
第18届全国大学生智能车智慧交通组解决方案: Transformer来袭
第18届全国大学生智能车强悍baseline
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
项目更新
2023-04-20修复了最新版本中work文件夹下data.txt缺失的问题
2023-04-15 修复了predict文件中的bug,使得FPS能够上30,并且更新如何对input shape进行修改的教程。修复了导出模型的bug。
一、第十八届智能车智慧交通组比赛背景;比赛链接
车辆的普及和人们对出行体验的重视,对地图导航提出了更高的要求。基于车载影像的AR导航系统能够精准快速的识别道路情况,不仅能够辅助驾驶系统进行高效的决策,同时结合终端渲染与语音技术,也能够为用户带来更为智能精准的导航体验。
作为『新一代人工智能地图』的百度地图,秉承着『用科技让出行更简单』的使命,借助于图像识别、语音识别、大数据处理等人工智能技术,大幅提升地图数据采集和处理的自动化程度,实现道路覆盖超过1000万公里,已成为业内AI化水平最高、搭载的AI技术最强最丰富的地图数据厂商。
全国大学生智能汽车竞赛是以智能汽车为研究对象的创意性科技竞赛,是面向全国大学生的一种具有探索性工程的实践活动,是教育部倡导的大学生A类科技竞赛之一。竞赛以立足培养,重在参与,鼓励探索,追求卓越为指导思想,培养大学生的创意性科技竞赛能力。
在百度智慧交通赛项中,百度飞桨场景化地设计了基于深度学习的智能车趣味赛题,要求同学们在一套故事线中,使用飞桨完成特定场景的自动驾驶任务及系列自动化操作,赛题旨在在为创新人才的培养提供综合演练平台,拓宽高校人工智能相关专业的教学内容,提升高校科技创新能力。
二、RTFormer介绍
Vision Transformer(ViT)作为近两年兴起并火遍视觉圈的模型,凭借其出色的性能而被广大研究者以及开发人员所使用。但是ViT也存在缺点,最直接的就是推理速度很慢。因此百度在NIPS2022上提出用于实时语义分割的Transformer模型RTFormer。笔者在另一个项目中曾介绍过RTFormer。RTFormer:Transformer实时语义分割来了
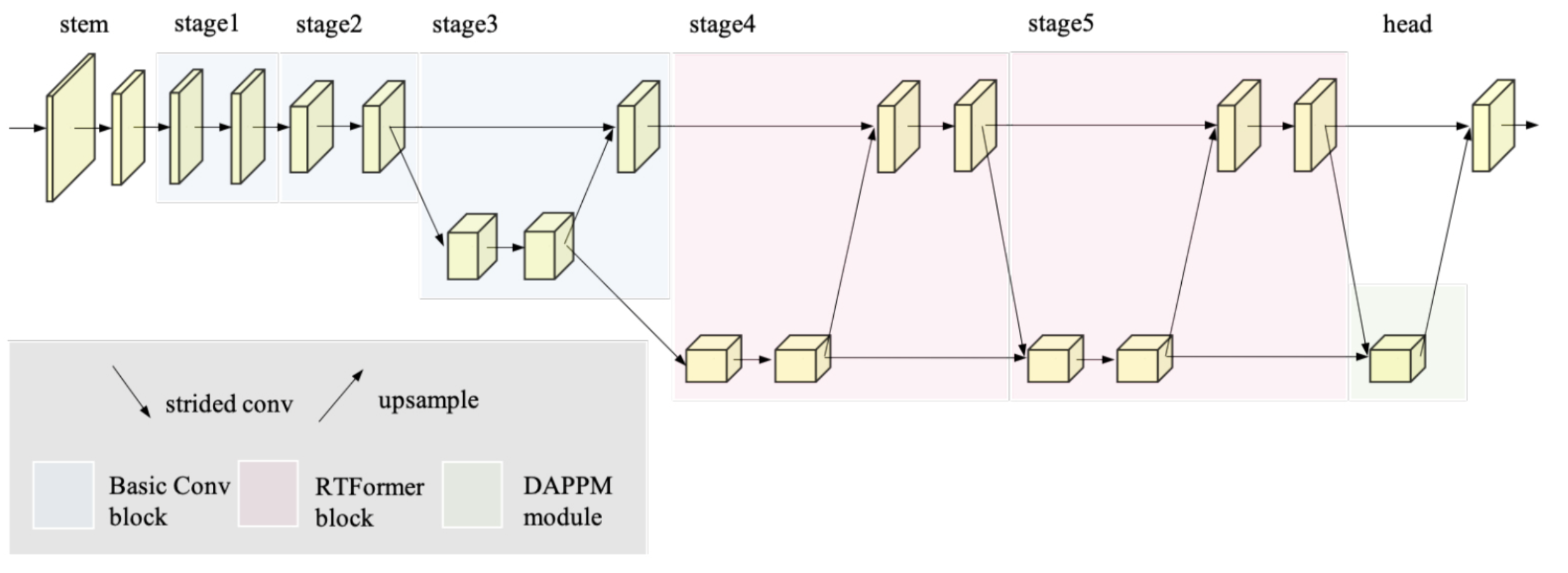
