
【科普&实践】超详细!一文带你玩转深度学习
了解深度学习是什么,有哪些应用,建立起对深度学习概念的立体认识,最后介绍了深度学习系统的基本构成和深度学习的一般过程。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
1. 什么是深度学习?
深度学习是机器学习领域中一个新的研究方向,它被引入机器学习使其更接近于人工智能。
- 深度学习是机器学习领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能。 深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
- 深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
1.1 人工智能、机器学习和深度学习的关系
人工智能是一个最宽泛的概念,是一个研究领域,同时也是一个实现目标,而机器学习则是实现这一目标的一类方法。深度学习只是机器学习这一类方法中的一种。
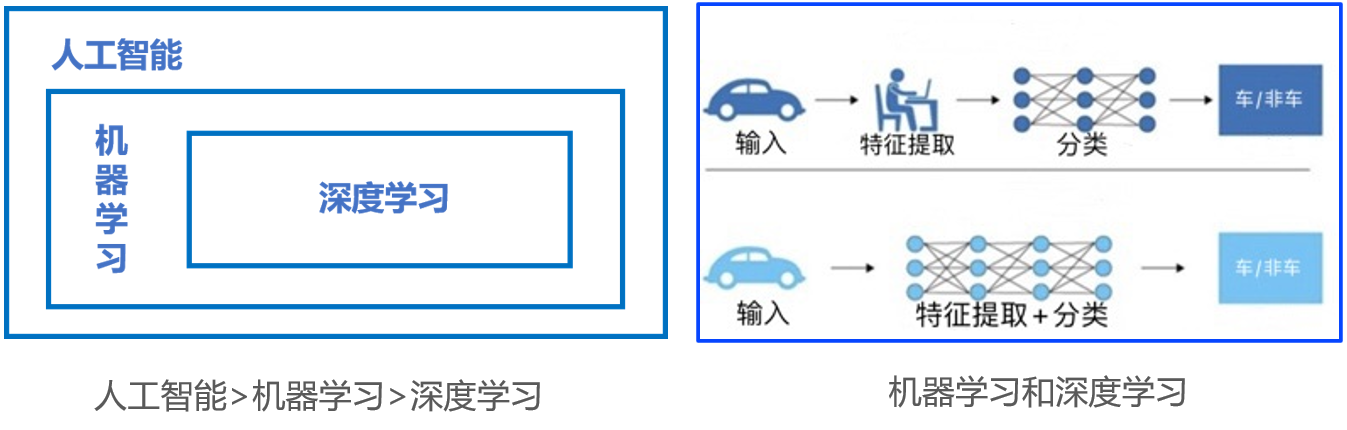
- 进一步说,由于人工智能这个最宽泛的概念只阐述了目标,而没有限定方法,因此实现人工智能存在的诸多方法和分支。机器学习是当前比较有效的一种实现人工智能的方式。深度学习是机器学习算法中最热门的一个分支,近些年取得了显著的进展,并替代了大多数传统机器学习算法。
- 如上图所示,传统机器学习算术依赖人工设计特征,并进行特征提取,而深度学习方法不需要人工,而是依赖算法自动提取特征。深度学习模仿人类大脑的运行方式,从经验中学习获取知识。这也是深度学习被看做黑盒子,可解释性差的原因。
1.2 深度学习的发展历程
早期的浅层结构(如支持向量机、逻辑回归等)在涉及到一些复杂的问题,如语音、图像、视觉等问题时,会造成维度灾难。
- 我们都知道,一种新的概念的出现必然是为了解决某种问题或者验证某种结论,那深度学习这一新概念的提出是为了解决什么问题的呢?
- 由于早期绝大多数机器学习与信号处理技术都使用浅层结构(如支持向量机、逻辑回归等),在解决大多数简单问题或者有限制条件的问题上效果明显。

- 但是涉及到一些复杂的问题,如语音、图像、视觉等问题时,数据的维度会很高,也就是我们通常所说的维数灾难,这会导致很多机器学习问题会变得相当困难。各位学者又是如何去解决这一问题的呢?
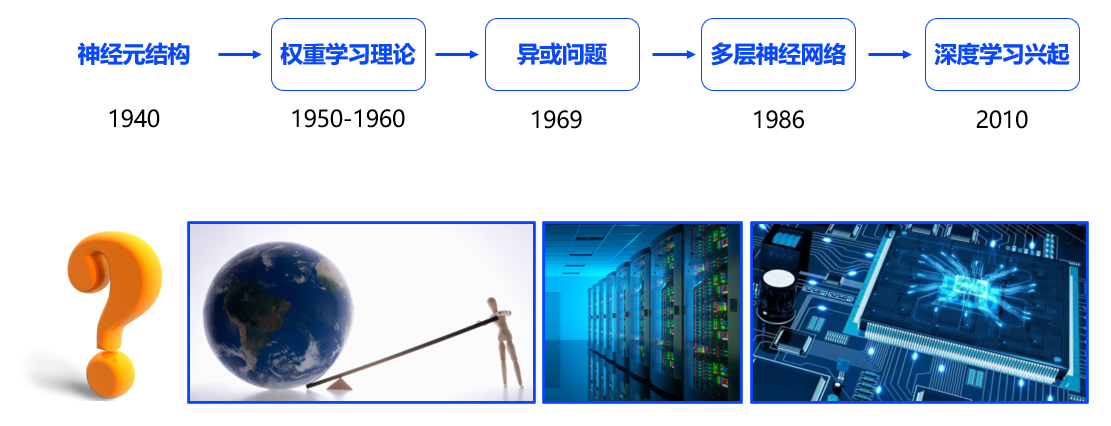
- 为何神经网络到2010年后才焕发生机呢?这与深度学习成功所依赖的先决条件:大数据涌现、硬件发展和算法优化有关。由于神经网络和深度学习是非常强大的模型,需要足够量级的训练数据,而大数据就是神经网络发展的有效前提,但很多场景下没有足够的标记数据来支撑深度学习。其实深度学习的能力特别像科学家阿基米德的豪言壮语:“给我一根足够长的杠杆,我能撬动地球!”,深度学习也可以发出类似的豪言:“给我足够多的数据,我能够学习任何复杂的关系”。但在现实中,足够长的杠杆与足够多的数据一样,往往只能是一种美好的愿景。直到近些年,各行业IT化程度提高,累积的数据量爆发式地增长,才使得应用深度学习模型成为可能。此外,还需要依靠硬件的发展和算法的优化。现阶段,依靠更强大的计算机、GPU、AutoEncoder、预训练和并行计算等技术,深度学习在模型训练上的困难已经被逐渐克服。其中,数据量和硬件是更主要的原因。
1.3 深度学习的前景
以深度学习为基础的人工智能技术,在升级改造众多的传统行业领域,存在极其广阔的应用场景。

- 以深度学习为基础的人工智能技术,在升级改造众多的传统行业领域,存在极其广阔的应用场景。艾瑞咨询的研究报告提到,人工智能技术不仅可在众多行业中落地应用(广度),同时,在部分行业(如安防、遥感、互联网、金融、工业等)已经实现了市场化变现和高速增长(深度),为社会贡献了巨大的经济价值。其实,以深度学习为基础的AI技术在各行业已经得到了广泛的应用:以计算机视觉的行业应用分布为例,根据互联网数据中心的数据统计和预测,随着人工智能向各个行业的渗透,当前较多运用人工智能的互联网行业的产值占比反而会逐渐变小。
深度学习改变了很多领域算法的实现模式。
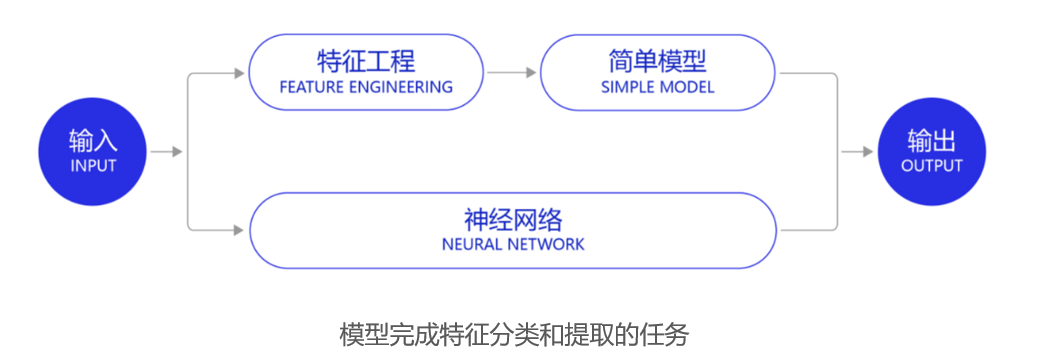
- 深度学习改变了很多领域算法的实现模式。在深度学习兴起之前,很多领域建模的思路是投入大量精力做特征工程,将专家对某个领域的“人工理解”沉淀成特征表达,然后使用简单模型完成任务(如分类或回归)。而在数据充足的情况下,深度学习模型可以实现端到端的学习,即不需要专门做特征工程,将原始的特征输入模型中,模型可如图所示,同时完成特征提取和分类任务。
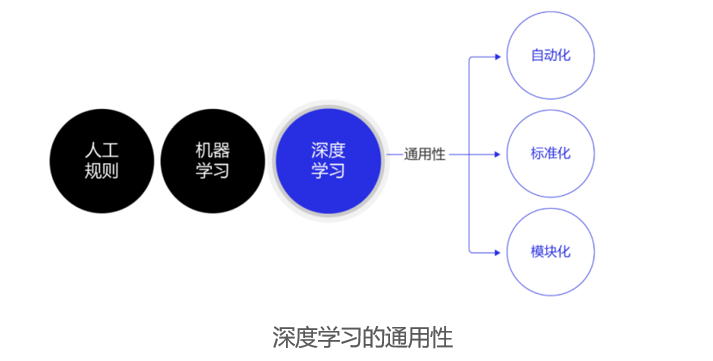
深度学习还推动人工智能进入了工业大生产阶段,算法的通用性促使标准化、自动化和模块化的框架产生。
-
除了应用广泛的特点外,深度学习还推动人工智能进入了工业大生产阶段,算法的通用性促使标准化、自动化和模块化的框架产生。
在深度学习出现之前,不同流派的机器学习算法理论和实现有所不同,这就导致每个算法均要独立实现,如随机森林和支撑向量机(SVM)。但在深度学习框架下,不同模型的算法结构具有较大的通用性,如常用于计算机视觉的卷积神经网络模型(CNN)和常用于自然语言处理的长期短期记忆模型(LSTM),都可以分为组网模块、梯度下降的优化模块和预测模块等。
这就使得抽象出统一的框架成为了可能,就能大大降低编写建模代码的成本。因此,一些相对通用的模块,如网络基础算子的实现、各种优化算法等都可以由框架实现。建模者只需要关注数据处理,配置组网的方式,并能够用少量代码串起训练和预测的流程即可。 -
在深度学习框架出现之前,机器学习工程师处于“手工作坊”生产的时代。为了完成建模,工程师需要储备大量的数学知识,并为特征工程工作积累大量行业知识。每个模型是极其个性化的,建模者如同手工业者一样,将自己的积累形成模型的“个性化签名”。而今,“深度学习工程师”进入了工业化大生产时代,只要掌握深度学习必要但少量的理论知识,掌握Python编程,即可在深度学习框架上实现非常有效的模型,甚至与该领域最领先的模型不相上下。建模领域的技术壁垒面临着颠覆,这同时也是新入行者的机遇。
2. 神经网络 —— 模拟人脑的计算方式
神经网络能够反映人类大脑的行为,允许计算机程序识别模式,以及解决人工智能、机器学习和深度学习领域的常见问题。

