
paddlepaddle打比赛之高分辨率遥感影像建筑物变化检测
城市是人类生活、生产的主要场所,在社会经济活动中处于重要位置。经济发展、人口增长和城市化进程的加快导致了城市地区的急剧变化,准确及时地识别这些变化并分析其趋势已经成为城市管理者的重要课题。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
1 赛事背景
城市是人类生活、生产的主要场所,在社会经济活动中处于重要位置。经济发展、人口增长和城市化进程的加快导致了城市地区的急剧变化,准确及时地识别这些变化并分析其趋势已经成为城市管理者的重要课题,是地理国情普查与监测的重点关注内容,成为目前亟待解决的问题。其中建筑的拆除、建设和扩建是城市蓝图规划关注的重要组成部分,与人类的生存活动密切相关。“吉林一号”卫星星座能提供高分辨率高频次的遥感影像数据,为精细、快速建筑物变化提供数据支撑。因此,本赛道旨在充分利用人工智能等先进技术,结合“吉林一号”卫星遥感数据,从高分辨率卫星遥感影像中对建筑物变化信息进行有效识别提取。
2 赛事任务
建筑物几何尺寸、变化特征具有时相、区域差异性,为实用高效的推动建筑物变化检测在实际需求中的应用,本次大赛以“吉林一号”高分辨率卫星遥感影像作为数据集,参赛选手需基于提供的样本构建模型,预测双时相影像中建筑物变化发生的位置与分布范围。
3 评审规则
3.1 数据说明
本次大赛提供吉林一号高分辨率遥感影像作为数据源,影像分辨率优于1米,由长光卫星技术股份有限公司拍摄、标注、构建。其中,初赛提供训练数据集2500对,测试数据集500对,复赛提供测试数据集500对。
-
原始影像:双时相影像格式为tif,包含R、G、B三个波段,训练集与测试集影像尺寸均为512*512像素。
-
标签数据:标签格式为单通道的png,每个像素的标签值由一个数值表示,使用‘uint8’数据类型存储,该数值表示是否为变化,“0”代表未变化,“1”代表变化,尺寸为512*512像素。
3.2 评估指标
为了评估算法的性能,采用mIOU进行评价。
1)首先基于建筑物变化检测的真实标签与预测结果,统计TP(表示被正确检测的变化像元数),FP(表示实际未变化但被检测为变化的像元数),TN(表示被正确检测的未变化像元数),FN(实际发生变化但未被检测为变化的像元数)。
2)通过第一步计算结果计算mIOU,得到最后评测结果,计算方式如下:
初赛:Score1 = mIOU
复赛:Score2 = 0.5Score1(复赛数据集测试分,即排行榜得分)+ 0.3效率分+ 0.1代码分+0.1技术文档分
3.3 评测及排行
-
初赛提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
-
排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
-
复赛排行榜前三名需提交技术报告(数据处理流程,代码及模型说明)、代码和模型,未按时提交的,将不计入复赛最终排名。
-
参赛选手要保证算法模型的可复现性,模型整体大小需不超过600MB。
4 作品提交要求
-
文件格式:
①提交submit.zip压缩包,内含文件夹submit,文件夹内为png格式图片;
②复赛排行榜更新结束后,排行榜前三名需要提交技术报告、代码和模型。
-
文件大小:无要求
-
提交次数限制:每支队伍每天最多3次
-
文件详细说明:
①图片以png格式提交,每个像素的标签值由一个数值表示,使用‘uint8’数据类型存储,该数值表示是否为变化,“0”代表未变化,“1”代表变化;
②预测结果中的单个文件名需和预测影像命名方式一致,若预测图片中包含test_1.tif,则预测结果中必须有test_1.png。
5 数据预处理
# 解压数据集
# 该操作涉及大量文件IO,可能需要一些时间
!unzip -o -d /home/aistudio/work/dataset /home/aistudio/data/data215567/高分辨率遥感影像建筑物变化检测挑战赛公开数据-初赛.zip > /dev/null
!mkdir /home/aistudio/dataset
!mkdir /home/aistudio/dataset/train /home/aistudio/dataset/test
# 将训练集与测试集移动至指定路径
!mv /home/aistudio/work/dataset/╕▀╖╓▒ц┬╩╥г╕╨╙░╧ё╜и╓■╬я▒ф╗п╝ь▓т╠Ї╒╜╚№╣л┐к╩¤╛▌-│ї╚№/│ї╚№▓т╩╘╝п/* /home/aistudio/dataset/test/
!mv /home/aistudio/work/dataset/╕▀╖╓▒ц┬╩╥г╕╨╙░╧ё╜и╓■╬я▒ф╗п╝ь▓т╠Ї╒╜╚№╣л┐к╩¤╛▌-│ї╚№/│ї╚№╤╡┴╖╝п/* /home/aistudio/dataset/train/
!rm -rf /home/aistudio/work/dataset/╕▀╖╓▒ц┬╩╥г╕╨╙░╧ё╜и╓■╬я▒ф╗п╝ь▓т╠Ї╒╜╚№╣л┐к╩¤╛▌-│ї╚№
5.1 将tif格式图片转换为png格式
!mkdir /home/aistudio/dataset/train/A /home/aistudio/dataset/train/B
!mkdir /home/aistudio/dataset/test/A /home/aistudio/dataset/test/B
