
基于掩蔽生成知识蒸馏(MGD)的钢铁表面缺陷检测
MGD是ECCV 2022关于知识蒸馏的论文: Masked Generative Distillation所提出的方法,本项目实现了该方法并在NEU-DET数据集上进行了测试。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
本项目首先对模型压缩领域中的知识蒸馏理论做了简单的介绍,然后基于PaddleDetection套件对目标检测知识蒸馏的最新方法(MGD)进行复现,对目标检测知识蒸馏的流程进行了细致的讲解。最后结果表明该方法具有较好的效果,可以明显提高学生模型的精度,甚至超越了教师模型。
| 模型 | mAP(IOU=0.5:0.95) | AP(S) | AP(M) | AP(L) |
|---|---|---|---|---|
| teacher(retinanet-r101) | 41.3 | 45.1 | 33.1 | 56.5 |
| student(retinanet-r50) | 40.0 | 34.9 | 33.1 | 44.1 |
| distill(retinanet-r50+MGD) | 41.5(+1.5) | 46.2(+11.3) | 34.0(+0.9) | 50.1(+6.0) |
如表格所示,蒸馏后涨点效果明显,大家可以按照本项目的流程对自己的数据集进行蒸馏训练。
一.项目背景
深度卷积神经网络以其突出的性能被广泛应用在目标检测任务上,然而庞大的模型参数和沉重的计算负担严重限制目标检测算法在移动机器人、车载摄像头等边缘设备上的应用,尤其在实时性要求较高的工业领域,过于复杂的模型必然会带来推理延时高的问题。随着深度学习技术的发展,采用知识蒸馏技术对模型进行压缩,可以实现知识迁移与网络精简。在人工智能逐步从理论研究走向大规模应用的背景下,如何利用知识蒸馏进行有效模型压缩已成为倍受关注且具有挑战性的研究热点。
1.1 基于logits的知识蒸馏
知识蒸馏最早是针对分类任务提出并广泛应用的,该方法以较小的精度损失为代价,将较大的教师模型的知识传递给较小的学生模型。2014年,Hinton等人首次提出基于logits的蒸馏方法,该论文给出了知识蒸馏的明确定义,即——将大模型或集成模型中的“暗知识”通过蒸馏的方式,迁移到小模型中,以达到缩小模型或提高精确度的目的。
