23,525] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/bert-wwm-ext-chinese.pdparams
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/30
[2022-07-17 01:37:24,958] [ WARNING] - Compatibility Warning: The params of LinearChainCrfLoss.forward has been modified. The third param is `labels`, and the fourth is not necessary. Please update the usage.
[2022-07-17 01:37:25,224] [ WARNING] - Compatibility Warning: The params of ChunkEvaluator.compute has been modified. The old version is `inputs`, `lengths`, `predictions`, `labels` while the current version is `lengths`, `predictions`, `labels`. Please update the usage.
step 10/170 - loss: 37.8878 - precision: 9.8571e-04 - recall: 0.0011 - f1: 0.0010 - 610ms/step
step 20/170 - loss: 64.3799 - precision: 9.8571e-04 - recall: 5.3981e-04 - f1: 6.9759e-04 - 611ms/step
step 30/170 - loss: 23.0739 - precision: 9.8571e-04 - recall: 3.5991e-04 - f1: 5.2729e-04 - 612ms/step
step 40/170 - loss: 30.1452 - precision: 9.8571e-04 - recall: 2.6922e-04 - f1: 4.2292e-04 - 611ms/step
step 50/170 - loss: 18.8763 - precision: 9.8377e-04 - recall: 2.1533e-04 - f1: 3.5333e-04 - 607ms/step
step 60/170 - loss: 62.2968 - precision: 0.0083 - recall: 0.0016 - f1: 0.0027 - 605ms/step
step 70/170 - loss: 21.5047 - precision: 0.0321 - recall: 0.0061 - f1: 0.0103 - 606ms/step
step 80/170 - loss: 57.2929 - precision: 0.0943 - recall: 0.0201 - f1: 0.0332 - 607ms/step
step 90/170 - loss: 19.2941 - precision: 0.1802 - recall: 0.0452 - f1: 0.0722 - 607ms/step
step 100/170 - loss: 65.4937 - precision: 0.2691 - recall: 0.0790 - f1: 0.1221 - 608ms/step
step 110/170 - loss: 28.6662 - precision: 0.3557 - recall: 0.1215 - f1: 0.1811 - 607ms/step
step 120/170 - loss: 14.6879 - precision: 0.4380 - recall: 0.1733 - f1: 0.2483 - 608ms/step
step 130/170 - loss: 1.7164 - precision: 0.5032 - recall: 0.2217 - f1: 0.3078 - 607ms/step
step 140/170 - loss: 2.6516 - precision: 0.5467 - recall: 0.2625 - f1: 0.3547 - 605ms/step
step 150/170 - loss: 9.7185 - precision: 0.5859 - recall: 0.3022 - f1: 0.3988 - 604ms/step
step 160/170 - loss: 1.4909 - precision: 0.6146 - recall: 0.3367 - f1: 0.4350 - 603ms/step
step 170/170 - loss: 4.1658 - precision: 0.6377 - recall: 0.3665 - f1: 0.4655 - 603ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/0
Eval begin...
step 10/74 - loss: 10.9286 - precision: 0.8872 - recall: 0.8968 - f1: 0.8920 - 342ms/step
step 20/74 - loss: 3.6730 - precision: 0.8686 - recall: 0.8845 - f1: 0.8765 - 349ms/step
step 30/74 - loss: 1.6067 - precision: 0.8766 - recall: 0.8902 - f1: 0.8833 - 346ms/step
step 40/74 - loss: 7.0303 - precision: 0.8790 - recall: 0.8944 - f1: 0.8866 - 347ms/step
step 50/74 - loss: 18.7744 - precision: 0.8731 - recall: 0.8891 - f1: 0.8810 - 351ms/step
step 60/74 - loss: 13.1668 - precision: 0.8706 - recall: 0.8871 - f1: 0.8788 - 349ms/step
step 70/74 - loss: 2.0590 - precision: 0.8670 - recall: 0.8857 - f1: 0.8762 - 348ms/step
step 74/74 - loss: 5.0448 - precision: 0.8675 - recall: 0.8862 - f1: 0.8767 - 349ms/step
Eval samples: 2368
Epoch 2/30
step 10/170 - loss: 5.0669 - precision: 0.8855 - recall: 0.8904 - f1: 0.8879 - 598ms/step
step 20/170 - loss: 1.0223 - precision: 0.8756 - recall: 0.8886 - f1: 0.8820 - 599ms/step
step 30/170 - loss: 9.6345 - precision: 0.8691 - recall: 0.8874 - f1: 0.8781 - 603ms/step
step 40/170 - loss: 1.5779 - precision: 0.8723 - recall: 0.8898 - f1: 0.8810 - 604ms/step
step 50/170 - loss: 29.1933 - precision: 0.8759 - recall: 0.8936 - f1: 0.8847 - 605ms/step
step 60/170 - loss: 1.4892 - precision: 0.8736 - recall: 0.8920 - f1: 0.8827 - 606ms/step
step 70/170 - loss: 13.0654 - precision: 0.8721 - recall: 0.8899 - f1: 0.8809 - 604ms/step
step 80/170 - loss: 1.7358 - precision: 0.8719 - recall: 0.8921 - f1: 0.8819 - 604ms/step
step 90/170 - loss: 0.8488 - precision: 0.8741 - recall: 0.8930 - f1: 0.8834 - 604ms/step
step 100/170 - loss: 0.0000e+00 - precision: 0.8761 - recall: 0.8939 - f1: 0.8849 - 603ms/step
step 110/170 - loss: 0.8198 - precision: 0.8799 - recall: 0.8977 - f1: 0.8887 - 603ms/step
step 120/170 - loss: 2.6585 - precision: 0.8827 - recall: 0.9001 - f1: 0.8913 - 605ms/step
step 130/170 - loss: 14.1505 - precision: 0.8842 - recall: 0.9017 - f1: 0.8929 - 604ms/step
step 140/170 - loss: 5.3528 - precision: 0.8847 - recall: 0.9022 - f1: 0.8934 - 602ms/step
step 150/170 - loss: 11.8976 - precision: 0.8855 - recall: 0.9029 - f1: 0.8941 - 601ms/step
step 160/170 - loss: 0.7898 - precision: 0.8865 - recall: 0.9044 - f1: 0.8953 - 601ms/step
step 170/170 - loss: 20.0034 - precision: 0.8884 - recall: 0.9064 - f1: 0.8973 - 602ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/1
Eval begin...
step 10/74 - loss: 4.8262 - precision: 0.9374 - recall: 0.9598 - f1: 0.9485 - 334ms/step
step 20/74 - loss: 1.5220 - precision: 0.9156 - recall: 0.9449 - f1: 0.9300 - 341ms/step
step 30/74 - loss: 0.2056 - precision: 0.9150 - recall: 0.9443 - f1: 0.9294 - 340ms/step
step 40/74 - loss: 2.1104 - precision: 0.9181 - recall: 0.9459 - f1: 0.9318 - 343ms/step
step 50/74 - loss: 19.1398 - precision: 0.9149 - recall: 0.9453 - f1: 0.9299 - 347ms/step
step 60/74 - loss: 4.1186 - precision: 0.9141 - recall: 0.9453 - f1: 0.9294 - 344ms/step
step 70/74 - loss: 1.5601 - precision: 0.9138 - recall: 0.9460 - f1: 0.9296 - 344ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9135 - recall: 0.9462 - f1: 0.9295 - 345ms/step
Eval samples: 2368
Epoch 3/30
step 10/170 - loss: 23.1120 - precision: 0.9264 - recall: 0.9507 - f1: 0.9384 - 601ms/step
step 20/170 - loss: 2.8615 - precision: 0.9172 - recall: 0.9414 - f1: 0.9291 - 607ms/step
step 30/170 - loss: 3.2435 - precision: 0.9195 - recall: 0.9424 - f1: 0.9308 - 611ms/step
step 40/170 - loss: 0.1930 - precision: 0.9229 - recall: 0.9439 - f1: 0.9333 - 602ms/step
step 50/170 - loss: 0.2932 - precision: 0.9237 - recall: 0.9448 - f1: 0.9341 - 605ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9234 - recall: 0.9443 - f1: 0.9338 - 606ms/step
step 70/170 - loss: 0.7442 - precision: 0.9267 - recall: 0.9458 - f1: 0.9362 - 607ms/step
step 80/170 - loss: 0.3235 - precision: 0.9288 - recall: 0.9467 - f1: 0.9377 - 608ms/step
step 90/170 - loss: 3.3412 - precision: 0.9288 - recall: 0.9469 - f1: 0.9377 - 608ms/step
step 100/170 - loss: 1.4943 - precision: 0.9284 - recall: 0.9471 - f1: 0.9376 - 609ms/step
step 110/170 - loss: 0.0000e+00 - precision: 0.9281 - recall: 0.9467 - f1: 0.9373 - 610ms/step
step 120/170 - loss: 6.6400 - precision: 0.9283 - recall: 0.9457 - f1: 0.9369 - 611ms/step
step 130/170 - loss: 1.4504 - precision: 0.9290 - recall: 0.9470 - f1: 0.9379 - 609ms/step
step 140/170 - loss: 39.4307 - precision: 0.9298 - recall: 0.9478 - f1: 0.9387 - 609ms/step
step 150/170 - loss: 4.2967 - precision: 0.9309 - recall: 0.9488 - f1: 0.9398 - 610ms/step
step 160/170 - loss: 2.0896 - precision: 0.9308 - recall: 0.9484 - f1: 0.9395 - 610ms/step
step 170/170 - loss: 1.5230 - precision: 0.9315 - recall: 0.9491 - f1: 0.9402 - 611ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/2
Eval begin...
