
【官方】2023年“中国软件杯”大学生软件设计大赛飞桨小汪赛道基线系统
基于PaddleDetection和PaddleSeg开发环境感知算法,打造面向复杂环境的智能电力巡检机器狗。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、赛题简介:赋予机器狗感知能力
2023年“中国软件杯”大学生软件设计大赛飞桨小汪赛道的主题是“电力巡检智能软硬件系统开发”。参赛选手需要让飞桨小汪学会感知复杂环境,为智能电力工作提供实时智能分析与决策支持。

参赛选手需要基于给定数据集设计,利用百度飞桨PaddlePaddle深度学习平台及宇树四足机器狗平台,在现有模型的基础上设计环境感知算法,打造面向复杂环境的智能电力巡检机器狗。
二、数据集简介:飞桨小汪的知识源泉
该数据集有两个部分,分别用于目标检测任务和语义分割任务:
└── robot_dog_dataset # 数据集根目录
├── detection # 用于目标检测任务的数据集
│ ├── annotations # 标签
│ └── images # 图像
└── segmentation # 用于语义分割任务的数据集
├── annotations # 标签
└── images # 图像
# 在使用前,请先解压数据集
!unzip /home/aistudio/data/data199384/robot_dog_dataset.zip -d /home/aistudio/data/
1.检测数据集
用于目标检测任务的数据放在robot_dog_dataset/detection文件夹下。该数据集采用COCO格式给出标注信息,即将所有训练图像的标注都存放到一个json文件中,数据以字典嵌套的形式存放。
关于目标检测数据集的介绍以及相关处理方法,可参考:【目标检测】从数据的角度深入解析比赛数据集的处理方法
检测数据集涉及3个场景,分别是“火灾检测”、“工业仪表检测”和“安全帽检测”,共7114张图像。这些图像按8:2的比例划分为训练集、验证集,即训练集中有5691张图像,验证集中有1423张图像。图像示例如下:

2.分割数据集
用于语义分割任务的数据放在robot_dog_dataset/segmentation文件夹下,其大致结构如下:
└── segmentation # 分割数据根目录
├── annotations # 存放标签文件 .png
├── images # 存放图片 .jpg
├── labels.txt # 存放具体类别名称
├── test.txt # 不需要使用,空文件
├── train.txt # 训练集
└── val.txt # 验证集
通常分割任务的标注图片是单通道的灰度图,显示是全黑效果,无法直接观察标注是否正确。因此,我们可以在原来的灰度标注图中注入调色板,就可以得到伪彩色的标注图。
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 配置数据集根目录
root = "/home/aistudio/data/data199384/robot_dog_dataset/segmentation/"
train_file = open("{}train.txt".format(root), 'r')
# 取训练集中第一张图像
paths = train_file.readline().split(" ")
image_path = root + paths[0]
gt_path = root + paths[1].strip('\n')
# 可视化图像、标签
image, label = cv2.imread(image_path), cv2.imread(gt_path)
image, label = cv2.cvtColor(image, cv2.COLOR_BGR2RGB), cv2.cvtColor(label, cv2.COLOR_BGR2GRAY)
plt.subplot(1,2,1),
plt.title('Train Image')
plt.imshow(image)
plt.axis('off')
plt.subplot(1,2,2),
plt.title('Label')
plt.imshow(label)
plt.axis('off')
plt.show()

分割数据集只涉及1个场景,即“工业仪表检测”,共414张图像。这些图像按9:1的比例划分为训练集、验证集,即训练集中有374张图像,验证集中有40张图像。
三、参考思路:飞桨开发套件助力机器狗环境感知
在比赛任务中,“火灾检测”和“安全帽检测”是纯目标检测任务,“工业仪表检测”既有目标检测任务,又有语义分割任务。因此,在提交测评系统时,可以先进行检测任务,如果检测出的类别是“工业仪表”,那么再送入语义分割模型得到最终结果;如果检测结果是“火灾”、“安全帽”,那么就不需要送入语义分割模型,从而提高效率。

