

基于PaddleOCRv3的手写英文单词识别
以PaddleOCRv3为框架,采用最新流行的OCR领域算法SVTR,完成手写英文单词识别算法搭建,识别效果要优于传统CRNN算法。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、项目背景及介绍:
手写英文识别(English Manuscript Recognition)是光学字符识别技术(OpticalCharacter Recognition,简称OCR)的一个分支,它研究的对象是:如何利用电子计算机自动辨认人手写在纸张上的英文单词及数字。
本项目以最新PaddleOCRv3为框架,采用最新的OCR领域算法SVTR,完成手写英文单词识别算法搭建。流程分为数据集构建、数据集处理、模型搭建与预测、推理等,数据集采用好未来教育提供的开源数据集,每张图片对应多个单词,相比传统单个手写数字识别具有一定难度。
识别结果:

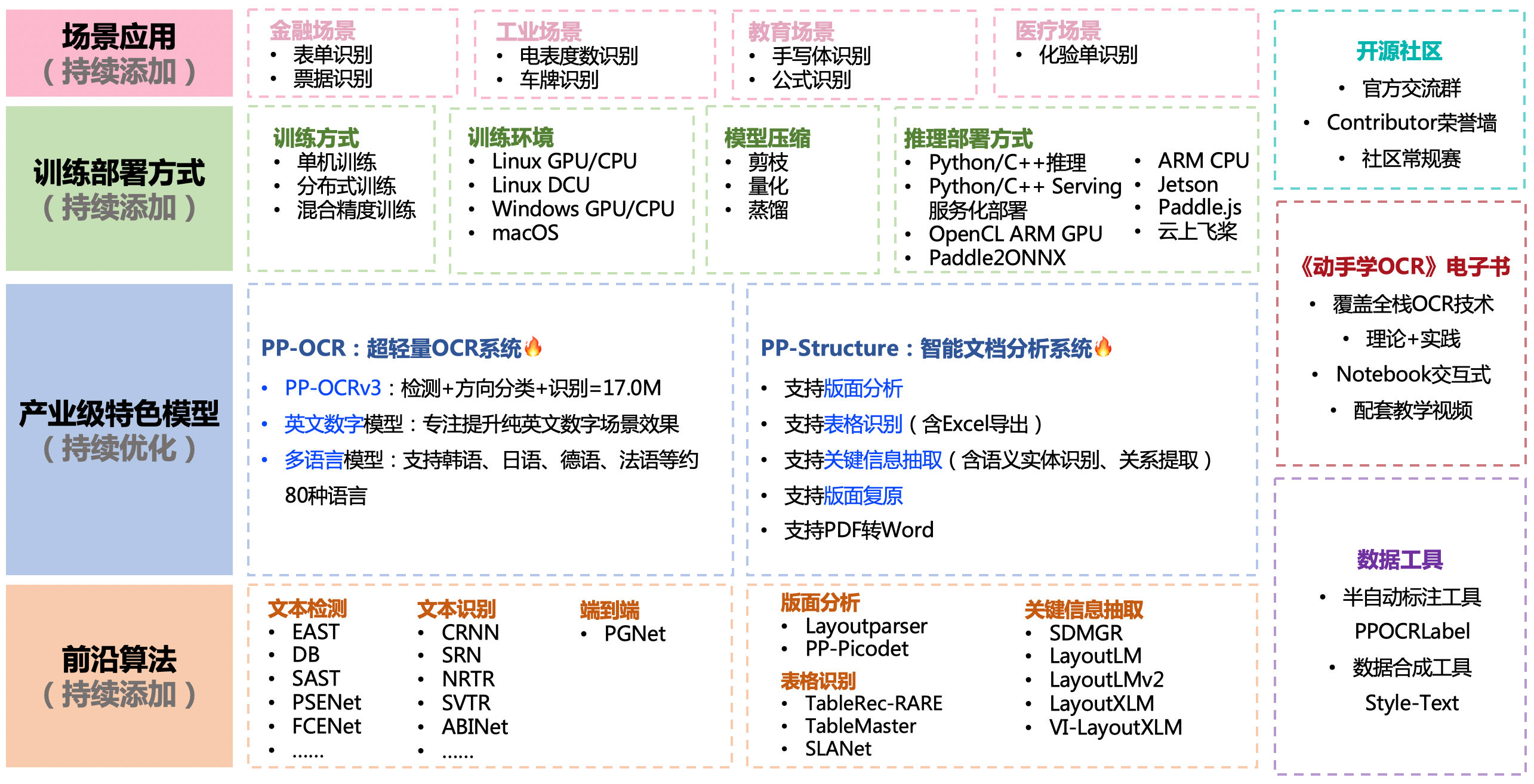
PaddleOCR结构:
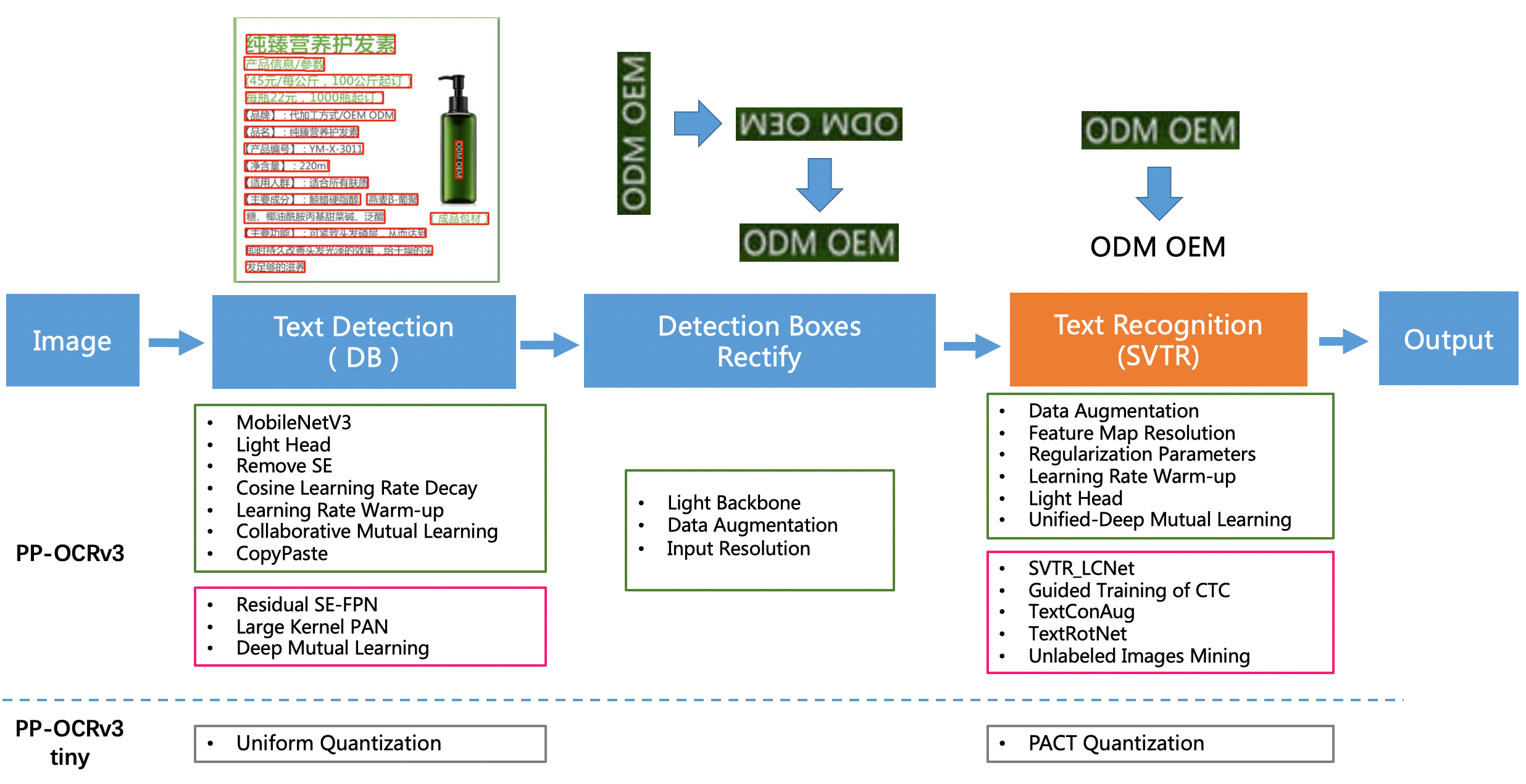
PaddleOCRv3介绍:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/README_ch.md
PP-OCRv3在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级:
-
PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
-
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
二、环境安装
#下载paddleocr
!git clone https://gitee.com/paddlepaddle/PaddleOCR
#安装相关依赖
%cd PaddleOCR
!pip install -r requirements.txt
三、数据集处理
数据集介绍
本项目数据集好未来提供的开源手写英文数据集,包含10000张手写英文图片,含概每张照片对应标注文件,可用于OCR识别项目。
图片样例1:

图片样例2:
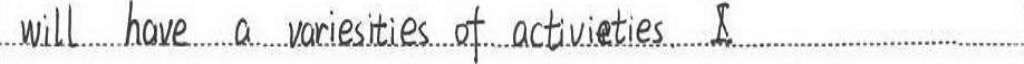
标注文txt件格式:
图片路径 +对应内容
1016_582_1.jpg $Visit China and have a one-day trip in
1016_390_2.jpg from NO.1 Middle School.The spring festival will
1016_1422_5.jpg our school,such as student's dining hall,library and so on.After this,
1016_1002_7.jpg you to the school kicteen. eat China food and drink China tea
1016_1401_2.jpg N0. 1 Middle School.I'm so glad that your team will
1016_158_0.jpg Dear Mr. Smith,
1016_1063_3.jpg China next Monday and stay at jiu jiang for day
1016_197_2.jpg could help them and they agrre! So now let me tell you where we'll go on the
1016_809_9.jpg and have a friendly talk with our headmaster.Next
#解压数据集
!unzip /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集.zip -d /home/aistudio/data/data192387/
#查看图片数量
ls -l /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition | grep "^-" | wc -l
数据集拆分
数据集按9:1划分训练集与测试集
#训练/测试数据清洗
path = '/home/aistudio/data/data128403/TAL_OCR_ENG手写英文数据集'
#数据准备
#格式示例: 1016_752_1.jpg I'm Li Hua,chairman of the Student Union from
with open(f'{path1}/label_10000.txt') as f:
lines = f.readlines()
# 9000用于训练, 1000用于测试
with open(f'{path1}//train.txt', 'w') as f1:
with open(f'{path1}//test.txt', 'w') as f2:
for index, line in enumerate(lines):
firstSpaceIndex = line.find(' ')
line2 = line[0:firstSpaceIndex] + '\t' + line[firstSpaceIndex+1:]
if index < 9000:
f1.write(line2)
if index >= 9000:
f2.write(line2)
print("数据处理完成")
!pwd
%cd PaddleOCR
!python ../split_data.py
数据集统计
因为本次为长文本英文数据集,需要做一些相关统计确定识别文件参数配置,依据结果是否调整配置文件中字典内容、最大字符长度及图片等参数配置。
代码具体内容见data.py,统计训练最多label长度、出现的label内容及映射。
!python /home/aistudio/data.py
数据集中包含字符最多的label长度为84
训练集中出现的label
{'$': 1089, 'V': 11, 'i': 23650, 's': 14007, 't': 24669, ' ': 61861, 'C': 521, 'h': 14694, 'n': 20575, 'a': 23662, 'd': 8406, 'v': 3354, 'e': 29818, 'o': 29365, '-': 518, 'y': 7935, 'r': 16273, 'p': 4390, 'f': 8127, 'm': 7558, 'N': 761, 'O': 236, '.': 6516, '1': 616, 'M': 1480, 'l': 15136, 'S': 1935, 'c': 8179, 'T': 994, 'g': 6502, 'w': 6525, 'u': 13047, ',': 4570, "'": 1797, 'b': 2447, 'A': 881, 'k': 2603, '0': 235, 'I': 2895, 'D': 592, 'x': 409, 'j': 712, '!': 97, 'Y': 646, ':': 95, 'L': 1710, 'H': 943, 'U': 491, 'W': 452, '?': 187, 'J': 1245, 'P': 136, '"': 88, 'F': 473, 'E': 62, 'X': 49, 'z': 88, ';': 4, 'G': 128, 'B': 192, '9': 16, '“': 2, 'Z': 17, '”': 2, 'q': 86, '5': 16, '3': 30, 'R': 46, '2': 34, 'K': 22, '7': 20, ':': 34, '8': 36, '6': 14, '>': 2, '—': 24, 'Q': 10, '(': 1, '~': 2, '4': 8, '…': 3, '?': 2, '\xad': 7, '《': 1, '》': 1, '、': 1, '/': 1, ',': 3, '\\': 2}
训练集+验证集中出现的label
{'$': 1211, 'V': 12, 'i': 26178, 's': 15551, 't': 27415, ' ': 68401, 'C': 574, 'h': 16219, 'n': 22836, 'a': 26230, 'd': 9341, 'v': 3724, 'e': 33031, 'o': 32641, '-': 582, 'y': 8813, 'r': 18080, 'p': 4829, 'f': 9016, 'm': 8414, 'N': 838, 'O': 260, '.': 7172, '1': 676, 'M': 1625, 'l': 16811, 'S': 2126, 'c': 9077, 'T': 1083, 'g': 7204, 'w': 7253, 'u': 14484, ',': 5098, "'": 1996, 'b': 2739, 'A': 989, 'k': 2890, '0': 269, 'I': 3190, 'D': 647, 'x': 451, 'j': 798, '!': 110, 'Y': 717, ':': 114, 'L': 1924, 'H': 1042, 'U': 534, 'W': 505, '?': 208, 'J': 