import os
import cv2
imagesDirectory = r"/home/aistudio/dataset/train/Image1" # tiff图片所在文件夹路径
png_path = r"/home/aistudio/dataset/train/A"
distDirectory = os.path.dirname(png_path)#
distDirectory = os.path.join(distDirectory, "B")# 要存放bmp格式的文件夹路径
print(distDirectory)
for imageName in os.listdir(imagesDirectory):
print("imageName", imageName)
imagePath = os.path.join(imagesDirectory, imageName)
print("imagePath", imagePath)
img = cv2.imread(imagePath)
try:
img.shape
except:
print('读取图片失败')
break
print("imageName.split('.')[0]", imageName.split('.')[0])
distImagePath = os.path.join(distDirectory, imageName.split('.')[0]+'.png')# 更改图像后缀为.jpg,并保证与原图像同名
print("distImagePath", distImagePath)
cv2.imwrite(distImagePath, img)
imagesDirectory = r"/home/aistudio/dataset/train/Image2" # tiff图片所在文件夹路径
png_path = r"/home/aistudio/dataset/train/B"
distDirectory = os.path.dirname(png_path)#
distDirectory = os.path.join(distDirectory, "B")# 要存放bmp格式的文件夹路径
print(distDirectory)
for imageName in os.listdir(imagesDirectory):
print("imageName", imageName)
imagePath = os.path.join(imagesDirectory, imageName)
print("imagePath", imagePath)
img = cv2.imread(imagePath)
try:
img.shape
except:
print('读取图片失败')
break
print("imageName.split('.')[0]", imageName.split('.')[0])
distImagePath = os.path.join(distDirectory, imageName.split('.')[0]+'.png')# 更改图像后缀为.jpg,并保证与原图像同名
print("distImagePath", distImagePath)
cv2.imwrite(distImagePath, img)
imagesDirectory = r"/home/aistudio/dataset/test/Image1" # tiff图片所在文件夹路径
png_path = r"/home/aistudio/dataset/test/A"
distDirectory = os.path.dirname(png_path)#
distDirectory = os.path.join(distDirectory, "A")# 要存放bmp格式的文件夹路径
print(distDirectory)
for imageName in os.listdir(imagesDirectory):
print("imageName", imageName)
imagePath = os.path.join(imagesDirectory, imageName)
print("imagePath", imagePath)
img = cv2.imread(imagePath)
try:
img.shape
except:
print('读取图片失败')
break
print("imageName.split('.')[0]", imageName.split('.')[0])
distImagePath = os.path.join(distDirectory, imageName.split('.')[0]+'.png')# 更改图像后缀为.jpg,并保证与原图像同名
print("distImagePath", distImagePath)
cv2.imwrite(distImagePath, img)
imagesDirectory = r"/home/aistudio/dataset/test/Image2" # tiff图片所在文件夹路径
png_path = r"/home/aistudio/dataset/test/B"
distDirectory = os.path.dirname(png_path)#