这里也向大家简单介绍一下RTFormer,具体的可以到上面链接里面阅读。下面展示的是RTFormer总体的一个结构图。
可以看出RTFormer采用类似HRNet的结构,但是其推理速度却远超HRNet,下面来看其中具体的block。
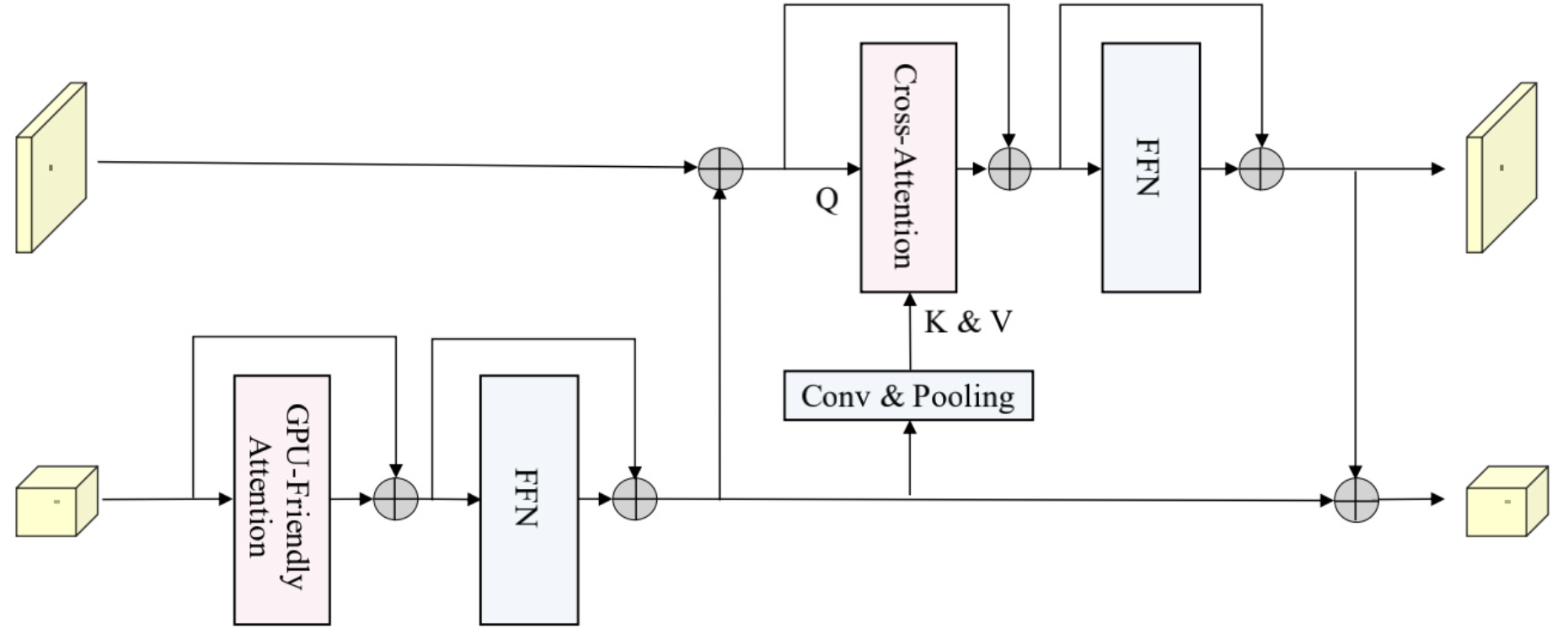
从图中,我们可以看到block主要有两个分支,两个分支的特征会在RTFormer提出的注意力加持下进行特征提取,并互相融合,下图是RTFormer注意力的具体结构。

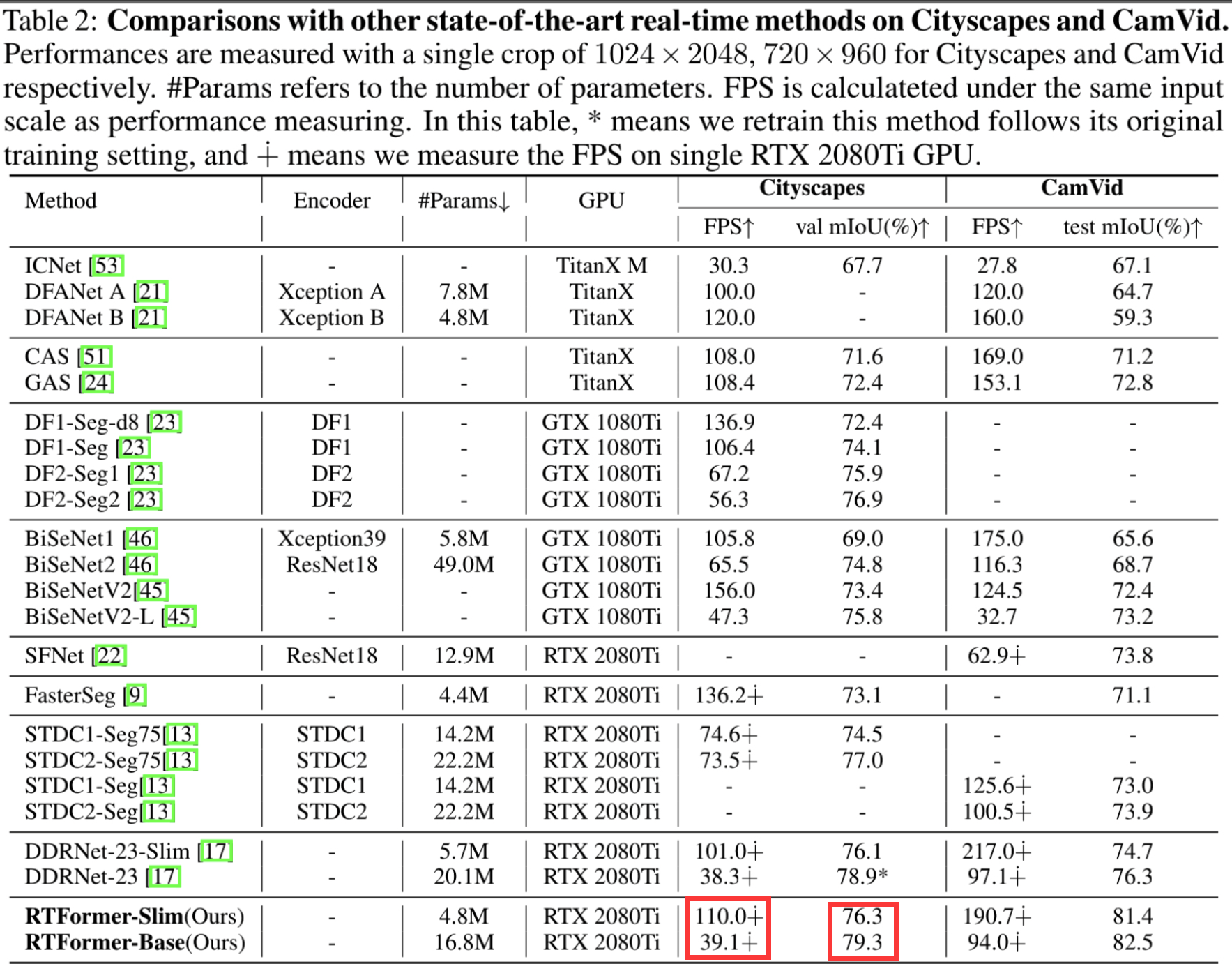
看完结构,我们来看看性能。从下图中可以看出,在实时检测模型中RTFormer实现了SOTA。这么强悍的性能,加上速度也很快,怎么能让人不使用。
三、线上赛基本流程以及RTFormer使用
相信大家更关心的是如何来使用RTFormer,别急。我们接下来一步步地来拆解这个比赛,让大家知道每个部分地作用。先安装一下Paddleseg
#安装Paddleseg
%cd PaddleSeg
!pip install -r requirements.txt
!python setup.py build develop
3.1 数据集分析
首先是数据集分析,很多新手上来就直接拿着模型就跑,这里我想问大家几个问题,如果能够基本回答上来,说明你是一个合格的炼丹师: (1)数据集有哪些类别。(2)数据集有哪些场景(白天、夜晚等)。(3)数据集提供的标签是什么格式的。(4)数据集是否有人为标注错误的地方。(5)数据集类别特征分布如何(颜色,大小,位置等)。
如果你还不能回答以上的几个问题,说明你还需要更多地了解数据集。深度学习说到底是数据驱动,因此开始炼丹之前我们需要对数据集进行分析,我这里着重针对问题(4)和问题(5)来对数据集进行优化。
首先,通过官网的信息,我们知道了数据集一共有4类。这里我们首先利用Paddleseg里面提供的方法将标签进行一下可视化。有同学会有疑问:为何我看标签都是黑的,啥也没有?这是因为每个像素代表其类别,也就是像素值只有0,1,2,3,我们知道0-255越小像素越黑,因此图片看上去都是黑色。
#先解压数据集
!unzip -d /home/aistudio/data/ /home/aistudio/data/data125507/car_data_2022.zip