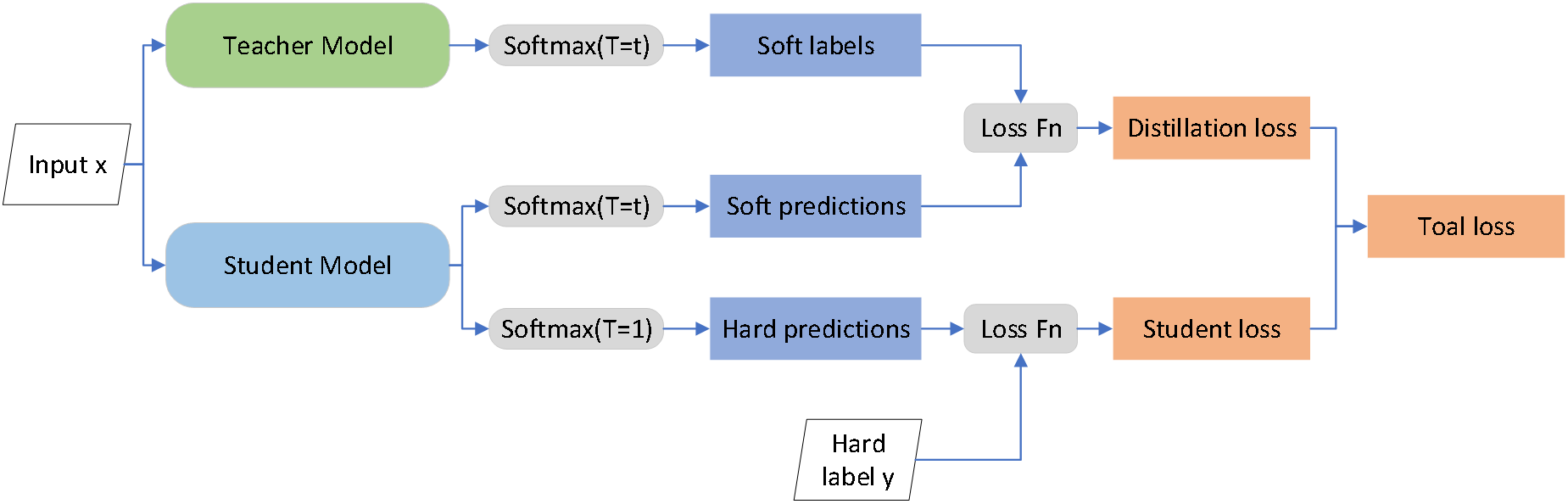
1.2 基于特征的知识蒸馏
当把知识蒸馏直接应用于目标检测任务上时,目标区域的差异性会被淹没在过多的非目标区域中(背景),使得优化目标被掩盖,模型难以收敛,传统知识蒸馏方法不再行之有效。于是目前在目标检测上主要使用的是基于特征匹配的知识蒸馏,即别提取教师和学生网络Backbone或neck层的特征图,让学生模型模仿教师模型的特征图,从而优化学生模型的表现。
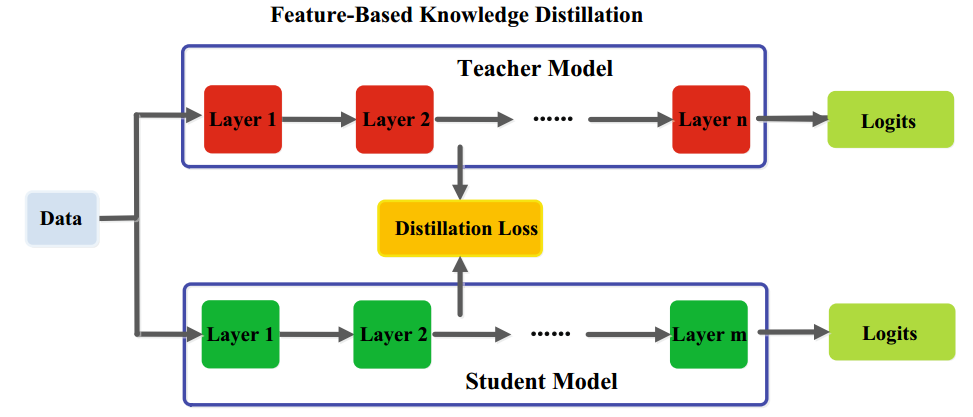
1.3 掩蔽生成知识蒸馏(Masked Generative Distillation)
MGD是ECCV 2022关于知识蒸馏的论文: Masked Generative Distillation所提出的方法,方法适用于分类,检测与分割任务。作者认为提升学生的表征能力并不一定需要通过直接模仿教师实现。从这点出发,把模仿任务修改成了生成任务:让学生凭借自己较弱的特征去生成教师较强的特征。在蒸馏过程中,对学生特征进行了随机mask,强制学生仅用自己的部分特征去生成教师的所有特征,以提升学生的表征能力。整体架构如下图所示:
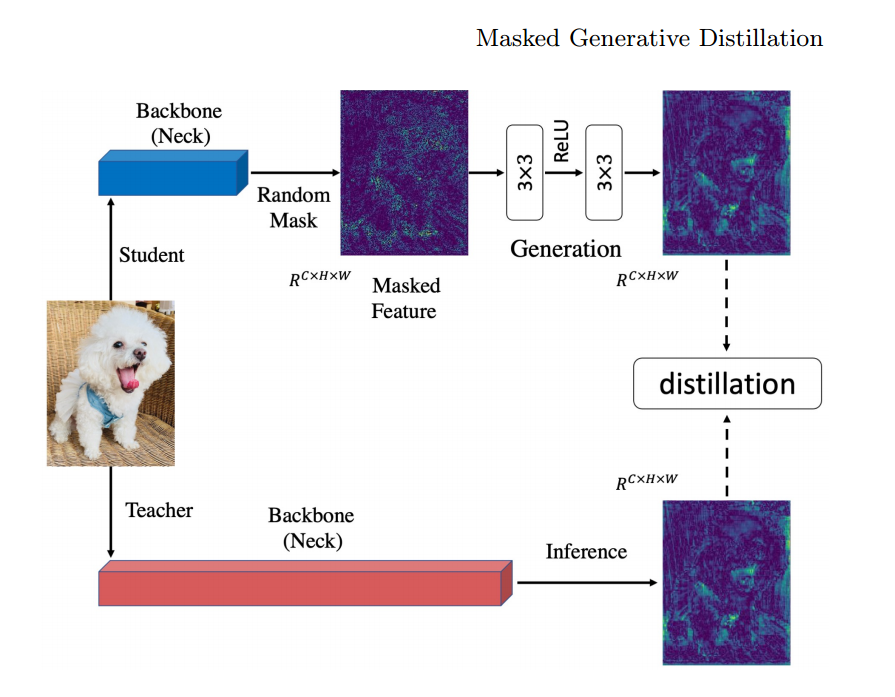
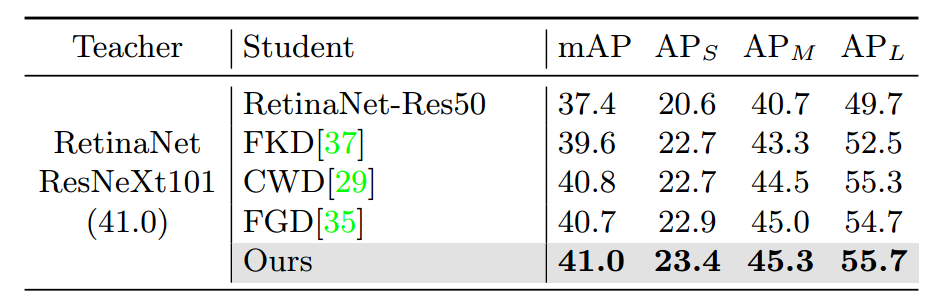
论文在COCO2017上使用RetinaNet(ResNeXt101)蒸馏RetinaNet(Res50)的结果如下:
二. 数据集介绍
原论文使用的是COCO2017数据集,由于算力成本以及时间限制,本项目使用的是由东北大学(NEU)发布的钢铁表面缺陷数据集,收集了热轧钢带的六种典型表面缺陷,即轧制氧化皮(RS),斑块(Pa),开裂(Cr),点蚀表面( PS),内含物(In)和划痕(Sc),每种缺陷类别300张。下图为六种典型表面缺陷的示例,每幅图像的分辨率为200 * 200像素,本项目中挂载的数据集已按照7:2:1的比例划分好。

三. 算法实现
得益于PaddleDetection的模块化设计,本项目实现了MGD算法。在PaddleDetection/ppdet/slim/distill.py中创建MGDDistillModel类和MGDFeatureLoss类,目前仅支持retinanet模型之间进行蒸馏。
class MGDDistillModel(nn.Layer):
"""
Build MGD distill model.
Args:
cfg: The student config.
slim_cfg: The teacher and distill config.
"""
def __init__(self, cfg, slim_cfg):
super(MGDDistillModel, self).__init__()
self.is_inherit = True
# build student model before load slim config
self.student_model = create(cfg.architecture)
self.arch = cfg.architecture
stu_pretrain = cfg['pretrain_weights']
slim_cfg = load_config(slim_cfg)
self.teacher_cfg = slim_cfg
self.loss_cfg = slim_cfg
tea_pretrain = cfg['pretrain_weights']
self.teacher_model = create(self.teacher_cfg.architecture)
self.teacher_model.eval()
for param in self.teacher_model.parameters():
param.trainable = False
if 'pretrain_weights' in cfg and stu_pretrain:
if self.is_inherit and 'pretrain_weights' in self.teacher_cfg and self.teacher_cfg.pretrain_weights:
load_pretrain_weight(self.student_model,
self.teacher_cfg.pretrain_weights)
logger.debug(
"Inheriting! loading teacher weights to student model!")