step 10/74 - loss: 3.7625 - precision: 0.9574 - recall: 0.9636 - f1: 0.9605 - 333ms/step
step 20/74 - loss: 1.2115 - precision: 0.9391 - recall: 0.9479 - f1: 0.9435 - 341ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9377 - recall: 0.9480 - f1: 0.9428 - 341ms/step
step 40/74 - loss: 1.3125 - precision: 0.9408 - recall: 0.9500 - f1: 0.9454 - 345ms/step
step 50/74 - loss: 5.6888 - precision: 0.9402 - recall: 0.9482 - f1: 0.9442 - 349ms/step
step 60/74 - loss: 3.5969 - precision: 0.9408 - recall: 0.9484 - f1: 0.9446 - 346ms/step
step 70/74 - loss: 1.7537 - precision: 0.9402 - recall: 0.9486 - f1: 0.9444 - 346ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9401 - recall: 0.9485 - f1: 0.9443 - 346ms/step
Eval samples: 2368
Epoch 4/30
step 10/170 - loss: 6.4533 - precision: 0.9492 - recall: 0.9579 - f1: 0.9535 - 582ms/step
step 20/170 - loss: 15.1555 - precision: 0.9459 - recall: 0.9589 - f1: 0.9523 - 596ms/step
step 30/170 - loss: 1.4166 - precision: 0.9509 - recall: 0.9627 - f1: 0.9567 - 600ms/step
step 40/170 - loss: 4.3327 - precision: 0.9488 - recall: 0.9630 - f1: 0.9558 - 596ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9498 - recall: 0.9622 - f1: 0.9560 - 597ms/step
step 60/170 - loss: 0.5473 - precision: 0.9483 - recall: 0.9615 - f1: 0.9549 - 596ms/step
step 70/170 - loss: 0.6853 - precision: 0.9456 - recall: 0.9605 - f1: 0.9530 - 598ms/step
step 80/170 - loss: 1.1679 - precision: 0.9442 - recall: 0.9604 - f1: 0.9523 - 596ms/step
step 90/170 - loss: 2.6168 - precision: 0.9440 - recall: 0.9601 - f1: 0.9520 - 596ms/step
step 100/170 - loss: 6.3373 - precision: 0.9437 - recall: 0.9601 - f1: 0.9519 - 598ms/step
step 110/170 - loss: 0.0000e+00 - precision: 0.9441 - recall: 0.9600 - f1: 0.9520 - 599ms/step
step 120/170 - loss: 4.6766 - precision: 0.9435 - recall: 0.9599 - f1: 0.9516 - 600ms/step
step 130/170 - loss: 15.0505 - precision: 0.9426 - recall: 0.9585 - f1: 0.9505 - 601ms/step
step 140/170 - loss: 0.7440 - precision: 0.9431 - recall: 0.9589 - f1: 0.9509 - 601ms/step
step 150/170 - loss: 1.4950 - precision: 0.9422 - recall: 0.9584 - f1: 0.9502 - 602ms/step
step 160/170 - loss: 1.8184 - precision: 0.9422 - recall: 0.9586 - f1: 0.9503 - 602ms/step
step 170/170 - loss: 0.0000e+00 - precision: 0.9421 - recall: 0.9578 - f1: 0.9499 - 603ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/3
Eval begin...
step 10/74 - loss: 2.9080 - precision: 0.9478 - recall: 0.9658 - f1: 0.9567 - 334ms/step
step 20/74 - loss: 0.9292 - precision: 0.9335 - recall: 0.9541 - f1: 0.9437 - 342ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9342 - recall: 0.9544 - f1: 0.9442 - 341ms/step
step 40/74 - loss: 0.9697 - precision: 0.9341 - recall: 0.9538 - f1: 0.9439 - 343ms/step
step 50/74 - loss: 13.7643 - precision: 0.9330 - recall: 0.9509 - f1: 0.9419 - 348ms/step
step 60/74 - loss: 2.8744 - precision: 0.9348 - recall: 0.9525 - f1: 0.9436 - 346ms/step
step 70/74 - loss: 1.4779 - precision: 0.9347 - recall: 0.9530 - f1: 0.9438 - 346ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9334 - recall: 0.9529 - f1: 0.9430 - 347ms/step
Eval samples: 2368
Epoch 5/30
step 10/170 - loss: 1.3427 - precision: 0.9588 - recall: 0.9704 - f1: 0.9646 - 630ms/step
step 20/170 - loss: 0.0000e+00 - precision: 0.9487 - recall: 0.9598 - f1: 0.9542 - 610ms/step
step 30/170 - loss: 0.4966 - precision: 0.9450 - recall: 0.9602 - f1: 0.9526 - 602ms/step
step 40/170 - loss: 0.0000e+00 - precision: 0.9435 - recall: 0.9599 - f1: 0.9516 - 603ms/step
step 50/170 - loss: 3.7062 - precision: 0.9441 - recall: 0.9594 - f1: 0.9517 - 605ms/step
step 60/170 - loss: 0.5852 - precision: 0.9459 - recall: 0.9597 - f1: 0.9527 - 602ms/step
step 70/170 - loss: 0.5695 - precision: 0.9473 - recall: 0.9611 - f1: 0.9541 - 600ms/step
step 80/170 - loss: 7.8907 - precision: 0.9475 - recall: 0.9614 - f1: 0.9544 - 600ms/step
step 90/170 - loss: 3.7535 - precision: 0.9467 - recall: 0.9607 - f1: 0.9536 - 601ms/step
step 100/170 - loss: 2.8390 - precision: 0.9463 - recall: 0.9604 - f1: 0.9533 - 601ms/step
step 110/170 - loss: 10.5855 - precision: 0.9463 - recall: 0.9606 - f1: 0.9534 - 600ms/step
step 120/170 - loss: 2.7303 - precision: 0.9462 - recall: 0.9608 - f1: 0.9534 - 600ms/step
step 130/170 - loss: 13.4303 - precision: 0.9453 - recall: 0.9608 - f1: 0.9530 - 599ms/step
step 140/170 - loss: 4.0857 - precision: 0.9451 - recall: 0.9605 - f1: 0.9528 - 601ms/step
step 150/170 - loss: 2.1932 - precision: 0.9448 - recall: 0.9604 - f1: 0.9526 - 602ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9448 - recall: 0.9603 - f1: 0.9525 - 602ms/step
step 170/170 - loss: 0.0000e+00 - precision: 0.9449 - recall: 0.9602 - f1: 0.9525 - 603ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/4
Eval begin...