- 人类发明的灵感来源有很多都是来自大自然,神经网络同样如此。人工神经网络是一种类似于人类神经网络的信息处理技术。但事实上,神经网络有很多种,虽然他们都统称为“神经网络”,但每种神经网络都各有其内部的机制与原理以及不同的神经网络采用不同的网络模型和学习机制。
- 神经网络反映人类大脑的行为,允许计算机程序识别模式,以及解决人工智能、机器学习和深度学习领域的常见问题。
2.1 生物神经网络的基本原理
在生物神经网络中,每个神经元与其他神经元通过突触进行连接。
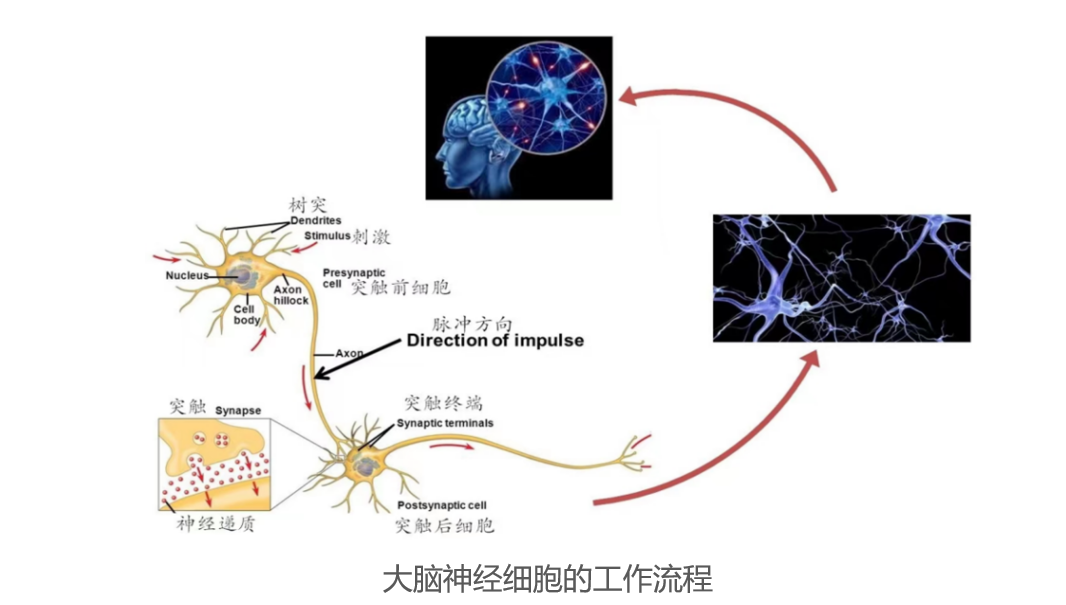
- 人,无疑是有智能的。如果想让“人造物”具备智能,模仿人类是最朴素不过的方法论了。自然地,人们同样期望研究生物大脑的神经网络,然后效仿之,从而获得智能。人工神经网络(Artificial Neural Network, ANN)便是其中的研究成果之一。而人工神经网络的性能好坏,高度依赖于神经系统的复杂程度,它通过调整内部大量“简单单元”之间的互连权重达到处理信息的目的,并具有自学习和自适应的能力。
- 而上述定义中的“简单单元”,就是神经网络中的最基本元素——神经元(Neuron)模型。如图所示,在生物神经网络中,每个神经元与其他神经元通过突触进行连接,神经元在工作的过程中,其他神经元的信号(输入信号)通过树突传递到细胞体(也就是神经元本体)中,细胞体把从其他多个神经元传递进来的输入信号进行合并加工,然后再通过轴突前端的突触传递给别的神经元。
神经元之间的信息传递,属于化学物质的传递。
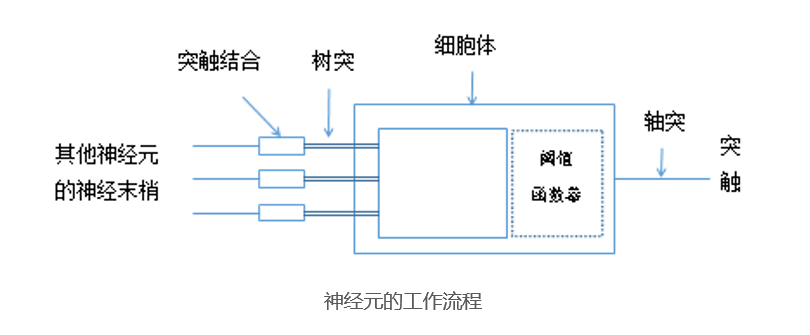
- 神经元之间的信息传递,属于化学物质的传递。当神经元“兴奋”时,就会向与它相连的神经元发送化学物质(神经递质,Neurotransmitter),从而改变这些神经元的电位。如果某些神经元的电位超过了一个阈值,相当于达到了阈值函数器的阈值,那么它就会被“激活”,在也就是“兴奋”起来,接着向其他神经元发送化学物质,一层接着一层传播。
2.2 M-P神经元模型
2.2.1 基本概念
M-P神经元模型实际上是对单个神经元的一种建模。
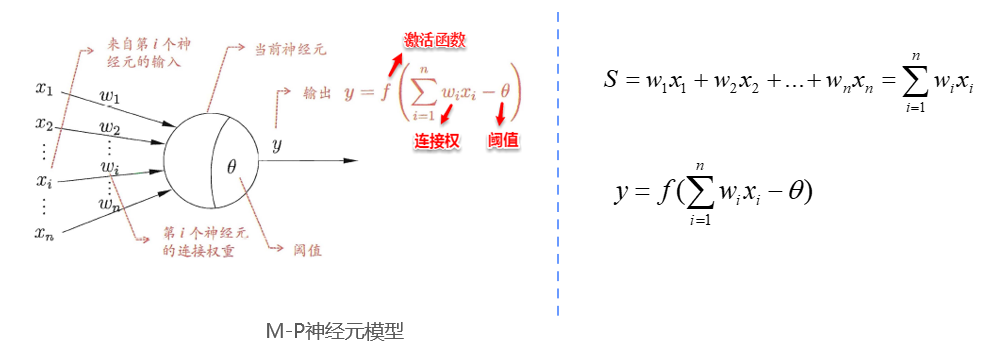
- 在这一模型中,神经元接收来自各个其他神经元传递过来的输入信号。这些信号的表达,通常通过神经元之间连接的权重(Weight)大小来表示,神经元将接收到的输入值按照某种权重叠加起来,叠加起来的刺激强度,可如图用公式表示
- 从公式可以看出,当前神经元按照某种“轻重有别”的方式,汇集了所有其他外联神经元的输入,并将其作为一个结果输出。但这种输出,并非直接输出,而是与当前神经元的阈值进行比较,然后通过激活函数(Activation Function)向外表达输出,在概念上这就叫感知机(Perceptron),其模型可用一下公式二来表示:
在这里, 就是所谓的“阈值(Threshold)”, 就是激活函数, 就是最终的输出。可以看出M-P模型就是一个加权求和再激活的过程,能够完成线性可分的分类问题。
2.2.2 代码实现
以经典乳腺癌为例
#导入需要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.datasets
from sklearn.metrics import accuracy_score #以准确率为评价指标
from sklearn.model_selection import train_test_split #用来分割数据集
#导入数据集
from sklearn.datasets import load_breast_cancer
#分离特征和标签
# 1表示良性,0表示恶性
breast_cancer = sklearn.datasets.load_breast_cancer()
data = pd.DataFrame(breast_cancer.data,columns=breast_cancer.feature_names)
data['class'] = breast_cancer.target
data['class'].value_counts()
X = data.drop('class',axis=1)
y = data['class']
#数据集划分
#划分数据集和测试集,测试集的大小为总体数据的15%。设置stratify=y
#按照数据集中y的比例分配给train和test,使得train和test中各类别数据的比例与原数据集的比例一致。通常在数据集的分类分布不平衡的情况下会用到stratify。
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.15, stratify=y, random_state=0)
#M—P神经元模型仅能把0或1作为输入,所以我们要把数据进行处理,划分为0和1两类。
X_binarise_train =X_train.apply(pd.cut, bins=2, labels=[1,0])
X_binarise_test = X_test.apply(pd.cut, bins=2, labels=[1,0])
#获取value,用数组进行计算
X_binarise_train = X_binarise_train.values
X_binarise_test = X_binarise_test.values
#构建M-P神经元类
class MPNeuron:
def __init__(self):
self.b = None
def model(self,x):
return (sum(x) >= self.b)
def predict(self,X):
y = []
for x in X:
y.append(self.model(x))
return np.array(y)
def fit(self,X,y):
accuracy = {}
for b in range(X.shape[1] + 1):
self.b = b
y_pred = self.predict(X)
accuracy[b] = accuracy_score(y_pred,y)
best_b = max(accuracy, key = accuracy.get)
self.b = best_b
#打印最佳b值和最高准确率
print('best_b:', best_b)
print('best_accuracy:', accuracy[best_b])
#用M-P神经元训练,机器学习叫作fit,深度学习叫作train
mp_neuron = MPNeuron()
mp_neuron.fit(X_binarise_train,y_train)
#打印accuracy_score
w = mp_neuron.predict(X_binarise_test)
accuracy_score(w,y_test)
2.3 激活函数
2.3.1 基本概念
阶跃函数 — 可以将神经元输入值与阈值的差值映射为输出值1或0.若差值大于等于零则输出1,对应兴奋;若差值小于零则输出0,对应抑制。