1352, 'P': 150, '"': 100, 'F': 518, 'E': 70, 'X': 54, 'z': 96, ';': 6, 'G': 145, 'B': 212, '9': 18, '“': 2, 'Z': 18, '”': 2, 'q': 98, '5': 17, '3': 32, 'R': 47, '2': 36, 'K': 27, '7': 21, ':': 34, '8': 46, '6': 15, '>': 2, '—': 28, 'Q': 10, '(': 1, '~': 2, '4': 8, '…': 3, '?': 2, '\xad': 7, '《': 1, '》': 1, '、': 1, '/': 1, ',': 3, '\\': 2, '(': 24, '空': 24, '一': 24, '格': 24, ')': 24, '!': 1, '\xa0': 1}
构造 label - id 之间的映射
☯ 0
■ 1
□ 2
$ 3
V 4
i 5
s 6
t 7
8
C 9
h 10
n 11
a 12
d 13
v 14
e 15
o 16
- 17
y 18
r 19
p 20
f 21
m 22
N 23
O 24
. 25
1 26
M 27
l 28
S 29
c 30
T 31
g 32
w 33
u 34
, 35
' 36
b 37
A 38
k 39
0 40
I 41
D 42
x 43
j 44
! 45
Y 46
: 47
L 48
H 49
U 50
W 51
? 52
J 53
P 54
" 55
F 56
E 57
X 58
z 59
; 60
G 61
B 62
9 63
“ 64
Z 65
” 66
q 67
5 68
3 69
R 70
2 71
K 72
7 73
: 74
8 75
6 76
> 77
— 78
Q 79
( 80
~ 81
4 82
… 83
? 84
85
《 86
》 87
、 88
/ 89
, 90
\ 91
( 92
空 93
一 94
格 95
) 96
! 97
98
训练文件设置
1.下载预训练模型
!wget -P ./pretrain_models/ https://paddleocr.bj.bcebos.com/PP-OCRv3/english/en_PP-OCRv3_rec_slim_train.tar
#解压到/pretrain_models
!tar -xf /home/aistudio/PaddleOCR/pretrain_models/en_PP-OCRv3_rec_slim_train.tar -C /home/aistudio/PaddleOCR/pretrain_models
2.下载配置文件
!wget -P ../work https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.6/configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml
#安装相关名,每次启动环境需要重新安装,也可直接加入环境txt中。
!pip install imgaug
!pip install Levenshtein
!pip install pyclipper
!pip install lmdb
!pip install skimage
四、 模型训练
配置文件参考en_PP-OCRv3_rec.yml ,识别采用SVTR算法,配置数据集路径,调整训练轮数、学习率、batchsize等参数,设置图像信息(3,48,320)并开启可视化visualdl。
1.模型介绍
SVTR论文: Scene Text Recognition with a Single Visual Model
SVTR介绍:
SVTR是2022年最新提出的一种端到端文字识别模型,仅通过单个视觉模型一站式地解决特征提取和文本转录这两个任务。验证了单视觉模型也能在识别任务中有比视觉-语言模型更好的效果,同时也保证了更快的推理速度,同时经过改进的版本被应用于PaddleOCRV3中。
算法结构
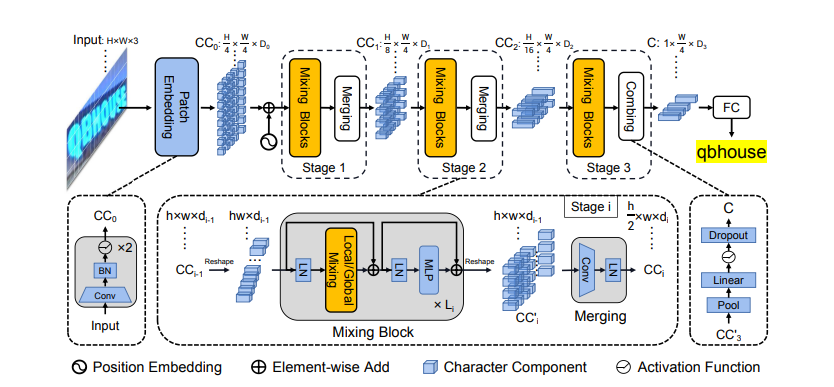
SVTR提出了一种用于场景文本识别的单视觉模型,使用特征提取模块包括**采用单视觉模型(类似ViT),基于patch-wise image tokenization框架,引入Mixing Block获取多粒度特征。完全摒弃了序列建模,在精度具有竞争力的前提下,模型参数量更少,速度更快。
算法总结
- SVTR首次发现单视觉模型可以达到与视觉语言模型相媲美甚至更高的准确率,并且其具有效率高和适应多语言的优点,在实际应用中很有前景。
