
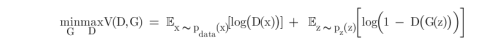
DCGAN伪造名人人脸(一文让你理解GAN)【新手友好】
本项目利用 GAN 的变种 DCGAN来伪造一批名人的人脸图像。所有过程都直接用paddlepaddle来实现,详细展示GAN的网络架构与训练过程,本文代码可以完全复现
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
本项目通过底层paddlepaddle的搭建完成一个比较简单的GAN项目,新手小白也完全可以复现本文代码
摘要
生成式对抗网络(GAN, Generative Adversarial Networks )[1] 是近年来比较流行的一种深
度学习模型,为复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模
块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生
好的输出。本项目利用 GAN 的变种 DCGAN[2] 来伪造一批名人的人脸图像。在本文中,我
将在第 I 节简单介绍 GAN 的原理,然后在第 II 节简述 DCGAN,第 III 节展示数据基本
的预处理,第 IV 节重点介绍 DCGAN 网络的架构,包括生成器和编码器两部分,第 V 节
展示相关的训练过程,第 VI 节为本项目的结果展示。相关数据集可在右边的网站进行下载:
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html 本文的代码可以直接复现。
I. 什么是 GAN?(What is GAN?)
生成对抗网络 (GAN)[1] 是深度学习(Deep Learning)模型的一种框架,使得 DL 模型可以
捕获训练数据的分布,这样我们就可以在相同的数据分布中生成新的数据。GAN 是 Goodfellow
于 2014 年发明的,并在 Generative Adversarial Nets 论文中首次提出。它由两个不同的模型组
成,一个生成器 (generator) 和一个判别器 (discriminator)。生成器的目标是生成类似于训练图
片的图片,判别器的目标是,输入一张图片,判断输入的图片是真图片还是生成器产生的假图
片。在训练过程中,生成器不断的生成更好的假图片试图骗过判别器,而判别器则在努力成为
更好的鉴别者,正确的对真假图片进行分类。这个游戏的平衡点就是生成器产生的图片就好像
是从训练图片中取出的一样,判别器总是有 50% 的置信度鉴别生成器的图片是真还是假。
在这里定义一些本项目中使用到的符号,方便读者理解与阅读:从判别器(discriminator)
