

百度网盘AI大赛-表格检测第3名
百度网盘AI大赛-表格检测第3名 https://aistudio.baidu.com/aistudio/competition/detail/702/0/introduction
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
赛题介绍
- 赛题名称:表格检测
- 赛题描述:生活中,扫描技术越来越常见,通过手机就能将图片转化为可编辑的文档等;但是现在的技术在处理带有表格类型的文字的时候往往没有那么灵敏,把完整表格拆分成难以使用的零散个体似乎很常见又令人苦恼。本次比赛旨在解决这个问题,通过万能的算法,准确地识别表格在图片中的位置并标注。

相关资料
- 算法论文参考
- 公开数据集参考
- 开源代码参考
开发团队简介
浙江我财网络科技有限公司是通过浙江省高新技术认证并拥有多项自主知识产权的科技型企业,公司专注于智能化算法创造极大价值的场景应用,致力于互联网应用一体化解决方案的实施运营,竭力为社会输送高素养、高水平的应用型人才,始终坚持“数据场景 智能应用”的企业使命,为各级政府单位与规模企业提供涵盖全领域、全流程、全覆盖的数字化服务。目前,公司的产品涵盖数字化战略咨询、产品研发、软件和行业应用定制,协助各领域合作伙伴快速完成人工智能的应用创新、数字化转型的成效提升和人才梯队的输送建设,完成多个政府与集团企业的数字化管理项目经典案例,为行业客户搭建数字化交流与分享的桥梁,努力成为智能化应用的急行军与先锋队、数字化领域的引领者与实践者、应用型人才的孵化园与演练场。
代码说明
- configs 继承PaddleDetection工程并做修改,各算法调试、训练、对比用;
- dataset 继承PaddleDetection工程,未用到;
- demo 自定义工具函数的测试demo;
- deploy 继承PaddleDetection工程并做修改,各算法调试、推理、对比用;
- imgs 预测的默认图片文件夹;
- model 预测使用模型储存的文件夹;
- ppdet 继承PaddleDetection工程,各算法调试、推理、对比用;
- tools 继承PaddleDetection工程,训练用;
- train_data 数据集文件夹(原始材料、生成数据、训练集、测试集);
- eval.py 仿造官方评分规则编写的评估脚本,用于测试调优手段有效性的评估;
- predict.py 按照官方要求的主函数入口;
- read_picodet_table.py 目标检测数据集生成;
- read_tinypose_table.py 关键点数据集生成;
- read_picodet_small.py GPU小显存下目标检测数据集生成;
- read_tinypose_small.py GPU小显存下关键点数据集生成;
环境搭建
使用到 PaddleDetection 套件,在AI Studio中选择并下载 PaddleDetection-2.5.0 套件,然后通过以下指令安装套件环境,导入对应的python库。
import os
os.chdir("/home/aistudio")
!tar -xv -f PaddleDetection-2.5.0.tar.gz
os.chdir("/home/aistudio/PaddleDetection-2.5.0")
!pip install -r requirements.txt
!python setup.py install
数据清洗逻辑&数据处理过程
# 1.分析官方提供的数据集,得到3大类数据:409条黑桌纸张数据集,91条白桌纸张数据集,9500条单表无纸张数据集,共计10000个数据;
# 2.考虑到目前手头24G单卡训练机的设备限制及时间考虑,以三大类数据总和不超过10000为限,生成数据集(有条件的可扩大数据集数量,提升最终成绩);
# 3.从9500条单表无纸张数据集中平均抽取1/3左右组成第一部分数据集;
# 4.采用轮廓识别+人工纠正的方式,制作背景(黑桌纸张、白桌纸张),然后结合TableBank数据集,从中随机抽取6000张左右的数据集,通过透视变换+高斯模糊的处理,模拟生成剩下2/3数据集;
# 备注:考虑到TableBank数据集的庞大和生成过程的耗时,程序已将过程数据全部储存压缩,可直接解压tabletrack_all.zip压缩包得到,也可以解压后删除数据重新生成
os.chdir("/home/aistudio")
