
钢铁缺陷挑战赛(Paddlex-PPyolov2)
Paddlex-PPyolov2完成钢铁缺陷检测(可直接运行)
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一. 项目背景
缺陷检测技术广泛应用于工业场景,比如汽车制造中的车身表面缺陷检测,零件外观缺陷检测,工件裂纹检测等。其中,金属表面缺陷识别技术的应用可以在生产及制造阶段的质量控制方面发挥重要作用。本项目以飞桨学习赛:钢铁缺陷检测挑战赛为背景,基于PaddleX-PPYOLOv2对钢铁检测数据集进行训练,并对其结果进行预测。
1.1 部分预测结果



1.2 PaddleX介绍
PaddleX集成飞桨智能视觉领域图像分类、目标检测、语义分割、实例分割任务能力,将深度学习开发全流程从数据准备、模型训练与优化到多端部署端到端打通,同时PaddleX推出GUI界面软件。PaddleX更适合新入门的小白,或者没有python基础的传统机器视觉从业者。
PaddleX目前提供了FasterRCNN和YOLOv3两种检测结构,多种backbone模型,可满足开发者不同场景和性能的需求。
更多介绍:PaddleX
GUI产品全景图:
1.3 PPYOLOv2介绍
- PP-YOLO是PaddleDetection优化和改进的YOLOv3的模型,其精度(COCO数据集mAP)和推理速度均优于YOLOv4模型
- PP-YOLO在COCO数据集精度45.9%,Tesla V100预测速度72.9FPS,精度速度均优于YOLOv4
- PP-YOLO v2是对PP-YOLO模型的进一步优化,在COCO数据集精度49.5%,Tesla V100预测速度68.9FPS
基于又快又好的原则,本项目中采用PPYOLOV2-ResNet50_vd_dcn作为检测模型进行钢材缺陷检测。
PPYOLO在COCO数据集上的表现
| 模型 | 骨干网络 | 输入尺寸 | Box APval | Box APtest | V100 FP32(FPS) | V100 TensorRT FP16(FPS) | 模型下载 |
|---|---|---|---|---|---|---|---|
| PP-YOLO | ResNet50vd | 608 | 44.8 | 45.2 | 72.9 | 155.6 | model |
| PP-YOLOv2 | ResNet50vd | 640 | 49.1 | 49.5 | 68.9 | 106.5 | model |
| PP-YOLOv2 | ResNet101vd | 640 | 49.7 | 50.3 | 49.5 | 87.0 | model |
二. 安装paddlex
!pip install paddlex
三. 数据集介绍
本数据集来自NEU表面缺陷检测数据集,收集了6种典型的热轧带钢表面缺陷,即氧化铁皮压入(RS)、斑块(Pa)、开裂(Cr)、点蚀(PS)、夹杂(In)和划痕(Sc)。
下图为六种典型表面缺陷的示例,每幅图像的分辨率为200 * 200像素。
3.1解压数据集(只运行一次)
!unzip data/data165665/dataset.zip -d ./work/
3.2 数据集划分
使用PaddleX可以方便地进行数据集划分,平常训练可以将数据集划分为train:val:test=7:3:1,由于是比赛,这里将数据集划分为train:val=8:2
使用paddleX的数据划分后,会在work/dataset/train下生成
labels.txt,train_list.txt,val_list.txt,分别存储类别信息,训练样本列表,验证样本列表,Annotations代表训练数据的标注信息,JPEGImages代表训练样本图片
!paddlex --split_dataset --format VOC --dataset_dir work/dataset/train --val_value 0.2
四. 模型训练
4.1图像处理数据增强
定义训练和验证时的transforms
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/transforms/transforms.md
# ppyolov2数据增强
import paddlex as pdx
from paddlex import transforms
train_transforms = transforms.Compose([
transforms.MixupImage(mixup_epoch=250),
transforms.RandomDistort(),
transforms.RandomExpand(),
transforms.RandomCrop(),
transforms.Resize(target_size=640, interp='RANDOM'),
transforms.RandomHorizontalFlip(),
transforms.Normalize(),
])
eval_transforms = transforms.Compose([
transforms.Resize(target_size=640, interp='CUBIC'),
transforms.Normalize(),
])
4.2加载数据集
读取PascalVOC格式的检测数据集,并对样本进行相应的处理
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/datasets.md
train_dataset = pdx.datasets.VOCDetection(
data_dir='work/dataset/train',
file_list='work/dataset/train/train_list.txt',
label_list='work/dataset/train/labels.txt',
transforms=train_transforms,
shuffle=True)
eval_dataset = pdx.datasets.VOCDetection(
data_dir='work/dataset/train',
file_list='work/dataset/train/val_list.txt',
label_list='work/dataset/train/labels.txt',
transforms=eval_transforms,
)
2023-03-28 14:43:01 [INFO] Starting to read file list from dataset...