step 10/74 - loss: 2.3857 - precision: 0.9492 - recall: 0.9641 - f1: 0.9566 - 334ms/step
step 20/74 - loss: 0.7967 - precision: 0.9367 - recall: 0.9541 - f1: 0.9454 - 342ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9388 - recall: 0.9542 - f1: 0.9465 - 342ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9406 - recall: 0.9556 - f1: 0.9481 - 345ms/step
step 50/74 - loss: 13.6570 - precision: 0.9383 - recall: 0.9521 - f1: 0.9452 - 348ms/step
step 60/74 - loss: 2.4857 - precision: 0.9389 - recall: 0.9525 - f1: 0.9456 - 346ms/step
step 70/74 - loss: 1.1514 - precision: 0.9390 - recall: 0.9536 - f1: 0.9463 - 345ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9383 - recall: 0.9538 - f1: 0.9460 - 345ms/step
Eval samples: 2368
Epoch 6/30
step 10/170 - loss: 0.9612 - precision: 0.9565 - recall: 0.9697 - f1: 0.9630 - 627ms/step
step 20/170 - loss: 0.5025 - precision: 0.9539 - recall: 0.9677 - f1: 0.9607 - 614ms/step
step 30/170 - loss: 0.6411 - precision: 0.9538 - recall: 0.9671 - f1: 0.9604 - 607ms/step
step 40/170 - loss: 0.0000e+00 - precision: 0.9560 - recall: 0.9674 - f1: 0.9616 - 606ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9535 - recall: 0.9668 - f1: 0.9601 - 605ms/step
step 60/170 - loss: 0.0513 - precision: 0.9518 - recall: 0.9661 - f1: 0.9589 - 604ms/step
step 70/170 - loss: 11.9224 - precision: 0.9523 - recall: 0.9666 - f1: 0.9594 - 603ms/step
step 80/170 - loss: 8.7516 - precision: 0.9518 - recall: 0.9669 - f1: 0.9593 - 604ms/step
step 90/170 - loss: 0.4971 - precision: 0.9522 - recall: 0.9667 - f1: 0.9594 - 603ms/step
step 100/170 - loss: 0.6159 - precision: 0.9514 - recall: 0.9663 - f1: 0.9588 - 601ms/step
step 110/170 - loss: 0.7499 - precision: 0.9511 - recall: 0.9663 - f1: 0.9586 - 599ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9507 - recall: 0.9657 - f1: 0.9582 - 601ms/step
step 130/170 - loss: 0.9771 - precision: 0.9503 - recall: 0.9652 - f1: 0.9577 - 600ms/step
step 140/170 - loss: 0.8141 - precision: 0.9502 - recall: 0.9654 - f1: 0.9577 - 601ms/step
step 150/170 - loss: 1.0270 - precision: 0.9505 - recall: 0.9655 - f1: 0.9580 - 600ms/step
step 160/170 - loss: 0.4564 - precision: 0.9488 - recall: 0.9646 - f1: 0.9567 - 602ms/step
step 170/170 - loss: 0.0924 - precision: 0.9488 - recall: 0.9644 - f1: 0.9565 - 600ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/5
Eval begin...
step 10/74 - loss: 1.7386 - precision: 0.9503 - recall: 0.9663 - f1: 0.9583 - 337ms/step
step 20/74 - loss: 0.4929 - precision: 0.9379 - recall: 0.9560 - f1: 0.9469 - 343ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9365 - recall: 0.9535 - f1: 0.9449 - 344ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9399 - recall: 0.9567 - f1: 0.9483 - 349ms/step
step 50/74 - loss: 5.4821 - precision: 0.9378 - recall: 0.9551 - f1: 0.9464 - 352ms/step
step 60/74 - loss: 1.9452 - precision: 0.9399 - recall: 0.9565 - f1: 0.9482 - 349ms/step
step 70/74 - loss: 0.9700 - precision: 0.9406 - recall: 0.9571 - f1: 0.9488 - 348ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9401 - recall: 0.9575 - f1: 0.9488 - 348ms/step
Eval samples: 2368
Epoch 7/30
step 10/170 - loss: 0.0000e+00 - precision: 0.9604 - recall: 0.9754 - f1: 0.9678 - 623ms/step
step 20/170 - loss: 0.1975 - precision: 0.9603 - recall: 0.9746 - f1: 0.9674 - 606ms/step
step 30/170 - loss: 0.1013 - precision: 0.9593 - recall: 0.9725 - f1: 0.9659 - 599ms/step
step 40/170 - loss: 1.2122 - precision: 0.9543 - recall: 0.9704 - f1: 0.9623 - 594ms/step
step 50/170 - loss: 0.1590 - precision: 0.9564 - recall: 0.9710 - f1: 0.9637 - 597ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9555 - recall: 0.9706 - f1: 0.9630 - 599ms/step
step 70/170 - loss: 0.0000e+00 - precision: 0.9563 - recall: 0.9702 - f1: 0.9632 - 598ms/step
step 80/170 - loss: 2.4406 - precision: 0.9555 - recall: 0.9692 - f1: 0.9623 - 602ms/step
step 90/170 - loss: 0.2545 - precision: 0.9561 - recall: 0.9700 - f1: 0.9630 - 605ms/step
step 100/170 - loss: 9.0094 - precision: 0.9565 - recall: 0.9699 - f1: 0.9631 - 603ms/step
step 110/170 - loss: 0.4064 - precision: 0.9569 - recall: 0.9700 - f1: 0.9634 - 604ms/step
step 120/170 - loss: 2.1084 - precision: 0.9570 - recall: 0.9693 - f1: 0.9632 - 605ms/step
step 130/170 - loss: 0.1534 - precision: 0.9569 - recall: 0.9692 - f1: 0.9630 - 607ms/step
step 140/170 - loss: 0.0943 - precision: 0.9567 - recall: 0.9691 - f1: 0.9628 - 606ms/step
step 150/170 - loss: 1.8138 - precision: 0.9561 - recall: 0.9689 - f1: 0.9625 - 605ms/step
step 160/170 - loss: 2.9595 - precision: 0.9565 - recall: 0.9692 - f1: 0.9628 - 605ms/step
step 170/170 - loss: 2.1049 - precision: 0.9562 - recall: 0.9686 - f1: 0.9624 - 605ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/6
Eval begin...
step 10/74 - loss: 0.8818 - precision: 0.9555 - recall: 0.9674 - f1: 0.9614 - 333ms/step
step 20/74 - loss: 0.2762 - precision: 0.9417 - recall: 0.9574 - f1: 0.9495 - 340ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9401 - recall: 0.9553 - f1: 0.9476 - 340ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9442 - recall: 0.9571 - f1: 0.9506 - 344ms/step
step 50/74 - loss: 12.3305 - precision: 0.9432 - recall: 0.9564 - f1: 0.9498 - 347ms/step
step 60/74 - loss: 1.4225 - precision: 0.9435 - recall: 0.9567 - f1: 0.9501 - 345ms/step
step 70/74 - loss: 0.8717 - precision: 0.9421 - recall: 0.9564 - f1: 0.9492 - 344ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9411 - recall: 0.9564 - f1: 0.9487 - 345ms/step
Eval samples: 2368
Epoch 8/30
step 10/170 - loss: 1.5566 - precision: 0.9518 - recall: 0.9685 - f1: 0.9601 - 593ms/step
step 20/170 - loss: 0.2517 - precision: 0.9564 - recall: 0.9720 - f1: 0.9641 - 608ms/step
step 30/170 - loss: 0.3810 - precision: 0.9553 - recall: 0.9686 - f1: 0.9619 - 605ms/step
step 40/170 - loss: 1.0434 - precision: 0.9579 - recall: 0.9701 - f1: 0.9640 - 606ms/step
step 50/170 - loss: 0.5080 - precision: 0.9589 - recall: 0.9708 - f1: 0.9648 - 606ms/step
step 60/170 - loss: 0.7369 - precision: 0.9593 - recall: 0.9702 - f1: 0.9647 - 604ms/step
step 70/170 - loss: 0.5305 - precision: 0.9580 - recall: 0.9696 - f1: 0.9638 - 605ms/step
step 80/170 - loss: 0.1309 - precision: 0.9577 - recall: 0.9698 - f1: 0.9637 - 607ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9577 - recall: 0.9703 - f1: 0.9640 - 605ms/step
step 100/170 - loss: 0.1138 - precision: 0.9580 - recall: 0.9712 - f1: 0.9646 - 606ms/step
step 110/170 - loss: 0.5397 - precision: 0.9589 - recall: 0.9715 - f1: 0.9652 - 607ms/step
step 120/170 - loss: 6.2977 - precision: 0.9588 - recall: 0.9711 - f1: 0.9649 - 607ms/step
step 130/170 - loss: 0.5059 - precision: 0.9591 - recall: 0.9710 - f1: 0.9650 - 607ms/step
step 140/170 - loss: 19.0301 - precision: 0.9586 - recall: 0.9709 - f1: 0.9647 - 607ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9587 - recall: 0.9711 - f1: 0.9649 - 606ms/step
step 160/170 - loss: 2.5309 - precision: 0.9582 - recall: 0.9707 - f1: 0.9644 - 605ms/step
step 170/170 - loss: 0.8877 - precision: 0.9583 - recall: 0.9709 - f1: 0.9645 - 605ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/7
Eval begin...