!unzip /home/aistudio/data/data192081/tabletrack_all.zip

# 如要重新生成训练数据集,可执行一下代码
#!rm -rf /home/aistudio/tabletrack/train_data/dettable
#!rm -rf /home/aistudio/tabletrack/train_data/posetable
#os.chdir("/home/aistudio/tabletrack")
#!python read_picodet_table.py
#!python read_tinypose_table.py
# 如设备比GPU 24G 单卡还要低的,需压缩数据集的相关尺寸和大小,可执行以下代码重新生成数据集
#!rm -rf /home/aistudio/tabletrack/train_data/det
#!rm -rf /home/aistudio/tabletrack/train_data/pose
#os.chdir("/home/aistudio/tabletrack")
#!python read_picodet_small.py
#!python read_tinypose_small.py
# 考虑模型训练文件所需的储存空间,将训练集以外的材料数据删除
!rm -rf /home/aistudio/tabletrack/train_data/train
!rm -rf /home/aistudio/tabletrack/train_data/det
!rm -rf /home/aistudio/tabletrack/train_data/pose

模型搭建思路
准备好环境和训练数据集,接下来就是模型的选择,主要实现所在最小外接矩形区域的识别以及左下、左上、右上、右下四个顶点的识别,结合paddle的Detection和OCR两个框架的应用,思路及实践过程如下:
- 参照PaddleOcr的 版面分析 去实现(PP-PicoDet 超轻量实时目标检测模型):
实践情况:可以识别矩形框,但因角度旋转的原因,并不能准确识别左下、左上、右上、右下四个顶点,因此需要有一个四顶点识别的模型; - 针对关键点识别,采用方式一(PP-YOLOE-R 高性能旋转框检测模型):
实践情况:针对旋转角度的表格比纯opencv实现要识别准确,但针对视觉伸缩、斜视的表格几乎没有办法,方案不可行;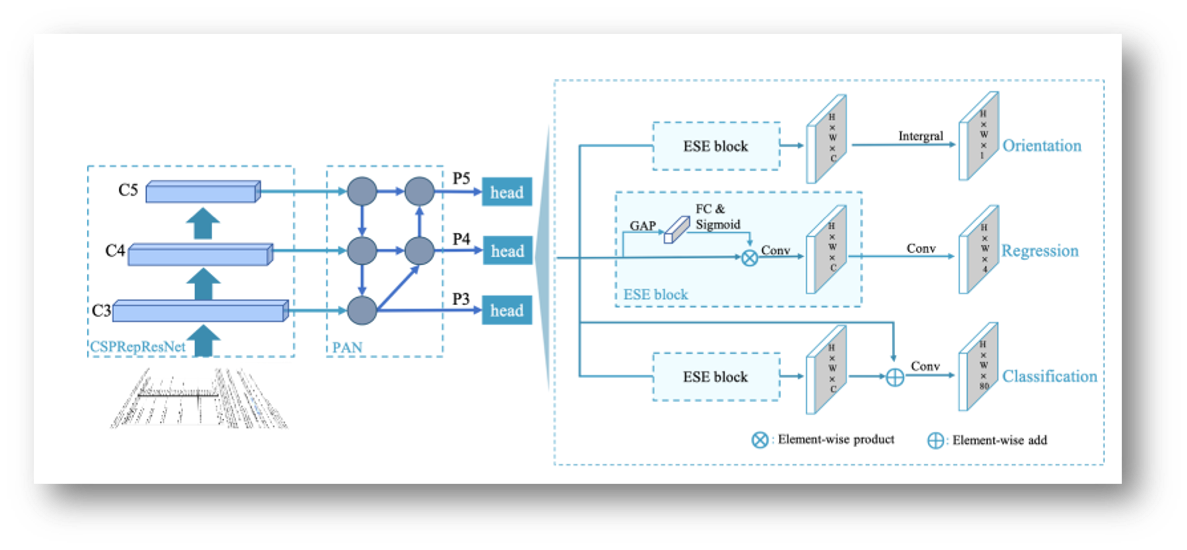
采用方式二(PP-TinyPose 人体骨骼关键点识别):
实践情况:结合PicoDet+TinyPose方式,可以基本实现表格以及四顶点的识别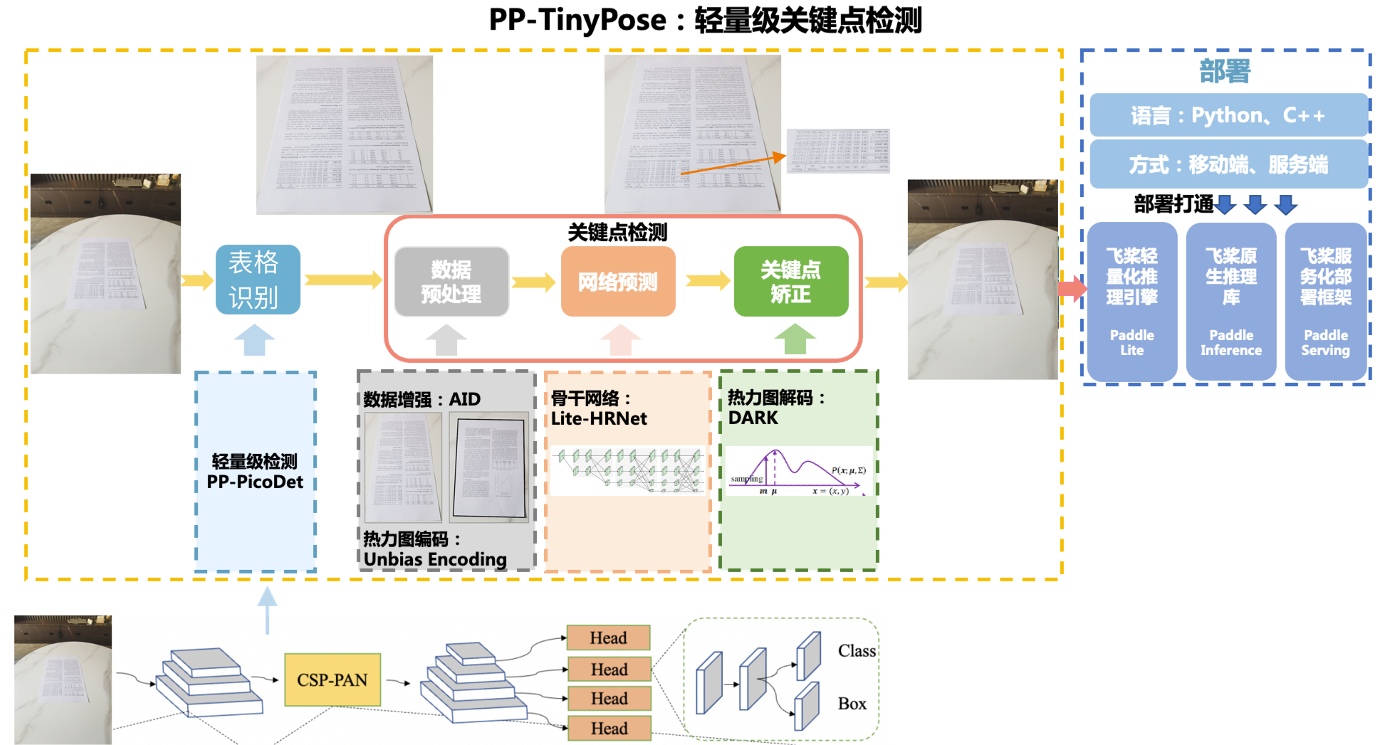
- 在基本实现的基础上,发现PicoDet的准确率相对Tinypose而言相对空间比较大,因此替换各种目标检测模型,以做比较,在有限的时间和尝试机会中,PP-YOLOE 高精度目标检测模型相对较优,
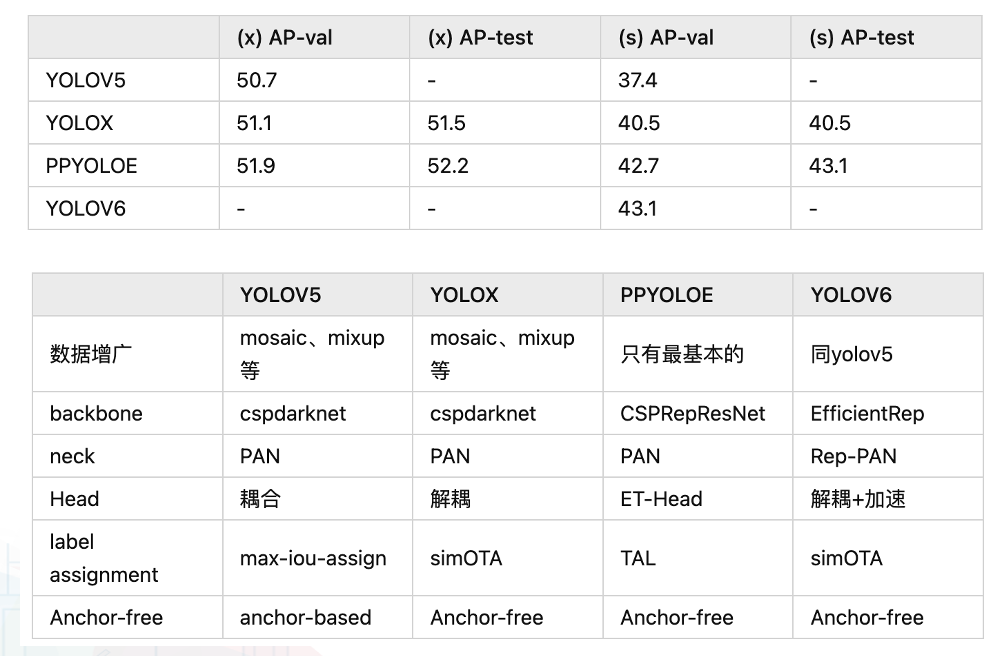
因此,最终模型搭建中采用Yoloe+TinyPose的组合来实现(可尝试不断替换和比较代替算法与模型,择优代替,可提高最终成绩);
在官方模型yml文件基础上,做模型调优、参数设置、参数遍历等方面优化和调试,得到yolox_x_300e_coco.yml和tinypose_small.yml,训练和导出模型过程如下:
# yolox
os.chdir("/home/aistudio/tabletrack")
# 训练模型 输入尺寸 640,batch_size 24G下取8/32G下取14,特征网络 CSPDarknet,激活函数 SiLU,暂时没有修改或调试出更优化的组合
!python -m paddle.distributed.launch tools/train.py -c configs/yolox/yolox_x_300e_coco.yml --amp --eval