2023-03-28 14:43:03 [INFO] 1120 samples in file work/dataset/train/train_list.txt, including 1120 positive samples and 0 negative samples.
creating index...
index created!
2023-03-28 14:43:03 [INFO] Starting to read file list from dataset...
2023-03-28 14:43:03 [INFO] 280 samples in file work/dataset/train/val_list.txt, including 280 positive samples and 0 negative samples.
creating index...
index created!
reated!
4.3开始训练
用PPYoloV2-ResNet50训练,函数内置了piecewise学习率衰减策略和momentum优化器。训练时间较长,建议用V100以上算力,一共训练130个epoch,map达到70左右,每5轮保存一次,只想看效果可将epochs改为10
API说明:https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/detection.md#1
num_classes = len(train_dataset.labels)
model = pdx.det.PPYOLOv2(num_classes=num_classes, backbone='ResNet50_vd_dcn')
model.train(
#建议用V100算力以上
num_epochs=130,
train_dataset=train_dataset,
train_batch_size=8,
eval_dataset=eval_dataset,
pretrain_weights='COCO',
learning_rate=0.005 / 12,
warmup_steps=1000,
warmup_start_lr=0.0,
lr_decay_epochs=[75, 105],
save_interval_epochs=5,
save_dir='output/ppyolov2_r50vd_dcn',
use_vdl=True,
)
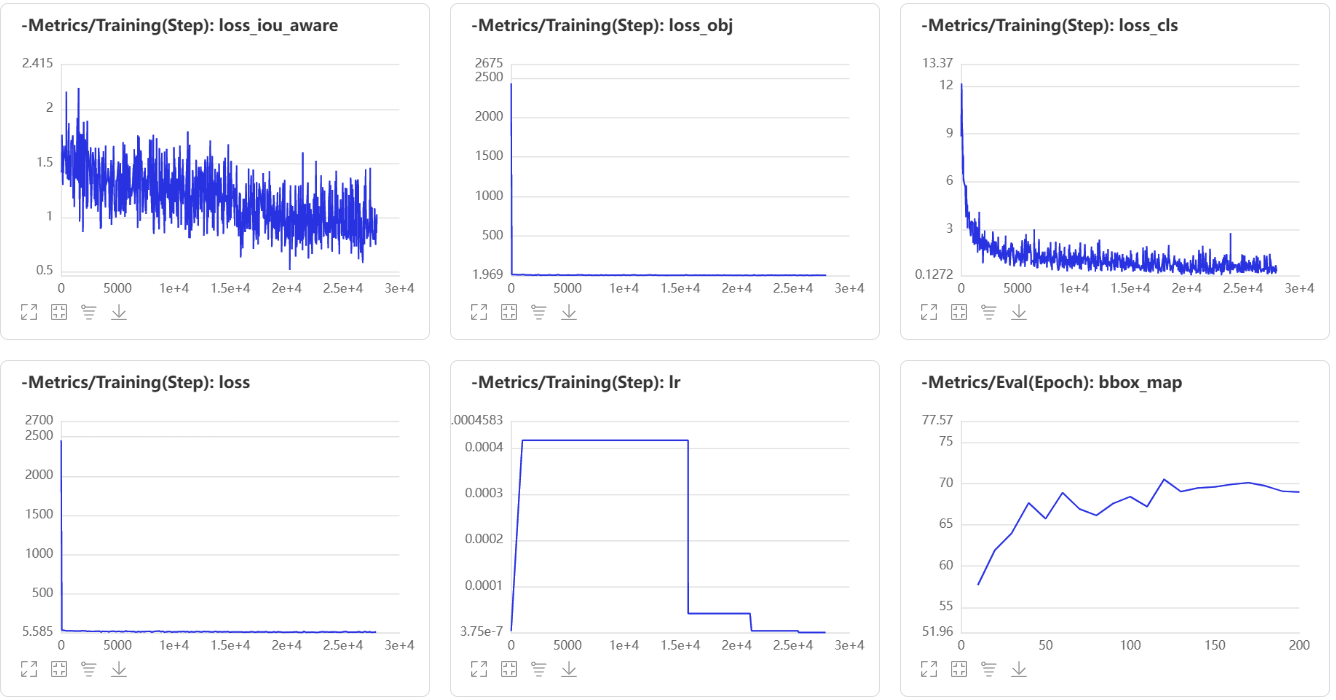
4.4训练可视化
在左侧可视化模块中使用VisualDL即可进行可视化操作,logdir选择output/ppyolov2_r50vd_dcn/vdl_log,模型文件选择output/ppyolov2_r50vd_dcn/best_model/model.pdparams
五. 进行预测
训练完成后可对test数据集中的图像进行预测



import os
name = [name for name in os.listdir('work/dataset/test/IMAGES') if name.endswith('.jpg')]
test_name_list=[]
for i in name:
tmp = os.path.splitext(i)
