
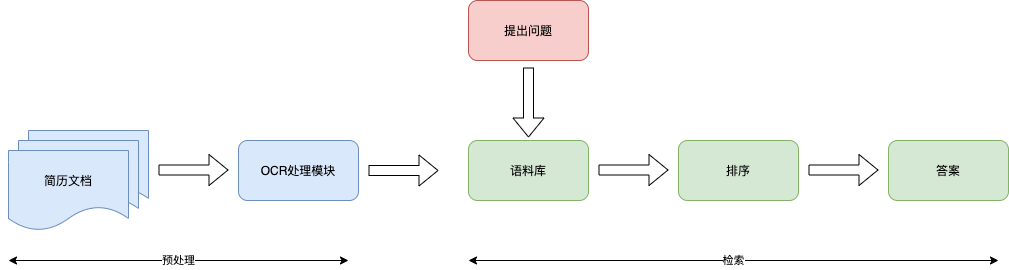
跨模态技术应用——构建简历跨模块智能问答库
跨模态文档问答 是跨模态的文档抽取任务,要求文档智能模型在文档中抽取能够回答文档相关问题的答案,需要模型在抽取和理解文档中文本信息的同时,还能充分利用文档的布局、字体、颜色等视觉信息。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
项目背景
企业里面,简历收集和简历筛选是2步相对独立的操作,在筛选简历的过程中,如果数据量小的情况下,每次根据问题全量检索一次所有简历没什么问题,但是如果简历的数量很大,很次检索都要花很多时间,严重影响工作效率,所以借鉴
重新调整了数据流程
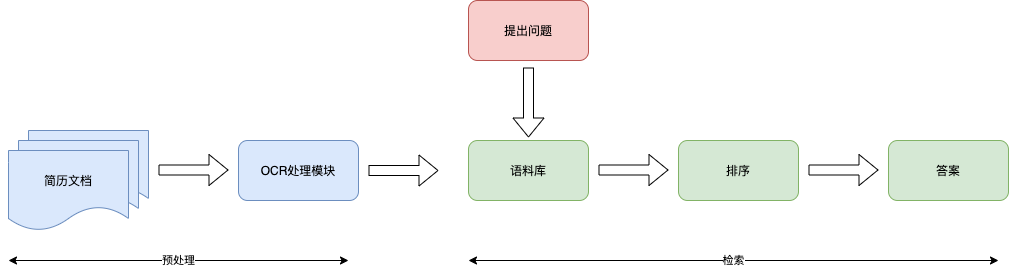
这样做的好处是扩展性更高
- 不需要提前准备需要的问题
- 更方便的检索一些未知条件,比如拥有的特殊技能
- 可以接入其他数据源,不限于简历库
参考资料
数据集介绍
数据集使用的是 简历信息抽取数据,共2000份非标准简历格式模板的人工构造数据。其中的文件分别是:
- result_sample.json 样例抽取结果文件
- sample.zip 样例简历数据,分为docx和pdf两种类型的文件
- train.json 训练标签数据
- train_20200121.zip 原始数据文件
- 192080.tar 模型微调checkkpoints
本文档主要使用的数据是
- train_20200121.zip中的pdf文件,用于简历文本抽取和标签制作
- train.json 训练标签数据,用于生成一些问答语料
环境准备
# 安装依赖库
!pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddle
!pip install paddlenlp==2.4
!pip install "paddleocr>=2.0.1"
!pip install PyMuPDF==1.19
!pip install yacs
数据准备
原始数据集存放在/home/aistudio/data里面
解压后文件放在/home/aistudio/work/data/train里面
# 解压数据文件
%cd /home/aistudio/
! bash data.sh
1、文档提取
第一步先从简历文件中提取相应的信息,数据文件格式有2种
- docx
经查看,发现docx文件和pdf文件数据一样,只不过文件存储格式不一样,所以只需要对pdf处理,转换成图片格式,放在/home/aistudio/work/data/images目录里面
import os
import fitz
def pdf2Image(pdfPath, imagePath):
fileNameList = os.listdir(pdfPath)
for fileName in fileNameList:
pdfDoc = fitz.open(os.path.join(pdfPath, fileName))
# 遍历pdf所有页面
for pg in range(pdfDoc.pageCount):
newFileName = imagePath + '/' + fileName +'_%s.png' % pg
if os.path.exists(newFileName):
continue
page = pdfDoc[pg]
rotate = int(0)
zoom_x = 4 # (1.33333333-->1056x816) (2-->1584x1224)
zoom_y = 4
mat = fitz.Matrix(zoom_x, zoom_y).prerotate(rotate)
pix = page.get_pixmap(matrix=mat, alpha=False)
if not os.path.exists(imagePath):
os.makedirs(imagePath)
pix.save(newFileName) # 将图片写入指定的文件夹内
print("保存pdf导出文件:" + newFileName)
if __name__ == "__main__":
# 指定pdf目录和输出的图片目录
pdf2Image("/home/aistudio/work/data/train/pdf", "/home/aistudio/work/data/images")
print("pdf导出图片任务完成")
2、生成语料库
通过上面脚本导出图片后,再使用paddleocr读取图片中的文字内容,保存到/home/aistudio/work/data/train.json文件中。
json文件格式参考:
{img_name: 0043e770a330, document: ["","",""],document_bbox: [[], []]}
其中img_name表示的是用户的简历文件名;document表示的是当前简历的分词数据;document_bbox表示的是分词在简历上的位置,分别用左上角的横纵坐标和右下角的横纵坐标表示。
import json
import os
import re
from paddleocr import PaddleOCR
from paddleocr import __version__ as paddleocr_version
from paddlenlp.transformers import LayoutXLMTokenizer
tokenizer = LayoutXLMTokenizer.from_pretrained("layoutxlm-base-uncased")
def get_all_chars(tokenizer):
all_chr = []
for i in range(30000):
tok_chr = tokenizer.tokenize(chr(i))
tok_chr = [tc.replace("▁", "") for tc in tok_chr]
while "" in tok_chr:
tok_chr.remove("")
tok_chr = "".join(tok_chr)
if len(tok_chr) != 1:
all_chr.append(i)
return all_chr
def merge_bbox(tok_bboxes):
min_gx = min([box[0] for box in tok_bboxes])
max_gx = max([box[1] for box in tok_bboxes])
min_gy = min([box[2] for box in tok_bboxes])
max_gy = max([box[3] for box in tok_bboxes])
height_g = max_gy - min_gy