开始。设 x 表示图像数据。D(x) 表示判别器,它的输出是一个表示这张图片真假的概率值 (标
量)。这里,我们处理的是 CHW(channel,height,width)为 36464 大小的图像。作为判别
器,其主要作用是为了鉴别真假,那么如果 x 来自训练真实样本,D(x) 的值应该较高,相反 x
如果来自生成器生成的假数据时,D(x) 应该较低。所以从本质来看,D(x) 就是传统的二元分
类器,其损失函数可以表示为二元交叉熵损失函数 (binary cross entropy)[3]。
对于生成器(generator )的符号,设 z 是从标准正态分布采样的隐向量 (该值在初始时就
是一个噪音),G(z) 表示将隐向量 z 映射到数据空间的生成函数。G 的目标是估算训练数据的
分布(pdata),以便从估计的分布(pg)中生成假样本。
因此,D(G(z)) 是生成器 G 输出是真实图片的概率(标量)。正如 Goodfellow 的论文中所
描述的:D 和 G 在玩一个极大极小博弈:D 试图最大化它能正确分类真赝品的概率 (logD(x)),
而 G 试图最小化 D 预测其输出是假的概率 (log(1−D(G(x))))。从论文中可以看出,GAN 的损
失函数为: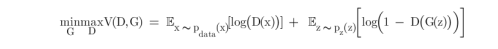
有关本损失函数详细解释可参考 [4] 博客,给出了一个清晰明了的解释。
II. 什么是 DCGAN?(What is DCGAN?)
DCGAN[2] 是 GAN 的一个变种,不同之处在于它在判别器和生成器中分别使用了卷积和
卷积转置层。它是由 Radford 等人在 Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks[2] 论文中首先提出的。其中的判别器由 convolution
层,batch norm 层,和 LeakyReLU 激活函数组成。输入是一个 36464 的图片数据,输出是
一个概率(标量),即输入来自真实数据的分布。其中的生成器由 convolutional-transpose 层,
batch norm 层,和 ReLU 激活函数组成。输入是一个隐向量——z,来自标准正态分布,输出
是一个 36464 的 GRB 图片。卷积转置层可以将隐向量转换成图像的形状。在本文第 IV 节
中,将详细讲解模型的细节结构。
III. 数据预处理 (Data preprocessing)
3.1 数据集介绍 (Dataset introduction)
CelebA 是 CelebFaces Attribute 的缩写,即名人人脸属性数据集,其包含 10,177 个名人
身份的 202,599 张人脸图片,每张图片都做好了特征标记,包含人脸 bbox 标注框、5 个人脸
特征点坐标以及 40 个属性标记,CelebA 由香港中文大学开放提供,广泛用于人脸相关的计
算机视觉训练任务,可用于人脸属性标识训练、人脸检测训练以及 landmark 标记等,官方网
址:http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html, 在本项目中,我们只会使用其中包含图
像数据的压缩包,名为 img_align_celeba.zip。数据集大小大概 13G 左右,包含 20 万张人脸
图片。数据集图片展示如下:

当下载完成之后上传到AI studio即可(本项目已经上传数据集,可以免去下载步骤,如有需要,可去官网查看),创建一个dataset目录并将 zip 文件解压到这个目录下,设置参数 dataroot
为该路径即可。因为我们将使用 ImageFolder 这个数据集类,它要求在这个数据集的根目录下
必须要有子目录。这也是为了方便之后创建数据集和 dataloader。
! unzip /home/aistudio/data/data224771/img_align_celeba.zip -d ./dataset/ #解压数据集
3.2 导入相关依赖 (Import dependent)
import paddle
import paddle.nn as nn
import paddle.vision.transforms as T
import paddle.optimizer as optim
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from paddle.vision.datasets import ImageFolder
from paddle.io import Dataset, DataLoader
3.3 参数定义 (Parameter definition)
- dataroot: 数据集路径(解压后的)
- workers: 多进程加载数据所用的进程数
- batch_size: 一个批次的数据量
- image_size: 图像尺寸
- nc: channel
- nz: 最初的噪声量,大小为1 * 1 * 1000
- ngf:生成器生成的图片尺寸
- ndf:判别器图片尺寸
- num_epochs:训练轮数
- lr: 学习率
- beta1: adam优化器参数,0.5是保证与论文中一致
- ngpu: 可用gpu数量
dataroot = r'/home/aistudio/dataset/img_align_celeba'
workers = 2
batch_size = 128
image_size = 64
nc = 3
nz = 100
ngf = 64
ndf = 64
num_epochs = 20
lr = 0.0002
beta1 = 0.5
ngpu = 1
3.4 数据加载 (Data loading)
通过ImageFolder 这个数据集类进行图片的加载,这个类在加载图片时有格
式要求,必须在数据集文件夹下每个类别图片单独为一个文件夹,否则运行时会报错。然后创建dataset, 再构建dataloader, 在jupyter notebook 中可通过 matplotlib 这个库展示一个批次的数据。