- 前面提到了,神经元的工作模型存在“激活(1)”和“抑制(0)”两种状态的跳变,那么理想的激活函数就应该是图中所示的阶跃函数(Step Function,阶跃函数是一种特殊的连续时间函数,是一个从0跳变到1的过程,属于奇异函数)。阶跃函数可以将神经元输入值与阈值的差值映射为输出值1或0;若差值大于等于零则输出1,对应兴奋;若差值小于零则输出0,对应抑制。
- 但事实上,在实际使用中,阶跃函数具有不光滑、不连续等众多不“友好”的特性,使用的并不广泛。说它“不友好”的原因是,在神经网络中训练网络权重时,通常依赖对某个权重求偏导、寻极值,而不光滑、不连续等通常意昧着该函数无法“连续可导”。
S型函数(sigmoid函数)— 无论输入值的范围有多大,这个函数都可以将输出挤压在范围(0,1)之内。
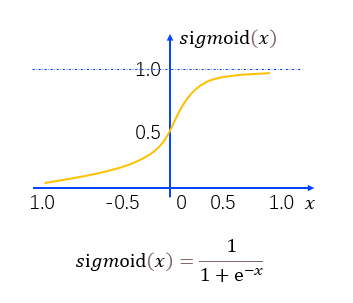
- 因此,我们通常用S型函数函数来代替阶跃函数,最常用的S型函数为sigmoid函数,如图中所示。在sigmoid函数中,无论输入值 的范围有多大,这个函数都可以将输出挤压在范围(0,1)之内,因此此这个函数又被称为“挤压函数(Squashing Function)”。这样,如果输入的值在(0,0.5)之间,那么对于Sigmoid函数,则输出大于0.5小于1,对应兴奋;如果输入值在(-0.5,0)之间,那么输出则小于0.5大于0,对应抑制。
- 既然如此,我们又应该怎样理解激活函数呢?其实从生活中就可以找到相似的影子。比如有一个父亲为了奖励他的孩子,对他说如果下次期末总成绩90分以上就奖励100元,不到90分就没有奖励。现在我们把这一过程抽象为一个M-P神经元模型。父亲最终会有两个状态,一个是奖励100元(激活),一个是没有奖励(抑制)。输入的 、 、到 等因素为孩子的表现,比如 代表孩子今天有没有认真听课, 代表孩子有没有认真完成作业, 代表孩子考试有没有认真计算。这些表现因素乘以各自的权重相加就是孩子的期末总成绩,如果总成绩没有超过父亲奖励的阈值,则最终相减的结果小于0,经过阶跃激活函数后值为0,代表父亲处于抑制状态,也就是没有奖励。但在第二次,孩子学习更加刻苦,考试过程中也特别认真,最后乘以各因素权重后的和超过了父亲的奖励阈值,即超过了90分,则最终相减的结果大于0,此时经过阶跃激活函数后的值为1,代表父亲处于激活状态,于是奖励给了孩子100元。
这便是激活函数以及整个M-P神经元模型的基本原理。
2.3.2 代码实现
阶跃函数
import numpy as np
def step_function(x):
"""
阶跃函数的Python实现
参数:
x -- 一个包含n个元素的一维数组,表示输入的测量值。
返回值:
一个包含m个元素的一维数组,表示阶跃函数的输出。
"""
m = len(x) - 1 # 阶跃函数的输出长度为输入长度减1
return np.where(x >= 0, 1, 0) # 如果输入值大于等于0,则输出1,否则输出0
S型函数
import math
def sigmoid(x):
return 1 / (1 + math.exp(-x))
3. 感知机
感知机是一种判别模型,其目标是求得一个能够将数据集中的正实例点和负实例点完全分开的分离超平面。

- 感知机在1957年由弗兰克·罗森布拉特提出,是支持向量机和神经网络的基础。
- 感知机是一种二类分类的线性分类模型,输入为实例的特征向量,输出为实例的类别,正类取1,负类取-1。
- 感知机是一种判别模型,其目标是求得一个能够将数据集中的正实例点和负实例点完全分开的分离超平面。如果数据不是线性可分的,则最后无法获得分离超平面。
3.1 单层感知机及其基本原理
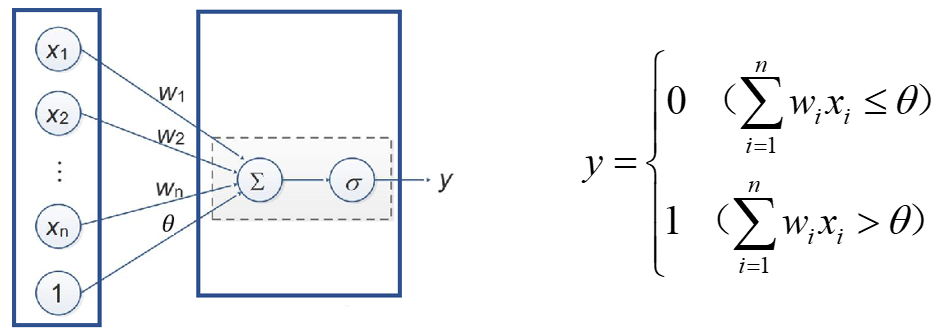
基本结构 — 由两层神经元构成的网络结构。
-
上面所讲到的M-P神经元模型其实就是对单个神经元的一种建模,需要注意的一点是,M-P模型的权重和阈值都是人为给定的,所以对这一类模型不存在“学习”的说法。其实,这也是M-P模型与单层感知机最大的区别,感知机中引入了学习的概念,权重和阈值是通过学习得来的。
-
单层感知机模型是由美国科学家Frank Rosenblatt(罗森布拉特)在1957年提出的,它的基本结构如图所示,简单来说,感知机(Perceptron)就是一个由两层神经元构成的网络结构:输入层接收外界的输入信号,通过激活函数(阈值)变换,把信号传送至输出层,因此它也被称为“阈值逻辑单元”;输出层(也被称为是感知机的功能层)就是M-P神经元。
-
输出的数学表达式如图所示。可以看到,大于阈值的时候输出为1,小于等于阈值的时候输出为0。
通过区分香蕉和西瓜的经典案例来看看感知机是如何工作的。
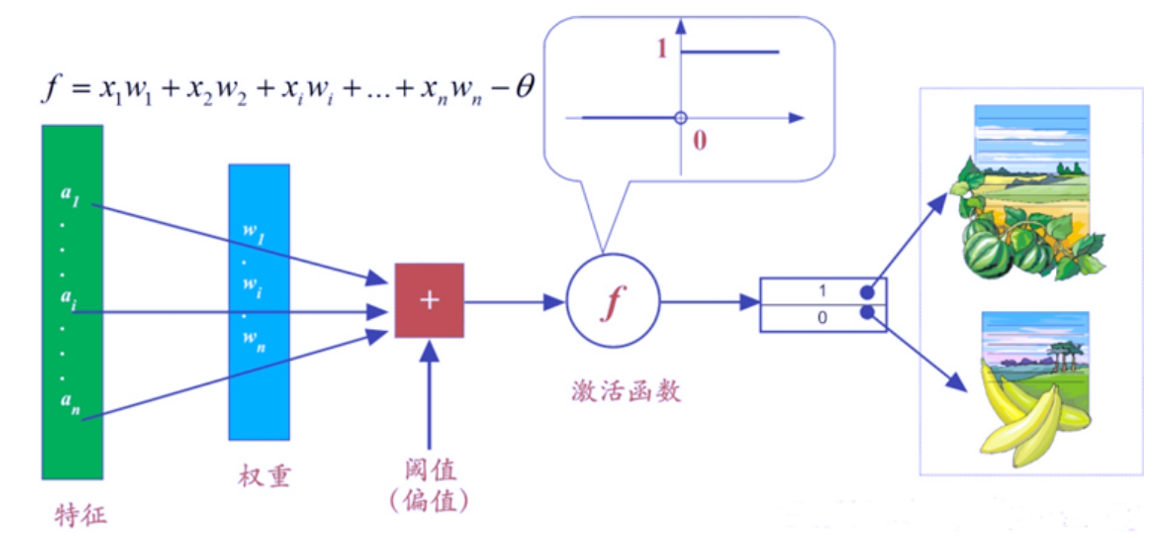
- 如图所示。为了简单起见,我们假设西瓜和香蕉由且仅有两个特征:形状和颜色,其他特征暂不考虑。这两个特征都是基于视觉刺激而最易得到的。假设特征 代表输入颜色,特征 代表形状,权重 和 的默认值暂且都设为1。为了进一步简化,我们把阈值 (也有教程称之为偏置—bias)设置为0。为了标识方便,我们将感知机输出数字化,若输出为“1”,代表判定为“西瓜”;若输出为“0”,代表判定为“香蕉”。