width_g = max_gx - min_gx
height_m = 0
width_m = 0
for box in tok_bboxes:
x_min, x_max, y_min, y_max = box
height_m += y_max - y_min
width_m += x_max - x_min
height_m = height_m / len(tok_bboxes)
if (height_g - height_m) < 0.5 * height_m and width_g - width_m < 0.1 * width_m:
return False, [min_gx, max_gx, min_gy, max_gy]
else:
return True, tok_bboxes[0]
def xlm_parse(ocr_res, tokenizer):
doc_bboxes = []
all_chr = get_all_chars(tokenizer)
try:
new_tokens, new_token_boxes = [], []
for item in ocr_res:
new_tokens.extend(item["tokens"])
new_token_boxes.extend(item["token_box"])
# get layoutxlm tokenizer results and get the final results
temp_span_text = "".join(new_tokens)
temp_span_bbox = new_token_boxes
span_text = ""
span_bbox = []
# drop blank space
for text, bbox in zip(temp_span_text, temp_span_bbox):
if text == " ":
continue
else:
span_text += text
span_bbox += [bbox]
# span_tokens starts with "_"
span_tokens = tokenizer.tokenize(span_text)
span_tokens[0] = span_tokens[0].replace("▁", "")
while "" in span_tokens:
span_tokens.remove("")
doc_bboxes = []
i = 0
for tid, tok in enumerate(span_tokens):
tok = tok.replace("▁", "")
if tok == "":
doc_bboxes.append(span_bbox[i])
continue
if tok == "<unk>":
if tid + 1 == len(span_tokens):
tok_len = 1
else:
if span_tokens[tid + 1] == "<unk>":
tok_len = 1
else:
for j in range(i, len(span_text)):
if span_text[j].lower() == span_tokens[tid + 1][0]:
break
tok_len = j - i
elif ord(span_text[i]) in all_chr:
if tid + 1 == len(span_tokens):
tok_len = 1
elif "°" in tok and "C" in span_tokens[tid + 1]:
tok_len = len(tok) - 1
if tok_len == 0:
doc_bboxes.append(span_bbox[i])
continue
elif span_text[i] == "ⅱ":
if tok == "ii":
if span_text[i + 1] != "i":
tok_len = len(tok) - 1
else:
tok_len = len(tok)
elif tok == "i":
tok_len = len(tok) - 1
if tok_len == 0:
doc_bboxes.append(span_bbox[i])
continue
elif "m" in tok and "2" == span_tokens[tid + 1][0]:
tok_len = len(tok) - 1
if tok_len == 0:
doc_bboxes.append(span_bbox[i])
continue
elif ord(span_text[i + 1]) in all_chr:
tok_len = 1
else:
for j in range(i, len(span_text)):
if span_text[j].lower() == span_tokens[tid + 1][0]:
break
if span_text[j].lower() == "," and span_tokens[tid + 1][0] == ",":
break
if span_text[j].lower() == ";" and span_tokens[tid + 1][0] == ";":
break
if span_text[j].lower() == ")" and span_tokens[tid + 1][0] == ")":
break
if span_text[j].lower() == "(" and span_tokens[tid + 1][0] == "(":
break
if span_text[j].lower() == "¥" and span_tokens[tid + 1][0] == "¥":
break
tok_len = j - i
else:
if "�" == span_text[i]:
tok_len = len(tok) + 1
elif tok == "......" and "…" in span_text[i : i + 6]:
tok_len = len(tok) - 2
elif "ⅱ" in span_text[i + len(tok) - 1]:
if tok == "i":
tok_len = 1
else:
tok_len = len(tok) - 1
elif "°" in tok and "C" in span_tokens[tid + 1]:
tok_len = len(tok) - 1
else:
tok_len = len(tok)
assert i + tok_len <= len(span_bbox)
tok_bboxes = span_bbox[i : i + tok_len]
_, merged_bbox = merge_bbox(tok_bboxes)
