
Ai绘画 PPDiffusers:支持ControlNet和LoRA,个人优化版
1. 一键体验文生图、图生图能力,新增ControlNet支持,新增Lora权重调整 2. 新增图生图批量处理,oponpose 预处理
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一、
1.第一次使用可以先看后面的模型准备,有各种模型的获取方式,包括control net 1.1的新模型
2.需要批处理的话,输入图片地址的位置直接输入文件夹地址就行了。一次处理10张以上的图片时不会展示图片,请到文件夹中查看效果。
3.需要改控件里的默认值,可以到m_ui文件夹里的config.py改
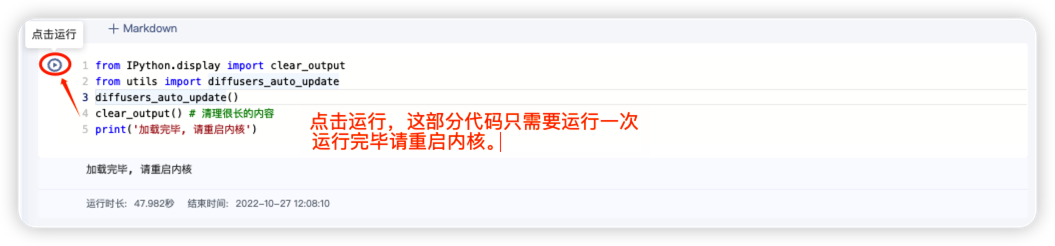
二、第一次进入本项目,运行下面的代码,并且重启内核!
进入之后,点击下边的框里左上角的“点击运行”按钮(或者点进下面的框内用快捷键 Ctrl + Enter)。
提示:下面安装环境的代码,只需要在你第一次进入本项目时运行!
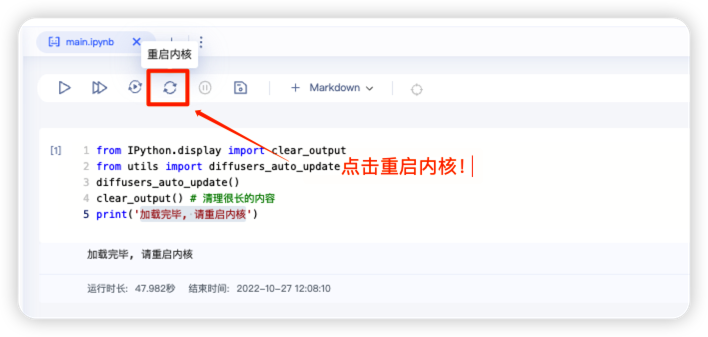
等到显示“加载完毕, 请重启内核”后,请重启内核。
# 固定为0.14.0版本,新版本会报错
# 这段代码作用是安装升级所有依赖库到最新版,一般永久只需要运行一次,然后重启内核,以后不需要运行也不需要重启.目前ppdiffusers版本为0.11.1,能正常使用,如果版本过高导致无法使用可以指定版本.
!pip install ppdiffusers==0.14.0 ppdiffusers paddlenlp safetensors OmegaConf --user
from IPython.display import clear_output
clear_output() # 清理很长的内容
print('加载完毕, 请重启内核')
加载完毕, 请重启内核
记得↑上面的代码运行后必须重启内核.
三、后面打开项目可以直接从这里开始
3.0 模型转换, 第一次使用不会的话直接点开始转换,一步到位
支持 ckpt 或者 safetensors 权重 第一次转换如果出错,再点一次就好,
我们可以使用下面的UI,在线转换pytorch的ckpt权重,当前仅支持SD-V1的权重进行转换!