dataset = ImageFolder(root=dataroot,
transform=T.Compose([
T.Resize(image_size),
T.CenterCrop(image_size),
T.ToTensor(),
T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]))
# Create the dataloader
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 绘图函数,将图片拼成8*8的网格进行展示
def make_grid(tensor_list, nrow=8, padding=2, normalize=False, scale_each=False):
if normalize:
tensor_list = [tensor / 2 + 0.5 for tensor in tensor_list]
if scale_each:
tensor_list = [tensor * 255 / (tensor.max() - tensor.min()) for tensor in tensor_list]
grid = np.concatenate([np.concatenate([tensor.numpy().transpose((1, 2, 0)) for tensor in tensor_list[i:i+nrow]], axis=1)
for i in range(0, len(tensor_list), nrow)], axis=0)
if padding > 0:
grid = np.pad(grid, pad_width=[(padding, padding), (padding, padding), (0, 0)], mode='constant')
return grid
real_batch = next(iter(dataloader)) # [128, 3, 64, 64]
grid_np = make_grid(real_batch[0][:64], padding=2, normalize=True)
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Training Images")
plt.imshow(grid_np)
plt.show()

IV.网络结构 (Network structure)
这一部分可谓是整个项目最精华的一部分,我将在 4.1 节给出权重初始化的代码,然后在
4.2 以及 4.3 节分别给出生成器以及判别器的详细实现,然后在 4.4 节给出优化器和损失函数的
选择。
4.1 初始化权重 (Initial weight)
在 DCGAN 的论文中,作者指定所有模型的初始化权重是一个均值为 0,标准差为 0.02 的
正态分布。weights_init 函数的输入是一个初始化的模型,然后按此标准重新初始化模型的卷
积层、卷积转置层和 BN 层的权重。模型初始化后应立即应用此函数。
# 初始化函数
def weights_init(m):
classname = m.__class__.__name__
if 'Conv' in classname:
nn.initializer.Normal(mean=0.0, std=0.02)(m.weight)
elif 'BatchNorm' in classname:
nn.initializer.Normal(mean=1.0, std=0.02)(m.weight)
nn.initializer.Constant(value=0.0)(m.bias)
4.2 生成器 (Generator)
生成器 G, 用于将初始噪音 (z) 映射到数据空间。由于我们的数据是图片,也就是通过隐向量 z(即噪音) 生成一张与训练图片大小相同的 RGB 图片 (比如 3x64x64). 在实践中,这是通过一系列的ConvTranspose2d,BatchNorm2d,ReLU 完成的。生成器的输出,通过 tanh 激活函数把数据映射到 [−1,1]。值得注意的是,在卷积转置层之后紧跟 BN 层,这些层(即 BN 层)
有助于训练过程中梯度的流动。DCGAN 论文中的生成器如图所示:
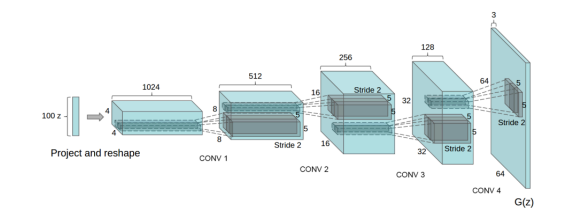
注意,我们在 3.3 小节设置的参数 (nz, ngf, and nc) 影响着生成器 G 的架构。nz 是隐向量 z 的长度, 这里是 1000,即输入是一个 111000 的向量;ngf 为生成器的特征图大小,大小为 64(这是因为真实数据的大小为 64);nc 是输出图片(若为 RGB 图像,则设置为 3)的通道数。生成器的代码如下:
class Generator(nn.Layer):
def __init__(self, ngpu, nz, ngf, nc):
super(Generator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is Z, going into a convolution
nn.Conv2DTranspose(in_channels=nz, out_channels=ngf * 8, kernel_size=4, stride=1, padding=0, bias_attr=False),
nn.BatchNorm2D(ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.Conv2DTranspose(in_channels=ngf * 8, out_channels=ngf * 4, kernel_size=4, stride=2, padding=1, bias_attr=False),