doc_bboxes.append(merged_bbox)
i = i + tok_len
except Exception:
print("Error")
span_tokens = ["▁"] * 512
doc_bboxes = [[0, 0, 0, 0]] * 512
return span_tokens, doc_bboxes
def tokenize_ocr_res(ocr_reses):
"""
input:
ocr_res: the ocr result of the image
return:
new_reses: {
pid: {
"text": all text in each ocr_res,
"bounding_box": the bounding box of the ocr_res,
"tokens": all chars in ocr_res,
"token_box: bounding box of each chars in ocr_res
}
}
"""
new_reses = []
for img_name, ocr_res in ocr_reses:
new_res = []
for para in ocr_res:
text = para["text"]
text_box = para["bbox"]
x_min, y_min = [int(min(idx)) for idx in zip(*text_box)]
x_max, y_max = [int(max(idx)) for idx in zip(*text_box)]
text_chars = list(text.lower())
char_num = 0
for char in text_chars:
if re.match("[^\x00-\xff]", char):
char_num += 2
else:
char_num += 1
width = x_max - x_min
shift = x_min
new_token_boxes, new_tokens = [], []
for char in text_chars:
if re.match("[^\x00-\xff]", char):
tok_x_max = shift + width / char_num * 2
else:
tok_x_max = shift + width / char_num * 1
tok_x_min = shift
tok_y_min = y_min
tok_y_max = y_max
shift = tok_x_max
new_token_boxes.append([round(tok_x_min), round(tok_x_max), tok_y_min, tok_y_max])
new_tokens.append(char)
new_res.append(
{
"text": para["text"],
"bounding_box": para["bbox"],
"tokens": new_tokens,
"token_box": new_token_boxes,
}
)
new_reses.append((img_name, new_res))
return new_reses
def process_input(ocr_reses, tokenizer, save_ocr_path):
ocr_reses = tokenize_ocr_res(ocr_reses)
examples = []
for img_name, ocr_res in ocr_reses:
doc_tokens, doc_bboxes = xlm_parse(ocr_res, tokenizer)
doc_tokens.insert(0, "▁")
doc_bboxes.insert(0, doc_bboxes[0])
example = {"img_name": img_name, "document": doc_tokens, "document_bbox": doc_bboxes}
examples.append(example)
with open(save_ocr_path, "w", encoding="utf8") as f:
for example in examples:
json.dump(example, f, ensure_ascii=False)
f.write("\n")
print(f"ocr parsing results has been save to: {save_ocr_path}")
def ocr_preprocess(img_dir):
#todo:根据服务器配置判断是否使用gpu
ocr = PaddleOCR(use_angle_cls=True, lang="ch", use_gpu=True)
ocr_reses = []
img_names = sorted(os.listdir(img_dir))
# todo: 由于训练数据太大,执行耗时,先处理部分数据
total = 100
for img_name in img_names:
total = total - 1
if (total < 0):
break
img_path = os.path.join(img_dir, img_name)
img_key = img_name.split(".")[0]
if (len(img_key) == 0):
continue
parsing_res = ocr.ocr(img_path, cls=True)
ocr_res = []
for para in parsing_res:
if paddleocr_version > "2.6.0.1":
para = para[0]
ocr_res.append({"text": para[1][0], "bbox": para[0]})
ocr_reses.append((img_key, ocr_res))
return ocr_reses
if __name__ == "__main__":
img_dir = "/home/aistudio/work/data/images"
save_path = "/home/aistudio/work/data/train.json"
ocr_results = ocr_preprocess(img_dir)
process_input(ocr_results, tokenizer, save_path)
3、排序模块
3.1 训练数据格式化
直接使用数据集中train.json文件生成一些用于提升模型准确度的数据,文件保存到/home/aistudio/work/data/train_data.tsv中
import json
import os
def transform_train_data(jsonFile):