- SVTR从字符组件的角度出发,逐渐的合并字符组件,自下而上地完成字符的识别。
- SVTR引入了局部和全局Mixing,分别用于提取字符组件特征和字符间依赖关系,与多尺度的特征一起,形成多粒度特征描述。
验证指标
PaddlleOCR指标以准确率及编辑距离为基础指标,识别返回结果为识别结果 + 置信度(result: slow 0.8795223 )

编辑距离:
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。在莱文斯坦距离中,可以删除、加入、替换字符串中的任何一个字元,也是较常用的编辑距离定义,常常提到编辑距离时,指的就是莱文斯坦距离。

归一化编辑距离:

2.设置配置文件
Global:
debug: false
use_gpu: true
epoch_num: 200
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/v3_en_mobile #模型保存路径
save_epoch_step: 3
eval_batch_step: [0, 500] 设置模型评估间隔
cal_metric_during_train: true
pretrained_model: #设置加载预训练模型路径
checkpoints: # 加载模型参数路径 用于中断后加载参数继续训练
save_inference_dir:
use_visualdl: True 设置是否启用visualdl进行可视化
infer_img: doc/imgs_words/ch/word_1.jpg
character_dict_path: ppocr/utils/en_dict.txt # 设置字典路径
max_text_length: &max_text_length 25 # 设置文本最大长度
infer_mode: false
use_space_char: true # 设置是否识别空格
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3_en.txt #推理保存结果
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR
Transform:
Backbone:
name: MobileNetV1Enhance
scale: 0.5
last_conv_stride: [1, 2]
last_pool_type: avg
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 64
depth: 2
hidden_dims: 120
use_guide: True
Head:
fc_decay: 0.00001
- SARHead:
enc_dim: 512
max_text_length: *max_text_length
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss:
- SARLoss:
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
ignore_space: False
Train:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition
ext_op_transform_idx: 1
label_file_list:
- /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape: [48, 320, 3]
max_text_length: *max_text_length
- RecAug:
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: true
batch_size_per_card: 128
drop_last: true
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition
label_file_list:
- /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/test.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
- RecResizeImg:
image_shape: [3, 48, 320]
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_sar
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 128