load_pretrain_weight(self.student_model, stu_pretrain)
if 'pretrain_weights' in self.teacher_cfg and self.teacher_cfg.pretrain_weights:
load_pretrain_weight(self.teacher_model,
self.teacher_cfg.pretrain_weights)
self.mgd_loss_dic = self.build_loss(
self.loss_cfg.distill_loss,
name_list=self.loss_cfg['distill_loss_name'])
def build_loss(self,
cfg,
name_list=[
'neck_f_4', 'neck_f_3', 'neck_f_2', 'neck_f_1',
'neck_f_0'
]):
loss_func = dict()
for idx, k in enumerate(name_list):
loss_func[k] = create(cfg)
return loss_func
def forward(self, inputs):
if self.training:
s_body_feats = self.student_model.backbone(inputs)
s_neck_feats = self.student_model.neck(s_body_feats)
with paddle.no_grad():
t_body_feats = self.teacher_model.backbone(inputs)
t_neck_feats = self.teacher_model.neck(t_body_feats)
loss_dict = {}
for idx, k in enumerate(self.mgd_loss_dic):
loss_dict[k] = self.mgd_loss_dic[k](s_neck_feats[idx],
t_neck_feats[idx])
if self.arch == "RetinaNet":
loss = self.student_model.head(s_neck_feats, inputs)
elif self.arch == "PicoDet":
head_outs = self.student_model.head(
s_neck_feats, self.student_model.export_post_process)
loss_gfl = self.student_model.head.get_loss(head_outs, inputs)
total_loss = paddle.add_n(list(loss_gfl.values()))
loss = {}
loss.update(loss_gfl)
loss.update({'loss': total_loss})
else:
raise ValueError(f"Unsupported model {self.arch}")
for k in loss_dict:
loss['loss'] += loss_dict[k]
loss[k] = loss_dict[k]
return loss
else:
body_feats = self.student_model.backbone(inputs)
neck_feats = self.student_model.neck(body_feats)
head_outs = self.student_model.head(neck_feats)
if self.arch == "RetinaNet":
bbox, bbox_num = self.student_model.head.post_process(
head_outs, inputs['im_shape'], inputs['scale_factor'])
return {'bbox': bbox, 'bbox_num': bbox_num}
elif self.arch == "PicoDet":
head_outs = self.student_model.head(
neck_feats, self.student_model.export_post_process)
scale_factor = inputs['scale_factor']
bboxes, bbox_num = self.student_model.head.post_process(
head_outs,
scale_factor,
export_nms=self.student_model.export_nms)
return {'bbox': bboxes, 'bbox_num': bbox_num}
else:
raise ValueError(f"Unsupported model {self.arch}")
@register
class MGDFeatureLoss(nn.Layer):
"""Paddle version of `Masked Generative Distillation`
Args:
student_channels(int): Number of channels in the student's feature map.
teacher_channels(int): Number of channels in the teacher's feature map.
name (str): the loss name of the layer
alpha_mgd (float, optional): Weight of dis_loss. Defaults to 0.00002
lambda_mgd (float, optional): masked ratio. Defaults to 0.65
"""
def __init__(self,
student_channels=256,
teacher_channels=256,
alpha_mgd=0.00002,
lambda_mgd=0.65,
):
super(MGDFeatureLoss, self).__init__()
self.alpha_mgd = alpha_mgd
self.lambda_mgd = lambda_mgd
if student_channels != teacher_channels:
self.align = nn.Conv2D(
student_channels,
teacher_channels,
kernel_size=1,
stride=1,
padding=0)
student_channels = teacher_channels
else:
self.align = None
self.generation = nn.Sequential(
nn.Conv2D(teacher_channels, teacher_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2D(teacher_channels, teacher_channels, kernel_size=3, padding=1))
def forward(self,
preds_S,
preds_T):
"""Forward function.