nn.BatchNorm2D(ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.Conv2DTranspose(in_channels=ngf * 4, out_channels=ngf * 2, kernel_size=4, stride=2, padding=1, bias_attr=False),
nn.BatchNorm2D(ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.Conv2DTranspose(in_channels=ngf * 2, out_channels=ngf, kernel_size=4, stride=2, padding=1, bias_attr=False),
nn.BatchNorm2D(ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.Conv2DTranspose(in_channels=ngf, out_channels=nc, kernel_size=4, stride=2, padding=1, bias_attr=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
DCGAN 与众不同的是,他采用了逆卷积,其输入是 111000 的向量,生成器最后的输出是64643 的伪照片,尺寸计算公式如下:
output = (input - 1)*stride + outputpadding - 2*padding + kernelsize
如果你想了解更多关于逆卷积的知识,参见 [5],实例化生成器,并应用 weights_init 方法。打印并查看生成器的结构
netG = Generator(ngpu, nz, ngf, nc)
netG.apply(weights_init)
print(netG)
Generator(
(main): Sequential(
(0): Conv2DTranspose(100, 512, kernel_size=[4, 4], data_format=NCHW)
(1): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
(2): ReLU(name=True)
(3): Conv2DTranspose(512, 256, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(4): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(5): ReLU(name=True)
(6): Conv2DTranspose(256, 128, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(7): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(8): ReLU(name=True)
(9): Conv2DTranspose(128, 64, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(10): BatchNorm2D(num_features=64, momentum=0.9, epsilon=1e-05)
(11): ReLU(name=True)
(12): Conv2DTranspose(64, 3, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(13): Tanh()
)
)
4.3 判别器 (Discriminator)
如前所述,判别器 D 是一个二分类网络,它将图片作为输入,输出其为真的标量概率。这
里,D 的输入是一个 36464 的图片,通过一系列的 Conv2d, BatchNorm2d, 和 LeakyReLU
层对其进行处理,最后通过 Sigmoid 激活函数输出最终概率。如有必要,你可以使用更多层对
其扩展。DCGAN 论文提到使用跨步卷积而不是池化进行降采样是一个很好的实践,因为它可
以让网络自己学习池化方法。BatchNorm2d 层和 LeakyReLU 层也促进了梯度的健康流动,这
对生成器 G 和判别器 D 的学习过程都是至关重要的。
class Discriminator(nn.Layer):
def __init__(self, ngpu, nc, ndf):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.main = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2D(nc, ndf, 4, 2, 1, bias_attr=False),
nn.LeakyReLU(0.2),
# state size. (ndf) x 32 x 32
nn.Conv2D(ndf, ndf * 2, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(ndf * 2),
nn.LeakyReLU(0.2),
# state size. (ndf*2) x 16 x 16
nn.Conv2D(ndf * 2, ndf * 4, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(ndf * 4),
nn.LeakyReLU(0.2),
# state size. (ndf*4) x 8 x 8
nn.Conv2D(ndf * 4, ndf * 8, 4, 2, 1, bias_attr=False),
nn.BatchNorm2D(ndf * 8),
nn.LeakyReLU(0.2),
# state size. (ndf*8) x 4 x 4
nn.Conv2D(ndf * 8, 1, 4, 1, 0, bias_attr=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