转换现成的模型比下载快很多.建议第一次使用先转换一个
用过的模型缓存在这/home/aistudio/model_weights/models,尽量删除不用的模型,避免每次项目启动和保存过慢
from m_ui import gui_convert # 点开始可能没反应,多等一会就好了,千万别多点,第一次转换如果出错,再点一次就好(有时候会出错俩次)
display(gui_convert.gui)# model_weights/models
#新转化的模型要重启内核才能在下面的ui里显示,如果没有显示直接复制路径进去也行。
Box(children=(Box(children=(Text(value='/home/aistudio/data/data205964/perfectWorld_v2Baked.safetensors', desc…
模型缓存目录/home/aistudio/model_weights/models/中尽量删除不用的模型,需要时在放进去,避免项目保存加载太慢
3.1 文生图UI使用 支持ControlNet和多LoRA融合保存调整权重
如果你没准备模型,请先用上面的转换模型,点开始转换,会得到一个现成的,如果你转换了其它模型,需要在模型名称那里填写正确的路径
注意:lora权重只能在界面上调整,sd的那种特殊格式提示词没有效果,当然会触发lora的正常提示词是有效的,
保存模型复选框勾上后点击生成图片一次会保存融合lora到文件夹/home/aistudio/model_weights/LoRA,你的所有lora文件也只能放在这里才能被识别,不要lora尽量删除,
多个ControlNet模型同时使用的思路可以看这里,希望有大佬能把这功能移植过来.https://github.com/haofanwang/ControlNet-for-Diffusers
from m_ui import gui_txt2img # 文生图支持ControlNet和LoRA,希望有大佬能研究下怎么同时用多个ControlNet模型
display(gui_txt2img.gui) # 生成的图片自动保存到左侧的 data/txt2img 的文件夹里
# 更新了新的模型后需要重新执行本块代码绘制ui,如果没出来可以重启内核下。
# 引导图支持目录或者文件,输入的是目录会挨个切换引导图,前提是你生成多张图片的情况下.
# openpose、canny引导图支持预处理,如果你放的是预处理好的图,请取消预处理复选框
Box(children=(HTML(value='<style>\n@media (max-width:576px) {\n .StableDiffusionUI_txt2img88D1 {\n m…
3.2 图生图UI使用 支持ControlNet和LoRA
3月27更新:
- 优化了一下界面,参数面板增加了 生成数量 输入图片路径 和 ControlNet 权重设定,没仔细研究代码,现在不清楚这个参数到底是不是控制权重的
- 现在引导图路径可以设定为目录,例如设定成这样:/home/aistudio/RES/depts ,在这个目录内放多个文件的情况下图生图和文生图会挨个切换引导图
- 支持多lora融合保存,以及权重调节,lora:xxx:0.5这种提示词不会生效,请直接在界面调整LoRA权重.
- 增加canny引导图预处理功能,canny引导图用正常图片,然后勾选预处理复选框.
注意,这笔记本输出内容范围太窄,为获得良好体验你可以右键图生图ui选择为输出创建新视图然后把它拖到main.ipynb旁边的标签上
或者shift加右键选择审查元素,在控制台输入一下命令可以增加输出内容高度
a = document.getElementsByClassName("lm-Widget p-Widget jp-OutputArea jp-Cell-outputArea");
a[3].style.maxHeight = '3200px'
a[4].style.maxHeight = '2000px'
from m_ui import gui_img2img # 图生图
display(gui_img2img.gui) # 生成的图片自动保存到左侧的 data/txt2img 的文件夹里
# ControlNet模型路径可用这三个: lllyasviel/sd-controlnet-canny lllyasviel/sd-controlnet-openpose lllyasviel/sd-controlnet-dept
# lora 文件放到 outputs/lora目录中,下载了新lora后需要重启内核,
# 引导图可用目录或者文件名,canny引导图支持预处理,
Box(children=(HTML(value="<style>\n@media (max-width:576px) {\n .StableDiffusionUI_img2img0AB9 {\n m…
3.3 超分UI使用
from m_ui import gui_superres # 超分 (图片放大一倍), 在左侧“文件”目录上传图片, 然后修改 "需要超分的图片路径"
display(gui_superres.gui) # 生成的图片自动保存到左侧的 /home/aistudio/data/highres 的文件夹里
Box(children=(Text(value='resources/image_Kurisu.png', description='需要超分的图片路径', layout=Layout(align_items='cen…
3.4 定制化训练(让模型认识新的物体或学习到新的风格)
除了直接调用外,PaddleNLP还提供好用的二次开发能力,可以参照下方或PaddleNLP仓库的教程,只需要几张图片,就可以定制属于自己的文图生成模型。
text_inversion 训练
在下面GIF例子中,我们进行了如下操作,更多信息可进入PaddleNLP examples中查看更多例子。
(1) 输入了代表该人物的新单词:<Alice>,新词用<>括起来,主要是为了避免与已有的单词混淆;
(2) 指定了与该人物比较接近的单词:girl, 该单词作为先验(已知)知识,可以帮助模型快速理解新单词,从而加快模型训练;
(3) 提供了含有下面6张图片的文件夹地址:resources/Alices,在这里我们指定了resources目录下的Alices文件夹。

from m_ui import gui_train_text_inversion # 训练
display(gui_train_text_inversion.gui) # 训练结果会保存到 outputs/textual_inversion 的文件夹
Box(children=(Box(children=(Dropdown(description='训练目标', description_tooltip='训练目标是什么?风格还是实体?', index=1, layou…
模型训练完成之后,可以使用新模型预测了!