from paddleseg.utils import visualize
from PIL import Image
import numpy as np
import cv2
from matplotlib import pyplot as plt
#读取图片
image = cv2.imread('/home/aistudio/data/car_data_2022/JPEGImages/00091.jpg') # 读取标签
image_path = '/home/aistudio/data/car_data_2022/JPEGImages/00091.jpg'
label = np.array(Image.open('/home/aistudio/data/car_data_2022/Annotations/00091.png')) # 读取标签
label[label==0] = 255 #不用可视化背景类
color_map = visualize.get_color_map_list(256, custom_color=None) #定义一下类别颜色
visualize.visualize(image_path,label,color_map,save_dir='/home/aistudio/data') #保存可视化结果的路径
color_label = cv2.imread("/home/aistudio/data/00091.jpg") #读取可视化结果图片
vis_image = np.concatenate([image,color_label],axis=1) # 将原图和可视化结果图拼接一下
plt.imshow(vis_image) #这里可视化比较粗糙,可以到 /home/aistudio/data文件夹下看可视化效果
<matplotlib.image.AxesImage at 0x7f25402829d0>

从上面图中可以看出,车道线、斑马线的位置均位于图像的下方。因此,图像上方的像素在训练过程中是背景类别,也就是说图像上方的像素其实不影响车道线这些类别的训练,我们在训练过程中将上面部分图片截掉,这样可以减少背景像素的数量。具体的代码如下,这部分代码已经加在PaddleSeg里面了。
class Compose:
"""
Do transformation on input data with corresponding pre-processing and augmentation operations.
The shape of input data to all operations is [height, width, channels].
Args:
transforms (list): A list contains data pre-processing or augmentation. Empty list means only reading images, no transformation.
to_rgb (bool, optional): If converting image to RGB color space. Default: True.
img_channels (int, optional): The image channels used to check the loaded image. Default: 3.
Raises:
TypeError: When 'transforms' is not a list.
ValueError: when the length of 'transforms' is less than 1.
"""
def __init__(self, transforms, to_rgb=True, img_channels=3):
if not isinstance(transforms, list):
raise TypeError('The transforms must be a list!')
self.transforms = transforms
self.to_rgb = to_rgb
self.img_channels = img_channels
self.read_flag = cv2.IMREAD_GRAYSCALE if img_channels == 1 else cv2.IMREAD_COLOR
def __call__(self, data):
"""
Args:
data: A dict to deal with. It may include keys: 'img', 'label', 'trans_info' and 'gt_fields'.