实例化判别器,并应用 weights_init 方法。打印并查看判别器的结构。
netD = Discriminator(ngpu,nc,ndf)
netD.apply(weights_init)
print(netD)
Discriminator(
(main): Sequential(
(0): Conv2D(3, 64, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(1): LeakyReLU(negative_slope=0.2)
(2): Conv2D(64, 128, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(3): BatchNorm2D(num_features=128, momentum=0.9, epsilon=1e-05)
(4): LeakyReLU(negative_slope=0.2)
(5): Conv2D(128, 256, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(6): BatchNorm2D(num_features=256, momentum=0.9, epsilon=1e-05)
(7): LeakyReLU(negative_slope=0.2)
(8): Conv2D(256, 512, kernel_size=[4, 4], stride=[2, 2], padding=1, data_format=NCHW)
(9): BatchNorm2D(num_features=512, momentum=0.9, epsilon=1e-05)
(10): LeakyReLU(negative_slope=0.2)
(11): Conv2D(512, 1, kernel_size=[4, 4], data_format=NCHW)
(12): Sigmoid()
)
)
(12): Sigmoid()
)
)
4.4 损失函数及优化器 (Loss Functions and Optimizers)
有了生成器 D 和判别器 G,我们可以为其指定损失函数和优化器来进行学习。这里将使用
Binary Cross Entropy 损失函数 [3] (BCELoss)。注意这个损失函数需要你提供两个 log 组件
(比如 log(D(x)) 和 log(1−D(G(z))))。我们可以指定 BCE 的哪个部分使用输入 y 标签。这将
会在接下来的训练小节中讲到,但是明白我们可以仅仅通过改变 y 标签来指定使用哪个 log 部
分是非常重要的 (比如 GT 标签)。
接下来,我们定义真实标签为 1,假标签为 0。这些标签用来计算生成器 D 和判别器 G
的损失,这也是原始 GAN 论文的惯例。最后,我们将设置两个独立的优化器,一个用于生成
器 G,另一个判别器 D。如 DCGAN 论文所述,两个 Adam 优化器学习率都为 0.0002,Beta1
都为 0.5。为了记录生成器的学习过程,我们将会生成一批符合高斯分布的固定的隐向量(即
fixed_noise)。在训练过程中,我们将周期性地把固定噪声作为生成器 G 的输入,通过输出看
到由噪声生成的图像。
criterion = nn.BCELoss()
fixed_noise = paddle.randn([64, nz, 1, 1], dtype='float32')
real_label = 1.0
fake_label = 0.0
optimizerD = optim.Adam(parameters=netD.parameters(), learning_rate=lr, beta1=beta1, beta2=0.999)
optimizerG = optim.Adam(parameters=netG.parameters(), learning_rate=lr, beta1=beta1, beta2=0.999)
V. 训练 (Training)
训练分为两个部分。第一部分更新判别器,第二部分更新生成器。
第一部分——训练判别器(Part 1 - Train the Discriminator)
回想一下,判别器的训练目的是最大化输入正确分类的概率。从 Goodfellow 的角度来看,我
们希望“通过随机梯度的变化来更新鉴别器”。实际上,我们想要最大化 log(D(x))+log(1−D(G(z)))。
为了区别 mini-batch,ganhacks 建议分两步计算。第一步,我们将会构造一个来自训练数据的
真图片 batch,作为判别器 D 的输入,计算其损失 loss(log(D(x)),调用 backward 方法计算梯
度。第二步,我们将会构造一个来自生成器 G 的假图片 batch,作为判别器 D 的输入,计算其
损失 loss(log(1−D(G(z))),调用 backward 方法累计梯度。最后,调用判别器 D 优化器的 step
方法更新一次模型(即判别器 D)的参数。
第二部分——训练生成器(Part 2 - Train the Generator)
如原论文所述,我们希望通过最小化 log(1−D(G(z))) 训练生成器 G 来创造更好的假图片。
作为解决方案,我们希望最大化 log(D(G(z)))。通过以下方法来实现这一点:使用判别器 D 来
分类在第一部分 G 的输出图片,计算损失函数的时候用真实标签(记做 GT),调用 backward
方法更新生成器 G 的梯度,最后调用生成器 G 优化器的 step 方法更新一次模型(即生成器
G)的参数。使用真实标签作为 GT 来计算损失函数看起来有悖常理,但是这允许我们可以使
用 BCELoss 的 log(x) 部分而不是 log(1−x) 部分
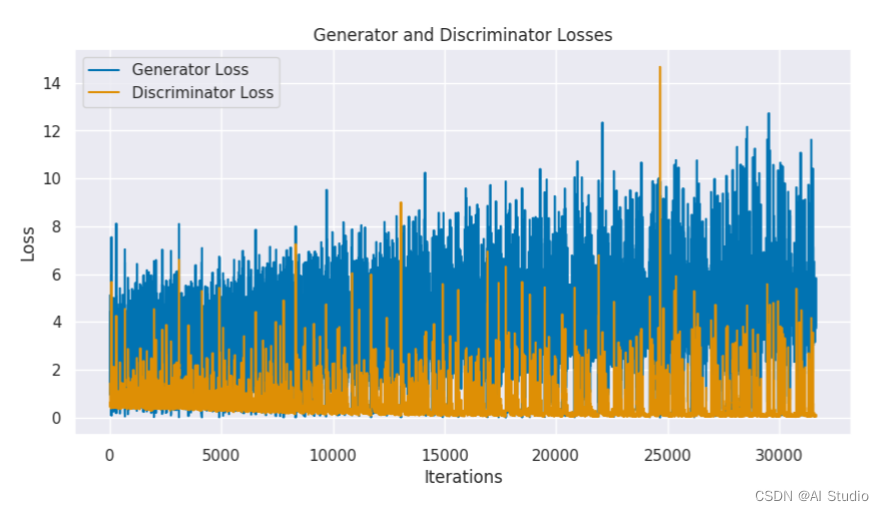
训练过程中统计数据报告如下:
(1) Loss_D - 真假 batch 图片输入判别器后,所产生的损失总和 ((log(D(x)) + log(D(G(z))))).