user_list = {}
with open(jsonFile, 'r') as f:
json_data = json.load(f)
for item_key in json_data:
user_info = json_data[item_key]
# user_info["file_key"] = item_key
user_name = user_info["姓名"]
#todo: 如果有一些数据需要提取,可以在此处格式化处理
# user_list[user_name] = json.dumps(user_info, ensure_ascii=False)
user_list[user_name + "的简历文件名"] = item_key
for sub_key in user_info:
if sub_key == "姓名":
continue
user_list[user_name + "的" + sub_key] = json.dumps(user_info[sub_key], ensure_ascii=False)
return user_list
def save_train_data(dataPath, data):
with open(dataPath, 'w') as f:
for key in data:
f.write(key + "\t\t" + data[key] + "\t1" + "\n")
jsonFile = "/home/aistudio/data/data40148/train.json"
dataFile = "/home/aistudio/work/data/train_data.tsv"
if not os.path.exists(dataFile):
out_data = transform_train_data(jsonFile)
save_train_data(dataFile, out_data)
print("执行完成")
3.2 训练模型
基于 base_model 在简历排序数据集上进行微调训练。
base_model 是 Dureader retrieval 数据集训练的排序模型,可点击下载,下载后将文件解压,放到checkpoints目录中。
%cd /home/aistudio/work/Rerank
# !unzip ./Rerank.zip
!rm -rf checkpoints
!mkdir checkpoints
!wget https://paddlenlp.bj.bcebos.com/models/base_ranker.tar.gz
!tar -xzvf base_ranker.tar.gz
!mv base_model ./checkpoints/
!rm -f base_ranker.tar.gz
# 开始训练模型
# 会占用大量gpu,建议上一步生成数据的时候,选择部分数据进行测试
%cd /home/aistudio/work/Rerank/
!head -20 ./data/train_data.tsv > ./data/train_data_test.tsv
!bash run_train.sh ./data/train_data_test.tsv ./checkpoints/base_model 5 1
3.3 测试模型
在模型训练完成后,便可以开启模型测试。
将用户问题和PaddleOCR识别结果的文本进行拼接,生成测试集。然后默认会加载./Rerank/checkpoints/ranker模型,并基于该模型进行测试。最终测试结果将保存至./data/demo.score文件中。
# 先去Rerank/output找到合适的模块,然后将模型重命名为 `ranker` 存放至 `./checkpoints/` 目录下
! rm -rf /home/aistudio/work/Rerank/checkpoints/ranker
# output目录下面的文件受训练时参数变动影响,所以需要修改此处,保证训练结果集存在
! cp -r /home/aistudio/work/Rerank/output/step_6 /home/aistudio/work/Rerank/checkpoints/ranker
%cd /home/aistudio/work/Rerank/
!bash run_test.sh 学士学位的人
4、跨模态阅读理解模块
跨模态阅读理解模型的训练集文件为/home/aistudio/work/data/train.json,其中重要的信息包括:“img_name”, “document”, “document_bbox”
- “img_name”: 简历文件名称
- “document”:OCR模块识别出的文字(token)
- “document_bbox”:每个token在简历上对应的坐标,分别对应(x_min, x_max, y_min, y_max)
4.1 模型训练
# 获取模型文件
%cd /home/aistudio/work/Extraction
!rm -rf ./checkpoints
!mkdir -p ./checkpoints
!wget https://paddlenlp.bj.bcebos.com/models/base_mrc.tar.gz
!tar -xzvf base_mrc.tar.gz -C ./checkpoints/
# 执行训练
%cd /home/aistudio/work/Extraction
!bash run_train.sh
!ls /home/aistudio/work/Extraction/checkpoints
# 重命名
%cd /home/aistudio/work/Extraction
%cp -r output/checkpoint-1240 checkpoints/
%mv checkpoints/checkpoint-1240 checkpoints/layoutxlm
4.2 模型测试
在模型训练完成后,便可以开启模型测试。实现根据用户问题,从给定的简历中抽取相关数据。
具体来讲,本节会分析排序模块输出的打分结果,然后获取与用户问题最相关的简历文档,并将两者相关信息传入至 跨模态阅读理解 模型中,模型将会分析并给出预测结果。
接下来,可以根据预测结果中布局信息,对于该简历符合条件的数据进行高亮显示,最终预测结果将保存至./answer.png文件中。
%cd /home/aistudio/work/Extraction
!bash run_test.sh 学士学位

小结
在本项目中,使用PaddleNLP提供的ERNIE-Layout文档智能问答能力,完成了针对特定业务需求的简历问答筛选功能开发
此文章为转载
原文链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)