num_workers: 4
#执行训练,上述参数也可以使用命令行形式修改
%cd /home/aistudio/PaddleOCR
!python tools/train.py -c /home/aistudio/work/en_PP-OCRv3_rec.yml
注:目前已跑通代码,由于本人使用单卡,训练时间较长,可以使用高配置继续训练。
设置继续训练
#加载上次保存模型,继续训练
%cd PaddleOCR
!python tools/train.py -c /home/aistudio/work/en_PP-OCRv3_rec.yml -o Global.checkpoints="/home/aistudio/PaddleOCR/output/v3_en_mobile/best_accuracy"
预测结果
# 图片显示
import matplotlib.pyplot as plt
import cv2
def imshow(img_path):
im = cv2.imread(img_path)
plt.imshow(im )
# 随便显示一张图片
path = '/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_1_13.jpg'
#path = '/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_722_15.jpg'
imshow(path)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cJrz3fas-1681979821411)(main_files/main_29_0.png)]
!python tools/infer_rec.py -c /home/aistudio/work/en_PP-OCRv3_rec.yml \
-o Global.infer_img="/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_1_13.jpg" \
Global.pretrained_model="/home/aistudio/PaddleOCR/output/v3_en_mobile/best_accuracy"
# Global.pretrained_model="/home/aistudio/PaddleOCR/pretrain_models/en_PP-OCRv3_rec_slim_train/best_accuracy"
#由于训练时间较长且内存配置要求高,这里直接使用训练好的模型预测最终效果
%cd PaddleOCR
!python tools/infer_rec.py -c /home/aistudio/work/rec_en_number_lite_train.yml \
-o Global.infer_img="/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_1_13.jpg" \
Global.pretrained_model="/home/aistudio/PaddleOCR/output/v3_pre/best_accuracy"
path = '/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_1_13.jpg'
#path = '/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_722_15.jpg'
imshow(path)
[Errno 2] No such file or directory: 'PaddleOCR'
/home/aistudio/PaddleOCR
[2023/03/30 11:17:44] ppocr INFO: Architecture :
[2023/03/30 11:17:44] ppocr INFO: Backbone :
[2023/03/30 11:17:44] ppocr INFO: model_name : small
[2023/03/30 11:17:44] ppocr INFO: name : MobileNetV3
[2023/03/30 11:17:44] ppocr INFO: scale : 0.5
[2023/03/30 11:17:44] ppocr INFO: small_stride : [1, 2, 2, 2]
[2023/03/30 11:17:44] ppocr INFO: Head :
[2023/03/30 11:17:44] ppocr INFO: fc_decay : 1e-05