step 10/74 - loss: 0.3071 - precision: 0.9602 - recall: 0.9707 - f1: 0.9654 - 340ms/step
step 20/74 - loss: 0.1061 - precision: 0.9439 - recall: 0.9558 - f1: 0.9498 - 349ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9394 - recall: 0.9529 - f1: 0.9461 - 348ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9418 - recall: 0.9545 - f1: 0.9481 - 350ms/step
step 50/74 - loss: 6.1648 - precision: 0.9418 - recall: 0.9529 - f1: 0.9473 - 354ms/step
step 60/74 - loss: 0.9898 - precision: 0.9412 - recall: 0.9529 - f1: 0.9470 - 351ms/step
step 70/74 - loss: 0.8586 - precision: 0.9415 - recall: 0.9535 - f1: 0.9475 - 351ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9406 - recall: 0.9541 - f1: 0.9473 - 351ms/step
Eval samples: 2368
Epoch 9/30
step 10/170 - loss: 1.4065 - precision: 0.9571 - recall: 0.9663 - f1: 0.9617 - 628ms/step
step 20/170 - loss: 0.3045 - precision: 0.9626 - recall: 0.9740 - f1: 0.9683 - 614ms/step
step 30/170 - loss: 1.4958 - precision: 0.9599 - recall: 0.9705 - f1: 0.9652 - 608ms/step
step 40/170 - loss: 2.6230 - precision: 0.9588 - recall: 0.9701 - f1: 0.9644 - 608ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9590 - recall: 0.9713 - f1: 0.9651 - 605ms/step
step 60/170 - loss: 4.9303 - precision: 0.9608 - recall: 0.9731 - f1: 0.9669 - 601ms/step
step 70/170 - loss: 4.1390 - precision: 0.9615 - recall: 0.9729 - f1: 0.9672 - 604ms/step
step 80/170 - loss: 0.6599 - precision: 0.9608 - recall: 0.9724 - f1: 0.9665 - 603ms/step
step 90/170 - loss: 0.2190 - precision: 0.9618 - recall: 0.9729 - f1: 0.9673 - 603ms/step
step 100/170 - loss: 0.2741 - precision: 0.9614 - recall: 0.9733 - f1: 0.9673 - 602ms/step
step 110/170 - loss: 4.1240 - precision: 0.9611 - recall: 0.9723 - f1: 0.9666 - 603ms/step
step 120/170 - loss: 0.8259 - precision: 0.9616 - recall: 0.9725 - f1: 0.9670 - 604ms/step
step 130/170 - loss: 0.4677 - precision: 0.9616 - recall: 0.9725 - f1: 0.9670 - 605ms/step
step 140/170 - loss: 0.0000e+00 - precision: 0.9618 - recall: 0.9724 - f1: 0.9671 - 605ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9621 - recall: 0.9725 - f1: 0.9673 - 605ms/step
step 160/170 - loss: 0.1807 - precision: 0.9613 - recall: 0.9725 - f1: 0.9668 - 606ms/step
step 170/170 - loss: 1.2906 - precision: 0.9606 - recall: 0.9720 - f1: 0.9663 - 605ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/8
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9581 - recall: 0.9680 - f1: 0.9630 - 333ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9414 - recall: 0.9522 - f1: 0.9468 - 341ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9383 - recall: 0.9491 - f1: 0.9437 - 340ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9437 - recall: 0.9516 - f1: 0.9477 - 343ms/step
step 50/74 - loss: 3.1415 - precision: 0.9427 - recall: 0.9493 - f1: 0.9460 - 347ms/step
step 60/74 - loss: 0.6287 - precision: 0.9431 - recall: 0.9486 - f1: 0.9458 - 345ms/step
step 70/74 - loss: 0.5417 - precision: 0.9425 - recall: 0.9487 - f1: 0.9456 - 346ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9423 - recall: 0.9494 - f1: 0.9458 - 346ms/step
Eval samples: 2368
Epoch 10/30
step 10/170 - loss: 0.0000e+00 - precision: 0.9473 - recall: 0.9641 - f1: 0.9556 - 615ms/step
step 20/170 - loss: 0.0000e+00 - precision: 0.9408 - recall: 0.9557 - f1: 0.9482 - 609ms/step
step 30/170 - loss: 0.2386 - precision: 0.9420 - recall: 0.9583 - f1: 0.9501 - 607ms/step
step 40/170 - loss: 19.2905 - precision: 0.9413 - recall: 0.9598 - f1: 0.9505 - 606ms/step
step 50/170 - loss: 2.2084 - precision: 0.9431 - recall: 0.9611 - f1: 0.9520 - 600ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9422 - recall: 0.9594 - f1: 0.9507 - 603ms/step
step 70/170 - loss: 0.2782 - precision: 0.9419 - recall: 0.9593 - f1: 0.9505 - 602ms/step
step 80/170 - loss: 0.2192 - precision: 0.9433 - recall: 0.9601 - f1: 0.9516 - 602ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9431 - recall: 0.9606 - f1: 0.9518 - 602ms/step
step 100/170 - loss: 0.2114 - precision: 0.9442 - recall: 0.9611 - f1: 0.9526 - 598ms/step
step 110/170 - loss: 23.1482 - precision: 0.9451 - recall: 0.9621 - f1: 0.9535 - 599ms/step
step 120/170 - loss: 9.3573 - precision: 0.9450 - recall: 0.9618 - f1: 0.9533 - 600ms/step
step 130/170 - loss: 0.0000e+00 - precision: 0.9460 - recall: 0.9623 - f1: 0.9541 - 601ms/step
step 140/170 - loss: 17.5295 - precision: 0.9454 - recall: 0.9619 - f1: 0.9535 - 601ms/step
step 150/170 - loss: 0.4457 - precision: 0.9461 - recall: 0.9619 - f1: 0.9539 - 602ms/step
step 160/170 - loss: 0.1673 - precision: 0.9454 - recall: 0.9615 - f1: 0.9534 - 603ms/step
step 170/170 - loss: 0.3054 - precision: 0.9459 - recall: 0.9618 - f1: 0.9538 - 603ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/9
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9479 - recall: 0.9685 - f1: 0.9581 - 333ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9348 - recall: 0.9623 - f1: 0.9483 - 342ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9322 - recall: 0.9599 - f1: 0.9459 - 341ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9346 - recall: 0.9603 - f1: 0.9473 - 344ms/step
step 50/74 - loss: 9.4212 - precision: 0.9323 - recall: 0.9577 - f1: 0.9448 - 348ms/step
step 60/74 - loss: 0.2021 - precision: 0.9328 - recall: 0.9579 - f1: 0.9452 - 345ms/step
step 70/74 - loss: 0.4219 - precision: 0.9329 - recall: 0.9584 - f1: 0.9455 - 345ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9325 - recall: 0.9583 - f1: 0.9452 - 345ms/step
Eval samples: 2368
Epoch 11/30
step 10/170 - loss: 0.1767 - precision: 0.9608 - recall: 0.9770 - f1: 0.9688 - 610ms/step
step 20/170 - loss: 0.0000e+00 - precision: 0.9615 - recall: 0.9742 - f1: 0.9678 - 605ms/step
step 30/170 - loss: 0.0000e+00 - precision: 0.9592 - recall: 0.9732 - f1: 0.9662 - 604ms/step
step 40/170 - loss: 2.0103 - precision: 0.9604 - recall: 0.9737 - f1: 0.9670 - 603ms/step
step 50/170 - loss: 12.3643 - precision: 0.9606 - recall: 0.9734 - f1: 0.9669 - 603ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9579 - recall: 0.9709 - f1: 0.9643 - 609ms/step
step 70/170 - loss: 0.0000e+00 - precision: 0.9582 - recall: 0.9711 - f1: 0.9646 - 606ms/step
step 80/170 - loss: 0.1425 - precision: 0.9581 - recall: 0.9697 - f1: 0.9639 - 606ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9590 - recall: 0.9715 - f1: 0.9652 - 604ms/step
step 100/170 - loss: 0.8140 - precision: 0.9580 - recall: 0.9712 - f1: 0.9646 - 606ms/step
step 110/170 - loss: 0.0000e+00 - precision: 0.9588 - recall: 0.9713 - f1: 0.9650 - 608ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9580 - recall: 0.9710 - f1: 0.9644 - 610ms/step
step 130/170 - loss: 0.1331 - precision: 0.9582 - recall: 0.9710 - f1: 0.9645 - 608ms/step
step 140/170 - loss: 1.0737 - precision: 0.9580 - recall: 0.9710 - f1: 0.9644 - 607ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9572 - recall: 0.9708 - f1: 0.9640 - 607ms/step
step 160/170 - loss: 15.2511 - precision: 0.9574 - recall: 0.9706 - f1: 0.9640 - 606ms/step
step 170/170 - loss: 0.9426 - precision: 0.9579 - recall: 0.9709 - f1: 0.9644 - 606ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/10
