
【大模型专区】Inpaint Anything——当SAM遇上图像修复
【大模型专区】Inpaint Anything——当SAM遇上图像修复
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、项目介绍
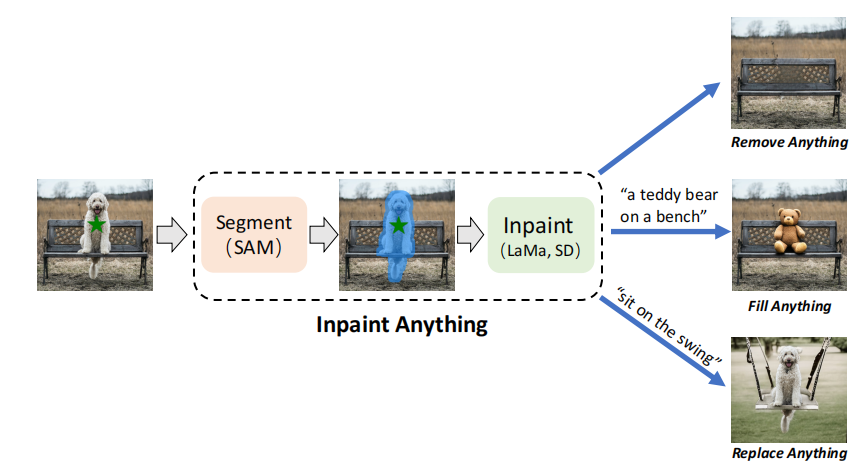
该项目的趣味点在于可以结合分割大模型 SAM 进行图像编辑(对象移除、替换背景、前景等),从而生成各种十分有趣的图像,相较于 stable diffusion 方式, 这种图像生成方式更加稳定可靠,且后续通过叠加人体姿态估计、视频渲染等技术可以实现AI视频生成,比如:实现 Wonder Studio 的AI 视频特效。

该项目是对 Inpaint Anything(pytorch) 官方项目的 paddle 实现, 采用分割大模型 Segment Anything(SAM)获得图像 mask,采用图像修复模型 LaMa 进行图像移除,并采用 stable_diffusion_inpaint 进行文本引导的图像编辑。用户可以通过图像中任意对象的点坐标,平滑地进行对象移除。此外,用户还可以通过文本提示,用任何内容填充对象,或任意替换对象的背景。同时,本人结合 PP-YOLOE 在COCO 数据集上的预训练模型,对图像级的 Remove Anything 进行扩展,实现了指定类别的视频目标移除(Remove Anything Video)。
该项目可以在 V100 16G 环境下运行,项目的主要工作是对 LaMa 模型的推理部分及依赖库 kornia 部分函数进行复现, 并通过调用 PaddleSeg 的 Segment Anything(SAM)模型 和 PaddleNLP 的 Stable Diffusion Inpaint模型, 完成 Inpaint Anything 相应功能的实现。对于视频目标移除部分,该项目首先采用PP-YOLOE 检测视频中的所有目标,之后,将每帧图像中用户需要移除对象的边界框依次送入到 SAM 模型中,获得每个移除对象的 mask,并将所有对象mask汇总为最终 mask,送入到 LaMa 模型中,进行对象移除。
该项目实现了 Inpaint Anything 中的 Remove Anything、Fill Anything 和 Replace Anything 三种图像编辑模式,并在 Remove Anything 基础上扩展出 Remove Anything Video 模式。 由于 paddle 的随机因子和 torch 不同,Fill Anything 和 Replace Anything 与官方项目的结果有所差异。
下面是 Inpaint Anything 的一些有趣例子:

二、详细说明
创意来源 :近期看到 Wonder Studio 的AI视频特效,被其合成的 CG 视频震撼到了,于是心血来潮,打算复刻一下低配版的 Wonder Studio 。根据官网网站,AI视频特效需要经过 Motion Capture(动作捕捉)、Character Pass(角色动作绑定)、Alpha Mask(Alpha遮罩)、Clean Plate(人物擦除)、Camera Track(相机跟踪)、Blender File(生成 Blender 文件)和 Final Render(视频渲染)七个部分。其中,动作捕捉部分可以采用 paddle 中的人体姿态估计方案,角色动作绑定、相机跟踪部分可以采用 Unity 或 UE4 图形学引擎解决, Blender 文件生成和视频渲染可以采用相关3d建模软件解决,但是一直没有找到合适的对象移除方案,来完成 Alpha Mask(Alpha遮罩)和 Clean Plate(目标移除)环节。Omnimatte 虽然可以将对象及对象所产生的效果一同移除,但是单个视频模型训练需要耗费2小时,且需要额外准备 光流文件和视频分割结果,因此性价比较低。偶然看到 Inpaint Anything 已经可以很好地进行图像移除了,于是对其中的LaMa进行了复现,并结合 paddle 的文本图像编辑模型,完成了 Inpaint Anything相关功能的实现。之后,本人结合 PP-YOLOE 检测模型,对图像级的 Remove Anything 进行了扩展,实现了指定类别的视频目标移除。
目前相关的项目: 官方 Inpaint Anything 地址(pytorch)如下: https://github.com/geekyutao/Inpaint-Anything。 官方项目就是对已有的图像分割、图像修复、文本图像生成 SOTA 方法进行组装。与官方项目不同的是,该项目对LaMa 源码进行了精简,只保留推理部分,因此不再需要安装 LaMa 训练所需的诸多依赖。此外,同类的视频对象移除(隐身)项目还包括 Omnimatte,项目地址如下:https://github.com/erikalu/omnimatte。