'trans_info' reserve the image shape informating. And the 'gt_fields' save the key need to transforms
together with 'img'
Returns: A dict after process。
"""
if 'img' not in data.keys():
raise ValueError("`data` must include `img` key.")
if isinstance(data['img'], str):
data['img'] = cv2.imread(data['img'],
self.read_flag).astype('float32')
if data['img'] is None:
raise ValueError('Can\'t read The image file {}!'.format(data[
'img']))
if not isinstance(data['img'], np.ndarray):
raise TypeError("Image type is not numpy.")
img_channels = 1 if data['img'].ndim == 2 else data['img'].shape[2]
if img_channels != self.img_channels:
raise ValueError(
'The img_channels ({}) is not equal to the channel of loaded image ({})'.
format(self.img_channels, img_channels))
if self.to_rgb and img_channels == 3:
data['img'] = cv2.cvtColor(data['img'], cv2.COLOR_BGR2RGB)
if 'label' in data.keys() and isinstance(data['label'], str):
data['label'] = np.array(Image.open(data['label']))
# the `trans_info` will save the process of image shape, and will be used in evaluation and prediction.
if 'trans_info' not in data.keys():
data['trans_info'] = []
#================下面就是截图部分的代码==============
data['img'] = data['img'][75:,:,:]
data['label'] = data['label'][75:,:]
#==================================================
for op in self.transforms:
data = op(data)
if data['img'].ndim == 2:
data['img'] = data['img'][..., np.newaxis]
data['img'] = np.transpose(data['img'], (2, 0, 1))
return data
这样问题(5)的一个方面我们就进行了优化,其他的大家可以按照这个思路进行优化。下面我们就针对问题(4)看一看数据集是否有错标注或者误标注图片呢。
#首先获取总的图片数量
#运行下面的代码需要先运行上面的代码
import os
image_list = os.listdir("/home/aistudio/data/car_data_2022/JPEGImages")
print("total image:",len(image_list))
root = '/home/aistudio/data/car_data_2022/Annotations'
label_list = os.listdir(root)
valid_label = []
for image_name in image_list:
if image_name.endswith('.jpg'):
label_name = image_name.strip('.jpg') + '.png'
label = np.array(Image.open(os.path.join(root,label_name)))
forg = (label!=0) #获取前景像素
coord = np.where(forg)
if len(coord[0]) == 0: #如果没有前景像素就跳过
continue
valid_label.append(label_name)
print("valid label num is :",len(valid_label))
total image: 16000
valid label num is : 14027
7
从上面可以看出有1千多张图片是全背景图片,因此可以删除。但是具体有哪些图片这里留给同学们思考一下,其实答案已经出来了。
3.2 模型选择
上面就是我对数据集一个简单的优化,当然这里还有数据增强部分没有说,我们决定把数据增强放到模型部分来讲述。对于模型,我相信很多同学只关注了miou指标,所以选择了DeepLabV3、OCRNet等网络,但是这些网络都太大了,FPS很低。因此,这里建议同学们选择实时推理的网络。这里给出几个推荐的模型: BiSeNetV2、ERFNet、PPLiteSeg(很推荐)、PP-MobileSeg(很推荐)、DDRNet、fastscnn、以及我们项目中的RTFormer。
在开始之前,我们先简单带大家过一下PaddleSeg。PaddleSeg中集成了很多优秀的分割算法,PaddleSeg中大家主要关注两个文件夹:PaddleSeg/paddleseg/models 和 config文件夹。config中定义的关于模型的内容在PaddleSeg/paddleseg/models均可找到。相关文件的含义见文件名即可
下面给大家看一下配置文件各部分内容主要含义。这里以PPLiteSeg为例,具体的内容见下面的代码块。
#这个单元格不要运行
batch_size: 4 #设定batch_size的值即为迭代一次送入网络的图片数量,一般显卡显存越大,batch_size的值可以越大。如果使用多卡训练,总得batch size等于该batch size乘以卡数。
iters: 1000 #模型训练迭代的轮数