test_name_list.append(tmp[0])
import paddlex as pdx
# 读取模型
model = pdx.load_model('output/ppyolov2_r50vd_dcn/best_model')
#建立一个标号和题目要求的id的映射
num2index={'crazing':0,'inclusion':1,'pitted_surface':2,'scratches':3,'patches':4,'rolled-in_scale':5}
result_list = []
# 将置信度较好的框写入result_list
for index in test_name_list:
image_name = '/home/aistudio/work/dataset/test/IMAGES/'+index+'.jpg'
predicts = model.predict(image_name)
for predict in predicts:
if predict['score']<0.5: continue;
# 将bbox转化为题目中要求的格式
tmp=predict['bbox']
tmp[2]+=tmp[0]
tmp[3]+=tmp[1]
line=[index,tmp,num2index[predict['category']],predict['score']]
result_list.append(line)
将结果写入submission.csv文件
import numpy as np
result_array = np.array(result_list)
import pandas as pd
df = pd.DataFrame(result_array,columns=['image_id','bbox','category_id','confidence'])
df.sort_values(by='image_id',inplace=True)
df.to_csv('submission.csv',index=None)
结果可视化
for index in test_name_list:
image_name = 'work/dataset/test/IMAGES/'+index+'.jpg'
predicts = model.predict(image_name)
pdx.det.visualize(image_name, predicts, threshold=0.5, save_dir='output/T001/visualize')
六.模型改进方向
- 数据:利用直方图均衡化,平衡图像的明暗度,反复调整train_transforms中的参数,对样本数据增强进行改进
- 参数:调整学习率,batchsize,优化器等,对样本进行聚类生成更加合适的anchors
- 模型结构:用模型丰富的Paddledetection框架来训练,替换网络模型如PPYOLOE,faster-rcnn等
七.参考文献
请点击此处查看本环境基本用法.
Please click here for more detailed instructions.
此文章为转载
原文链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)