技术细节:Inpaint Anything 的项目架构图如下:首先,将待编辑图像及其点坐标输入到 Segment Anything中获得指定图像 mask,之后结合图像修复SOTA模型(如:LaMa、Repaint、MAT 和 ZITS)对指定对象进行移除,结合AIGG模型(如:扩散模型 stable diffusion 等)和文本提示,对指定图像或其所在的背景进行填充。下面将对项目的具体实现步骤进行阐述。由于代码块不会自动释放显存,项目模型显存占用率又比较高,必要时需要重启内核,释放显存。
2.1 环境配置
由于该项目直接调用的 PaddleSeg 中的 SAM 模型和 PaddleNLP 的 stable_diffusion_inpaint模型,因此需要安装 PaddleSeg 、ppdiffusers 等相关库。此外,由于模型文件过大,两个模型加在一起约 6 G 左右,每次启动项目都要下载十分耗时,因此,这里将 SAM 模型、 stable_diffusion_inpaint 权重文件和视频目标移除的检测器 PP-YOLOE 权重文件 保存在 AI studio 数据集中,启动项目后直接拷贝到预设路径即可。由于命令行会将其权重文件解压到 AI Studio 本地路径,解压命令只需要在初次运行项目时运行一次即可,之后可以注释掉解压命令,每次只将权重拷贝到预定义路径即可。
# 安装 paddleseg,以便调用其中的SAM模型
%cd /home/aistudio/
!pip install --user paddleseg==2.8.0
# 安装 LaMA 相关依赖库
!pip install --user omegaconf
# 安装SAM模型的依赖包
!pip install --user ftfy regex
# 安装 pddiffuser,以便调用其中的paddlenlp 模型
!pip install --user --upgrade ppdiffusers
# 由于下载SAM模型时间较长,这里直接将其拷贝到 paddleseg要求的模型目录下
%cd /home/aistudio/
!mkdir .paddleseg
!mkdir .paddleseg/pretrained_model
!mkdir .paddleseg/pretrained_model/vit_l
!cp /home/aistudio/data/data211468/vit_l_sam.pdparams /home/aistudio/.paddleseg/pretrained_model/vit_l/model.pdparams
# 由于 stable diffusion inpaint模型 下载时间过长,这里直接将其拷贝到 paddlenlp 要求的模型目录下
# 这里只需要解压一次,之后可注释掉解压命令,直接拷贝即可,该过程耗时3分钟左右
%cd /home/aistudio/
!unzip /home/aistudio/data/data211468/stable_diff_inpaint.zip
!mkdir .cache
!cp -r /home/aistudio/stable_diffusion_inpaint/paddlenlp /home/aistudio/.cache/
# 解压检测器模型,以便对视频中需要移除的目标进行检测
%cd /home/aistudio/
!unzip /home/aistudio/data/data211468/coco.zip
由于新安装的依赖库不会同步更新到 notebook 中,此处需要先重启内核,再运行 2.2 之后的代码,否则会报错“找不到 paddleseg 环境”,其他找不到环境问题一般可以通过加入 --user 重新安装或者重启内核解决
2.2 加载SAM模型,并获取指定目标 mask
# 将当前路径切换为/home/aistudio/work/,以便导入LaMa代码中的相关函数
%cd /home/aistudio/work/
# 导入相关包
import os
import sys
import argparse
from PIL import Image
from pathlib import Path
import paddle
import cv2
import numpy as np
os.path.join( "/home/aistudio/work/..")