[2023/03/30 11:17:44] ppocr INFO: name : CTCHead
[2023/03/30 11:17:44] ppocr INFO: Neck :
[2023/03/30 11:17:44] ppocr INFO: encoder_type : rnn
[2023/03/30 11:17:44] ppocr INFO: hidden_size : 48
[2023/03/30 11:17:44] ppocr INFO: name : SequenceEncoder
[2023/03/30 11:17:44] ppocr INFO: Transform : None
[2023/03/30 11:17:44] ppocr INFO: algorithm : CRNN
[2023/03/30 11:17:44] ppocr INFO: model_type : rec
[2023/03/30 11:17:44] ppocr INFO: Eval :
[2023/03/30 11:17:44] ppocr INFO: dataset :
[2023/03/30 11:17:44] ppocr INFO: data_dir : /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition
[2023/03/30 11:17:44] ppocr INFO: label_file_list : ['/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/test.txt']
[2023/03/30 11:17:44] ppocr INFO: name : SimpleDataSet
[2023/03/30 11:17:44] ppocr INFO: transforms :
[2023/03/30 11:17:44] ppocr INFO: DecodeImage :
[2023/03/30 11:17:44] ppocr INFO: channel_first : False
[2023/03/30 11:17:44] ppocr INFO: img_mode : BGR
[2023/03/30 11:17:44] ppocr INFO: CTCLabelEncode : None
[2023/03/30 11:17:44] ppocr INFO: RecResizeImg :
[2023/03/30 11:17:44] ppocr INFO: image_shape : [3, 32, 320]
[2023/03/30 11:17:44] ppocr INFO: KeepKeys :
[2023/03/30 11:17:44] ppocr INFO: keep_keys : ['image', 'label', 'length']
[2023/03/30 11:17:44] ppocr INFO: loader :
[2023/03/30 11:17:44] ppocr INFO: batch_size_per_card : 256
[2023/03/30 11:17:44] ppocr INFO: drop_last : False
[2023/03/30 11:17:44] ppocr INFO: num_workers : 8
[2023/03/30 11:17:44] ppocr INFO: shuffle : False
[2023/03/30 11:17:44] ppocr INFO: Global :
[2023/03/30 11:17:44] ppocr INFO: cal_metric_during_train : True
[2023/03/30 11:17:44] ppocr INFO: character_dict_path : ppocr/utils/en_dict.txt
[2023/03/30 11:17:44] ppocr INFO: checkpoints : None
[2023/03/30 11:17:44] ppocr INFO: distributed : False
[2023/03/30 11:17:44] ppocr INFO: epoch_num : 200
[2023/03/30 11:17:44] ppocr INFO: eval_batch_step : [0, 100]
[2023/03/30 11:17:44] ppocr INFO: infer_img : /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_1_13.jpg