distDirectory = os.path.join(distDirectory, "B")# 要存放bmp格式的文件夹路径
print(distDirectory)
for imageName in os.listdir(imagesDirectory):
print("imageName", imageName)
imagePath = os.path.join(imagesDirectory, imageName)
print("imagePath", imagePath)
img = cv2.imread(imagePath)
try:
img.shape
except:
print('读取图片失败')
break
print("imageName.split('.')[0]", imageName.split('.')[0])
distImagePath = os.path.join(distDirectory, imageName.split('.')[0]+'.png')# 更改图像后缀为.jpg,并保证与原图像同名
print("distImagePath", distImagePath)
cv2.imwrite(distImagePath, img)
6 模型训练
变化检测任务的mIoU与F1分数指标定义:
m I o U = 1 2 ( T P F N + F P + T P + T N F P + F N + T N ) mIoU=\frac{1}{2}\left(\frac{TP}{FN+FP+TP}+\frac{TN}{FP+FN+TN}\right) mIoU=21(FN+FP+TPTP+FP+FN+TNTN)
F 1 = 2 ⋅ T P 2 ⋅ T P + F N + F P F1=\frac{2 \cdot TP}{2 \cdot TP + FN + FP} F1=2⋅TP+FN+FP2⋅TP
式中, T P TP TP表示预测为变化且实际为变化的样本数, T N TN TN表示预测为不变且实际为不变的样本数, F P FP FP表示预测为变化但实际为不变的样本数, F N FN FN表示预测为不变但实际为变化的样本数。
此外,PaddleRS在验证集上汇报针对每一类的指标,因此对于二类变化检测来说,category_acc、category_F1-score等指标均存在两个数据项,以列表形式体现。由于变化检测任务主要关注变化类,因此观察和比较每种指标的第二个数据项(即列表的第二个元素)是更有意义的。
# 安装paddleseg
!pip install paddleseg==2.2.0
# 划分训练集/验证集,并生成文件名列表,fork后只运行一次
# 训练的时候保证训练集、验证集不变。
import random
import os.path as osp
from glob import glob
# 随机数生成器种子
RNG_SEED = 114514
# 调节此参数控制训练集数据的占比
TRAIN_RATIO = 0.95
# 数据集路径
DATA_DIR = '/home/aistudio/dataset/'
def write_rel_paths(phase, names, out_dir, prefix=''):
"""将文件相对路径存储在txt格式文件中"""
with open(osp.join(out_dir, phase+'.txt'), 'w') as f:
for name in names:
f.write(
' '.join([
osp.join(prefix, 'A', name),
osp.join(prefix, 'B', name),
osp.join(prefix, 'label1', name)
])
)
f.write('\n')
random.seed(RNG_SEED)
# 随机划分训练集/验证集
names = list(map(osp.basename, glob(osp.join(DATA_DIR, 'train', 'label1', '*.png'))))
# 对文件名进行排序,以确保多次运行结果一致
names.sort()
random.shuffle(names)
len_train = int(len(names)*TRAIN_RATIO) # 向下取整
write_rel_paths('train_list', names[:len_train], DATA_DIR, prefix='dataset/train')
write_rel_paths('val_list', names[len_train:], DATA_DIR, prefix='dataset/train')
write_rel_paths(
'test_list',
map(osp.basename, glob(osp.join(DATA_DIR, 'test', 'A', '*.png'))),
DATA_DIR,
prefix='dataset/test'
)
print("数据集划分已完成。")
数据集划分已完成。
# 构建数据集
import os
import cv2
import numpy as np
import paddle
from paddle.io import Dataset
from paddleseg.transforms import Compose, Resize
import paddleseg.transforms as T