-
这样一来,可以很容易根据感知机输出 数学表达式,如下式所示,对西瓜和香蕉做出鉴定:
西瓜:𝑦=𝑓(𝑤_1 𝑥_1+𝑤_2 𝑥_2−𝜃)=𝑓(1×1+1×1−0)=𝑓(2)=1
香蕉:𝑦=𝑓(𝑤_1 𝑥_1+𝑤_2 𝑥_2−𝜃)=𝑓(1×(−1)+1×(−1)−0)=𝑓(−2)=0
这里,我们使用了最简单的阶跃函数作为激活函数。在阶跃函数中,输出规则非常简单:当 中 时, 输出为1,否则输出为0。通过激活函数的“润滑”之后,结果就变成我们想要的样子,这样就实现了西瓜和香蕉的判定。
这里需要说明的是,对象的不同特征(比如水果的颜色或形状等),只要用不同数值区分表示开来即可,具体用什么样的值,其实并没有关系。但你们或许还会疑惑,这里的阈值(threshold) 和两个连接权值 和 ,为啥就这么巧分别就是0、1、1呢?如果取其它数值,会有不同的判定结果吗?
接下来我们假定 还是等于1,而 等于-1,阈值 还是等于0。然后我们对于西瓜的特征:绿色圆形通过加权求和再经过阶跃激活函数后输出如下式所示:
西瓜:𝑦=𝑓(𝑤_1 𝑥_1+𝑤_2 𝑥_2−𝜃)=𝑓(1×1+(−1)×1−0)=𝑓(0)=0 -
输出为0,而我们假设的输出值0为香蕉,显然判断错了,对于香蕉的特征我们加权求和经过阶跃激活函数得到输出值为0,对应香蕉,判断正确。由此观之,我们判断正确错误和我们的权值 、 和阈值相关。那么怎么选择权值和阈值呢?事实上,我们并不能一开始就知道这几个参数的取值,而是一点点地“折腾试错”(Try-Error),而这里的“折腾试错”其实就是感知机的学习过程。
3.2 感知机的学习过程
神经网络的学习规则 — 调整神经元之间的连接权值和神经元内部阈值的规则。
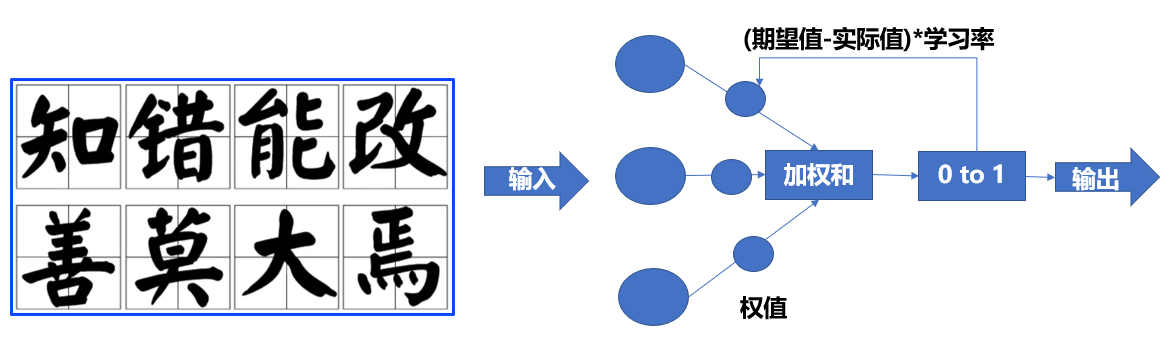
- 中国有句古话:“知错能改,善莫大焉”说的就是,犯了错误而能改正,没有比这更好的事了。放到机器学习领域,这句话显然属于“监督学习”的范畴,因为“知错”,就表明事先已有了事物的评判标准,如果你的行为不符合或者偏离这些标准,那么就要根据偏离的程度,来“改善”自己的行为。
- 下面,我们根据这个思想来制定感知机的学习规则。从前面的讨论中,我们已经知道,感知机学习属于“有监督学习”(也称分类算法),具有明确的结果导向性,其实这就类似于“不管白猫黑猫,抓住老鼠就是好猫”的说法,无论是什么样的学习规则,能达到良好的分类目的,就是好的学习规则。我们都知道,对象本身的特征值一旦确定下来就不会变化,可视为常数。因此,如下图所示,神经网络的学习规则就是调整神经元之间的连接权值和神经元内部阈值的规则(这个结论对于深度学习而言依然是适用的)。
感知机的学习过程分为四个阶段。
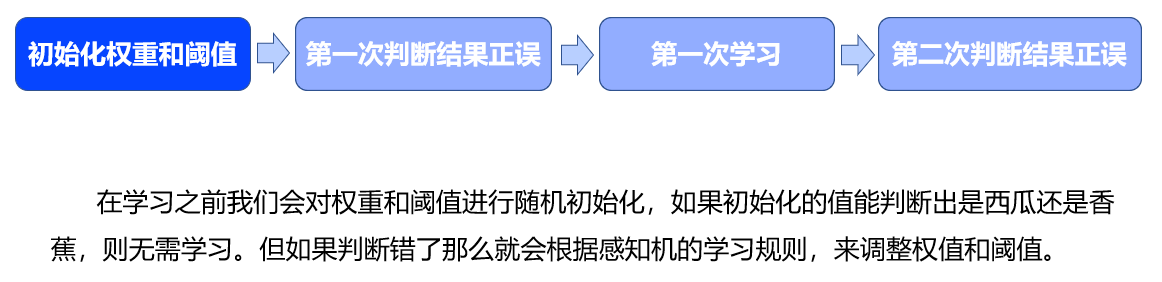
- 第一个阶段,在学习之前我们会对权重和阈值进行随机初始化,如果初始化的值能判断出是西瓜还是香蕉,则无需学习。但如果判断错了那么就会根据感知机的学习规则,来调整权值和阈值。

- 第二个阶段、上面我们假定的权值ω1=1,ω2 =-1,θ=0,判断出来的结果是错误的,下面我们就用上面的学习规则来模拟感知机的学习过程,完成判定西瓜的学习。第一次判断西瓜的输出值 y如图所示,判断错误。

- 第三个阶段、假设学习规则如下:
在𝜀=𝑦−𝑦^′ 𝑦为期望输出,𝑦^′是实际输出。也就是说 是二者的“落差”。这个差值就是整个网络中权值和阔值的调整动力。进行第一次学习如下。
𝜀_1=𝑦−𝑦^′=1−0=1𝑤_(𝑛𝑒𝑤_1)=𝑤_(𝑜𝑙𝑑_1)+𝜀_1=1+(1−0)=2𝑤_(𝑛𝑒𝑤_2)=𝑤_(𝑜𝑙𝑑_2)+𝜀_1=(−1)+(1−0)=0𝜃_𝑛𝑒𝑤=𝜃_𝑜𝑙𝑑+𝜀_1=0+(1−0)=1

- 结果显示判断正确,因此我们可以认为这个模型在这一的权重和阈值下是没有问题的。
- 在上述案例中,我们仅仅经过一轮“试错法”,我们就搞定了参数的训练,但其实这相当于一个“Hello World”版本的神经网络。事实上,在有监督的学习规则中,我们需要根据输出与期望值的差值,经过多轮重试,反复调整神经网络的权值,直至这个“落差”收敛到能够忍受的范围之内,训练才告结束。比如上面学习的例子中,我们最后得到的新的权重。也就是说没有考虑形状这个特征,虽然我们能正确分类,但显然是不够合理的。

- 综上所述,当我们给定训练数据、神经网络中的参数(权重和阈值)时,都可以通过不断地“纠偏”学习得到最终参数。为了方便,我们通常把阈值视为,而其输入值固定为“-1”(也资料将这个固定值设置为1,其实都是一样的,主要取决于表达式前面的正负号),那么阈值就可被视为一个“哑元节点(Dummy Node)”这样一来,权重和阈值的学习就可以统一为“权重”的学习了。
3.3 感知机的几何意义
- 刚刚我们学习了感知机的训练过程,其实感知机实际解决的是一个二分类问题。下面我们来分析一下感知机的几何意义。
单个特征的感知机 — 在红点和蓝点交界的区间内直接任取一点都可以将这两部分样本分开。
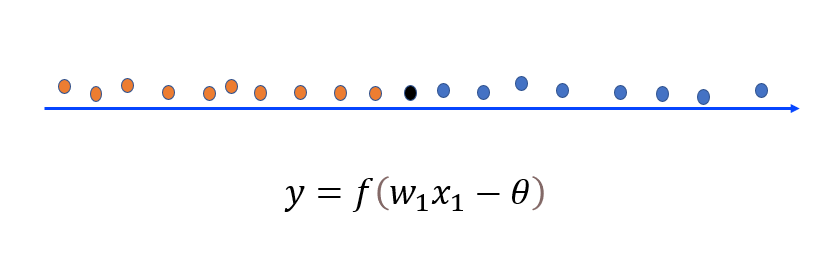
- 先来看一个例子,上图是一个只有𝑥轴的一维坐标轴,该轴同样存在原点,𝑥轴正方向和𝑥轴反方向,且该轴上分布了很多红点和蓝点,此时如果要求在坐标轴上找一个分割点,来分割红点和蓝点,而且要求只允许找一个点来分割这两部分样本,并且要求此点分割效果最好,如何去找呢?答案是:在红点和蓝点交界的区间内直接任取一点都可以将这两部分样本分开,比如这个黑点。其实这个就是我们刚刚学习到的𝑤_2等于0的情况,也就是只根据特征𝑤_1判断输出。
二维特征的感知机 — 可以找到一条直线将两类样本点分开。
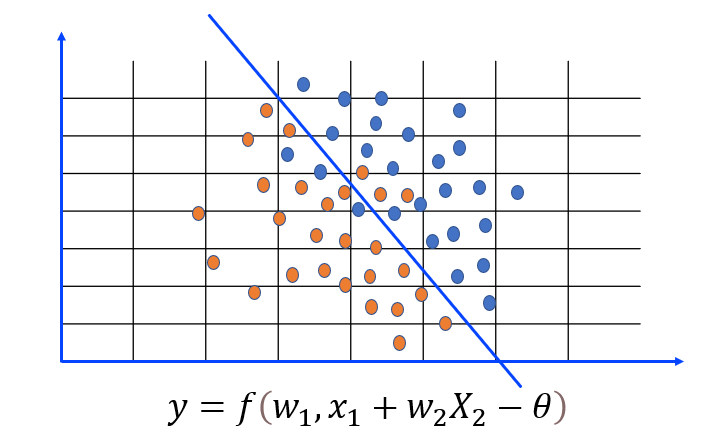
- 上面是一维坐标下的情况,我们再来看一个二维坐标下的例子,如下图左侧所示的二维直角坐标系中要将红点与蓝点分开如何做呢?答案是:我们可以找到一条直线将两类样本点分开。在数学中,找到这条直线可以分两步:
-
找到两类样本之间最近的那一部分点;
-
找到一条直线使得最近的那些样本点到此直线的距离相等且尽量最大,此处可以用“点到直线的距离”来解决,并且由于要把两类样本分开,所以必然一部分样本点在直线上方,一部分在直线下方,点的位置由两个输入特征横坐标和纵坐标来决定。这个例子就类似于我们一开始权重 、 都等于1,阈值等于0的情况。
三维特征的感知机 —用一个面将红点和蓝点分离开,这样平面的位置就由三个输入特征决定。
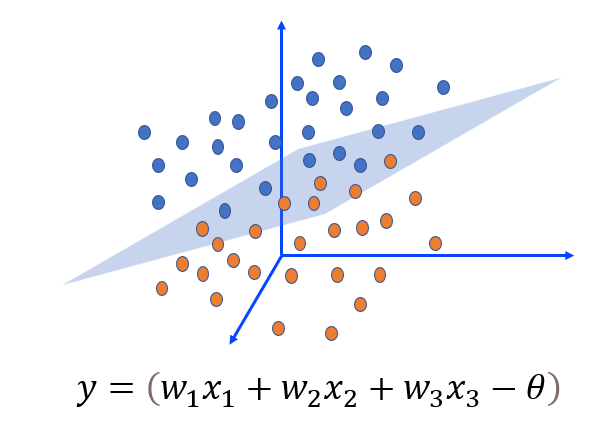
- 同样,在如图右侧所示的三维空间中,我们可以用一个面将红点和蓝点分离开,这样平面的位置就由三个输入特征决定。相对应的,如果这是在上面所提到的西瓜香蕉分类问题中,输入特征再加上重量这一条,类似于在三维坐标下了。
由上述内容,我们总结得到:

- 如果是更高维的数据呢?这时就需要引入超平面。超平面指 维 线性空间中维度为 的子空间。它可以把线性空间分割成不相交的两部分,即把一个空间分成了两个半平面。这就是感知机几何意义,因此,感知机可看作一个由超平面划分空间位置的识别器。
3.3 感知机的应用
布尔函数 — 输入输出都是布尔值的一种函数,主要有“与”门、“与非”门、“或”门、“异或”门。
- 在学习感知机的应用之前,我们可以先来了解一下布尔函数:计算机语言中的布尔变量,只有0和1两种可能的值,布尔函数就是输入输出都是布尔值的一种函数,主要有“与”门、“与非”门、“或”门、“异或”门,以下是各自的功能。
- 1.“与”门,表示输入有0值,输出就为0,输入全为1输出才为1;
- 2.“与非”门,和“与”门相反,输入有0,则输出为1,输入全1才输出0;
- 3.“或”门,表示输入有1,就输出1,输入全0才输出0;
- 4.“异或”门,表示输入相同输出为0,输入不同输出则为1。
- 其实感知机模型的输出就是0和1,以两个输入为例,有没有可能调整权重𝑤和偏置𝜃的值使这个感知机实现“与”门、“与非”门、“或”门和“异或”门的功能呢?我们接下来分别看一下。
“与”门 — 当两个输入均为1时输出为1,其他时候输出为0。
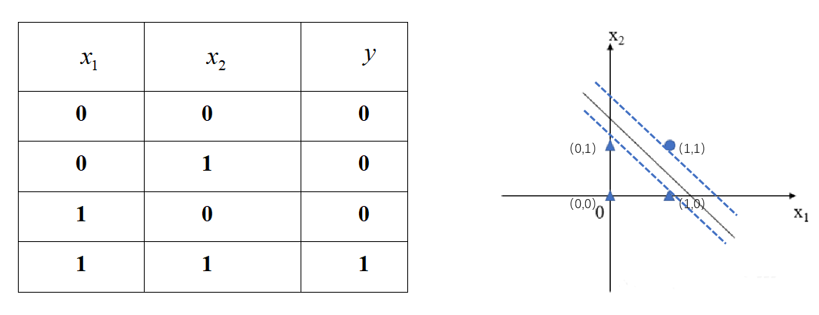
- 与门为有两个输入和一个输出的门电路,它的真值表如下图中左侧所示,当两个输入均为1时输出为1,其他时候输出为0。这里我们可以根据输出 值将结果分为“0”和“1”两类,也可以看为一个二分类问题。
- 将𝑥_1、𝑥_2作为横纵坐标轴,将对应点花在坐标轴上如图3-10所示,其中三角形表示输出𝑦=0,圆形表示输出𝑦=1。我们发现在两临界边界(如图中虚线所示)之间的任意一条线均可作为实现“与”门感知机的分类超平面。
- 如果要使用感知机实现与门真值表的逻辑功能,按照我们之前的理解,只需设定合适的权重参数就可以了。其实我们可以尝试根据感知机的网络参数学习算法求解一个线性方程来表示“与”门,确定满足上表的参数值。方法过程和上面讲的分类香蕉西瓜的例子相同,此处不再赘述,例如[𝑤_1,𝑤_2,𝜃]可以取[1,1,2],[0.5,0.5,0.6]等,大家可以将输入𝑥_1、𝑥_2值代入我们的感知机中进行验证。
“与非”门 — 当输入全1的时候输出为0,当输入有0则输出为1。
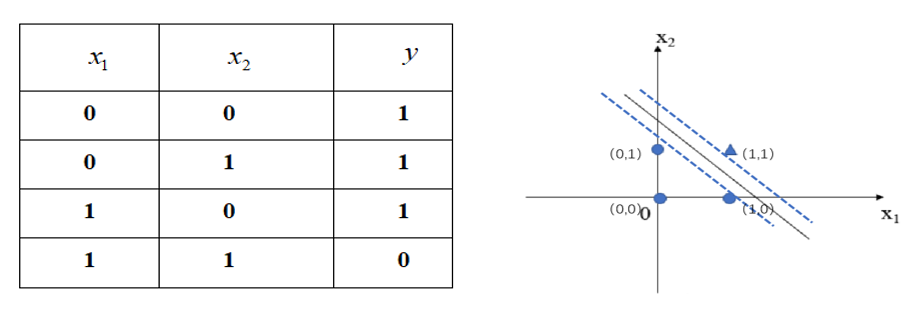
- 将𝑥_1、𝑥_2作为横纵坐标轴,将对应点如下图所示标在坐标系中,其中三角形表示输出𝑦=0,圆形表示输出𝑦=1。不难发现在两临界边界(如图中虚线所示)之间的任意一条线均可作为实现“与非”门感知机的分类超平面。
- 根据感知机的网络参数学习算法求解线性方程来表示“与非”门,从而确定满足上表的参数值。方法过程和上面讲的分类香蕉西瓜的例子相同,此处不再赘述,如[𝑤_1,𝑤_2,𝜃]可以取[-0.5,-0.5,-0.7]等值,将输入𝑥_1、𝑥_2值代入我们的感知机中验证。
“或”门——只要有一个输入信号为1,输出就为1的逻辑电路。
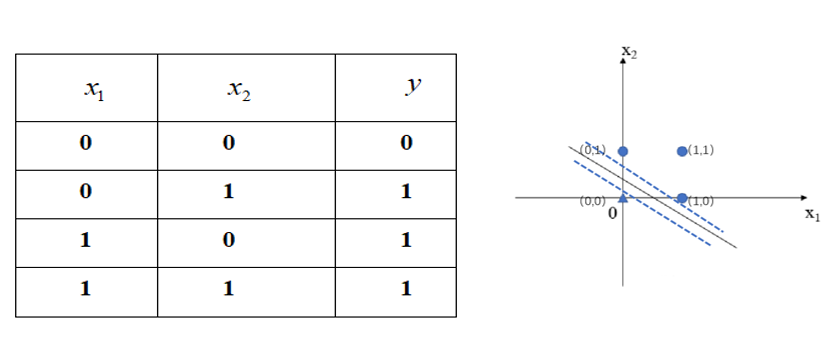
- 我们可以将𝑥_1、𝑥_2作为横纵坐标轴,将对应点如下图所示标注在坐标系中,其中三角形表示输出𝑦=0,圆形表示输出𝑦=1。这是在两临界边界(如图中虚线所示)之间的任意一条线均可作为实现“或”门感知机的分类超平面。
- 根据感知机的网络参数学习算法求解一个线性方程来表示“或”门,确定满足上表的参数值。方法过程和上面讲的分类香蕉西瓜的例子相同,此处不再赘述,如[𝑤_1,𝑤_2,𝜃]可以取[1,1,0.5]等值,将输入𝑥_1、𝑥_2值代入我们的感知机中验证。
“异或”门——当𝑥_1和 𝑥_2相同时输出为0,𝑥_1和𝑥_2不同时则输出为1。
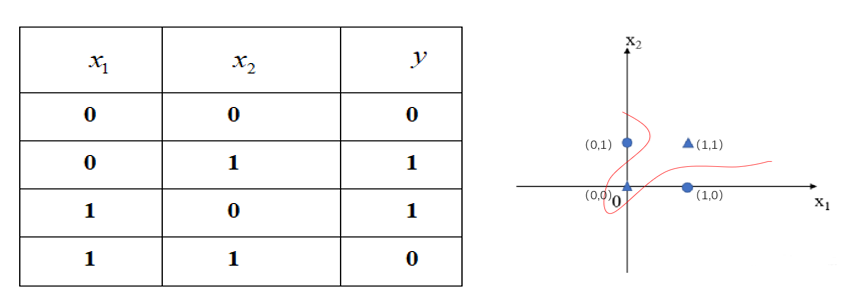
- 将𝑥_1、𝑥_2作为横纵坐标轴,并将对应点标注在下图所示坐标系中,根据图像可知,我们已经无法再通过一条直线将一个整体划为两部分,若强行将它分为两部分,那么就只能是曲线,所划空间也成为非线性空间。
- 在这种情况下,感知机的学习过程就会发生“震荡(Fluctuation)”,权重就难以求得合适的解。因此,单个感知机的局限性在于它只能表示由一条直线分割的空间,对于非线性问题(即线性不可分问题,如上图中的非线性空间)仅用单个感知机无法解决。
4. 深度神经网络
深度神经网络是一种使用数学模型处理图像以及其他数据的多层系统,而且目前已经发展为人工智能的重要基石。