Args:
preds_S(Tensor): Bs*C*H*W, student's feature map
preds_T(Tensor): Bs*C*H*W, teacher's feature map
"""
assert preds_S.shape[-2:] == preds_T.shape[-2:]
if self.align is not None:
preds_S = self.align(preds_S)
loss = self.get_dis_loss(preds_S, preds_T)*self.alpha_mgd
return loss
def get_dis_loss(self, preds_S, preds_T):
N, C, H, W = preds_T.shape
mat = paddle.rand((N,1,H,W))
mat = paddle.where(mat>1-self.lambda_mgd, 0, 1)
mat=paddle.cast(mat,'float32')
masked_fea = paddle.multiply(preds_S, mat)
new_fea = self.generation(masked_fea)
dis_loss = F.mse_loss(new_fea, preds_T,reduction="sum")/N
return dis_loss
此外,还需要在slim文件夹下的_init_.py中作如下修改,以通过配置文件来创建蒸馏模型。
if slim_load_cfg['slim'] == 'Distill':
if "slim_method" in slim_load_cfg and slim_load_cfg[
'slim_method'] == "FGD":
model = FGDDistillModel(cfg, slim_cfg)
elif "slim_method" in slim_load_cfg and slim_load_cfg[
'slim_method'] == "MGD":
model = MGDDistillModel(cfg, slim_cfg)
四. 环境配置
4.1 解压数据集
!tar -zxvf /home/aistudio/data/data218435/NEU-DET-COCO.tar.gz -C /home/aistudio/data/
4.2 下载PaddleDetection并安装依赖项
从github拉取PaddleDetection,或者在左侧的套件管理中直接快速下载PaddleDetection-2.5,下载完毕需要重命名文件夹为PaddleDetection。
!git clone -b release/2.5 https://github.com/PaddlePaddle/PaddleDetection.git
将下列文件拷贝到PaddleDetection中
!cp -r work/demo work/output work/ppdet PaddleDetection/
%cd PaddleDetection