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9565 - recall: 0.9680 - f1: 0.9622 - 336ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9411 - recall: 0.9555 - f1: 0.9483 - 346ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9395 - recall: 0.9551 - f1: 0.9473 - 345ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9417 - recall: 0.9556 - f1: 0.9486 - 348ms/step
step 50/74 - loss: 9.0334 - precision: 0.9399 - recall: 0.9548 - f1: 0.9473 - 352ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9400 - recall: 0.9546 - f1: 0.9473 - 350ms/step
step 70/74 - loss: 0.4106 - precision: 0.9395 - recall: 0.9551 - f1: 0.9472 - 349ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9389 - recall: 0.9548 - f1: 0.9468 - 350ms/step
Eval samples: 2368
Epoch 12/30
step 10/170 - loss: 0.0409 - precision: 0.9686 - recall: 0.9799 - f1: 0.9742 - 623ms/step
step 20/170 - loss: 0.1095 - precision: 0.9698 - recall: 0.9770 - f1: 0.9733 - 612ms/step
step 30/170 - loss: 5.7944 - precision: 0.9670 - recall: 0.9766 - f1: 0.9718 - 605ms/step
step 40/170 - loss: 22.8293 - precision: 0.9665 - recall: 0.9759 - f1: 0.9712 - 603ms/step
step 50/170 - loss: 0.1391 - precision: 0.9672 - recall: 0.9766 - f1: 0.9718 - 600ms/step
step 60/170 - loss: 0.2796 - precision: 0.9673 - recall: 0.9763 - f1: 0.9718 - 598ms/step
step 70/170 - loss: 0.0000e+00 - precision: 0.9661 - recall: 0.9760 - f1: 0.9710 - 599ms/step
step 80/170 - loss: 0.0000e+00 - precision: 0.9642 - recall: 0.9742 - f1: 0.9692 - 601ms/step
step 90/170 - loss: 1.0060 - precision: 0.9632 - recall: 0.9740 - f1: 0.9686 - 602ms/step
step 100/170 - loss: 0.0000e+00 - precision: 0.9630 - recall: 0.9738 - f1: 0.9683 - 603ms/step
step 110/170 - loss: 6.3978 - precision: 0.9628 - recall: 0.9737 - f1: 0.9682 - 603ms/step
step 120/170 - loss: 2.9741 - precision: 0.9625 - recall: 0.9733 - f1: 0.9679 - 604ms/step
step 130/170 - loss: 0.1366 - precision: 0.9616 - recall: 0.9731 - f1: 0.9673 - 603ms/step
step 140/170 - loss: 0.0680 - precision: 0.9615 - recall: 0.9730 - f1: 0.9672 - 601ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9606 - recall: 0.9725 - f1: 0.9665 - 602ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9613 - recall: 0.9730 - f1: 0.9671 - 601ms/step
step 170/170 - loss: 0.0000e+00 - precision: 0.9618 - recall: 0.9730 - f1: 0.9673 - 600ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/11
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9415 - recall: 0.9620 - f1: 0.9516 - 335ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9266 - recall: 0.9544 - f1: 0.9403 - 341ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9265 - recall: 0.9557 - f1: 0.9409 - 340ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9317 - recall: 0.9578 - f1: 0.9446 - 343ms/step
step 50/74 - loss: 7.6531 - precision: 0.9287 - recall: 0.9564 - f1: 0.9423 - 348ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9295 - recall: 0.9562 - f1: 0.9427 - 346ms/step
step 70/74 - loss: 0.2289 - precision: 0.9280 - recall: 0.9567 - f1: 0.9421 - 346ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9273 - recall: 0.9571 - f1: 0.9419 - 346ms/step
Eval samples: 2368
Epoch 13/30
step 10/170 - loss: 0.0562 - precision: 0.9482 - recall: 0.9613 - f1: 0.9547 - 616ms/step
step 20/170 - loss: 0.1747 - precision: 0.9484 - recall: 0.9628 - f1: 0.9555 - 612ms/step
step 30/170 - loss: 0.0000e+00 - precision: 0.9498 - recall: 0.9654 - f1: 0.9575 - 604ms/step
step 40/170 - loss: 0.0000e+00 - precision: 0.9551 - recall: 0.9668 - f1: 0.9609 - 599ms/step
step 50/170 - loss: 11.2888 - precision: 0.9540 - recall: 0.9666 - f1: 0.9603 - 598ms/step
step 60/170 - loss: 0.8426 - precision: 0.9560 - recall: 0.9684 - f1: 0.9622 - 597ms/step
step 70/170 - loss: 0.0663 - precision: 0.9566 - recall: 0.9685 - f1: 0.9625 - 598ms/step
step 80/170 - loss: 0.0345 - precision: 0.9561 - recall: 0.9686 - f1: 0.9623 - 598ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9584 - recall: 0.9701 - f1: 0.9642 - 601ms/step
step 100/170 - loss: 0.1843 - precision: 0.9601 - recall: 0.9710 - f1: 0.9655 - 601ms/step
step 110/170 - loss: 0.2809 - precision: 0.9610 - recall: 0.9721 - f1: 0.9665 - 601ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9618 - recall: 0.9723 - f1: 0.9670 - 603ms/step
step 130/170 - loss: 2.4491 - precision: 0.9618 - recall: 0.9727 - f1: 0.9672 - 603ms/step
step 140/170 - loss: 0.0000e+00 - precision: 0.9625 - recall: 0.9728 - f1: 0.9676 - 603ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9625 - recall: 0.9728 - f1: 0.9676 - 605ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9626 - recall: 0.9730 - f1: 0.9678 - 604ms/step
step 170/170 - loss: 0.5205 - precision: 0.9620 - recall: 0.9729 - f1: 0.9674 - 603ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/12
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9616 - recall: 0.9663 - f1: 0.9640 - 343ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9417 - recall: 0.9525 - f1: 0.9471 - 348ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9430 - recall: 0.9526 - f1: 0.9478 - 346ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9450 - recall: 0.9532 - f1: 0.9490 - 349ms/step
step 50/74 - loss: 2.7836 - precision: 0.9435 - recall: 0.9516 - f1: 0.9475 - 353ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9450 - recall: 0.9519 - f1: 0.9485 - 350ms/step
step 70/74 - loss: 0.2467 - precision: 0.9453 - recall: 0.9528 - f1: 0.9490 - 349ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9449 - recall: 0.9530 - f1: 0.9490 - 350ms/step
Eval samples: 2368
Epoch 14/30
step 10/170 - loss: 0.0000e+00 - precision: 0.9677 - recall: 0.9747 - f1: 0.9712 - 587ms/step
step 20/170 - loss: 0.0000e+00 - precision: 0.9680 - recall: 0.9762 - f1: 0.9721 - 611ms/step
step 30/170 - loss: 0.0000e+00 - precision: 0.9651 - recall: 0.9762 - f1: 0.9706 - 603ms/step
step 40/170 - loss: 0.0000e+00 - precision: 0.9669 - recall: 0.9774 - f1: 0.9721 - 600ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9676 - recall: 0.9777 - f1: 0.9726 - 603ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9678 - recall: 0.9778 - f1: 0.9728 - 599ms/step
step 70/170 - loss: 0.0000e+00 - precision: 0.9672 - recall: 0.9769 - f1: 0.9720 - 599ms/step
step 80/170 - loss: 1.6375 - precision: 0.9670 - recall: 0.9772 - f1: 0.9721 - 599ms/step
step 90/170 - loss: 0.2718 - precision: 0.9670 - recall: 0.9764 - f1: 0.9717 - 601ms/step
step 100/170 - loss: 0.0000e+00 - precision: 0.9670 - recall: 0.9760 - f1: 0.9715 - 600ms/step
step 110/170 - loss: 0.0000e+00 - precision: 0.9669 - recall: 0.9766 - f1: 0.9717 - 601ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9664 - recall: 0.9769 - f1: 0.9717 - 602ms/step
step 130/170 - loss: 0.0000e+00 - precision: 0.9669 - recall: 0.9770 - f1: 0.9719 - 602ms/step
step 140/170 - loss: 0.0000e+00 - precision: 0.9674 - recall: 0.9773 - f1: 0.9723 - 598ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9677 - recall: 0.9776 - f1: 0.9726 - 598ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9680 - recall: 0.9774 - f1: 0.9727 - 597ms/step
step 170/170 - loss: 1.5205 - precision: 0.9684 - recall: 0.9778 - f1: 0.9731 - 598ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/13