train_dataset: #训练数据设置
type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。
dataset_root: data/optic_disc_seg #数据集路径
train_path: data/optic_disc_seg/train_list.txt #数据集中用于训练的标识文件
num_classes: 2 #指定类别个数(背景也算为一类)
mode: train #表示用于训练
transforms: #模型训练的数据预处理方式。
- type: ResizeStepScaling #将原始图像和标注图像随机缩放为0.5~2.0倍
min_scale_factor: 0.5
max_scale_factor: 2.0
scale_step_size: 0.25
- type: RandomPaddingCrop #从原始图像和标注图像中随机裁剪512x512大小
crop_size: [512, 512]
- type: RandomHorizontalFlip #对原始图像和标注图像随机进行水平反转
- type: RandomDistort #对原始图像进行亮度、对比度、饱和度随机变动,标注图像不变
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize #对原始图像进行归一化,标注图像保持不变
val_dataset: #验证数据设置
type: Dataset #指定加载数据集的类。数据集类的代码在`PaddleSeg/paddleseg/datasets`目录下。
dataset_root: data/optic_disc_seg #数据集路径
val_path: data/optic_disc_seg/val_list.txt #数据集中用于验证的标识文件
num_classes: 2 #指定类别个数(背景也算为一类)
mode: val #表示用于验证
transforms: #模型验证的数据预处理的方式
- type: Normalize #对原始图像进行归一化,标注图像保持不变
optimizer: #设定优化器的类型
type: sgd #采用SGD(Stochastic Gradient Descent)随机梯度下降方法为优化器
momentum: 0.9 #设置SGD的动量
weight_decay: 4.0e-5 #权值衰减,使用的目的是防止过拟合
lr_scheduler: # 学习率的相关设置
type: PolynomialDecay # 一种学习率类型。共支持12种策略
learning_rate: 0.01 # 初始学习率
power: 0.9
end_lr: 0
loss: #设定损失函数的类型
types:
- type: CrossEntropyLoss #CE损失
coef: [1, 1, 1] # PP-LiteSeg有一个主loss和两个辅助loss,coef表示权重,所以 total_loss = coef_1 * loss_1 + .... + coef_n * loss_n
model: #模型说明
type: PPLiteSeg #设定模型类别
backbone: # 设定模型的backbone,包括名字和预训练权重
type: STDC2
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet2.tar.gz
好,介绍完配置文件,我们来看一下我们这一次关于RTFormer配置文件。配置文件放在/home/aistudio/PaddleSeg/configs/rtformer_car.yml
batch_size: 32 #定义batch size
iters: 80000 #总的迭代次数
train_dataset:
type: Dataset
dataset_root: /root/paddlejob/workspace/train_data/datasets/car_data_2022
train_path: /root/paddlejob/workspace/train_data/datasets/car_data_2022/train_list.txt
num_classes: 4
transforms: #数据增强部分
- type: RandomHorizontalFlip
- type: RandomBlur
- type: RandomRotation
- type: Resize
target_size: [432, 432]
interp: 'LINEAR'
- type: RandomDistort
brightness_range: 0.4
contrast_range: 0.4
saturation_range: 0.4
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
- type: RandomErasings
prob: 0.5
scale: [0.02, 0.4]
ratio: [0.3, 3.3]
value: 'random'
inplace: False
mode: train
val_dataset:
type: Dataset
dataset_root: /root/paddlejob/workspace/train_data/datasets/car_data_2022
val_path: /root/paddlejob/workspace/train_data/datasets/car_data_2022/val_list.txt
num_classes: 4
transforms:
- type: Resize
target_size: [432, 432]
interp: 'LINEAR'
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
mode: val
export: #导出设置
transforms:
- type: Resize
target_size: [432, 432]
interp: 'LINEAR'
- type: Normalize
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
optimizer: #优化配置
type: AdamW
beta1: 0.9
beta2: 0.999
weight_decay: 0.05
lr_scheduler:
type: PolynomialDecay
learning_rate: 2.5e-5
power: 1.