from segment_anything.predictor import SamPredictor
from segment_anything.build_sam import sam_model_registry
from lama_inpaint import inpaint_img_with_lama
from utils import load_img_to_array, save_array_to_img, dilate_mask, \
show_mask, show_points
from matplotlib import pyplot as plt
import warnings
warnings.filterwarnings("ignore")
import logging
logging.disable(logging.WARNING)
os.environ["TF_CPP_MIN_LOG_LEVEL"] = '0'
# SAM 模型不同版本下载地址
model_link = {
'vit_h':
"https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_h/model.pdparams",
'vit_l':
"https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_l/model.pdparams",
'vit_b':
"https://bj.bcebos.com/paddleseg/dygraph/paddlesegAnything/vit_b/model.pdparams"
}
input_path ="/home/aistudio/work/example/remove-anything/sample1.png"
sam_model_type = "vit_l"
point = np.array([[750, 500]])
point_labels=1
# 读取输入图片
img = cv2.imread(input_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 加载SAM模型
model = sam_model_registry[sam_model_type](
checkpoint=model_link[sam_model_type])
# 调用Sam模型进行图像mask推理,可以采用 box或 point 提示,简单起见,这里输入待分割目标point(x,y)
predictor = SamPredictor(model)
predictor.set_image(img)
masks, _, _ = predictor.predict(
point_coords=point,
point_labels=point_labels,
box=None,
multimask_output=True, )
masks = masks.astype(np.uint8) * 255
# mask 可视化
for idx, mask in enumerate(masks):
dpi = plt.rcParams['figure.dpi']
height, width = img.shape[:2]
plt.imshow(img)
plt.axis('off')
show_mask(plt.gca(), mask, random_color=False)
plt.show()
break
2.3 利用mask,实现图像对象移除(Remove Anything)
import cv2
import os
import sys
import numpy as np
import paddle
import yaml
import glob
import argparse
from PIL import Image
from omegaconf import OmegaConf
from saicinpainting.training.modules import make_generator
import paddle.nn.functional as F
from lama_inpaint import pad_tensor_to_modulo
# 利用LaMa 进行目标移除
def inpaint_img_with_lama(
img: np.ndarray,
mask: np.ndarray,
config_p: str,
ckpt_p: str,
predict_config: str="./lama/configs/prediction/default.yaml",
mod=8,
):
assert len(mask.shape) == 2
# 图像和mask预处理
if np.max(mask) == 1:
mask = mask * 255
img = paddle.to_tensor(img/255.0,dtype='float32')
mask = paddle.to_tensor(mask,dtype="float32")
# 加载推理配置文件
predict_config = OmegaConf.load(predict_config)
predict_config.model.path = ckpt_p
# 加载模型配置文件
with open(config_p, 'r') as f:
train_config = OmegaConf.create(yaml.safe_load(f))
train_config.training_model.predict_only = True
train_config.visualizer.kind = 'noop'
# 构建模型并加载相应权重
model = make_generator(train_config, **train_config.generator)
path = ckpt_p
state = paddle.load(path)