- 深度神经网络是一种使用数学模型处理图像以及其他数据的多层系统,而且目前已经发展为人工智能的重要基石。深度学习需要收集大量的数据,并且拥有处理这些数据的能力,做到这些并非易事,但深度学习技术正在蓬勃发展的道路上,并且已经突破了很多障碍。深度学习对于分析非结构化数据具有非常大的优势。
- 2006年,杰弗里·辛顿提出了在非监督数据上建立多层神经网络的一个有效方法,简单的说,分为两步,一是每次训练一层网络,二是调优使原始表示x向上生成的高级表示r和该高级表示r向下生成的x’尽可能一致。
4.1 深度神经网络结构
单层的感知机不能解决“异或”问题。
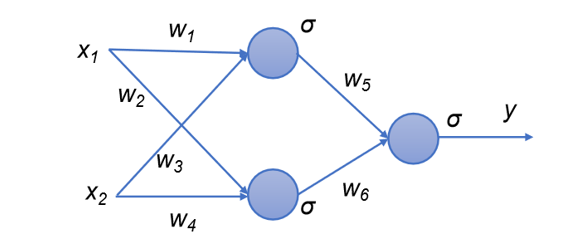
- 在前面分别介绍了M-P神经元模型和感知机模型。在M-P神经元模型中,神经元接收到若干个输入信号,并将计算得到的加权后的总输入,经过激活函数的处理,最终产生神经元的输出。而感知机模型则由两层神经元组成,输入层接收外界输入信号后,经过激活函数处理,传递给输出层,输出层再经过激活函数处理形成最终的输出。
- 还讲到,单层的感知机不能解决“异或”问题,也正是因此被人工智能泰斗明斯基并无恶意地把人工智能打入“冷宫”二十载。其实解决“异或”问题的关键在于能否解决非线性可分问题,而要解决非线性问题就需要提高网络的表征能力,也就是需要使用更加复杂的网络。
按照这个思路,我们可以考虑在输入层和输出层之间添加一层神经元,将其称之为隐藏层(Hidden Layer,又称“隐含层”或“隐层”)。
- 多层感知机模型 — 在输入层和输出层之间添加一层神经元,将其称之为隐藏层(Hidden Layer)这样一来输入与隐藏单元,隐藏单元与输出单元之间,都有了权重相连,也就是说这个模型是全连接的,并且隐藏层和输出层中的神经元都拥有激活函数。
- 这样一来输入与隐藏单元,隐藏单元与输出单元之间,都有了权重相连,也就是说这个模型是全连接的,并且隐藏层和输出层中的神经元都拥有激活函数。这种多层感知机模型,就能够解决单个神经元无法解决的异或问题了,如当权重[𝑤_1,𝑤_2,𝑤_3,𝑤_4,𝑤_5,𝑤_6] =[1,-1,-1,1,1,1],各个神经元阈值𝜃均为0.5时,可以实现“异或”功能。
神经网络模型
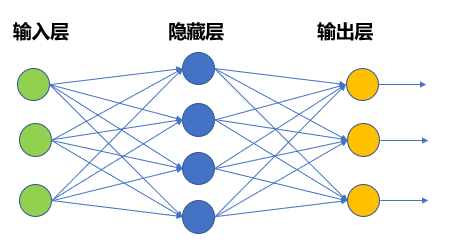
- 虽然多层感知机模型较M-P神经元而言已经有了很大进步,但这一类模型仍然无法很好地解决比较复杂的非线性问题。因此,在多层感知机模型的基础上,还研究出了如图所示的神经网络模型。
- 神经网络模型具有如下特点:
- 由输入层、隐藏层和输出层组成,根据问题的需要,结构中可能含有更多隐藏层;
- 每层神经元与下一层神经元两两之间建立连接;
- 神经元之间不存在同层连接,也不存在跨层连接;
- 输入层仅仅起到接收输入的作用,不进行函数处理;
- 而隐藏层与输出层的神经元都具有激活函数,是功能神经元。上图所示为具备单个隐藏层的神经网络。
深度神经网络(Deep Neural Network,DNN)— 将若干个单层神经网络级联在一起,前一层的输出作为后一层的输入。
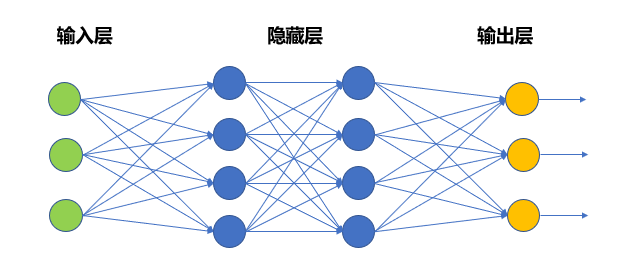
- 此外,针对以上的第1条中,对于神经网络模型,当隐藏层如下图中所示大于等于两层时,就称之为深度神经网络(Deep Neural Network,DNN)。
- 在这种结构中,将若干个单层神经网络级联在一起,前一层的输出作为后一层的输入,这样构成了多层前馈神经网络(Multi-layer Feedforward Neural Networks)更确切地说,每一层神经元仅与下一层的神经元全连接,并且输入层—隐藏层、隐藏层—隐藏层、隐藏层—输出层之间,都有权重相连。但在同一层之内,神经元彼此不连接,而且跨层之间的神经元,彼此也不相连。
- 之所以加上“前馈”这个定语,是想特别强调,这样的网络是没有反馈的。也就是说,位置靠后的层次不会把输出反向连接到之前的层次上作为输入,输入信号可以“一马平川”地单向向前传播。很明显,相比于纵横交错的人类大脑神经元的连接结构,这种结构做了极大简化,即使如此,它也具有很强的表达力。
- 在上图的DNN模型中,输入从最左侧的输入单元进入DNN模型,从左至右依次经过两个隐藏层,最后到达输出层形成输出。每一次层间的传递,都是加权求和的过程。在到达下一层后,会经过激活函数的作用,成为这一层的输出。站在数学的角度看,其实权重作用,就是对上一层的输出进行线性变换,作为下一层的输入。激活函数的作用则是对输入进行了非线性的映射。在深度网络的结构下,权重和激活函数结合,使得模型具备了解决复杂的线性不可分问题的能力。
4.2 深度神经网络的训练过程
4.2.1 基本概念
深度神经网络模型解决回归问题。
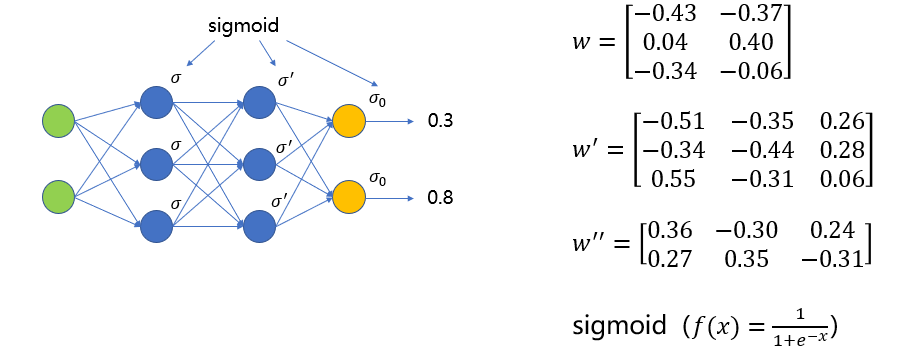
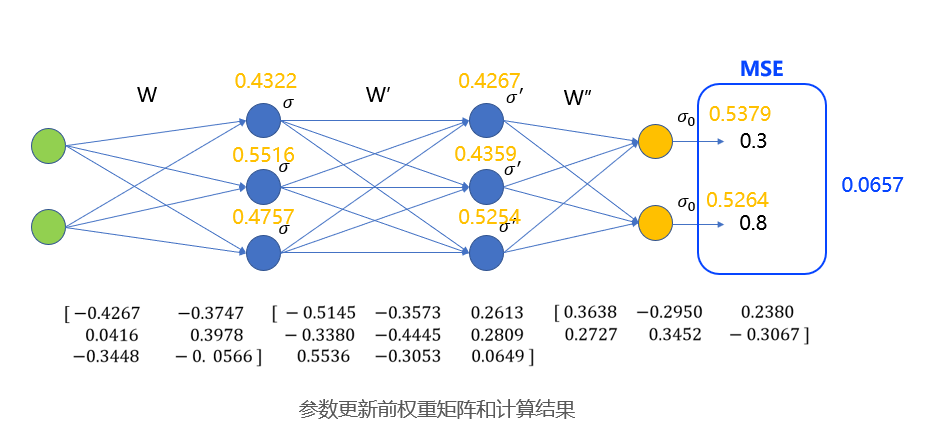
- 从左至右用𝑤,𝑤′,𝑤′′来标记这三个矩阵(偏置𝜃假设全为零)。矩阵的维度是由相邻两层神经元的个数决定的。对于全连接网络,权重矩阵的维度应该为𝑛(𝑡+1)∗𝑛(𝑡),即后一层的神经元数量乘本层的神经元数量。输入的维度是21, 维度是32,𝑤′维度是3*3,𝑤′′维度是2*3。为了方便讲解,在本案例中三个权重矩阵初始值如图中公式
- 隐藏层单元和输出层单元都具有激活函数,在这里使用sigmoid(𝑓(𝑥)=1/(1+𝑒^(−𝑥) ))函数。虽然实际应用中都是用大量的数据进行训练的,在这里先用一条数据来进行讲解,输入值为0.2、0.5,真值为0.3、0.8。由于最终的真值是数值,因此这是一个回归问题。
前向传播 — 从输入层出发,逐层推进,将上一层的输出与权重结合后,作为下一层的输入,并计算下一层的输出,如此进行,直到运算到输出层为止。
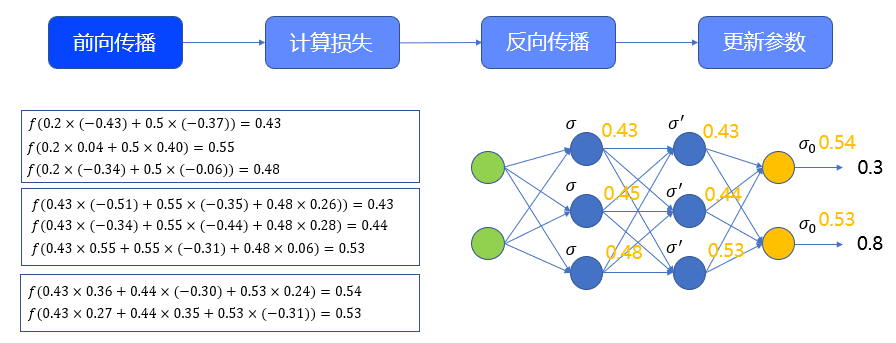
- 此案例中,输入经过权重𝑤和激活函数𝑓后,得到第一个隐藏层的输出,是一个3*1的向量,分别是(𝑓为sigmoid函数):
𝑓(0.2×(−0.43)+0.5×(−0.37))=0.43
𝑓(0.2×0.04+0.5×0.40)=0.55
𝑓(0.2×0.04+0.5×0.40)=0.55
- 这个向量,经过 后作为输入,带入sigmoid函数,得到了第二个隐藏层的输出。这个输出依然是3*1的向量:
𝑓(0."43"×(−0.“51”)+0."55"×(−0.35)+“0.48"×"0.26”))=0.43
𝑓(0."43"×(−0.“34”)+0."55"×(−0.“44”)+“0.48"×"0.28”)=0.44
𝑓(0.“43"×"0.55”+0."55"×(−0.31)+“0.48"×"0.06”)=0.“53”
- 最后,这个向量经过 作为输入,经过sigmoid,得到最终输出,计算后是:
𝑓(0.“43"×"0.36”+0."44"×(−0.30)+“0.53"×"0.24”)=0.“54”
𝑓(0.“43"×"0.27”+0.“44"×"0.35”+“0.53"×(−"0.31”))=0.“53”
计算损失 — 利用损失函数来调节网络中的权重,进而减小损失函数,即使得输入经过权重能准确的预测出实际值。
-
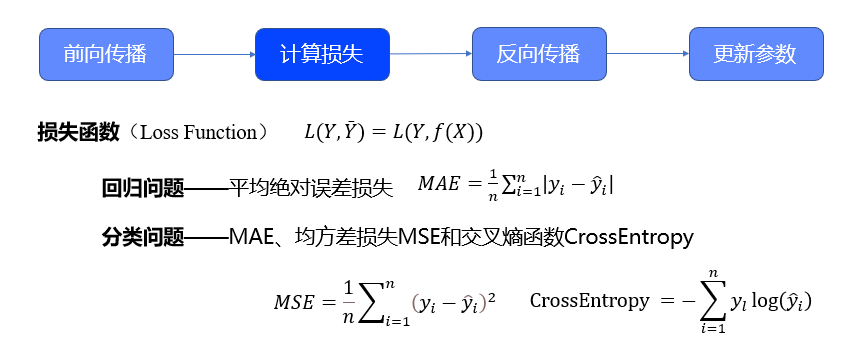
计算损失,在机器学习中的“有监督学习”算法里,在假设空间𝛤中,构造一个决策函数𝑓, 对于给定的输入𝑥,由𝑓(𝑥)给出相应的输出 ,这个实际输出值¯𝑌和原先预期值𝑌可能不一致。于是,需要定义了一个损失函数(Loss Function),也有人称之为代价函数(Cost Function)来度量两者之间的“落差”程度。这个损失函数通常记作𝐿(𝑌,𝑌 ̄)=𝐿(𝑌,𝑓(𝑋)),为了方便起见,这个函数的值为非负数。损失函数值越小,说明实际输出¯𝑌和预期输出𝑌之间的差值就越小,也就说明构建的模型越好。因此神经网络学习的本质,其实就是利用损失函数来调节网络中的权重,进而减小损失函数,即使得输入经过权重能准确的预测出实际值。
-
对于不同类型的问题,通常会使用不同的损失函数。比如对于回归问题,一般会使用均方差损失MSE,或平均绝对误差损失MAE。均方差损失和平均绝对误差损失的计算公式如下方所示,𝑦_𝑖为维度𝑖的真值,𝑦 ̂_𝑖为预测值,也就是输出。MSE计算的是每一项误差的平方,而MAE计算的是每一项误差的绝对值。𝑀𝑆𝐸=1/𝑛 ∑2_(𝑖=1)^𝑛▒(𝑦_𝑖−𝑦 ̂_𝑖 )^2 、𝑀𝐴𝐸=1/𝑛 ∑_(𝑖=1)^𝑛▒|𝑦_𝑖−𝑦 ̂_𝑖 |
-
对于分类问题,MSE和MAE也是可用的,但更多情况下,使用的是交叉熵损失函数。确切地说,是将Softmax激活函数和交叉熵损失CrossEntropy搭配使用,交叉熵函数表达式如图中"CrossEntropy"所示。这一点,我们在后续会进行讲解。
-
此处,使用MSE来作为损失函数来计算损失。在前向传播中通过给定的权重计算出的实际输出为0.54和0.53,因此总的损失应该是(0.3-0.54)的平方加上(0.8-0.53)的平方,再除以2,计算的到的结果是 0.066,即为我们在这一次前向传播过程中预测值与真值的偏差。
反向传播——沿着模型相反的方向,从后向前地逐层计算每个神经元的损失,并更新参数。
-
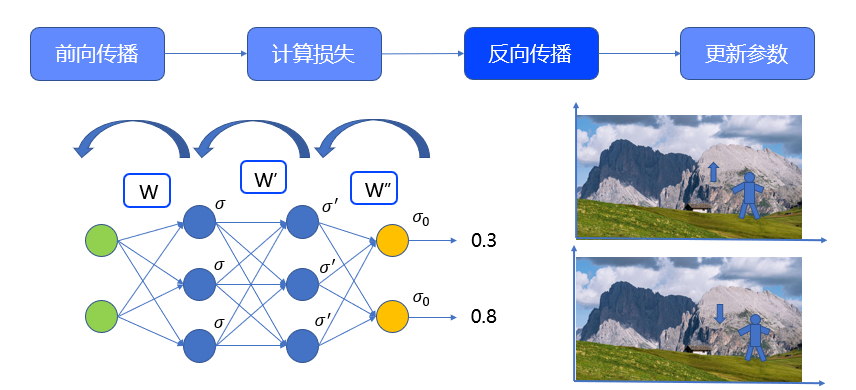
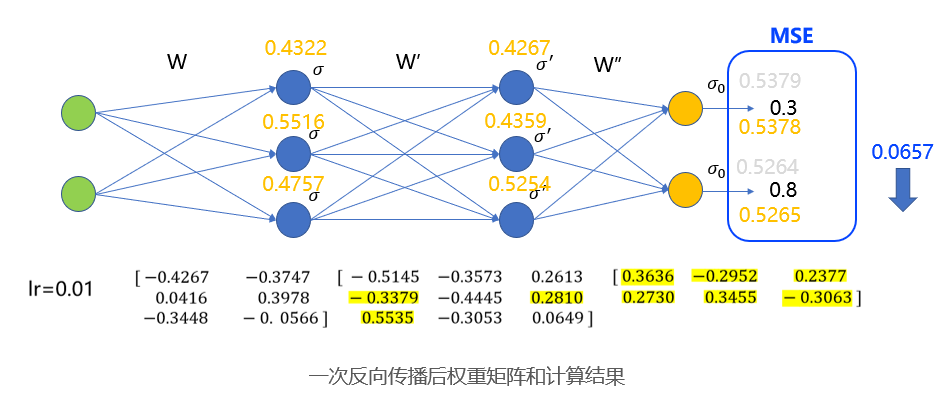
反向传播,所谓反向传播,就是沿着模型相反的方向,从后向前地逐层计算每个神经元的损失,并更新参数。以神经网络为例,从输出层出发,首先被更新的,应该是输出层与第二个隐藏层之间的权重矩阵 ,第二被更新的,是两个隐藏层之间的权重矩阵𝑤^′,最后被更新的是输入层和第一个隐藏层的权重矩阵𝑤,示意图如图所示。
-
在训练中,反向传播需要搭配优化算法才能实现参数的更新。接下来就来介绍一个经典优化策略——梯度下降。
-
我们训练的最终目标就是让损失函数的值最小,因为当损失函数值最小的时候,预测值最接近真值。当然最理想的情况是损失为零,此时预测值与真值完全相符。由于模型复杂,所以无法知道损失函数的全貌,那我们要怎么决定向哪个方向改变呢?
-
就像我们下山一样,如果遇到了雾,无法看见山路的全部走向,只能看见周围的一小片区域。那么就只能基于能看见的部分做一个决策。(忽略主观因素)如果想尽快下山的话,那么我们应该找最陡峭的方向,因为陡峭的路在海拔上变化更快。大方向确定了,那么现在可以在二维平面考虑这个问题。如果发现自己目前是在向上爬坡的,比如左图那样,说明我身后的海拔比我此时的海拔更低。因此,为了降低海拔,那么应当掉头向反方向走,这样更容易走到山脚,如图右边。
-
反之,如果此时发现自己是在向下走的,那么我应该继续前进,因为我前方的海拔比我此时的海拔低,我更容易走到山脚。在这个场景下,“上”坡和“下”坡,如果换用数学语言来描述,其实就是在坐标系下,这个山的斜率(梯度)符号。上坡就是斜率大于0,下坡就是斜率小于0。那上坡时,我们要选择的是 减小的方向,下坡时选择的是 增大的方向。也就是说我们总是沿着斜率的反方向来走的。
反向传播与更新参数——沿着模型相反的方向,从后向前地逐层计算每个神经元的损失,并更新参数。