(2) Loss_G - 生成器损失总和 (log(D(G(z))))
(3) D(x) - 真 batch 图片输入判别器后,所产生的的平均值(即平均概率)。这个值理论
上应该接近 1,然后随着生成器的改善,它会收敛到 0.5 左右。
(4) D(G(z)) - 假 batch 图片输入判别器后,所产生的平均值(即平均概率)。第一个值在
判别器 D 更新之前,第二个值在判别器 D 更新之后。这两个值应该从接近 0 开始,随着 G 的
改善收敛到 0.5。
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starting Training Loop...")
# 每轮迭代
for epoch in range(num_epochs):
# dataloader中每个批次进行迭代
for i, data in enumerate(dataloader, 0):
############################
# (1)最大化优化判别器 log(D(x)) + log(1 - D(G(z)))
###########################
## 用全真标签进行训练
netD.clear_gradients()
real_cpu = data[0]
b_size = real_cpu.shape[0]
label = paddle.full((b_size,), real_label, dtype='float32')
output = netD(real_cpu).reshape([-1])
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
## 用全假标签进行训练
# 生成初始噪音
noise = paddle.randn([b_size, nz, 1, 1], dtype='float32')
# 生成假图片
fake = netG(noise)
label.fill_(fake_label)
# 用判别器进行分类假图片
output = netD(fake.detach()).reshape([-1])
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
# Update D
optimizerD.step()
############################
# (2) 更新生成器 log(D(G(z)))
###########################
netG.clear_gradients()
label.fill_(real_label)
output = netD(fake).reshape([-1])
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.numpy(), errG.numpy(), D_x, D_G_z1, D_G_z2))
G_losses.append(errG.numpy())
D_losses.append(errD.numpy())
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with paddle.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(make_grid(fake, padding=2, normalize=True))
iters += 1
VI. 结果 (Result)
通过 matplotlib 来可视化存放在 img_list 中的图像。左边为真实数据图像,右边为网络拟
合出的伪造人脸图片。如果你觉得不够逼真,可以增加训练轮数以达到足够逼真
# 训练过程的损失展示
sns.set(style="darkgrid", palette="colorblind")
plt.figure(figsize=(10, 5))
plt.plot(G_losses, label="Generator Loss")
plt.plot(D_losses, label="Discriminator Loss")
plt.xlabel("Iterations")
plt.ylabel("Loss")
plt.title("Generator and Discriminator Losses")
plt.legend()
plt.show()
real_batch = next(iter(dataloader)) # [128, 3, 64, 64]
grid_real = make_grid(real_batch[0][:64], padding=2, normalize=True)
plt.figure(figsize=(15, 15))
plt.subplot(1, 2, 1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(grid_real)
plt.show()

# 展示生成的图片
plt.figure(figsize=(10, 10))
plt.axis("off")
plt.title("Generated Images")
plt.imshow(img_list[-1])
plt.show()

引用 (Reference)
[1] 生成对抗网络论文原址:
Conditional Generative Adversarial Netshttps://arxiv.org/abs/1406.2661
[2] DCGAN 论文原址:
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial
Networks https://arxiv.org/abs/1511.06434
[3] 二元交叉熵损失函数详解:
https://blog.csdn.net/Cy_coding/article/details/116427968
[4] GANS 损失函数详解:
https://zhuanlan.zhihu.com/p/562091596
[5] 逆卷积详解:😕/zhuanlan.zhihu.com/p/485999111
作者:唐星冉 大连理工大学 百度大工飞桨领航团团长
此文章为搬运
原项目链接

学大模型,用大模型上飞桨星河社区!每天8点V100G算力免费领!免费领取ERNIE 4.0 100w Token >>>
更多推荐



 0
0 0
0- 0



 已为社区贡献1437条内容
已为社区贡献1437条内容

所有评论(0)