model.set_state_dict(state)
model.eval()
# 创建batch字典,作为模型输入
batch = {}
batch['image'] = img.transpose([2, 0, 1]).unsqueeze(0)
batch['mask'] = mask[None, None]
unpad_to_size = [batch['image'].shape[2], batch['image'].shape[3]]
batch['image'] = pad_tensor_to_modulo(batch['image'], mod)
batch['mask'] = pad_tensor_to_modulo(batch['mask'], mod)
batch['mask'] = (batch['mask'] > 0).cast('float32')
img = batch['image']
mask = batch['mask']
img = paddle.to_tensor(img)
mask = paddle.to_tensor(mask)
masked_img = img * (1 - mask)
masked_img = paddle.concat([masked_img, mask], axis =1)
# 预测图像修复结果
with paddle.no_grad():
batch['predicted_image'] = model(masked_img)
batch['inpainted'] = mask * batch['predicted_image'] + (1 - mask) * batch['image']
# 根据预设键值,获取修复后的图像
cur_res = batch[predict_config.out_key][0].transpose([1, 2, 0])
cur_res = cur_res.detach().cpu().numpy()
#对修复结果进行后处理
if unpad_to_size is not None:
orig_height, orig_width = unpad_to_size
cur_res = cur_res[:orig_height, :orig_width]
cur_res = np.clip(cur_res * 255, 0, 255).astype('uint8')
return cur_res
lama_config="/home/aistudio/work/lamn/big_lanm/config.yaml"
lama_ckpt="/home/aistudio/data/data211468/paddle_gen.pdparams"
predict_config="/home/aistudio/work/lamn/config/default.yml"
dilate_kernel_size = 15
# 对mask 进行膨胀操作,此步十分重要,否则由于没有目标周围纹理作为参考,图像修复效果会变得极差。
masks1 = [dilate_mask(mask, dilate_kernel_size) for mask in masks]
# 移除后的图像可视化
for idx, mask in enumerate(masks1):
img_inpainted = inpaint_img_with_lama(
img, mask, lama_config, lama_ckpt, predict_config)
plt.imshow(img_inpainted)
plt.show()
break
2.4 结合 PP-YOLOE,实现视频对象移除(Remove Anything Video)
%cd /home/aistudio/work/
from tqdm import tqdm
from remove_anything_video import label_list,save_videos_grid, process_yoloe,array_to_img
# 设置视频路径和移除对象类别
input_path = "/home/aistudio/work/example/remove-anything-video/car.mp4"
remove_type = ["car"]
# 设置输出路径和配置文件路径
output_dir="/home/aistudio/work/results"
lama_config="/home/aistudio/work/lamn/big_lanm/config.yaml"
lama_ckpt="/home/aistudio/data/data211468/paddle_gen.pdparams"
predict_config="/home/aistudio/work/lamn/config/default.yml"
dilate_kernel_size = 15
src_video_dir = input_path
# 读取视频
video_object = cv2.VideoCapture(src_video_dir)
fps = video_object.get(cv2.CAP_PROP_FPS)
frame_paths_list = []
# 加载检测器模型
detector = paddle.jit.load('/home/aistudio/ppyoloe_plus_crn_l_80e_coco/model')
detector.eval()
# 获取视频总帧数,并设置进度条
frame_count = int(video_object.get(cv2.CAP_PROP_FRAME_COUNT))
progress_bar = tqdm(total=frame_count)
# 由于检测器在COCO数据训练,检测不出COCO 80类外的类别,如果需要移除的类别不在COCO 80类中,程序会报错
for item in remove_type:
if item not in label_list:
raise ValueError('the remove object type is not in COCO 80 class ')
# 根据用户指定类别对检测器中的边界框进行筛选
def select_desired_box(pre,remove_type):
box = []
maxS = 0
box = []
max_item = None
# 遍历检测结果
for item in pre[0].numpy():
cls, value, xmin, ymin, xmax, ymax = list(item)
cls, xmin, ymin, xmax, ymax = [int(x) for x in [cls, xmin, ymin, xmax, ymax]]
curS = (ymax-ymin)*(xmax-xmin)
label = label_list[cls]
# 对于非"person"的其他类别,如果边界框类别包含在指定类别中,则将其加入到最终box列表中
if value>0.5 and label!="person" and (label in remove_type):
box.append( np.array([[xmin, ymin], [xmax, ymax]]))
# 对于"person"类别,如果"person"类别包含在指定类别中,则将面积最大的检测框加入到box中
if value>0.5 and label=="person" and (label in remove_type):
if curS>maxS:
maxS=curS
max_item = item
# 判断"person"类别的最大检测框是否存在,若存在,加入到box列表中
if max_item is not None:
cls, value, xmin, ymin, xmax, ymax = list( max_item )
box.append( np.array([[xmin, ymin], [xmax, ymax]]))
return box
# 遍历视频
while True:
ret, frame = video_object.read()
# 已经是最后一帧,则退出
if ret == False:
print("predict_rbox_frame_from_video({})".format(src_video_dir))
break
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
im_info = {
'scale_factor': np.array(
[1., 1.], dtype=np.float32),
'im_shape': None}
h1, w1 = frame.shape[:-1]
#进行图像预处理,以便后续检测器进行检测
im, im_shape, factor = process_yoloe(frame, im_info, [640, 640])
# 使用 PP-YOLOE 对图像中所有目标进行检测
with paddle.no_grad():
pre = detector(im, factor)
# 筛选出位于移除类别列表中的检测框
box = select_desired_box(pre,remove_type)
if len(box)>0:
# 初始化一张值全为0的mask
init_mask = np.zeros([h1,w1])
for b in box:
# 采用SAM获取边界框所对应的 mask
predictor = SamPredictor(model)
predictor.set_image(frame)
masks1, _, _ = predictor.predict(
point_coords=None,
point_labels=1,
box=b,
multimask_output=True, )
masks1 = masks1.astype(np.uint8) * 255
# 对mask进行膨胀处理
if dilate_kernel_size is not None:
masks1 = [dilate_mask(mask, dilate_kernel_size) for mask in masks1]
# 将当前边界框mask融合到初始化mask中
idx = np.array(masks1[0]==255)
init_mask[idx]=255
# 将包含所有需要移除目标mask的初始化mask送入到LaMa中进行目标移除
img_inpainted = inpaint_img_with_lama(
frame, init_mask, lama_config, lama_ckpt, predict_config)
img_inpainted = array_to_img(img_inpainted)
frame_remove = np.array(img_inpainted)
frame_remove = cv2.resize( frame_remove,dsize=None, fx=0.4, fy= 0.4 )
orginal_frame = cv2.resize( frame,dsize=None, fx=0.4, fy= 0.4)
# 将原始帧和移除后帧拼接,并加入到 frame_paths_list 列表中
concat_frame = np.hstack(( orginal_frame,frame_remove))
frame_remove = paddle.to_tensor(concat_frame /255.0, dtype='float32').unsqueeze(0)
frame_paths_list.append( frame_remove)
# break
progress_bar.update(1)
# 创建输出目录
video_seq = paddle.concat(frame_paths_list, axis= 0)