class MyDataset(Dataset):
# 这里的transforms、num_classes和ignore_index需要,避免PaddleSeg在Eval时报错
def __init__(self, dataset_path, mode, transforms=[], num_classes=2, ignore_index=255):
list_path = os.path.join(dataset_path, (mode + '_list.txt'))
self.data_list = self.__get_list(list_path)
self.mode = mode
self.data_num = len(self.data_list)
self.transforms = Compose(transforms, to_rgb=False) # 一定要设置to_rgb为False,否则这里有6个通道会报错
self.is_aug = False if len(transforms) == 0 else True
self.num_classes = num_classes # 分类数
self.ignore_index = ignore_index # 忽视的像素值
def __getitem__(self, index):
A_path, B_path, lab_path = self.data_list[index]
A_img = cv2.cvtColor(cv2.imread(A_path), cv2.COLOR_BGR2RGB)
B_img = cv2.cvtColor(cv2.imread(B_path), cv2.COLOR_BGR2RGB)
image = np.concatenate((A_img, B_img), axis=-1) # 将两个时段的数据concat在通道层
label = cv2.imread(lab_path, cv2.IMREAD_GRAYSCALE)
if self.is_aug:
image, label = self.transforms(im=image, label=label)
image = paddle.to_tensor(image).astype('float32')
else:
image = paddle.to_tensor(image.transpose(2, 0, 1)).astype('float32')
if self.mode != 'test':
label = label.clip(max=1) # 这里把0-255变为0-1,否则啥也学不到,计算出来的Kappa系数还为负数
label = paddle.to_tensor(label[np.newaxis, :]).astype('int64')
return image, label
def __len__(self):
return self.data_num
# 这个用于把list.txt读取并转为list
def __get_list(self, list_path):
data_list = []
with open(list_path, 'r') as f:
data = f.readlines()
for d in data:
data_list.append(d.replace('\n', '').split(' '))
return data_list
dataset_path = 'dataset'
# 完成两个数据的创建
transforms = [Resize([512, 512])]
train_data = MyDataset(dataset_path, 'train', transforms)
val_data = MyDataset(dataset_path, 'val', transforms)
import paddle
from paddleseg.models import UNetPlusPlus,UNet3Plus
from paddleseg.models.losses import BCELoss,MixedLoss,LovaszSoftmaxLoss
from paddleseg.core import train
from paddleseg.models.backbones.resnet_vd import ResNet50_vd
# 参数、优化器及损失
batch_size = 8
epochs = 30
log_iters = int(len(train_data)/batch_size /3) #日志打印间隔
iters = int(len(train_data)/batch_size) * epochs #训练次数
save_interval = int(len(train_data)/batch_size) * 5 #保存的间隔次数
base_lr= 2e-4
model = UNetPlusPlus(in_channels=6, num_classes=2, use_deconv=True)
# model = UNet3Plus(in_channels=6, num_classes=2)
lr = paddle.optimizer.lr.CosineAnnealingDecay(base_lr, T_max=(iters // 3), last_epoch=0.5)