现在模型已经认识 <Alice> 这个object(人物、物体,everything…)了。
比如输入Prompt:<Alice> at the lake,就可以生成一张站在湖边的 <Alice> 图像了。
Dreambooth 训练
下面是Dreambooth训练部分
可以参考 https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/examples/dreambooth 配置下面的选项
from m_ui import gui_dreambooth #训练dreambooth
#开启将同类图片加入训练(with_prior_prior_preservation)=训练物体,关闭=训练画风
display(gui_dreambooth.gui)
Box(children=(Box(children=(Combobox(value='/home/aistudio/data/model_weights/models/mixProV3_v3', description…
可以把/home/aistudio/m_ui/config.py里的临时路径改到模型输出的路径下,就可以很方便的选择训练出的模型进行使用
四、第一次使用需要先准备好你要用的模型
模型下载网站 https://civitai.com ,https://huggingface.co
4.1基本模型
1.ppdiffusers可直接使用的模型列表
把名字复制到模型路径即可 不存在的时候会自动下载
Linaqruf/anything-v3.0
MoososCap/NOVEL-MODEL
Baitian/momocha
Baitian/momoco
hequanshaguo/monoko-e
ruisi/anything
hakurei/waifu-diffusion-v1-3
CompVis/stable-diffusion-v1-4
runwayml/stable-diffusion-v1-5
stabilityai/stable-diffusion-2
stabilityai/stable-diffusion-2-base
hakurei/waifu-diffusion
naclbit/trinart_stable_diffusion_v2_60k
naclbit/trinart_stable_diffusion_v2_95k
naclbit/trinart_stable_diffusion_v2_115k
ringhyacinth/nail-set-diffuser
Deltaadams/Hentai-Diffusion
BAAI/AltDiffusion
BAAI/AltDiffusion-m9
IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-v0.1
IDEA-CCNL/Taiyi-Stable-Diffusion-1B-Chinese-EN-v0.1
huawei-noah/Wukong-Huahua
2.自己从模型网站上下载,然后上传到数据集,修改项目的数据集后通过上面模型转化功能转化完成即可使用
3.直接使用本项目挂载的数据集里的模型,模型转化里直接点开始就行了,前提是你没有修改数据集
4.2 ControlNet模型
推理和训练方法 请看官方github
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/examples/controlnet
ControlNet作者仓库 https://github.com/lllyasviel/ControlNet
ControlNet作者huggingface空间,预训练模型都在这
https://huggingface.co/lllyasviel
1.可以直接使用的controlnet模型,把名字复制到模型路径即可,不存在的时候会自动下载
lllyasviel/sd-controlnet-canny
lllyasviel/sd-controlnet-openpose
这两个直接复制到模型名称就可以用
2.从ControlNet作者huggingface空间下载,然后将模型格式转换成 pdparams格式
模型转换方法:官方提供了转换脚本,你需要要本地机器或者支持torch的机器上运行脚本
用法https://github.com/PaddlePaddle/PaddleNLP/tree/develop/ppdiffusers/scripts/convert_diffusers_model
%cd PaddleNLP/ppdiffusers/scripts/convert_diffusers_model/
!python convert_diffusers_controlnet_to_ppdiffusers.py --pretrained_model_name_or_path 这里填模型目录需要包含bin和json两个文件 --output_path 这里填输出目录
3.转化好的模型下载
我转了几个1.1新模型
https://huggingface.co/privateteam/ppmodel/tree/main
旧的深度检测的模型,可以在这里下载
https://huggingface.co/blueskyfff/sd-controlnet-depth
下载后将.pdparams格式的文件改名为 model_state.pdparams 然后把它和config.json放在同一个文件夹内,上传到数据集,运行下面的代码复制到你要的路径下
需要注意sd-controlnet-depth是包含model_state.pdparams和config.json这两个文件的文件夹,这两个文件名不对的话好像无法正确加载.