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9538 - recall: 0.9652 - f1: 0.9595 - 335ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9421 - recall: 0.9555 - f1: 0.9488 - 342ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9401 - recall: 0.9533 - f1: 0.9467 - 341ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9426 - recall: 0.9541 - f1: 0.9483 - 345ms/step
step 50/74 - loss: 5.8878 - precision: 0.9421 - recall: 0.9528 - f1: 0.9474 - 349ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9435 - recall: 0.9526 - f1: 0.9480 - 347ms/step
step 70/74 - loss: 0.9192 - precision: 0.9426 - recall: 0.9526 - f1: 0.9476 - 346ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9418 - recall: 0.9524 - f1: 0.9471 - 346ms/step
Eval samples: 2368
Epoch 15/30
step 10/170 - loss: 0.0000e+00 - precision: 0.9737 - recall: 0.9763 - f1: 0.9750 - 619ms/step
step 20/170 - loss: 0.0000e+00 - precision: 0.9713 - recall: 0.9815 - f1: 0.9763 - 612ms/step
step 30/170 - loss: 0.0000e+00 - precision: 0.9741 - recall: 0.9809 - f1: 0.9775 - 614ms/step
step 40/170 - loss: 0.0680 - precision: 0.9736 - recall: 0.9802 - f1: 0.9769 - 610ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9734 - recall: 0.9808 - f1: 0.9771 - 607ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9728 - recall: 0.9802 - f1: 0.9765 - 610ms/step
step 70/170 - loss: 0.0000e+00 - precision: 0.9731 - recall: 0.9803 - f1: 0.9767 - 610ms/step
step 80/170 - loss: 0.0000e+00 - precision: 0.9729 - recall: 0.9804 - f1: 0.9766 - 608ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9735 - recall: 0.9805 - f1: 0.9770 - 604ms/step
step 100/170 - loss: 0.0000e+00 - precision: 0.9724 - recall: 0.9798 - f1: 0.9761 - 604ms/step
step 110/170 - loss: 1.0789 - precision: 0.9722 - recall: 0.9799 - f1: 0.9761 - 603ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9715 - recall: 0.9794 - f1: 0.9754 - 604ms/step
step 130/170 - loss: 0.0000e+00 - precision: 0.9702 - recall: 0.9788 - f1: 0.9745 - 603ms/step
step 140/170 - loss: 11.6717 - precision: 0.9706 - recall: 0.9791 - f1: 0.9748 - 603ms/step
step 150/170 - loss: 0.0000e+00 - precision: 0.9705 - recall: 0.9791 - f1: 0.9748 - 602ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9699 - recall: 0.9786 - f1: 0.9743 - 601ms/step
step 170/170 - loss: 0.0000e+00 - precision: 0.9696 - recall: 0.9785 - f1: 0.9740 - 599ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/14
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9447 - recall: 0.9641 - f1: 0.9543 - 332ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9357 - recall: 0.9577 - f1: 0.9466 - 341ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9337 - recall: 0.9566 - f1: 0.9450 - 341ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9348 - recall: 0.9573 - f1: 0.9459 - 344ms/step
step 50/74 - loss: 8.2618 - precision: 0.9330 - recall: 0.9551 - f1: 0.9439 - 348ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9330 - recall: 0.9549 - f1: 0.9439 - 347ms/step
step 70/74 - loss: 0.0149 - precision: 0.9321 - recall: 0.9553 - f1: 0.9436 - 346ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9314 - recall: 0.9554 - f1: 0.9433 - 347ms/step
Eval samples: 2368
Epoch 16/30
step 10/170 - loss: 8.7271 - precision: 0.9624 - recall: 0.9772 - f1: 0.9698 - 623ms/step
step 20/170 - loss: 0.0000e+00 - precision: 0.9625 - recall: 0.9748 - f1: 0.9686 - 615ms/step
step 30/170 - loss: 0.0000e+00 - precision: 0.9649 - recall: 0.9779 - f1: 0.9714 - 613ms/step
step 40/170 - loss: 0.7330 - precision: 0.9644 - recall: 0.9767 - f1: 0.9705 - 608ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9644 - recall: 0.9772 - f1: 0.9708 - 607ms/step
step 60/170 - loss: 0.8477 - precision: 0.9635 - recall: 0.9774 - f1: 0.9704 - 607ms/step
step 70/170 - loss: 2.0178 - precision: 0.9632 - recall: 0.9769 - f1: 0.9700 - 606ms/step
step 80/170 - loss: 0.0000e+00 - precision: 0.9635 - recall: 0.9772 - f1: 0.9703 - 605ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9644 - recall: 0.9772 - f1: 0.9708 - 604ms/step
step 100/170 - loss: 0.0000e+00 - precision: 0.9644 - recall: 0.9766 - f1: 0.9705 - 603ms/step
step 110/170 - loss: 0.0000e+00 - precision: 0.9638 - recall: 0.9760 - f1: 0.9699 - 603ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9634 - recall: 0.9758 - f1: 0.9696 - 603ms/step
step 130/170 - loss: 0.0000e+00 - precision: 0.9635 - recall: 0.9760 - f1: 0.9697 - 603ms/step
step 140/170 - loss: 0.0000e+00 - precision: 0.9635 - recall: 0.9746 - f1: 0.9691 - 602ms/step
step 150/170 - loss: 4.1852 - precision: 0.9636 - recall: 0.9749 - f1: 0.9692 - 603ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9628 - recall: 0.9746 - f1: 0.9687 - 603ms/step
step 170/170 - loss: 0.0000e+00 - precision: 0.9626 - recall: 0.9743 - f1: 0.9684 - 603ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/15
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9584 - recall: 0.9636 - f1: 0.9610 - 346ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9425 - recall: 0.9536 - f1: 0.9480 - 352ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9404 - recall: 0.9518 - f1: 0.9461 - 350ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9427 - recall: 0.9534 - f1: 0.9480 - 351ms/step
step 50/74 - loss: 5.7181 - precision: 0.9391 - recall: 0.9504 - f1: 0.9447 - 355ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9400 - recall: 0.9504 - f1: 0.9452 - 352ms/step
step 70/74 - loss: 0.0000e+00 - precision: 0.9399 - recall: 0.9513 - f1: 0.9455 - 351ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9398 - recall: 0.9516 - f1: 0.9456 - 352ms/step
Eval samples: 2368
Epoch 17/30
step 10/170 - loss: 2.8177 - precision: 0.9728 - recall: 0.9765 - f1: 0.9746 - 608ms/step
step 20/170 - loss: 1.3634 - precision: 0.9688 - recall: 0.9765 - f1: 0.9726 - 609ms/step
step 30/170 - loss: 0.0000e+00 - precision: 0.9709 - recall: 0.9780 - f1: 0.9744 - 605ms/step
step 40/170 - loss: 0.0000e+00 - precision: 0.9710 - recall: 0.9770 - f1: 0.9740 - 608ms/step
step 50/170 - loss: 0.0000e+00 - precision: 0.9693 - recall: 0.9775 - f1: 0.9734 - 609ms/step
step 60/170 - loss: 0.0000e+00 - precision: 0.9693 - recall: 0.9784 - f1: 0.9738 - 606ms/step
step 70/170 - loss: 0.0000e+00 - precision: 0.9706 - recall: 0.9787 - f1: 0.9747 - 602ms/step
step 80/170 - loss: 2.3523 - precision: 0.9701 - recall: 0.9786 - f1: 0.9743 - 600ms/step
step 90/170 - loss: 0.0000e+00 - precision: 0.9688 - recall: 0.9774 - f1: 0.9731 - 604ms/step
step 100/170 - loss: 0.0000e+00 - precision: 0.9684 - recall: 0.9775 - f1: 0.9729 - 602ms/step
step 110/170 - loss: 0.0000e+00 - precision: 0.9683 - recall: 0.9772 - f1: 0.9727 - 602ms/step
step 120/170 - loss: 0.0000e+00 - precision: 0.9686 - recall: 0.9777 - f1: 0.9731 - 604ms/step
step 130/170 - loss: 0.0000e+00 - precision: 0.9691 - recall: 0.9777 - f1: 0.9734 - 605ms/step
step 140/170 - loss: 0.0000e+00 - precision: 0.9693 - recall: 0.9775 - f1: 0.9734 - 605ms/step
step 150/170 - loss: 6.3472 - precision: 0.9685 - recall: 0.9771 - f1: 0.9728 - 605ms/step
step 160/170 - loss: 0.0000e+00 - precision: 0.9672 - recall: 0.9762 - f1: 0.9717 - 605ms/step
step 170/170 - loss: 0.4156 - precision: 0.9671 - recall: 0.9763 - f1: 0.9717 - 605ms/step
save checkpoint at /home/aistudio/paddle_ner/checkpoint/16
Eval begin...