[2023/03/30 11:17:44] ppocr INFO: infer_mode : False
[2023/03/30 11:17:44] ppocr INFO: log_smooth_window : 20
[2023/03/30 11:17:44] ppocr INFO: max_text_length : 250
[2023/03/30 11:17:44] ppocr INFO: pretrained_model : /home/aistudio/PaddleOCR/output/v3_pre/best_accuracy
[2023/03/30 11:17:44] ppocr INFO: print_batch_step : 10
[2023/03/30 11:17:44] ppocr INFO: save_epoch_step : 3
[2023/03/30 11:17:44] ppocr INFO: save_inference_dir : None
[2023/03/30 11:17:44] ppocr INFO: save_model_dir : ./output/rec_en_number_lite
[2023/03/30 11:17:44] ppocr INFO: use_gpu : True
[2023/03/30 11:17:44] ppocr INFO: use_space_char : True
[2023/03/30 11:17:44] ppocr INFO: use_visualdl : True
[2023/03/30 11:17:44] ppocr INFO: Loss :
[2023/03/30 11:17:44] ppocr INFO: name : CTCLoss
[2023/03/30 11:17:44] ppocr INFO: Metric :
[2023/03/30 11:17:44] ppocr INFO: main_indicator : acc
[2023/03/30 11:17:44] ppocr INFO: name : RecMetric
[2023/03/30 11:17:44] ppocr INFO: Optimizer :
[2023/03/30 11:17:44] ppocr INFO: beta1 : 0.9
[2023/03/30 11:17:44] ppocr INFO: beta2 : 0.999
[2023/03/30 11:17:44] ppocr INFO: lr :
[2023/03/30 11:17:44] ppocr INFO: learning_rate : 0.005
[2023/03/30 11:17:44] ppocr INFO: name : Cosine
[2023/03/30 11:17:44] ppocr INFO: name : Adam
[2023/03/30 11:17:44] ppocr INFO: regularizer :
[2023/03/30 11:17:44] ppocr INFO: factor : 1e-05
[2023/03/30 11:17:44] ppocr INFO: name : L2
[2023/03/30 11:17:44] ppocr INFO: PostProcess :
[2023/03/30 11:17:44] ppocr INFO: name : CTCLabelDecode
[2023/03/30 11:17:44] ppocr INFO: Train :
[2023/03/30 11:17:44] ppocr INFO: dataset :
[2023/03/30 11:17:44] ppocr INFO: data_dir : /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition
[2023/03/30 11:17:44] ppocr INFO: label_file_list : ['/home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/train.txt']
[2023/03/30 11:17:44] ppocr INFO: name : SimpleDataSet
[2023/03/30 11:17:44] ppocr INFO: transforms :
[2023/03/30 11:17:44] ppocr INFO: DecodeImage :
[2023/03/30 11:17:44] ppocr INFO: channel_first : False
[2023/03/30 11:17:44] ppocr INFO: img_mode : BGR