end_lr: 1.0e-7
warmup_iters: 1500
warmup_start_lr: 1.0e-7
#损失函数定义
loss:
types:
- type: MixedLoss
losses:
- type: LaneCrossEntropyLoss
weights: [0.5, 1.0, 1.0, 1.0]
- type: LovaszSoftmaxLoss
coef: [1, 0.2]
- type: LaneCrossEntropyLoss
weights: [0.4, 1.0, 1.0, 1.0]
coef: [1, 0.4]
#模型配置
model:
type: RTFormer
base_channels: 64
head_channels: 128
use_injection: [True, False]
pretrained: https://paddleseg.bj.bcebos.com/dygraph/backbone/rtformer_base_backbone_imagenet_pretrained.zip
从配置文件中,可以看到我们用了更多的数据增强,包括RandomErase等,实验结果表明数据增强是可以明显提升模型性能的。这里有两种数据增强方式: 离线数据增强和在线数据增强。我们这里使用在线数据增强,也就是训练过程中对数据进行增强。离线数据增强是先对数据进行增强,然后作为新的数据集再进行训练。具体的数据增强该怎么选,这个也是需要大家试出来的,没有啥很好的技巧。
这里建议同学们不要上来就想着怎么怎么改模型,这些模型都是工程师们精心设计的,所以用于我们任务是完全足够的。对predict.py和数据优化远比模型优化收益高。
下面我们就开始训练模型,这里有几个可以提高成绩的建议: (1)损失函数可以精心选择一下。(2)相信大力出奇迹,让模型训练更多迭代次数。
#开启训练
#这里解释一下各个参数意义: --config 配置文件路径 --do_eval 边训练边验证 --save_interval 保存模型以及验证的迭代次数 --num_workers 线程数
!python tools/train.py --config configs/rtformer_car.yml --do_eval --use_ema --save_interval 1000 --num_workers 4
#导出模型
#注意将模型路径改成自己模型的路径
!python tools/export.py --config configs/rtformer_car.yml --model_path output_dir/model.pdparams --input_shape 1 3 432 432
4提交成绩
好了,基本的训练过程已经讲完了,下面我们就要提交成绩了。这里,我们提供一个data.txt让大家可以自行测试自己的predict.py是否跑通。具体文件在 /home/aistudio/work文件夹下。开始提交成绩前你需要作一下几个改动: (1)首先将/home/aistudio/PaddleSeg/paddleseg/transforms/transforms.py 里面的下面部分内容注释掉(第1227-1233行),因为这个部分只在Paddle2.4中才有效,对于评测系统Paddle2.2会报错。一定要注释掉,不然提交会报错!!(2)将PaddleSeg复制到work文件夹下。
@manager.TRANSFORMS.add_component
class RandomErasings(transforms.RandomErasing):
def __init__(self,cfg = None,**kwargs):
super().__init__(**kwargs)
def _apply_image(self, sample):
sample['img'] = super()._apply_image(sample['img'])
return sample
另外,如果大家测试的FPS小于30的,可以将下面函数中target size继续减小,直至FPS高于30,虽然会有miou损失,但是至少保证有成绩可以交。
#这个函数在predict.py中
def seg_transforms(im, target_size=432, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]):
"""自构的预处理 -- 只需要关注target_size即可
desc: 分割模型需要的预处理方法集合
Args:
im: numpy.ndarray, 输入图像数据
target_size: int|list|tuple, 缩放目标大小
mean: list, 每个通道的归一化均值数据
std: list, 每个通道的归一化方差数据
Return
im: numpy.ndarray, 预处理好的图像数据
"""
im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
im = resize(im, target_size=target_size)
im = normalize(im, mean=mean, std=std)
im = np.transpose(im, (2, 0, 1))
return im
%cd /home/aistudio/work
!python predict.py data.txt result.json
#需要注意,导出的模型需要移到work/model文件夹下,这里可能有人有疑问为何不在/home/aistudio下直接将PaddleSeg。
#work 下的PaddleSeg删掉一些不符合PaddlePaddle2.2的内容,这样可以保证程序可以跑通
!zip -r -q -o submission.zip PaddleSeg/ model/ train.py predict.py
这里给大家的predict.py的优化建议: 着重关注对predict中的FPS进行优化,优化办法有: 多进程、cython加速、C++重写。这里比较推荐第一个,后面两个需要有一定的编程基础和调试基础。
下面展示了RTFormer的提交结果,大家可以自由发挥。

从上图可以看出,速度还不是很快。但是速度优化后RTFormer是可以上40FPS的,这里有一个我优化的结果,前后对比发现速度有很大提升。这也启发同学们可以着重研发速度的优化策略

好啦!以上就是本项目全部内容,如果有疑问欢迎在评论区留言或者在QQ群联系我,预祝各位同学取得好成绩!如果你觉得本项目对你有帮助,可以点个喜欢!
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐


 0
0 0
0- 0



 已为社区贡献1438条内容
已为社区贡献1438条内容

所有评论(0)