!pip install -r requirements.txt
4.3 从源码编译安装PaddleDetection
后续若对源码进行改动,务必再次执行下列命令重新编译
!python setup.py install
五. 开始训练
5.1和5.2主要内容是训练教师模型和学生模型,若已有训练好的模型,可直接跳到5.3开始蒸馏训练
5.1 训练教师模型
这里选择的是retinanet_r101_fpn作为教师模型,训练时通过加载PaddleDetection官方在coco上训练好的模型作为预训练模型,再微调训练三十几个epoch即可达到收敛。按照如下图所示修改retinanet_r101_fpn_2x_coco.yml配置文件,为方便操作,本项目把所有需要用到的配置文件全都放到了根目录中,后续修改好所需的文件后,通过命令一键导入所有配置到相应位置
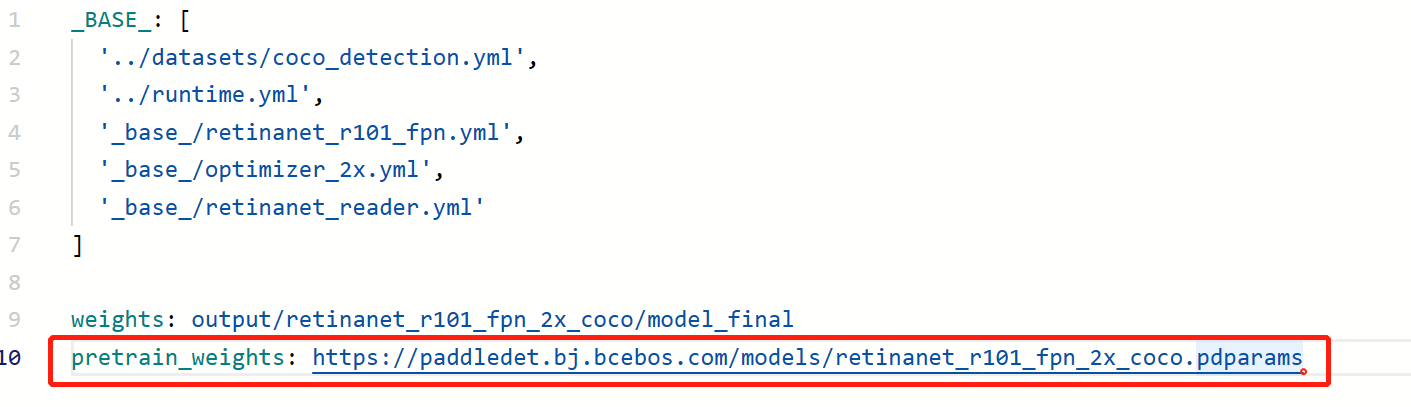
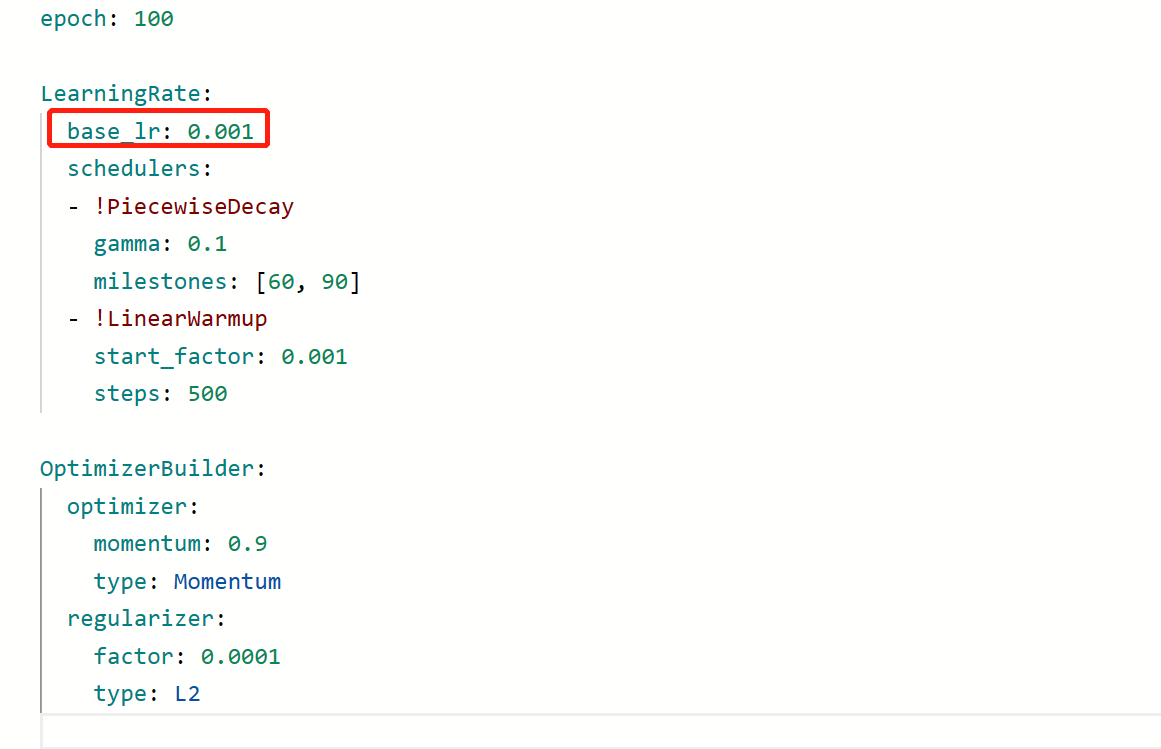
导入coco预训练模型后,需在optimizer_2x.yml配置文件中降低学习率,这里把原本的0.01降低了10倍
其余的配置文件按照自己需要修改即可,修改完毕使用下面的命令一键导入
!cp ../runtime.yml configs/runtime.yml
!cp ../coco_detection.yml configs/datasets/coco_detection.yml
!cp ../retinanet_r101_fpn.yml configs/retinanet/_base_/retinanet_r101_fpn.yml
!cp ../optimizer_2x.yml configs/retinanet/_base_/optimizer_2x.yml
!cp ../retinanet_reader.yml configs/retinanet/_base_/retinanet_reader.yml
!cp ../retinanet_r101_fpn_2x_coco.yml configs/retinanet/retinanet_r101_fpn_2x_coco.yml
执行下面的命令开始训练
!python tools/train.py -c configs/retinanet/retinanet_r101_fpn_2x_coco.yml --use_vdl=True --vdl_log_dir=./teacher/retinanet_r101/ --eval
我训练的教师模型验证集mAP最高为0.413

5.2 训练学生模型
单独训练学生模型的目的是为了与蒸馏训练后的模型进行对比,与训练教师模型类似,加载预训练模型和修改学习率,这里不再赘述
导入配置文件
!cp ../runtime.yml configs/runtime.yml
!cp ../coco_detection.yml configs/datasets/coco_detection.yml