- 在数学问题上,如果不知道一个函数的解析形式或者很难对函数进行微分计算的时候,就可以通过这样的思想,来搜索函数的最小值。
对于如下图所示的函数来说,要搜索最小值,当处于左侧点位时,斜率𝑘<0,应当朝正方向搜索,即𝛥𝑥>0, 如果位于右侧点位,𝑘>0,那么朝着副方向 的方向搜索。
回到三维甚至多维问题上进行讨论。在数学上,在某一点上,函数值变化最快,也就是所谓的最陡峭的方向,就是这一点梯度所在的方向。刚才已经得到了结论,如果要找最小值,应当朝梯度的反方向走。 - 这就是在更新时候使用的梯度下降算法,每次更新都是向着当前梯度的反方向更新一步。但应当注意到,梯度可以很大,如果完全按照梯度作为步长进行移动,有可能会错过一些最小值,因此通常会用一个系数,用来调整步长。这就是学习率learning rate,它是模型训练时一个重要的超参数。

- 那么,针对损失函数的权值的梯度如上所示。
- 这里𝛻𝐿就是损失函数的梯度,它本身也是个向量,它的多个维度分别由损失函数 对多个权值𝑊_𝑚𝑛求偏导所得。当梯度被解释为权值空间中的一个向量时,它就确定了陡峭上升的方向,那么梯度递减的训练法则就是:𝑤_𝑚𝑛 (𝑡+1)←𝑤_𝑚𝑛 (𝑡)+𝛥𝑤_𝑚𝑛,其中𝛥𝑤_𝑚𝑛=−𝜂 𝜕𝐿/(𝜕𝑤_𝑚𝑛 ), 为学习率,负号表示梯度的相反方向,因此梯度训练法则为:
𝑤_𝑚𝑛 (𝑡+1)←𝑤_𝑚𝑛 (𝑡)−𝜂 𝜕𝐿/(𝜕𝑤_𝑚𝑛 )

- 求解损失函数对各参数的偏导数就需要用到数学上的链式法则𝑑𝑢/𝑑𝑥=𝑑𝑢/𝑑𝑦⋅𝑑𝑦/𝑑𝑥,链式法则在偏微分中同样适用。如图所示为链式法则求各偏导示意图。其中:𝑧_0=𝑤_0 𝑥;𝑦_1=𝑓_1 (𝑧_0 );𝑧_1=𝑤_1 𝑦_1;𝑦_2=𝑓_2 (𝑧_1 );𝑧_2=𝑤_2 𝑦_2;𝑦_3=𝑓_3 (𝑧_2 )
- 那么如果要求最终的输出 对最初的权重 的偏导,应用链式法则,会得到:
(𝜕𝑦_3)/(𝜕𝑤_0 )=(𝜕𝑦_3)/(𝜕𝑧_2 )×(𝜕𝑧_2)/(𝜕𝑦_2 )×(𝜕𝑦_2)/(𝜕𝑧_1 )×(𝜕𝑧_1)/(𝜕𝑦_1 )×(𝜕𝑦_1)/(𝜕𝑧_0 )×(𝜕𝑧_0)/(𝜕𝑤_0 )=𝑓_3′×𝑤_2×𝑓_2′×𝑤_1×𝑓_1^′×𝑥
参数更新前权重矩阵和计算结果。
一次反向传播后权重矩阵和计算结果。
分类问题