optimizer = paddle.optimizer.AdamW(lr, parameters=model.parameters())
mixtureLosses = [BCELoss(),LovaszSoftmaxLoss()]
mixtureCoef = [0.8,0.2]
losses = {}
losses['types'] = [MixedLoss(mixtureLosses,mixtureCoef)]
losses['coef'] = [1]
W0509 15:17:51.106863 27758 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0509 15:17:51.112594 27758 device_context.cc:465] device: 0, cuDNN Version: 7.6.
# 训练
train(
model=model,
train_dataset=train_data,
val_dataset=val_data,
optimizer=optimizer,
save_dir='output/unet2plus',
iters=iters,
batch_size=batch_size,
save_interval=save_interval,
log_iters=log_iters,
num_workers=0,
losses=losses,
use_vdl=True)
import paddle
from paddleseg.models import UNetPlusPlus,UNet3Plus
import matplotlib.pyplot as plt
model_path = 'output/unet2plus/best_model/model.pdparams' # 加载得到的最好参数
model = UNetPlusPlus(in_channels=6, num_classes=2, use_deconv=True)
# model = UNet3Plus(in_channels=6, num_classes=2)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
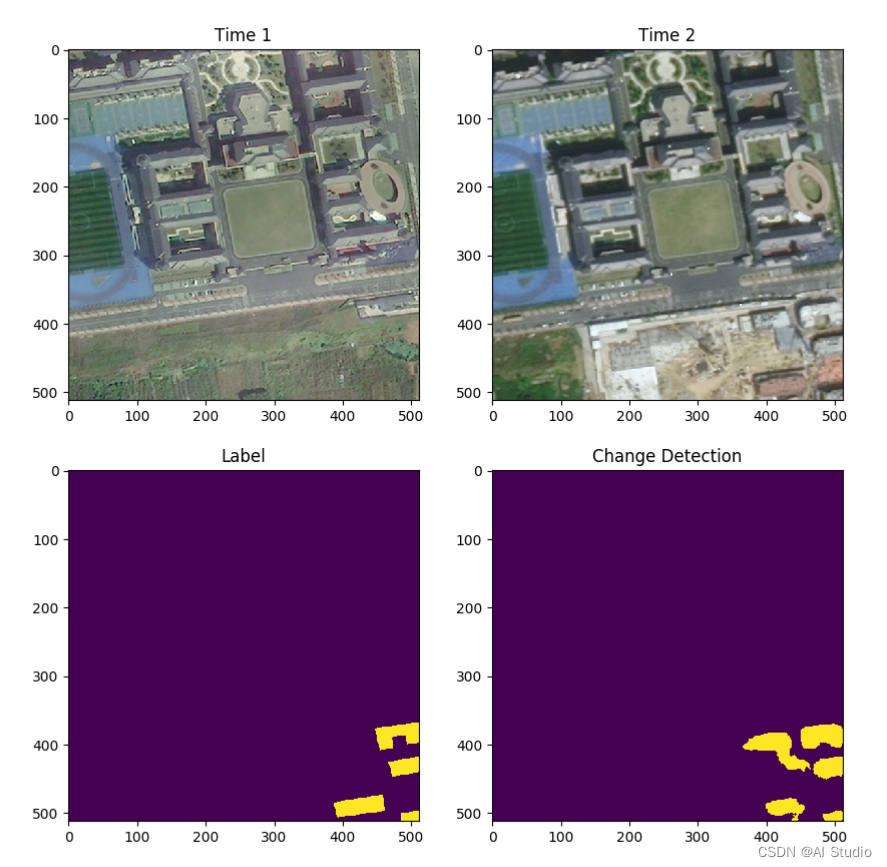
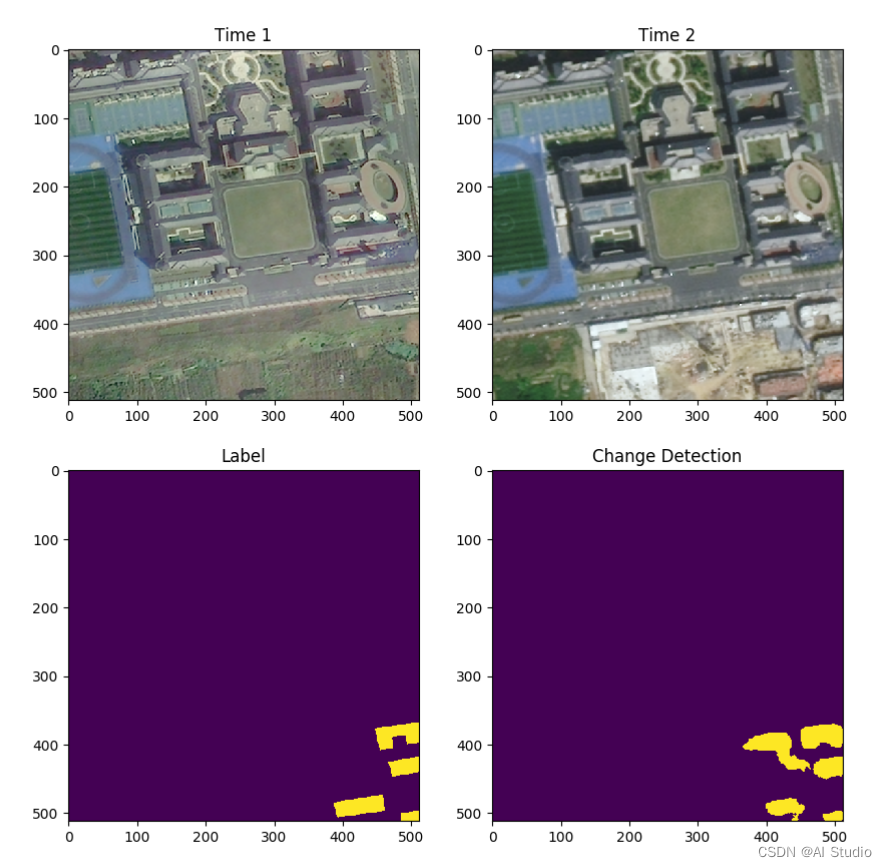
for idx, (img, lab) in enumerate(val_data): # 从test_data来读取数据
if idx == 6:
m_img = img.reshape((1, 6, 512, 512))
m_pre = model(m_img)
s_img = img.reshape((6, 512, 512)).numpy().transpose(1, 2, 0)
# 拆分6通道为两个3通道的不同时段图像
s_A_img = s_img[:,:,0:3]
s_B_img = s_img[:,:,3:6]
lab_img = lab.reshape((512, 512)).numpy()
pre_img = paddle.argmax(m_pre[0], axis=1).reshape((512, 512)).numpy()
plt.figure(figsize=(10, 10))
plt.subplot(2,2,1);plt.imshow(s_A_img.astype('int64'));plt.title('Time 1')
plt.subplot(2,2,2);plt.imshow(s_B_img.astype('int64'));plt.title('Time 2')
plt.subplot(2,2,3);plt.imshow(lab_img);plt.title('Label')
plt.subplot(2,2,4);plt.imshow(pre_img);plt.title('Change Detection')
plt.savefig('val.png')
plt.show()
break
7 模型预测
# 构建数据集
import os
import cv2
import numpy as np
import paddle
from paddle.io import Dataset
from paddleseg.transforms import Compose, Resize
import paddleseg.transforms as T
class MyDataset(Dataset):
# 这里的transforms、num_classes和ignore_index需要,避免PaddleSeg在Eval时报错
def __init__(self, dataset_path, mode, transforms=[], num_classes=2, ignore_index=255):
list_path = os.path.join(dataset_path, (mode + '_list.txt'))
self.data_list = self.__get_list(list_path)
self.mode = mode
self.data_num = len(self.data_list)