1.检测任务
下面,我们将基于检测数据集训练一个目标检测模型。
环境安装:PaddleDetection
PaddleDetection是一个基于PaddlePaddle的目标检测端到端开发套件,在提供丰富的模型组件和测试基准的同时,注重端到端的产业落地应用,通过打造产业级特色模型|工具、建设产业应用范例等手段,帮助开发者实现数据准备、模型选型、模型训练、模型部署的全流程打通,快速进行落地应用。
# 克隆PaddleDetection仓库
# 如果已经克隆,则不需要重复运行,可把第3行直接注释,从第6行开始运行
# !git clone https://gitee.com/PaddlePaddle/PaddleDetection.git
# 更新pip版本
!pip install --upgrade pip
# 安装其他依赖
%cd PaddleDetection
!pip install -r requirements.txt --user
# 编译安装paddledet
!python setup.py install
%cd ~
配置数据集
在PaddleDetection/configs/datasets文件夹下,新建一个配置文件dog_detection.yml:

配置超参数
在本教程中,使用的是PP-YOLOE模型,那么可以在PaddleDetection/configs/ppyoloe文件夹下找到README_cn.md,里面会有详细的说明。
| 模型 | Epoch | GPU个数 | 每GPU图片个数 | 骨干网络 | 输入尺寸 | Box APval 0.5:0.95 |
Box APtest 0.5:0.95 |
Params(M) | FLOPs(G) | V100 FP32(FPS) | V100 TensorRT FP16(FPS) | 模型下载 | 配置文件 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-YOLOE+_s | 80 | 8 | 8 | cspresnet-s | 640 | 43.7 | 43.9 | 7.93 | 17.36 | 208.3 | 333.3 | model | config |
| PP-YOLOE+_m | 80 | 8 | 8 | cspresnet-m | 640 | 49.8 | 50.0 | 23.43 | 49.91 | 123.4 | 208.3 | model | config |
| PP-YOLOE+_l | 80 | 8 | 8 | cspresnet-l | 640 | 52.9 | 53.3 | 52.20 | 110.07 | 78.1 | 149.2 | model | config |
| PP-YOLOE+_x | 80 | 8 | 8 | cspresnet-x | 640 | 54.7 | 54.9 | 98.42 | 206.59 | 45.0 | 95.2 | model | config |
使用PP-YOLOE+_l进行训练时,使用的GPU个数为8,每GPU图片个数为8,那么batchsize就是64( 8 x 8 = 64 8x8=64 8x8=64),假设此时的学习率为0.001,而你想用单卡来跑这个模型,此时你的实际batchsize为8( 1 x 8 = 8 1x8=8 1x8=8),为了保持一致,学习率应该除以8,即0.000125( 0.001 / 8 = 0.000125 0.001/8=0.000125 0.001/8=0.000125)。

不同模型的默认配置不一样,具体请查看模型的文档。
模型训练
配置好基本参数以后,就可以用一行代码开启训练。
%cd ~
%cd PaddleDetection
!python tools/train.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco.yml --eval
训练结束后,其模型会保存在PaddleDetection/output/ppyoloe_plus_crn_l_80e_coco文件夹下。
导出模型
将训练好的模型导出。
%cd ~
%cd PaddleDetection
# 将"-o weights"里的模型路径换成你自己训好的模型
!python tools/export_model.py -c configs/ppyoloe/ppyoloe_plus_crn_l_80e_coco.yml \
-o weights=output/ppyoloe_plus_crn_l_80e_coco/best_model.pdparams \
TestReader.fuse_normalize=true
2.分割任务
下面,我们将基于数据集中的“工业仪表数据集”训练一个语义检测模型。
环境安装:PaddleSeg
PaddleSeg是基于飞桨PaddlePaddle的端到端图像分割套件,内置45+模型算法及140+预训练模型,支持配置化驱动和API调用开发方式,打通数据标注、模型开发、训练、压缩、部署的全流程,提供语义分割、交互式分割、Matting、全景分割四大分割能力,助力算法在医疗、工业、遥感、娱乐等场景落地应用。
# 克隆PaddleSeg仓库
# 如果已经克隆,则不需要重复运行,可把第4行直接注释,从第7行开始运行
%cd ~
# !git clone https://github.com/PaddlePaddle/PaddleSeg
# 更新pip版本
!pip install --upgrade pip
# 安装其他依赖
%cd PaddleSeg
!pip install -r requirements.txt --user
# 编译安装paddleseg
!pip install -v -e .
%cd ~
配置数据集
在/home/aistudio/PaddleSeg/configs/_base_文件夹下,新建一个配置文件dog.yml:

配置时,可以以`PaddleSeg/configs/_base_/cityscapes.yml`为参考进行配置。
### 配置超参数
再在这里,我们使用使用PaddleSeg轻量级语义分割模型bisenet模型进行训练。
在`PaddleSeg/configs/bisenet`文件夹下新建一个配置文件`new_bisenet_480x480.yml`,并设置数据集路径等参数:
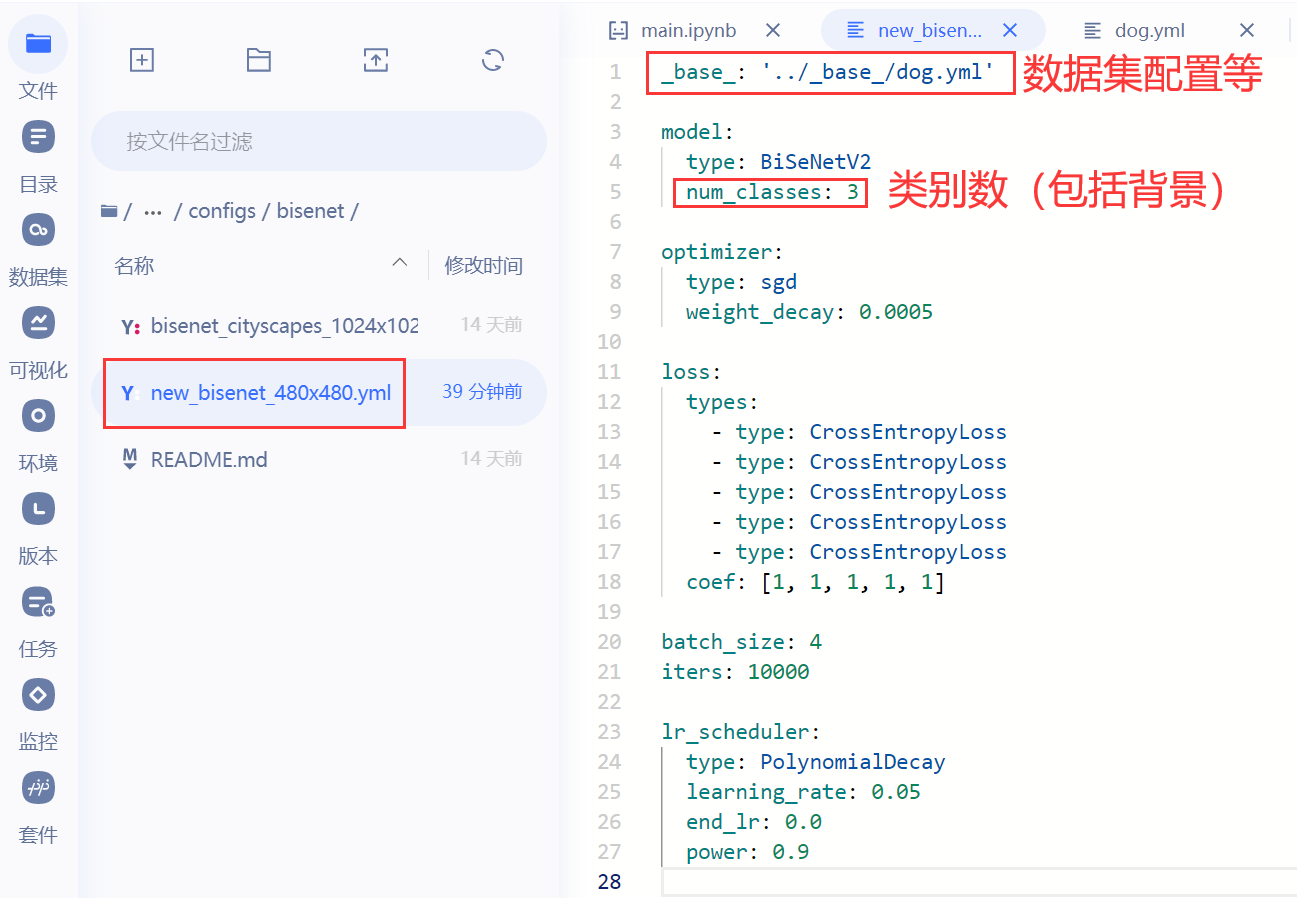
### 模型训练
配置好基本参数以后,就可以开始训练了。
```python
%cd ~
%cd PaddleSeg
!python train.py --config configs/bisenet/new_bisenet_480x480.yml \
--do_eval \
--save_interval 400
训练结束后,其模型会保存在PaddleSeg/output文件夹下。
导出模型
将训练好的模型导出。
%cd ~
%cd PaddleSeg
!python export.py --config configs/bisenet/new_bisenet_480x480.yml \
--model_path output/best_model/model.pdparams
四、代码提交:检验飞桨小汪的学习成果
为了检验飞桨小汪的学习成果,我们在AI Studio上提供了一套测评系统,选手可以将训练好的模型和预测代码打包上传,测评系统会自动算分。
1.格式要求
参赛选手需要提交一个命名为submission.zip的压缩包,并且压缩包内应包含:
| -- model # 存放模型,并且大小不超过400M(检测+分割)
| | -- xxx.pdmodel
| | -- xxx.pdiparams
| | …
| -- env # 存放依赖库,如PaddleDetection、PaddleSeg
| | --
| |…
| -- det_predict.py # 专用于目标检测任务的评估代码
| -- seg_predict.py # 专用于目标检测任务的评估代码
| -- …
注意:
model文件夹的名称以及det_predict.py、'seg_predict.py`的文件命名应保持一致
参赛选手在代码提交页面提交压缩包后,测评系统会解压你提交的压缩包,并执行如下命令:
python det_predict.py det_data.txt det_result.json
python seg_predict.py seg_data.txt seg_result.json
其中,det_predict.py用来执行目标检测任务,并将检测结果保存至det_result.json;相应地,seg_predict.py用来执行语义分割任务,并将分割结果保存至seg_result.json。执行完毕后,测评系统会分别计算目标检测任务和语义分割任务的得分,并按 9 : 1 9:1 9:1的比例计算最终得分。
2.评分规则
具体地,模型预测速度在v100显卡需达到20 FPS及以上(预测时间包括前处理和后处理用时),视为有效,在满足速度基础上,按照精度高低进行排名。
对于目标检测任务,我们采用平均F1-score来评估结果,针对每一个类别F1-score 计算公式如下:
Accuracy = T P + T N T P + T N + F P + F N Precision = T P T P + F P Recall = T P T P + F N F1-score = 2 × Precision × Recall Precision + Recall \begin{aligned} & \text { Accuracy }=\frac{T P+T N}{T P+T N+F P+F N} \\ & \text { Precision }=\frac{T P}{T P+F P} \\ & \text { Recall }=\frac{T P}{T P+F N} \\ & \text { F1-score }=\frac{2 \times \text { Precision } \times \text { Recall }}{\text { Precision }+ \text { Recall }} \end{aligned} Accuracy =TP+TN+FP+FNTP+TN Precision =TP+FPTP Recall =TP+FNTP F1-score = Precision + Recall 2× Precision × Recall
对于语义分割任务,我们采用平均交并比MIoU来评估结果,记真实值为 i i i,预测为 j j j的像素数量为 p i j p_{ij} pij,则MIoU的具体计算公式为:
M I o U = 1 K + 1 ∑ i = 0 k p i i ∑ j = 0 k p i j + ∑ j = 0 k p j i − p i i MIoU=\frac{1}{K+1} \sum_{i=0}^k \frac{p_{i i}}{\sum_{j=0}^k p_{i j}+\sum_{j=0}^k p_{j i}-p_{i i}} MIoU=K+11i=0∑k∑j=0kpij+∑j=0kpji−piipii
最终得分:
S c o r e = ( F1-score × 0.9 + MIoU-score × 0.1 ) × 100 Score=(\text { F1-score } \times {0.9} + \text { MIoU-score } \times {0.1}) \times 100 Score=( F1-score ×0.9+ MIoU-score ×0.1)×100
3.整理提交代码
本次线上赛的测评逻辑是分别计算目标检测任务和语义分割任务的得分,并根据测试集的数据量按 9 : 1 9:1 9:1的比例计算最终得分。所以,跟以往的比赛不不同,参赛选手需要在submission.zip中为目标检测任务和语义分割任务分别准备一个执行预测用的predict.py。
在本基线系统中,已经整理好了一个submission.zip,该提交代码还有很大的提升空间,仅供各位参赛选手参考。
# 请解压后再测试运行
%cd /home/aistudio/submission
!python det_predict.py det_data.txt det_result.json
!python seg_predict.py seg_data.txt seg_result.json
/home/aistudio/submission
detection cost: 5.238214492797852s
segmentation cost: 0.0018520355224609375s
5s
作者简介
郑博培,百度飞桨开发者技术专家,AI Studio精选项目审稿人,前任百度飞桨北京领航团团长、百度飞桨领航团技术面试官,多次参与各大竞赛基线系统的开发、多次担任课程讲师及助教。
我在AI Studio上获得至尊等级,点亮10个徽章,来互关呀!!!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/147378
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 3
3 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)