video_seq = paddle.to_tensor(video_seq).transpose([3, 0, 1, 2 ]).unsqueeze(0)
img_stem = Path( input_path).stem
out_dir = Path(output_dir) / img_stem
out_dir.mkdir(parents=True, exist_ok=True)
# 将原始视频和移除后的视频保存为GIF
git_img_p ="{}/ {}".format(out_dir,os.path.basename(input_path).replace(".mp4",".gif"))
save_videos_grid(video_seq, git_img_p,fps=fps )
视频移除完成后,可以在 /home/aistudio/work/results/car/ 路径下点击 car.gif 图像,在AI Studio中 查看移除视频的效果。具体效果如下:

2.5 利用mask,实现对象填充(Fill Anything)
from utils.mask_processing import crop_for_filling_pre, crop_for_filling_post
from utils.crop_for_replacing import recover_size, resize_and_pad
from ppdiffusers import StableDiffusionInpaintPipeline
# 利用 StableDiffusionInpaint 实现对象填充
def fill_img_with_sd(
img: np.ndarray,
mask: np.ndarray,
text_prompt: str,
):
# 加载 StableDiffusionInpaint 模型
pipe = StableDiffusionInpaintPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting")
# 对 img 和 mask进行预处理(缩放、填充、裁剪)
img_crop, mask_crop = crop_for_filling_pre(img, mask)
# 生成填充后的图像
img_crop_filled = pipe(
prompt=text_prompt,
image=Image.fromarray(img_crop),
mask_image=Image.fromarray(mask_crop)
).images[0]
# 对填充后的图像进行后处理(将合成的前景图像填充回原图像中)
img_filled = crop_for_filling_post(img, mask, np.array(img_crop_filled))
return img_filled
# 对mask 进行膨胀操作,此步十分重要,否则由于没有目标周围纹理作为参考,图像填充效果会变得极差。
dilate_kernel_size = 50
masks1 = [dilate_mask(mask, dilate_kernel_size) for mask in masks]
# 对象填充结果可视化
text_prompt ="a teddy bear on a bench"
for idx, mask in enumerate(masks1):
paddle.seed(1234)
img_filled = fill_img_with_sd(img, mask, text_prompt)
plt.imshow( img_filled)
plt.show()
break
2.6 利用mask,实现背景填充(Replace Anything)
from utils.mask_processing import crop_for_filling_pre, crop_for_filling_post
from utils.crop_for_replacing import recover_size, resize_and_pad
from ppdiffusers import StableDiffusionInpaintPipeline
# 利用 StableDiffusionInpaint 实现背景填充
def replace_img_with_sd(
img: np.ndarray,
mask: np.ndarray,
text_prompt: str,
step: int = 50,
):
# 加载 StableDiffusionInpaint 模型
pipe = StableDiffusionInpaintPipeline.from_pretrained("stabilityai/stable-diffusion-2-inpainting")
# 对img和mask进行预处理(缩放、填充)
img_padded, mask_padded, padding_factors = resize_and_pad(img, mask)
img_padded = pipe(
prompt=text_prompt,
image=Image.fromarray(img_padded),
mask_image=Image.fromarray(255 - mask_padded),
num_inference_steps=step,
).images[0]
height, width, _ = img.shape
# 将img和mask缩放回原尺寸
img_resized, mask_resized = recover_size(
np.array(img_padded), mask_padded, (height, width), padding_factors)
mask_resized = np.expand_dims(mask_resized, -1) / 255
# 利用缩放后的mask,对生成的背景和原图像前景进行混合
img_resized = img_resized * (1-mask_resized) + img * mask_resized
