
体验文本到视频的趣味创作
随着大模型的不断迭代更新,现在的文本生成模型越来越强大,本项目中使用飞桨ppdiffusers库中的模型实现prompt文本输入生成趣味视频
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
1.项目简介
在过去的几年中,随着互联网行业的迅猛发展,在线视频已经成为了人们获取信息、娱乐休闲、传达思想的重要手段。而在线视频的制作也逐渐从传统的高门槛、高成本的专业制作转变为普通用户可以轻松完成的自媒体时代。然而,对于许多没有专业制作经验的人来说,制作一部优秀的视频仍然相当困难,需要耗费大量的时间和精力。
尤其近期chatgpt的火爆,从最初的GPT3.0到GPT.3.5到GPT4.0发展迅速,从单一的对话到4.0时代的多模态,AI模型不断地在迭代升级🚀,AIGC已经迎来新的发展😸。我找到一个比较有趣的模型text-to-video,使用文本prompt提示生成视频video,本项目使用这个最新的人工智能技术构建一个文本到视频自动创作系统,可以根据用户提供的文本描述信息,自动生成符合用户需求的视频内容。
下面是是一些AI video的有趣例子
prompt1:一只穿着红色斗篷超级英雄服装的狗,在天空中飞翔

prompt2:猫手里拿着遥控器看电视

2.技术原理
text-to-video是一种神经网络模型,用于将文本描述内容转换为视频内容。其主要原理是将文本输入放入一个文本特征提取器中,该提取器可以将文本转换为高维向量。然后使用这些向量作为输入,训练一个生成器,使其能够生成相应的视频输出。该模型包含三个子网络:文本特征提取、文本特征向视频潜空间扩散模型和视频潜空间到视频视觉空间。整个模型参数约有17亿,目前仅仅支持英文输入。扩散模型采用了Unet3D结构,在纯高斯噪声视频的迭代去噪过程中实现视频生成功能。
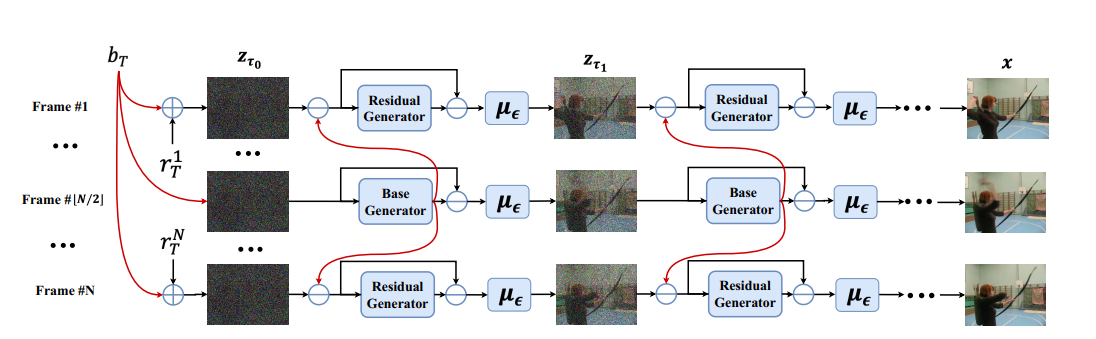
模型中采用了分解扩散过程,将每帧的噪声分解为基础噪声和残差噪声。基础噪声在所有帧中共享,而残差噪声沿时间轴变化。模型通过两个联合学习的网络来匹配噪声分解。该模型在生成高质量视频方面超越了以前的基于GAN和扩散的替代品。模型通过预训练的图像扩散模型,并支持文本条件下的视频创建。
3.示例实现
3.1 安装依赖库
这里需要安装一些模型所需要的依赖库,为了避免之后的重复安装,可以将依赖安装到external-libraries文件夹上并将其添加到sys.path中,这样重新启动就只用添加环境变量到sys.path就可以使用库,目前我还是使用直接pip,持久化安装出现了一些环境问题,所需要安装的依赖库已经写到了requirements.txt,有能力解决环境问题的可以自己分析解决持久化安装的问题
# 直接pip安装
!pip install --upgrade ppdiffusers
# 持久化安装
!pip install -U -r requirements.txt -t /home/aistudio/external-libraries
# 添加外部依赖库到系统变量中
import sys
sys.path.insert(1,'/home/aistudio/external-libraries')
3.2 加载模型
目前这个模型已经更新到PaddleNLP下的ppdiffusers中,可使用飞桨直接预加载模型,也可以通过飞桨加载后保存到服务器本地路径进行本地加载(下文有介绍),加载使用TextToVideoSDPipeline推理器,请注意增加num_frames会使得视频质量下降,需要同时增加num_inference_steps,但这会使得推理时间增加,使用模型推理时可选的一些参数如下:
-
prompt:(可选,str或List [str])-用于指导视频生成的提示。如果未定义,则必须传递prompt_embeds。 -
height:(可选,int,默认为self.unet.config.sample_size * self.vae_scale_factor)-生成视频的高度(以像素为单位)。 -
width:(可选,int,默认为self.unet.config.sample_size * self.vae_scale_factor)-生成视频的宽度(以像素为单位)。 -
num_frames:(可选,int,默认为16)-生成的视频帧数。默认为16帧,以每秒8帧的速度计算,相当于2秒的视频。 -
num_inference_steps:(可选,int,默认为50)-去噪步骤的数量。通常更多的去噪步骤会导致更高质量的视频,但代价是推理速度变慢。 -
guidance_scale:(可选,float,默认为7.5)-分类器自由扩散引导中定义的指导权值。guidance_scale定义为Imgen Paper中方程式2中的w。 如果设置guidance_scale> 1,则启用指导规模。较高的指导规模鼓励生成与文本提示密切相关的视频,通常以降低视频质量为代价。 -
negative_prompt:(可选,str或List [str])-不指导视频生成的提示。如果未定义,则必须传递negative_prompt_embeds。当不使用指导时将被忽略(即,如果guidance_scale小于1,则忽略)。 -
eta:(可选,float,默认为0.0)- 对应于DDIM论文中的参数eta(η),学习步长类似学习率 -
output_type:(可选,str,默认为“np”)-生成视频的输出格式。在paddle.float或np.array之间选择。 -