- DNN训练以解决分类问题我们已经学习过了,接下来看一下分类问题。
- 在数据的角度上,二者的区别主要在真值形式,分类问题的真值通常是one-hot编码过的向量。只有代表正确分类的元素为1,其余都为0。例如3分类问题,一条数据属于第二类,则它的真值应该是010。分类问题与回归问题的训练过程是一致的。主要区别的点在于输出层函数的选取和损失函数的选取。先看一下激活函数,分类问题一般使用softmax作为激活函数
- 在分类问题中,𝑘代表第𝑘类,𝑛是总分类数。𝑧_𝑘就是第𝑘个输出单元的输入值。因为分母是各类别输入之和,所以通过softmax函数,我们可以将数值转化成数据属于各分类的概率。各输出加和就应该为1。比如输入0.2,0.5经过了一个神经网络,在输出层经过softmax,得到二分类的概率是0.48和0.52
对于分类问题,常用的损失函数为交叉熵损失,将输出的二分类概率0.48和0.52带入得:
"Loos "=0.73
4.1.2 代码实现
import numpy
def sigmoid (x): #激活函数
return 1/(1+numpy.exp(-x))
def der_sigmoid(x): #激活函数的导数
return sigmoid(x)*(1-sigmoid(x))
def mse_loss(y_tr,y_pre): #均方误差损失函数
return((y_tr - y_pre)**2).mean()
class nerualnetwo():
def __init__(self): #感知神经元的权值属性定义,初始化随机值,会导致模型以及预测结果每次都不同
self.w1 = numpy.random.normal()
self.w2 = numpy.random.normal()
self.w3 = numpy.random.normal()
self.w4 = numpy.random.normal()
self.w5 = numpy.random.normal()
self.w6 = numpy.random.normal()
self.b1 = numpy.random.normal()
self.b2 = numpy.random.normal()
self.b3 = numpy.random.normal()
def feedforward(self,x): #前向计算方法,#返回所有神经元值
h1 = x[0]*self.w1+x[1]*self.w2+self.b1
h1f = sigmoid(h1)
h2 = x[0]*self.w3+x[1]*self.w4+self.b2
h2f = sigmoid(h2)
o1 = h1f*self.w5+h2f*self.w6+self.b3
of = sigmoid(o1)
return h1,h1f,h2,h2f,o1,of
def simulate (self,x): #前向计算方法,返回预测值
h1 = x[0]*self.w1+x[1]*self.w2+self.b1
h1f = sigmoid(h1)
h2 = x[0]*self.w3+x[1]*self.w4+self.b2
h2f = sigmoid(h2)
o1 = h1f*self.w5+h2f*self.w6+self.b3
of = sigmoid(o1)
return of
def train(self,data,all_y_tr):
epochs = 1000 #迭代次数
learn_rate = 0.1 #学习率
#print(self.w1)
for i in range(epochs):
for x , y_tr in zip(data,all_y_tr):
valcell = self.feedforward(x) #使用当前权值前向计算所有神经元值
#h1-cell[0],h1f-cell[1],h2-cell[2],h2f-cell[3],o1-cell[4],of-cell[5]
y_pre = valcell[5] #当前预测结果
#反向传播求导计算,每个节点或权值仅仅需要求导一次,即可覆盖下方所有节点
der_L_y_pre = -2*(y_tr-y_pre) #损失函数L对y_pre求导
#y_pre对h1f求偏导,y_pre就是of, of=sg(o1),o1= h1f*self.w5+h2f*self.w6+self.b3(w5后面做常数处理)
#用下一层的输出对上一层的输出逐层求偏导, 目的是求出对权值的偏导
#(权值是刻画数据的元数据,机器学习的目的就是以数据为依据求出刻画自身的元数据)
der_y_pre_h1f = der_sigmoid(valcell[4])*self.w5
der_y_pre_h2f = der_sigmoid(valcell[4])*self.w6
#print(valcell,der_y_pre_h2f)
#h1f对w1,w2求偏导
der_h1f_w1 = der_sigmoid(valcell[0])*x[0]
der_h1f_w2 = der_sigmoid(valcell[0])*x[1]
#h2f对w3,w4求偏导
der_h2f_w3 = der_sigmoid(valcell[2])*x[0]
der_h2f_w4 = der_sigmoid(valcell[2])*x[1]
#y_pre对w5w6b3求偏导
der_y_pre_w5 = der_sigmoid(valcell[4])*valcell[1]
der_y_pre_w6 = der_sigmoid(valcell[4])*valcell[3]
der_y_pre_b3 = der_sigmoid(valcell[4])
#h1f对b1求偏导
der_h1f_b1 = der_sigmoid(valcell[0])
#h2f对b2求偏导
der_h2f_b2 = der_sigmoid(valcell[2])
#反向传播,以损失函数为起点反向传播(通过求导链式法则)到各个权值参数
#梯度下降,调整权值,按照学习速率逐渐下降,学习率与梯度的乘积为下降步长。
#即权重和偏置每向前一步,就需要走学习率和当前梯度的乘积这么远
self.w1 -= learn_rate * der_L_y_pre * der_y_pre_h1f * der_h1f_w1
self.w2 -= learn_rate * der_L_y_pre * der_y_pre_h1f * der_h1f_w2
self.w3 -= learn_rate * der_L_y_pre * der_y_pre_h2f * der_h2f_w3
self.w4 -= learn_rate * der_L_y_pre * der_y_pre_h2f * der_h2f_w4
self.w5 -= learn_rate * der_L_y_pre * der_y_pre_w5
self.w6 -= learn_rate * der_L_y_pre * der_y_pre_w6
self.b1 -= learn_rate * der_L_y_pre * der_y_pre_h1f * der_h1f_b1
self.b2 -= learn_rate * der_L_y_pre * der_y_pre_h2f * der_h2f_b2
self.b3 -= learn_rate * der_L_y_pre *der_y_pre_b3
if i % 10 ==0 :
#对训练数据数组作为simulate函数的参数依次进行处理得到当前预测值
y_pred = numpy.apply_along_axis(self.simulate,1,data)
#对真实值与预测值两个数组使用损失函数求均方误差作为参数的评价标准
loss = mse_loss (all_y_tr , y_pred)
print(i,loss)
f.simulate,1,data)
#对真实值与预测值两个数组使用损失函数求均方误差作为参数的评价标准
loss = mse_loss (all_y_tr , y_pred)
print(i,loss)
4.3 梯度消失和梯度爆炸
- 在机器学习的过程中,我们有时候会发现,随着训练轮数的增加,在验证结果并不很好的情况下,网络权重几乎不变了,这其实是很常见的一种问题,造成这种问题的原因有很多,其中一条是传播过程中的梯度消失,与之相对的也有可能出现参数有巨大变化的现象,它的原因可能是在传播过程中出现了梯度爆炸。
梯度消失——反向传播的过程,会有若干个小数,且是小于0.25的数相乘的情况。
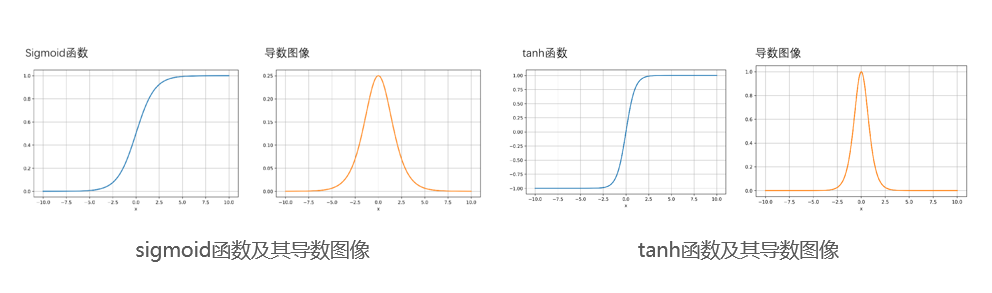
- 对于sigmoid激活函数而言,它的函数曲线和导数曲线如图所示。可以看到当𝑥<−5或𝑥>5的时候,函数接近一条横线,此时斜率约等于0,即使是靠近0附近的线性区,斜率(梯度)也仅有0.25。
- Tanh是另一种常见的激活函数,它虽然0处的导数值为1,但是导数沿正负 轴的方向,下降的都非常快。且tanh依然有饱和区即导数约等于0的区域存在,其函数及其导数图像如右图所示。
- 如果一个深度网络模型使用了这两种激活函数,反向传播的过程,会有若干个小数,且是小于0.25的数相乘的情况,那么在靠近输入层的区域,梯度就会很小,权重的更新值就将接近于0。这就是我们所说的梯度消失。

- 还是以刚才讲解链式法则的例子说明(如图所示),我们刚才推导出了𝑦_3对𝑤_0的偏导数表达形式,我们以𝑓_1,𝑓_2,𝑓_3都是sigmoid函数进行计算。可以算出:
𝑧_0=𝑤_0 𝑥=0.06;𝑦_1=𝑓_1 (𝑧_0 )=0.515;𝑧_1=𝑤_1 𝑦_1=0.103𝑦_2=𝑓_2 (𝑧_1 )=0.525;𝑧_2=𝑤_2 𝑦_2=0.315;𝑦_3=𝑓_3 (𝑧_2 )=0.578
(𝜕𝑦_3)/(𝜕𝑤_0 )=(𝜕𝑦_3)/(𝜕𝑧_2 )×(𝜕𝑧_2)/(𝜕𝑦_2 )×(𝜕𝑦_2)/(𝜕𝑧_1 )×(𝜕𝑧_1)/(𝜕𝑦_1 )×(𝜕𝑦_1)/(𝜕𝑧_0 )×(𝜕𝑧_0)/(𝜕𝑤_0 )=𝑓_3′×𝑤_2×𝑓_2′×𝑤_1×𝑓_1^′×𝑥 =0.000036
- 可以看到,偏导数的值小于 ,是一个非常小的量了。
Relu函数
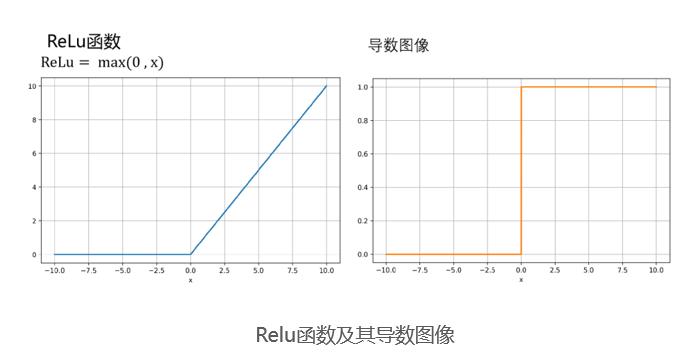
- 为了缓解梯度消失问题,我们可以使用ReLU函数,作为激活函数。如下图所示,只要𝑥大于0,导数就是。那么反向传播过程中偏导数相乘结果的绝对值就不会越来越小了。梯度下降问题可以得到缓解。
梯度爆炸 — 当初始的权重过大(如大于10)时,在反向传播的过程中会造成梯度呈指数增长,在靠近输入层的位置,由于梯度过大,导致权重有非常大的更新。

- 刚刚讲完了梯度下降现象,接下来介绍梯度爆炸现象,梯度爆炸的主要原因不在激活函数,而在于模型的权重,梯度爆炸: 当初始的权重过大(如大于10)时,在反向传播的过程中会造成梯度呈指数增长,在靠近输入层的位置,由于梯度过大,导致权重有非常大的更新。
- 如果一个模型,激活函数都选用了ReLU,而权重的绝对值都很大,那么反向传播过程会发生些什么呢?感兴趣的同学可以自己试一下。
- 想要缓解梯度爆炸,一个常见的做法是优化初始化权重,如使用正态分布的初始化权重。更多的方法就不展开介绍了。
5. 关于作者 & 总结
5.1 关于作者
徐嘉祁 成都锦城学院 飞桨领航团团长
5.2 总结
本文主要介绍了人工智能、机器学习和深度学习的关系、深度学习的基本概念与发展历程、深度学习的应用和发展前景、生物神经网络的基本原理、M-P神经元模型以及阶跃函数和S型函数两种激活函数、感知机模型的原理与应用、感知机的学习过程、感知机的几何意义、感知机可以实现的“与”门、“与非”门、“或”门以及“异或门应用、深度神经网络的概念及结构,深度神经网络的训练过程,最后介绍了梯度消失与梯度爆炸。希望大家通过本文的介绍能够建立起对深度神经网络的了解和认识。
5.3 参考文献:《飞桨产业案例实践库》、《人工智能概论与产业案例赏析》
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 1
1 0
0- 0



 已为社区贡献1436条内容
已为社区贡献1436条内容

所有评论(0)