return img_resized
# 对背景填充结果进行可视化
masks1 = masks
text_prompt="sit on the swing"
for idx, mask in enumerate(masks1):
paddle.seed(1234)
img_replaced = replace_img_with_sd(
img, mask, text_prompt)
plt.imshow( img_replaced.astype(np.uint8))
plt.show()
break
三、更多的结果展示
3.1 Remove Anything

3.2 Remove Angthing Video



3.3 Fill Anything

3.4 Replace Anything

四、部署细节
在运行推理代码之前,请确保已经完成 2.1 环境配置中所有代码块的运行。如果运行了二、详细说明中的 2.2-2.6 代码块,请先重启内核,否则会导致显存崩溃。
4.1 Remove Anything
根据输入坐标,移除指定对象。示例图像位于/home/aistudio/work/example/remove-anything目录下,points_coords.yaml 记录了每张示例图像的 x,y 坐标,运行脚本时,可以参考上述坐标进行目标移除。使用模型推理时可选的一些参数如下:
input_img:(str)- 输入图像路径。point_coords:(int, int)-需要移除对象的 x,y 坐标。point_labels:(int)-需要移除对象的分割标签,默认为1。dilate_kernel_size:(int)-膨胀核大小,对分割 mask 进行膨胀,不进行该操作,会导致生成图像保留部分原图像痕迹。output_dir:(str)-生成结果所在目录,默认输出结果保存在/home/aistudio/work/results目录下。sam_model_type:(str)-SAM 模型类型,包含 vit_l/vit_b/vit_h 三种,越大的模型分割效果会越好,但是推理速度也越慢,这里 vit_l 模型就已经可以满足项目需求了,且已经保存在 AI studio 数据集中,选用其他模型单独重新下载。lama_config:(str)-LaMa 模型配置文件路径。lama_ckpt:(str)-LaMa 模型权重件路径,已经保存在 AI studio 数据集中。predict_config:(str)-LaMa 模型推理配置文件路径。
# 显存 7G ,耗时15s
%cd /home/aistudio/work/
!python remove_anything.py \
--input_img /home/aistudio/work/example/remove-anything/cat.jpg \
--point_coords 600 1100 \
--point_labels 1 \
--dilate_kernel_size 15 \
--output_dir /home/aistudio/work/results \
--sam_model_type "vit_l" \
--lama_config /home/aistudio/work/lamn/big_lanm/config.yaml \
--lama_ckpt /home/aistudio/data/data211468/paddle_gen.pdparams \
--predict_config /home/aistudio/work/lamn/config/default.yml
4.2 Remove Anything Video
根据移除对象的类型,移除视频中的指定对象。示例视频位于 /home/aistudio/work/example/remove-anything-video 目录下,remove_type.yaml 记录了每个示例视频的移除对象,运行脚本时,可以参考上述移除类别进行视频对象移除。需要注意的是如果视频中的目标过大或背景比较复杂会导致移除效果较差,且移除对象的类别需要在 COCO 80类中(检测器是在COCO数据集进行训练的),使用模型推理时可选的一些参数如下:
input_video:(str)- 输入视频的路径。remove_type:(str)-移除对象的类别。dilate_kernel_size:(int)-膨胀核大小,对分割 mask 进行膨胀,不进行该操作,会导致生成视频保留部分原图像痕迹。output_dir:(str)-生成结果所在目录,默认输出结果保存在/home/aistudio/work/results目录下。sam_model_type:(str)-SAM 模型类型,包含 vit_l/vit_b/vit_h 三种,越大的模型分割效果会越好,但是推理速度也越慢,这里 vit_l 模型就已经可以满足项目需求了,且已经保存在 AI studio 数据集中,选用其他模型单独重新下载。lama_config:(str)-LaMa 模型配置文件路径。lama_ckpt:(str)-LaMa 模型权重件路径,已经保存在 AI studio 数据集中。predict_config:(str)-LaMa 模型推理配置文件路径。
# 显存 7.2 G, 耗时 30 s
%cd /home/aistudio/work/
!python remove_anything_video.py \
--input_video /home/aistudio/work/example/remove-anything-video/car.mp4 \
--remove_type "car"\
--dilate_kernel_size 15 \
--output_dir /home/aistudio/work/results \
--sam_model_type "vit_l" \