下载之后需要先上传到数据集,然后运行下面代码复制到存放模型的路径下
# 示例 复制sd-controlnet-depth模型到持久缓存目录,路径改成自己的路径
%mkdir -p /home/aistudio/model_weights/models/lllyasviel/sd-controlnet-depth/
!cp /home/aistudio/data/data198060/sd-controlnet-depth.pdparams /home/aistudio/model_weights/models/lllyasviel/sd-controlnet-depth/model_state.pdparams
!cp /home/aistudio/data/data198060/config.json /home/aistudio/model_weights/models/lllyasviel/sd-controlnet-depth/config.json
cp: 无法获取'/home/aistudio/data/data198060/sd-controlnet-depth.pdparams' 的文件状态(stat): 没有那个文件或目录
cp: 无法获取'/home/aistudio/data/data198060/config.json' 的文件状态(stat): 没有那个文件或目录
4.3 LoRA模型
1.从模型网站上下载,然后直接上传文件到rola模型目录/home/aistudio/model_weights/LoRA下,很方便
2.下面是前人留下的下载代码,我没试过
# LoRA下载,下载后需要重启内核才会更新lora列表
url = '这里替换成lora文件的下载地址'
!cd /home/aistudio/outputs/lora;curl -OJL -k --tlsv1 $url
/bin/bash: 第 0 行: cd: /home/aistudio/outputs/lora: 没有那个文件或目录
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1169 100 1169 0 0 226 0 0:00:05 0:00:05 --:--:-- 248
1 319M 1 6206k 0 0 47047 0 1:58:34 0:02:15 1:56:19 17857 0:01:36 1:36:08 13724
五、历史更新
4月30
改了排版,加了一些资源
4月23
1.新增了图生图批处理功能,输入图片地址的位置直接输入文件夹地址就行了。一次处理10张以上的图片时不会展示图片,请到文件夹中查看效果。
2.controlnet模型输入改为下拉选框,能自动读取/home/aistudio/model_weights/models/lllyasviel/下的目录,如果下载了controlnet模型请放到这个目录下,预处理功能增加了openpose,原来的代码openpose_body_estimation模型在ui的代码内运行会出错的原因我猜测是加载模型后占用了资源,所以把预处理图片放在加载模型前执行就没问题了。基本模型也能自动读取已经存在的模型名。
3.修改了之前在没有使用controlnet的情况下,引导图不存在会报错的bug
3.修改了原来Rola从有模型名调整至五个空模型名时,rola 效果不会消失的bug
3.图片默认输出的位置改到data下了,记得保存喜欢的图,不然会消失。
4.保留了原来的代码,放在ui文件夹下,我自己改的部分放在m_ui文件夹,因为没改模型训练的部分,这部分用的还是之前的代码,所以两个文件夹都不要删
其实我完全不懂python ,感谢朋友当我的技术顾问,感谢chat GPT.
以下来自w碧海蓝天w
项目地址[https://aistudio.baidu.com/aistudio/projectdetail/5803979]
本人水平有限,刚熬夜看了下ppdiffusers的部分代码.