# 导出模型 模型准确率超过93.8可复制到/home/aistudio/tabletrack/model/yolo,更迭模型
!python tools/export_model.py -c configs/yolox/yolox_x_300e_coco.yml -o weights=output/yolox_x_300e_coco/best_model.pdparams
# 训练时间较长 AI Studio 中断时可以用以下指令断点续练
#python -m paddle.distributed.launch tools/train.py -c configs/yolox/yolox_x_300e_coco.yml -r output/yolox_x_300e_coco/XX --amp --eval
# tinypose
os.chdir("/home/aistudio/tabletrack")
# 修改关键点 17 -> 4 修改库文件
! cp -f /home/aistudio/cocoeval.py /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/pycocotools/cocoeval.py
# 训练模型 输入尺寸 800,sigmas 调整成4个点 计划 0.15->1.15 时间不足以测试、目前默认[0.75, 0.75, 0.75, 0.75],骨干网络 LiteHRNet, 采用top-down(不用bottom-up)
!python tools/train.py -c configs/keypoint/tiny_pose/tinypose_small.yml --eval
# 导出模型 模型准确率超过96.3可复制到/home/aistudio/tabletrack/model/key,更迭模型
!python tools/export_model.py -c configs/keypoint/tiny_pose/tinypose_small.yml -o weights=output/tinypose_small/best_model.pdparams --output_dir=output_inference/
算法实现详情
- 运行 predict.py, 带输入图片文件夹和目标输出文件夹;
- 支持指令模式和运行调试模式,执行预测主函数 process(src_image_dir, save_dir);
- 以1600为高等比例resize图片尺寸,记比例为radio;
- 输入预测图片,调用目标检测模型和关键点识别模型自定义函数(包含预处理优化内容):
det_detector, key_detector, model_flag, results = unite_infer.key_infer(det_detector, key_detector, model_flag, read_image) - 得到预测结果,调用结果解析自定义函数(包含后处理优化内容):
rec_dict = get_recresult(boxes_list[index], keypoint_list[index], radio, org_image, filename) - 执行结束,写入结果文件:
f.write(json.dumps(result))
结果分析与优化
yolox 当前模型评估:
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.935
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.964
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.947
- Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.332
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.936
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.774
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.972
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.975
- Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.950
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.975
- [02/26 17:17:20] ppdet.engine INFO: Total sample number: 978, averge FPS: 32.94384339582133
- [02/26 17:17:20] ppdet.engine INFO: Best test bbox ap is 0.935.
- tinypose 当前模型评估:
- Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.963
- Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.979
- Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.967
- Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 1.000
- Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.963
- Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.972
- Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.990
- Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.971
- Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = 1.000
- Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.972
- | AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) |
- |—|—|—|—|—|—|—|—|—|—|—|
- | 0.963 | 0.979 | 0.967 | 1.000 | 0.963 | 0.972 | 0.990 | 0.971 | 1.000 | 0.972 |
- [02/26 13:02:56] ppdet.engine INFO: Total sample number: 1186, averge FPS: 18.78031311202696
- [02/26 13:02:57] ppdet.engine INFO: Best test keypoint ap is 0.963.
分析:
- 模型搭建过程中的择优组合:从开始的picodet、到yoloe-r、到picodet+tinypose、到目前的yolox+tinypose,precision和recall的baseline实现了从0.2、0.4、0.5、0.7的提升,尚未执行的猜想中,还有两个方向可能存在提升空间,一个是Ocr识别配合OpenCv轮廓识别等新组合;另外一种是在现有的组合里,按照应用场景,尝试更多特征网络和激活函数变换;
- 输入预处理的图像分辨率,目前试过的是640、1600以及原尺寸,得到的综合情况是1600在时间和准确率综合表现比较好,可通过二分法不断尝试关键分辨率下的综合表现,应该有略微提升的可能性;
- 图像后处理部分,在picodet+tinypose组合时,利用准确率筛选公式牺牲少量recall的情况下提高precision,利用两个模型的互相矫正同时提高precision和recall,利用凹凸四边形,针对性筛除或利用四边形矫正,综合起来提升比较大;因时间问题,采用yolox+tinypose尚未来得及调试和继承过来这些措施,后续这块应该还有一定的提升空间;
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为转载
原文链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)