--lama_config /home/aistudio/work/lamn/big_lanm/config.yaml \
--lama_ckpt /home/aistudio/data/data211468/paddle_gen.pdparams \
--predict_config /home/aistudio/work/lamn/config/default.yml
4.3 Fill Anything
根据输入坐标和文本提示填充指定对象。示例图像位于/home/aistudio/work/example/fill-anything目录下,points_coords.yaml 记录了每张示例图像的 x,y 坐标,text_prompt.yaml 记录每张示例图像的文本提示,运行脚本时,可以参考上述坐标和文本提示进行对象填充。使用模型推理时可选的一些参数如下:
input_img:(str)- 输入图像路径。point_coords:(int, int)-需要填充对象的 x,y 坐标。point_labels:(int)-需要填充对象的分割标签,默认为1。text_prompt:(str)-用于指导填充对象生成的文本提示。dilate_kernel_size:(int)-膨胀核大小,对分割 mask 进行膨胀,不进行该操作,会导致生成图像保留部分原图像痕迹。output_dir:(str)-生成结果所在目录,默认输出结果保存在/home/aistudio/work/results目录下。sam_model_type:(str)-SAM 模型类型,包含 vit_l/vit_b/vit_h 三种,越大的模型分割效果会越好,但是推理速度也越慢,这里 vit_l 模型就已经可以满足项目需求了,且已经保存在 AI studio 数据集中,选用其他模型单独重新下载。
%cd /home/aistudio/work/
# 9.1GB 显存,耗时 2分钟左右
!python fill_anything.py \
--input_img /home/aistudio/work/example/fill-anything/sample5.png\
--point_coords 627 845\
--point_labels 1 \
--text_prompt "a Picasso painting on the wall" \
--dilate_kernel_size 50 \
--output_dir /home/aistudio/work/results \
--sam_model_type "vit_l"
4.4 Replace Anything
根据输入坐标和文本提示,替换指定对象的背景。示例图像位于/home/aistudio/work/example/replace-anything目录下,points_coords.yaml 记录了每张示例图像的 x,y 坐标,text_prompt.yaml 记录了每张示例图像的文本提示,运行脚本时,可以参考上述坐标和文本提示进行背景替换。使用模型推理时可选的一些参数如下:
input_img:(str)-输入图像路径。point_coords:(int, int)-需要填充对象的 x,y 坐标。point_labels:(int)-需要填充对象的分割标签,默认为1。text_prompt:(str)-用于指导填充背景生成的文本提示。output_dir:(str)-生成结果所在目录,默认输出结果保存在/home/aistudio/work/results目录下。sam_model_type:(str)-SAM 模型类型,包含 vit_l/vit_b/vit_h 三种,越大的模型分割效果会越好,但是推理速度也越慢,这里 vit_l 模型就已经可以满足项目需求了,且已经保存在 AI studio 数据集中,选用其他模型单独重新下载。
# 显存为 9G 左右,耗时 2分钟 左右
%cd /home/aistudio/work/
!python replace_anything.py \
--input_img /home/aistudio/work/example/replace-anything/dog.png \
--point_coords 750 500 \
--point_labels 1 \
--text_prompt "sit on the swing" \
--output_dir /home/aistudio/work/results \
--sam_model_type "vit_l" \
五、总结
该项目对 LaMa 模型的推理部分进行了复现,并结合 paddleseg 中的 SAM 模型和 ppdiffuser 中的 stable diffusion inpaint 模型,实现 Inpaint Anything 中 Remove Anything、Fill Anything 和 Replace Anything 图像编辑模式。利用这三种模式,用户可以生成一些有趣的图片。此外,本人还基于图像级的 Inpaint Anything 和 PPYOLOE 在COCO数据集上的训练模型 实现了特定类别的视频对象移除。本人下一步计划是实现一个低配版的 Wonder Studio AI 视频特效项目。
图像编辑和视频编辑是一件十分有趣的事情。 Inpaint Anything 的Paddle 实现代码已经上传到 Github 上, repo地址为:https://github.com/LHE-IT/Inpaint-Anything-Paddle,欢迎大家参与到项目建设中。
参考项目:
【1】 Inpaint Anything: Segment Anything Meets Image Inpainting
【2】 Segment Anything with PaddleSeg
【3】 PPDiffusers: Diffusers toolbox implemented based on PaddlePaddle
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)