勉强把ControlNet的功能整合到了UI中,现在文图生图UI中都可以使用啦,
但可能存在bug,功能也还不完善,希望有大佬能改进下
3月29更新
- 增加同时使用多个LoRA的功能,权重可以直接在界面上调整单个权重和合并到大模型的整体权重,注意:用lora:xxxx:0.x这种格式的提示词是没效果的,权重只能在界面上调整,因为我觉得提示词改权重太麻烦,
- 当你使用多个lora并且调整权重融合出了满意的效果后可以勾选上保存模型复选框,然后点击一次生成图片,他会保存当前融合后的新模型到/home/aistudio/model_weights/LoRA,注意及时清理无用模型避免占用空间.保存后需要取消这个复选框,不然会重复保存无法生成图片.
- canny支持预处理功能了,用的opencv简单实现的,效果可能不是最好的,感谢这个项目作者提供思路https://aistudio.baidu.com/aistudio/projectdetail/2490960?channelType=0&channel=0 有兴趣的也可以去学习下,里面有多种方法,
- 增加了openpose骨架图预测功能,openpose_body_estimation模型在ui的代码内运行会出错不知道啥原因,暂时放在后面的代码里,如果你要转换骨骼图,可以在后面的代码找到运行处理.
- 暂时没有禁用ControlNet的功能,ControlNet权重拉到0虽然不会生效但是也会加载模型,另外引导图一定要存在,如果不存在会报错,因为影响不大,懒得改代码了.
3月27更新优化了下界面,加了点设置,修复了模型切换的问题.把ctrl权重拉到0可以关掉ControlNet的效果.
但我不确定/home/aistudio/ui/pipeline_stable_diffusion_all_in_one.py中关于ControlNet的代码部分是否正确,
官方好像只转换了Canny 和pose的模型,我转换了另一个实用性比较高的depth模型可在这里下载https://huggingface.co/blueskyfff/sd-controlnet-depth
另外还有多个模型同时使用的思路可以看这里,希望有大佬能把这功能移植过来.
https://github.com/haofanwang/ControlNet-for-Diffusers
一个好用的在线pose编辑工具
https://github.com/ZhUyU1997/open-pose-editor
感谢 @风飏 开发者开发的UI界面!
感谢所有对这个项目改进的大佬,
六、参考资料
- https://github.com/PaddlePaddle/PaddleNLP
- https://github.com/lllyasviel/ControlNet
- https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
- https://github.com/huggingface/diffusers
- https://github.com/CompVis/stable-diffusion
- https://arxiv.org/pdf/2006.11239.pdf
- https://arxiv.org/pdf/2208.01618.pdf
- https://huggingface.co/runwayml/stable-diffusion-v1-5 (请注意里面使用的LICENSE)
- https://aistudio.baidu.com/aistudio/projectdetail/2490960?channelType=0&channel=0 边缘检测
- https://aistudio.baidu.com/aistudio/projectdetail/1421950?channelType=0&channel=0 姿势检测
- https://aistudio.baidu.com/aistudio/projectdetail/5540885?channelType=0&channel=0 多lora
- https://aistudio.baidu.com/aistudio/projectdetail/5737077?channelType=0&channel=0 多lora融合保存
七、鸣谢
感谢 @风飏 开发者开发的UI界面!这个界面真的太好用啦!!!
感谢开发ControlNet的大佬 https://github.com/lllyasviel/ControlNet
感谢官方PaddleNLP所有贡献者 https://github.com/PaddlePaddle/PaddleNLP
感谢 Online 3D Openpose Editor作者 https://github.com/ZhUyU1997/open-pose-editor
原始项目大概是这个官方发的 @飞桨PaddleNLP https://aistudio.baidu.com/aistudio/projectdetail/4905623?channelType=0&channel=0
目前这个项目的改进fork自 @天堂进制 https://aistudio.baidu.com/aistudio/projectdetail/5800945?channelType=0&channel=0
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)