return_dict:(可选,bool,默认为True)-是否返回~pipelines.stable_diffusion.TextToVideoSDPipelineOutput而不是普通的元组。 -
cross_attention_kwargs:(可选,dict)-如果指定,则传递给diffusers.cross_attention中self.processor下定义的AttentionProcessor的kwargs字典。
import paddle
from ppdiffusers import TextToVideoSDPipeline
from ppdiffusers.utils import export_to_video
# 加载pipeline,可以通过设置cache_dir将模型放到自己想要放的路径
pipe = TextToVideoSDPipeline.from_pretrained("damo-vilab/text-to-video-ms-1.7b",cache_dir="/home/aistudio/cache")
# 查看存储模型的文件路径,不设置cache_dir的预训练模型默认放在这个位置
!ls ~/.cache/paddlenlp/ppdiffusers
damo-vilab
# 将模型文件移动到work路径下保存
!ls ~/.cache/paddlenlp/ppdiffusers/damo-vilab/text-to-video-ms-1.7b
!mv ~/.cache/paddlenlp/ppdiffusers/damo-vilab/text-to-video-ms-1.7b* /home/aistudio/work/models
model_index.json scheduler text_encoder tokenizer unet vae
# 使用本地化路径加载pipeline
import paddle
from ppdiffusers import TextToVideoSDPipeline
from ppdiffusers.utils import export_to_video
pipe = TextToVideoSDPipeline.from_pretrained("/home/aistudio/work/models")
3.3 降噪处理
对输入进行降噪声处理,pipe.scheduler可选的调度器参考,由于这个TextToVideoSDPipeline类是继承DiffusionPipeline也可以使用该类支持的调度器,只需要使用from ppdiffusers import导入就可以
-
DDIMScheduler:使用 DDIM (Deep Diffeomorphic Image Matching) 方法进行降噪。 -
LMSDiscreteScheduler:使用 LMS-Discrete (Local Mean-Subtraction with Discrete Cosine Transform) 方法进行降噪。 -
PNDMScheduler:使用 PNDM (Patch-based Non-Local Despeckling Model) 方法进行降噪。 -
ConstantScheduler: 将所有时间步的耦合大小设为常数。 -
InverseScheduler: 将所有时间步的耦合大小设置为一个初始值除以时间步数加一。 -
LinearScheduler: 将所有时间步的耦合大小设置为一个线性函数。 -
DPMSolverScheduler: 使用 DPM-Solver 算法自适应计算每个时间步的耦合大小。 -
DPMSolverMultistepScheduler: 使用 DPM-Solver++ 算法计算多步耦合大小。
from ppdiffusers import DPMSolverMultistepScheduler
# 这个语句是用来输入降噪
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
3.4 句子翻译
目前的text-to-video模型只支持英文输入,如果需要中文prompt转英文prompt的可以使用paddlehub提供的预训练翻译模型,也可以使用百度翻译直接翻译😂,英语好的小伙伴可以直接写英文prompt,这里我希望能够多输入进行翻译,因此使用paddlehub的transformer_zh-en模型进行推理实现中英转换(使用模型翻译不一定百分百准确),另外构建prompt尽可能要把每个部分特征分开,不要一个部分写太长,目前模型对冗长的语句的生成效果不太精准
# hub安装翻译模型
!hub install transformer_zh-en==1.1.0
import paddlehub as hub
model = hub.Module(name='transformer_zh-en', beam_size=5)
# 输入中文进行英文翻译的函数,返回翻译后句子列表
def trans_zh(model):
src_texts = []
while True:
src_text=input("请输入你要构造视频的中文prompt(输入q结束):")
if src_text == 'q' or src_text == 'Q':
break
src_texts.append(src_text)
trg_texts = model.predict(src_texts)
for i in range(len(trg_texts)):
print("{} 英文翻译后句子为: {}".format(src_texts[i],trg_texts[i]))