!cp ../retinanet_r50_fpn.yml configs/retinanet/_base_/retinanet_r50_fpn.yml
!cp ../optimizer_2x.yml configs/retinanet/_base_/optimizer_2x.yml
!cp ../retinanet_reader.yml configs/retinanet/_base_/retinanet_reader.yml
!cp ../retinanet_r50_fpn_2x_coco.yml configs/retinanet/retinanet_r50_fpn_2x_coco.yml
开始训练
!python tools/train.py -c configs/retinanet/retinanet_r50_fpn_2x_coco.yml --use_vdl=True --vdl_log_dir=./student/retinanet_r50/ --eval
训练的学生模型验证集mAP最高为0.40

5.3 蒸馏训练
修改蒸馏的配置文件retinanet_resnet101_coco_mgd_distill.yml,pretrain_weights路径选择训练好的教师模型路径
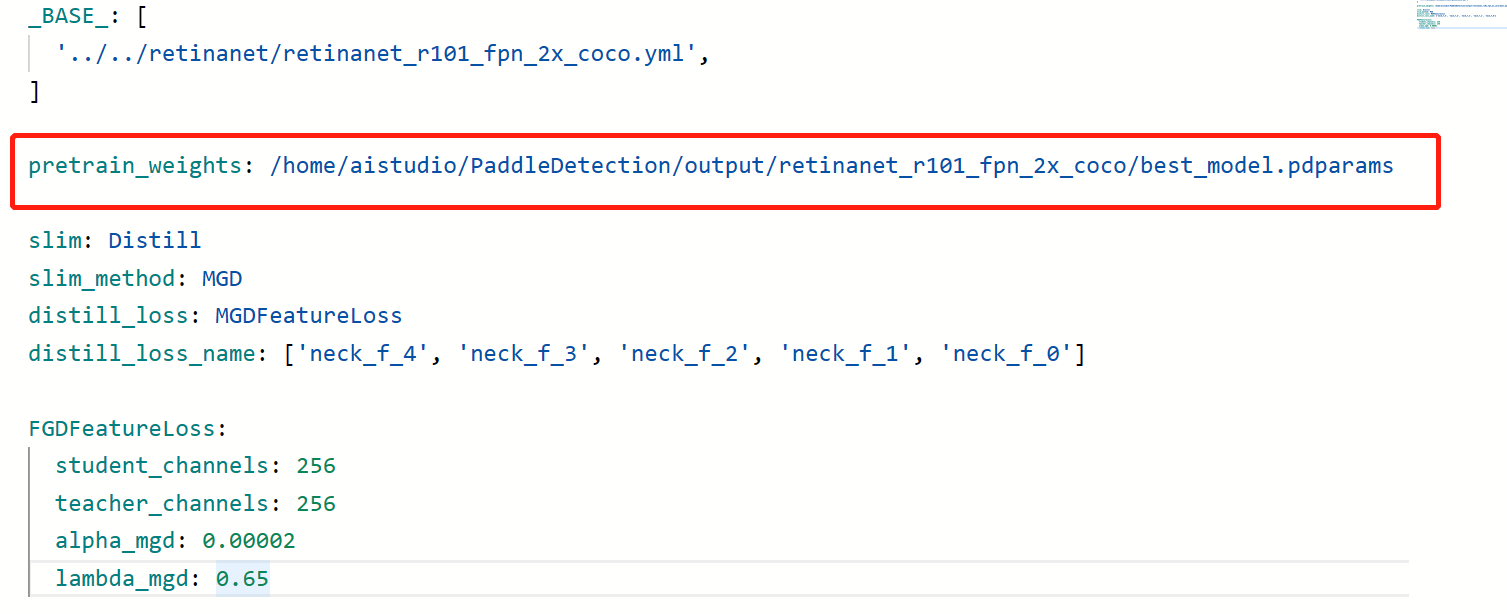
导入配置文件
!cp ../runtime.yml configs/runtime.yml
!cp ../coco_detection.yml configs/datasets/coco_detection.yml
!cp ../retinanet_r50_fpn.yml configs/retinanet/_base_/retinanet_r50_fpn.yml
!cp ../optimizer_2x.yml configs/retinanet/_base_/optimizer_2x.yml
!cp ../retinanet_reader.yml configs/retinanet/_base_/retinanet_reader.yml
!cp ../retinanet_r50_fpn_2x_coco.yml configs/retinanet/retinanet_r50_fpn_2x_coco.yml
!cp ../retinanet_resnet101_coco_mgd_distill.yml configs/slim/distill/retinanet_resnet101_coco_mgd_distill.yml
单卡训练
!python tools/train.py -c configs/retinanet/retinanet_r50_fpn_2x_coco.yml --slim_config configs/slim/distill/retinanet_resnet101_coco_mgd_distill.yml \
--use_vdl=True --vdl_log_dir=./distill/retinanet_r50/ --eval