[2023/03/30 11:17:44] ppocr INFO: RecAug : None
[2023/03/30 11:17:44] ppocr INFO: CTCLabelEncode : None
[2023/03/30 11:17:44] ppocr INFO: RecResizeImg :
[2023/03/30 11:17:44] ppocr INFO: image_shape : [3, 32, 320]
[2023/03/30 11:17:44] ppocr INFO: KeepKeys :
[2023/03/30 11:17:44] ppocr INFO: keep_keys : ['image', 'label', 'length']
[2023/03/30 11:17:44] ppocr INFO: loader :
[2023/03/30 11:17:44] ppocr INFO: batch_size_per_card : 256
[2023/03/30 11:17:44] ppocr INFO: drop_last : True
[2023/03/30 11:17:44] ppocr INFO: num_workers : 4
[2023/03/30 11:17:44] ppocr INFO: shuffle : True
[2023/03/30 11:17:44] ppocr INFO: profiler_options : None
[2023/03/30 11:17:44] ppocr INFO: train with paddle 2.4.0 and device Place(gpu:0)
W0330 11:17:44.301728 3748 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0330 11:17:44.305572 3748 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023/03/30 11:17:45] ppocr INFO: load pretrain successful from /home/aistudio/PaddleOCR/output/v3_pre/best_accuracy
[2023/03/30 11:17:45] ppocr INFO: infer_img: /home/aistudio/data/data192387/TAL_OCR_ENG手写英文数据集/data_composition/1016_1_13.jpg
[2023/03/30 11:17:47] ppocr INFO: result: Laces in our city.It is also interesting to climb 0.9326204657554626
[2023/03/30 11:17:47] ppocr INFO: success!
NG手写英文数据集/data_composition/1016_1_13.jpg
[2023/03/30 11:17:47] ppocr INFO: result: Laces in our city.It is also interesting to climb 0.9326204657554626
[2023/03/30 11:17:47] ppocr INFO: success!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XzCB1wxi-1681979821411)(main_files/main_31_1.png)]
模型推理
#注意将pretrained_model的路径设置为本地路径。
%cd PaddleOCR
!python3 tools/export_model.py -c /home/aistudio/work/en_PP-OCRv3_rec.yml -o Global.pretrained_model=/home/aistudio/PaddleOCR/output/v3_pre/iter_epoch_801 Global.save_inference_dir=./inference/rec_en
总结
本项目主要对手写英文单词进行识别,以最新PaddleOCRv3为框架,采用最新的OCR领域算法SVTR,完成手写英文单词识别算法搭建,在识别精度上要优于传统CRNN算法。但由于本数据集的单张内容为多个单词组成,内容较长,相比较传统单词识别识别更加困难,且训练时间长,需要训练配置高,后期大家可以尝试更多模型进行尝试,加快训练速度。
此文章为转载
原文链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)