return trg_texts
# 翻译后的句子是个列表,可以使用for语句或者数组下标获取句子
trans_prompt=trans_zh(model)
# 文本提示
prompt = "ironman is dancing"
# 视频片段num_frames=64
video_frames = pipe(prompt, num_inference_steps=50).frames
# 视频保存路径,这里放到在mp4文件夹下
video_path = export_to_video(video_frames,output_video_path='/home/aistudio/mp4/test.mp4')
0%| | 0/50 [00:00<?, ?it/s]
# 另外一个prompt
prompt1="A cat wearing sunglasses is eating pizza"
video_frames1 = pipe(prompt1, num_inference_steps=50,).frames
video_path1 = export_to_video(video_frames1,output_video_path='/home/aistudio/mp4/test1.mp4')
0%| | 0/50 [00:00<?, ?it/s]
3.5 视频输出问题
由于notebook中不能直接显示mp4格式的文件,所以需要用一些其它方法才能让结果展现出来,视频文件本质是由一帧一帧的图片连续构成,我们只需要提取帧并连续切换就可实现视频效果。这里提供两种思路:
1.将视频转换为图片帧frames之后遍历加载,可自由调整视频帧率
2.目前生成的视频较短可将其转化为gif再显示
from IPython.display import clear_output, display, HTML
import PIL.Image
import matplotlib.pyplot as plt
import time
import cv2
import os
# 显示视频的函数
def display_mp4(video_path:str,small:int=2):
if not os.path.exists(video_path):
print("视频文件不存在")
video = cv2.VideoCapture(video_path)
current_time = 0
while(True):
try:
clear_output(wait=True)
ret, frame = video.read()
if not ret:
break
lines, columns, _ = frame.shape
if current_time == 0:
current_time = time.time()
else:
last_time = current_time
current_time = time.time()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, (int(columns / small), int(lines / small)))
img = PIL.Image.fromarray(frame)
display(img)
# 控制帧率
time.sleep(0.1)
except KeyboardInterrupt:
video.release()
from moviepy.editor import VideoFileClip
from IPython.display import Image
import os
# 输入视频路径和输出文件夹,测试好的gif放在gif文件夹中
def output_gif(video_path:str,output:str,name:str):
path=os.path.join(output,name)+'.gif'
clip = (VideoFileClip(video_path).resize(1))
clip.write_gif(path)
return Image(filename=path)
3.6 结果展示
# 显示gif1
output_gif(video_path, output='/home/aistudio/gif/', name='test')
<IPython.core.display.Image object>
# 显示视频1
display_mp4(video_path)
# 显示gif2
output_pdf(video_path1, output='/home/aistudio/gif/', name='test1')
MoviePy - Building file /home/aistudio/gif/test1.gif with imageio.
<IPython.core.display.Image object>
# 显示视频2
display_mp4(video_path1)
4.项目总结
目前模型还不支持中文😅,只能使用English prompt进行输入生成,后面可以考虑使用ERNIE模型将中文文本输入翻译成英文再进行测试(飞桨中可以快速调用这个模型),这个模型目前还是有一些缺陷的,且生成长的视频还比较困难(可生成长一点的但是目前环境比较难处理),能否用gradio来部署web端部署也还在分析(模型比较大),不过这个模型还是比较有趣的,也欢迎各位来体验一下😎,如果喜欢的话可以多多点赞哦💕
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)