多卡训练时需要注意batch_size的大小,将retinanet_reader.yml中的batch_size修改为2,这样四卡总的batch_size还是8

!python -m paddle.distributed.launch --log_dir=logs/ --gpus 0,1,2,3 tools/train.py -c configs/retinanet/retinanet_r50_fpn_2x_coco.yml --slim_config configs/slim/distill/retinanet_resnet101_coco_mgd_distill.yml \
--use_vdl=True --vdl_log_dir=./distill/retinanet_r50/ --eval
使用MGD方法进行蒸馏训练后的模型结果,可以看出各项指标都有明显提升

5.4 模型评估
!python tools/eval.py -c configs/retinanet/retinanet_r50_fpn_2x_coco.yml -o weights=output/retinanet_resnet101_coco_mgd_distill/best_model.pdparams
5.5 推理预测
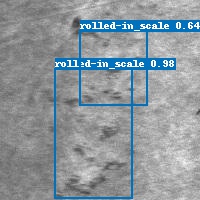
!python tools/infer.py -c configs/retinanet/retinanet_r50_fpn_2x_coco.yml -o weights=output/retinanet_resnet101_coco_mgd_distill/best_model.pdparams --infer_img=demo/patches_237.jpg
从测试集中选取了几张图片,预测结果如下,可以看出效果还是不错的




六. 总结
本项目对模型压缩领域中的知识蒸馏做了简单的介绍,并基于PaddleDetection套件对目标检测知识蒸馏的最新方法(MGD)进行复现,结果表明该方法具有较好的效果,可以明显提高学生模型的精度,甚至超越了教师模型,尤其是对小目标的检测提升较大。使用较小的模型却能获得接近甚至超越更复杂模型的性能,这就是知识蒸馏的意义所在。
| 模型 | mAP(IOU=0.5:0.95) | AP(S) | AP(M) | AP(L) |
|---|---|---|---|---|
| teacher(retinanet-r101) | 41.3 | 45.1 | 33.1 | 56.5 |
| student(retinanet-r50) | 40.0 | 34.9 | 33.1 | 44.1 |
| distill(retinanet-r50+MGD) | 41.5(+1.5) | 46.2(+11.3) | 34.0(+0.9) | 50.1(+6.0) |
后续工作:
- 目前仅支持retinanet,考虑增加适配更多模型,如PPYOLOE。
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)