step 10/74 - loss: 0.0000e+00 - precision: 0.9478 - recall: 0.9669 - f1: 0.9572 - 333ms/step
step 20/74 - loss: 0.0000e+00 - precision: 0.9324 - recall: 0.9571 - f1: 0.9446 - 342ms/step
step 30/74 - loss: 0.0000e+00 - precision: 0.9313 - recall: 0.9557 - f1: 0.9433 - 342ms/step
step 40/74 - loss: 0.0000e+00 - precision: 0.9319 - recall: 0.9567 - f1: 0.9441 - 346ms/step
step 50/74 - loss: 6.9929 - precision: 0.9314 - recall: 0.9556 - f1: 0.9433 - 351ms/step
step 60/74 - loss: 0.0000e+00 - precision: 0.9330 - recall: 0.9556 - f1: 0.9442 - 349ms/step
step 70/74 - loss: 0.0000e+00 - precision: 0.9335 - recall: 0.9564 - f1: 0.9448 - 349ms/step
step 74/74 - loss: 0.0000e+00 - precision: 0.9328 - recall: 0.9567 - f1: 0.9446 - 349ms/step
Eval samples: 2368
Epoch 17: Early stopping.
Best checkpoint has been saved at /home/aistudio/paddle_ner/checkpoint/best_model
save checkpoint at /home/aistudio/paddle_ner/checkpoint/final
# 训练,以loss作为指标训练
project_dir_name="paddle_ner" # 项目文件目录
project_root_dir = os.path.join(os.path.abspath('.'), project_dir_name) # 项目路径
train(project_root_dir)
[2023-01-09 13:45:22,426] [ INFO] - Downloading http://bj.bcebos.com/paddlenlp/models/transformers/bert/bert-wwm-ext-chinese-vocab.txt and saved to /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese
[2023-01-09 13:45:22,430] [ INFO] - Downloading bert-wwm-ext-chinese-vocab.txt from http://bj.bcebos.com/paddlenlp/models/transformers/bert/bert-wwm-ext-chinese-vocab.txt
100%|██████████| 107k/107k [00:00<00:00, 6.38MB/s]
[2023-01-09 13:45:22,557] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/tokenizer_config.json
[2023-01-09 13:45:22,561] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/special_tokens_map.json
5 训练过程及结果
-
EarlyStoping的monitor先后分别使用了loss和precision作为监控指标,耐心值设置为4 epoch,loos作为监控指标13 epoch自动停止,第9 eopch取得最好的模型;precision作为监控指标17 epoch自动停止,第13 epoch取得最好的模型。
-
monitor:loss 蓝色
-
monitor:precision 绿色
-
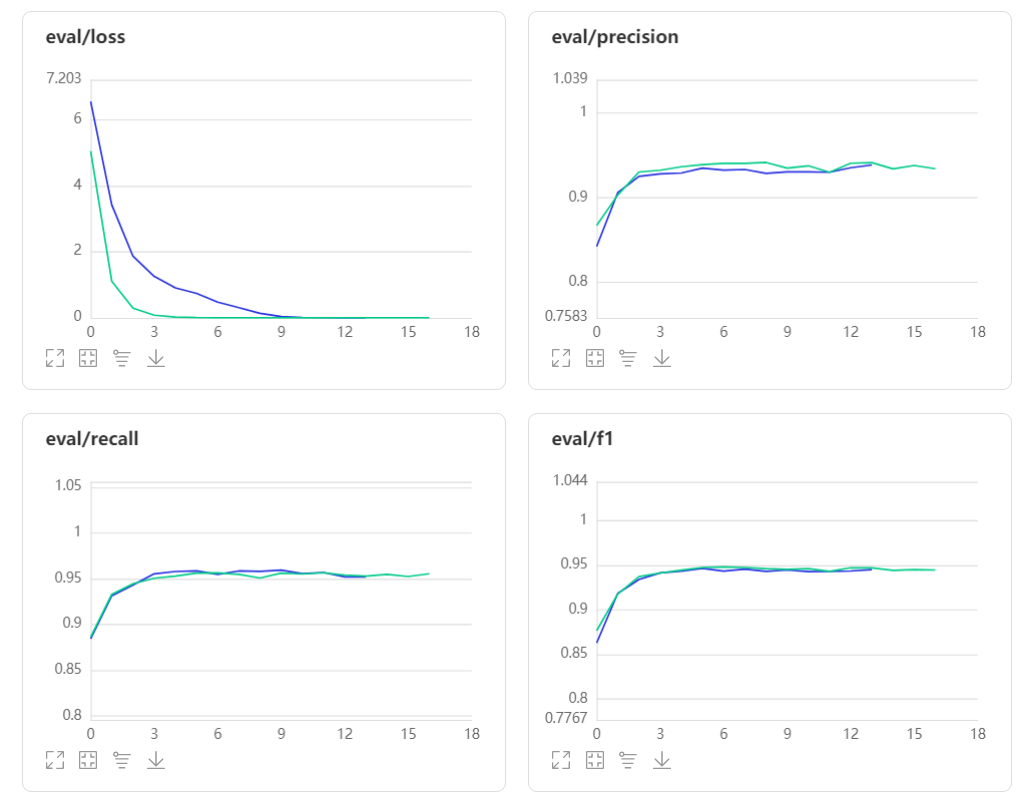
-
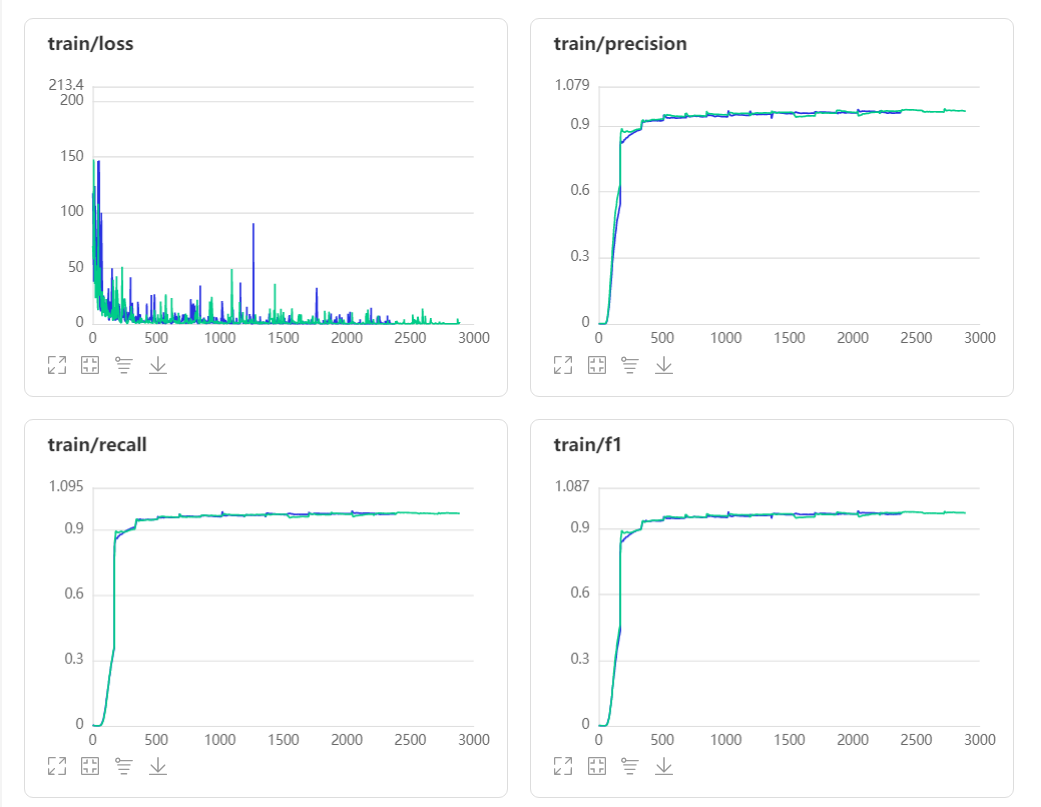
5.1 结果分析
训练集precision一般在95%-96%,随着epoch不断增加,precision也能达到97%以上,但是对比发现验证集准确率并没有上去,估计是有点过拟合,那部分模型直接丢掉,recall和F1-score都在96%-97%之间。
验证集precision一般在94%-95%,recall在95%-96%之间,F1-score在94%-95%之间
6 模型转换
训练完成后保存的模型只是模型的参数,需要将动态的模型保存为静态模型,才能用于部署。
6.1 先加载保存的最好的模型
# 加载最好的动态模型,模型文件已经删除,需要重新训练
lstm_hidden_size = 512 # 这个参数在train()函数中写死了,训练时可以根据需求调
model_name="best_model.pdparams"
# 加载映射文件
with open(os.path.join(project_root_dir, "data/id2labels.json"), "r", encoding="utf-8") as f:
id2labels = json.load(f)
# 加载bert
bert = BertModel.from_pretrained("bert-wwm-ext-chinese")
# 加载动态模型
model = NERModel(bert, lstm_hidden_size=lstm_hidden_size, num_class=len(id2labels))
model_dict = paddle.load(path = os.path.join(project_root_dir, "checkpoint", model_name))
model.load_dict(model_dict)
6.2 通过paddle.jit.save方法把动态的模型转换为静态模型,并保存,需要事先定义好输入句柄
# 将模型转换为静态图,并保存
input_spec = [
InputSpec([None, None], dtype="int64", name="input_ids"),
InputSpec([None, None], dtype="int64", name="token_type_ids"),
InputSpec([None], dtype="int64", name="seq_len")
]
# 保存为静态模型
paddle.jit.save(model,input_spec=input_spec, path=os.path.join(project_root_dir, "static_model","best_model"))
6.3 通过paddle.jit.load方法可直接加载静态模型
# 加载保存的静态模型
model=paddle.jit.load("paddle_ner/static_model/static_model")
7 测试
# 测试,测试的句子长度能超过BERT支持的最大长度即512,实际不能超过510,因为有[CLS] [SEP]
# 百度上找的两个例子
# 患者出现头晕、 乏力、伴耳鸣、心悸、气短,容易疲劳,注意力不容易集中,伴纳差,食欲不振,活动后加重,无端坐呼吸和夜间阵发性呼吸困难。
# 无发热、胸痛,无咳嗽咳痰;曾在明珠医院就诊,卡介苗示室性早搏,予以丹参片2#、 Tid 口服,无明显效果,今来我院就诊。TID口服,无明显效果,今来我院就诊。
model.eval()