self.transforms = Compose(transforms, to_rgb=False) # 一定要设置to_rgb为False,否则这里有6个通道会报错
self.is_aug = False if len(transforms) == 0 else True
self.num_classes = num_classes # 分类数
self.ignore_index = ignore_index # 忽视的像素值
def __getitem__(self, index):
A_path, B_path, lab_path = self.data_list[index]
A_img = cv2.cvtColor(cv2.imread(A_path), cv2.COLOR_BGR2RGB)
B_img = cv2.cvtColor(cv2.imread(B_path), cv2.COLOR_BGR2RGB)
image = np.concatenate((A_img, B_img), axis=-1) # 将两个时段的数据concat在通道层
image = paddle.to_tensor(image.transpose(2, 0, 1)).astype('float32')
return image
def __len__(self):
return self.data_num
# 这个用于把list.txt读取并转为list
def __get_list(self, list_path):
data_list = []
with open(list_path, 'r') as f:
data = f.readlines()
for d in data:
data_list.append(d.replace('\n', '').split(' '))
return data_list
dataset_path = 'dataset'
# 完成测试数据的创建
transforms = [Resize([512, 512])]
test_data = MyDataset(dataset_path, 'test', transforms)
!mkdir submit
import paddle
from paddleseg.models import UNetPlusPlus,UNet3Plus
import matplotlib.pyplot as plt
model_path = 'output/unet2plus/best_model/model.pdparams' # 加载得到的最好参数
model = UNetPlusPlus(in_channels=6, num_classes=2, use_deconv=True)
# model = UNet3Plus(in_channels=6, num_classes=2)
para_state_dict = paddle.load(model_path)
model.set_dict(para_state_dict)
for idx, img in enumerate(test_data): # 从test_data来读取数据
index = test_data.data_list[idx][0].split('/')[3].split('.')[0]
m_img = img.reshape((1, 6, 512, 512))
m_pre = model(m_img)
pre_img = paddle.argmax(m_pre[0], axis=1).reshape((512, 512)).numpy()
pre_img = ((pre_img-np.min(pre_img))/(np.max(pre_img)-np.min(pre_img))*255).astype('uint8') # 转换成0-255
cv2.imwrite('submit/' + index + '.png', pre_img)
mkdir: 无法创建目录"submit": 文件已存在
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/ipykernel_launcher.py:17: RuntimeWarning: invalid value encountered in true_divide
ivide
8 结果文件生成
# 压缩当前路径所有文件,输出zip文件
path='submit'
import zipfile,os
zipName = 'submit.zip' #压缩后文件的位置及名称
f = zipfile.ZipFile( zipName, 'w', zipfile.ZIP_DEFLATED )
for dirpath, dirnames, filenames in os.walk(path):
for filename in filenames:
print(filename)
f.write(os.path.join(dirpath,filename))
f.close()
9 提分技巧

-
对数据集进行fft变换等数据增强操作,以达到较好的精度;
-
对部分超参数进行调整,寻求更好的和更合适的超参数,对模型训练起正向作用;
-
使用PaddleRS进行遥感图像变化检测模型训练,里面提供了多种可选择的变化检测模型。
参考资料
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)