# 加载映射文件
with open("paddle_ner/data/id2labels.json", "r", encoding="utf-8") as f:
id2labels = json.load(f)
with open("paddle_ner/data/label2name.json", "r", encoding="utf-8") as f:
label2name = json.load(f)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-wwm-ext-chinese")
# 测试加载的模型
text = "患者出现头晕、 乏力、伴耳鸣、心悸、气短,容易疲劳,注意力不容易集中,伴纳差,食欲不振,活动后加重,无端坐呼吸和夜间阵发性呼吸困难。"
,容易疲劳,注意力不容易集中,伴纳差,食欲不振,活动后加重,无端坐呼吸和夜间阵发性呼吸困难。
# 无发热、胸痛,无咳嗽咳痰;曾在明珠医院就诊,卡介苗示室性早搏,予以丹参片2#、 Tid 口服,无明显效果,今来我院就诊。TID口服,无明显效果,今来我院就诊。
model.eval()
# 加载映射文件
with open("paddle_ner/data/id2labels.json", "r", encoding="utf-8") as f:
id2labels = json.load(f)
with open("paddle_ner/data/label2name.json", "r", encoding="utf-8") as f:
label2name = json.load(f)
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained("bert-wwm-ext-chinese")
# 测试加载的模型
text = "患者出现头晕、 乏力、伴耳鸣、心悸、气短,容易疲劳,注意力不容易集中,伴纳差,食欲不振,活动后加重,无端坐呼吸和夜间阵发性呼吸困难。"
test(text,id2labels,label2name,tokenizer,model)
[2022-07-27 23:39:04,349] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/bert-wwm-ext-chinese/bert-wwm-ext-chinese-vocab.txt
[1 3 3 3 3 9 8 3 3 3 3 3 3 9 8 3 9 8 3 9 8 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 9 8 8 8 3 2]
[(4, 5, 'SIGNS'), (12, 13, 'SIGNS'), (15, 16, 'SIGNS'), (18, 19, 'SIGNS')]
患者出现头晕、 乏力、伴耳鸣、心悸、气短,容易疲劳,注意力不容易集中,伴纳差,食欲不振,活动后加重,无端坐呼吸和夜间阵发性呼吸困难。
[{'entity': '头晕', 'label': '症状和体征'}, {'entity': '耳鸣', 'label': '症状和体征'}, {'entity': '心悸', 'label': '症状和体征'}, {'entity': '气短', 'label': '症状和体征'}]
8 模型部署
Paddle Inference 是飞桨的原生推理库, 作用于服务器端和云端,提供高性能的推理能力。
Paddle Inference 功能特性丰富,性能优异,针对不同平台不同的应用场景进行了深度的适配优化,做到高吞吐、低时延,保证了飞桨模型在服务器端即训即用,快速部署。
若要在服务器部署,请下载static_model文件夹下的静态模型文件,部署模型代码请参考deployment_model.py文件,涉及的核心代码是加载模型,处理数据,喂入数据,解析预测结果
受bert的影响,代码中设置了推理最大长度限制为512,超长会被截断
创建一个Config对象,将模型文件地址作为参数传入,然后再根据配置加载模型
config = Config("checkpoint/static_model.pdmodel", "checkpoint/static_model.pdiparams") # 通过模型和参数文件路径加载
predictor = paddle_infer.create_predictor(config) # 根据预测配置创建预测引擎predictor
先通过获取输入Tensor的名称,再根据名称获取到输入Tensor的句柄
# 获取输入变量句柄
input_names = predictor.get_input_names()
inputs_ids_handle = predictor.get_input_handle(input_names[0]) # [batch_size,max_seq_len]
token_type_ids_handel = predictor.get_input_handle(input_names[1]) # [batch_size,max_seq_len]
seq_len_handel = predictor.get_input_handle(input_names[2]) # [seq_len]
通过process_text方法将文本处理成输入特征
input_ids, token_type_ids, seq_len = process_text(text_list)
在predict方法中,首先要将输入特征喂入模型,然后进行推理,再获取推理结果,最后解析推理结果
def predict(text=None, input_ids=None, token_type_ids=None, seq_len=None):
"""
预测函数
:param text:
:param input_ids:
:param token_type_ids:
:param seq_len:
:return:
"""
assert text is not None and len(
text) > 0 and input_ids is not None and token_type_ids is not None and seq_len is not None, "参数有误"
# 设置输入
inputs_ids_handle.copy_from_cpu(input_ids)
token_type_ids_handel.copy_from_cpu(token_type_ids)
seq_len_handel.copy_from_cpu(seq_len)
# 推理
predictor.run()
# 获取输出
output_names = predictor.get_output_names()
prediction_handel = predictor.get_output_handle(output_names[-1])
prediction = prediction_handel.copy_to_cpu()
# label_id转 label
prediction = np.reshape(prediction, [-1])
pred_labels = []
for idx in prediction:
label = id2labels[str(idx)]
pred_labels.append(label)
# 解析抽取结果,解析时排除[CLS] [SEP]
return parse_pred_labels_to_entity(text, pred_labels[1:-2])
部署模型推理示例:由于设置了循环,当输入q!时自动退出
9 项目优点和不足
- 项目的结果达到了不错的效果
- 项目能识别的实体类型不够丰富
- 设计模型没有过考虑实体重叠的情况
- 训练不够充分,没有对所有的超参数做系统调参,完全凭感觉
此文章为转载
原文链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 6
6 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)